Wir starten diesen Dezember das allererste Open Source Virtualisierungs-Treffen oder englisch: Open Source Virtualization Gathering! Begleiten Sie uns zu einem Abend des offenen Austauschs rund um Virtualisierung mit Technologien wie KVM, Proxmox und XCP-ng.
Liebe Open-Source-Community, liebe Partner und Kunden,
wir freuen uns, Ihnen mitteilen zu können, dass die credativ GmbH wieder Mitglied der Open Source Business Alliance (OSBA) in Deutschland ist. Diese Rückkehr ist für uns eine Herzensangelegenheit und knüpft an eine langjährige Tradition an, denn bereits vor der Übernahme durch NetApp war die credativ® ein aktives und engagiertes Mitglied der Allianz. Wir blicken mit großer Freude auf die erneute Zusammenarbeit und die Möglichkeit, wieder aktiv an der Gestaltung der Open-Source-Landschaft in Deutschland mitzuwirken.
Die OSBA
Die OSBA hat sich zum Ziel gesetzt, den Einsatz von Open-Source-Software (OSS) in Unternehmen und der öffentlichen Verwaltung zu stärken. Dieses Ziel teilen wir aus tiefster Überzeugung. Unsere erneute Mitgliedschaft soll nicht nur die Vernetzung innerhalb der Community fördern, sondern vor allem auch die wichtige Arbeit der OSBA unterstützen, den öffentlichen Dialog über die Vorteile von Open Source zu intensivieren.
Mit unserer Mitgliedschaft bekräftigen wir unser Engagement für eine offene, kollaborative und souveräne digitale Zukunft. Wir freuen uns darauf, gemeinsam mit der OSBA und allen Mitgliedern die Vorteile von Open Source weiter voranzutreiben.
Schleswig-Holsteins Weg
Wir sehen in Open-Source-Lösungen nicht nur eine kosteneffiziente Alternative, sondern vor allem einen Weg zu mehr digitaler Souveränität. Das Bundesland Schleswig-Holstein ist hierbei ein leuchtendes Beispiel: Es zeigt, wie die öffentliche Hand den Wandel einleiten und die Abhängigkeit von kommerzieller Software reduzieren kann. Dies führt nicht nur zu Einsparungen, sondern auch zur Unabhängigkeit von den Geschäftsmodellen und politischen Einflüssen ausländischer Anbieter.
Open Source Wettbewerb
Ein weiteres Highlight in der Open-Source-Szene ist der diesjährige Open-Source-Wettbewerb der OSBA. Wir freuen uns besonders, dass dieser bedeutende Wettbewerb in diesem Jahr unter der Schirmherrschaft von Bundesdigitalminister Dr. Karsten Wildberger steht. Dies unterstreicht die wachsende Bedeutung von Open Source auf politischer Ebene. Begleitender Träger ist das Zentrum für Digitale Souveränität (ZenDiS), das ebenfalls die Relevanz des Themas betont.
Wir sind überzeugt, dass der Wettbewerb einen wichtigen Beitrag zur Förderung innovativer Open-Source-Projekte leisten wird und freuen uns auf die daraus entstehenden Impulse.
Weitere Informationen zum Wettbewerb finden Sie hier:
credativ GmbH ist wieder Mitglied der Open Source Business Alliance (OSBA) in Deutschland.
Die OSBA fördert den Einsatz von Open-Source-Software in Unternehmen und der öffentlichen Verwaltung.
Mitgliedschaft bekräftigt das Engagement für eine offene digitale Zukunft und fördert den Dialog über Open Source.
Schleswig-Holstein zeigt, wie Open-Source-Lösungen die digitale Souveränität erhöhen können.
Der Open-Source-Wettbewerb der OSBA steht unter der Schirmherrschaft von Bundesdigitalminister Dr. Karsten Wildberger.
Migration von VMs von VMware ESXi zu Proxmox
Als Reaktion auf Broadcoms jüngste Änderungen im Abonnementmodell von VMware überdenken immer mehr Unternehmen ihre Virtualisierungsstrategien. Angesichts erhöhter Bedenken hinsichtlich Lizenzkosten und Feature-Zugänglichkeit wenden sich Unternehmen open source Lösungen zu, um mehr Flexibilität und Kosteneffizienz zu erzielen. Proxmox VE hat insbesondere als praktikable Alternative große Aufmerksamkeit erregt. Bekannt für seinen robusten Funktionsumfang und seine offene Architektur bietet Proxmox eine überzeugende Plattform für Organisationen, die die Auswirkungen proprietärer Lizenzmodelle mindern und gleichzeitig umfassende Virtualisierungsfunktionen beibehalten möchten. Dieser Trend unterstreicht eine breitere Branchenverschiebung hin zur Akzeptanz von open source Technologien als praktikable Alternativen in der Virtualisierungslandschaft. Es sei erwähnt, dass Proxmox weithin als praktikable Alternative zu VMware ESXi bekannt ist, aber es gibt auch andere Optionen, wie zum Beispiel bhyve, die wir auch in einem unserer Blogbeiträge behandelt haben.
Vorteile von Open-Source-Lösungen
In der dynamischen Landschaft des modernen Geschäftslebens stellt die Entscheidung für open source Lösungen für die Virtualisierung einen strategischen Vorteil für Unternehmen dar. Mit Plattformen wie KVM, Xen und sogar LXC-Containern können Unternehmen von der Abwesenheit von Lizenzgebühren profitieren, was erhebliche Kosteneinsparungen ermöglicht und Ressourcen in Innovation und Wachstum umleitet. Diese finanzielle Flexibilität ermöglicht es Unternehmen, strategische Investitionen in ihre IT-Infrastruktur zu tätigen, ohne die Belastung durch proprietäre Lizenzkosten. Darüber hinaus fördert die Open-Source-Virtualisierung die Zusammenarbeit und Transparenz, sodass Unternehmen ihre Umgebungen an ihre individuellen Bedürfnisse anpassen und nahtlos in bestehende Systeme integrieren können. Durch die Community-gesteuerte Entwicklung und robuste Support-Netzwerke erhalten Unternehmen Zugang zu einem reichen Wissens- und Ressourcenpool, der die Zuverlässigkeit, Sicherheit und Skalierbarkeit ihrer virtualisierten Infrastruktur gewährleistet. Die Nutzung der Open-Source-Virtualisierung bietet nicht nur greifbare finanzielle Vorteile, sondern stattet Unternehmen auch mit der Agilität und Anpassungsfähigkeit aus, die sie benötigen, um in einer sich ständig weiterentwickelnden digitalen Landschaft erfolgreich zu sein.
Migrieren einer VM
Voraussetzungen
Um einen reibungslosen Migrationsprozess von VMware ESXi zu Proxmox zu gewährleisten, müssen mehrere wichtige Schritte unternommen werden. Zunächst muss der SSH-Zugriff sowohl auf dem VMware ESXi-Host als auch auf dem Proxmox-Host aktiviert werden, um die Remote-Verwaltung und -Administration zu ermöglichen. Zusätzlich ist es entscheidend, Zugriff auf beide Systeme zu haben, um den Migrationsprozess zu erleichtern. Des Weiteren ist die Herstellung einer SSH-Verbindung zwischen VMware ESXi und Proxmox für eine nahtlose Kommunikation zwischen den beiden Plattformen unerlässlich. Dies gewährleistet eine effiziente Datenübertragung und -verwaltung während der Migration. Darüber hinaus ist es zwingend erforderlich, das Proxmox VE-System oder den Cluster ähnlich dem ESXi-Setup zu konfigurieren, insbesondere hinsichtlich der Netzwerkkonfigurationen. Dies beinhaltet die Sicherstellung der Kompatibilität mit VLANs oder VXLANs für komplexere Setups. Zusätzlich sollten beide Systeme entweder auf lokalem Speicher laufen oder Zugriff auf gemeinsamen Speicher, wie NFS, haben, um die Übertragung von virtuellen Maschinendaten zu erleichtern. Schließlich ist es vor Beginn der Migration unerlässlich zu überprüfen, ob das Proxmox-System über ausreichend verfügbaren Speicherplatz verfügt, um die importierte virtuelle Maschine aufzunehmen und so einen erfolgreichen Übergang ohne Speicherengpässe zu gewährleisten.
SSH auf ESXi aktivieren
Der SSH-Server muss aktiviert sein, um den Inhalt vom ESXi-System an den neuen Speicherort auf dem Proxmox-Server zu kopieren. Die virtuelle Maschine wird später auf den Proxmox-Server kopiert. Daher ist es notwendig, dass das Proxmox-System eine SSH-Verbindung über tcp/22 zum ESXi-System herstellen kann:
Melden Sie sich beim VMware ESXi-Host an.
Navigieren Sie zu Konfiguration > Sicherheitsprofil.
Aktivieren Sie SSH unter Dienste.
Quellinformationen über VM auf ESXi finden
Eine der herausfordernden Aufgaben ist das Auffinden des Speicherorts der virtuellen Maschine, die die virtuelle Festplatte enthält. Der Pfad kann in der Web-UI des ESXi-Systems gefunden werden:
Suchen Sie den ESXi-Knoten, auf dem die virtuelle Maschine ausgeführt wird, die migriert werden soll
Identifizieren Sie die zu migrierende virtuelle Maschine (z. B. pgsql07.gyptazy.ch).
Ermitteln Sie den Speicherort der virtuellen Festplatte (VMDK), die der VM zugeordnet ist, über das Konfigurationsfeld.
Der VM-Speicherortpfad sollte angezeigt werden (z. B. /vmfs/volumes/137b4261-68e88bae-0000-000000000000/pgsql07.gyptazy.ch).
VM stoppen und herunterfahren.
Eine neue leere VM auf Proxmox erstellen
Erstellen Sie eine neue leere VM in Proxmox.
Weisen Sie die gleichen Ressourcen wie im ESXi-Setup zu.
Stellen Sie den Netzwerktyp auf VMware vmxnet3 ein.
Stellen Sie sicher, dass die benötigten Netzwerkressourcen (z. B. VLAN, VXLAN) ordnungsgemäß konfiguriert sind.
Stellen Sie den SCSCI-Controller für die Festplatte auf VMware PVSCSI ein.
Erstellen Sie keine neue Festplatte (diese wird später von der ESXi-Quelle importiert).
Jede VM erhält eine von Proxmox zugewiesene ID (notieren Sie diese, sie wird später benötigt).
VM von ESXi zu Proxmox kopieren
Der Inhalt der virtuellen Maschine (VM) wird vom ESXi- auf das Proxmox-System mithilfe des open source Tools rsync zur effizienten Synchronisierung und Kopie übertragen. Daher müssen die folgenden Befehle vom Proxmox-System aus ausgeführt werden, wo wir ein temporäres Verzeichnis zur Speicherung des VM-Inhalts erstellen:
mkdir /tmp/migration_pgsql07.gyptazy.ch
cd /tmp/migration_pgsql07.gyptazy.ch
rsync -avP root@esx02-test.gyptazy.ch:/vmfs/volumes/137b4261-68e88bae-0000-000000000000/pgsq07.gyptazy.ch/* .
Abhängig von der Dateigröße der virtuellen Maschine und der Netzwerkkonnektivität kann dieser Vorgang einige Zeit dauern.
VM in Proxmox importieren
Anschließend wird die Festplatte mit dem qm-Dienstprogramm importiert, wobei die VM-ID (die während des VM-Erstellungsprozesses erstellt wurde) definiert wird, sowie der Festplattenname (der kopiert wurde) und der Zieldatenspeicher auf dem Proxmox-System angegeben werden, wo die VM-Festplatte gespeichert werden soll:
qm disk import 119 pgsql07.gyptazy.ch.vmdk local-lvm
Abhängig vom Erstellungsformat der VM oder dem Exportformat kann es mehrere Festplattendateien geben, die auch mit _flat ergänzt werden können. Dieses Verfahren muss für alle verfügbaren Festplatten wiederholt werden.
VM starten
Im letzten Schritt sollten alle Einstellungen, Ressourcen, Definitionen und Anpassungen des Systems gründlich überprüft werden. Nach der Validierung kann die VM gestartet werden, um sicherzustellen, dass alle Komponenten für den Betrieb in der Proxmox-Umgebung korrekt konfiguriert sind.
Fazit
Dieser Artikel behandelt nur eine von vielen möglichen Methoden für Migrationen in einfachen, eigenständigen Setups. In komplexeren Umgebungen mit mehreren Host-Knoten und verschiedenen Speichersystemen wie Fibre Channel oder Netzwerkspeicher gibt es erhebliche Unterschiede und zusätzliche Überlegungen. Darüber hinaus kann es spezifische Anforderungen in Bezug auf Verfügbarkeit und Service Level Agreements (SLAs) geben, die zu berücksichtigen sind. Dies kann für jede Umgebung sehr spezifisch sein. Sie können sich jederzeit gerne an uns wenden, um eine persönliche Beratung zu Ihren spezifischen Migrationsanforderungen zu erhalten. Gerne bieten wir Ihnen auch unsere Unterstützung in verwandten Bereichen in open source wie Virtualisierung (z. B. OpenStack, VirtualBox) und Themen im Zusammenhang mit Cloud-Migrationen an.
Nachtrag
Am 27. März hat Proxmox seinen neuen Import-Assistenten (pve-esxi-import-tools) veröffentlicht, der Migrationen von VMware ESXi-Instanzen in eine Proxmox-Umgebung erheblich vereinfacht. In einem kommenden Blogbeitrag werden wir weitere Informationen zu den neuen Tools und Anwendungsfällen bereitstellen, in denen diese nützlicher sein könnten, aber auch die Randfälle behandeln, in denen der neue Import-Assistent nicht verwendet werden kann.
Nachdem die vorausgegangenen Artikel eine Einführung in AppArmor gegeben sowie das Vorgehen zum Erstellen eines AppArmor-Profils für nginx beschrieben haben, geht dieser Artikel noch einen Schritt weiter: neben statischen Inhalten soll der nginx-Webserver auch klassische CGI-Scripte ausführen und deren Ausgabe zurückliefern können.
