TOASTed JSONB-Daten in PostgreSQL: Leistungstests verschiedener Kompressionsalgorithmen
| Kategorien: | HowTos PostgreSQL® |
|---|---|
| Tags: | planetpostgresql PostgreSQL® |
TOAST (The Oversized Attribute Storage Technique) ist der Mechanismus von PostgreSQL zur Handhabung großer Datenobjekte, die die 8-KB-Datenseitenbegrenzung überschreiten. Eingeführt in PostgreSQL 7.1, ist TOAST eine verbesserte Version des Out-of-Line-Speichermechanismus, der in Oracle-Datenbanken zur Handhabung großer Objekte (LOBs) verwendet wird. Beide Datenbanken speichern Daten variabler Länge entweder inline innerhalb der Tabelle oder in einer separaten Struktur. PostgreSQL begrenzt die maximale Größe eines einzelnen Tupels auf eine Datenseite. Wenn die Größe des Tupels, einschließlich komprimierter Daten in einer Spalte variabler Länge, einen bestimmten Schwellenwert überschreitet, wird der komprimierte Teil in eine separate Datendatei verschoben und automatisch in Chunks aufgeteilt, um die Leistung zu optimieren.
 TOAST kann zur Speicherung von langen Texten, Binärdaten in Bytea-Spalten, JSONB-Daten, langen HSTORE-Schlüssel-Wert-Paaren, großen Arrays, umfangreichen XML-Dokumenten oder benutzerdefinierten zusammengesetzten Datentypen verwendet werden. Sein Verhalten wird von zwei Parametern beeinflusst: TOAST_TUPLE_THRESHOLD und TOAST_TUPLE_TARGET. Der erste ist ein fest codierter Parameter, der im PostgreSQL-Quellcode in der Datei heaptoast.h definiert ist, basierend auf der Funktion MaximumBytesPerTuple, die für vier TOAST-Tupel pro Seite berechnet wird, was zu einer Begrenzung von 2000 Byte führt. Dieser fest codierte Schwellenwert verhindert, dass Benutzer zu kleine Werte im Out-of-Line-Speicher ablegen, was die Leistung beeinträchtigen würde. Der zweite Parameter, TOAST_TUPLE_TARGET, ist ein Speicherparameter auf Tabellenebene, der mit demselben Wert wie TOAST_TUPLE_THRESHOLD initialisiert wird, aber für einzelne Tabellen angepasst werden kann. Er definiert die minimale Tupellänge, die erforderlich ist, bevor versucht wird, lange Spaltenwerte zu komprimieren und in TOAST-Tabellen zu verschieben.
TOAST kann zur Speicherung von langen Texten, Binärdaten in Bytea-Spalten, JSONB-Daten, langen HSTORE-Schlüssel-Wert-Paaren, großen Arrays, umfangreichen XML-Dokumenten oder benutzerdefinierten zusammengesetzten Datentypen verwendet werden. Sein Verhalten wird von zwei Parametern beeinflusst: TOAST_TUPLE_THRESHOLD und TOAST_TUPLE_TARGET. Der erste ist ein fest codierter Parameter, der im PostgreSQL-Quellcode in der Datei heaptoast.h definiert ist, basierend auf der Funktion MaximumBytesPerTuple, die für vier TOAST-Tupel pro Seite berechnet wird, was zu einer Begrenzung von 2000 Byte führt. Dieser fest codierte Schwellenwert verhindert, dass Benutzer zu kleine Werte im Out-of-Line-Speicher ablegen, was die Leistung beeinträchtigen würde. Der zweite Parameter, TOAST_TUPLE_TARGET, ist ein Speicherparameter auf Tabellenebene, der mit demselben Wert wie TOAST_TUPLE_THRESHOLD initialisiert wird, aber für einzelne Tabellen angepasst werden kann. Er definiert die minimale Tupellänge, die erforderlich ist, bevor versucht wird, lange Spaltenwerte zu komprimieren und in TOAST-Tabellen zu verschieben.
