Vor einiger Zeit gab es einen großflächigen Ausfall bei Gitlab. Die Administratoren haben diesen in beispielhafter Weise dokumentiert und auch ein Post-Mortem dazu veröffentlicht. Wir von credativ haben nun eine erste Änderung für eines der Probleme in Postgres eingebracht, die Datenbank-Administratoren in ähnlicher Lage in Zukunft helfen soll.
Ein Teil des Problems trat bei der Verwendung des pg_basebackup-Programms zum Aufsetzen eines neuen lesenden Postgres-Standbys auf, nachdem der eigentliche Standby auf Grund von zu großem Replikations-Verzug und fehlender Transaktionslog-Archivierung nicht mehr verwendbar war.
Die Administratoren haben pg_basebackup ausgeführt, jedoch dieses mehrmals abgebrochen, nachdem weder im normalen Betrieb, noch mit der Option –verbose eine Ausgabe erfolgte und weder Netzwerkverkehr stattfand noch Daten in das Speichersystem geschrieben wurden. Offenbar haben sie vor jedem Aufruf von pg_basebackup das gewünschte Daten-Verzeichnis gelöscht, wobei schließlich aus Versehen das Datenverzeichnis des Master-Servers gelöscht wurde.
Was die Gitlab-Administratoren zu dem Zeitpunkt nicht wussten: Vor Beginn der Übertragung des Datenverzeichnisses vom entfernten Server muss auf diesem ein sogenannter Checkpoint geschrieben werden, bei dem alle ausstehenden Transaktionslogs in das Datenverzeichnis persistiert werden, so dass dieses konsistent ist. Dies kann bei einer hohen Anzahl an ausstehenden Änderungen an dem Datenbestand unter Umständen mehrere Minuten dauern.
Das Postgres-Projekt hat jetzt mit einer ersten kleinen Änderung auf das Gitlab-Problem reagiert: Zum einen wurde die Durchführung des Checkpoints in der Dokumentation des pg_basebackup-Programms unter „Notes“ erwähnt, zum anderen wurde die Ausgabe von pg_basebackup so angepasst, dass zumindest bei der Verwendung der –verbose oder –progress Optionen eine hilfreiche Mitteilung bzgl. dem andauernden Checkpoint erfolgt. Diese Änderungen wurden von credativ erstellt und wurden inzwischen in den offiziellen Postgres-Quellcode aufgenommen und werden auch in den nächsten Wartungs-Releases der Postgres-Versionen 9.4 bis 9.6 enthalten sein.
Seit dem 07. April 2017 befindet sich die aktuelle Entwicklerversion von PostgreSQL® für das nächste Hauptrelease im Feature Freeze. Dies bedeutet, dass keine neuen Features in den aktuellen Entwicklerzweig aufgenommen werden dürfen. Zeit also, einen Blick auf die kommende Version 10.0 der freien Datenbank zu werfen.
Die augenscheinlichste Neuerung finden aufmerksame Leser bereits in der Einleitung dieses Artikels: Die Änderung an der Versionsnummer. Diese folgte seither einer dreistelligen Nomenklatur:
HAUPTVERSION - FIRST . HAUPTVERSION - SECOND . MINOR
Die Hauptversion wird durch die ersten beiden Stellen der Versionsnummer gebildet. Die dritte Stelle gibt immer die sogenannte Minorversion an, also z.B. den Patchlevel der jeweiligen Hauptversion. Aktuell sind also demnach folgende Hauptversionen von PostgreSQL® unterstützt:
- 9.6
- 9.5
- 9.4
- 9.3
- 9.2
Hauptversionen sind einander inkompatibel, d.h. ein Datenbankcluster initialisiert mit PostgreSQL® 9.2 kann nicht einfach mit einer Version 9.3 gestartet werden. Datenbankkatalog aber auch binäre Abweichungen spielen hier eine wichtige Rolle, weshalb man nicht einfach durch Installation und Neustart auf eine neue Version wechseln kann. Die dritte Minornummer gibt den Patchlevel der jeweiligen Hauptversion an und diese sind natürlich ohne weiteres durch ein Update der PostgreSQL® Installation aktualisierbar.
Die kommende Version 10 von PostgreSQL® bricht nun mit dieser Methodik und kürzt die Hauptversion auf eine einzige Zahl, die zweite Nummer ist dann der jeweilige Patchlevel:
HAUPTVERSION . MINOR
D.h. mit Erscheinen von PostgreSQL® 10 im Herbst diesen Jahres sieht die Liste der Versionen (vorerst) aus wie folgt:
- 10
- 9.6
- 9.5
- 9.4
- 9.3
- 9.2
PostgreSQL® 10.0 markiert dann die erste Version im neuen Zweig. Die folgenden Patchlevel werden dann 10.1, 10.2, 10.3 usw. bekommen. Die nächste Hauptversion wird dann folglich PostgreSQL® 11.0 heißen. Die Version 9.2 wird dann auch im September 2017 auslaufen. Die alten Versionen werden die bisherige dreistellige Versionsnummer beibehalten.
Dieser Artikel markiert den Auftakt zu einer Serie von Themen rund um die kommende Version von PostgreSQL® 10.
Einleitung
Heute muss nicht mehr argumentiert werden, warum zentrales Logging sinnvoll oder sogar notwendig ist. Die meisten mittelständischen Unternehmen haben mittlerweile ein zentrales Logging oder führen dieses gerade ein.
Wenn die Infrastruktur einmal geschaffen ist, gilt es diese sinnvoll und effizient zu nutzen! Gerade als Infrastrukturbetreiber oder Dienstleister geht es darum verschiedene Akteure, mit verschiedenen Anforderungen, bestmöglich zu unterstützen. So sollte z.B. die Entwicklungsabteilung kontinuierlich Zugriff auf alle Logs ihrer Testsysteme haben. Aus der Produktion werden aber vielleicht nur alle Fehlermeldungen in Echtzeit benötigt, auf Freigabe jedoch auch mehr.
Solche Modelle lassen sich mit graylog® oder Kibana® leicht umsetzen und testen. Die Klassifizierung und Auswertung mag im Testbetrieb oder in kleinen Umgebungen auch mit den PostgreSQL®-Standardeinstellungen gut und performant funktionieren. Werden jedoch sehr viele Datenbanken betrieben oder die Logs lange aufgehoben, kann die Nutzung schnell schwierig werden.
Problemstellung
Die Logeinträge sind zentral erfasst und können prinzipiell verwendet werden. In der Praxis ist es jedoch schwierig bis unmöglich alle relevanten Informationen zeitnah zu extrahieren. Die Suche nach bestimmten Einträgen erfordert Volltextsuchen mit Wildcards, dies ist bei großen Datenbeständen nicht mehr praktikabel ist.
Möchte man beispielsweise bestimmten Gruppen ausschließlich Zugriff auf Logs geben, die bestimmten fachlichen Kriterien entsprechen, z.B. Datenbankname, error_severity oder der gleichen, muss dies über Volltextsuche und fehleranfällige Filter realisiert werden.
Möchte ein DBA z.B. alle Meldungen eines bestimmten Users, einer bestimmten Query oder einer Session sehen, wird hierzu eine besonders aufwendige Indizierung für Wildcard-Suchen benötigt. Alternativ sind solche Anfragen sehr langsam und können nicht sofort beantwortet werden.
| Ausgangspunkt: | Es wurde bereits ein Zentrales Logging eingeführt, z.B. ELK-Stack oder graylog®. |
| Ziel: | Wir möchten die PostgreSQL®-Logmeldungen semantisch erfassen und dadurch effizient: klassifizieren, gruppieren und auswerten. |
Alternative
Die Alternative besteht nun darin, die Logmeldungen semantisch zu erfassen und die einzelnen Felder in einer entsprechenden Datenstruktur abzulegen.
Wird das normale stderr-Log verwendet, gestaltet sich das Parsen als schwierig bis unmöglich, da die einzelnen Felder hier nicht zu erkennen sind. PostgreSQL® bietet jedoch auch die Möglichkeit Logmeldungen im CSV-Format zu produzieren (csvlog). Hiermit werden alle Felder Komma separiert ausgegeben.