Obwohl das Common Gateway Interface, kurz CGI, seine Hochzeit in den 1990er Jahren erlebte und vielerorts durch modernere Alternativen verdrängt wurde, finden sich auch heute noch Systeme und Prozesse bei denen jahrzehntelang gepflegte CGI-Scripte zum Einsatz kommen.
Unabhängig davon eignet sich die Thematik für diesen Artikel deshalb besonders, weil der Aufbau und die Einrichtung eines Szenarios einfach genug zu beschreiben ist, sodass das eigentliche Thema für diesen Artikel, nämlich AppArmor-Kindprofile, problemlos auf andere Konstrukte übertragen werden kann.
nginx und fcgiwrap
Eine weit verbreitete Methode, um den nginx-Webserver um die Fähigkeit CGI-Scripte ausführen zu können zu erweitern, ist die Verwendung von fcgiwrap.
Die Projektbeschreibung nennt fcgiwrap einen “einfachen FastCGI-Wrapper für CGI-Scripte”, also ein Programm, das herkömmliche CGI-Scripte ausführt und für diese die FastCGI-Kommunikation mit dem Webserver übernimmt, ohne dass die eigentlichen Scripte angepasst werden müssen.
Um den Rahmen dieses Artikels nicht zu sprengen sei auf die Anleitung aus dem nginx-Wiki zur Installation und Konfiguration von fcgiwrap verwiesen.
Beispielkonfiguration
Das folgende Listing zeigt die für unser Szenario verwendete Konfigurationsdatei /etc/nginx/conf.d/cgi-bin.conf, welche auf der von fcgiwrap mitgelieferten Beispielkonfiguration, zu finden unter /usr/share/doc/fcgiwrap/examples/nginx.conf, basiert.
Aus dem Listing ist leicht zu entnehmen, dass sich im Ordner /cgi-bin/ unterhalb des root-Verzeichnisses /var/www Scripte befinden, die ausgeführt werden sollen – in diesem Szenario handelt es sich dabei um einfache Python-Scripte.
Das Programm fcgiwrap läuft als eigenständiger Prozess auf dem System und öffnet ein Unix-Socket, über das der nginx-Webserver gemäß dem FastCGI-Protokoll mit fcgiwrap kommunizieren kann, um die Ausführung der Scripte zu veranlassen und die dabei erzeugte Ausgabe zurück zu erhalten.
Für die Überwachung und Absicherung des nginx-Webservers mittels AppArmor wird das im vorherigen Artikel erstellte Profil benutzt. Obwohl bislang ungenutzte Funktionen des nginx zum Einsatz kommen muss dieses nicht angepasst werden: auf den Ordner cgi-bin/ greift der Webserver selbst überhaupt nicht zu; stattdessen veranlasst er fcgiwrap über das Socket das angeforderte Script auszuführen.
Auch der Zugriff auf das Socket /var/run/fcgiwrap.socket muss nicht explizit erlaubt werden: hierfür existieren bereits Regeln in abstractions/base.
Kindprozesse
Spätestens hier wird klar: wenn nicht nginx, sondern fcgiwrap die Scripte ausführt, greift das verwendete AppArmor-Profil nicht, da dieses nur die nginx-Prozesse überwacht. Es muss also ein weiteres Profil angelegt werden!
Mit einem einzigen Profil für fcgiwrap ist es dabei jedoch nicht getan, denn ein Script, das von fcgiwrap ausgeführt wird, läuft als eigenständiger Kindprozess: für ein Python-Script startet fcgiwrap also beispielsweise den Python-Interpreter – und der sollte dann auch von AppArmor überwacht werden!
Anders gesagt: da ein Profil für fcgiwrap wiederum nur Prozesse der Programmdatei /usr/sbin/fcgiwrap berücksichtigt, liefe der Python-Interpreter ohne AppArmor-Kontrolle. Durch spezielle Execute-Permissions und Kindprofile lässt sich jedoch genau bestimmen ob und in welchem Rahmen Kindprozesse eines von AppArmor überwachten Prozesses ausgeführt werden dürfen.
Kindprofile
Das folgende Listing zeigt den Inhalt des AppArmor-Profils /etc/apparmor.d/usr.sbin.fcgiwrap. Anhand dieses Listings soll die Definition von Kindprofilen erläutert werden:
include <tunables/global>
@{CGIBIN}=/var/www/cgi-bin
profile fcgiwrap /usr/sbin/fcgiwrap {
include <abstractions/base>
/usr/sbin/fcgiwrap mr,
@{CGIBIN}/* rcix,
profile @{CGIBIN}/* {
include <abstractions/base>
include <abstractions/nameservice>
include <abstractions/python>
/usr/bin/python3.9 mr,
@{CGIBIN}/* r,
}
}
Auf den ersten Blick gleicht das gezeigte Profil den Profilen aus den vergangenen Artikeln. Es fällt jedoch auf, dass innerhalb des Profilteils ein weiteres, namenloses Profil definiert wird, dessen Pfadangabe auf alle Dateien in /var/www/cgi-bin/ passt.
Dieses sogenannte Kindprofil wird durch die Regel @{CGIBIN}/* rcix im äußeren Profil auf alle durch fcgiwrap ausgeführten Scripte im Ordner CGIBIN angewendet. Die Permission r steht dabei wie gehabt für Lesezugriff; interessanter ist die Permission cix: x erlaubt wie gehabt die Ausführung der Datei (execute), c gibt jedoch an, dass dabei ein entsprechendes Kindprofil angewendet werden soll. Wird das Kindprofil nicht gefunden sorgt i dafür, dass das aktuelle Profil vererbt (inherited) wird.
Würde die Permission c als Großbuchstabe, also C, angegeben, würden vor der Ausführung die Umgebungsvariablen gelöscht. Da CGI zur einwandfreien Funktion jedoch auf deren Erhalt angewiesen ist, kam diese Option hier nicht in Frage. Als Alternative zu i gibt es die Permission u, die dafür sorgt, dass der Kindprozess unconfined, also uneingeschränkt, läuft, falls das Kindprofil nicht gefunden wird. Auch dies wäre in diesem Falle nicht wünschenswert.
Im Quick guide to AppArmor profile Language findet sich im Abschnitt File permissions eine Übersicht an Möglichkeiten die Execute-Permission genauer zu spezifizieren. In der AppArmor Core Policy Reference werden sie im Abschnitt Execute rules noch einmal genauer gruppiert erläutert.
Da es sich bei Python um eine interpretierte Sprache handelt, werden die Scripte, wie oben erwähnt, nicht selbst ausgeführt, sondern (vereinfacht gesagt) von einem Interpreter geladen und von diesem ausgeführt. Der Aufbau des eigentlichen Kindprofils sollte daher leicht verständlich sein: der Python-Interpreter /usr/bin/python3.9 darf in den Speicher geladen und ausgeführt werden (mr) und alle Dateien im Ordner @{CGIBIN} lesen, eine Berechtigung zur Ausführung ist nicht nötig.
Zur Ausführung eines Python-Scripts werden in der Regel noch verschiedene Bibliotheken und Module benötigt. Diese, beziehungsweise ihre Pfade, wurden bereits in <abstractions/python> zusammengefasst, sodass AppArmor-Profile für Python-Scripte diese Regeln lediglich mittels include einbinden müssen.
Das obige Kindprofil enthält sonst keinerlei Regeln. Daher beschränken sich die erlaubten Zugriffe auf solche, die von den in den Abstractions enthaltenen Regeln definiert werden. Durch die Erfahrungen aus den letzten beiden Artikeln ist das Kindprofil jedoch schnell um entsprechende Regeln erweitert. Auch aa-logprof kann hierbei wieder zu Rate gezogen werden.
Sollen die Scripte beispielsweise Dateien im Verzeichnis /data lesend und schreibend verarbeiten dürfen, geht es von Hand immer noch am schnellsten: es muss lediglich die Zeile /data/* rw, in das Kindprofil eingetragen werden.
Der Anfang ist gemacht
Der Einsatz von Kindprofilen beschränkt sich nicht nur auf Webserver: jegliche Software, die andere Programme als Kindprozess startet lässt sich nach diesem Prinzip genauso gut mit AppArmor überwachen und absichern. Gleiches gilt für Scripte und Interpreter anderer Programmiersprachen.
Wir unterstützen Sie gerne
Ob AppArmor, Debian oder PostgreSQL: mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich kann die credativ GmbH Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Sie haben Fragen zu unserem Artikel oder würden sich wünschen, dass die Spezialisten von credativ sich eine andere Software ihrer Wahl angucken? Dann schauen Sie doch vorbei und melden sich über unser Kontaktformular oder schreiben uns eine E-Mail an info@credativ.de.
Über credativ
Die credativ GmbH ist ein herstellerunabhängiges Beratungs- und Dienstleistungsunternehmen mit Standort in Mönchengladbach. Seit dem erfolgreichen Merger mit Instaclustr 2021 ist die credativ GmbH das europäische Hauptquartier der Instaclustr Gruppe.
Die Instaclustr Gruppe hilft Unternehmen bei der Realisierung eigener Applikationen im großen Umfang dank Managed-Plattform-Solutions für Open Source Technologien wie zum Beispiel Apache Cassandra®, Apache Kafka®, Apache Spark™, Redis™, OpenSearch™, Apache ZooKeeper™, PostgreSQL® und Cadence. Instaclustr kombiniert eine komplette Dateninfrastruktur-Umgebung mit praktischer Expertise, Support und Consulting um eine kontinuierliche Leistung und Optimierung zu gewährleisten. Durch Beseitigung der Komplexität der Infrastruktur wird es Unternehmen ermöglicht, ihre internen Entwicklungs- und Betriebsressourcen auf die Entwicklung innovativer kundenorientierter Anwendungen zu geringeren Kosten zu konzentrieren. Zu den Kunden von Instaclustr gehören einige der größten und innovativsten Fortune-500-Unternehmen.
Wie im vorausgegangenen Beitrag beschrieben erfolgt unter unixoiden Systemen die Rechtekontrolle traditionell nach dem Prinzip der Discretionary Access Control (DAC). Anwendungen und Dienste laufen unter einer bestimmten User- und Group-ID und erhalten die entsprechenden Zugriffsrechte auf Dateien und Ordner.
AppArmor implementiert für Linux, aufbauend auf den Linux Security Modules, eine sogenannte Mandatory Access Control: eine Zugriffskontrollstrategie mit der einzelnen Programmen bestimmte Rechte gewährt oder verweigert werden können. Diese Sicherheitsschicht existiert zusätzlich zur traditionellen DAC.
Seit Debian 10 buster ist AppArmor standardmäßig im Kernel enthalten und aktiviert. Die Pakete apparmor und apparmor-utils bringen Tools zur Erstellung und Pflege von AppArmor-Profilen mit.
Mitgelieferte Profile
Die beiden erwähnten Pakete bringen keine fertigen Profile, sondern lediglich die im vorigen Artikel erwähnten Abstractions mit: Sammlungen von Regeln, die in mehreren Profilen eingebunden werden können.
Manche Programme bringen ihre Profile in ihren Paketen selbst mit, andere enthalten Profile, wenn entsprechende Module nachinstalliert werden – zum Beispiel mod_apparmor beim Apache Webserver.
Die Pakete apparmor-profiles und apparmor-profiles-extra enthalten AppArmor-Profile, die nach der Installation in den Verzeichnissen /etc/apparmor.d (für erprobte Profile) beziehungsweise /usr/share/apparmor/extra-profiles (für experimentelle Profile) zu finden sind. Diese Profile können als Grundlage für eigene Profile herangezogen werden.
Profile selbst erstellen
Während für die meisten gängigen Serverdienste wie beispielsweise den Apache Webserver zumindest experimentelle Profile zur Verfügung stehen, ist für den nginx Webserver nichts zu finden. Dies ist jedoch nicht weiter tragisch, denn ein neues AppArmor-Profil ist mit Hilfe der apparmor-utils schnell erstellt.
Beispiel nginx
Im Folgenden wird eine einfache Basisinstallation des nginx, die lediglich HTML-Dateien unter /var/www/html über HTTP ausliefert, angenommen. Dabei liegt der Fokus vor allem auf der allgemeinen Herangehensweise, sich wiederholende Schritte werden also übersprungen.
Die geschilderte Herangehensweise lässt sich auf beliebige andere Programme übertragen. Um sich über die verwendeten Pfade und Dateien eines Programms zu informieren, kann dpkg mit der Option -L herangezogen werden, welche alle Pfade eines Pakets auflistet. Dabei ist zu beachten, dass hierfür möglicherweise mehrere Pakete befragt werden müssen, für nginx liefert das gleichnamige Paket kaum brauchbare Informationen; diese erhält man erst mit dem Paket nginx-common:
# dpkg -L nginx-common
Für die folgenden Schritte empfiehlt es sich zwei Terminals mit root-Rechten geöffnet zu haben.
Bevor der Webserver-Prozess zur Erstellung eines Profils beobachtet werden kann, müssen all seine laufenden Prozesse beendet werden:
# systemctl stop nginx
Sind alle Prozesse gestoppt, wird im zweiten Terminal aa-genprof mit dem Pfad der Programmdatei des Webservers aufgerufen:
# aa-genprof /usr/sbin/nginx
Es erscheinen einige Informationen zum aktuellen Aufruf von aa-genprof, darunter der Hinweis Profiling: /usr/sbin/nginx, gefolgt von Please start the application to be profiled in another window and exercise its functionality now.
Um dem Folge zu leisten wird im ersten Terminalfenster der Webserver-Prozess wieder gestartet:
# systemctl start nginx
Bevor im zweiten Fenster die Option S zum durchsuchen der Logdateien nach AppArmor-Events aufgerufen wird, sollte der Webserver einige Momente laufen, auch sollte er von einem Browser aus aufgerufen werden, damit möglichst alle üblichen Aktivitäten des Prozesses aufgezeichnet werden.
Ist dies geschehen, können mit einem Druck auf die Taste S die Logdateien nach Events durchsucht werden:
[(S)can system log for AppArmor events] / (F)inish
Reading log entries from /var/log/syslog.
Updating AppArmor profiles in /etc/apparmor.d.