In der Quelldatei heaptoast.h erklärt ein Kommentar: „Ist ein Tupel größer als TOAST_TUPLE_THRESHOLD, versuchen wir, es durch Komprimieren komprimierbarer Felder und Verschieben von EXTENDED- und EXTERNAL-Daten Out-of-Line auf nicht mehr als TOAST_TUPLE_TARGET Bytes zu „toasten“. Die Zahlen müssen nicht identisch sein, obwohl sie es derzeit sind. Es ist nicht sinnvoll, dass TARGET THRESHOLD überschreitet, aber es könnte nützlich sein, es kleiner zu machen.“ Das bedeutet, dass in realen Tabellen direkt im Tupel gespeicherte Daten komprimiert sein können oder auch nicht, abhängig von ihrer Größe nach der Komprimierung. Um zu überprüfen, ob Spalten komprimiert sind und welcher Algorithmus verwendet wird, können wir die PostgreSQL-Systemfunktion pg_column_compression verwenden. Zusätzlich hilft die Funktion pg_column_size, die Größe einzelner Spalten zu überprüfen. PostgreSQL 17 führt eine neue Funktion, pg_column_toast_chunk_id, ein, die anzeigt, ob der Wert einer Spalte in der TOAST-Tabelle gespeichert ist.
In den neuesten PostgreSQL-Versionen werden zwei Kompressionsalgorithmen verwendet: PGLZ (PostgreSQL LZ) und LZ4. Beide sind Varianten des LZ77-Algorithmus, wurden aber für unterschiedliche Anwendungsfälle entwickelt. PGLZ eignet sich für gemischte Text- und numerische Daten, wie XML oder JSON in Textform, und bietet ein Gleichgewicht zwischen Kompressionsgeschwindigkeit und -rate. Es verwendet einen Gleitfenstermechanismus, um wiederholte Sequenzen in den Daten zu erkennen, und bietet ein angemessenes Gleichgewicht zwischen Kompressionsgeschwindigkeit und Kompressionsrate. LZ4 hingegen ist eine schnelle Kompressionsmethode, die für Echtzeitszenarien entwickelt wurde. Es bietet Hochgeschwindigkeitskomprimierung und -dekomprimierung, was es ideal für leistungskritische Anwendungen macht. LZ4 ist deutlich schneller als PGLZ, insbesondere bei der Dekomprimierung, und verarbeitet Daten in festen Blöcken (typischerweise 64 KB) unter Verwendung einer Hash-Tabelle, um Übereinstimmungen zu finden. Dieser Algorithmus zeichnet sich bei Binärdaten wie Bildern, Audio- und Videodateien aus.
In meinem internen Forschungsprojekt, das darauf abzielte, die Leistung von JSONB-Daten unter verschiedenen Anwendungsfällen zu verstehen, habe ich mehrere Leistungstests für Abfragen durchgeführt, die JSONB-Daten verarbeiten. Die Ergebnisse einiger Tests zeigten interessante und manchmal überraschende Leistungsunterschiede zwischen diesen Algorithmen. Die vorgestellten Beispiele sind jedoch anekdotisch und können nicht verallgemeinert werden. Ziel dieses Artikels ist es, das Bewusstsein dafür zu schärfen, dass es enorme Leistungsunterschiede geben kann, die je nach spezifischen Daten und Anwendungsfällen sowie der spezifischen Hardware variieren. Daher können diese Ergebnisse nicht blind angewendet werden.
JSONB-Daten werden als binäres Objekt mit einer Baumstruktur gespeichert, wobei Schlüssel und Werte in separaten Zellen gespeichert werden und Schlüssel auf derselben JSON-Ebene in sortierter Reihenfolge abgelegt sind. Verschachtelte Ebenen werden als zusätzliche Baumstrukturen unter ihren entsprechenden Schlüsseln der höheren Ebene gespeichert. Diese Struktur bedeutet, dass das Abrufen von Daten für die ersten Schlüssel in der obersten JSON-Ebene schneller ist als das Abrufen von Werten für stark verschachtelte Schlüssel, die tiefer im Binärbaum gespeichert sind. Obwohl dieser Unterschied normalerweise vernachlässigbar ist, wird er bei Abfragen, die sequentielle Scans über den gesamten Datensatz durchführen, signifikant, da diese kleinen Verzögerungen die Gesamtleistung kumulativ beeinträchtigen können.
Der für die Tests verwendete Datensatz bestand aus historischen GitHub-Ereignissen, die als JSON-Objekte von gharchive.org verfügbar waren und die erste Januarwoche 2023 abdeckten. Ich habe drei verschiedene Tabellen getestet: eine mit PGLZ, eine mit LZ4 und eine mit EXTERNAL-Speicher ohne Komprimierung. Ein Python-Skript lud die Daten herunter, entpackte sie und lud sie in die jeweiligen Tabellen. Jede Tabelle wurde separat geladen, um zu verhindern, dass frühere Operationen das PostgreSQL-Speicherformat beeinflussen.