Exkurs: Die Idee ist nicht neu. Seit Langem laden einige DBAs ihre Logs direkt wieder in eine PostgreSQL®-Tabelle. So können die Logs mit SQL und allen bekannten Boardmitteln durchsuchen und bearbeiten. Die DBAs sind meist sehr zufrieden mit diesem Konstrukt, es stellt jedoch eine Insellösung dar. Beispieltabelle PostgreSQL® 9.5:
CREATE TABLE postgres_log ( log_time timestamp(3) with time zone, user_name text, database_name text, process_id integer, connection_from text, session_id text, session_line_num bigint, command_tag text, session_start_time timestamp with time zone, virtual_transaction_id text, transaction_id bigint, error_severity text, sql_state_code text, message text, detail text, hint text, internal_query text, internal_query_pos integer, context text, query text, query_pos integer, location text, application_name text, PRIMARY KEY (session_id, session_line_num) ); |
Aufbau
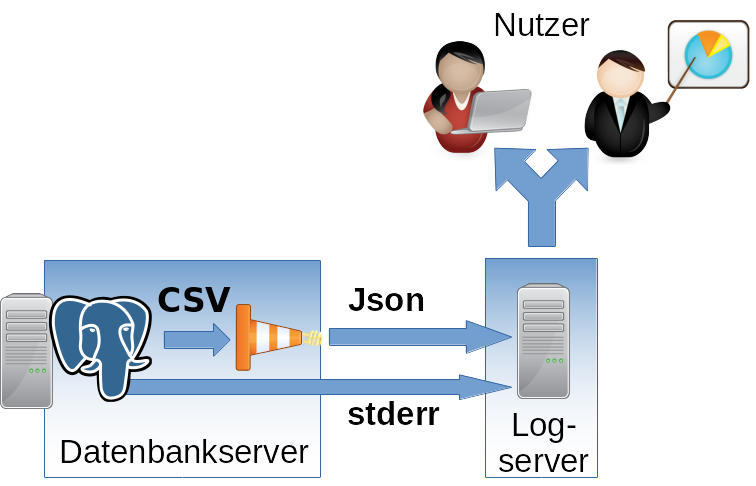
Umsetzung
Das csvlog kann als Grundlage für das effiziente Befüllen eines zentralen Loggingsystems dienen. Um hier die weitere Verarbeitung möglichst einfach zu gestalten und um sich auf kein Loggingsystem festlegen zu müssen, übersetzen wir das Log von CSV nach Json. Im Anschluss kann es dann beliebig eingespeist werden. Im folgenden Beispiel wird TCP verwendet.
Um das Logformat zu ändern müssen in PostgreSQL® folgende Optionen angepasst werden:
#------------------------------------------------------------------------------
# ERROR REPORTING AND LOGGING
#------------------------------------------------------------------------------
# - Where to Log -
log_destination = 'csvlog' # Valid values are combinations of
# stderr, csvlog, syslog, and eventlog,
# depending on platform. csvlog
# requires logging_collector to be on.
# This is used when logging to stderr:
logging_collector = on # Enable capturing of stderr and csvlog
# into log files. Required to be on for
# csvlogs.
# (change requires restart)
# These are only used if logging_collector is on:
log_directory = '/var/log/postgresql' # directory where log files are written,
# can be absolute or relative to PGDATA
Zum Parsen und Übersetzen in Json sowie zum Einliefern ins Loggingsystem verwenden wir logstash® mit folgender Konfiguration als Jinja2-Template:
input {
file {
"path" => "/var/log/postgresql/*.csv"
"sincedb_path" => "/tmp/sincedb_pgsql"
# fix up multiple lines in log output into one entry
codec => multiline {
pattern => "^%{TIMESTAMP_ISO8601}.*"
what => previous
negate => true
}
}
}
# Filter is testet for PostgreSQL® 9.5
filter {
csv {
columns => [ "pg_log_time", "pg_user_name", "pg_database_name",
"pg_process_id", "pg_connection_from", "pg_session_id",
"pg_session_line_num", "pg_command_tag",
"pg_session_start_time", "pg_virtual_transaction_id",
"pg_transaction_id", "pg_error_severity", "pg_sql_state_code",
"pg_sql_message", "pg_detail", "pg_hint", "pg_internal_query",
"pg_internal_query_pos", "pg_context", "pg_query",
"pg_query_pos", "pg_location", "pg_application_name" ]
}
date {
#2014-05-22 17:02:35.069 CDT
match => ["log_time", "YYYY-MM-dd HH:mm:ss.SSS z"]
}
mutate {
add_field => {
"application_name" => "postgres"
}
}
}
output {
tcp {
host => "{{ log_server }}"
port => {{ log_port }}
codec => "json_lines"
}
}
Wichtig ist hier, dass der Filter zum Übersetzen der CSV-Felder an die verwendete PostgreSQL®-Hauptversion angepasst wird. Die Felder können sich von Version zu Version unterscheiden. In den meisten Fällen werden neue Felder hinzugefügt.
Auch zu beachten ist, dass logstash® Probleme hat den Timestamp eigenständig zu erkennen. Hier sollte das konkrete Format vorgegeben werden (Zeitzone).
Folgenden Variablen müssen gesetzt werden:
| {{ log_server }} | Logserver, in unserem Fall ein graylog® |
| {{ log_port }} | Port auf dem Logserver |
So konfiguriert, können die Logfiles effizient klassifiziert und durchsucht werden. Auch die Berechtigungen gestalten sich einfacher.
- Berechtigung auf Datenbankebene => pg_database_name
- Severity => pg_error_severity
- Berechtigung für Loggs durch bestimmte Hosts => pg_connection_from
- Berechtigung für Loggs durch bestimmte Anwendungen => pg_application_name
Wichtig: Das normale stderr-Log sollte in jedem Fall noch mit ins zentrale Logging aufgenommen werden. Hier landen zwar nach dem Start keine normalen Betriebsmeldungen von PostgreSQL® mehr, jedoch Fehlerausgaben von beteiligten Prozessen. Hier kann z.B. die stderr-Ausgabe eines fehlgeschlagenen Archivecommands gefunden werden. Dieses Informationen sind für die Administration essentiell.
Wir unterstützen bereits zahlreiche Kunden dabei das beschriebene Verfahren in Produktion zu betreiben. Falls Sie Fragen zu diesem Thema haben oder Unterstützung benötigen, dann können Sie sich selbstverständlich gern an unser PostgreSQL® Competence Center wenden.
Dieser Artikel wurde ursprünglich von Alexander Sosna verfasst.
Das Repository für Debian- und Ubuntu-Pakete für PostgreSQL® auf apt.postgresql.org wurde um eine weitere Prozessor-Architektur erweitert. Ab sofort stehen auch fertige Binär-Pakete für ppc64el, die little endian-Version der IBM POWER-Architektur, zur Verfügung. Neben amd64 (64-bit x86 Intel) und i386 (32-bit x86 Intel) ist dies die nun dritte unterstützte Variante.
Das heutige Release der neuen PostgreSQL®-Version 9.6 ist bereits im Repository enthalten.
Genau wie auf den bisherigen Architekturen werden alle Pakete für alle PostgreSQL®-Versionen unterstützt, momentan sind dies alle Versionen von 9.1 bis 9.6. Mit nur wenigen Ausnahmen sind alle bisher enthaltenen Pakete nun auch für ppc64el kompiliert worden. [1]
Unterstützt werden die Debian-Versionen 8 (jessie) und unstable (sid), und die Ubuntu-Versionen 14.04 (trusty) und 16.04 (xenial).
Die Arbeiten an diesem Projekt wurden von credativ gemeinsam mit 2ndQuadrant und IBM Italien durchgeführt. Der ppc64el-Buildhost wird vom IBM Power Systems Linux Center in Montpellier bereit gestellt.
Für unsere Support-Kunden unterstützt die credativ natürlich auch den PostgreSQL®-Betrieb auf POWER. Bei Fragen stehen wir gerne zur Verfügung, sprechen Sie uns an!
[1] plv8 ist nicht verfügbar; pg-partman ist noch nicht für 9.6 verfügbar; psqlodbc und libpqtypes sind auf trusty nicht verfügbar.
Mit PostgreSQL® 9.6 wird der bekannte View pg_stat_activity um zwei Spalten erweitert: wait_event und wait_event_type. Die alte Spalte waiting fällt dafür weg.
Hintergrund
PostgreSQL® unterscheidet intern zwischen zwei Lock-Typen: Heavyweight-Locks und Lightweight-Locks (LWLocks). Je nach zu erwartender Dauer des Locks kommt entweder die eine oder die andere Variante zum Einsatz.
Zu Heavyweight-Locks zählen Locks, die sich auf Datenbankobjekte beziehen. Sie werden verwendet, um auf SQL-Ebene gleichzeitige, konfligierende Aktionen gegeneinander abzusichern. So darf beispielsweise eine Tabelle erst gelöscht werden, sobald es keine Transaktionen mehr gibt, die diese verwenden, oder zwei Transaktionen, die ein UPDATE der gleichen Zeile versuchen, müssen auf einander warten. Diese Locks können im View pg_locks eingesehen werden. In Verbindung mit dem View pg_stat_activity kann so herausgefunden werden, wer auf wen wartet. Eine Beispielquery befindet sich im PostgreSQL®-Wiki.
Lightweight-Locks hingegen werden für kurze Locking-Operationen verwendet. Dies beinhaltet zum Beispiel das Füllen der WAL-Buffer (WALBufMappingLock) oder auch das Warten auf das Herausschreiben selbiger (WALWriteLock). Ein weiteres Beispiel ist der Zugriff auf Pages innerhalb des Shared Memory Segments (buffer_content), wie er beim Lesen oder Schreiben von Daten auftritt. Problematisch ist nun, dass Lightweight-Locks, im Gegensatz zu Heavyweight-Locks, nicht in pg_locks oder einem anderen System-View erfasst sind. Um bei Performanceanalysen zu erkennen, auf welchen LWLock gerade gewartet wurde, musste bis dato zu externen Tools Tools wie perf gegriffen werden.