Complain-mode changes:
Wurde ein Event gefunden, wird das betroffene Profil sowie die Aktion angezeigt, die von AppArmor aufgezeichnet wurde:
Hier fordert das Programm /usr/sbin/nginx die Capabilitydac_override an, die bereits im letzten Artikel beschrieben wurde. Sie ist für den Betrieb des Webservers unabdingbar und wird mittels Druck auf A erlaubt. Alternativ kann die Anforderung mit D verweigert oder mit I ignoriert werden. Mit der Option Audit würde diese Anforderung auch weiterhin im laufenden Betrieb in der Logdatei aufgezeichnet.
Das nächste Event zeigt, dass der Prozess die Capabilitynet_bind_service anfordert, der benötigt wird, um einen Port mit einer Portnummer kleiner als 1024 zu öffnen.
Anders als bei der ersten Nachfrage gibt es hier zwei Möglichkeiten den Zugriff zukünftig zu erlauben: in der ersten Option werden Abstractions für NIS, den Network Information Service eingebunden. In dieser Abstraction, welche unter /etc/apparmor.d/abstractions/nis zu finden ist, ist neben einer Regel, die den Zugriff auf Regelwerke für NIS erlaubt auch die Capabilitynet_bind_service aufgeführt.
Da der HTTP-Server jedoch keine NIS-Funktionalität mitbringt, reicht es lediglich die Capability zu erlauben. Mit einem Druck auf 2 und A wird diese in das Profil übernommen.
Gleiches gilt für die in den folgenden Schritten vorgeschlagenen Abstractions für dovecot und postfix: hier genügt es lediglich die Capabilitiessetgid und setuid zu erlauben.
Manchmal kann die Bezeichnung der Abstractions etwas irreführend sein: so enthält die Abstractionnameservice neben Regeln, welche neben dem lesenden Zugriff auf die üblichen Nameservice-Dateien wie passwd oder hosts erlauben auch solche Regeln, die den Netzwerkzugriff gestatten. Es lohnt also immer ein Blick in die jeweilige Datei unter /etc/apparmor.d/abstractions/, ob sich das Einbinden der Abstraction lohnt.
Nachdem der Webserver-Prozess alle nötigen Capabilities erhalten hat, versucht er offenbar seine Fehler-Logdatei /var/log/nginx/log mit Schreibrechten zu öffnen. Hier fällt auf, dass neben dem üblichen Allow, Deny und Ignore noch die Optionen Glob und Glob with Extension hinzugekommen sind.
Der Dateiname error.log wurde durch einen Wildcard und die Endung .log ersetzt. Diese Regel würde neben den Schreibrechten auf die Datei /var/log/nginx/error.log beispielsweise auch solche auf die Datei /var/log/nginx/access.log gewähren – das sind (mindestens) zwei Regeln zusammengefasst zu einer einzigen.
Diese Regeln würde für dieses Beispiel bereits ausreichen, möglicherweise sollen aber auch Dateien, welche nicht die Dateiendung .log besitzen, im Verzeichnis /var/log geschrieben werden dürfen. Durch Eingabe von G wird der Liste noch ein weiterer Vorschlag hinzugefügt:
Der Dateiname wurde nun durch einen einzelnen Wildcard ersetzt, der Prozess dürfte also beliebige Dateien in /var/log/nginx mit Schreibrechten öffnen.
Wie bereits erwähnt werden durch die vorgeschlagenen Regeln ausschließlich Schreib-, jedoch keine Leserechte eingeräumt, selbst wenn die Zugriffsrechte der Datei mehr erlauben würden. Für Logdatei eines Webservers reichen die Schreibrechte jedoch völlig aus.
Im Folgenden verlangt nginx lesenden Zugriff auf verschiedene Konfigurationsdateien, zum Beispiel /etc/nginx/nginx.conf. Diese befindet sich im Konfigurationsverzeichnis des nginx Webservers, in dem noch weitere Dateien liegen, die ebenfalls gelesen werden können sollen.
Profile: /usr/sbin/nginx
Path: /etc/nginx/nginx.conf
New Mode: owner r
Severity: unknown
[1 - owner /etc/nginx/nginx.conf r,]
Auch hier kann mit G die Regel auf alle Dateien des Verzeichnisses /etc/nginx erweitert werden.
Gleiches gilt für die Unterverzeichnisse des Konfigurationsverzeichnisses, diese können durch Globbing als /etc/nginx/*/ abgedeckt werden.
Einen Spezialfall für das Globbing stellen die in jenen Unterverzeichnissen enthaltenen Dateien dar:
Profile: /usr/sbin/nginx
Path: /etc/nginx/sites-available/default
New Mode: owner r
Severity: unknown
[1 - owner /etc/nginx/sites-available/default r,]
Nach zweifacher Eingabe von G wird nach dem von oben bekannten Wildcard * das Wildcard ** vorgeschlagen, welches, wie im vorherigen Artikel beschrieben, alle in Unterverzeichnissen (und deren Unterverzeichnissen) befindlichen Dateien abdeckt.
Die letzten Schritte enthielten außerdem alle das Attribut owner: dieses bewirkt, dass eine Regel ausschließlich dann Anwendung findet, wenn der zugreifende Prozess auch Besitzer der Datei ist. Ist die Datei vorhanden, gehört jedoch jemand anderem, wird der Zugriff verweigert.
Es folgen noch einige weitere Pfade und Dateien wie /usr/share/nginx/modules-available/, /run/nginx.pid und /proc/sys/kernel/random/boot_id, welche der nginx ebenfalls zum ordnungsgemäßen Betrieb benötigt. Die Vorgehensweise bleibt jedoch unverändert.
Sind alle Events durchlaufen schließt das Programm mit der Meldung:
= Changed Local Profiles =
The following local profiles were changed. Would you like to save them?
[1 - /usr/sbin/nginx]
(S)ave Changes / Save Selec(t)ed Profile / [(V)iew Changes] / View Changes b/w (C)lean profiles / Abo(r)t
Die Optionen sind klar: mit S werden Änderungen gespeichert, mit V können diese vorher als Diff angeschaut werden. Das folgende Listing zeigt das im obigen Durchlauf erzeugte Profil.
Nach dem Speichern der Änderungen kehrt aa-genprof zu seinem Startbildschirm zurück. Hier könnte nun erneut in Logdateien nach Events gesucht oder aber das Programm mit F beendet werden.
Das Programm endet mit der Meldung:
Setting /usr/sbin/nginx to enforce mode.
Reloaded AppArmor profiles in enforce mode.
Das soeben erstellte Profil wurde also geladen und in den enforce-Modus versetzt. Das bedeutet, dass dem Programm nur noch im Profil erlaubte Zugriffe möglich sind, alle anderen Zugriffsversuche werden von AppArmor blockiert und im Syslog festgehalten.
Für simple Programme ist die Erstellung eines Profils damit beendet und AppArmor kann seine Arbeit verrichten; komplexere Programme hingegen werden im weiteren Verlauf bislang unbekanntes Verhalten zeigen, das vom bislang erstellten Profil unterbunden würde. Hier hilft es, das Profil mittels aa-complain in den sogenannten complain-Modus zu schalten.
# aa-complain nginx
Zugriffe, welche über das bekannte Profil hinausgehen werden im complain-Modus grundsätzlich erlaubt, aber im Syslog festgehalten.
Im obigen Auszug aus dem Syslog wurde das Webroot-Verzeichnis auf dem Host web01 zu /srv/www geändert, das vormals erstellte AppArmor-Profil jedoch nicht angepasst. Da sich das Profil nun im complain-Modus befindet wurde der Zugriff dennoch erlaubt: apparmor="ALLOWED"; im enforce-Mode stünde dort ein DENIED und der Zugriff würde verweigert.
An den übrigen Informationen ist gut zu erkennen, was passiert ist: der Prozess mit der Prozess-ID (pid) 4190 hat versucht die Datei /srv/www/index.html (name) lesend (requested_mask) zu öffnen, was aufgrund des Profils (profile) nginx jedoch untersagt wäre (denied_mask).
Sollte eine mit AppArmor abgesicherte Software also einmal nicht so funktionieren wie erwartet, lohnt zu allererst ein Blick ins Syslog!
Nach einiger Zeit werden sich dort einige Einträge befinden, die dann in das AppArmor-Profil übernommen werden sollen. Dafür wird das Programm aa-logprof verwendet: es durchsucht das Syslog nach Einträgen und fragt in der Manier von aa-genprof nach, ob und wie darauf Einträge im Profil erstellt werden sollen. Dieser Vorgang kann beliebig oft wiederholt werden.
Finden sich im Syslog keine weiteren Einträge mehr, Wurde das Profil genügend angepasst und kann mit aa-enforce wieder in den enforce-Modus versetzt werden:
# aa-enforce nginx
Damit ist die grundlegende Erstellung eines einfachen AppArmor-Profils abgeschlossen und die Prozesse des nginx werden entsprechend der darin definierten Regeln kontrolliert und überwacht.
Wir unterstützen Sie gerne
Ob AppArmor, Debian oder PostgreSQL: mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich, kann die credativ GmbH Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Sie haben Fragen zu unserem Artikel oder würden sich wünschen, dass die Spezialisten von credativ sich eine andere Software ihrer Wahl angucken?
Dann schauen Sie doch vorbei und melden sich über unser Kontaktformular oder schreiben uns eine E-mail an info@credativ.de.
Über credativ
Die credativ GmbH ist ein herstellerunabhängiges Beratungs- und Dienstleistungsunternehmen mit Standort in Mönchengladbach. Seit dem erfolgreichen Merger mit Instaclustr 2021 ist die credativ GmbH das europäische Hauptquartier der Instaclustr Gruppe.
Die Instaclustr Gruppe hilft Unternehmen bei der Realisierung eigener Applikationen im großen Umfang dank Managed-Plattform-Solutions für Open Source Technologien wie zum Beispiel Apache Cassandra®, Apache Kafka®, Apache Spark™, Redis™, OpenSearch™, Apache ZooKeeper™, PostgreSQL® und Cadence.
Instaclustr kombiniert eine komplette Dateninfrastruktur-Umgebung mit praktischer Expertise, Support und Consulting um eine kontinuierliche Leistung und Optimierung zu gewährleisten. Durch Beseitigung der Komplexität der Infrastruktur, wird es Unternehmen ermöglicht, ihre internen Entwicklungs- und Betriebsressourcen auf die Entwicklung innovativer kundenorientierter Anwendungen zu geringeren Kosten zu konzentrieren. Zu den Kunden von Instaclustr gehören einige der größten und innovativsten Fortune-500-Unternehmen.
Eigentlich ist Zugriffskontrolle unter Linux eine einfache Sache:
Dateien geben ihre Zugriffsrechte (Ausführen, Schreiben, Lesen) getrennt für ihren Besitzer, ihre Gruppe und zu guter Letzt sonstige Benutzer an. Jeder Prozess (egal ob die Shell eines Benutzers oder ein Systemdienst) auf dem System läuft unter einer Benutzer-ID sowie Gruppen-ID, welche für die Zugriffskontrolle herangezogen werden.
Einem Webserver, der mit den Rechten des Users www-data und der Gruppe www-data ausgeführt wird, kann so der Zugriff auf seine Konfigurationsdatei im Verzeichnis /etc, seine Logdatei unter /log und die auszuliefernden Dateien unter /var/www gestattet werden. Mehr Zugriffsrechte sollte der Webserver für seine Arbeit nicht brauchen.
Dennoch könnte er, sei es durch Fehlkonfiguration oder eine Sicherheitslücke, auch auf Dateien anderer Benutzer und Gruppen zugreifen und diese ausliefern, solange diese für jedermann lesbar sind, wie es zum Beispiel technisch bedingt bei /etc/passwd der Fall ist. Mit der traditionellen Discretionary Access Control (DAC), wie sie unter Linux und anderen unixoiden Systemen eingesetzt wird, ist dies leider nicht zu verhindern.
Schon seit Dezember 2003 bietet der Linux-Kernel jedoch mit den Linux Security Modules (LSM) ein Framework an, mit der sich eine Mandatory Access Control (MAC) implementieren lässt, bei der in Regelwerken genau spezifiziert werden kann, auf welche Ressourcen ein Prozess zugreifen darf. AppArmor implementiert eine solche MAC und ist bereits seit 2010 im Linux-Kernel enthalten. Während es ursprünglich nur bei SuSE und später Ubuntu Verwendung fand, ist es seit Buster (2019) auch in Debian standardmäßig aktiviert.
AppArmor
AppArmor überprüft und überwacht auf Basis eines Profils, welche Berechtigungen ein Programm oder Script auf einem System hat. Ein Profil enthält dabei im Normalfall das Regelwerk für ein einzelnes Programm. Darin ist zum Beispiel definiert wie (lesend, schreibend) auf welche Dateien und Verzeichnisse zugegriffen werden darf, ob ein Netzwerksocket erzeugt werden darf oder ob und in welchem Rahmen andere Anwendungen ausgeführt werden dürfen. Alle anderen, nicht im Profil definierten Aktionen, werden verweigert.
Aufbau eines Profils
Das folgende Listing (die Zeilennummern sind nicht Bestandteil der Datei und dienen lediglich der Orientierung) zeigt das Profil für einen einfachen Webserver, dessen Programmdatei unter /usr/sbin/httpd zu finden ist.
Standardmäßig liegen AppArmor-Profile im Verzeichnis /etc/apparmor.d und sind per Konvention nach dem Pfad der Programmdatei benannt. Der erste Schrägstrich wird dabei ausgelassen, alle folgenden Schrägstriche werden durch Punkte ersetzt. Das Profil des Webservers befindet sich demnach in der Datei /etc/apparmor.d/usr.sbin.httpd.
Die Anweisung include in Zeile 1 fügt, wie die gleichnamige C-Präprozessordirektive, den Inhalt anderer Dateien an Ort und Stelle ein. Ist der Dateiname wie hier von spitzen Klammern umgeben, so bezieht sich der angegebene Pfad auf den Ordner /etc/apparmor.d, bei Anführungszeichen ist der Pfad relativ zur Profildatei.
