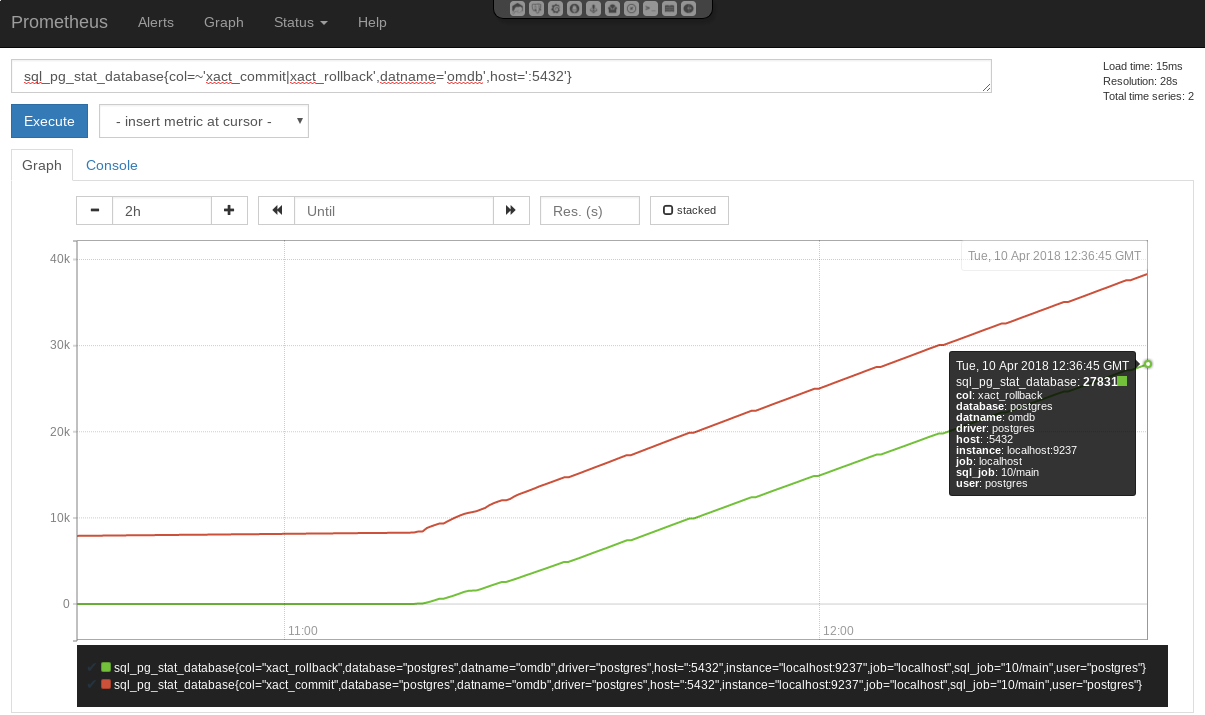
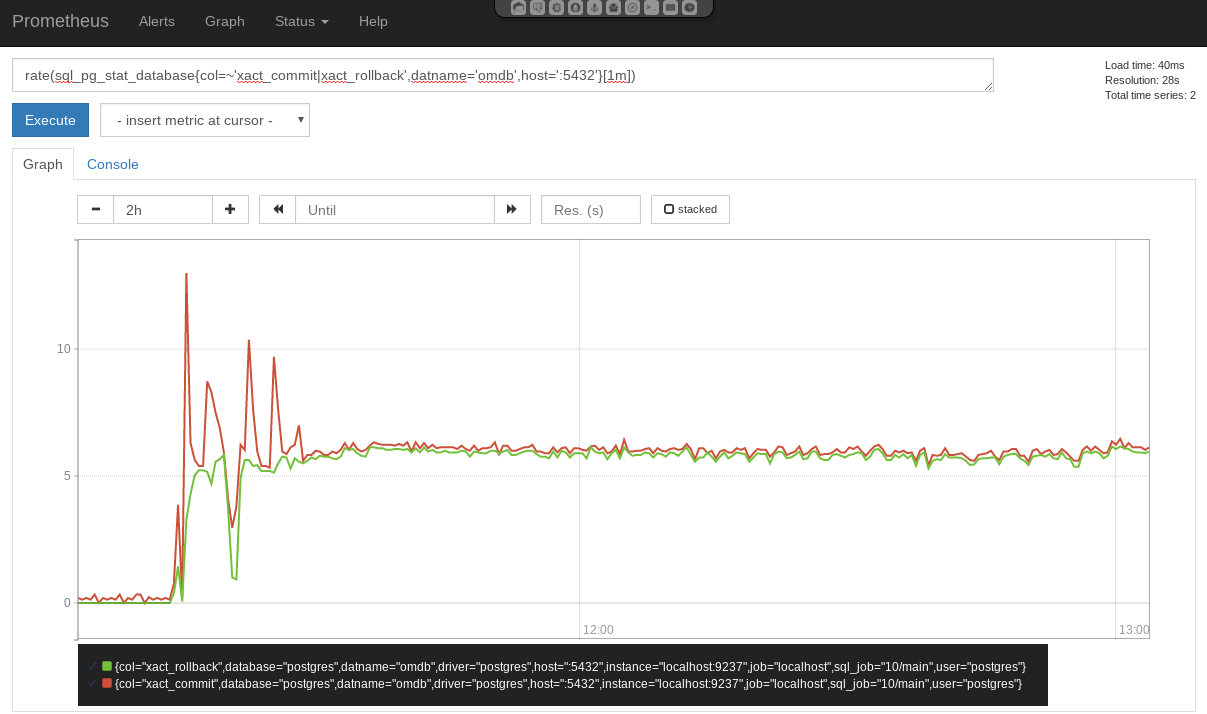
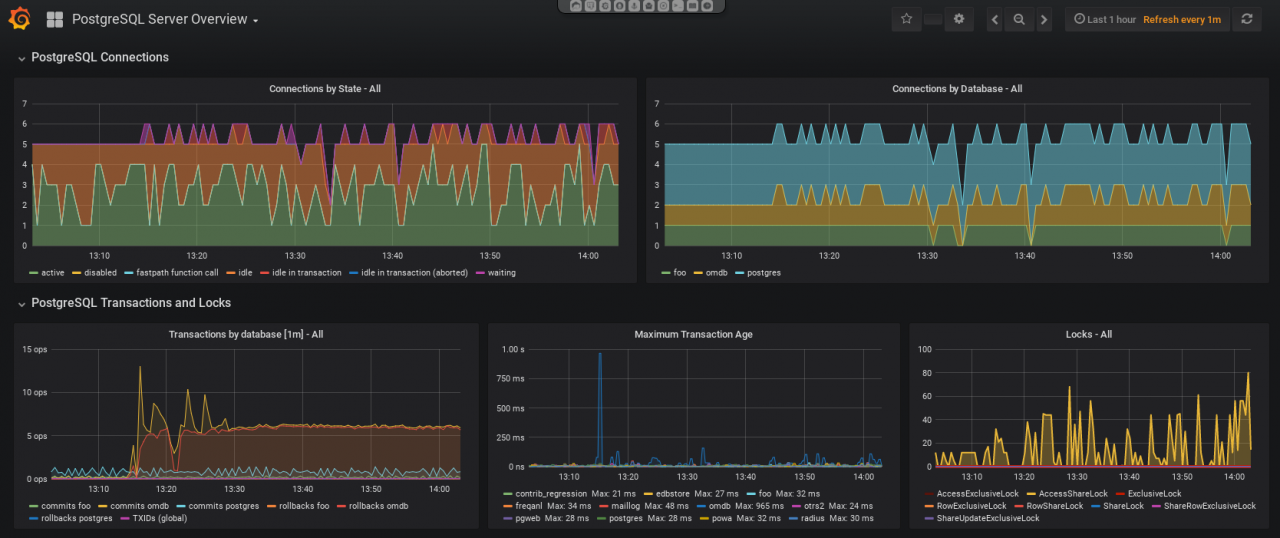
Patroni ist eine Cluster-Lösung für PostgreSQL®, die sich gerade im Cloud- und Kubernetes-Umfeld auf Grund seiner Integration mit z.B. Etcd immer größerer Beliebtheit erfreut. Vor einiger Zeit haben wir über die Integration von Patroni in Debian berichtet. Seit kurzem ist auch das eng mit Patroni verzahnte vip-manager Projekt in Debian verfügbar, welches im Folgenden vorgestellt wird.
Patroni verwendet für Leader-Election und Failover einen sogenannten „Distributed Consensus Store“ (DCS). Der momentane Cluster-Leader aktualisiert laufend seinen Leader-Key im DCS. Sobald dieser von Patroni nicht mehr aktualisiert werden kann und obsolet wird, erfolgt eine neue Leader-Election unter den verbleibenden Knoten.
Client-Lösungen für Hochverfügbarkeit
Allerdings muss auch aus Anwendersicht gewährleistet sein, dass die Anwendung mit dem Leader verbunden ist, da sonst keine schreibenden Transaktionen möglich sind. Herkömmliche Hochverfügbarkeits-Lösungen wie Pacemaker verwenden hier virtuelle IPs (VIPs), die im Failover-Fall zum neuen Primary-Knoten geschwenkt werden.
Für Patroni gab es diesen Mechanismus bisher nicht. Üblicherweise wird entweder HAProxy (oder eine ähnliche Lösung) verwendet, welche einen periodischen Health-Check auf die Patroni-API der einzelnen Knoten durchführt und so den aktuellen Leader ermittelt und Client-Anfragen dorthin weiterleitet.
Eine Alternative ist die Verwendung von Client-seitigem Failover, welches seit PostgreSQL® 10 verfügbar ist. Hierbei werden alle Mitglieder des Clusters beim Client konfiguriert. Dieser versucht nach einem Verbindungs-Abbruch reihum die anderen Knoten zu erreichen, bis er erneut einen Primary findet.
vip-manager
Ein komfortabler neuer Ansatz ist vip-manager. Dieser in Go geschriebene Service wird auf allen Cluster-Knoten gestartet und verbindet sich mit dem DCS.
Falls der lokale Knoten den Leader-Key besitzt, startet vip-manager die konfigurierte VIP. Im Fall eines Failovers entfernt vip-manager die VIP vom alten Leader und der entsprechende Service des neuen Leaders startet diese dort. Der Client kann nun für diese VIP konfiguriert werden und wird sich stets mit dem Cluster-Leader verbinden.