Funktion
Zusätzlich zu den bereits bekannten Statusinformationen wie pid, query_start oder auch query, halten mit PostgreSQL® 9.6 zwei neue Spalten Einzug in pg_stat_activity. Die Spalten wait_event und wait_event_type enthalten detaillierte Locking Informationen. Sie ersetzt zeitgleich die Spalte waiting, die früher je nach Status lediglich TRUE oder FALSE beinhaltete und damit signalisierte, dass auf einen Heavyweight-Lock gewartet wurde.
Die neue Spalte gibt wait_event nun auch Aufschluss darüber ob und auf welche Art von LWLocks gewartet wird. Muss ein Backend auf einen Lock warten, enthält die Spalte wait_event den Namen des Events, andernfalls NULL.
Beispiel
Zur Veranschaulichung des neuen Features bemühen wir das PostgreSQL®-eigene Benchmark-Tool pgbench.
Zunächst erstellen wir uns eine neue Testdatenbank und befüllen diese mit Testdaten.
$ createdb pgbench
$ pgbench -i -s 50 pgbench
Nachdem unsere Datenbank erstellt und gefüllt ist, starten wir pgbench mit 20 gleichzeitigen Verbindungen in 2 Threads:
$ pgbench -c 20 -j 2 -T 300 pgbench
Schauen wir uns zeitgleich den View pg_stat_activity an, so stellen wir fest, dass viele der Backends auf Locks vom Typ LWLockNamed warten, einen WALWriteLock. Sie warten also darauf, dass die geschriebenen WAL-Records auf die Festplatte geschrieben werden:
psql=# select pid, wait_event, wait_event_type, state, query from pg_stat_activity WHERE wait_event is not NULL;
pid | wait_event | wait_event_type | state | query
-------+---------------+-----------------+--------+------------------------------------------------------------------------
25632 | transactionid | Lock | active | UPDATE pgbench_branches SET bbalance = bbalance + -3359 WHERE bid = 4;
25633 | WALWriteLock | LWLockNamed | active | END;
25635 | WALWriteLock | LWLockNamed | active | END;
25636 | transactionid | Lock | active | UPDATE pgbench_branches SET bbalance = bbalance + 1807 WHERE bid = 1;
25638 | transactionid | Lock | active | UPDATE pgbench_branches SET bbalance = bbalance + -603 WHERE bid = 12;
25639 | transactionid | Lock | active | UPDATE pgbench_tellers SET tbalance = tbalance + 2794 WHERE tid = 169;
25640 | WALWriteLock | LWLockNamed | active | END;
25642 | WALWriteLock | LWLockNamed | active | END;
25643 | transactionid | Lock | active | UPDATE pgbench_branches SET bbalance = bbalance + -4985 WHERE bid = 5;
25644 | WALWriteLock | LWLockNamed | active | END;
25645 | WALWriteLock | LWLockNamed | active | END;
25646 | WALWriteLock | LWLockNamed | active | END;
25648 | transactionid | Lock | active | UPDATE pgbench_branches SET bbalance = bbalance + 2700 WHERE bid = 1;
25649 | transactionid | Lock | active | UPDATE pgbench_branches SET bbalance = bbalance + -456 WHERE bid = 5;
25650 | transactionid | Lock | active | UPDATE pgbench_branches SET bbalance = bbalance + -617 WHERE bid = 17;
25651 | WALWriteLock | LWLockNamed | active | END;
(16 rows)
Ändern wir nun beispielsweise die Einstellung synchronous_commit auf off, so stellen wir fest, dass genau diese WALWriteLocks nicht mehr Auftreten. Die Backends warten nicht mehr darauf, dass ihre Daten auf die Festplatte geschrieben werden:
psql=# SELECT pid, wait_event, wait_event_type, state, query from pg_stat_activity WHERE wait_event is not NULL;
pid | wait_event | wait_event_type | state | query
-------+---------------+-----------------+--------+-------------------------------------------------------------------------
26201 | transactionid | Lock | active | UPDATE pgbench_branches SET bbalance = bbalance + -1065 WHERE bid = 7;
26203 | transactionid | Lock | active | UPDATE pgbench_tellers SET tbalance = tbalance + -3052 WHERE tid = 173;
26204 | transactionid | Lock | active | UPDATE pgbench_branches SET bbalance = bbalance + -2375 WHERE bid = 5;
(3 rows)
Fazit
Das oben gezeigte Beispiel veranschaulicht, wie detailliert nun Einsicht in das Locking der Datenbank genommen werden kann. Besonders für Analysen der Datenbankperformance bietet dies entscheidende Vorteile gegenüber den bisherigen Möglichkeiten.
Details
Detailliertere Informationen zu den verwendeten Lock-Typen, deren Bedeutung und Verwendung hat die PostgreSQL®-Dokumentation. Wem dies nicht ausreicht, dem bietet die Datei src/backend/storage/lmgr/README im Sourcecode weitere Informationen über Locking in PostgreSQL®.
Bei Fragen steht Ihnen außerdem unser PostgreSQL® Competence Center zu Verfügung.
PostgreSQL® 9.6 befindet sich aktuell in der Beta Phase. Ein Release- Datum steht aktuell noch nicht fest. Wer die neue Version bereits im Vorfeld testen möchte, findet den aktuellen Tarball unter www.postgresql.org. Für Debian und Ubuntu stehen auf apt.postgresql.org bereits vorgefertigte Pakete bereit.
Im Zuge von PostgreSQL® 9.6 werden, wie in jedem Major-Release, einige neue Features eingeführt. Eines davon ist der „Idle In Transaction“ Timeout.
Funktion
Sobald ein Datenbankverbindung mit offener Transaktion länger als idle_in_transaction_timeout inaktiv ist, wird die Verbindung terminiert.
Hintergrund
Backends, die sich in einer Transaktion befinden, allerdings keine Aktivität aufweisen, befinden sich im Status „Idle In Transaction“. Hält dieser Zustand nur kurz an, ist dies kein Problem. Befindet sich ein Backend allerdings über einen längeren Zeitraum in diesem Zustand, führt dies dazu, dass Autovacuum potentiell nicht mehr gebrauchte Tupelversionen nicht als gelöscht markieren kann. Die von ihnen belegte Platz kann somit nicht wiederverwendet werden. Dies führt zu aufgeblähten Tabellen und einer Degradierung der Datenbankperformance.
Ist das Problem nicht innerhalb der Anwendung zu beheben, wurde bisher oft zu einer Lösung via Cronjobs gegriffen, die die oben genannte Funktionalität bereitstellen.
Beispiel
Zunächst muss der Parameter idle_in_transaction_session_timeout auf einen Wert größer 0 gesetzt werden, hier im Beispiel ‚5s‘ für 5 Sekunden:
psql=# ALTER SYSTEM SET idle_in_transaction_session_timeout TO '5s';
psql=# SELECT pg_reload_conf();
Starten wir nun eine Transaktion, ohne einen Befehl abzusetzen, wird diese nach 5 Sekunden automatisch terminiert. Versuchen wir dennoch eine Anfrage an den Server zu schicken bekommen wir die Meldung, dass unsere Verbindung unterbrochen wurde:
psql=# BEGIN;
BEGIN
psql=# -- 5 Sekunden warten
psql=# SELECT 1;
FATAL: terminating connection due to idle-in-transaction timeout
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
Möchte man erfahren, welche Backends sich aktuell im Status „Idle In Transaction“ befinden, kann man dies mit folgender Abfrage herausfinden:
psql=# SELECT pid, now() - state_change AS inactive_since FROM pg_stat_activity WHERE state = 'idle in transaction';
pid | inactive_since
-------+-----------------
16645 | 00:00:04.400098
(1 row)
PostgreSQL® 9.6 befindet sich aktuell in der Beta Phase. Ein Release- Datum steht aktuell noch nicht fest. Wer die neue Version bereits im Vorfeld testen möchte, findet den aktuellen Tarball unter www.postgresql.org. Für Debian und Ubuntu stehen auf apt.postgresql.org bereits vorgefertigte Pakete bereit.
Ein interessantes Werkzeug zur Qualitätssicherung von C-Compilern ist Csmith, ein Generator zufälliger C-Programme.
Zu schätzen gelernt hatte ich es bei der Entwicklung einer Optimierungsphase für einen C-Compiler. Dieser verfügt über umfangreiche Regressionstests, und die Korrektheit der übersetzten Programme wird auch anhand standardisierter Benchmarks getestet. Letztere hatten z.B. einen Bug in meiner Optimierung aufgedeckt, weil ein in der Benchmark-Sammlung enthaltenes Schachprogramm, das mit dem Compiler übersetzt wurde, beim Spielen gegen sich selbst einen anderen Zug machte als erwartet.
Irgendwann waren diese Mittel jedoch ausgeschöpft und alles war scheinbar abgabefertig. Ich erinnerte mich dann an Csmith, das ich bis zu diesem Punkt eher belächelt hatte. „Kann ja nicht schaden, es mal laufen zu lassen“. Zu meiner Überraschung fand es weitere kritische Bugs in meinem Code, die bei den anderen Tests nicht zu Tage kamen.