Vereinzelt, wenn auch mittlerweile veraltet, findet sich noch die Schreibweise #include. Da Kommentare in AppArmor-Profilen jedoch mit einem # beginnen und der Rest der Zeile ignoriert wird, führt die alte Schreibweise zu einem Widerspruch: eine vermeintlich auskommentierte #include-Anweisung würde nämlich sehr wohl ausgeführt! Um eine include-Anweisung auszukommentieren empfiehlt sich also ein Leerzeichen nach dem #.
Die Dateien im Unterordner tunables enthalten in der Regel Variablen- und Alias-Definitionen, die von mehreren Profilen benutzt und gemäß dem don’t repeat yourself-Prinzip (DRY) nur an einer Stelle definiert werden.
In Zeile 2 wird mit @{WEBROOT} die Variable WEBROOT angelegt und ihr den Wert /var/www/html zugewiesen. Würden neben dem aktuellen Profil auch noch andere Profile Regeln für das Webroot-Verzeichnis definieren, könnte sie stattdessen auch in einer eigenen Datei tunables definiert und in den entsprechenden Profilen per include eingebunden werden.
Profilteil
Der Profilteil beginnt in Zeile 5 mit dem Schlüsselwort profile. Ihm folgt der Name des Profils, hier httpd, der Pfad der ausführbaren Datei, /usr/sbin/httpd, sowie gegebenenfalls Flags, welche das Verhalten des Profils beeinflussen. Von geschweiften Klammern eingeschlossen folgen dann die einzelnen Regeln des Profils.
Wie bereits zuvor fügt auch in den Zeilen 6 und 7include den Inhalt der angeführten Datei an Ort und Stelle ein. Im Unterordner abstractions befinden sich gemäß dem DRY-Prinzip Dateien mit Regelsätzen, die in der gleichen Form immer wieder auftreten, da sie grundlegende aber auch spezifische Funktionalitäten behandeln.
So wird in der Datei base beispielsweise neben dem Zugriff auf verschiedene Dateisysteme wie /dev, /proc und /sys auch der auf Laufzeitbibliotheken oder einige systemweite Konfigurationsdateien geregelt. Die Datei nameservice enthält, entgegen ihrer Benennung, nicht nur Regeln, welche die Namensauflösung betreffen, sondern auch solche, die überhaupt erst einen Zugriff auf das Netzwerk erlauben. Diese beiden abstractions finden sich also in den meisten Profilen, vor allem von Netzwerkdiensten.
Beginnend mit Zeile 9 räumen Regeln mit dem Schlüsselwort capability einem Programm besondere Privilegien, sogenannte capabilities ein. Dabei gehören setuid und setgid sicherlich zu den bekannteren: sie erlauben dem Programm, seine eigene uid und gid zu ändern; beispielsweise kann ein Webserver so als root starten, den privilegierten Port 80 öffnen und dann seine root-Rechte ablegen. dac_override und dac_read_search erlauben es, die Überprüfung von Lese-, Schreib- und Ausführungsrechten zu umgehen. Ohne diese capability dürfte selbst ein Programm, welches unter der uidroot läuft, anders als man es von der Shell gewöhnt ist, nicht ungeachtet der Dateiattribute die Dateien zugreifen.
Ab Zeile 14 befinden sich Regeln, welche über Zugriffsberechtigungen auf Pfade (also Ordner und Dateien) entscheiden. Der Aufbau ist denkbar einfach: zu Beginn wird der Pfad angegeben, gefolgt von einem Leerzeichen und den Kürzeln für die erteilten Berechtigungen.
Exkurs: Berechtigungen
Folgende Tabelle liefert einen kurzen Überblick über die gängigsten Berechtigungen:
Kürzel
Bedeutung
Beschreibung
r
read
lesender Zugriff
w
write
schreibender Zugriff
a
append
Anhängen von Daten
x
execute
Ausführen
m
memory map executable
Mappen und Ausführen des Inhalts der Datei im Speicher
k
lock
Setzen einer Sperre
l
link
Erstellen eines Links
Exkurs: Globbing
Pfade können sowohl einzeln voll ausgeschrieben oder mehrere Pfade durch Wildcards zu einem Pfad zusammengefasst werden. Dieses Globbing genannte Verfahren findet heutzutage auch bei den meisten Shells Anwendung, sodass diese Schreibweise keine Schwierigkeiten mit sich bringen sollte.
Ausdruck
Beschreibung
/dir/file
bezeichnet genau eine Datei
/dir/*
umfasst alle Dateien innerhalb von /dir/
/dir/**
umfasst alle Dateien innerhalb von /dir/ samt Unterverzeichnisse
?
steht für genau ein Zeichen
{}
Geschweifte Klammern ermöglichen Alternationen
[]
Eckige Klammern können für Zeichenklassen verwendet Werden
Beispiele:
Ausdruck
Beschreibung
/dir/???
bezeichnet also alle Dateien in /dir, deren Dateiname genau 3 Zeichen lang ist
/dir/*.{png,jpg}
bezeichnet alle Bilddateien in /dir, deren Dateiendung png oder jpg lautet
/dir/[abc]*
bezeichnet alle Dateien in /dir, deren Name mit den Buchstaben a, b oder c beginnt
Für Zugriffe auf die Programmdatei /usr/sbin/httpd erhält der Webserver in Zeile 14 die Berechtigungen mr. Das Kürzel r steht für read und bedeutet, dass der Inhalt der Datei gelesen werden darf, m steht für memory map executable und erlaubt es, den Inhalt der Datei in den Arbeitsspeicher zu laden und auszuführen.
Wer einen Blick in die Datei /etc/apparmor.d/abstractions/base wagt, wird sehen, dass die Berechtigung m unter anderem auch für das Laden von Bibliotheken nötig ist.
Während des Startvorgangs wird der Webserver versuchen seine Konfiguration aus der Datei /etc/httpd.conf auszulesen. Da der Pfad die Berechtigung r zum lesen besitzt, wird AppArmor dies erlauben. Anschließend schreibt httpd seine PID in die Datei /run/httpd.pid. Das Kürzel w steht natürlich für write und erlaubt Schreiboperationen auf dem Pfad. (Zeilen 16, 17)
Der Webserver soll Dateien unterhalb des WEBROOT-Verzeichnisses ausliefern. Um nicht alle Dateien und Unterverzeichnisse nicht einzeln aufführen zu müssen kann der Wildcard ** benutzt werden. Der Ausdruck @{WEBROOT}/** in Zeile 19 steht also für alle Dateien innerhalb und unterhalb des Ordners /var/www/html – inklusive Unterordnern und versteckten Dateien. Da es sich um eine statische Webseite handelt und der Webserver die Dateien nicht zu verändern braucht, wird mit r nur eine Leseberechtigung erteilt.
Wie üblich werden alle Zugriffe auf den Webserver in den Logdateien access.log und error.log im Verzeichnis /var/log/httpd/ protokolliert. Diese werden vom Webserver nur geschrieben, es reicht also in Zeile 21 mit w lediglich eine Schreibberechtigung auf den Pfad /var/log/httpd/* zu setzen.
Damit ist das Profil auch schon komplett und bereit für den Einsatz. Neben den hier gezeigten gibt es noch eine ganze Reihe weiterer Regeltypen, mit denen das erlaubte Verhalten eines Prozesses genau definiert werden kann.
Einige Anwendungen und Pakete bringen bereits fertige AppArmor-Profile mit, andere müssen noch an die Gegebenheiten angepasst werden. Wiederum andere Pakete bringen überhaupt keine Profile mit – diese müssen vom Admin selbst erstellt werden.
Um ein neues AppArmor-Profil für eine Anwendung zu erstellen wird üblicherweise zuerst ein nur sehr grundlegendes Profil angelegt und AppArmor angewiesen dieses im sogenannten complain mode zu behandeln. Hier werden Zugriffe, welche noch nicht im Profil definiert sind, in den Logdateien des Systems festzuhalten.
Anhand dieser Log-Einträge kann das Profil dann nach einiger Zeit nachgebessert und, wenn keine Einträge mehr in den Logs auftauchen, AppArmor angewiesen werden die in dem Profil in den enforce mode zu übernehmen und die darin aufgeführten Regeln durchzusetzen sowie nicht definierte Zugriffe zu sperren.
Auch wenn es problemlos möglich ist ein AppArmor-Profil von Hand in einem Texteditor zu erstellen und anzupassen, finden sich im Paket apparmor-utils verschiedene Hilfsprogramme, die einem die Arbeit erleichtern können: so hilft aa-genprof beim Anlegen eines neuen Profils, aa-complain schaltet dieses in den complain mode, aa-logprof hilft dabei Logdateien zu durchsuchen und dem Profil entsprechende neue Regeln hinzuzufügen, aa-enforce schaltet das Profil letztendlich in den enforce mode.
Im nächsten Artikel dieser Serie werden wir auf den hier geschaffenen Grundlagen ein eigenes Profil für den Webserver nginx erstellen.
Wir unterstützen Sie gerne
Ob AppArmor, Debian oder PostgreSQL: mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich kann die credativ GmbH Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Sie haben Fragen zu unserem Artikel oder würden sich wünschen, dass die Spezialisten von credativ sich eine andere Software ihrer Wahl angucken? Dann schauen Sie doch vorbei und melden sich über unser Kontaktformular oder schreiben uns eine E-Mail an info@credativ.de.
Über credativ
Die credativ GmbH ist ein herstellerunabhängiges Beratungs- und Dienstleistungsunternehmen mit Standort in Mönchengladbach. Seit dem erfolgreichen Merger mit Instaclustr 2021 ist die credativ GmbH das europäische Hauptquartier der Instaclustr Gruppe.
Die Instaclustr Gruppe hilft Unternehmen bei der Realisierung eigener Applikationen im großen Umfang dank Managed-Plattform-Solutions für Open Source Technologien wie zum Beispiel Apache Cassandra®, Apache Kafka®, Apache Spark™, Redis™, OpenSearch™, Apache ZooKeeper™, PostgreSQL® und Cadence. Instaclustr kombiniert eine komplette Dateninfrastruktur-Umgebung mit praktischer Expertise, Support und Consulting um eine kontinuierliche Leistung und Optimierung zu gewährleisten. Durch Beseitigung der Komplexität der Infrastruktur wird es Unternehmen ermöglicht, ihre internen Entwicklungs- und Betriebsressourcen auf die Entwicklung innovativer kundenorientierter Anwendungen zu geringeren Kosten zu konzentrieren. Zu den Kunden von Instaclustr gehören einige der größten und innovativsten Fortune-500-Unternehmen.
Eine moderne IT-Infrastruktur ist ein hochkomplexes Gebilde aus Rechen-, Speicher- und Netzwerkressourcen. Managed Platforms stellen eine lohnenswerte Alternative dar.
Unternehmen, die moderne Anwendungen nutzen wollen, haben einen großen Berg an Arbeit vor sich. Sie müssen nicht nur einen konkreten Fahrplan erstellen, welche Lösungen in Sachen Hard- und Software betrieben werden sollen, auch das dafür erforderliche Personal muss vorhanden sein. Zudem stellt sich die Frage nach den entstehenden Kosten für die IT-Infrastruktur. Um sie gering zu halten, setzen viele Unternehmen auf Open-Source-Software (OSS), doch trotz der enormen Vorteile in Sachen Flexibilität und Erweiterbarkeit hat selbst diese Sache einen Haken: Auch der Einsatz von OSS kann initial sehr auf-wendig sein und senkt nicht per se die Kosten.
Natürlich kostet Open-Source-Software in der Regel weder Anschaffungs- noch Lizenzgebühren. Allerdings beinhalten diese Technologien praktisch nie Modelle für Support, Deployment, Management und das kontinuierliche Monitoring der so zusammengestellten IT-Infrastruktur. Unternehmen brauchen also neues Personal, um diese Aufgaben zu stemmen, was wiederum mit hohen Kosten verbunden ist.
IT-Infrastruktur: IT-Dienstleister unterstützen beim Datenbank-Management
Um Kosten und Mitarbeiterressourcen einzusparen, setzen Firmen deswegen unter anderem vermehrt auf externe Unterstützung. IT-Dienstleister, in diesem Fall etwa IT-Consultants, übernehmen dabei spezielle Tätigkeiten für das Unternehmen, beispielsweise das Datenbank-Management und -Hosting. Der Nachteil solcher Dienstleister ist eine mögliche Abhängigkeit, da ihre speziell im Kontext des jeweiligen Unternehmens erworbene Expertise möglicherweise unverzichtbar wird.
Auch die Notwendigkeit, externen Beschäftigten Zugriff auf die internen Daten zu geben, ist für viele Unternehmen ein Problem. Das Einkaufen von reinen Support-Kapazitäten für spezielle Teile der IT-Infrastruktur, etwa die Datenbank, ist ebenfalls nicht zielführend: Bei ihnen fehlt logischerweise die Übersicht über die gesamte IT-Infrastruktur. Managed Platforms dagegen vereinen alle Vorteile aus den verschiedenen Modellen.
Managed Platforms: Das Beste aus beiden Welten
Der womöglich wichtigste Grund für die Beauftragung eines externen Dienstleisters ist natürlich ein geringerer personeller Aufwand für die Unternehmen selbst. Eine Managed Platform ist im Grunde eine Sammlung von Managed Services, die Unternehmen selbst über ein entsprechendes User Interface (UI) steuern können. Anders als bei „herkömmlichen“ Managed-Services-Providern bietet eine Managed Platform also nicht nur einen bestimmten Service, den der Anbieter vollständig verwaltet, sondern eine Vielzahl ineinandergreifender Technologien. So können Organisationen ihre Mitarbeiterinnen und Mitarbeiter noch stärker entlasten, da sie bei Bedarf gleich mehrere Services extern einkaufen. Die frei gesetzten Ressourcen können stattdessen für produktivere und innovativere Aufgaben genutzt werden.
Natürlich übernehmen auch Anbieter von Managed Platforms für ihre Nutzer bis zu einem gewissen Grad die Bereitstellung und das Management bestimmter Technologien. Sie erledigen diese Aufgaben allerdings minimalinvasiv, das heißt ohne Zugriff auf die internen Daten. Für viele potenzielle Nutzer von Managed Platforms ist dieser Aspekt sehr wichtig, denn gerade Finanzdienstleister oder Unternehmen im Gesundheitswesen unterliegen beispielsweise strengen Regularien, wenn es um den Schutz der Kundendaten geht.