Die erste bemerkenswerte Beobachtung war der Größenunterschied zwischen den Tabellen. Die Tabelle mit LZ4-Komprimierung war die kleinste mit etwa 38 GB, gefolgt von der Tabelle mit PGLZ mit 41 GB. Die Tabelle mit externem Speicher ohne Komprimierung war mit 98 GB deutlich größer. Da die Testmaschinen nur 32 GB RAM hatten, passte keine der Tabellen vollständig in den Speicher, was die Festplatten-I/O zu einem wichtigen Leistungsfaktor machte. Etwa ein Drittel der Datensätze wurde in TOAST-Tabellen gespeichert, was eine typische Datengrößenverteilung widerspiegelte, wie sie von unseren Kunden beobachtet wird.
Um Caching-Effekte zu minimieren, habe ich mehrere Tests mit mehreren parallelen Sitzungen durchgeführt, die Testabfragen mit jeweils zufällig gewählten Parametern ausführten. Zusätzlich zu Anwendungsfällen mit verschiedenen Indextypen führte ich auch sequentielle Scans über die gesamte Tabelle durch. Die Tests wurden mit unterschiedlicher Anzahl paralleler Sitzungen wiederholt, um genügend Datenpunkte zu sammeln, und dieselben Tests wurden an allen drei Tabellen mit verschiedenen Kompressionsalgorithmen durchgeführt.
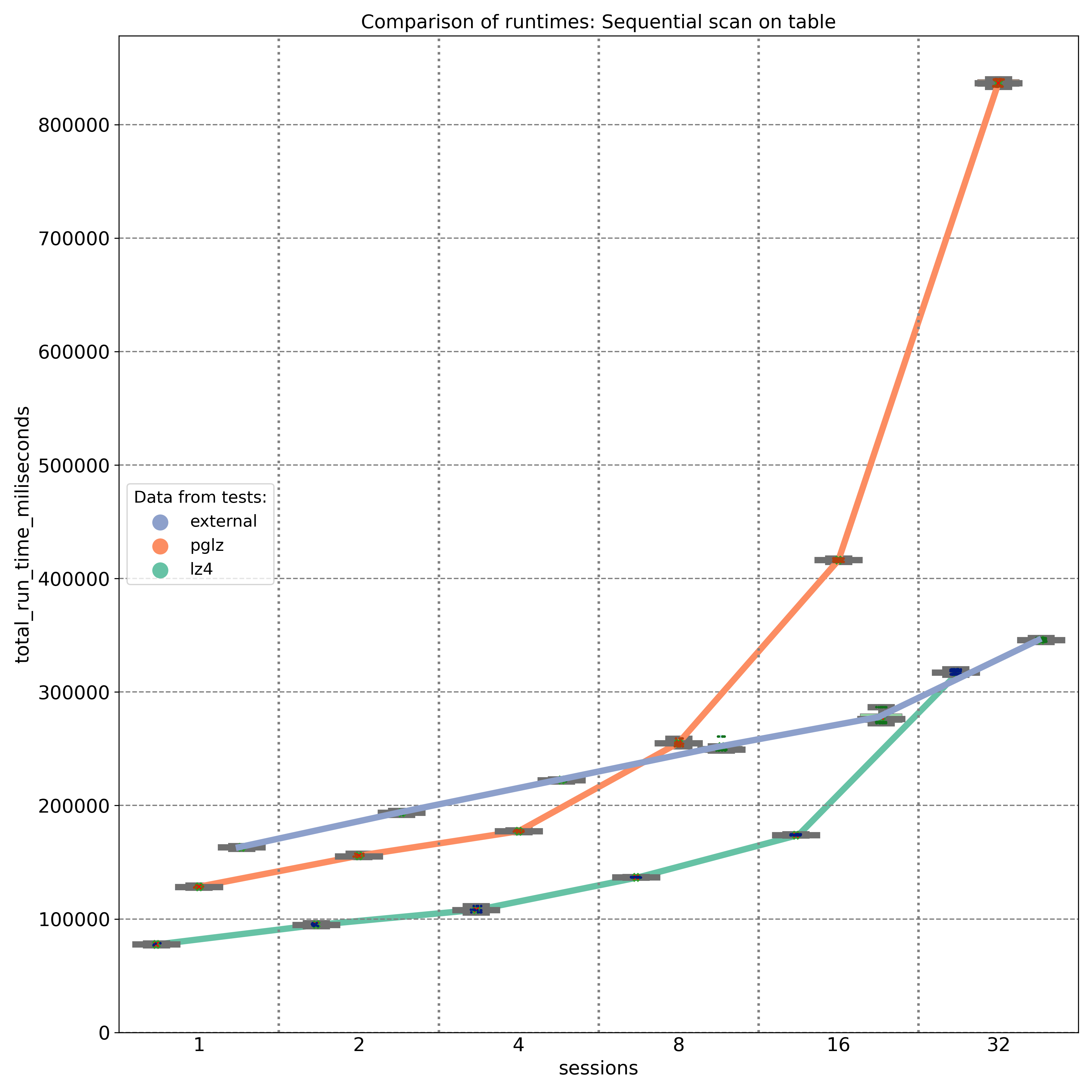
Die erste Grafik zeigt die Ergebnisse von SELECT-Abfragen, die sequentielle Scans durchführen und JSON-Schlüssel abrufen, die am Anfang des JSONB-Binärobjekts gespeichert sind. Wie erwartet bietet externer Speicher ohne Komprimierung (blaue Linie) eine nahezu lineare Leistung, wobei die Festplatten-I/O der Hauptfaktor ist. Auf einer 8-Kern-Maschine liefert der PGLZ-Algorithmus (rote Linie) unter geringeren Lasten eine recht gute Leistung. Sobald jedoch die Anzahl der parallelen Abfragen die Anzahl der verfügbaren