Als es beruflich dann wieder Richtung Datenbanken ging, vermisste ich ein solches Werkzeug für die PostgreSQL®-Entwicklung. Ein Jahr und 269 Commits später kann ich nun das erste Release von SQLsmith 1.0 verkünden.
SQLsmith generiert zufällige SQL-Abfragen, wobei alle in der Datenbank vorhandenen Tabellen, Datentypen und Funktionen berücksichtigt werden. Durch die Zufälligkeit sind die Abfragen oft deutlich anders strukturiert als man sie von „Hand“ aufschreiben würde und decken daher viele Randfälle im Optimizer und Executor in PostgreSQL® auf, die sonst nie getestet werden würden.
Bereits während der Entwicklung hat SQLsmith 30 Bugs in PostgreSQL® gefunden, die durch die PostgreSQL®-Community umgehend korrigiert wurden.
Wer Erweiterungen für PostgreSQL® programmiert, oder allgemein an PostgreSQL® entwickelt, hat nun mit SQLsmith ein zusätzliches Debug-Werkzeug zur Verfügung. Aber auch User profitieren von SQLsmith durch die zusätzliche Qualitätssicherung, die nun bei der PostgreSQL®-Entwicklung stattfindet.
Der Quellcode für SQLsmith ist unter GPLv3 auf github zu finden.
Dieser Artikel wurde ursprünglich von Andreas Seltenreich verfasst.
Heute sind aktualisierte Pakete der stabilen Versionen von PostgreSQL® erschienen. Vor allem für Benutzer mit anderen Locale als C oder SQL_ASCII (im besonderen de_DE.UTF-8) ist die neue Version 9.5.2 wichtig. Verwendet man PostgreSQL® 9.5.0 oder 9.5.1 und Indexe auf Spalten mit den Typen character, varchar oder text, so ist generell ein REINDEX nach dem Update auf 9.5.2 angeraten. Binärpakete stehen für gängige RPM-basierte Systeme auf http://yum.postgresql.org bzw. für Debian und Ubuntu auf https://wiki.postgresql.org/wiki/Apt zur Verfügung.
Hintergrund
Mit dem Erscheinen von PostgreSQL® 9.5 wurde eine Optimierung für Sortieroperationen auf Zeichentypen eingeführt. Diese Optimierung nennt sich Abbreviated Keys, die es erlaubt, eine verkürzte Binärform einer Zeichenkette als Sortierschlüssel heranzuziehen. Hierzu wird die Systemroutine strxfrm() verwendet, die einen normalisierten Binärstring der ursprünglichen Zeichenkette zurückliefert. PostgreSQL® verwendet nun die ersten 8 Bytes für den Sortierschlüssel, was diesen Vorgang insbesondere beim Indizieren bzw. Sortieren von sehr großen Datenmengen massiv beschleunigt. Die ersten 8 Bytes stellten sich bei umfangreichen Tests als ausreichend für Stringvergleiche heraus. Tiefergehende Details finden sich im Blogartikel von Peter Geoghegan, den Autor dieser Optimierung. Ein Voraussetzung für die Verwendung und Eignung dieser Methode in PostgreSQL® wie beschrieben, war die in der C-Library ausgewiesene Kompatiblität der Sortierreihenfolge zwischen strcoll() und strxfrm(). Mit anderen Worten, wird das Ergebnis zweier Zeichenketten von strxfrm() mittels strcmp() verglichen, so ist das Ergebnis dasselbe, als würden die Zeichenketten direkt mit strcoll() verglichen. Diese Reihenfolge ist besonders für die Ermittlung der Indexposition für einen BTree-Index relevant.
Leider hat sich herausgestellt, dass Plattformen mit der GNU Libc unter Umständen eine fehlerhafte Implementierung aufweisen, die Inkompatibilitäten zwischen dem Ergebnis von strcoll() und der Kombination von strxfrm()/strcmp() verursachen. Dies führt in aktuellen PostgreSQL® 9.5.0 und 9.5.1 Releases zu gegebenenfalls korrupten Indexen, je nachdem ob das verwendete Locale diese Unterschiede aufweist, oder nicht. Leider kann man nicht sagen, welche der Locales generell davon Probleme verursachen, es gibt jedoch deutliche Hinweise, dass insbesondere das deutsche Locale de_DE.UTF-8 massiv von dieser Problematik betroffen ist.
Daher ist es auf jeden Fall angeraten, entsprechende Indexe in Datenbanken mit anderen Locale als C bzw. SQL_ASCII
neu anzulegen. Hierzu lässt sich das Kommando REINDEX verwenden. Wer wissen möchte, ob er bestimmte BTree-Indexe auf char, varchar oder text Typen verwendet, kann folgende Query anwenden und den REINDEX auf diese beschränken (also das Reindizieren der kompletten Datenbank vermeiden):
SELECT
DISTINCT r.relname, indisprimary AS primary_key, indisunique AS is_unique
FROM
pg_class r
JOIN pg_index i ON i.indexrelid = r.oid
JOIN pg_am am ON am.oid = r.relam
JOIN pg_namespace n ON n.oid = r.relnamespace
JOIN pg_attribute attr ON attr.attnum = ANY(i.indkey)
JOIN pg_type t ON t.oid = attr.atttypid
WHERE r.relkind = 'i'
AND am.amname = 'btree'
AND n.nspname NOT LIKE E'pg\\_%'
AND t.typname IN ('text', 'varchar', 'bpchar');
Die aktuelle Version 9.5.2 deaktiviert zunächst die Optimierung vollständig, bis die genaue Ursache für das Problem identifziert werden konnte. Natürlich stehen wir auch bei der Problemlösung mit dem Supportteam der credativ gerne zur Verfügung.
Mit dem Ende des Support-Zyklus für den Long Term Support für Debian Squeeze endet auch das PostgreSQL®-LTS-Projekt für 8.4, das credativ seit dem offiziellen EOL von PostgreSQL® 8.4 im Juli 2014 betreut hatte.
Die letzte Version „8.4.22lts6“ wurde jetzt kurz vor Ende der Squeeze-LTS-Laufzeit hochgeladen. Sie korrigiert eine Sicherheitslücke im Zusammenhang mit regulären Ausdrücken (CVE-2016-0773). Außerdem wurde eine Änderung aus der Version 9.1.20 zurück portiert, die verhindert, dass bei fehlenden PID-Dateien mehrere Instanzen der Datenbank gleichzeitig laufen.
Neben den Paketen in Debian Squeeze-LTS, stehen die 8.4-LTS-Tarballs auch auf Github zum Download bereit.
Die Debian-Version nach Squeeze – Wheezy – enthält die Version 9.1 von PostgreSQL®, für die der Upstream-Support im September 2016 ausläuft. Für Wheezy-LTS wird credativ dann wieder LTS-Pakete für diese PostgreSQL®-Version erstellen.
Maschinen, die jetzt noch mit Debian Squeeze oder PostgreSQL® 8.4 laufen, sollten dringend auf eine neuere Version aktualisiert werden. Die credativ unterstützt ihre Kunden natürlich gerne bei der Planung und Durchführung von Migrationsprojekten.
PostgreSQL® Version 9.5 ist fertig! Die neue Hauptversion glänzt mit einer Vielzahl an neuen, nützlichen Features, massiven Verbesserungen an der Geschwindigkeit vor allem auf Systemen mit vielen CPU-Kernen, aber auch einigen Änderungen, die sich auf die Kompatibilität älterer Anwendungen auswirken. Im Folgenden findet sich eine Zusammenfassung der wichtigsten Merkmale der neuen Version.
Upsert
Die wohl prominenteste Neuerung findet sich in PostgreSQL® 9.5 in der Erweiterung der INSERT-Syntax um die Möglichkeit, bei Konflikt eine alternative Aktion bezüglich des betroffenen Tupels auszuführen. Dieses Verfahren, umgangssprachlich auch unter der Bezeichnung Upsert bekannt, ist ein von der PostgreSQL®-Community schon sehr lange gewünschtes Feature. Anwendungen mussten bisher entweder die Fehler bei Konflikten selbst behandeln, z.B. bei einem INSERT-Konflikt die Transaktion mit einem UPDATE wiederholen (mit entsprechenden Maßnahmen gegenüber nebenläufigen Transaktionen), oder umständliche Prozeduren verwenden, die die entsprechende Funktionalität kapselten.
An dieser Stelle gab es bereits einen Blogartikel, der sich mit den Möglichkeiten dieser neuen Funktionalität detailliert beschäftigt hat und beispielhaft die Syntax illustriert.
Block Range Indexe
Block Range Index (verkürzt BRIN genannt), waren ebenfalls bereits Thema eines vorangegangenen Artikels.