Unternehmen behalten Kontrolle über den Data Layer
Neben der Hoheit über die internen Daten liegt bei Managed Platforms auch die Kontrolle über den Data Layer zu jeder Zeit beim Unternehmen und nicht beim Anbieter der Dienstleistung. Das User Interface der Managed Platform stellt dabei quasi die Verwaltungsebene dar, über die die Nutzer ihre IT-Infrastruktur verwalten können. Auf Wunsch können Unternehmen so je nach Bedarf neue Services oder weitere Kapazitäten zu ihrem bisherigen Portfolio hinzubuchen oder abbestellen. Dieses Verfahren ist deutlich günstiger und weniger aufwendig, als die entsprechende Hard- und Software dafür intern bereitzustellen beziehungsweise in Betrieb zu nehmen. Gerade die hohe Skalierbarkeit ist ein wichtiger Punkt, warum Organisationen auf Managed Platforms zurückgreifen.
IT-Infrastruktur: Automatisierung und Zuverlässigkeit im Fokus
Der hohe Automatisierungsgrad, der Managed Platforms auf allen Ebenen auszeichnet, ist nur durch den Einsatz standardisierter Prozesse und Technologien möglich. Gerade Open-Source-Software eignet sich sehr gut dafür. Je höher der Grad an Automatisierung, desto höher ist in der Regel auch die Zuverlässigkeit. Inhouse betriebene IT-Infrastrukturen sind nicht nur sehr kostenintensiv und mit einem hohen personellen Auf-wand verbunden, sie sind in den meisten Fällen auch deutlich unzuverlässiger als ausgelagerte Varianten.
Managed Platforms bieten Flexibilität auf allen Ebenen
Managed Platforms sind über die bisher erwähnten Vorteile hinaus extrem flexibel. Unternehmen können ihre IT-Infrastruktur etwa voll-ständig in der Cloud oder sogar in hybriden oder Multi-Cloud-Umgebungen betreiben. Wem das zu unsicher ist, hat natürlich auch die Möglichkeit, die Managed Platform On-premises zu nutzen. Eine hohe Flexibilität bietet dabei vor allem der Einsatz von Open-Source-Software. Durch die offenen Entwicklungsprozesse ist der Managed-Platform-Anbieter in der Lage, Updates für die IT-Infrastruktur einzuspielen und Bugs zu fixen, ohne dass diese Vorgänge die Nutzer und deren Geschäftsbetrieb negativ beeinflussen – etwa durch einen Service-Ausfall.
Zudem können IT-Lösungen, die auf Open-Source-Technologien basieren, in praktisch jedes bestehende System integriert werden. Und das ohne mühselige architektonische Änderungen vollziehen zu müssen. Managed Platforms, die auf Open-Source-Software setzen, sind für KMU, aber auch für große Firmen definitiv eine Überlegung wert. Denn die Kombination aus Einsparung von Anschaffungskosten für Software, den freigeschaufelten Mitarbeiterressourcen und aus Skalierbarkeit, Erweiterbarkeit und Zuverlässigkeit sind schlagkräftige Argumente für Managed Platforms.
In den vorausgegangenen Artikeln haben wir, um OpenVPN um eine Zwei-Faktor-Authentisierung zu erweitern, stets eine weitere Technologie wie TOTP oder Yubico OTP eingeführt. Diese neuen Technologien erhöhen die Komplexität eines Systems und erfordern von Admins, dass sich diese in die Thematik einarbeiten. Es kann daher durchaus wünschenswert sein auf bereits bestehende Dienste zurückzugreifen.
Moderne Unternehmensnetzwerke, egal ob kabelgebundenes Ethernet oder kabelloses WLAN, erfordern von ihren Clients, dass diese sich beim Verbindungsaufbau authentifizieren. In den meisten Unternehmen kommt hierfür ein RADIUS-Server wie FreeRADIUS zum Einsatz, bei dem Ethernet-Switches oder Wireless-Access-Points die übermittelten Zugangsdaten ihrer Clients überprüfen können, bevor diese ins Netz gelassen werden.
Ist ein solcher RADIUS-Server also ohnehin bereits vorhanden, bietet es sich an, diesen als zweiten Faktor für die Authentisierung von OpenVPN-Verbindungen zu verwenden.
Einrichtung
Das in diesem Artikel beschriebene Setup geht von einem OpenVPN-Server mit der IP-Adresse 192.0.2.10 aus, welcher seine Clients anhand von Zertifikaten authentisiert. Des Weiteren ist ein FreeRADIUS-Server mit der IP-Adresse 192.0.2.11 Teil des Setups. Prinzipiell könnten beide Dienste auch auf dem gleichen System betrieben werden, die Aufteilung auf mehrere Rechner ist aber wahrscheinlicher.
Anders als in den vorausgegangenen Artikeln wird der OpenVPN-Server diesmal nicht über PAM, sondern über ein eigenes Plugin direkt an den RADIUS-Server angebunden – ein weiterer Punkt, der die Komplexität dieses Setups verringert.
RADIUS
Damit der OpenVPN-Server überhaupt mit dem RADIUS-Server sprechen darf, muss zunächst auf dem RADIUS-Server ein weiterer Client in der Konfiguration angelegt werden. Dies geschieht, indem der Datei /etc/freeradius/3.0/clients.conf ein weiterer client–Abschnitt hinzugefügt wird:
Der neue client erhält den Identifier OpenVPN. Die Option ipaddr enthält die IP-Adresse, von der aus sich der OpenVPN-Server mit dem RADIUS-Server verbindet, secret das Passwort, mit dem dieser sich authentifiziert.
Mit einem Reload des RADIUS-Dienstes wird die neue Konfiguration übernommen und seine Einrichtung ist abgeschlossen.
systemctl reload freeradius
OpenVPN
Im Gegensatz zu den vorausgegangenen Artikeln übergibt OpenVPN bei diesem Setup die Credentials nicht dem lokalen PAM, welches diese dann vom entsprechenden Dienst überprüfen ließe, sondern übergibt diese über ein Plugin selbst an den RADIUS-Server.
Manche Linux-Distributionen installieren das Plugin zusammen mit OpenVPN, unter Debian GNU/Linux muss das Paket openvpn-auth-radius jedoch separat installiert werden:
apt install openvpn-auth-radius
Damit OpenVPN das Plugin verwendet, wird der Konfigurationsdatei die Zeile
hinzugefügt. Diese lädt das Plugin radiusplugin.so im Verzeichnis /usr/lib/openvpn mit der Konfigurationsdatei /etc/openvpn/radiusplugin.cnf.
Da die Konfigurationsdatei nicht existiert, muss diese noch angelegt werden:
NAS-Identifier=OpenVPN
NAS-IP-Address=192.0.2.10
OpenVPNConfig=/etc/openvpn/server.conf
server
{
name=192.0.2.11
authport=1812
acctport=1813
sharedsecret=shei5Rahs0ik
}
Die Optionen NAS-Identifier und NAS-IP-Address werden auf die beim Anlegen des Clients auf dem RADIUS-Server gewählten Werte gesetzt, hier also OpenVPN und 192.0.2.10. In der Sektion server wird unter name die IP-Adresse des RADIUS-Servers eingetragen, unter sharedsecret, das beim Anlegen des Clients gewählte secret, hier also shei5Rahs0ik. Unter OpenVPNConfig wird die Konfigurationsdatei des OpenVPN-Servers samt Pfad angegeben. Das Plugin durchsucht diese nach dort gesetzten Optionen und verhält sich diesen entsprechend.
Für ein einfaches Setup wie dieses reichen also schon wenige Konfigurationsoptionen aus. Eine voll kommentierte Beispielkonfiguration befindet sich im Verzeichnis /usr/share/doc/openvpn-auth-radius/examples/ in der Datei radiusplugin.cnf.
Mit einem Neustart des OpenVPN-Services ist auch dessen Konfiguration abgeschlossen.
systemctl restart openvpn
Client
Auch beim Einsatz von RADIUS auf der Serverseite ist der Konfigurationsaufwand auf der Seite des Clients minimal: hier muss der Konfiguration lediglich wieder die Direktive auth-user-pass hinzugefügt werden, sodass der Benutzer beim Verbindungsaufbau nach Benutzername und Passwort gefragt wird – den gleichen Credentials, die er auch für andere Netze des Unternehmens benötigt.
Fazit
Die Kürze dieses Artikels zeigt es bereits: um OpenVPN mit einer Zwei-Faktor-Authentisierung abzusichern bedarf es weder der Einführung neuer Technologien noch aufwändiger Konfiguration. Oft sind geeignete Dienste wie RADIUS bereits im Einsatz und müssen nur noch eingebunden werden.
Zwar handelt es sich bei den über RADIUS abgefragten Credentials in der Regel um Benutzernamen sowie statische Passwörter und nicht um zeitabhängig generierte Einmalpasswörter, ein Sicherheitsgewinn allein durch die Nutzung eines zweiten Faktors ist dennoch nicht von der Hand zu weisen.
Unterstützung
Falls Sie Unterstützung bei der Konfiguration oder dem Einsatz von Zwei-Faktor-Authentisierung wünschen, steht Ihnen unser Open Source Support Center gerne zur Verfügung – falls gewünscht auch 24 Stunden am Tag, an 365 Tagen im Jahr.
Das neue PostgreSQL® Enterprise Paket der credativ ist ab sofort verfügbar. In dem umfangreichen Servicepaket sind eine Vielzahl von Leistungen für den gesamten PostgreSQL®-Lifecycle gebündelt.
Ihre gesamte Enterprise-Umgebung – ein fester Preis
Das PostgreSQL® Enterprise Paket wird allen Anforderungen an den Betrieb von PostgreSQL® in einer Enterprise-Umgebung gerecht.
Bestehend aus einem Kontingent für Beratungs-, Service- und Supportleistungen sowie Unterstützungsleistungen vor Ort sind alle Aspekte des Datenbankbetriebs abgedeckt – das Besondere: Die Leistungen können für 24×7-Support, als auch für Services eingesetzt werden. Besonders Wartungen und Pflege, Schulungen und Trainings, aber auch Health-Checks und Tuning sind Bestandteil der angebotenen Serviceleistungen für Ihre PostgreSQL®-Datenumgebung.
Maximale Kostenkontrolle
Bei dem PostgreSQL® Enterprise Paket spielt es keine Rolle, wie viele Datenbanken innerhalb Ihres Unternehmens betrieben werden. Auch Faktoren wie die Anzahl der Cores, CPUs oder Usern auf der Datenbank verändern den Preis des Paketes nicht. Somit bietet Ihnen unser Paket eine hundertprozentige Kostenkontrolle bei einer gleichzeitig beliebigen Skalierung Ihrer gesamten Datenbankumgebung.
Im Gegensatz zu anderen PostgreSQL®-Service-Paketen legen wir besonderen Wert darauf, keine proprietären Elemente zu verwenden. Trotzdem bieten wir mit unserem PostgreSQL® Enterprise Paket die notwendige Absicherung des Betriebs Ihrer Datenbankumgebung in unternehmenskritischen Bereichen.
Weitere Informationen
Das PostgreSQL® Enterprise Paket ist ab 49.000 € zzgl. MwSt. pro Jahr erhältlich.
Weitere Informationen erhalten Sie auf unserer Website – Wir freuen uns auf Ihre Anfrage.
Dieser Artikel wurde ursprünglich von Philip Haas geschrieben.
Wer mit Kubernetes arbeitet, der kommt nicht umhin sich auch mit kubectl zu beschäftigen. Es ist das standard Command-Line-Interface zur Arbeit mit einem Kubernetes Cluster.
Dieser Blogpost soll dazu dienen, den initialen Start mit kubectl zu vereinfachen und den ein oder anderen Hinweis aufzuzeigen. Er orientiert sich dabei an Aufgaben und Problemstellungen, mit denen der reguläre Benutzer eines Clusters konfrontiert wird.
Kubeconfig
Zuerst wird eine sogenannte KUBECONFIG Konfigurationsdatei benötigt. Diese beinhaltet alle Parameter, die für eine oder mehrere Verbindung(en) zu Kubernetes benötigt werden.
Pfad
Standardmäßig prüft kubectl, ob sich unter ~/.kube/config eine Konfigurationsdatei findet. Um alternative Konfigurationsdateien zu nutzen, gibt es zwei Optionen diese zu definieren:
Command-Line-Argument --kubeconfig=<filepath> oder aber als
Environment Variable KUBECONFIG=<filepath>
Aufbau
Für eine Verbindung wird mindestens der Name des Clusters und der Benutzer innerhalb des Clusters benötigt. Diese Informationen werden in einem so genannten Context zusammengefasst. Optional kann an dieser Stelle der Namespace angegeben werden, der verwendet wird, sofern dieser beim Aufruf nicht angegeben wird.
Der gezeigte Context alleine reicht allerdings noch nicht aus, um Kontakt zu unserem Cluster aufzunehmen. Es fehlen Detailinformationen für cluster und user.
Neben den bereits gezeigten Abschnitten definieren wir den ausgewählten Context.
Auch wenn der Name des Contexts frei gewählt werden kann, empfehlen sich eindeutige Bezeichnungen: default/my-k8s-cluster/system:admin
Dieser beinhaltet alle wichtigen Details zur Verbindung und ist damit eindeutig identifizierbar.
Zusätzliche Einträge wie cluster, user und context können ebenfalls definiert werden.
Somit ist es möglich, verschiedene Konstellationen in der Konfiguration zu hinterlegen, zwischen denen gewechselt werden kann.
Contexts
Die konfigurierten contexts können wir uns mit dem folgenden Befehl anzeigen lassen.
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* default/my-k8s-cluster/system:admin my-k8s-cluster system-admin default
Der ausgewählte context wird durch einen * gekennzeichnet. Sofern mehrere contexts definiert wurden, können diese mit kubectl config use-context <context> gewechselt werden.
kubectl bietet neben der Anzeige und Auswahl der contexts auch die Möglichkeit die ausgewählte KUBECONFIG via Command-Line zu editieren.