Debian-Integration von vip-manager
Für Debian wurde das pg_createconfig_patroni Programm angepasst, so dass es nun auch eine vip-manager Konfiguration erstellen kann:
pg_createconfig_patroni 11 test --vip=10.0.3.2
Den Service starten wir analog zu Patroni für jede Instanz:
systemctl start vip-manager@11-test
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.247 | Leader | running | 1 | |
| 11-test | pg2 | 10.0.3.94 | | running | 1 | 0 |
| 11-test | pg3 | 10.0.3.214 | | running | 1 | 0 |
+---------+--------+------------+--------+---------+----+-----------+
Im Journal von pg1 kann man sehen, dass die VIP konfiguriert wurde:
Dez 09 14:53:38 pg1 vip-manager[9314]: 2019/12/09 14:53:38 IP address 10.0.3.2/24 state is false, desired true
Dez 09 14:53:38 pg1 vip-manager[9314]: 2019/12/09 14:53:38 Configuring address 10.0.3.2/24 on eth0
Dez 09 14:53:38 pg1 vip-manager[9314]: 2019/12/09 14:53:38 IP address 10.0.3.2/24 state is true, desired true
Im Fall von LXC-Containern sieht man dies auch im Output von lxc-ls -f:
NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
pg1 RUNNING 0 - 10.0.3.2, 10.0.3.247 - false
pg2 RUNNING 0 - 10.0.3.94 - false
pg3 RUNNING 0 - 10.0.3.214 - false
Die vip-manager Pakete sind für Debian testing (bullseye) und unstable in den offiziellen Debian-Repositories erhältlich.
Für Debian stable (buster), sowie Ubuntu 19.04 und 19.10 sind Pakete auf dem von credativ gepflegten apt.postgresql.org verfügbar, zusammen mit den aktualisierten Patroni-Paketen mit vip-manager Integration.
Switchover-Verhalten
Im Falle eines geplanten Switchovers wird z.B. pg2 zum neuen Leader:
# patronictl -c /etc/patroni/11-test.yml switchover --master pg1 --candidate pg2 --force
Current cluster topology
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.247 | Leader | running | 1 | |
| 11-test | pg2 | 10.0.3.94 | | running | 1 | 0 |
| 11-test | pg3 | 10.0.3.214 | | running | 1 | 0 |
+---------+--------+------------+--------+---------+----+-----------+
2019-12-09 15:35:32.52642 Successfully switched over to "pg2"
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.247 | | stopped | | unknown |
| 11-test | pg2 | 10.0.3.94 | Leader | running | 1 | |
| 11-test | pg3 | 10.0.3.214 | | running | 1 | 0 |
+---------+--------+------------+--------+---------+----+-----------+
Die VIP wurde nun auf den neuen Leader geschwenkt:
NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
pg1 RUNNING 0 - 10.0.3.247 - false
pg2 RUNNING 0 - 10.0.3.2, 10.0.3.94 - false
pg3 RUNNING 0 - 10.0.3.214 - false
Dies ist auch in den Journals zu sehen, hier vom alten Leader:
Dez 09 15:35:31 pg1 patroni[9222]: 2019-12-09 15:35:31,634 INFO: manual failover: demoting myself
Dez 09 15:35:31 pg1 patroni[9222]: 2019-12-09 15:35:31,854 INFO: Leader key released
Dez 09 15:35:32 pg1 vip-manager[9314]: 2019/12/09 15:35:32 IP address 10.0.3.2/24 state is true, desired false
Dez 09 15:35:32 pg1 vip-manager[9314]: 2019/12/09 15:35:32 Removing address 10.0.3.2/24 on eth0
Dez 09 15:35:32 pg1 vip-manager[9314]: 2019/12/09 15:35:32 IP address 10.0.3.2/24 state is false, desired false
Sowie vom neuen Leader pg2:
Dez 09 15:35:31 pg2 patroni[9229]: 2019-12-09 15:35:31,881 INFO: promoted self to leader by acquiring session lock
Dez 09 15:35:31 pg2 vip-manager[9292]: 2019/12/09 15:35:31 IP address 10.0.3.2/24 state is false, desired true
Dez 09 15:35:31 pg2 vip-manager[9292]: 2019/12/09 15:35:31 Configuring address 10.0.3.2/24 on eth0
Dez 09 15:35:31 pg2 vip-manager[9292]: 2019/12/09 15:35:31 IP address 10.0.3.2/24 state is true, desired true
Dez 09 15:35:32 pg2 patroni[9229]: 2019-12-09 15:35:32,923 INFO: Lock owner: pg2; I am pg2
Wie man sehen kann erfolgt der Schwenk der VIP innerhalb einer Sekunde.
Aktualisiertes Ansible Playbook
Unser Ansible-Playbook für die automatisierte Einrichtung eines Drei-Knoten-Clusters unter Debian wurde ebenfalls aktualisiert und kann nun bei Bedarf eine VIP konfigurieren:
# ansible-playbook -i inventory -e vip=10.0.3.2 patroni.yml
Unterstützung
Falls Sie Unterstützung beim Einsatz von PostgreSQL®, Patroni, vip-manager oder anderer Software für Hochverfügbarkeit benötigen, steht Ihnen unser Open Source Support Center zur Verfügung – Falls gewünscht auch 24 Stunden am Tag, an 365 Tagen im Jahr.
Wir freuen uns auf Ihre Kontaktaufnahme.