CPU-Kerne (8) erreicht, beginnt seine Leistung abzunehmen und wird schlechter als die Leistung unkomprimierter Daten. Unter höheren Lasten wird er zu einem ernsthaften Engpass. Im Gegensatz dazu verarbeitet LZ4 (grüne Linie) parallele Abfragen außergewöhnlich gut und behält eine bessere Leistung als unkomprimierte Daten bei, selbst bei bis zu 32 parallelen Abfragen auf 8 Kernen.
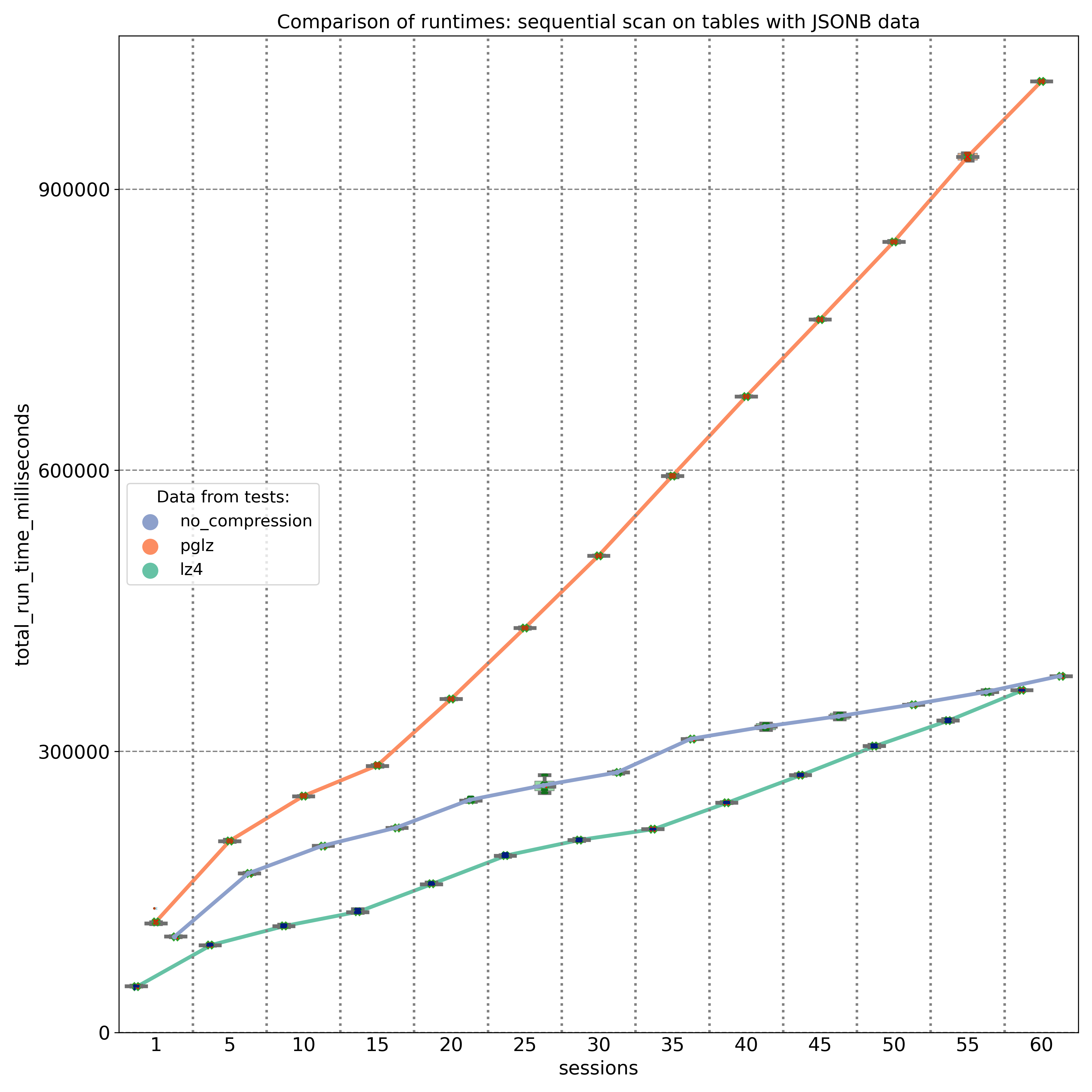
Der zweite Test zielte auf JSONB-Schlüssel ab, die an verschiedenen Positionen (Anfang, Mitte und Ende) innerhalb des JSONB-Binärobjekts gespeichert sind. Die Ergebnisse, gemessen auf einer 20-Kern-Maschine, zeigen, dass PGLZ (rote Linie) von Anfang an langsamer ist als die unkomprimierte Tabelle. In diesem Fall verschlechtert sich die Leistung von PGLZ linear statt geometrisch, liegt aber immer noch deutlich hinter LZ4 (grüne Linie). LZ4 übertraf während des gesamten Tests durchweg die unkomprimierten Daten.
Wenn wir uns jedoch entscheiden, den Kompressionsalgorithmus zu ändern, ändert das einfache Erstellen einer neuen Tabelle mit der Einstellung default_toast_compression auf „lz4“ und das Ausführen von INSERT INTO my_table_lz4 SELECT * FROM my_table_pglz; den Kompressionsalgorithmus bestehender Datensätze nicht. Jeder bereits komprimierte Datensatz behält seinen ursprünglichen Kompressionsalgorithmus bei. Sie können die Systemfunktion pg_column_compression verwenden, um zu überprüfen, welcher Algorithmus für jeden Datensatz verwendet wurde. Die Standard-Komprimierungseinstellung gilt nur für neue, unkomprimierte Daten; alte, bereits komprimierte Daten werden unverändert kopiert.