Wie dies genau funktioniert, beschreibt die Hilfeausgabe:
$ kubectl config --help
Modify kubeconfig files using subcommands like "kubectl config set current-context my-context"
The loading order follows these rules:
1. If the --kubeconfig flag is set, then only that file is loaded. The flag may only be set once and no merging takes
place.
2. If $KUBECONFIG environment variable is set, then it is used as a list of paths (normal path delimiting rules for
your system). These paths are merged. When a value is modified, it is modified in the file that defines the stanza. When
a value is created, it is created in the first file that exists. If no files in the chain exist, then it creates the
last file in the list.
3. Otherwise, ${HOME}/.kube/config is used and no merging takes place.
Available Commands:
current-context Displays the current-context
delete-cluster Delete the specified cluster from the kubeconfig
delete-context Delete the specified context from the kubeconfig
get-clusters Display clusters defined in the kubeconfig
get-contexts Describe one or many contexts
rename-context Renames a context from the kubeconfig file.
set Sets an individual value in a kubeconfig file
set-cluster Sets a cluster entry in kubeconfig
set-context Sets a context entry in kubeconfig
set-credentials Sets a user entry in kubeconfig
unset Unsets an individual value in a kubeconfig file
use-context Sets the current-context in a kubeconfig file
view Display merged kubeconfig settings or a specified kubeconfig file
Usage:
kubectl config SUBCOMMAND [options]
Use "kubectl <command> --help" for more information about a given command.
Use "kubectl options" for a list of global command-line options (applies to all commands).
Anzeige
Das wohl meistgenutzte Feature von kubectl ist die Anzeige von Objekten innerhalb des Clusters und deren Status. Hierzu stehen gleich mehrere Methoden bereit, je nachdem welche Informationen wir uns anzeigen lassen wollen. Unter anderem:
get: Auflisten und Anzeigen von Objekten
describe: Beschreibung von Objekten und deren Status
logs: Anzeige der Logs eines Containers
explain: Anzeigen des Aufbaus von Ojekten
get
Mittels der get Methoden kann sich der User alle Objekte innerhalb des Clusters anzeigen lassen, auf die er Zugriff hat.
Hierzu muss mindestens ein Objekttyp angegeben werden, der angezeigt werden soll. Alternativ kann man sich mit all auch mehrere Objekttypen anzeigen lassen.
An dieser Stelle sollte angemerkt werden, dass all nicht all bedeutet. Es werden lediglich die gängigsten Objekte angezeigt.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 47s
nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 47s
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 100s
pod/nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 100s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deployment 2/2 2 2 100s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-deployment-6dd86d77d 2 2 2 100s
Die ausgabe des all Befehls kann in unserem konkreten Fall auch dadurch erreicht werden, dass mehrere Objekttypen gleichzeitig abgefragt werden.
Um alle Instanzen der Objekttypen pod, deployment und replicaset anzuzeigen, können wir auch folgenden Befehl verwenden:
$ kubectl get pods,deployments,replicasets
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 4m35s
pod/nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 4m35s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.extensions/nginx-deployment 2/2 2 2 4m35s
NAME DESIRED CURRENT READY AGE
replicaset.extensions/nginx-deployment-6dd86d77d 2 2 2 4m35s
Sobald die Antwort des Servers mehrere Objekttypen beinhaltet, werden die einzelnen Objektnamen mit ihrem Typ gepräfixt.
Soll nur der Status eines spezifischen Objekts ausgegeben werden, so geschieht dies durch Angabe des Objektnamens nach dem Objekttyp:
$ kubectl get pod nginx-deployment-6dd86d77d-5hldn
NAME READY STATUS RESTARTS AGE
nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 19m
Alternativ kann auch die Syntax <typ>/<name> verwendet werden.
Zum Beispiel: kubectl get pod/nginx-deployment-6dd86d77d-5hldn
Welche Informationen bei der Anzeige ausgegeben werden, hängt sowohl vom Ojekttyp selber, als auch vom Ausgabeformat ab. Neben dem Standardausgabeformat stehen unter anderem die folgenden Formate zur Verfügung:
wide: Darstellung zusätzlicher Informationen
yaml: Ausgabe des gesamten Objekts im YAML format
json: Ausgabe des gesamten Objekts im JSON format
jsonpath: Ausgabe definierter Bereiche
Eine vollständige Liste der Ausgabeformate kann der Ausgabe von kubectl get --help entnommen werden.
Schauen wir uns beispielsweise die Ausgabe der laufenden Pods mithilfe des Ausgabeformats wide an, dann werden neben den bereits bekannten Informationen zusätzliche Laufzeitinformationen angezeigt. Hierzu zählen unter anderem die IP-Adresse des Pods, sowie der Node auf dem der Pod ausgeführt wird.
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 112m 10.233.65.109 node-05.example.com <none> <none>
nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 112m 10.233.79.238 node-04.example.com <none> <none>
Die Formate yaml sowie json unterscheiden sich – abgesehen vom Format selbst – nicht in ihrem Inhalt. Beide liefern das ausgewählte Objekt und all seine Eigenschaften zurück.
Neben den manuell definierten Eigenschaften liefern die beiden Ausgabeformate zudem sehr detailierte Informationen über den Status des Objekts.
Das Ausgabeformat jsonpath ist immer dann hilfreich, wenn Abschnitte der Ausgabe weiterverarbeitet werden sollen. Ein Beispiel stellt das Dekodieren eines base64 kodierten secrets dar.
Values innerhalb von secrets werden base64 kodiert gespeichert, was bedeutet, dass wir die Kodierung zunächst durch den Aufruf von base64 -d rückgängig machen müssen. Dank jsonpath können wir das in einem Aufruf bewerkstelligen.
Angenommen, wir wollen den Wert des Keys password als Plaintext darstellen und unser secret ist wie folgt aufgebaut. Dies können wir dann mithilfe des Befehls kubectl get secret mysecret -o jsonpath='{.data.password}' | base64 -d bewerkstelligen.
Auch ist es möglich, sich ausschließlich Objekte mit einem bestimmten Label anzeigen zu lassen. Hierzu bietet kubectl für den get Befehl die entsprechende Filteroption. Wollen wir uns beispielsweise alle deployments, replicasets und pods mit dem Label app=nginx anzeigen, so können wir dies mit dem folgenden Befehl bewerkstelligen:
kubectl get deployments,replicasets,pods -l app=nginx
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.extensions/nginx-deployment 2/2 2 2 7d6h
NAME DESIRED CURRENT READY AGE
replicaset.extensions/nginx-deployment-6dd86d77d 2 2 2 7d6h
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 7d6h
pod/nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 7d6h
Welches Label ein Objekt besitzt, kann übrigens durch den zusätzlichen get-Parameter --show-labels angezeigt werden.
describe
Neben der einfachen Auflistung der Objekte ist es oftmals hilfreich, sich Objekte beschreiben zu lassen. Hierzu steht der Befehl describe zur Verfügung.
Die Ausgabe des describe-Befehls gibt eine relativ ausführliche Darstellung des Aufbaus und des Zustands des Objektes aus. Die describe-Ausgabe eines Pods gibt beispielsweise Aufschluss über:
Die priority-class des Pods
Container des Pods einschließlich:
Pod-ID
Image-Hash (sh256-Hash)
Status
QoS-Class
Node-Selectors
Tolerations
Events
Vor allem die Events eines Objekts sind oft ein wertvolles Mittel, um eventuellen Fehlern auf die Schliche zu kommen. Als Beispiel sei die Analyse der Fehlermeldung „ImagePullBackOff“ genannt. Oftmals bieten die Events einen Anhaltspunkt wo bei der Fehlanalyse anzusetzten ist.
$ kubectl describe pod nginx-deployment-6dd86d77d-9fm6w
Name: nginx-deployment-6dd86d77d-9fm6w
Namespace: test
Priority: 0
PriorityClassName: <none>
Node: node-05.example.com/10.66.0.5
Start Time: Mon, 02 Sep 2019 20:44:29 +0200
Labels: app=nginx
pod-template-hash=6dd86d77d
Annotations: <none>
Status: Running
IP: 10.233.65.100
Controlled By: ReplicaSet/nginx-deployment-6dd86d77d
Containers:
nginx:
Container ID: docker://7a3e3b51987da42a421d6f965824bfe2ba5d553a9f1d2e93758207c34cd4e31b
Image: nginx:1.7.9
Image ID: docker-pullable://nginx@sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Mon, 02 Sep 2019 20:44:31 +0200
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-q2h6q (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-q2h6q:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-q2h6q
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 19s default-scheduler Successfully assigned test/nginx-deployment-6dd86d77d-9fm6w to node-05.example.com
Normal Pulled 18s kubelet, node-05.example.com Container image "nginx:1.7.9" already present on machine
Normal Created 18s kubelet, node-05.example.com Created container nginx
Normal Started 17s kubelet, node-05.example.com Started container nginx
logs
Wird die Ausgabe eines Containers benötigt, so steht der Befehl logs zur Verfügung. Sollte sich ein Pod im Status „CrashLoopBackOff“ befinden, gibt die Anzeige der Logs des ensprechenden Containers meist Aufschluss über die Ursache des Problems.
Bei der Verwendung des logs-Befehls müssen wir explizit zwischen Pods und Containern unterscheiden. Da ein Pod mehrere Container beinhalten kann reicht es, dass einer der Container nicht richtig funktioniert, um den Pod in einen fehlerhaften Zustand zu bringen.
Sollen die Logs eines Pods mit ausschließlich einem Container angezeigt werden, so gestaltet sich die Ausgabe der Logs recht einfach:
$ kubectl logs nginx-deployment-6dd86d77d-9fm6w
Beinhaltet der zu analysierende Pod mehrere Container wird Kubernetes auf die gleiche Anfrage mit einem Fehler antworten.
Dabei ist Kubernetes allerdings so freundlich und liefert die entsprechende Lösung gleich mit.
Beinhaltet ein Pod mehrere Container, so muss neben dem Pod-Namen ebenfalls der Container-Name angegeben werden:
Oftmals muss die Ausgabe des logs-Befehls allerdings nicht für die akute Fehlerbehebung herangezogen werden, sondern wird bei der Fehleranalyse vergangener Ereignisse benötigt.
Hierzu steht das zusätzliche Flag --previous zur Verfügung. Dabei werden nicht die aktuellen Logs des Containers angezeigt, sondern die der vorangegangenen Instanz des Containers / Pods.
Explain
Wer (wie ich) nicht immer den exakten Namen eines Parameters oder dessen Platzierung innerhalb der Objektstruktur im Kopf hat, kann sich mit Hilfe des explain-Befehls selbst helfen und sich den korrekten Aufbau eines Kubernetes-Objekts in der genutzten API-Version anzeigen zu lassen.
Er gibt neben dem Aufbau von Objekten auch eine kurze Beschreibung zu allen Parametern aus.
Wollen wir uns beispielsweise den Aufbau der Pod-Spezifiation anschauen, so könnnen wir dies mithilfe des folgenden Befehls bewerkstelligen:
$ kubectl explain pod
KIND: Pod
VERSION: v1
DESCRIPTION:
Pod is a collection of containers that can run on a host. This resource is
created by clients and scheduled onto hosts.
FIELDS:
apiVersion <string>
APIVersion defines the versioned schema of this representation of an
object. Servers should convert recognized schemas to the latest internal
value, and may reject unrecognized values. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#resources
kind <string>
Kind is a string value representing the REST resource this object
represents. Servers may infer this from the endpoint the client submits
requests to. Cannot be updated. In CamelCase. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#types-kinds
metadata <Object>
Standard object's metadata. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#metadata
spec <Object>
Specification of the desired behavior of the pod. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status
status <Object>
Most recently observed status of the pod. This data may not be up to date.
Populated by the system. Read-only. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status
Wer eine rekursive Auflistung aller möglichen Parameter erhalten möchte erlangt diese mithilfe des folgenden Befehls:
kubectl explain --recursive pod.spec
KIND: Pod
VERSION: v1
RESOURCE: spec <Object>
DESCRIPTION:
Specification of the desired behavior of the pod. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status
PodSpec is a description of a pod.
FIELDS:
activeDeadlineSeconds <integer>
.. Output Skipped ...
automountServiceAccountToken <boolean>
containers <[]Object>
args <[]string>
command <[]string>
env <[]Object>
name <string>
value <string>
valueFrom <Object>
configMapKeyRef <Object>
key <string>
name <string>
optional <boolean>
fieldRef <Object>
apiVersion <string>
fieldPath <string>
resourceFieldRef <Object>
containerName <string>
divisor <string>
resource <string>
secretKeyRef <Object>
key <string>
name <string>
optional <boolean>
.. Output Skipped ..
name <string>
ports <[]Object>
.. Output Skipped ...
volumes <[]Object>
awsElasticBlockStore <Object>
fsType <string>
partition <integer>
readOnly <boolean>
volumeID <string>
.. output Skipped ..
vsphereVolume <Object>
fsType <string>
storagePolicyID <string>
storagePolicyName <string>
volumePath <string>
Die Ausgabe des explain-Befehls kann so eine Recherche innerhalb der Kubernetes-Dokumentation überflüssig machen. Das spart nicht nur Zeit, sondern oftmals auch Nerven.
Code-Completion
Wer regelmäßig mit der Konsole arbeitet, lernt das autocompletion-Feature zu lieben.
Oftmals ist die Syntax eines Befehles nicht 100 prozentig klar, oder es müssen Argumente vervollständigt werden, deren Namen man sich einfach nicht merken kann oder will. Viele Command-Line-Tools bringen deshalb so genannte completion-files mit und kubectl ist hier keine Ausnahme.
Wer die autocompletion-Funktionalität von kubectl verwenden will, muss dazu den Befehl kubectl completion ... bemühen. Der completion-Befehl gibt die entsprechenden completion-scripts sowohl für bash als auch für zsh aus. Wer die Autovervollständigung ad-hoc nutzten möchte, der kann sich mithilfe der folgenden Befehle behelfen:
bash: source <(kubectl completion bash)
zsh: source <(kubectl completion zsh)
Wer auch nach Beenden des Terminals in den Genuss der Auto-Completion kommen möchte, speichert sich die Ausgabe der Befehle kubectl completion bash/zsh innerhalb einer Datei ab und lädt diese wie gewohnt innerhalb seiner .bashrc oder .zshrc.