Zum Verständnis sei hier noch einmal darauf verwiesen, dass PostgreSQL® Daten innerhalb von Tabellen in festen physikalischen Blöcken innerhalb von Dateisegmenten organisiert. Ein solcher Block hat eine feste Größe von jeweils 8KB. Zusammenfassend kann ein Block Range Index so beschrieben werden, dass er keine absoluten Werte und deren Position in der Tabelle indiziert, sondern das Auftreten eines bestimmten Wertebereiches eines Blocks einer Tabelle erfasst. Mit anderen Worten, ein Eintrag in einem Block Range Index speichert Minimal- und Maximalwerte für jeden Tabellenblock. Daher ist ein BRIN-Index sehr kompakt und kann im speziellen Fall von geclusterten Daten einer Tabelle massive Vorteile bringen. Für Details sei an dieser Stelle nochmals auf den Blogartikel zum Thema verwiesen.
Row Level Security (RLS)
Für bestimmte Einsatzzwecke ergibt sich manchmal der Bedarf, Zeilen einer Tabelle beispielsweise vor spezifischen Datenbankrollen zu verstecken. Früher war es für diese Szenarien gebräuchlich, entsprechende Views anzulegen, die die Zeilen für diese Datenbankrollen entsprechend ausblendeten, was allerdings erst mit sogenannten SECURITY BARRIER-Views ab PostgreSQL® 9.2 wirklich sicher ist. Ferner ist dieses Verfahren ein wenig umständlich, da entsprechende Views gepflegt werden müssen, die durch die SECURITY BARRIER Direktive unter Umständen auch langsamer werden. Der Blogartikel RLS bietet einen detaillierten Überblick über dieses neue Feature, das weit über die bisherigen Möglichkeiten hinausgeht. RLS ist hierbei transparent und vermeidet das Erstellen umständlicher Zugriffspfade wie Views oder Funktionen.
Konfigurationsparameter checkpoint_segments
Der für die Gesamtperformance immanent wichtige Konfigurationsparameter checkpoint_segments wird durch eine bessere und deutlich angenehmere Infrastruktur ersetzt. Mit checkpoint_segments war es immer schwierig, eine bestimmte Größe des Transaktionslogs in PostgreSQL® zu konfigurieren. Zwar gab es die einschlägige Formel ((2 + checkpoint_completion_target) * checkpoint_segments) + 1 für die Anzahl vorzuhaltender Transaktionslogsegmente. Für die Anwender war es jedoch immer ungewöhnlich hier im Kontext von Segmentanzahl zu konfigurieren, anstatt einfach minimale und maximale Größen (beispielsweise in Megabyte) vorzugeben. Die neuen Konfigurationsparameter min_wal_size und max_wal_size ersetzen nun den Konfigurationsparameter und erlauben das Festsetzen minimaler und maximaler Größen des Transaktionslogs. max_wal_size ist jedoch (genau wie vormals checkpoint_segments) keine feste Grenze, sondern ein Softlimit, das bei Lastspitzen durchaus diese Grenzen überschreiten kann. Die Standardeinstellungen für min_wal_size und max_wal_size sind 80MB bzw. 1GB. Dabei werden die Transaktionslogsegmente nur bei Bedarf allokiert, bis max_wal_size erreicht ist. Bleibt die generierte Transaktionsloggröße unter der konfigurierten min_wal_size werden auch keine weiteren Transaktionslogsegmente verwendet.
Für den Umstieg der gewohnten Einstellungen von checkpoint_segments kann folgende Formel verwendet werden:
max_wal_size = (3 * checkpoint_segments) * 16MB
Zu beachten ist allerdings, dass die Standardeinstellung in PostgreSQL® 9.5 schon deutlich höher gewählt sind als bisher.
Index-Only Scans für GiST-Indexe
PostgreSQL® muss in der Regel jeden Indextreffer evaluieren, ob dieser für die aktuelle Transaktion noch relevant ist. Unter bestimmten Voraussetzungen kann man sich jedoch das zusätzliche (und unter Umständen teure) Lesen der Tabellenzeile sparen. Bisher war dies BTree-Indexe vorbehalten, mit PostgreSQL® 9.5 ist diese Zugriffsmethode nun auch für GiST-basierte Indextypen möglich. Ein Beispiel hierfür ist das contrib-Modul btree_gist, dass einige Anwendungsmöglichkeiten demonstriert.
Verbesserte Skalierbarkeit
Wie bei fast jedem Release bietet auch die neue Version einige Verbesserungen hinsichtlich der vertikalen Skalierbarkeit. So wurde unter anderem der Zugriff auf die LWLock Infrastruktur verbessert, indem das Anfordern derartiger Sperren nun über atomare Zugriffspfade realisiert wird, anstatt hierfür ebenfalls wiederum eine exklusive Sperre anzufordern. Da LWLocks in erster Linie für den Zugriff auf Datenstrukturen im Shared Memory verwendet werden, erhöht dies die Skalierbarkeit insbesondere auf Maschinen mit sehr vielen CPU-Kernen. Auch Seitenersetzungen im PostgreSQL®-eigenen Shared Buffer sind nun aufgrund der Verwendung von Spinlocks und verbessertem Lockingalgorithmus deutlich granularer. Desweiteren wurde für bestimmte Datentypen (text und numeric) die Geschwindigkeit für Sortieroperationen verbessert. Anstatt gleich die volle Länge des Sortierschlüssels zu benutzen, wird zunächst eine abgekürzte, feste Schlüssellänge verwendet, um Unterschiede schneller festzustellen. Daneben gibt es noch viele weitere, kleinere Verbesserungen.
Inkompatiblitäten
Mit Erscheinen der Version 9.5 werden in PostgreSQL® auch Inkompatibilitäten eingeführt, die alte Funktionalität ersetzt oder wegrationalisiert. Die wichtigsten Änderungen im Überblick:
Änderung von Operator-Präzedenzen
Die Präzedenz von Operatoren definiert, welche Priorität diesen beim Evaluieren innerhalb von Ausdrücken eingeräumt bekommen. Ein gutes Beispiel ist immer der Vergleich von Subtraktion/Addition und Multiplikation. Der Multiplikation muss eine höhere Präzedenz eingeräumt werden, da mathematisch immer Punkt-vor-Strich eingehalten werden muss. So ist es auch in PostgreSQL®, der *-Operator ist in der Präzedenz eine Stufe höher definiert als die +– bzw. --Operatoren.
Die Operatoren <=, >= und <> besitzen nun dieselbe Präzedenz wie die Operatoren <, > und =. Dies ist eine Änderung gegenüber den Vorgängerversionen von PostgreSQL® 9.5, in denen letztere in der Präzedenz eine Stufe höher eingeordnet waren.
Außerdem wurde die Präzedenz der IS-Operatoren herabgesetzt, diese befindet sich jetzt unterhalb der genannten Operatoren. Die Konsequenz sollte relativ überschaubar sein, allerdings gibt es dennoch SQL-Ausdrücke, die in ihrer Konstruktion aufgrund der geänderten Präzedenzen nun unterschiedliche Ergebnisse zur Folge haben. Ein Beispiel wäre folgender, zugegebenermaßen sehr konstruierter Fall. In PostgreSQL® 9.4:
SELECT f1 <= f2 || f3 FROM (VALUES('abc', 'ab', 'c')) AS t(f1, f2, f3);
?column?
----------
falsec
(1 row)
Das falsec ist ein Ergebnis der Konvertierung des boolschen Werts in text und der anschließenden Text-Konkatenation. Durch die angesprochenen Änderungen ergibt sich jedoch in PostgreSQL® 9.5 folgendes Bild:
#= SELECT f1 <= f2 || f3 FROM (VALUES('abc', 'ab', 'c')) AS t(f1, f2, f3);
?column?
----------
t
(1 row)
Hier erkennt man auch die Gründe für die Änderungen, das Ergebnis des letzten Ausdrucks ist korrekt. Solche Konstrukte waren in der Vergangenheit schon immer problematisch, so dass die Mehrzahl der Anwendungen explizite Klammern benutzt haben, um korrekte Ergebnisse zu erzielen. Wer sich bei der Evaluierung von PostgreSQL® 9.5 in seiner Umgebung nicht sicher ist, nicht doch irgendwelche Probleme zu bekommen, kann in PostgreSQL® 9.5 den Konfigurationsparameter operator_precedence_warning benutzen, der Hinweise auf entsprechende Fälle gibt:
SET operator_precedence_warning TO on;
SELECT f1 <= f2 || f3 FROM (VALUES('abc', 'ab', 'c')) AS t(f1, f2, f3);
WARNING: operator precedence change: <= is now lower precedence than ||
LINE 1: SELECT f1 <= f2 || f3 FROM (VALUES('abc', 'ab', 'c')) AS t(f...
^
?column?
----------
t
(1 row)
Änderung in pg_ctl
Bis einschließlich PostgreSQL® 9.4 verwendete pg_ctl den Shutdownmodus smartstandardmässig, falls nicht explizit abweichend per -m-Kommandozeilenschalter definiert. Mit PostgreSQL® 9.5 ändert sich der Standardmodus nun zu fast, was ein sofortiges Zurückrollen aller laufenden Transaktion und Beenden offener Datenbankverbindungen beinhaltet. Dies steht im Kontrast zum smart-Shutdownmodus, was solange mit dem Stoppen der PostgreSQL®-Instanz wartete, bis alle offenen Transaktionen und Datenbankverbindungen explizit beendet wurden.