Die PostgreSQL® Global Development Group (PGDG) hat Version 12 der populären, freien Datenbank PostgreSQL® freigegeben. Wie unser Artikel für Beta 4 bereits angedeutet hat, sind eine Vielzahl von neuen Features, Verbesserungen und Optimierungen in das Release eingeflossen. Dazu gehören unter anderem:
Optimierte Speicherplatznutzung und Geschwindigkeit bei btree-Indexen
btree-Indexe, der Standardindextyp in PostgreSQL®, hat einige Optimierungen in PostgreSQL® 12 erfahren.
btree Indexe speicherten in der Vergangenheit Doubletten (also mehrfache Einträge mit denselben Schlüsselwerten) in einer unsortierten Reihenfolge. Dies hatte eine suboptimale Nutzung der physischen Repräsentation in betreffenden Indexen zu Folge. Eine Optimierung speichert diese mehrfachen Schlüsselwerte nun in derselben Reihenfolge, wie diese auch physisch in der Tabelle gespeichert sind. Dies verbessert die Speicherplatzausnutzung und die Aufwände für das Verwalten entsprechender Indexe vom Typ btree. Darüber hinaus verwenden Indexe mit mehreren indizierten Spalten eine verbesserte physische Repräsentation, sodass deren Speicherplatznutzung ebenfalls verbessert wird. Um hiervon in PostgreSQL® 12 zu profitieren, müssen diese jedoch, falls per binärem Upgrade mittels pg_upgrade auf die neue Version gewechselt wurde, diese Indexe neu angelegt bzw. reindiziert werden.
Einfügeoperationen in btree-Indexe werden zudem durch verbessertes Locking beschleunigt.
Verbesserungen für pg_checksums
credativ hat eine Erweiterung für pg_checksums beigesteuert, die es ermöglicht Blockprüfsummen in gestoppten PostgreSQL®-Instanzen zu aktivieren oder zu deaktivieren. Vorher konnte dies nur durch ein Neuanlegen der physischen Datenrepräsentation des Clusters per initdb durchgeführt werden.
pg_checksums verfügt nun auch mit dem Parameter --progress über die Möglichkeit, einen Statusverlauf auf der Konsole anzuzeigen. Die entsprechenden Codebeiträge stammen von den Kollegen Michael Banck und Bernd Helmle.
Optimizer Inlining von Common Table Expressions
Bis einschließlich PostgreSQL® 11 war es dem PostgreSQL® Optimizer nicht möglich, Common Table Expressions (auch CTE oder WITH Abfragen genannt) zu optimieren. Wurde ein solcher Ausdruck in einer Abfrage verwendet, so wurde die CTE immer als erstes evaluiert und materialisiert, bevor der Rest der Abfrage abgearbeitet wurde. Dies führte bei komplexeren CTE Ausdrücken zu entsprechend teuren Ausführungsplänen. Folgendes generisches Beispiel illustriert dies anschaulich. Gegeben sei ein Join mit einem CTE Ausdruck, der alle gerade Zahlen aus einer numerischen Spalten filtert:
WITH t_cte AS (SELECT id FROM foo WHERE id % 2 = 0) SELECT COUNT(*) FROM t_cte JOIN bar USING(id);
In PostgreSQL® 11 führt die Verwendung einer CTE immer zu einem CTE Scan, der den CTE Ausdruck als erstes materialisiert:
EXPLAIN (ANALYZE, BUFFERS) WITH t_cte AS (SELECT id FROM foo WHERE id % 2 = 0) SELECT COUNT(*) FROM t_cte JOIN bar USING(id) ;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Aggregate (cost=2231.12..2231.14 rows=1 width=8) (actual time=48.684..48.684 rows=1 loops=1)
Buffers: shared hit=488
CTE t_cte
-> Seq Scan on foo (cost=0.00..1943.00 rows=500 width=4) (actual time=0.055..17.146 rows=50000 loops=1)
Filter: ((id % 2) = 0)
Rows Removed by Filter: 50000
Buffers: shared hit=443
-> Hash Join (cost=270.00..286.88 rows=500 width=0) (actual time=7.297..47.966 rows=5000 loops=1)
Hash Cond: (t_cte.id = bar.id)
Buffers: shared hit=488
-> CTE Scan on t_cte (cost=0.00..10.00 rows=500 width=4) (actual time=0.063..31.158 rows=50000 loops=1)
Buffers: shared hit=443
-> Hash (cost=145.00..145.00 rows=10000 width=4) (actual time=7.191..7.192 rows=10000 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 480kB
Buffers: shared hit=45
-> Seq Scan on bar (cost=0.00..145.00 rows=10000 width=4) (actual time=0.029..3.031 rows=10000 loops=1)
Buffers: shared hit=45
Planning Time: 0.832 ms
Execution Time: 50.562 ms
(19 rows)
Dieser Plan materialisiert zunächst die CTE mit einem Sequential Scan mit entsprechendem Filter (id % 2 = 0). Hier wird kein funktionaler Index verwendet, daher ist dieser Scan entsprechend teurer. Danach wird das Ergebnis der CTE per Hash Join mit der entsprechenden Join Bedingung mit der Tabelle bar verknüpft. Mit PostgreSQL® 12 erhält der Optimizer nun die Fähigkeit, diese CTE Ausdrücke ohne vorherige Materialisierung zu inlinen. Der zugrundeliegende, optimierte Plan in PostgreSQL® 12 sieht dann wie folgt aus:
EXPLAIN (ANALYZE, BUFFERS) WITH t_cte AS (SELECT id FROM foo WHERE id % 2 = 0) SELECT COUNT(*) FROM t_cte JOIN bar USING(id) ;
QUERY PLAN
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Aggregate (cost=706.43..706.44 rows=1 width=8) (actual time=9.203..9.203 rows=1 loops=1)
Buffers: shared hit=148
-> Merge Join (cost=0.71..706.30 rows=50 width=0) (actual time=0.099..8.771 rows=5000 loops=1)
Merge Cond: (foo.id = bar.id)
Buffers: shared hit=148
-> Index Only Scan using foo_id_idx on foo (cost=0.29..3550.29 rows=500 width=4) (actual time=0.053..3.490 rows=5001 loops=1)
Filter: ((id % 2) = 0)
Rows Removed by Filter: 5001
Heap Fetches: 10002
Buffers: shared hit=74
-> Index Only Scan using bar_id_idx on bar (cost=0.29..318.29 rows=10000 width=4) (actual time=0.038..3.186 rows=10000 loops=1)
Heap Fetches: 10000
Buffers: shared hit=74
Planning Time: 0.646 ms
Execution Time: 9.268 ms
(15 rows)
Der Vorteil dieser Methode ist, dass das initiale materialisieren des CTE Ausdrucks entfällt. Stattdessen wird die Abfrage direkt mit einem Join ausgeführt.