Um alte Daten wirklich in einen anderen Kompressionsalgorithmus zu konvertieren, müssen wir sie über Text umwandeln. Für JSONB-Daten würden wir eine Abfrage wie diese verwenden: INSERT INTO my_table_lz4 (jsonb_data, …) SELECT jsonb_data::text::jsonb, … FROM my_table_pglz; Dies stellt sicher, dass alte Daten mit der neuen LZ4-Komprimierung gespeichert werden. Dieser Prozess kann jedoch zeit- und ressourcenintensiv sein, daher ist es wichtig, die Vorteile abzuwägen, bevor man ihn in Angriff nimmt.
Zusammenfassend lässt sich sagen: Meine Tests zeigten signifikante Leistungsunterschiede zwischen den Algorithmen PGLZ und LZ4 zur Speicherung komprimierter JSONB-Daten. Diese Unterschiede sind besonders ausgeprägt, wenn die Maschine unter hoher paralleler Last steht. Die Tests zeigten eine starke Leistungsverschlechterung bei Daten, die mit dem PGLZ-Algorithmus gespeichert wurden, wenn die Anzahl der parallelen Sitzungen die Anzahl der verfügbaren Kerne überschritt. In einigen Fällen schnitt PGLZ von Anfang an schlechter ab als unkomprimierte Daten. Im Gegensatz dazu übertraf LZ4 sowohl unkomprimierte als auch PGLZ-komprimierte Daten durchweg, insbesondere unter hoher Last. Die Festlegung von LZ4 als Standardkomprimierung für neue Daten scheint die richtige Wahl zu sein, und einige Cloud-Anbieter haben diesen Ansatz bereits übernommen. Diese Ergebnisse sollten jedoch nicht blind auf bestehende Daten angewendet werden. Sie sollten Ihre spezifischen Anwendungsfälle und Daten testen, um festzustellen, ob eine Konvertierung den Zeit- und Ressourcenaufwand wert ist, da die Datenkonvertierung ein Umwandeln erfordert und ein ressourcenintensiver Prozess sein kann.
| Kategorien: | HowTos PostgreSQL® |
|---|---|
| Tags: | planetpostgresql PostgreSQL® |