PL/pgSQL mit geänderten Typcasts
PL/pgSQL verwendete seither intern immer die Umwandlung über text-Typen für die Datentypkonvertierung. Mit PostgreSQL® 9.5 ändert sich das Verhalten, indem PL/pgSQL nun direkt die Typecasts für den jeweiligen Zieltyp verwendet, falls vorhanden. Dies ändert das Verhalten von PL/pgSQL in bestimmten Fällen, wie die folgenden Beispiele illustrieren. Ein Fall ist die Zuweisung von numeric-Werten an integer-Typen, in PostgreSQL® 9.4 ergab sich bisher folgende Situation:
DO LANGUAGE plpgSQL
$$
DECLARE
i integer;
n numeric;
BEGIN
n := 1.6;
i := n;
RAISE NOTICE 'i = %', i;
END;
$$;
ERROR: invalid input syntax for integer: "1.6"
CONTEXT: PL/pgSQL function inline_code_block line 1 at assignment
Die Konvertierung ist nicht möglich, da der Umweg über die Text-I/O Routinen wiederum den Wert 1.6 an die integer-Variable i übergibt. Mit der Verwendung über die integrierten Typcast-Funktionen ändert sich das Verhalten in PostgreSQL® 9.5:
NOTICE: i = 2
Das Runden entspricht dem Verhalten von numeric-nach-integer-Umwandlungen aus der SQL-Welt, wenn die Typcastroutinen des entsprechenden Zieltyps direkt verwendet werden (int4() ist die für den Cast von numeric auf integer verwendete Routine), ohne den zusätzlichen Schritt über text:
SELECT int4(1.6);
int4
------
2
(1 row)
Eine weitere Auswirkung dieser Änderung ist die Repräsentation von boolean, die sich bei der Konvertierung direkt in einen text-Typ von t/fauf true/false ändert:
DO LANGUAGE plpgSQL
$$
DECLARE
b boolean := TRUE;
t text;
BEGIN
t := b;
RAISE NOTICE 't value = %', t;
END;
$$;
NOTICE: t value = t
Das Ergebnis in PostgreSQL® 9.5 ist dagegen:
NOTICE: t value = true
Anwendungen, die sich in irgendeiner Form auf das alte Verhalten verlassen, sollten sorgfältig auf entsprechende Auswirkungen überprüft werden.
Wegfall des Parameters ssl_renegotiation_limit
Zwar akzeptiert PostgreSQL® nach wie vor die pure Existenz des Parameters, allerdings zeigt er in PostgreSQL® 9.5 keine Wirkung mehr, bzw. muss zwingend auf „0“ stehen.
Zusammenfassung
Mit Erscheinen der Version 9.5 liefert das Datenbanksystem PostgreSQL® wieder eine Fülle von Neuerungen und verspricht insbesondere auf Systemen mit vielen CPU-Kernen deutliche Geschwindigkeitssteigerungen. Selbstverständlich stehen ebenfalls fertige Pakete für alle gängigen RPM-basierten Linuxdistributionen auf yum.postgresql.org sowie für Debian und Ubuntu auf apt.postgresql.org bereit. Das Supportteam der credativ GmbH unterstützt Sie gerne bei der Planung, Einsatz oder Migration der neuen PostgreSQL® Version.
Dieser Artikel wurde initial von Bernd Helmle verfasst.
BRIN ist ein in PostgreSQL® 9.5 neu eingeführter Indextyp, der Name steht für Block Range INdex.
Was ist ein Block Range Index?
Die meisten Indexe werden als Baumstruktur realisiert mit deren Hilfe gesuchte Einträge sehr schnell gefunden werden können. Der Aufwand für Suchanfragen in derartig organisierten Indexstrukturen beträgt in der Regel O(log(Anzahl der Einträge)). Ein solcher Baum skaliert mit wachsender Datenmengen, bezogen auf die Abfragezeit folglich logarithmisch. Es spielt für das Auffinden eines bestimmten Eintrags keine große Rolle, ob eine Tabelle 100.000 oder 100.000.000 Zeilen enthält ( log(100.000) ≈ 11,5 | log(100.000.000) ≈ 18,4). Der Speicherbedarf des Baumes wächst jedoch linear mit den Daten, was dazu führt, dass Indexe sehr groß und entsprechend „unhandlich“ werden. Sollen bei einer Tabelle mehr als eine Spalte indiziert werden kann das schnell dazu führen, dass die Indexe ein vielfaches des Speicherplatz der Daten selbst benötigen. Doch auch der Verzicht auf weitere Indexe ist bei großen Datenmengen nicht praktikabel, da beim sequentiellem Zugriff im Zweifel sämtliche Daten gelesen werden müssen.
BRIN Indexe schaffen an dieser Stelle sehr attraktive Einsatzmöglichkeiten. Wie der Name vermuten lässt, werden nicht sämtliche Einträge einzeln im Index aufgeführt, sondern ganze Blöcke. Da ein Block nicht durch einen einzelnen Wert dargestellt werden kann, wird für jeden Block ein Minimal- und Maximalwert abgelegt. Verwendet nun eine Abfrage eine indizierte Spalte muss nicht der gesamte Datenbestand durchsucht werden, sondern nur die Blöcke in denen der gesuchte Wert überhaupt enthalten sein kann.
Einschränkungen
Hier offenbart sich allerdings auch gleichzeitig ein Nachteil dieses Indextyps. Sind die Daten völlig zufällig verteilt, kann es nötig sein, sehr viele Blöcke zu durchsuchen und der Geschwindigkeitsvorteil fällt nur gering aus. Sind die Daten jedoch natürlich sortiert, z.B. Rechnungsnummer oder Bestelldatum in einer Bestelltabelle, oder bilden natürliche Gruppen mit gleichen bzw. ähnlichen Werten, kann das volle Potenzial genutzt werden. Abfragen mit einfachen Vergleichsoperationen werden je nach Datenstruktur und Blockgröße eher weniger von den Vorteilen eines BRIN-Index profitieren. Bereichsabfragen auf günstig verteilten oder gar sortierten Datenbeständen werden im Vergleich zu herkömmlichen sequentiellen Abfragestrategien massiv beschleunigt.
Klein, kleiner, BRIN
Der Hauptvorteil ist jedoch der Speicherverbrauch, so ist ein BRIN z.T. um den Faktor 10.000 kleiner als ein entsprechender Btree. Nachfolgend ein Beispiel von zwei Indexen auf der gleichen Spalte vom Typ timestamp einer 7300 MB großen Tabelle. Zuerst ein Btree- und anschließend der BRIN-Index, der Größenunterschied beträgt etwa Faktor 7000:
# \di+
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------------+-------+----------+-----------+---------+-------------
public | brin_test_time_btree | index | postgres | brin_test | 2142 MB |
public | brin_test_time_brin | index | postgres | brin_test | 288 kB |
Blockgröße
Die Blockgröße kann an die zugrunde liegenden Daten angepasst werden. Bei natürlich sortierten Spalten ist die genaue Blockgröße nicht ganz unkritisch. Hier sind größere Blöcke und damit ein noch kleinerer Index je nach Abfragen von Vorteil. Gibt es im Datenbestand jedoch häufig Ausreißer oder sind die Einträge nicht natürlich sortiert, kann die Wahl einer kleineren Blockgröße die Performance stark verbessern. Beim Anlegen des Index kann die Anzahl an indizierten Tabellenblöcken pro BRIN-Block angegeben werden. Der Vorgabewert ist 128, bei der Standardpagegröße von 8 kB ergibt sich eine indizierte Tabellenblockgröße von 1 MB. Nachfolgend Beispiele für Indexe zwischen 8 Pages (64 kB) und 2048 Pages (16 MB) großen Blöcken:
# \di+
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+--------------------------+-------+----------+-----------+---------+-------------
public | brin_test_time_btree | index | postgres | brin_test | 2142 MB |
public | brin_test_time_brin_8 | index | postgres | brin_test | 3936 kB |
public | brin_test_time_brin_32 | index | postgres | brin_test | 1016 kB |
public | brin_test_time_brin_128 | index | postgres | brin_test | 288 kB | Standard
public | brin_test_time_brin_256 | index | postgres | brin_test | 160 kB |
public | brin_test_time_brin_512 | index | postgres | brin_test | 104 kB |
public | brin_test_time_brin_1024 | index | postgres | brin_test | 72 kB |
public | brin_test_time_brin_2048 | index | postgres | brin_test | 56 kB |
Abfrageperformance
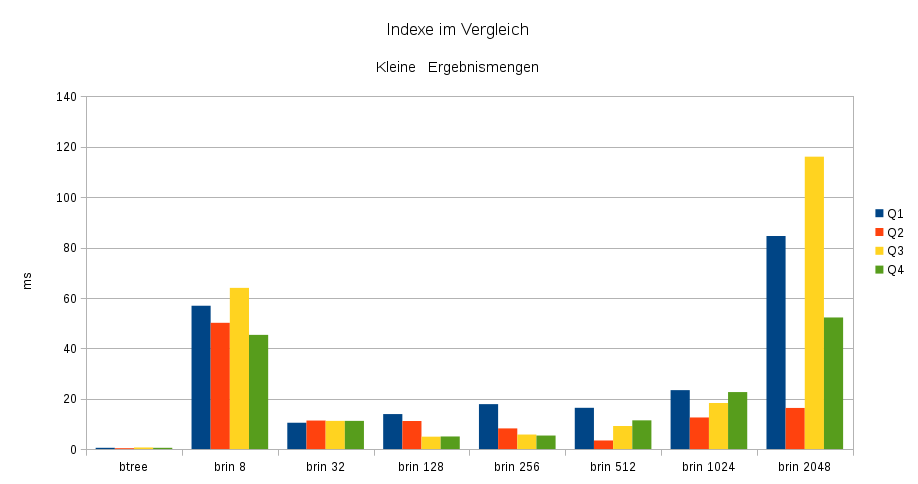
Die nachfolgenden Diagramme zeigen die Ausführungszeiten von fünf SQL-Abfragen und deren Nutzung der verschiedenen Indexe. Die Abfragen Q1 bis Q4 liefern nur kleine Ergebnismengen zurück. Hier zeigt sich die Effektivität des Btree-Indexes sowie der Overhead durch die kleine Blockgröße beim 8-Page-BRIN. Mit steigender Blockgröße sinkt dieser Overhead, doch die Menge an zu durchsuchenden und durch nur ein Min/Max-Paar repräsentierten Daten steigt. Dieser negative Effekt lässt sich an den Indexen mit Blockgröße ab 1024 Pages erkennen. Die von PostgreSQL® verwendete Standardgröße von 128 Pages pro Block ist bei den hier verwendeten Testdaten ein sehr guter Wert, auch wenn z.B. Q2 von einer etwas höheren Blockgröße profitieren würde. Je nach Abfrage und Daten, kann die sinnvollste Blockgröße natürlich variieren.