Dies funktioniert bei allen nicht-rekursiven CTE Ausdrücken ohne Seiteneffekte (beispielsweise CTEs mit Schreibanweisungen) und solchen, die jeweils nur einmal pro Abfrage referenziert sind. Das alte Verhalten des Optimizers kann mit der Anweisung WITH ... AS MATERIALIZED ... forciert werden.
Generated Columns
Neu in PostgreSQL® 12 sind sogenannte Generated Columns, die auf Ausdrücken basierend ein Ergebnis anhand vorhandener Spaltenwerte berechnen. Diese werden mit den entsprechenden Quellwerten im Tupel gespeichert. Der Vorteil ist, dass das Anlegen von Triggern zur nachträglichen Berechnung von Spaltenwerten entfallen kann. Folgendes einfaches Beispiel anhand einer Preistabelle mit Netto und Bruttopreisen illustriert die neue Funktionalität:
CREATE TABLE preise(netto numeric,
brutto numeric GENERATED ALWAYS AS (netto * 1.19) STORED);
INSERT INTO preise VALUES(17.30);
INSERT INTO preise VALUES(225);
INSERT INTO preise VALUES(247);
INSERT INTO preise VALUES(19.15);
SELECT * FROM preise;
netto │ brutto
───────┼─────────
17.30 │ 20.5870
225 │ 267.75
247 │ 293.93
19.15 │ 22.7885
(4 rows)
Die Spalte brutto wird direkt aus dem Nettopreis berechnet. Das Schlüsselwort STORED ist Pflicht. Selbstverständlich können auf Generated Columns auch Indexe erzeugt werden, allerdings können sie nicht Teil eines Primärschlüssels sein. Ferner muss der SQL Ausdruck eindeutig sein, d.h. auch bei gleicher Eingabemenge das dasselbe Ergebnis liefern. Spalten die als Generated Columns deklariert sind, können nicht explizit in INSERT– oder UPDATE-Operationen verwendet werden. Falls eine Spaltenliste unbedingt notwendig ist, kann mit dem Schlüsselwort DEFAULT der entsprechende Wert indirekt referenziert werden.
Wegfall von expliziten OID Spalten
Explizite OID Spalten waren historisch gesehen ein Weg, eindeutige Spaltenwerte zu erzeugen, so dass eine Tabellenzeile Datenbankweit eindeutig identifiziert werden kann. Seit langer Zeit werden diese in PostgreSQL® jedoch nur noch explizit angelegt und deren grundlegende Funktionalität als überholt angesehen. Mit PostgreSQL® wird nun auch die Möglichkeit explizit solche Spalten anzulegen, endgültig abgeschafft. Damit wird es nicht mehr möglich sein, die Direktive WITH OIDS bei Tabellen anzugeben. Systemtabellen, die schon immer per OID Objekte eindeutig referenzieren, geben OID Werte ab sofort ohne explizite Angabe von OID Spalten in der Ergebnismenge zurück. Besonders ältere Software, die sorglos mit Katalogabfragen hantierte, könnte Probleme durch eine doppelte Spaltenausgabe bekommen.
Verschieben der recovery.conf in die postgresql.conf
Bis einschließlich PostgreSQL® 11 konfigurierte man Datenbankrecovery und Streaming Replication Instanzen über eine separate Konfigurationsdatei recovery.conf.
Mit PostgreSQL® 12 wandern nun sämtliche dort getätigte Konfigurationsarbeiten in die postgresql.conf. Die Datei recovery.conf entfällt ab sofort. PostgreSQL® 12 weigert sich zu starten, sobald diese Datei vorhanden ist. Ob Recovery oder ein Streaming Standby gewünscht ist, entscheidet nun entweder eine Datei recovery.signal (für Recovery) oder standby.signal (für Standby Systeme). Letztere hat bei Vorhandensein beider Dateien den Vorrang. Der alte Parameter standby_mode, der dieses Verhalten seither kontrollierte, wurde entfernt.
Für automatische Deployments von hochverfügbaren Systemen bedeutet dies eine große Änderung. Allerdings ist es nun auch möglich, entsprechende Konfigurationsarbeiten fast vollständig per ALTER SYSTEM vorzunehmen, sodass man nur noch eine Konfigurationsdatei pflegen muss.
REINDEX CONCURRENTLY
Mit PostgreSQL® 12 gibt es nun eine Möglichkeit, Indexe mit so geringen Sperren wie möglich neu anzulegen. Dies vereinfacht einer der häufigsten Wartungsaufgaben in sehr schreiblastigen Datenbanken erheblich. Zuvor musste mit einer Kombination aus CREATE INDEX CONCURRENTLY und DROP INDEX CONCURRENTLY gearbeitet werden. Hierbei musste man auch aufpassen, dass Indexnamen entsprechend neu vergeben wurden.
Die Release Notes geben eine noch viel detailliertere Übersicht über alle Neuerungen und vor allem auch Inkompatiblitäten gegenüber den vorangegangenen PostgreSQL® Versionen.
In diesem Beitrag beschäftigen wir uns mit dem hochverfügbaren Betrieb von PostgreSQL® in einer Kubernetes-Umgebung. Ein Thema, dass für viele unserer PostgreSQL® Anwender sicher von besonderem Interesse ist.
Gemeinsam mit unserem Partnerunternehmen MayaData, demonstrieren wir Ihnen nachfolgend die Einsatzmöglichkeiten und Vorteile des äußerst leistungsfähigen Open Source Projektes – OpenEBS
OpenEBS ist ein frei verfügbares Storage Management System, dessen Entwicklung von MayaData unterstützt und begleitet wird.
Wir bedanken uns ganz besonders bei Murat-Karslioglu von MayaData und unserem Kollegen Adrian Vondendriesch für diesen interessanten und hilfreichen Beitrag, den die Kollegen aufgrund der internationalen Zusammenarbeit diesmal natürlich in englischer Sprach verfasst haben.
PostgreSQL® anywhere — via Kubernetes with some help from OpenEBS and credativ engineering
by Murat Karslioglu, OpenEBS and Adrian Vondendriesch, credativ
Introduction
If you are already running Kubernetes on some form of cloud whether on-premises or as a service, you understand the ease-of-use, scalability and monitoring benefits of Kubernetes — and you may well be looking at how to apply those benefits to the operation of your databases.
PostgreSQL® remains a preferred relational database, and although setting up a highly available Postgres cluster from scratch might be challenging at first, we are seeing patterns emerging that allow PostgreSQL® to run as a first class citizen within Kubernetes, improving availability, reducing management time and overhead, and limiting cloud or data center lock-in.
There are many ways to run high availability with PostgreSQL®; for a list, see the PostgreSQL® Documentation. Some common cloud-native Postgres cluster deployment projects include Crunchy Data’s, Sorint.lab’s Stolon and Zalando’s Patroni/Spilo. Thus far we are seeing Zalando’s operator as a preferred solution in part because it seems to be simpler to understand and we’ve seen it operate well.
Some quick background on your authors:
- OpenEBS is a broadly deployed OpenSource storage and storage management project sponsored by MayaData.
- credativ is a leading open source support and engineering company with particular depth in PostgreSQL®.
In this blog, we’d like to briefly cover how using cloud-native or “container attached” storage can help in the deployment and ongoing operations of PostgreSQL® on Kubernetes. This is the first of a series of blogs we are considering — this one focuses more on why users are adopting this pattern and future ones will dive more into the specifics of how they are doing so.
At the end you can see how to use a Storage Class and a preferred operator to deploy PostgreSQL® with OpenEBS underlying
If you are curious about what container attached storage of CAS is you can read more from the Cloud Native Computing Foundation (CNCF) here.
Conceptually you can think of CAS as being the decomposition of previously monolithic storage software into containerized microservices that themselves run on Kubernetes. This gives all the advantages of running Kubernetes that already led you to run Kubernetes — now applied to the storage and data management layer as well. Of special note is that like Kubernetes, OpenEBS runs anywhere so the same advantages below apply whether on on-premises or on any of the many hosted Kubernetes services.
PostgreSQL® plus OpenEBS
®-with-OpenEBS-persistent-volumes.png“> Postgres-Operator (for cluster deployment)
Postgres-Operator (for cluster deployment)
Install OpenEBS
- If OpenEBS is not installed in your K8s cluster, this can be done from here. If OpenEBS is already installed, go to the next step.
- Connect to MayaOnline (Optional): Connecting the Kubernetes cluster to MayaOnline provides good visibility of storage resources. MayaOnline has various support options for enterprise customers.
Configure cStor Pool
- If cStor Pool is not configured in your OpenEBS cluster, this can be done from here. As PostgreSQL® is a StatefulSet application, it requires a single storage replication factor. If you prefer additional redundancy you can always increase the replica count to 3.
During cStor Pool creation, make sure that the maxPools parameter is set to >=3. If a cStor pool is already configured, go to the next step. Sample YAML named openebs-config.yaml for configuring cStor Pool is provided in the Configuration details below.
openebs-config.yaml
#Use the following YAMLs to create a cStor Storage Pool. # and associated storage class. apiVersion: openebs.io/v1alpha1 kind: StoragePoolClaim metadata: name: cstor-disk spec: name: cstor-disk type: disk poolSpec: poolType: striped # NOTE — Appropriate disks need to be fetched using `kubectl get disks` # # `Disk` is a custom resource supported by OpenEBS with `node-disk-manager` # as the disk operator # Replace the following with actual disk CRs from your cluster `kubectl get disks` # Uncomment the below lines after updating the actual disk names. disks: diskList: # Replace the following with actual disk CRs from your cluster from `kubectl get disks` # — disk-184d99015253054c48c4aa3f17d137b1 # — disk-2f6bced7ba9b2be230ca5138fd0b07f1 # — disk-806d3e77dd2e38f188fdaf9c46020bdc # — disk-8b6fb58d0c4e0ff3ed74a5183556424d # — disk-bad1863742ce905e67978d082a721d61 # — disk-d172a48ad8b0fb536b9984609b7ee653 — -
Create Storage Class
- You must configure a StorageClass to provision cStor volume on a cStor pool. In this solution, we are using a StorageClass to consume the cStor Pool which is created using external disks attached on the Nodes. The storage pool is created using the steps provided in the Configure StoragePool section. In this solution, PostgreSQL® is a deployment. Since it requires replication at the storage level the cStor volume replicaCount is 3. Sample YAML named openebs-sc-pg.yaml to consume cStor pool with cStorVolume Replica count as 3 is provided in the configuration details below.
openebs-sc-pg.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-postgres
annotations:
openebs.io/cas-type: cstor
cas.openebs.io/config: |
- name: StoragePoolClaim
value: "cstor-disk"
- name: ReplicaCount
value: "3"
provisioner: openebs.io/provisioner-iscsi
reclaimPolicy: Delete
---
Launch and test Postgres Operator
- Clone Zalando’s Postgres Operator.
git clone https://github.com/zalando/postgres-operator.git cd postgres-operator
Use the OpenEBS storage class
- Edit manifest file and add openebs-postgres as the storage class.
nano manifests/minimal-postgres-manifest.yaml
After adding the storage class, it should look like the example below:
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: acid-minimal-cluster
namespace: default
spec:
teamId: "ACID"
volume:
size: 1Gi
storageClass: openebs-postgres
numberOfInstances: 2
users:
# database owner
zalando:
- superuser
- createdb
# role for application foo
foo_user: []
#databases: name->owner
databases:
foo: zalando
postgresql:
version: "10"
parameters:
shared_buffers: "32MB"
max_connections: "10"
log_statement: "all"
Start the Operator
- Run the command below to start the operator
kubectl create -f manifests/configmap.yaml # configuration kubectl create -f manifests/operator-service-account-rbac.yaml # identity and permissions kubectl create -f manifests/postgres-operator.yaml # deployment
Create a Postgres cluster on OpenEBS
Optional: The operator can run in a namespace other than default. For example, to use the test namespace, run the following before deploying the operator’s manifests:
kubectl create namespace test kubectl config set-context $(kubectl config current-context) — namespace=test
- Run the command below to deploy from the example manifest:
kubectl create -f manifests/minimal-postgres-manifest.yaml
2. It only takes a few seconds to get the persistent volume (PV) for the pgdata-acid-minimal-cluster-0 up. Check PVs created by the operator using the kubectl get pv command:
$ kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-8852ceef-48fe-11e9–9897–06b524f7f6ea 1Gi RWO Delete Bound default/pgdata-acid-minimal-cluster-0 openebs-postgres 8m44s pvc-bfdf7ebe-48fe-11e9–9897–06b524f7f6ea 1Gi RWO Delete Bound default/pgdata-acid-minimal-cluster-1 openebs-postgres 7m14s
Connect to the Postgres master and test
- If it is not installed previously, install psql client:
sudo apt-get install postgresql-client
2. Run the command below and note the hostname and host port.
kubectl get service — namespace default |grep acid-minimal-cluster
3. Run the commands below to connect to your PostgreSQL® DB and test. Replace the [HostPort] below with the port number from the output of the above command:
export PGHOST=$(kubectl get svc -n default -l application=spilo,spilo-role=master -o jsonpath="{.items[0].spec.clusterIP}")
export PGPORT=[HostPort]
export PGPASSWORD=$(kubectl get secret -n default postgres.acid-minimal-cluster.credentials -o ‘jsonpath={.data.password}’ | base64 -d)
psql -U postgres -c ‘create table foo (id int)’
Congrats you now have the Postgres-Operator and your first test database up and running with the help of cloud-native OpenEBS storage.
Partnership and future direction
As this blog indicates, the teams at MayaData / OpenEBS and credativ are increasingly working together to help organizations running PostgreSQL® and other stateful workloads. In future blogs, we’ll provide more hands-on tips.
We are looking for feedback and suggestions on where to take this collaboration. Please provide feedback below or find us on Twitter or on the OpenEBS slack community.
In den letzten Tagen berichteten verschiedene Quellen von einer angeblich schwereren
COPY <table> FROM|TO PROGRAM
Die Details hierzu werden in CVE-2019-9193 beschrieben.
Stellungnahme und Erläuterung
Diese Darstellung ist unter sachlicher Betrachtung allerdings keine Sicherheitslücke im eigentlichen Sinn. Vielmehr handelt es sich bei dem betroffenen COPY-Kommando um eine privilegierte Datenbankoperation, die unter allen Umständen entweder Superuserberechtigungen (in der Regel z.B. der Benutzer postgres) oder Mitgliedschaft in der Datenbankrolle pg_execute_server_program erfordert. In dieser Hinsicht enthält der im Link angegebene CVE auch einen Fehler, denn die Rolle pg_read_server_files ist nicht ausreichend, um als unprivilegierter Datenbankbenutzer überhaupt dieses Kommando ausführen zu können.