Anlegen / Ändern / Löschen
Zum Anlegen, Ändern oder Löschen von Objekten stehen via kubectl unterschiedliche Methoden zur Verfügung. Alle haben gemeinsam, dass sie das zu kontrollierende Objekt anhand ihres Namens und Namespaces (bei namespacesbehafteten Objekten) identifizieren.
Um ein neues Objekt im Cluster anzulegen, können sowohl die Befehle create als auch apply verwendet werden. Dabei setzt create voraus, dass das Zielobjekt noch nicht existiert. Das folgende Beispiel zeigt die Erzeugung eines Deplyoments, welcher den Webserver Nginx als einzigen Pod beinhaltet:
create
$ kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
Versuchen wir nun das gleiche Deployment erneut anzulegen, erhalten wir eine Fehlermeldung, weil ein Deployment mit den namen nginx bereits exisiert.
kubectl create deployment nginx --image=nginx
Error from server (AlreadyExists): deployments.apps "nginx" already exists
Der create Befehl stellt somit eine konkrete Aktion dar und beschreibt nicht – wie andere Befehle – den Zielzustand.
Des Weiteren wurde die Definition des Objekts nicht lokal gespeichert, sondern lediglich dem Cluster mitgeteilt. Um das Objekt, in unserem Fall das Nginx Deployment, auch in anderen Cluster bereitzustellen, muss nun der gleiche Befehl gegen den neuen Cluster ausgeführt werden.
Oftmals ist es eine bessere Idee, Objekte nicht ad-hoc zu erstellen, sondern den Zwischenweg über eine YAML Datei zu gehen, welche die Definition des Selbigen beinhaltet.
kubectl create kann hierbei Hilfestellung leisten.
Der Parameter --output yaml erstellt nicht nur das Objekt, er generiert auch die Definition des Objekts im YAML Format und gibt diese auf der Konsole aus.
Soll die generierte Definition vor dem Einspielen in den Cluster bearbeitet werden, so kann zwischenzeitlich der Parameter --dry-run genutzt werden.
Die Ausgabe des oben stehenden Befehls kann nun als Datei abgelegt und beispielsweise durch Git unter Versionskontrolle gestellt werden.
Wer die resultierende Definition via create gegen den Cluster anwenden will, der kann dies mit dem Befehl kubectl create -f nginx-deployment.yaml bewerkstelligen.
Eine Hilfestellung bietet create oft dann, wenn die Alternative zu fehleranfällig wäre. Als Beispiel sei hier die Erstellung eines secrets genannt, dass sowohl ein Serverzertifikat als auch den dazugehörigen Schlüssel beinhalten soll. Secrets enthalten base64 encodete Werte, weshalb eine manuelle Erstellung mehrere Schritte beinhalten würde.
Mit dem Befehl kubectl create secret tls certificate-pair --cert=certificate.pem --key=key.pem -o yaml --dry-run hingegen ist das gewünschte Secret in einem Befehl erstellt.
Da nicht alle Objekttypen oder Parameter als Argumente an create übergeben werden können, muss teilweise der Weg über eine Manifestdatei gegangen werden.
apply
Neben create können neue Objekte auch mithilfe des apply-Befehls erstellt werden. Hierbei unterscheidet sich apply jedoch leicht im Handling.
apply spielt seine Stärken im Umgang mit YAML-Manifesten aus. Nehmen wir die in create dargestellte Deployment-Definition und nehmen an, dass diese als nginx-deployment.yaml vorliegt. Dann können wir diese mit Hilfe des folgenden Befehls im Cluster einspielen:
kubectl apply -f nginx-deployment.yaml
deployment.apps/nginx created
Im Gegensatz zu create verhält sich apply bei erneuter Ausführung des Befehls unterschiedlich.
Denn durch apply wird keine Aktion sondern ein Zielzustand definiert, welche vom Cluster berücksichtigt wird. In unserem Beispiel also die Existenz eines Deployment-Objekts namens nginx unter Verwendung des Image nginx und einem Replika.
Wollen wir die Anzahl der Replikas nun Beispielsweise auf 2 anheben, so genügt es, die Datei entsprechend zu aktualisieren und erneut den apply-Befehl auszuführen.
Das definierte Ziel, unser Objekt, wird dabei immer anhand der apiVersion, Kind, name und namespace identifiziert.
Viele Eigenschafen eines Objekts können auf diese Weise geändert werden. Es gibt jedoch s.g. immutable Eigenschaften oder Felder, die nach der Erstellung des Objekts nicht mehr angepasst werden können. apply liefert dann eine entsprechende Fehlermeldung.
Weil keine Aktion, sondern ein Zielzustand definiert wird, eignet sich apply für mehrere Anwendungsfälle. Ferner ist es dazu geeignet, in Scripts oder Pipelines verwendet zu werden.
patch
Um Eigenschaften eines Objekts anzupassen, steht zusätzlich der Befehl patch zur Verfügung. Dieser enthält die Information, welches Objekt geändert werden soll und wie. Wollen wir z.B. die Anzahl der Replikas auf drei erhöhen, können wir dies mit dem folgenden patch-Befehl bewerkstelligen:
patch bietet sich vor allem dann an, wenn Objekte den eigenen Vorstellungen nach geändert werden sollen, aber automatisiert erstellt werden. Zum Beispiel node Objekte.
Spezifische Befehle
Neben den generischen Methoden wie apply oder patch stellt kubectl eine Reihe von spezifischen Befehlen bereit. Anhand dieser Befehle können beispielsweise Deployments oder StatefulSets skaliert werden, auf einen früheren Stand eines Deployments zurückgewechselt werden, oder aber der Status eines sogenannten rollouts überprüft werden.
Nachfolgend werden ein paar der gängigen Befehle und deren Verwendung grob skizziert:
label, annotate: Hinzufügen, ändern oder löschen von labels und annotations.
Beispiel: kubectl label deployment nginx comment=awebserver
scale: Anpassen der Anzahl der replica-Eigenschaft.
rollout (history, pause, restart, undo): Steuerung von rollouts. Z.B. Rollback auf eine frühere Version eines Deployments.
expose: Erstellung ein Service zu einem gegebenen Objekt.
delete
Früher oder später kommt der Moment, in dem die angelegten Objekte auch wieder gelöscht werden sollen.
Hier kommt der Befehl delete zum Einsatz.
Wie auch bei create kann delete das Zielobjekt auf unterschiedliche Weise identifizieren. Entweder durch Angabe der Typs und des Namens oder aber indirekt über den Parameter -f und eine entsprechende Objektdefinition. Wollen wir unser Nginx Deployment löschen geschieht dies z.B. mit Hilfe des Befehls:
Alternativ hätten wir das Deployment auch via kubectl delete deployment nginx löschen können.
Exec
Auch wenn keine manuellen Änderungen an Dateien oder Prozessen innerhalb eines Containers vorgenommen weden sollen, kann es manchmal durchaus hilfreich sein, in einen Container hineinzusehen. Besonders bei der Entwicklung bietet der Blick in einen Container oftmals schnelleren Einblick in die Situation als andere Lösungen.
Nehmen wir an, wir wollen unseren Nginx-Web-Service debuggen und prüfen, ob dieser auf bestimmte Requests reagiert, so kann der exec Befehl helfen.
kubectl exec führt den angegebenen Befehl innerhalb des Containers aus. Auch eine interaktive Shell innerhalb des Containers kann mit exec gestartet werden, sofern vorhanden.
Wollen wir beispielsweise sicherstellen, dass der Inhalt einer Datei innerhalb des Containers mit unseren Erwartungen übereinstimmt, dann können wir uns diese Datei mittels cat anzeigen lassen:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-65f88748fd-lt2z5 1/1 Running 0 4m35s
nginx-65f88748fd-mmwl5 1/1 Running 0 4m35s
$ kubectl exec nginx-65f88748fd-lt2z5 cat /etc/nginx/nginx.conf
user nginx;
worker_processes 1;
...
http {
include /etc/nginx/mime.types;
...
include /etc/nginx/conf.d/*.conf;
}
Möchten wir eine interaktive Shell im Container starten, dann müssen wir neben dem Befehl selbst weitere Parameter angeben. Dabei handelt es sich um --stdin und --tty. Andernfalls wird die Shell zwar gestartet, sie beendet sich allerdings direkt wieder falls wir keine Argumente übergeben haben.
Dies ist bereits aus der Verwendung von docker exec bekannt. Das dort verwendete Kürzel -it kann auch bei kubectl exec verwendet werden. Ein vollständiges Beispiel sieht dann wie folgt aus:
Der auszuführende Befehl muss natürlich innerhalb des Containers vorhanden sein. Da die benutzten Images meist auf minimale Größe ausgelegt sind, ist die Auswahl der Tools innerhalb des Containers oft stark begrenzt. Aus Security-Sicht ist dies eine gute Sache.
Sofern der Zielpod mehrere Container beherbergt, oder gar Init-Container verwendet, kann mittels -c der ensprechende Containername angegeben werden.
Port Weiterleitung
Manchmal müssen Services analysiert werden, die nicht direkt der Außenwelt präsentiert werden, oder aber vorgelagerte Proxies und Loadbalancer bei einer Fehleranalyse ausgeschlossen werden sollen.
Hierzu ist es notwenig, dass direkt auf den entsprechenden Service zugegriffen werden kann. Auch wenn dies normalerweise nicht der Fall ist.
Um direkten Zugriff zu ermöglichen stellt kubectl den Befehl port-forward bereit. Dieser dient dazu, einen lokalen Port auf den Port eines Objekts innerhalb des Cluster weiterzuleiten. Als Ziel können unter Anderem Services, Pods auch auch ganze Deployments dienen.
Dabei wird das Ziel in der Form <typ-short>/ angegebenen. Als weiterer Parameter muss eine Kombination aus lokalem Port und Remoteport angegeben werden.
Wollen wir nun direkt auf einen unserer Nginx Pods zugreifen sieht die entsprechende Syntax wie folgt aus:
$ kubectl port-forward pod/nginx-65f88748fd-lt2z5 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
Dabei gibt 8080 den lokal zu öffnenden Port, 80 den den Zielport. Ein Aufruf von http://localhost:8080 zeigt ob der Port-Forward funktioniert hat und wie erwartet unser Nginx antwortet:
$ curl http://localhost:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
...
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
kubectl port-forward bestätigt dabei den Request mit dem Output Handling connection for 8080. Sollte es kubectl aus irgendeinem Grund nicht möglich sein den Request weiterzuleiten, so wird eine entsprechende Fehlermledung ausgegeben.
Alternativ kann der lokale Port auch weggelassen werden, dann versucht kubectl lokal den gleichen Port zu öffnen, auf den weitergeleitet werden soll. Je nach Port-Range benötigt man dazu allerdings lokale Root-Berechtigungen. Wer einen zufälligen, lokalen Port öffnen möchte kann dies anhand der Syntax :<target-port> bewerkstelligen.
Wollen wir die Weiterleitung auf eine dedizierte IP-Adresse binden, dann kann dies mit Hilfe des Parameters --address geschehen. Diese nimmt im Zweifelsfall auch mehrere IP-Adressen als Argument auf.
Weiteres
diff
Anhand des diff Befehls ist es möglich, die Abweichungen des IST mit dem SOLL Zustand anzuzeigen.
Hierzu nimmt der diff Befehl den Parameter -f auf. Das folgende Beispiel zeigt die diff Ausgabe nach Aktualisieren unseres Nginx Deployment YAML und vor dem apply:
Wer Daten in oder aus einem laufenden Container kopieren möchte, dem steht mit kubectl cp ein Befehl zur Hand, der genau diese Aufgabe erfüllt. Voraussetzung ist allerdings ein installiertes tar innerhalb des Containers.
Wollen wir Beispielsweise die nginx.conf aus unserem Nginx Container kopieren, dann würde der entsprechende Befehl wie folgt aussehen:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-65f88748fd-lt2z5 1/1 Running 0 3d20h
nginx-65f88748fd-mmwl5 1/1 Running 0 3d20h
$ kubectl cp nginx-65f88748fd-lt2z5:/etc/nginx/nginx.conf nginx-65f88748fd-lt2z5_nginx.conf
tar: Removing leading `/' from member names
Falls innerhalb des Zielpods mehrere Container betrieben werden, so muss mithilfe des Parameter -c <container-name> der Zielcontainer angegeben werden.
wait
Manchmal könnte bestimmte Aktionen erst durchgeführt werden, nachdem andere erfolgreich abgeschlossen wurden. Oder man möchte einfach nur informiert werden sobald eine spezifische Aktion abgeschlossen wurde. Dies kann mit Hilfe des Befehls wait vollbracht werden.
wait nimmt ein Set an Argumenten auf, die sowohl das Zielobjekt als auch den Zielzustand beschreiben.
Wollen wir beispielsweise darauf warten, dass sich einer unserer Pods im Zustand Ready befindet, so sieht der Befehl wie folgt aus:
$ kubectl wait --for=condition=Ready pod/nginx-65f88748fd-lt2z5
pod/nginx-65f88748fd-lt2z5 condition met
Soll auf das endgültige Löschen eines Pods gewartet werden, so kann als Argument --for der Wert delete angegeben werden.
Dies ist insofern nützlich, als dass bei einem delete nicht der Löschvorgang selber durchgeführt wird, sondern das enstprechende Objekt nur als zu löschen makiert wird.
kubectl wait --for=delete pod/nginx-65f88748fd-49qv2 --timeout=120s
pod/nginx-65f88748fd-49qv2 condition met
Unterstützung
Falls Sie Unterstützung beim Einsatz von Kubernetes benötigen, steht Ihnen unser Open Source Support Center zur Verfügung – Falls gewünscht auch 24 Stunden am Tag, an 365 Tagen im Jahr.
Bei credativ halten wir regelmäßig Vorträge*, bei denen wir interessante Themen oder Neuigkeiten aus der Open Source Welt vorstellen. Vor kurzem gab uns Julian einen Einblick in VisualStudio Code.
Der 2016 von Microsoft veröffentlichte Editor VisualStudio Code erfreut sich wachsender Beliebtheit. Grund genug, um sich die Software genauer anzusehen.