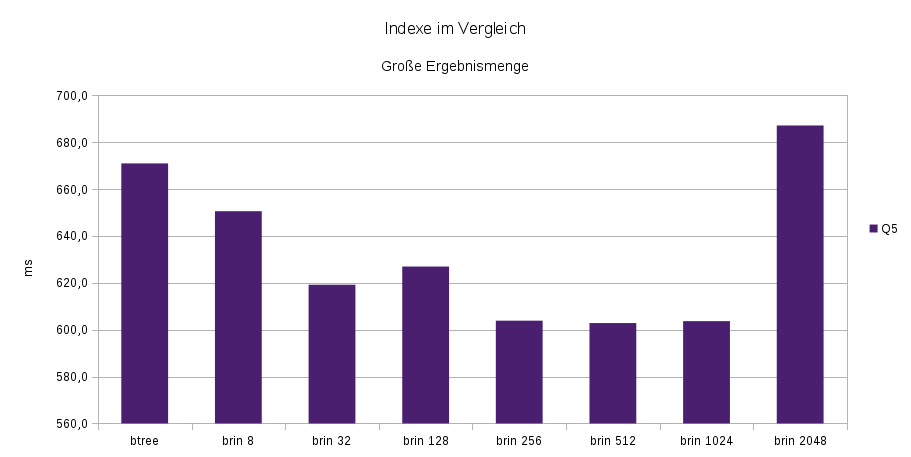
Abfrage Q5 liefert wesentlich mehr Ergebnisse zurück, wodurch das Auffinden der einzelnen Ergebnisse weit weniger die Gesamtzeit beeinflusst. Die Wahl des Indexes spielt hier eine untergeordnete Rolle. Durch die einfachere Möglichkeit ganze Blöcke zurückzuliefern haben Block Range Indexe hier einen Vorteil.
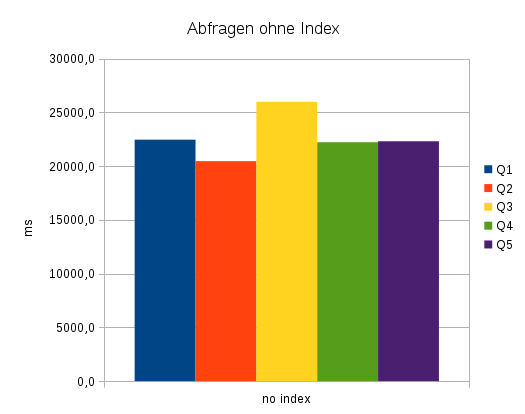
Um keine logarithmische Skala verwenden zu müssen, sind die Ausführungen ohne Indexnutzung in einem zusätzlichen Diagramm dargestellt. Die Ausführungszeiten liegen hier alle im Bereich von 20 s bis 26 s.
Wartung
Block Range Indexe werden nicht automatisch aktualisiert und die Minimal- und Maximalangaben pro Spalte sind nicht zwingend genau, sondern verstehen sich als obere und untere Schranken. Wird eine Tabelle ständig erweitert (INSERT) verschlechtert dies die Qualität des Index nicht. Werden jedoch die vorhandenen Daten Umstrukturiert oder geändert (UPDATE, DELETE), kann es nötig werden einen BRIN-Index neu zu erzeugen. Ob PostgreSQL® hier um einen automatischen Mechanismus erweitert wird, ist noch nicht abschließend geklärt.
Fazit / tl;dnr
Die Verwendung von BRIN ist nicht überall sinnvoll, bei der Analyse sehr großer Datenbestände, die in irgendeiner Form gruppiert oder sortiert sind, spielen Block Range Indexe jedoch ihre Vorteile aus. Durch die stetig wachsende Datenmengen ergeben sich hier viele spannende Anwendungsfälle. Beim gezielten Einsatz von Block Range Indexen unterstützt unser PostgreSQL® Competence Center Sie natürlich genauso gerne wie bei allen anderen Themen und Problemstellungen rund um PostgreSQL®.
Anhang
Wenn Sie bereits eine Vorabversion von PostgreSQL® 9.5 testen und 10 GB freien Speicherplatz haben, können Sie die oben gezeigten Beispiele leicht selbst nachstellen. Für eigene Experimente sind Tabellen- und Indexdefinitionen sowie die verwendeten Abfragen angehängt.
-- Tabelle
CREATE TABLE brin_test AS
SELECT
series AS id,
md5(series::TEXT) AS value,
'2015-10-31 13:37:00.313370+01'::TIMESTAMP + (series::TEXT || ' Minute')::INTERVAL AS time
FROM
generate_series(0,100000000) AS series;
-- Indexe
CREATE INDEX brin_test_time_btree ON brin_test USING btree (time);
CREATE INDEX brin_test_time_brin_8 ON brin_test USING brin (time) WITH (pages_per_range=8);
CREATE INDEX brin_test_time_brin_32 ON brin_test USING brin (time) WITH (pages_per_range=32);
CREATE INDEX brin_test_time_brin_128 ON brin_test USING brin (time) WITH (pages_per_range=128);
CREATE INDEX brin_test_time_brin_256 ON brin_test USING brin (time) WITH (pages_per_range=256);
CREATE INDEX brin_test_time_brin_512 ON brin_test USING brin (time) WITH (pages_per_range=512);
CREATE INDEX brin_test_time_brin_1024 ON brin_test USING brin (time) WITH (pages_per_range=1024);
CREATE INDEX brin_test_time_brin_2048 ON brin_test USING brin (time) WITH (pages_per_range=2048);
-- Abfragen
SELECT * FROM brin_test WHERE time = '2100-11-11 13:37:00.31337'; -- Q1
SELECT * FROM brin_test WHERE time = '2205-12-19 00:16:00.31337'; -- Q2
SELECT * FROM brin_test WHERE time >= '2016-11-11' AND time <= '2016-11-12'; -- Q3
SELECT * FROM brin_test WHERE time >= '2100-11-11' AND time <= '2100-11-12'; -- Q4
SELECT * FROM brin_test WHERE time >= '2200-01-01 00:00:00.00000'; -- Q5
-- Ergebnisse
-- btree brin1 brin 8 brin 32 brin 128 brin 256 brin 512 brin 1024 brin 2048 no index
-- Q1 0,5 348,6 56,9 10,5 13,9 17,8 16,4 23,4 84,6 22450,3
-- Q2 0,4 318,4 50,1 11,3 11,1 8,2 3,4 12,6 16,3 20455,7
-- Q3 0,6 327,2 64,0 11,2 4,9 5,8 9,1 18,3 116,1 25972,1
-- Q4 0,5 316,9 45,3 11,2 5,0 5,4 11,4 22,6 52,2 22216,3
-- Q5 670,9 902,2 650,5 619,2 626,9 603,8 602,8 603,6 687,1 22305,2
Weiterführende Informationen: BRIN Indexes
Dieser Artikel wurde ursprünglich von Alexander Sosna verfasst.
Hintergrund
Mehrsprachige Unterstützung ist seit jeher in PostgreSQL® fester Bestandteil. PostgreSQL® nutzt dabei die Funktionen, die vom Betriebssystem zur Verfügung gestellt werden. Dies hat den Vorteil, dass PostgreSQL® sich hinsichtlich der Behandlung von Zeichenketten identisch zu allen anderen Programmen verhält, die ebenfalls auf den Betriebssystemroutinen basieren. Unter Linux ist hierfür maßgeblich die in der glibc vorhandene Unterstützung verantwortlich. So verhalten sich alle aus der Unixwelt bekannten Tools für Textverarbeitung analog zu den Vorgaben, die die jeweilige Locale-Einstellung in der aktuellen Linuxumgebung vorgibt. Die Locale-Einstellungen umfassen mehrere Elemente:
- Sortierung
- Interpretation von Stringliteralen
- Interpretation von Zahlen
- Interpretation von Zeitwerten
- Währungssymbole
- Ausgabe von Programmmeldungen
Die Liste erhebt keinen Anspruch von Vollständigkeit und kann sicherlich noch erweitert werden. Sie sollte jedoch alle insbesondere für PostgreSQL® relevanten Attribute abdecken. Vor allem die ersten beiden Eigenschaften sind für PostgreSQL® interessant, da beim Anlegen einer Datenbank vornherein entschieden werden muss, welche Sprache für Zeichenketten interessant sind. In der Regel übernimmt PostgreSQL® die Standardeinstellung hierfür direkt vom Betriebssystem, jedoch kann beispielsweise auch das CREATE DATABASE Kommando verwendet werden, um hier alternative Attribute pro Datenbank zu verwenden. Die relevanten Einstellungen werden über das LC_CTYPE Argument für Zeicheninterpretation (was ist eine Zahl und was ein Buchstabe) sowie LC_COLLATE (wie wird sortiert) für die gesamte Datenbank permanent festgelegt. Diese Einstellungen entscheiden auch, wie entsprechende Werte im Index abgelegt werden und wie Vergleiche mit Zeichenketten interpretiert werden.
Problematik
In letzter Zeit hat sich herauskristallisiert, dass Betriebssysteme beim Wechsel in eine neue Version vermehrt Probleme bekommen, die Konsistenz dieser Locales zu garantieren. Dies führt insbesondere bei PostgreSQL® dazu, dass beim Upgrade auf eine neue Betriebssystemversion sehr stark auf die Kompatibilität zwischen den verwendeten Locales geachtet werden muss. Ein prominentes Beispiel ist Red Hat und damit in Verbindung auch das sehr häufig verwendete freie Derivat CentOS. Beim Wechsel von auf CentOS 5.11 auf CentOS 6.6 ändern sich die Sortierreihenfolgen für bestimmte Zeichenketten in einigen Locales. Betroffen hiervon ist u.a. auch die Locale für de_DE.UTF-8. Bestimmte Zeichenketten werden bei der Sortierung unterschiedlich behandelt. CentOS 5.11 sortiert zum Beispiel Zeichenketten im Format 9-9-0 und 999 wie folgt:
echo -e '9-9-9\n999\n110\n1-1-0' | LANG=de_DE.UTF-8 sort
110
1-1-0
999
9-9-9
In CentOS 6.6 ändert sich die Sortierreihenfolge:
echo -e '9-9-9\n999\n110\n1-1-0' | LANG=de_DE.UTF-8 sort
1-1-0
110
9-9-9
999
Ausschlaggebend ist hier offensichtlich das zusätzliche, zur Formatierung vorgesehene ‚-‚-Zeichen, dass unter CentOS 5.11 und 6.6 dazu führt, dass solche Zeichenketten unterschiedlich interpretiert werden. Dies hat schwerwiegende Auswirkungen auf die Art und Weise, wie Indexe in PostgreSQL®-Datenbanken mit de_DE.UTF-8 Locale aufgebaut und gelesen werden. Standardmässig benutzt PostgreSQL® für Indexe für Zeichentypen wie text, character oder varchar immer einen sogenannten BTree-Indextyp. Ein BTree ist immer aufsteigend sortiert und PostgreSQL® nutzt BTree-Indexe ebenfalls auch für eindeutige Schlüssel (Primary Key, Unique Constraints). Die Folge sind unter Umständen logische Inkonsistenzen, wenn von CentOS 5 auf CentOS 6 gewechselt wird. Dies ist insbesondere unter folgenden Voraussetzungen der Fall:
- Die Datenbanken verwenden ein Locale, das von Betriebssystemseitigen Änderungen betroffen ist, in diesem Fall
de_DE.UTF-8. - Die Datenbank wurde entweder physisch auf die neue Plattform umgezogen, oder
- ein Upgrade des Betriebssystems wurde vorgenommen.
- Die Datenbank ist ein Streaming Standby auf einer Plattform mit unterschiedlichen Locales.
Logische Inkonsistenzen können hierbei nicht nur in entsprechenden Indexen auftreten, sondern auch fehlerhafte Abfrageergebnisse zur Folge haben. Da gegebenenfalls Sortieroperationen für eine Abfrage genutzt werden, können unterschiedliche Ergebnismengen erzeugt werden. Insbesondere Abfragepläne mit zugrundeliegenden Sortieroperationen wie Merge Join, DISTINCT oder einfaches ORDER BYsind hier Kandidaten. Die Folgen können jedoch noch vielfältiger sein. Auch bei Installationen mit Streaming Standby Servern auf unterschiedlichen Betriebssystemversionen muss daher auf die Kompatibilität der Locales geachtet werden.
Tests haben außerdem ergeben, dass mindestens auch die Versionen 6 und 7 von RedHat Enterprise Linux sowie CentOS 7 die beschriebenen Inkompabilitäten enthalten:
- CentOS 5 und CentOS 7 sowie RHEL 7 verhalten sich hinsichtlich unserer Erkenntnisse für das Locale
de_DE.UTF-8identisch. - RHEL6 und CentOS 6 sind inkompatibel zur
de_DE.UTF-8Locale in den vorhergehenden und nachfolgenden Hauptversionen. - Es gibt Indikatoren, die darauf hindeuten, dass andere Locales ebenfalls betroffen sind: https://bugs.centos.org/view.php?id=7009 und https://bugs.centos.org/view.php?id=6210.
Die Folgende Tabellen zeigt die nach unseren Tests festgestellten Inkompatibilitäten für das deutsche Locale de_DE.UTF-8 zwischen den CentOS-Versionen:
| de_DE.UTF-8 | CentOS 5.11 | CentOS 6.6 | CentOS 7.1 |
| CentOS 5.11 | X | ||
| CentOS 6.6 | X | X | |
| CentOS 7.1 | X |
Maßnahmen
Generell sollte ein gründlicher Test des Betriebes von PostgreSQL® im Falle von Betriebssystemupgrades im Vorfeld erfolgen. Ist ein Upgrade bereits erfolgt, so sollten unbedingt auf jeden Fall alle Indexe auf Charaktertypen überprüft und auf jeden Fall mit REINDEX neu erzeugt werden. Ist das Kind bereits in den Brunnen gefallen und man stellt beispielsweise Dubletten bei eindeutigen Textschlüsseln fest, so sollte man die Daten einer logischen Prüfung unterziehen. In diesem Fall hilft vor dem wiederholten Erzeugen der Textschlüssel nur das Bereinigen der Inkonsistenzen.
Streaming Standby erfordern Binärkompatible Plattformen, jedoch können unterschiedliche Betriebsversionen zum Einsatz kommen. Hier sollte ebenfalls sorgfältig die Zielplattform geprüft werden, da unter Umständen sonst zum Primärserver abweichende Abfrageergebnisse materialisiert werden können. Generell sind die Lösungsmöglichkeiten eines korrekten Betriebes in solchen Fällen für Streaming Standby begrenzt. Da ein Standby eine Blockweise Kopie der Datenbank darstellt und keine schreibenden Transaktionen zulässt, können logische Inkonsistenzen nur bei Abfragen gegen die Datenbasis auftreten. Ein Vorgehen wäre beispielsweise die Localerepräsentation auf den Standbysystemen durch diejenige des Primärservers zu ersetzen.
Wird ein Streaming Standby für ein Upgrade auf eine neue, mit inkompatiblen Locale behaftete Betriebssystemversion verwendet, so sollte nach dem Wechsel und vor Inbetriebnahme in Produktion die Datenbank reindiziert werden.
Zusammenfassung
Unterschiede in den Locales zwischen CentOS 5, CentOS 6 und CentOS 7 sowie RHEL 6 und RHEL 7 können unter bestimmten Voraussetzungen zu logischen Inkonsistenzen in der Datenbasis in PostgreSQL® führen oder Abfrageergebnisse verfälschen. Daher ist bei Upgrades von Betriebssystemen auf jeden Fall eine sorgfältige Prüfung der verwendeten Locales angeraten. Erste Tests zeigen, dass es zumindest für das deutsche Locale de_DE.UTF-8 in CentOS 7 keine Unterschiede zu CentOS 5 gibt. Besondere Vorgehensweisen und Vorkehrungen sind daher zu beachten, sollte eine PostgreSQL®-Datenbank von CentOS 6 auf CentOS 7 oder CentOS 5 auf CentOS 6 umgezogen werden.
Das Team der credativ GmbH unterstützt Sie bei der Planung solcher Upgrades, aber auch bei der Fehlerbehandlung, sollte ein entsprechendes Problem bereits aufgetreten sein.