Gegeben sind in den folgenden Beispielen die Rollen bernd und test, wobei bernd eine Datenbankrolle mit Superuserprivileg ist und test lediglich das LOGIN-Privileg besitzt (also ein normaler Datenbankbenutzer).
bernd@db=# \duS bernd
List of roles
Role name │ Attributes │ Member of
───────────┼────────────────────────────────────────────────────────────┼───────────
bernd │ Superuser, Create role, Create DB, Replication, Bypass RLS │ {}
bernd@db=# \duS test
List of roles
Role name │ Attributes │ Member of
───────────┼────────────┼───────────
test │ │ {}
Im Folgenden wird nun versucht, als Benutzer bernd die Ausgabe des Linux-Kommandos echo in eine Tabelle zu schreiben:
bernd@db=# CREATE TABLE test(val text);
CREATE TABLE
bernd@db=# SELECT current_role;
current_role
--------------
bernd
(1 row)
bernd@db=# COPY test FROM PROGRAM '/bin/echo hallo welt';
COPY 1
bernd@db=# SELECT * FROM test;
val
------------
hallo welt
(1 row)
Das hat funktioniert, da die Superuserprivilegien des Datenbankrolle bernd dies explizit erlauben. Anders sieht dies mit der unprivilegierten Rolle test aus:
test@db=> SELECT current_role; current_role -------------- test (1 row) test@db=> COPY test FROM PROGRAM 'echo hallo welt'; FEHLER: nur Superuser oder Mitglieder von pg_execute_server_program können COPY mit externen Programmen verwenden HINT: Jeder kann COPY mit STDOUT oder STDIN verwenden. Der Befehl \copy in psql funktioniert auch für jeden.
Das Ausführen von COPY FROM PROGRAM ist der Rolle test nicht gestattet. Man kann es jetzt wie im CVE beschrieben mit der Mitgliedschaft in der Rolle pg_read_server_files versuchen:
bernd@db=# GRANT pg_read_server_files TO test; bernd@db=# SET ROLE test; test@db=> COPY test FROM PROGRAM 'echo hallo welt'; FEHLER: nur Superuser oder Mitglieder von pg_execute_server_program können COPY mit externen Programmen verwenden HINT: Jeder kann COPY mit STDOUT oder STDIN verwenden. Der Befehl \copy in psql funktioniert auch für jeden.
Auch das ist offensichtlich nicht ausreichend. Mit der Mitgliedschaft pg_execute_server_program kommt man dann jedoch an das Ziel:
bernd@db=# GRANT pg_execute_server_program TO test;
bernd@db=# SET ROLE test;
test@db=> COPY test FROM PROGRAM 'echo hallo welt';
test@db=> SELECT * FROM test;
val
────────────
hallo welt
hallo welt
(2 rows)
Normale Datenbankrollen mit entsprechend fehlenden Berechtigungen sind folglich nicht in der Lage, dieses Kommando auszuführen. Dies ist das Standardverhalten und benötigt keine entsprechenden Änderungen an der Datenbankkonfiguration. Nur Superuser der PostgreSQL®-Instanz besitzen standardmäßig die Berechtigung für das erfolgreiche Ausführen von COPY TO|FROM PROGRAM. Dieser Sachverhalt ist auch entsprechend in der PostgreSQL® Dokumentation beschrieben.
Das mit COPY TO|FROM angegebene Executable wird immer im Kontext des Betriebssystem-Benutzers ausgeführt, unter dem die jeweilige PostgreSQL®-Instanz läuft (in der Regel eigentlich immer postgres). D.h. die Ausführung des Executable unterliegt immer dem Berechtigungskontexts dieses Benutzers. Dieser ist in der Regel eher eingeschränkt, da PostgreSQL® bspw. als root nicht gestartet werden kann. Das heißt, beliebige Zugriffe sind somit ausgeschlossen. Folgendes Beispiel versucht nun mit der Rolle test die Datei /etc/shadow mit den Passwörtern des Betriebssystems zu lesen:
test@db=> COPY test FROM PROGRAM 'cat /etc/shadow'; FEHLER: Programm »cat /etc/shadow« fehlgeschlagen DETAIL: Kindprozess hat mit Code 1 beendet
Dies schlägt fehl, denn der angesprochene Berechtigungskontext des Betriebsystem-Benutzers, unter dem die PostgreSQL®-Instanz ausgeführt wird, hat keine Zugriffsberechtigung auf /etc/shadow.
Zusammenfassung
Es ist nicht möglich als Standard-Datenbankrolle ohne entsprechend erteilte Berechtigungen ohne weiteres die angebliche Sicherheitslücke wie im CVE beschrieben auszunutzen. Datenbankrollen müssen entgegen der empfohlenen Praxis entweder über SUPERUSER Privilegien verfügen oder explizit die Berechtigung der Rolle pg_execute_server_program erhalten. Daher ist es wichtig bei PostgreSQL® Installationen beim Anlegen und Verteilen von Berechtigungen entsprechend sorgfältig vorzugehen. Der Blogartikel des Core Committee Mitglieds Magnus Hagander (in englischer Sprache) beinhaltet ebenfalls eine entsprechende Erläuterung zum Sachverhalt und empfiehlt sich zur weiteren Lektüre.
An dieser Stelle soll explizit von der Verwendung von Datenbankrollen mit SUPERUSER Privileg für Anwendungen oder Nutzern abgeraten werden. Superuser verfügen noch über viel weitreichendere Berechtigungen als COPY TO|FROM PROGRAM. Sie können beliebige Shared Libraries laden, beliebige Objekte ändern und beliebige Konfigurationsänderungen vornehmen. Daher ist die Verwendung von derart privilegierten Rollen außerhalb des Administrationskontextes dringenst zu vermeiden.