Grundsätzlich ist VisualStudio Code eher ein Text-Editor, als eine IDE (Integrated development environment). Durch die Integration von Containern und Remote-(SSH)-Hosts kann ein Verhalten ähnlich des „Tramp-Mode“ vom Emacs-Editor erzielt werden.
Dadurch eignet sich VisualStudio Code auch für Use-Cases der modernen Linux-Administration.
Wichtigen Gesprächsstoff liefert zudem die Lizenz der Software. Der Sourcecode selbst steht unter der zu den ‚permissive-licenses‚ zählenden MIT-Lizenz, die gängigen Binaries hingegen nicht. Für diese Binaries hat Microsoft eine eigene Lizenz geschaffen. Es ist wichtig darauf hinzuweisen, dass es Passagen gibt, die eine Datensammlung erzwingen und ein Verbot des Reverse-Engineerings aussprechen. Dadurch eröffnet sich natürlich die Frage nach freien Alternativen.
Hier ist vor allem der VSCodium-Editor zu nennen, den wir in den nächsten Monaten ausgiebig testen werden. Ein Drop-in Replacement von VisualStudio Code auf vollständiger Basis der MIT-Lizenz klingt auf jeden Fall vielversprechend.
*Unsere freitäglichen Vorträge, genannt Bill-Talks (siehe Ted-Talks), entstanden aus der Idee, dass wir im Rahmen unserer alltäglichen Arbeit immer wieder neue Open-Source-Projekte kennenlernen. Da nicht jeder Kollege in jedem Team vertreten ist, dienen diese Vorträge dem Wissenstransfer, um das Gelernte mit den Kollegen zu teilen.
Dieser Artikel wurde ursprünglich geschrieben von Julian Schauder.
Die PostgreSQL® Global Development Group (PGDG) hat Version 12 der populären, freien Datenbank PostgreSQL®freigegeben. Wie unser Artikel für Beta 4 bereits angedeutet hat, sind eine Vielzahl von neuen Features, Verbesserungen und Optimierungen in das Release eingeflossen. Dazu gehören unter anderem:
Optimierte Speicherplatznutzung und Geschwindigkeit bei btree-Indexen
btree-Indexe, der Standardindextyp in PostgreSQL®, hat einige Optimierungen in PostgreSQL® 12 erfahren.
btree Indexe speicherten in der Vergangenheit Doubletten (also mehrfache Einträge mit denselben Schlüsselwerten) in einer unsortierten Reihenfolge. Dies hatte eine suboptimale Nutzung der physischen Repräsentation in betreffenden Indexen zu Folge. Eine Optimierung speichert diese mehrfachen Schlüsselwerte nun in derselben Reihenfolge, wie diese auch physisch in der Tabelle gespeichert sind. Dies verbessert die Speicherplatzausnutzung und die Aufwände für das Verwalten entsprechender Indexe vom Typ btree. Darüber hinaus verwenden Indexe mit mehreren indizierten Spalten eine verbesserte physische Repräsentation, sodass deren Speicherplatznutzung ebenfalls verbessert wird. Um hiervon in PostgreSQL® 12 zu profitieren, müssen diese jedoch, falls per binärem Upgrade mittels pg_upgrade auf die neue Version gewechselt wurde, diese Indexe neu angelegt bzw. reindiziert werden.
Einfügeoperationen in btree-Indexe werden zudem durch verbessertes Locking beschleunigt.
Verbesserungen für pg_checksums
credativ hat eine Erweiterung für pg_checksums beigesteuert, die es ermöglicht Blockprüfsummen in gestoppten PostgreSQL®-Instanzen zu aktivieren oder zu deaktivieren. Vorher konnte dies nur durch ein Neuanlegen der physischen Datenrepräsentation des Clusters per initdb durchgeführt werden. pg_checksumsverfügt nun auch mit dem Parameter --progress über die Möglichkeit, einen Statusverlauf auf der Konsole anzuzeigen. Die entsprechenden Codebeiträge stammen von den Kollegen Michael Banck und Bernd Helmle.
Optimizer Inlining von Common Table Expressions
Bis einschließlich PostgreSQL® 11 war es dem PostgreSQL® Optimizer nicht möglich, Common Table Expressions (auch CTE oder WITH Abfragen genannt) zu optimieren. Wurde ein solcher Ausdruck in einer Abfrage verwendet, so wurde die CTE immer als erstes evaluiert und materialisiert, bevor der Rest der Abfrage abgearbeitet wurde. Dies führte bei komplexeren CTE Ausdrücken zu entsprechend teuren Ausführungsplänen. Folgendes generisches Beispiel illustriert dies anschaulich. Gegeben sei ein Join mit einem CTE Ausdruck, der alle gerade Zahlen aus einer numerischen Spalten filtert:
WITH t_cte AS (SELECT id FROM foo WHERE id % 2 = 0) SELECT COUNT(*) FROM t_cte JOIN bar USING(id);
In PostgreSQL® 11 führt die Verwendung einer CTE immer zu einem CTE Scan, der den CTE Ausdruck als erstes materialisiert:
EXPLAIN (ANALYZE, BUFFERS) WITH t_cte AS (SELECT id FROM foo WHERE id % 2 = 0) SELECT COUNT(*) FROM t_cte JOIN bar USING(id) ;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Aggregate (cost=2231.12..2231.14 rows=1 width=8) (actual time=48.684..48.684 rows=1 loops=1)
Buffers: shared hit=488
CTE t_cte
-> Seq Scan on foo (cost=0.00..1943.00 rows=500 width=4) (actual time=0.055..17.146 rows=50000 loops=1)
Filter: ((id % 2) = 0)
Rows Removed by Filter: 50000
Buffers: shared hit=443
-> Hash Join (cost=270.00..286.88 rows=500 width=0) (actual time=7.297..47.966 rows=5000 loops=1)
Hash Cond: (t_cte.id = bar.id)
Buffers: shared hit=488
-> CTE Scan on t_cte (cost=0.00..10.00 rows=500 width=4) (actual time=0.063..31.158 rows=50000 loops=1)
Buffers: shared hit=443
-> Hash (cost=145.00..145.00 rows=10000 width=4) (actual time=7.191..7.192 rows=10000 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 480kB
Buffers: shared hit=45
-> Seq Scan on bar (cost=0.00..145.00 rows=10000 width=4) (actual time=0.029..3.031 rows=10000 loops=1)
Buffers: shared hit=45
Planning Time: 0.832 ms
Execution Time: 50.562 ms
(19 rows)
Dieser Plan materialisiert zunächst die CTE mit einem Sequential Scan mit entsprechendem Filter (id % 2 = 0). Hier wird kein funktionaler Index verwendet, daher ist dieser Scan entsprechend teurer. Danach wird das Ergebnis der CTE per Hash Join mit der entsprechenden Join Bedingung mit der Tabelle bar verknüpft. Mit PostgreSQL® 12 erhält der Optimizer nun die Fähigkeit, diese CTE Ausdrücke ohne vorherige Materialisierung zu inlinen. Der zugrundeliegende, optimierte Plan in PostgreSQL® 12 sieht dann wie folgt aus:
EXPLAIN (ANALYZE, BUFFERS) WITH t_cte AS (SELECT id FROM foo WHERE id % 2 = 0) SELECT COUNT(*) FROM t_cte JOIN bar USING(id) ;
QUERY PLAN
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Aggregate (cost=706.43..706.44 rows=1 width=8) (actual time=9.203..9.203 rows=1 loops=1)
Buffers: shared hit=148
-> Merge Join (cost=0.71..706.30 rows=50 width=0) (actual time=0.099..8.771 rows=5000 loops=1)
Merge Cond: (foo.id = bar.id)
Buffers: shared hit=148
-> Index Only Scan using foo_id_idx on foo (cost=0.29..3550.29 rows=500 width=4) (actual time=0.053..3.490 rows=5001 loops=1)
Filter: ((id % 2) = 0)
Rows Removed by Filter: 5001
Heap Fetches: 10002
Buffers: shared hit=74
-> Index Only Scan using bar_id_idx on bar (cost=0.29..318.29 rows=10000 width=4) (actual time=0.038..3.186 rows=10000 loops=1)
Heap Fetches: 10000
Buffers: shared hit=74
Planning Time: 0.646 ms
Execution Time: 9.268 ms
(15 rows)
Der Vorteil dieser Methode ist, dass das initiale materialisieren des CTE Ausdrucks entfällt. Stattdessen wird die Abfrage direkt mit einem Join ausgeführt.
Dies funktioniert bei allen nicht-rekursiven CTE Ausdrücken ohne Seiteneffekte (beispielsweise CTEs mit Schreibanweisungen) und solchen, die jeweils nur einmal pro Abfrage referenziert sind. Das alte Verhalten des Optimizers kann mit der Anweisung WITH ... AS MATERIALIZED ... forciert werden.
Generated Columns
Neu in PostgreSQL® 12 sind sogenannte Generated Columns, die auf Ausdrücken basierend ein Ergebnis anhand vorhandener Spaltenwerte berechnen. Diese werden mit den entsprechenden Quellwerten im Tupel gespeichert. Der Vorteil ist, dass das Anlegen von Triggern zur nachträglichen Berechnung von Spaltenwerten entfallen kann. Folgendes einfaches Beispiel anhand einer Preistabelle mit Netto und Bruttopreisen illustriert die neue Funktionalität:
CREATE TABLE preise(netto numeric,
brutto numeric GENERATED ALWAYS AS (netto * 1.19) STORED);
INSERT INTO preise VALUES(17.30);
INSERT INTO preise VALUES(225);
INSERT INTO preise VALUES(247);
INSERT INTO preise VALUES(19.15);
SELECT * FROM preise;
netto │ brutto
───────┼─────────
17.30 │ 20.5870
225 │ 267.75
247 │ 293.93
19.15 │ 22.7885
(4 rows)
Die Spalte brutto wird direkt aus dem Nettopreis berechnet. Das Schlüsselwort STORED ist Pflicht. Selbstverständlich können auf Generated Columns auch Indexe erzeugt werden, allerdings können sie nicht Teil eines Primärschlüssels sein. Ferner muss der SQL Ausdruck eindeutig sein, d.h. auch bei gleicher Eingabemenge das dasselbe Ergebnis liefern. Spalten die als Generated Columns deklariert sind, können nicht explizit in INSERT– oder UPDATE-Operationen verwendet werden. Falls eine Spaltenliste unbedingt notwendig ist, kann mit dem Schlüsselwort DEFAULT der entsprechende Wert indirekt referenziert werden.
Wegfall von expliziten OID Spalten
Explizite OID Spalten waren historisch gesehen ein Weg, eindeutige Spaltenwerte zu erzeugen, so dass eine Tabellenzeile Datenbankweit eindeutig identifiziert werden kann. Seit langer Zeit werden diese in PostgreSQL® jedoch nur noch explizit angelegt und deren grundlegende Funktionalität als überholt angesehen. Mit PostgreSQL® wird nun auch die Möglichkeit explizit solche Spalten anzulegen, endgültig abgeschafft. Damit wird es nicht mehr möglich sein, die Direktive WITH OIDS bei Tabellen anzugeben. Systemtabellen, die schon immer per OID Objekte eindeutig referenzieren, geben OID Werte ab sofort ohne explizite Angabe von OID Spalten in der Ergebnismenge zurück. Besonders ältere Software, die sorglos mit Katalogabfragen hantierte, könnte Probleme durch eine doppelte Spaltenausgabe bekommen.
Verschieben der recovery.conf in die postgresql.conf
Bis einschließlich PostgreSQL® 11 konfigurierte man Datenbankrecovery und Streaming Replication Instanzen über eine separate Konfigurationsdatei recovery.conf.
Mit PostgreSQL® 12 wandern nun sämtliche dort getätigte Konfigurationsarbeiten in die postgresql.conf. Die Datei recovery.conf entfällt ab sofort. PostgreSQL® 12 weigert sich zu starten, sobald diese Datei vorhanden ist. Ob Recovery oder ein Streaming Standby gewünscht ist, entscheidet nun entweder eine Datei recovery.signal (für Recovery) oder standby.signal (für Standby Systeme). Letztere hat bei Vorhandensein beider Dateien den Vorrang. Der alte Parameter standby_mode, der dieses Verhalten seither kontrollierte, wurde entfernt.
Für automatische Deployments von hochverfügbaren Systemen bedeutet dies eine große Änderung. Allerdings ist es nun auch möglich, entsprechende Konfigurationsarbeiten fast vollständig per ALTER SYSTEM vorzunehmen, sodass man nur noch eine Konfigurationsdatei pflegen muss.
REINDEX CONCURRENTLY
Mit PostgreSQL® 12 gibt es nun eine Möglichkeit, Indexe mit so geringen Sperren wie möglich neu anzulegen. Dies vereinfacht einer der häufigsten Wartungsaufgaben in sehr schreiblastigen Datenbanken erheblich. Zuvor musste mit einer Kombination aus CREATE INDEX CONCURRENTLY und DROP INDEX CONCURRENTLY gearbeitet werden. Hierbei musste man auch aufpassen, dass Indexnamen entsprechend neu vergeben wurden.
Die Release Notes geben eine noch viel detailliertere Übersicht über alle Neuerungen und vor allem auch Inkompatiblitäten gegenüber den vorangegangenen PostgreSQL® Versionen.
Suche
Sie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Sie sehen gerade einen Platzhalterinhalt von Brevo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Turnstile. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
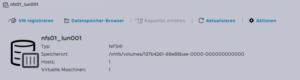
 Anschließend wird die Festplatte mit dem qm-Dienstprogramm importiert, wobei die VM-ID (die während des VM-Erstellungsprozesses erstellt wurde) definiert wird, sowie der Festplattenname (der kopiert wurde) und der Zieldatenspeicher auf dem Proxmox-System angegeben werden, wo die VM-Festplatte gespeichert werden soll:
Anschließend wird die Festplatte mit dem qm-Dienstprogramm importiert, wobei die VM-ID (die während des VM-Erstellungsprozesses erstellt wurde) definiert wird, sowie der Festplattenname (der kopiert wurde) und der Zieldatenspeicher auf dem Proxmox-System angegeben werden, wo die VM-Festplatte gespeichert werden soll: