Viele Unternehmen denken heutzutage darüber nach, ihre Datenbanken von Legacy- oder proprietären Systemen auf PostgreSQL zu migrieren. Das primäre Ziel ist es, die Kosten zu senken, die Fähigkeiten zu verbessern und die langfristige Nachhaltigkeit zu gewährleisten. Doch allein die Vorstellung, auf PostgreSQL zu migrieren, kann schon überwältigend sein. Sehr oft ist das Wissen über die Altanwendungen begrenzt oder sogar verloren gegangen. In einigen Fällen nimmt die Unterstützung durch den Hersteller ab, und der Expertenpool und die Unterstützung durch die Community schrumpfen. Außerdem laufen alte Datenbanken oft auf veralteter Hardware und alten Betriebssystemen, was weitere Risiken und Einschränkungen mit sich bringt. (mehr …)
Wir freuen uns sehr, Gastgeber des 5. PostgreSQL User Group NRW Meetups zu sein – und das in unseren neuen Geschäftsräumen direkt am Borussia-Park in Mönchengladbach! (mehr …)
Die PGConf.DE 2025, die 9. jährliche PostgreSQL-Konferenz in Deutschland, fand vom 8. bis 9. Mai 2025 im Marriott Hotel in der Nähe des Potsdamer Platzes in Berlin statt. Die Veranstaltung brachte zwei Tage lang PostgreSQL-Enthusiasten, Entwickler, DBAs und Industriesponsoren zu faszinierenden Vorträgen in vier parallelen Tracks zusammen. Mit 347 Teilnehmern war es die bisher größte Veranstaltung. Die gesamte Konferenz war sehr gut organisiert, und daher gebührt allen Organisatoren – insbesondere Andreas Scherbaum, dem Hauptorganisator – ein besonderer Dank für ihre Bemühungen und ihre harte Arbeit.
Unser Unternehmen, die credativ GmbH, ist wieder unabhängig und nahm als Gold-Sponsor teil. Der CTO von credativ, Alexander Wirt, der Head of Sales & Marketing, Peter Dreuw, und der Teamleiter des Datenbank-Teams, Dr. Tobias Kauder, standen den Teilnehmern am Stand von credativ zur Verfügung. Vielen Dank an unseren Teamkollegen Sascha Spettmann für die Lieferung aller Utensilien und Werbetafeln zur Konferenz und zurück.



Insgesamt hielten wir vier Vorträge auf der Konferenz. Michael Banck, technischer Leiter unseres Datenbank-Teams, präsentierte den deutschsprachigen Vortrag „PostgreSQL Performance Tuning“. Er gab einen tiefen und umfassenden Überblick über die wichtigsten Performance-Tuning-Parameter in PostgreSQL und erklärte, wie sie das Verhalten der Datenbank beeinflussen. Sein Vortrag zog ein großes Publikum an und wurde sehr gut aufgenommen.


Ich hatte die absolut einzigartige Gelegenheit, drei verschiedene Vorträge im englischen Track zu halten. In meinem regulären Vortrag „PostgreSQL Connections Memory Usage: How Much, Why and When“ präsentierte ich die Ergebnisse meiner Forschung und Tests zum Speicherverbrauch von PostgreSQL-Verbindungen. Nachdem ich die wichtigsten Aspekte des Linux-Speichermanagements und die Messungen des Speicherverbrauchs, die von Standardbefehlen gemeldet werden, erläutert hatte, beschrieb ich detailliert den Speicherverbrauch von PostgreSQL-Verbindungen während der Abfrageausführung basierend auf den Zahlen, die in smaps-Dateien gemeldet wurden. Ich plane hierzu detaillierte Blogbeiträge über meine Erkenntnisse zu veröffentlichen. Mein anderer Vortrag, „Building a Data Lakehouse with PostgreSQL“, wurde ursprünglich als Reservevortrag für den Fall einer kurzfristigen Absage ausgewählt. Der Vortrag „Creating a Board Game Chatbot with Postgres, AI, and RAG“ von Matt Cornillon musste ersetzt werden. Der Sprecher konnte nicht teilnehmen, da sein Flug sehr kurzfristig und unerwartet annulliert wurde.


Im Sponsor-Track präsentierten der CTO von credativ, Alexander Wirt, und ich einen Vortrag mit dem Titel „Your Data Deserves the Best: Migration to PostgreSQL“. Darin stellten wir unser neues Migrationstool „credativ-pg-migrator“ vor. Es ist in der Lage, Datenmodelle (Tabellen, Daten, Indizes, Constraints und Views) von Informix, IBM DB2 LUW, MS SQL Server, Sybase ASE, SQL Anywhere und MySQL/MariaDB zu migrieren. Im Falle von Informix kann es auch Stored Procedures, Funktionen und Trigger in PostgreSQL PL/pgSQL konvertieren. Weitere Details zu diesem Tool werden wir in einem separaten Blogbeitrag mitteilen.

Da es immer drei oder vier parallele Vorträge gab, musste ich sorgfältig auswählen, an welchen Sessions ich teilnehmen wollte. Besonders gefallen hat mir der Vortrag „András in Windowsland – a DBA’s (mis)adventures“ von András Váczi von Cybertec. Der Sprecher gab viele nützliche Tipps für den Zugriff auf und die Fehlerbehebung von PostgreSQL unter Windows. Mir gefiel auch der deutsche Vortrag „Modern VACUUM“ von Christoph Berg von Cybertec. Er gab wertvolle Einblicke in die Geschichte und Implementierungsdetails des VACUUM-Befehls und der Autovacuum-Hintergrundprozesse. Ein weiterer sehr interessanter Vortrag war die deutsche Präsentation „Modernes SSL ideal einsetzen“ von Peter Eisentraut von EDB. Der Vortrag behandelte die Auswahl geeigneter Protokollversionen und kryptografischer Cipher Suites, die Verwaltung von Schlüsseln und Zertifikaten sowie die Konfiguration von Client-/Server-Einstellungen zur Erfüllung zeitgemäßer Sicherheitsstandards. Der Vortrag „Comparing the Oracle and PostgreSQL transaction systems“ von Laurenz Albe von Cybertec erhielt viel wohlverdiente Aufmerksamkeit. Zu den Kernthemen gehörten der Undo/Redo-Mechanismus von Oracle im Vergleich zum MVCC-Ansatz von PostgreSQL, Unterschiede bei den Standard-Isolationsstufen und Anomalien sowie die Art und Weise, wie jede Datenbank Constraints und transaktionale DDL implementiert. Nicht zuletzt möchte ich den Vortrag „What is an SLRU anyway?“ erwähnen, der von einem wichtigen PostgreSQL-Contributor, Álvaro Herrera, gehalten wurde. Er erklärte, dass SLRUs im Wesentlichen zirkuläre Logs mit einem In-Memory-Cache sind, die zur Nachverfolgung von Informationen wie committeden Transaktionen oder Snapshot-Daten verwendet werden, und hob die Bedeutung der Innovationen in PostgreSQL 17 hervor, die SLRU-Cache-Größen konfigurierbar machten. Leider wurden die Vorträge nicht aufgezeichnet, aber die Folien für die Mehrheit der Vorträge sind bereits auf der Konferenz-Website verfügbar.
Die gesamte Veranstaltung war sehr informativ und bot hervorragende Möglichkeiten zum Networking. Wir freuen uns schon auf die nächste PGConf.DE. In der Zwischenzeit bleiben Sie auf dem Laufenden über alle Neuigkeiten der credativ und folgen Sie uns auf den sozialen Medien – LinkedIn und Mastodon.
Wenn Sie mehr über unsere Angebote zu PostgreSQL-Services wissen möchten, klicken Sie bitte hier!
Der Prague PostgreSQL Developer Day (P2D2) ist eine etablierte tschechische PostgreSQL-Konferenz. Die diesjährige 17. Ausgabe war außergewöhnlich, mit 275 registrierten Besuchern und 16 Vorträgen auf zwei Tracks. Bemerkenswert ist, dass mehrere wichtige PostgreSQL-Mitwirkende und Kernmitglieder anwesend waren, was die Bedeutung der Veranstaltung unterstreicht. Tomas Vondra organisierte die Konferenz, wie in den Vorjahren. Bruce Momjian, Vizepräsident und Postgres-Evangelist bei EDB, leitete einen halbtägigen Workshop mit dem Titel „Postgres & AI: From the Trenches to the Sky.“ Robert Haas hielt einen sehr interessanten Vortrag über Inkrementelles Backup in PostgreSQL 17, eine Funktion, die er entwickelt hat.
Ich hatte die fantastische Gelegenheit, zu dieser Konferenz mit meinem neuen Vortrag „Aufbau eines Data Lakehouse mit PostgreSQL: Einblicke in Formate, Tools, Techniken und Strategien“ beizutragen. Angesichts der sich noch entwickelnden Natur dieses Themas und der unterschiedlichen Definitionen von Data Lakehouses habe ich die wichtigsten Bereiche abgedeckt, wobei ich die Funktionalitäten und Erweiterungen hervorhob, die PostgreSQL bietet. Ich erhielt sehr positives Feedback zu meinem Vortrag und hatte mehrere aufschlussreiche Diskussionen über das Thema mit verschiedenen Personen.
Unter den Vorträgen, die ich besuchte, gefielen mir besonders Robert Haas‘ Präsentation über Inkrementelle Backups, die praktische Demonstration von PostgreSQL-Statistiken im Vortrag „Statistics: How PostgreSQL Counts Without Counting“ von Sadeq Dousti und die sehr interessante Präsentation „Anatomy of Table-Level Locks in PostgreSQL“ von Gülçin Yıldırım Jelínek. Sie erklärte detailliert die Hierarchie verschiedener Sperrebenen und die Ereignisse, die zu Verzögerungen bei Operationen aufgrund von Sperren führen. Weitere bemerkenswerte Vorträge waren „Replicating Schema Changes with PostgreSQL“ von Esther Miñano und „When Autovacuum Met FinOps: A Cloud Romance“ von Mayuresh Bagayatkar. Zusammenfassungen aller Vorträge und bald auch die Folien finden Sie






(c) Tomas Vondra EDB & Organisatoren der P2D2-Konferenz
Das Problem des Table- und Index-Bloats aufgrund fehlgeschlagener Einfügungen bei Unique Constraints ist bekannt und wurde in verschiedenen Artikeln im Internet diskutiert. Allerdings mangelt es diesen Diskussionen manchmal an einem klaren, praktischen Beispiel mit Messungen, um die Auswirkungen zu veranschaulichen. Und trotz der Vertrautheit mit diesem Problem sehen wir dieses Designmuster – oder besser gesagt Anti-Pattern – immer noch häufig in realen Anwendungen. Entwickler verlassen sich oft auf Unique Constraints, um zu verhindern, dass doppelte Werte in Tabellen eingefügt werden. Obwohl dieser Ansatz unkompliziert, vielseitig und allgemein als effektiv angesehen wird, führen in PostgreSQL Einfügungen, die aufgrund von Verletzungen von Unique Constraints fehlschlagen, leider immer zu Table- und Index-Bloat. Und auf stark frequentierten Systemen kann dieser unnötige Bloat die Disk-I/O und die Häufigkeit von Autovacuum-Läufen erheblich erhöhen. In diesem Artikel möchten wir dieses Problem noch einmal hervorheben und ein einfaches Beispiel mit Messungen zur Veranschaulichung geben. Wir schlagen eine einfache Verbesserung vor, die dazu beitragen kann, dieses Problem zu mildern und die Autovacuum-Auslastung und die Disk-I/O zu reduzieren.
Zwei Ansätze zur Duplikatsvermeidung
In PostgreSQL gibt es zwei Hauptmethoden, um doppelte Werte mithilfe von Unique Constraints zu verhindern:
1. Standard-Insert-Befehl (INSERT INTO table)
Der übliche INSERT INTO table-Befehl versucht, Daten direkt in die Tabelle einzufügen. Wenn das Einfügen zu einem doppelten Wert führen würde, schlägt es mit einem Fehler „duplicate key value violates unique constraint“ fehl. Da der Befehl keine Duplikatsprüfungen spezifiziert, fügt PostgreSQL intern sofort die neue Zeile ein und beginnt erst dann mit der Aktualisierung der Indizes. Wenn eine Verletzung eines Unique Index auftritt, löst dies den Fehler aus und löscht die neu hinzugefügte Zeile. Die Reihenfolge der Indexaktualisierungen wird durch ihre Beziehungs-IDs bestimmt, sodass das Ausmaß des Index-Bloats von der Reihenfolge abhängt, in der Indizes erstellt wurden. Bei wiederholten Fehlern aufgrund von „unique constraint violation“ sammeln sich sowohl in der Tabelle als auch in einigen Indizes gelöschte Datensätze an, was zu Bloat führt, und die resultierenden Schreiboperationen erhöhen die Disk-I/O, ohne ein nützliches Ergebnis zu erzielen.
2. Konfliktbewusstes Einfügen (INSERT INTO table … ON CONFLICT DO NOTHING)
Der Befehl INSERT INTO table ON CONFLICT DO NOTHING verhält sich anders. Da er spezifiziert, dass ein Konflikt auftreten könnte, prüft PostgreSQL zuerst auf potenzielle Duplikate, bevor versucht wird, Daten einzufügen. Wenn ein Duplikat gefunden wird, führt PostgreSQL die angegebene Aktion aus – in diesem Fall „DO NOTHING“ – und es tritt kein Fehler auf. Diese Klausel wurde in PostgreSQL 9.5 eingeführt, aber einige Anwendungen laufen entweder noch auf älteren PostgreSQL-Versionen oder behalten Legacy-Code bei, wenn die Datenbank aktualisiert wird. Infolgedessen wird diese Option zur Konfliktbehandlung oft zu wenig genutzt.
Testbeispiel
Um Tests durchführen zu können, müssen wir PostgreSQL mit „autovacuum=off“ starten. Andernfalls verarbeitet Autovacuum bei meist inaktiver Instanz aufgeblähte Objekte sofort, und es wäre nicht möglich, Statistiken zu erfassen. Wir erstellen ein einfaches Testbeispiel mit mehreren Indizes:
CREATE TABLE IF NOT EXISTS test_unique_constraints(
id serial primary key,
unique_text_key text,
unique_integer_key integer,
some_other_bigint_column bigint,
some_other_text_column text);
CREATE INDEX test_unique_constraints_some_other_bigint_column_idx ON test_unique_constraints (some_other_bigint_column ); CREATE INDEX test_unique_constraints_some_other_text_column_idx ON test_unique_constraints (some_other_text_column ); CREATE INDEX test_unique_constraints_unique_text_key_unique_integer_key__idx ON test_unique_constraints (unique_text_key, unique_integer_key, some_other_bigint_column ); CREATE UNIQUE test_unique_constraints_unique_integer_key_idx INDEX ON test_unique_constraints (unique_text_key ); CREATE UNIQUE test_unique_constraints_unique_text_key_idx INDEX ON test_unique_constraints (unique_integer_key );
Und nun füllen wir diese Tabelle mit eindeutigen Daten:
DO $$ BEGIN FOR i IN 1..1000 LOOP INSERT INTO test_unique_constraints (unique_text_key, unique_integer_key, some_other_bigint_column, some_other_text_column) VALUES (i::text, i, i, i::text); END LOOP; END; $$;
Im zweiten Schritt verwenden wir ein einfaches Python-Skript, um eine Verbindung zur Datenbank herzustellen, zu versuchen, widersprüchliche Daten einzufügen, und die Sitzung nach einem Fehler zu schließen. Zuerst sendet es 10.000 INSERT-Anweisungen, die mit dem Index „test_unique_constraints_unique_int_key_idx“ in Konflikt stehen, dann weitere 10.000 INSERTs, die mit „test_unique_constraints_unique_text_key_idx“ in Konflikt stehen. Der gesamte Test wird in wenigen Dutzend Sekunden durchgeführt, danach inspizieren wir alle Objekte mit der Erweiterung „pgstattuple“. Die folgende Abfrage listet alle Objekte in einer einzigen Ausgabe auf:
WITH maintable AS (SELECT oid, relname FROM pg_class WHERE relname = 'test_unique_constraints') SELECT m.oid as relid, m.relname as relation, s.* FROM maintable m JOIN LATERAL (SELECT * FROM pgstattuple(m.oid)) s ON true UNION ALL SELECT i.indexrelid as relid, indexrelid::regclass::text as relation, s.* FROM pg_index i JOIN LATERAL (SELECT * FROM pgstattuple(i.indexrelid)) s ON true WHERE i.indrelid::regclass::text = 'test_unique_constraints' ORDER BY relid;
Beobachtete Ergebnisse
Nach mehrmaligem Ausführen des gesamten Tests beobachten wir Folgendes:
- Die Haupttabelle „test_unique_constraints“ hat immer 1.000 Live-Tupel und 20.000 zusätzliche Dead-Records, was zu ca. 85 % Dead-Tupeln in der Tabelle führt
- Der Index auf dem Primärschlüssel zeigt immer 21.000 Tupel an, ohne zu wissen, dass 20.000 dieser Datensätze in der Haupttabelle als gelöscht markiert sind.
- Andere nicht eindeutige Indizes zeigen in verschiedenen Läufen unterschiedliche Ergebnisse, die zwischen 3.000 und 21.000 Datensätzen liegen. Die Zahlen hängen von der Verteilung der Werte ab, die das Skript für die zugrunde liegenden Spalten generiert. Wir haben sowohl wiederholte als auch vollständig eindeutige Werte getestet. Wiederholte Werte führten zu weniger Datensätzen in Indizes, vollständig eindeutige Werte führten zu einer vollständigen Anzahl von 21.000 Datensätzen in diesen Indizes.
- Unique Indizes zeigten wiederholt Tupelanzahlen nur zwischen 1.000 und 1.400 in allen Tests. Der Unique Index auf dem „unique_text_key“ zeigt immer einige Dead-Tupel in der Ausgabe. Eine genaue Erklärung dieser Zahlen würde eine eingehendere Untersuchung dieser Beziehungen und des Codes der pgstattuple-Funktion erfordern, was den Rahmen dieses Artikels sprengen würde. Aber auch hier wird ein geringer Bloat gemeldet.
- Von der pgstattuple-Funktion gemeldete Zahlen warfen Fragen nach ihrer Genauigkeit auf, obwohl die Dokumentation zu dem Schluss zu führen scheint, dass die Zahlen auf Tupelebene genau sein sollten.
- Die anschließende manuelle Vacuum-Operation bestätigt 20.000 Dead-Records in der Haupttabelle und 54 Seiten, die aus dem Primärschlüsselindex entfernt wurden, sowie bis zu mehreren Dutzend Seiten, die aus anderen Indizes entfernt wurden – unterschiedliche Zahlen in jedem Lauf in Abhängigkeit von der Gesamtzahl der Tupel in diesen Beziehungen, wie oben beschrieben.
- Jeder fehlgeschlagene Insert erhöht auch die Transaktions-ID und damit das Transaktionsalter der Datenbank.
Hier ist ein Beispielausgabe aus der oben gezeigten Abfrage nach dem Testlauf, der eindeutige Werte für alle Spalten verwendete. Wie wir sehen können, kann der Bloat von nicht eindeutigen Indizes aufgrund fehlgeschlagener Inserts groß sein.
relid | relation | table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent -------+-----------------------------------------------------------------+-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+-------------- 16418 | test_unique_constraints | 1269760 | 1000 | 51893 | 4.09 | 20000 | 1080000 | 85.06 | 5420 | 0.43 16424 | test_unique_constraints_pkey | 491520 | 21000 | 336000 | 68.36 | 0 | 0 | 0 | 51444 | 10.47 16426 | test_unique_constraints_some_other_bigint_column_idx | 581632 | 16396 | 326536 | 56.14 | 0 | 0 | 0 | 168732 | 29.01 16427 | test_unique_constraints_some_other_text_column_idx | 516096 | 16815 | 327176 | 63.39 | 0 | 0 | 0 | 101392 | 19.65 16428 | test_unique_constraints_unique_text_key_unique_integer_key__idx | 1015808 | 21000 | 584088 | 57.5 | 0 | 0 | 0 | 323548 | 31.85 16429 | test_unique_constraints_unique_text_key_idx | 57344 | 1263 | 20208 | 35.24 | 2 | 32 | 0.06 | 15360 | 26.79 16430 | test_unique_constraints_unique_integer_key_idx | 40960 | 1000 | 16000 | 39.06 | 0 | 0 | 0 | 4404 | 10.75 (7 rows)
In einem zweiten Test modifizieren wir das Skript, um die Klausel ON CONFLICT DO NOTHING in den INSERT-Befehl aufzunehmen, und wiederholen beide Tests. Diesmal führen Inserts nicht zu Fehlern; stattdessen geben sie einfach „INSERT 0 0“ zurück, was anzeigt, dass keine Datensätze eingefügt wurden. Die Überprüfung der Transaktions-ID nach diesem Test zeigt nur einen minimalen Anstieg, der durch Hintergrundprozesse verursacht wird. Versuche, widersprüchliche Daten einzufügen, führten nicht zu einer Erhöhung der Transaktions-ID (XID), da PostgreSQL zuerst nur eine virtuelle Transaktion startete, um auf Konflikte zu prüfen, und weil ein Konflikt gefunden wurde, die Transaktion abbrach, ohne eine neue XID zugewiesen zu haben. Die „pgstattuple“-Ausgabe bestätigt, dass alle Objekte nur Live-Daten enthalten, diesmal ohne Dead-Tupel.
Zusammenfassung
Wie gezeigt, bläht jeder fehlgeschlagene Insert die zugrunde liegende Tabelle und einige Indizes auf und erhöht die Transaktions-ID, da jeder fehlgeschlagene Insert in einer separaten Transaktion erfolgt. Folglich wird Autovacuum gezwungen, häufiger zu laufen, was wertvolle Systemressourcen verbraucht. Daher sollten Anwendungen, die sich immer noch ausschließlich auf einfache INSERT-Befehle ohne ON CONFLICT-Bedingungen verlassen, diese Implementierung überdenken. Aber wie immer sollte die endgültige Entscheidung auf den spezifischen Bedingungen jeder Anwendung basieren.
Veranstaltungsort
Die vierzehnte PGConf.EU fand in Athen statt und erfreut sich weiterhin steigender Beliebtheit. Mit 782 Besuchern konnte die PGConf.EU einmal mehr ihren Besucherrekord übertreffen. Damit ist sie die bisher größte PostgreSQL Konferenz weltweit. Veranstaltungsort war das Divani Caravel Hotel, welches viel Platz für Teilnehmer, Speaker und Sponsoren bot. Als NetApp Open Source Services waren wir zu dritt auf der Konferenz vertreten. Neben mir waren noch Patrick Lauer und Michael Banck vor Ort.
Talks
Nach einer kurzen Begrüßung durch das Organisationsteam machte Stacey Haysler mit der Keynote „The PostgreSQL license fee“ den Anfang, indem Sie hervorhob, wovon PostgreSQL lebt und was es so erfolgreich macht: Die Community, die ihre PostgreSQL Beiträge auf vielfältige Arten leistet und würdigte damit weit mehr als die reine Code-Entwicklung. Anschließend erwartete uns das Programm mit 51 Talks, verteilt auf 3 Tracks, plus extra Sponsorentrack mit zusätzlichen 14 Talks. Die Entscheidung für den einen oder anderen Talk fiel nicht immer leicht.
Michael Banck aus unserem Datenbankteam und Maintainer von Patroni für Debian und Ubuntu, gab in seinem Vortag „Patroni Deployment Patterns“ einen groben Überblick über Patroni und zeigte zusätzlich verschiedene Einsatzmöglichkeiten auf, sowie die Probleme, die dabei auftreten können. Es entwickelte sich ein konstruktiver Austausch mit dem Publikum über die Möglichkeiten, Probleme und die zukünftige Entwicklung von Patroni.

Patroni Deployment Patterns, Michael Banck, PGConf.EU 24
Rafael Thofehrn Castro von EDB stellte in seinem Talk „Debugging active queries with mid-flight instrumented explain plans“ einen Patch vor mit dem es ihm möglich ist, Querypläne zur Laufzeit zu beobachten. Das ist überaus hilfreich bei Queries mit minutenlangen Laufzeiten oder wie im vorgeführten Beispiel mit einer Laufzeit von über einer Stunde. Live Debugging und Optimierung von Queries, die nie fertig werden würden, ist damit denkbar. Die Begeisterung am Ende war nicht zu überhören. Ob und wann das allerdings in PostgreSQL Core landet, ist aktuell noch unklar.
PostgreSQL hat sich laut der aktuellen Stack Overflow Umfrage inzwischen zu Platz 1 der beliebtesten Datenbanken entwickelt. Migrationen beispielsweise von Oracle zu PostgreSQL bleiben daher auch in Zukunft ein wichtiges Thema. Teresa Lopes von Adyen beschrieb in ihrem Vortrag „PostgreSQL for Oracle DBAs – A walk in the park?“ ihre Erfahrungen dabei, was ihr besonders gut an PostgreSQL gefällt und welche gewohnten Features aus Oracle sie noch vermisst.
Zu jedem Talk hat man die Möglichkeit Feedback zu geben, welches sehr wertvoll für die Speaker und das Organisationsteam ist. Im letzten Jahr schienen nur wenige davon Gebrauch gemacht zu haben, weshalb sich das Organisationsteam dieses Jahr dazu entschieden hat einen zusätzlichen Anreiz zu geben. Für jedes abgegebene Feedback steigert man seine Chance auf ein Gratis-Ticket für die nächste PGConf.EU. Alle Talks wurden aufgezeichnet, sofern der jeweilige Speaker der Aufnahme nicht widersprochen hat. Einige wurden bereits auf YouTube veröffentlicht.
Das alljährliche Social-Event fand wieder am Mittwoch, dem ersten Konferenztag, im Konferenzhotel statt und bot Gelegenheit zum Austausch zwischen Teilnehmern, Speakern und Sponsoren. Insgesamt wuchs die Zahl der Sponsoren in diesem Jahr auf insgesamt 35.
Ausblick
Einen besonderen Dank möchten wir dem Organisationsteam aussprechen, welches erneut eine sehr lehrreiche Konferenz auf die Beine gestellt hat. Wir freuen uns bereits auf die nächste PGConf.EU. Bis dahin werden wir auch auf der nächsten PGConf.DE wieder anzutreffen sein.
TOAST (The Oversized Attribute Storage Technique) ist der Mechanismus von PostgreSQL zur Handhabung großer Datenobjekte, die die 8-KB-Datenseitenbegrenzung überschreiten. Eingeführt in PostgreSQL 7.1, ist TOAST eine verbesserte Version des Out-of-Line-Speichermechanismus, der in Oracle-Datenbanken zur Handhabung großer Objekte (LOBs) verwendet wird. Beide Datenbanken speichern Daten variabler Länge entweder inline innerhalb der Tabelle oder in einer separaten Struktur. PostgreSQL begrenzt die maximale Größe eines einzelnen Tupels auf eine Datenseite. Wenn die Größe des Tupels, einschließlich komprimierter Daten in einer Spalte variabler Länge, einen bestimmten Schwellenwert überschreitet, wird der komprimierte Teil in eine separate Datendatei verschoben und automatisch in Chunks aufgeteilt, um die Leistung zu optimieren.
 TOAST kann zur Speicherung von langen Texten, Binärdaten in Bytea-Spalten, JSONB-Daten, langen HSTORE-Schlüssel-Wert-Paaren, großen Arrays, umfangreichen XML-Dokumenten oder benutzerdefinierten zusammengesetzten Datentypen verwendet werden. Sein Verhalten wird von zwei Parametern beeinflusst: TOAST_TUPLE_THRESHOLD und TOAST_TUPLE_TARGET. Der erste ist ein fest codierter Parameter, der im PostgreSQL-Quellcode in der Datei heaptoast.h definiert ist, basierend auf der Funktion MaximumBytesPerTuple, die für vier TOAST-Tupel pro Seite berechnet wird, was zu einer Begrenzung von 2000 Byte führt. Dieser fest codierte Schwellenwert verhindert, dass Benutzer zu kleine Werte im Out-of-Line-Speicher ablegen, was die Leistung beeinträchtigen würde. Der zweite Parameter, TOAST_TUPLE_TARGET, ist ein Speicherparameter auf Tabellenebene, der mit demselben Wert wie TOAST_TUPLE_THRESHOLD initialisiert wird, aber für einzelne Tabellen angepasst werden kann. Er definiert die minimale Tupellänge, die erforderlich ist, bevor versucht wird, lange Spaltenwerte zu komprimieren und in TOAST-Tabellen zu verschieben.
TOAST kann zur Speicherung von langen Texten, Binärdaten in Bytea-Spalten, JSONB-Daten, langen HSTORE-Schlüssel-Wert-Paaren, großen Arrays, umfangreichen XML-Dokumenten oder benutzerdefinierten zusammengesetzten Datentypen verwendet werden. Sein Verhalten wird von zwei Parametern beeinflusst: TOAST_TUPLE_THRESHOLD und TOAST_TUPLE_TARGET. Der erste ist ein fest codierter Parameter, der im PostgreSQL-Quellcode in der Datei heaptoast.h definiert ist, basierend auf der Funktion MaximumBytesPerTuple, die für vier TOAST-Tupel pro Seite berechnet wird, was zu einer Begrenzung von 2000 Byte führt. Dieser fest codierte Schwellenwert verhindert, dass Benutzer zu kleine Werte im Out-of-Line-Speicher ablegen, was die Leistung beeinträchtigen würde. Der zweite Parameter, TOAST_TUPLE_TARGET, ist ein Speicherparameter auf Tabellenebene, der mit demselben Wert wie TOAST_TUPLE_THRESHOLD initialisiert wird, aber für einzelne Tabellen angepasst werden kann. Er definiert die minimale Tupellänge, die erforderlich ist, bevor versucht wird, lange Spaltenwerte zu komprimieren und in TOAST-Tabellen zu verschieben.
In der Quelldatei heaptoast.h erklärt ein Kommentar: „Ist ein Tupel größer als TOAST_TUPLE_THRESHOLD, versuchen wir, es durch Komprimieren komprimierbarer Felder und Verschieben von EXTENDED- und EXTERNAL-Daten Out-of-Line auf nicht mehr als TOAST_TUPLE_TARGET Bytes zu „toasten“. Die Zahlen müssen nicht identisch sein, obwohl sie es derzeit sind. Es ist nicht sinnvoll, dass TARGET THRESHOLD überschreitet, aber es könnte nützlich sein, es kleiner zu machen.“ Das bedeutet, dass in realen Tabellen direkt im Tupel gespeicherte Daten komprimiert sein können oder auch nicht, abhängig von ihrer Größe nach der Komprimierung. Um zu überprüfen, ob Spalten komprimiert sind und welcher Algorithmus verwendet wird, können wir die PostgreSQL-Systemfunktion pg_column_compression verwenden. Zusätzlich hilft die Funktion pg_column_size, die Größe einzelner Spalten zu überprüfen. PostgreSQL 17 führt eine neue Funktion, pg_column_toast_chunk_id, ein, die anzeigt, ob der Wert einer Spalte in der TOAST-Tabelle gespeichert ist.
In den neuesten PostgreSQL-Versionen werden zwei Kompressionsalgorithmen verwendet: PGLZ (PostgreSQL LZ) und LZ4. Beide sind Varianten des LZ77-Algorithmus, wurden aber für unterschiedliche Anwendungsfälle entwickelt. PGLZ eignet sich für gemischte Text- und numerische Daten, wie XML oder JSON in Textform, und bietet ein Gleichgewicht zwischen Kompressionsgeschwindigkeit und -rate. Es verwendet einen Gleitfenstermechanismus, um wiederholte Sequenzen in den Daten zu erkennen, und bietet ein angemessenes Gleichgewicht zwischen Kompressionsgeschwindigkeit und Kompressionsrate. LZ4 hingegen ist eine schnelle Kompressionsmethode, die für Echtzeitszenarien entwickelt wurde. Es bietet Hochgeschwindigkeitskomprimierung und -dekomprimierung, was es ideal für leistungskritische Anwendungen macht. LZ4 ist deutlich schneller als PGLZ, insbesondere bei der Dekomprimierung, und verarbeitet Daten in festen Blöcken (typischerweise 64 KB) unter Verwendung einer Hash-Tabelle, um Übereinstimmungen zu finden. Dieser Algorithmus zeichnet sich bei Binärdaten wie Bildern, Audio- und Videodateien aus.
In meinem internen Forschungsprojekt, das darauf abzielte, die Leistung von JSONB-Daten unter verschiedenen Anwendungsfällen zu verstehen, habe ich mehrere Leistungstests für Abfragen durchgeführt, die JSONB-Daten verarbeiten. Die Ergebnisse einiger Tests zeigten interessante und manchmal überraschende Leistungsunterschiede zwischen diesen Algorithmen. Die vorgestellten Beispiele sind jedoch anekdotisch und können nicht verallgemeinert werden. Ziel dieses Artikels ist es, das Bewusstsein dafür zu schärfen, dass es enorme Leistungsunterschiede geben kann, die je nach spezifischen Daten und Anwendungsfällen sowie der spezifischen Hardware variieren. Daher können diese Ergebnisse nicht blind angewendet werden.
JSONB-Daten werden als binäres Objekt mit einer Baumstruktur gespeichert, wobei Schlüssel und Werte in separaten Zellen gespeichert werden und Schlüssel auf derselben JSON-Ebene in sortierter Reihenfolge abgelegt sind. Verschachtelte Ebenen werden als zusätzliche Baumstrukturen unter ihren entsprechenden Schlüsseln der höheren Ebene gespeichert. Diese Struktur bedeutet, dass das Abrufen von Daten für die ersten Schlüssel in der obersten JSON-Ebene schneller ist als das Abrufen von Werten für stark verschachtelte Schlüssel, die tiefer im Binärbaum gespeichert sind. Obwohl dieser Unterschied normalerweise vernachlässigbar ist, wird er bei Abfragen, die sequentielle Scans über den gesamten Datensatz durchführen, signifikant, da diese kleinen Verzögerungen die Gesamtleistung kumulativ beeinträchtigen können.
Der für die Tests verwendete Datensatz bestand aus historischen GitHub-Ereignissen, die als JSON-Objekte von gharchive.org verfügbar waren und die erste Januarwoche 2023 abdeckten. Ich habe drei verschiedene Tabellen getestet: eine mit PGLZ, eine mit LZ4 und eine mit EXTERNAL-Speicher ohne Komprimierung. Ein Python-Skript lud die Daten herunter, entpackte sie und lud sie in die jeweiligen Tabellen. Jede Tabelle wurde separat geladen, um zu verhindern, dass frühere Operationen das PostgreSQL-Speicherformat beeinflussen.
Die erste bemerkenswerte Beobachtung war der Größenunterschied zwischen den Tabellen. Die Tabelle mit LZ4-Komprimierung war die kleinste mit etwa 38 GB, gefolgt von der Tabelle mit PGLZ mit 41 GB. Die Tabelle mit externem Speicher ohne Komprimierung war mit 98 GB deutlich größer. Da die Testmaschinen nur 32 GB RAM hatten, passte keine der Tabellen vollständig in den Speicher, was die Festplatten-I/O zu einem wichtigen Leistungsfaktor machte. Etwa ein Drittel der Datensätze wurde in TOAST-Tabellen gespeichert, was eine typische Datengrößenverteilung widerspiegelte, wie sie von unseren Kunden beobachtet wird.
Um Caching-Effekte zu minimieren, habe ich mehrere Tests mit mehreren parallelen Sitzungen durchgeführt, die Testabfragen mit jeweils zufällig gewählten Parametern ausführten. Zusätzlich zu Anwendungsfällen mit verschiedenen Indextypen führte ich auch sequentielle Scans über die gesamte Tabelle durch. Die Tests wurden mit unterschiedlicher Anzahl paralleler Sitzungen wiederholt, um genügend Datenpunkte zu sammeln, und dieselben Tests wurden an allen drei Tabellen mit verschiedenen Kompressionsalgorithmen durchgeführt.
Die erste Grafik zeigt die Ergebnisse von SELECT-Abfragen, die sequentielle Scans durchführen und JSON-Schlüssel abrufen, die am Anfang des JSONB-Binärobjekts gespeichert sind. Wie erwartet bietet externer Speicher ohne Komprimierung (blaue Linie) eine nahezu lineare Leistung, wobei die Festplatten-I/O der Hauptfaktor ist. Auf einer 8-Kern-Maschine liefert der PGLZ-Algorithmus (rote Linie) unter geringeren Lasten eine recht gute Leistung. Sobald jedoch die Anzahl der parallelen Abfragen die Anzahl der verfügbaren CPU-Kerne (8) erreicht, beginnt seine Leistung abzunehmen und wird schlechter als die Leistung unkomprimierter Daten. Unter höheren Lasten wird er zu einem ernsthaften Engpass. Im Gegensatz dazu verarbeitet LZ4 (grüne Linie) parallele Abfragen außergewöhnlich gut und behält eine bessere Leistung als unkomprimierte Daten bei, selbst bei bis zu 32 parallelen Abfragen auf 8 Kernen.
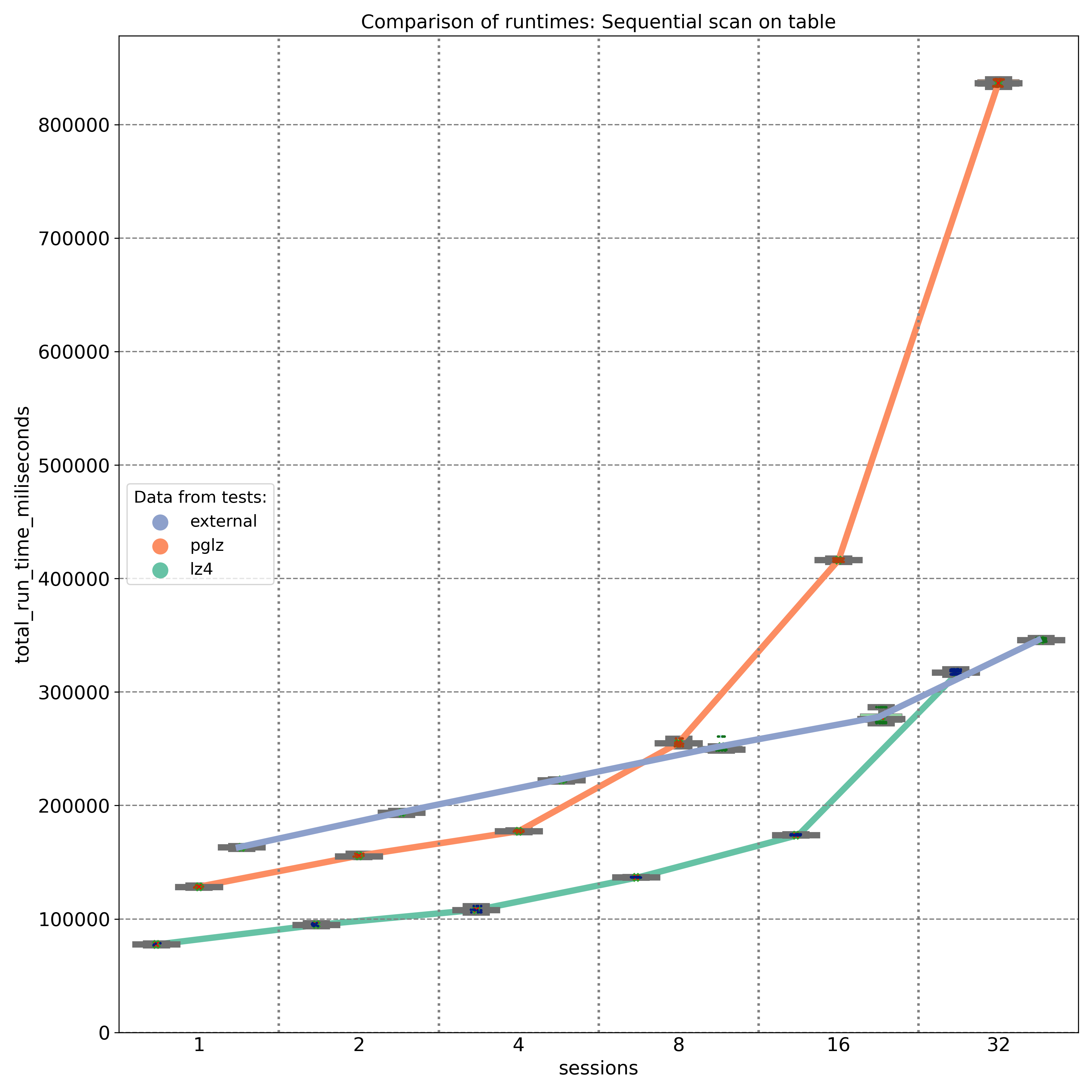
Der zweite Test zielte auf JSONB-Schlüssel ab, die an verschiedenen Positionen (Anfang, Mitte und Ende) innerhalb des JSONB-Binärobjekts gespeichert sind. Die Ergebnisse, gemessen auf einer 20-Kern-Maschine, zeigen, dass PGLZ (rote Linie) von Anfang an langsamer ist als die unkomprimierte Tabelle. In diesem Fall verschlechtert sich die Leistung von PGLZ linear statt geometrisch, liegt aber immer noch deutlich hinter LZ4 (grüne Linie). LZ4 übertraf während des gesamten Tests durchweg die unkomprimierten Daten.
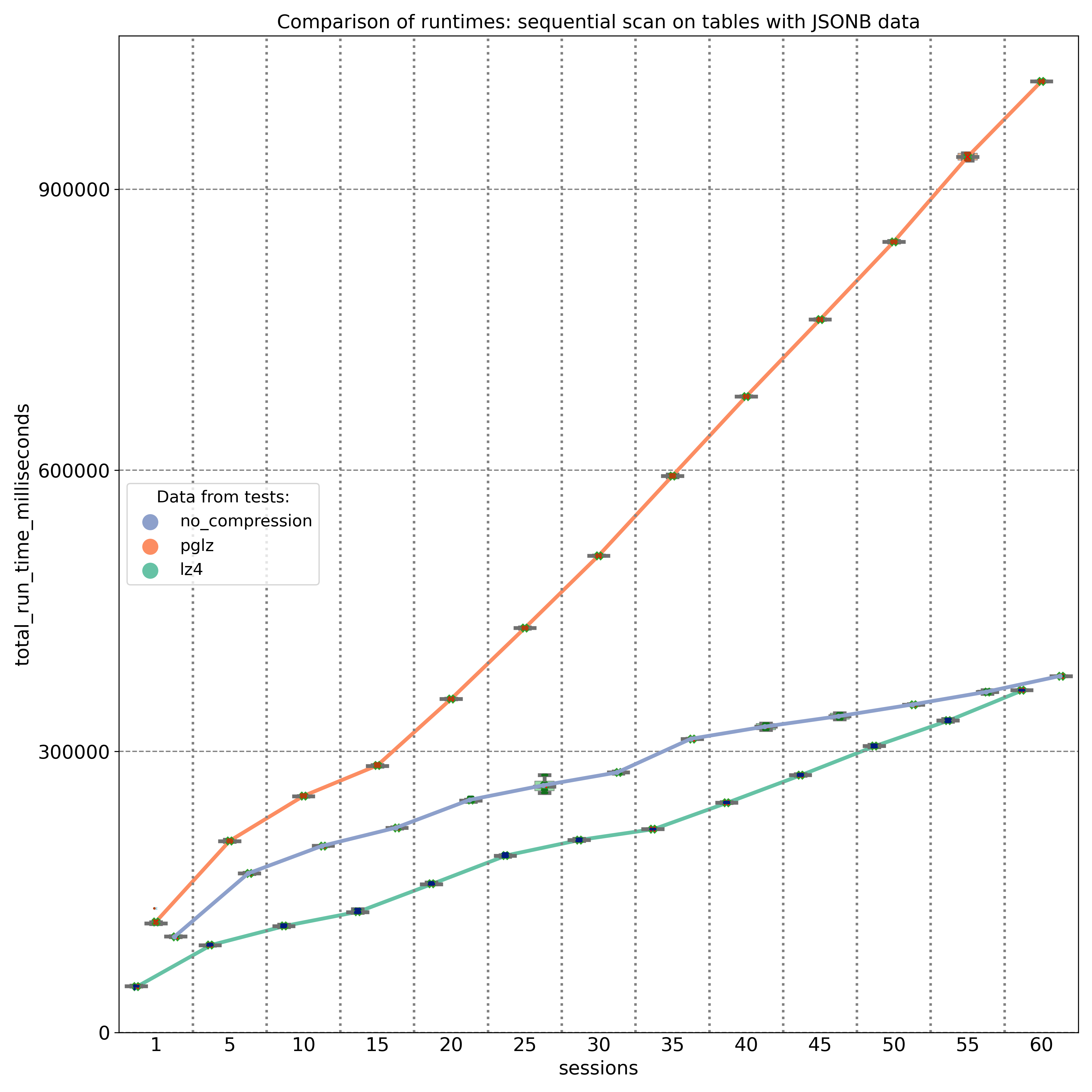
Wenn wir uns jedoch entscheiden, den Kompressionsalgorithmus zu ändern, ändert das einfache Erstellen einer neuen Tabelle mit der Einstellung default_toast_compression auf „lz4“ und das Ausführen von INSERT INTO my_table_lz4 SELECT * FROM my_table_pglz; den Kompressionsalgorithmus bestehender Datensätze nicht. Jeder bereits komprimierte Datensatz behält seinen ursprünglichen Kompressionsalgorithmus bei. Sie können die Systemfunktion pg_column_compression verwenden, um zu überprüfen, welcher Algorithmus für jeden Datensatz verwendet wurde. Die Standard-Komprimierungseinstellung gilt nur für neue, unkomprimierte Daten; alte, bereits komprimierte Daten werden unverändert kopiert.
Um alte Daten wirklich in einen anderen Kompressionsalgorithmus zu konvertieren, müssen wir sie über Text umwandeln. Für JSONB-Daten würden wir eine Abfrage wie diese verwenden: INSERT INTO my_table_lz4 (jsonb_data, …) SELECT jsonb_data::text::jsonb, … FROM my_table_pglz; Dies stellt sicher, dass alte Daten mit der neuen LZ4-Komprimierung gespeichert werden. Dieser Prozess kann jedoch zeit- und ressourcenintensiv sein, daher ist es wichtig, die Vorteile abzuwägen, bevor man ihn in Angriff nimmt.
Zusammenfassend lässt sich sagen: Meine Tests zeigten signifikante Leistungsunterschiede zwischen den Algorithmen PGLZ und LZ4 zur Speicherung komprimierter JSONB-Daten. Diese Unterschiede sind besonders ausgeprägt, wenn die Maschine unter hoher paralleler Last steht. Die Tests zeigten eine starke Leistungsverschlechterung bei Daten, die mit dem PGLZ-Algorithmus gespeichert wurden, wenn die Anzahl der parallelen Sitzungen die Anzahl der verfügbaren Kerne überschritt. In einigen Fällen schnitt PGLZ von Anfang an schlechter ab als unkomprimierte Daten. Im Gegensatz dazu übertraf LZ4 sowohl unkomprimierte als auch PGLZ-komprimierte Daten durchweg, insbesondere unter hoher Last. Die Festlegung von LZ4 als Standardkomprimierung für neue Daten scheint die richtige Wahl zu sein, und einige Cloud-Anbieter haben diesen Ansatz bereits übernommen. Diese Ergebnisse sollten jedoch nicht blind auf bestehende Daten angewendet werden. Sie sollten Ihre spezifischen Anwendungsfälle und Daten testen, um festzustellen, ob eine Konvertierung den Zeit- und Ressourcenaufwand wert ist, da die Datenkonvertierung ein Umwandeln erfordert und ein ressourcenintensiver Prozess sein kann.
Einführung
Das Ausführen von ANALYZE (entweder explizit oder über Auto-Analyze) ist sehr wichtig, um aktuelle Datenstatistiken für den Postgres-Query-Planer zu haben. Insbesondere nach In-Place-Upgrades über ANALYZE nur Teile der Blöcke in einer Tabelle abtastet, ähnelt das I/O-Muster eher einem Direktzugriff als einem sequenziellen Lesen. Version 14 von Postgres hat die Möglichkeit maintenenance_io_concurrency gesteuert, der standardmäßig auf 10 gesetzt ist (im Gegensatz zu effective_io_concurrency, der standardmäßig auf 1 gesetzt ist).
Benchmark
Um die Änderungen zwischen Version 13 und 14 zu testen und zu demonstrieren, haben wir einige kurze Benchmarks mit den aktuellen Wartungsversionen (13.16 und 14.13) auf Debian 12 mit Paketen von https://apt.postgresql.org durchgeführt. Hardwareseitig wurde ein ThinkPad T14s Gen 3 mit einer Intel i7-1280P CPU mit 20 Kernen und 32 GB RAM verwendet. Die Basis ist eine pgbench-Datenbank, die mit einem Skalierungsfaktor von 1000 initialisiert wurde:
$ pgbench -i -I dtg -s 1000 -d pgbenchDadurch werden 100 Millionen Zeilen erstellt, was zu einer Datenbankgröße von etwa 15 GB führt. Um pgbench_accounts:
$ vacuumdb -Z -v -d pgbench -t pgbench_accounts
INFO: analyzing "public.pgbench_accounts"
INFO: "pgbench_accounts": scanned 300000 of 1639345 pages,
containing 18300000 live rows and 0 dead rows;
300000 rows in sample, 100000045 estimated total rowsZwischen den Durchläufen wird der Dateisystem-Seitencache über echo 3 | sudo tee /proc/sys/vm/drop_caches gelöscht und alle Durchläufe werden dreimal wiederholt. Die folgende Tabelle listet die Laufzeiten (in Sekunden) des obigen vacuumdb-Befehls für verschiedene Einstellungen von maintenance_io_concurrency auf:
| Version | 0 | 1 | 5 | 10 | 20 | 50 | 100 | 500 |
|---|---|---|---|---|---|---|---|---|
| 13 | 19.557 | 21.610 | 19.623 | 21.060 | 21.463 | 20.533 | 20.230 | 20.537 |
| 14 | 24.707 | 29.840 | 8.740 | 5.777 | 4.067 | 3.353 | 3.007 | 2.763 |
Analyse
Zwei Dinge gehen aus diesen Zahlen deutlich hervor: Erstens ändern sich die Laufzeiten für Version 13 nicht, der Wert von maintenance_io_concurrency hat für diese Version keine Auswirkung. Zweitens, sobald das Prefetching für Version 14 einsetzt (maintenance_io_concurrency=0) oder nur auf 1 gesetzt ist, schlechter sind als bei Version 13, aber da der Standardwert für maintenance_io_concurrency 10 ist, sollte dies in der Praxis niemanden betreffen.
Fazit
Das Aktivieren von Prefetching für ANALYZE in Version 14 von PostgreSQL hat die Statistikabtastung erheblich beschleunigt. Der Standardwert von 10 für ANALYZE.
Am Donnerstag, den 27. Juni, und Freitag, den 28. Juni 2024, hatte ich die großartige Gelegenheit, am Swiss PGDay 2024 teilzunehmen. Die Konferenz fand an der OST Ostschweizer Fachhochschule, Campus Rapperswil, statt, die wunderschön am Ufer des Zürichsees in einer schönen, grünen Umgebung gelegen ist. Mit etwa 110 Teilnehmern hatte die Veranstaltung hauptsächlich einen B2B-Fokus, wenn auch nicht ausschließlich. Obwohl die Konferenz im Vergleich zu PostgreSQL-Veranstaltungen in größeren Ländern scheinbar kleiner war, spiegelte sie doch perfekt den für die Schweiz relevanten Umfang wider.
Während der Konferenz hielt ich meinen Vortrag „GIN, BTREE_GIN, GIST, BTREE_GIST, HASH & BTREE Indexes on JSONB Data“. Der Vortrag fasste die Ergebnisse meines Langzeitprojekts bei NetApp zusammen, einschließlich neuerer interessanter Erkenntnisse im Vergleich zu der Präsentation,
Ganz am Ende am Freitag hielt ich auch einen Lightning Talk, „Kann PostgreSQL eine prominentere Rolle im KI-Boom spielen?“ (meine Folien befinden sich am Ende der Datei). In diesem kurzen Vortrag stellte ich die Frage, ob es möglich wäre, KI-Funktionalitäten direkt in PostgreSQL zu implementieren, einschließlich der Speicherung von Embedding-Modellen und trainierten neuronalen Netzen innerhalb der Datenbank. Mehrere Personen im Publikum, die mit ML/KI befasst sind, reagierten positiv auf diesen Vorschlag und bestätigten, dass PostgreSQL tatsächlich eine wichtigere Rolle in ML- und KI-Themen spielen könnte.
Die Konferenz bot zwei Vortragsreihen, eine auf Englisch und die andere auf Deutsch, was eine vielfältige Auswahl an Themen und Referenten ermöglichte. Einige davon möchte ich hervorheben:
- Tomas Vondra präsentierte „The Past and the Future of the Postgres Community“, wobei er erklärte, wie die Arbeit an PostgreSQL-Änderungen und -Korrekturen in Commitfests organisiert ist und zukünftige Entwicklungsideen innerhalb der Community diskutierte.
- Laurenz Albes Vortrag, „Sicherheitsattacken auf PostgreSQL“, beleuchtete mehrere potenzielle Angriffsvektoren in PostgreSQL und erregte mit überraschenden Beispielen große Aufmerksamkeit.
- Chris Engelberts Präsentation, „PostgreSQL on Kubernetes: Dos and Don’ts“, behandelte die Hauptprobleme im Zusammenhang mit dem Betrieb von PostgreSQL auf Kubernetes und diskutierte Lösungen, einschließlich der Vor- und Nachteile bestehender PostgreSQL Kubernetes Operatoren.
- Maurizio De Giorgi und Ismael Posada Trobo diskutierten „Solving PostgreSQL Connection Scalability Issues: Insights from CERN’s GitLab Service“ und erläuterten die Herausforderungen und Lösungen für die Skalierbarkeit in CERNs riesiger Datenbankumgebung.
- Dirk Krautschicks Vortrag, „Warum sich PostgreSQL-Fans auch für Kafka und Debezium interessieren sollten?“, zeigte Beispiele für die Verwendung von Debezium-Konnektoren und Kafka mit PostgreSQL für verschiedene Anwendungsfälle, einschließlich Datenmigrationen.
- Patrick Stählin diskutierte „Wie wir einen Datenkorruptions-Bug mit der Hilfe der Community gefunden und gefixt haben“, wobei er Probleme mit Free-Space-Map-Dateien nach der Migration auf PostgreSQL 16 ansprach.
- Marion Baumgartners Präsentation, „Geodaten-Management mit PostGIS“, lieferte interessante Details zur Verarbeitung von Geodaten in PostgreSQL mithilfe der PostGIS-Erweiterung.
- Prof. Stefan Keller, einer der Hauptorganisatoren und Professor für Data Engineering an der OST Universität Rapperswil, präsentierte „PostgreSQL: A Reliable and Extensible Multi-Model SQL Database“, wobei er die Multi-Modell-Struktur von PostgreSQL inmitten des schwindenden Interesses an NoSQL-Lösungen diskutierte.
- Luigi Nardi von DBTune präsentierte „Lessons Learned from Autotuning PostgreSQL“ und beschrieb ein KI-basiertes Performance-Tuning-Tool, das von seinem Unternehmen entwickelt wurde.
- Kanhaiya Lal und Belma Canik gingen auf „Beyond Keywords: AI-powered Text Search with pgvector for PostgreSQL“ ein und untersuchten die Verwendung der pgvector-Erweiterung zur Verbesserung der Volltextsuchfunktionen in PostgreSQL.
- Gabriele Bartolini, der Entwickler des PostgreSQL Kubernetes Operators „CloudNativePG“, diskutierte in seinem Vortrag „Unleashing the Power of PostgreSQL in Kubernetes“ die Geschichte und Fähigkeiten dieses Operators.
Am Ende des ersten Tages wurden alle Teilnehmer zu einem Social Event zum Networking und persönlichen Austausch eingeladen, das sehr gut organisiert war. Ich möchte die harte Arbeit und das Engagement aller Organisatoren würdigen und ihnen für ihre Bemühungen danken. Der Swiss PGDay 2024 war wirklich eine unvergessliche und wertvolle Erfahrung, die großartige Lernmöglichkeiten bot. Ich bin dankbar für die Gelegenheit, an der Konferenz teilzunehmen und dazu beizutragen, und ich freue mich auf zukünftige Ausgaben dieser Veranstaltung. Ich bin auch NetApp-credativ sehr dankbar, dass sie meine Teilnahme an der Konferenz ermöglicht haben.
Fotos von Organisatoren, Gülçin Yıldırım Jelínek und Autor:






On Wednesday, June 5th, I attended the Prague PostgreSQL Developers Day 2024. It is the leading PostgreSQL conference in the Czech Republic, which took place for the 16th time this year. Die Veranstaltung fand in der modernen und komfortablen Umgebung der Tschechischen Technischen Universität statt und wurde von fast 270 Teilnehmern besucht.
Während der Konferenz hielt ich meinen Vortrag „GIN-, BTREE_GIN-, GIST- und BTREE-Indizes für JSONB-Daten”. Dieser Vortrag fasste die aktuellen Ergebnisse meines Projekts bei NetApp (credativ) zusammen, das ich initiiert habe, um unser Verständnis dieser Indizierungsmethoden und ihrer Leistungsergebnisse zu vertiefen. Unser Ziel ist es, unseren Kunden relevante und wertvolle Lösungen anzubieten, die häufig Schwierigkeiten bei der Implementierung von JSONB-Spalten und -Operationen in ihre Anwendungen haben und die verfügbaren Informationen als unzureichend empfinden. Selbst bestehende KI-Modelle sind unzureichend, da sie sich auf dieselben begrenzten öffentlich zugänglichen Daten stützen. Das Projekt konzentriert sich auf JSONB-Daten, jedoch haben die Ergebnisse bereits gezeigt, dass es über diesen Datentyp hinaus anwendbar ist. Die positiven Reaktionen des Publikums zeigten, dass meine Präsentation gut angekommen war. Die Konferenz ist eine zweisprachige Veranstaltung mit Vorträgen auf Tschechisch und Englisch. Da ich aus Tschechien komme, hielt ich meinen Vortrag auf Tschechisch, verwendete jedoch englische Folien.
Die Konferenz bot den ganzen Tag über auch sieben weitere aufschlussreiche Vorträge. Der erste Vortrag von Jan Karremans von Cybertec befasste sich mit dem CloudNativePG-Operator, der PostgreSQL für den Betrieb auf Kubernetes implementiert. Der zweite Vortrag von Jakub Zemanek von initMax bot eine detaillierte Anleitung zur
Die Konferenz war sehr gut organisiert, und ich spreche Tomas Vondra und den anderen Organisatoren meinen Dank für ihre harte Arbeit aus. Insgesamt war es eine sehr erfolgreiche Veranstaltung, gefüllt mit wertvollen Erkenntnissen, anregenden Diskussionen und Networking-Möglichkeiten. Ich freue mich darauf, das hier gewonnene Wissen anzuwenden, und bin gespannt auf zukünftige Ausgaben der P2D2-Konferenz.
Nützliche Links:
- Vorträge des Prague PostgreSQL Developer Day 2024 – Zusammenfassungen mit Links zu den Folien (Englisch / Tschechisch)
- Rückblick auf den Prague PostgreSQL Developer Day 2024 – Tomas Vondra (Englisch)
Fotos von Tomas Vondra (EDB):

Die Deutsche Postgres Konferenz fand dieses Jahr zum 8. Mal statt, dieses Mal am 12. April in München. Es war die bisher größte PGConf.DE mit 270 Registrierungen, 16 mehr als letztes Jahr. Auf der Konferenz waren wir mit sieben Kollegen vertreten, sodass wir uns über die drei parallelen Tracks plus einen Sponsor-Track aufteilen konnten. Einer der drei Tracks hatte deutschsprachige Vorträge, wo auch Michael Banck in seinem Vortrag die drei führenden Cloud Provider (Amazon RDS, Google Cloud SQL, Microsoft Azure Database) miteinander verglich zudem es auch positives Feedback gab.

Michael Banck bei seinem Vortrag – PostgreSQL-As-A-Service: Vergleich von Cloud Providern
Simon Riggs, eine wichtige Person in der PostgreSQL-Community verstarb leider zwei Wochen vor der Konferenz. In den Vorträgen gab es große Anteilnahme an seinem Verlust und Gülçin Jelinek gedachte seiner gleich zu Beginn der Konferenz. Das letzte mal trafen wir ihn Ende 2023 in Prag auf der PGConf.EU, wo er die Keynote hielt.
Am Tag vor der Konferenz nahm mein Kollege Michael Banck an dem zweiten Patroni Contributor Meeting teil. Das erste Meeting war letztes Jahr vor der letzten Deutschen Postgres Konferenz in Essen. Zu dem Treffen kamen die beiden Patroni-Maintainer Alexander Kukushkin und Polina Bungina, sowie Verteter von EnterpriseDB, Cybertec und Data Egret. Es wurden einige organisatorische Fragen (z.B. über das Logo) geklärt, die Roadmap besprochen sowie einige vorgeschlagene Features für Multi-Site Patroni diskutiert. Nach dem Patroni Meeting war am Abend das Organiser- und Speaker-Dinner im Gasthaus Eder in der Nähe des Konferenz-Hotels.
Der Feature Freeze für PostgreSQL 17 war nur wenige Tage vor der Konferenz am 08. April. Daher wurden die damit verbundenen Verbesserungen in den Vorträgen berücksichtigt oder befassten sich vollständig mit einem neuen Feature. Dazu zählen unter anderem native inkrementelle Backups und Migration von logical replication Slots bei Major Upgrades. Die Veröffentlichung von PostgreSQL 17 ist für September geplant. Bis dahin könnten einzelne Features noch entfernt werden, falls Probleme auftreten, die nicht rechtzeitig gelöst werden können.
Insgesamt war die Qualität der Vorträge sehr hoch, sodass man aus jedem Vortrag etwas interessantes mitnehmen konnte. Deshalb freuen wir uns bereits auf die kommende PGConf.EU im Oktober in Athen.
Übersicht
Tabellen, die bei Bedarf erstellt und gelöscht werden, ob temporär oder regulär, werden von Anwendungsentwicklern in PostgreSQL häufig verwendet, um die Implementierung verschiedener Funktionalitäten zu vereinfachen und Antworten zu beschleunigen. Zahlreiche Artikel im Internet beschreiben die Vorteile der Verwendung solcher Tabellen zum Speichern von Suchergebnissen, zum Vorberechnen von Zahlen für Berichte, zum Importieren von Daten aus externen Dateien und mehr. Man kann sogar eine TEMP TABLE mit der Bedingung ON COMMIT DROP definieren, wodurch das System automatisch bereinigen kann. Wie die meisten Dinge hat diese Lösung jedoch potenzielle Nachteile, da die Größe eine Rolle spielt. Eine Lösung, die für Dutzende paralleler Sitzungen reibungslos funktioniert, kann plötzlich unerwartete Probleme verursachen, wenn die Anwendung während der Stoßzeiten von Hunderten oder Tausenden von Benutzern gleichzeitig verwendet wird. Das häufige Erstellen und Löschen von Tabellen und verwandten Objekten kann zu einer erheblichen Aufblähung bestimmter PostgreSQL-Systemtabellen führen. Dies ist ein bekanntes Problem, das in vielen Artikeln erwähnt wird, denen es jedoch oft an detaillierten Erklärungen und einer Quantifizierung der Auswirkungen mangelt. Mehrere pg_catalog-Systemtabellen können erheblich aufgebläht werden. Die Tabelle pg_attribute ist am stärksten betroffen, gefolgt von pg_attrdef und pg_class.
Was ist das Hauptproblem bei der Aufblähung von Systemtabellen?
Wir sind bereits in den PostgreSQL-Protokollen eines unserer Kunden auf dieses Problem gestoßen. Als die Aufblähung der Systemtabellen zu groß wurde, beschloss PostgreSQL, während eines Autovacuum-Vorgangs freien Speicherplatz zurückzugewinnen. Diese Aktion verursachte exklusive Sperren auf der Tabelle und blockierte alle anderen Operationen für mehrere Sekunden. PostgreSQL konnte keine Informationen über die Strukturen aller Beziehungen lesen. Infolgedessen mussten selbst die einfachsten Select-Operationen verzögert werden, bis die Operation abgeschlossen war. Dies ist natürlich ein extremes und seltenes Szenario, das nur unter außergewöhnlich hoher Last auftreten kann. Dennoch ist es wichtig, sich dessen bewusst zu sein und beurteilen zu können, ob dies auch in unserer Datenbank passieren könnte.
Beispiel für eine Berichtstabelle in einer Buchhaltungssoftware
CREATE TEMP TABLE pivot_temp_table ( id serial PRIMARY KEY, inserted_at timestamp DEFAULT current_timestamp, client_id INTEGER, name text NOT NULL, address text NOT NULL, loyalty_program BOOLEAN DEFAULT false, loyalty_program_start TIMESTAMP, orders_202301_count_of_orders INTEGER DEFAULT 0, orders_202301_total_price NUMERIC DEFAULT 0, ... orders_202312_count_of_orders INTEGER DEFAULT 0, orders_202312_total_price NUMERIC DEFAULT 0);
CREATE INDEX pivot_temp_table_idx1 ON pivot_temp_table (client_id); CREATE INDEX pivot_temp_table_idx2 ON pivot_temp_table (name); CREATE INDEX pivot_temp_table_idx3 ON pivot_temp_table (loyalty_program); CREATE INDEX pivot_temp_table_idx4 ON pivot_temp_table (loyalty_program_start);
- Eine temporäre Tabelle, pivot_temp_table, mit 31 Spalten, von denen 27 Standardwerte haben.
- Einige der Spalten haben den Datentyp TEXT, was zur automatischen Erstellung einer TOAST-Tabelle führt.
- Die TOAST-Tabelle benötigt einen Index für chunk_id und chunk_seq.
- Die ID ist der Primärschlüssel, was bedeutet, dass automatisch ein eindeutiger Index für die ID erstellt wurde.
- Die ID ist als SERIAL definiert, was zur automatischen Erstellung einer Sequenz führt, die im Wesentlichen eine weitere Tabelle mit einer speziellen Struktur ist.
- Wir haben auch vier zusätzliche Indizes für unsere temporäre Tabelle definiert.
Lassen Sie uns nun untersuchen, wie diese Beziehungen in PostgreSQL-Systemtabellen dargestellt werden.
Tabelle pg_attribute
- Jede Zeile in unserer pivot_temp_table enthält sechs versteckte Spalten (tableoid, cmax, xmax, cmin, xmin, ctid) und 31 ’normale‘ Spalten. Dies ergibt insgesamt 37 eingefügte Zeilen für die temporäre Haupttabelle.
- Indizes fügen für jede im Index verwendete Spalte eine Zeile hinzu, was in unserem Fall fünf Zeilen entspricht.
- Es wurde automatisch eine TOAST-Tabelle erstellt. Sie hat sechs versteckte Spalten und drei normale Spalten (chunk_id, chunk_seq, chunk_data) sowie einen Index für chunk_id und chunk_seq, was insgesamt 11 Zeilen ergibt.
- Es wurde eine Sequenz für die ID erstellt, die im Wesentlichen eine weitere Tabelle mit einer vordefinierten Struktur ist. Sie hat sechs versteckte Spalten und drei normale Spalten (last_value, log_cnt, is_called), was weitere neun Zeilen hinzufügt.
Tabelle pg_attrdef
SELECT c.relname as table_name, o.rolname as table_owner, c.relkind as table_type, a.attname as column_name, a.attnum as column_number, a.atttypid::regtype as column_data_type, pg_get_expr(adbin, adrelid) as sql_command FROM pg_attrdef ad JOIN pg_attribute a ON ad.adrelid = a.attrelid AND ad.adnum = a.attnum JOIN pg_class c ON c.oid = ad.adrelid JOIN pg_authid o ON o.oid = c.relowner WHERE c.relname = 'pivot_temp_table' ORDER BY table_name, column_number;
table_name | table_owner | table_type | column_name | column_number | column_data_type | sql_command
------------------+-------------+------------+-------------------------------+---------------+-----------------------------+----------------------------------------------
pivot_temp_table | postgres | r | id | 1 | integer | nextval('pivot_temp_table_id_seq'::regclass)
pivot_temp_table | postgres | r | inserted_at | 2 | timestamp without time zone | CURRENT_TIMESTAMP
pivot_temp_table | postgres | r | loyalty_program | 6 | boolean | false
pivot_temp_table | postgres | r | orders_202301_count_of_orders | 8 | integer | 0
pivot_temp_table | postgres | r | orders_202301_total_price | 9 | numeric | 0
--> bis zur Spalte "orders_202312_total_price"
Tabelle pg_class
Die Tabelle pg_class speichert primäre Informationen über Beziehungen. Dieses Beispiel erstellt neun Zeilen: eine für die temporäre Tabelle, eine für die Toast-Tabelle, eine für den Toast-Tabellenindex, eine für den eindeutigen Index des ID-Primärschlüssels, eine für die Sequenz und vier für die benutzerdefinierten Indizes.
Zusammenfassung dieses Beispiels
Unser erstes Beispiel erzeugte eine scheinbar kleine Anzahl von Zeilen – 62 in pg_attribute, 27 in pg_attrdef und 9 in pg_class. Dies sind sehr niedrige Zahlen, und wenn eine solche Lösung nur von einem Unternehmen verwendet würde, würden wir kaum Probleme sehen. Stellen Sie sich jedoch ein Szenario vor, in dem ein Unternehmen Buchhaltungssoftware für kleine Unternehmen hostet und Hunderte oder sogar Tausende von Benutzern die App während der Stoßzeiten nutzen. In einer solchen Situation würden viele temporäre Tabellen und verwandte Objekte relativ schnell erstellt und gelöscht. In der Tabelle pg_attribute könnten wir innerhalb weniger Stunden zwischen einigen Tausend und sogar Hunderttausenden von Datensätzen sehen, die eingefügt und dann gelöscht werden. Dies ist jedoch immer noch ein relativ kleiner Anwendungsfall. Lassen Sie uns nun etwas noch Größeres vorstellen und benchmarken.
Beispiel für einen Online-Shop
- Die Tabelle „session_events“ speichert ausgewählte Aktionen, die der Benutzer während der Sitzung durchgeführt hat. Ereignisse werden für jede Aktion erfasst, die der Benutzer auf der Website ausführt, sodass mindestens Hunderte, aber häufig Tausende von Ereignissen aus einer Sitzung aufgezeichnet werden. Diese werden alle parallel in die Hauptereignistabelle gesendet. Die Haupttabelle ist jedoch enorm. Daher speichert diese benutzerspezifische Tabelle nur einige Ereignisse, was eine schnelle Analyse der letzten Aktivitäten usw. ermöglicht. Die Tabelle hat 25 verschiedene Spalten, von denen einige vom Typ TEXT und eine Spalte vom Typ JSONB sind – was bedeutet, dass eine TOAST-Tabelle mit einem Index erstellt wurde. Die Tabelle hat einen Primärschlüssel vom Typ Serial, der die Reihenfolge der Aktionen angibt – d. h. ein eindeutiger Index, eine Sequenz und ein Standardwert wurden erstellt. Es gibt keine zusätzlichen Standardwerte. Die Tabelle hat auch drei zusätzliche Indizes für einen schnelleren Zugriff, jeder für eine Spalte. Ihr Nutzen könnte fraglich sein, aber sie sind Teil der Implementierung.
- Zusammenfassung der Zeilen in Systemtabellen – pg_attribute – 55 Zeilen, pg_class – 8 Zeilen, pg_attrdef – 1 Zeile
- Die Tabelle „last_visited“ speichert eine kleine Teilmenge von Ereignissen aus der Tabelle „session_events“, um schnell anzuzeigen, welche Artikel der Benutzer während dieser Sitzung besucht hat. Entwickler haben sich aus Gründen der Bequemlichkeit für diese Implementierung entschieden. Die Tabelle ist klein und enthält nur 10 Spalten, aber mindestens eine ist vom Typ TEXT. Daher wurde eine TOAST-Tabelle mit einem Index erstellt. Die Tabelle hat einen Primärschlüssel vom Typ TIMESTAMP, daher hat sie einen eindeutigen Index, einen Standardwert, aber keine Sequenz. Es gibt keine zusätzlichen Indizes.
- Zeilen in Systemtabellen – pg_attribute – 28 Zeilen, pg_class – 4 Zeilen, pg_attrdef – 1 Zeile
- Die Tabelle „last_purchases“ wird beim Anmelden aus der Haupttabelle gefüllt, die alle Käufe speichert. Diese benutzerspezifische Tabelle enthält die letzten 50 Artikel, die der Benutzer in früheren Sitzungen gekauft hat, und wird vom Empfehlungsalgorithmus verwendet. Diese Tabelle enthält vollständig denormalisierte Daten, um ihre Verarbeitung und Visualisierung zu vereinfachen, und hat daher 35 Spalten. Viele dieser Spalten sind vom Typ TEXT, sodass eine TOAST-Tabelle mit einem Index erstellt wurde. Der Primärschlüssel dieser Tabelle ist eine Kombination aus dem Kaufzeitstempel und der Ordnungszahl des Artikels in der Bestellung, was zur Erstellung eines eindeutigen Index, aber keiner Standardwerte oder Sequenzen führt. Im Laufe der Zeit hat der Entwickler vier Indizes für diese Tabelle für verschiedene Sortierzwecke erstellt, jeder für eine Spalte. Der Wert dieser Indizes kann in Frage gestellt werden, aber sie existieren immer noch.
- Zeilen in Systemtabellen – pg_attribute – 57 Zeilen, pg_class – 8 Zeilen
- Die Tabelle „selected_but_not_purchased“ wird beim Anmelden aus der entsprechenden Haupttabelle gefüllt. Sie zeigt die letzten 50 Artikel an, die noch im Shop verfügbar sind, die der Benutzer zuvor in Betracht gezogen hat, aber später aus dem Warenkorb entfernt oder die Bestellung überhaupt nicht abgeschlossen hat, und der Inhalt des Warenkorbs ist abgelaufen. Diese Tabelle wird vom Empfehlungsalgorithmus verwendet und hat sich als erfolgreiche Ergänzung der Marketingstrategie erwiesen, die die Käufe um einen bestimmten Prozentsatz erhöht. Die Tabelle hat die gleiche Struktur und verwandte Objekte wie „last_purchases“. Die Daten werden getrennt von den Käufen gespeichert, um Fehler bei der Dateninterpretation zu vermeiden, und auch, weil dieser Teil des Algorithmus viel später implementiert wurde.
- Zeilen in Systemtabellen – pg_attribute – 57 Zeilen, pg_class – 8 Zeilen
- Die Tabelle „cart_items“ speichert Artikel, die für den Kauf in der aktuellen Sitzung ausgewählt, aber noch nicht gekauft wurden. Diese Tabelle wird mit der Haupttabelle synchronisiert, aber auch eine lokale Kopie in der Sitzung wird verwaltet. Die Tabelle enthält normalisierte Daten und hat daher nur 15 Spalten, von denen einige vom Typ TEXT sind, was zur Erstellung einer TOAST-Tabelle mit einem Index führt. Sie hat eine Primärschlüssel-ID vom Typ UUID, um Kollisionen über alle Benutzer hinweg zu vermeiden, was zur Erstellung eines eindeutigen Index und eines Standardwerts, aber keiner Sequenz führt. Es gibt keine zusätzlichen Indizes.
- Zeilen in Systemtabellen – pg_attribute – 33 Zeilen, pg_class – 4 Zeilen, pg_attrdef – 1 Zeile
Die Erstellung all dieser benutzerspezifischen Tabellen führt zum Einfügen der folgenden Anzahl von Zeilen in die PostgreSQL-Systemtabellen – pg_attribute: 173 Zeilen, pg_class: 32 Zeilen, pg_attrdef: 3 Zeilen.
Analyse des Datenverkehrs
Als ersten Schritt stellen wir eine Analyse des Business Use Case und der Saisonalität des Datenverkehrs bereit. Stellen wir uns vor, unser Einzelhändler ist in mehreren EU-Ländern tätig und richtet sich hauptsächlich an Personen im Alter von 15 bis 35 Jahren. Der Online-Shop ist relativ neu und hat derzeit 100.000 Konten. Basierend auf Whitepapers, die im Internet verfügbar sind, können wir folgende Benutzeraktivität annehmen:
| Aktivitätsniveau des Benutzers | Verhältnis der Benutzer [%] | Gesamtzahl der Benutzer | Besuchshäufigkeit auf der Seite |
|---|---|---|---|
| sehr aktiv | 10% | 10.000 | 2x bis 4x pro Woche |
| normale Aktivität | 30% | 30.000 | ~1 Mal pro Woche |
| geringe Aktivität | 40% | 40.000 | 1x bis 2x pro Monat |
| fast keine Aktivität | 20% | 20.000 | wenige Male im Jahr |
Da es sich um einen Online-Shop handelt, ist der Datenverkehr stark saisonabhängig. Artikel werden hauptsächlich von Einzelpersonen für den persönlichen Gebrauch gekauft. Daher überprüfen sie den Shop während des Arbeitstages zu ganz bestimmten Zeiten, z. B. während der Reise oder der Mittagspause. Der Hauptverkehr während des Arbeitstages liegt zwischen 19:00 und 21:00 Uhr. Freitage haben in der Regel einen viel geringeren Datenverkehr, und das Wochenende folgt diesem Beispiel. Die verkehrsreichsten Tage sind in der Regel am Ende des Monats, wenn die Leute ihr Gehalt erhalten. Der Shop verzeichnet den stärksten Datenverkehr am Thanksgiving Thursday und am Black Friday. Die übliche Praxis in den letzten Jahren ist es, den Shop für ein oder zwei Stunden zu schließen und dann zu einer bestimmten Stunde mit reduzierten Preisen wieder zu eröffnen. Dies führt zu einer großen Anzahl von Beziehungen, die in relativ kurzer Zeit erstellt und später gelöscht werden. Die Dauer der Verbindung eines Benutzers kann von wenigen Minuten bis zu einer halben Stunde reichen. Benutzerspezifische Tabellen werden erstellt, wenn sich der Benutzer im Shop anmeldet. Sie werden später von einem speziellen Prozess gelöscht, der einen ausgeklügelten Algorithmus verwendet, um zu bestimmen, ob Beziehungen bereits abgelaufen sind oder nicht. Dieser Prozess umfasst verschiedene Kriterien und wird in unterschiedlichen Abständen ausgeführt, sodass wir eine große Anzahl von Beziehungen sehen können, die in einem Durchgang gelöscht werden. Lassen Sie uns diese Beschreibungen quantifizieren:
| Datenverkehr an verschiedenen Tagen | Anmeldungen pro 30 min | pg_attribute [Zeilen] | pg_class [Zeilen] | pg_attrdef [Zeilen] |
|---|---|---|---|---|
| Zahlen aus der Analyse pro 1 Benutzer | 1 | 173 | 32 | 3 |
| Durchschnittlicher Datenverkehr am Nachmittag | 1.000 | 173.000 | 32.000 | 3.000 |
| Normaler Arbeitstagabend mit hohem Datenverkehr | 3.000 | 519.000 | 96.000 | 9.000 |
| Abend nach Gehaltszahlung, geringer Datenverkehr | 8.000 | 1.384.000 | 256.000 | 24.000 |
| Abend nach Gehaltszahlung, hoher Datenverkehr | 15.000 | 2.595.000 | 480.000 | 45.000 |
| Singles‘ Day, Abenderöffnung | 40.000 | 6.920.000 | 1.280.000 | 120.000 |
| Thanksgiving Donnerstag, Abenderöffnung | 60.000 | 10.380.000 | 1.920.000 | 180.000 |
| Black Friday, Abenderöffnung | 50.000 | 8.650.000 | 1.600.000 | 150.000 |
| Black Friday Wochenende, höchster Datenverkehr | 20.000 | 3.460.000 | 640.000 | 60.000 |
| Theoretisches Maximum – alle Benutzer verbunden | 100.000 | 17.300.000 | 3.200.000 | 300.000 |
Jetzt können wir sehen, was Skalierbarkeit bedeutet. Unsere Lösung wird an normalen Tagen definitiv angemessen funktionieren. Der Datenverkehr an den Abenden, nachdem die Leute ihr Gehalt erhalten haben, kann jedoch sehr hoch sein. Thanksgiving Donnerstag und Black Friday testen die Grenzen wirklich aus. Zwischen 1 und 2 Millionen benutzerspezifische Tabellen und zugehörige Objekte werden an diesen Abenden erstellt und gelöscht. Und was passiert, wenn unser Shop noch erfolgreicher wird und die Anzahl der Konten auf 500 000, 1 Million oder mehr ansteigt? Die Lösung würde an einigen Stellen definitiv an die Grenzen der vertikalen Skalierung stoßen, und wir müssten über Möglichkeiten nachdenken, sie horizontal zu skalieren.
Wie man Bloat untersucht
WITH tablenames AS (SELECT tablename FROM (VALUES('pg_attribute'),('pg_attrdef'),('pg_class')) as t(tablename))
SELECT
tablename,
now() as checked_at,
pg_relation_size(tablename) as relation_size,
pg_relation_size(tablename) / (8*1024) as relation_pages,
a.*,
s.*
FROM tablenames t
JOIN LATERAL (SELECT * FROM pgstattuple(t.tablename)) s ON true
JOIN LATERAL (SELECT last_autovacuum, last_vacuum, last_autoanalyze, last_analyze, n_live_tup, n_dead_tup
FROM pg_stat_all_tables WHERE relname = t.tablename) a ON true
ORDER BY tablename
tablename | pg_attribute checked_at | 2024-02-18 10:46:34.348105+00 relation_size | 44949504 relation_pages | 5487 last_autovacuum | 2024-02-16 20:07:15.7767+00 last_vacuum | 2024-02-16 20:55:50.685706+00 last_autoanalyze | 2024-02-16 20:07:15.798466+00 last_analyze | 2024-02-17 22:05:43.19133+00 n_live_tup | 3401 n_dead_tup | 188221 table_len | 44949504 tuple_count | 3401 tuple_len | 476732 tuple_percent | 1.06 dead_tuple_count | 107576 dead_tuple_len | 15060640 dead_tuple_percent| 33.51 free_space | 28038420 free_percent | 62.38
WITH pages AS (
SELECT * FROM generate_series(0, (SELECT pg_relation_size('pg_attribute') / 8192) -1) as pagenum),
tuples_per_page AS (
SELECT pagenum, nullif(sum((t_xmin is not null)::int), 0) as tuples_per_page
FROM pages JOIN LATERAL (SELECT * FROM heap_page_items(get_raw_page('pg_attribute',pagenum))) a ON true
GROUP BY pagenum)
SELECT
count(*) as pages_total,
min(tuples_per_page) as min_tuples_per_page,
max(tuples_per_page) as max_tuples_per_page,
round(avg(tuples_per_page),0) as avg_tuples_per_page,
mode() within group (order by tuples_per_page) as mode_tuples_per_page
FROM tuples_per_page
pages_total | 5487 min_tuples_per_page | 1 max_tuples_per_page | 55 avg_tuples_per_page | 23 mode_tuples_per_page | 28
Hier können wir sehen, dass wir in unserer pg_attribute-Systemtabelle durchschnittlich 23 Tupel pro Seite haben. Jetzt können wir die theoretische Größenzunahme dieser Tabelle für unterschiedlichen Datenverkehr berechnen. Die typische Größe dieser Tabelle beträgt in der Regel nur wenige hundert MB. Ein theoretischer Bloat von etwa 3 GB während der Black Friday Tage ist also eine ziemlich bedeutende Zahl für diese Tabelle.
| Logins | pg_attribute Zeilen | Datenseiten | Größe in MB |
|---|---|---|---|
| 1 | 173 | 8 | 0.06 |
| 1.000 | 173.000 | 7.522 | 58.77 |
| 3.000 | 519.000 | 22.566 | 176.30 |
| 15.000 | 2.595.000 | 112.827 | 881.46 |
| 20.000 | 3.460.000 | 150.435 | 1.175.27 |
| 60.000 | 10.380.000 | 451.305 | 3.525.82 |
| 100.000 | 17.300.000 | 752.174 | 5.876.36 |
Zusammenfassung
Wir haben ein Reporting-Beispiel aus einer Buchhaltungssoftware und ein Beispiel für benutzerspezifische Tabellen aus einem Online-Shop vorgestellt. Obwohl beide theoretisch sind, soll die Idee Muster veranschaulichen. Wir haben auch den Einfluss der saisonalen Hochsaison auf die Anzahl der Einfügungen und Löschungen in Systemtabellen diskutiert. Wir haben ein Beispiel für eine extrem erhöhte Last in einem Online-Shop an großen Verkaufstagen gegeben. Wir glauben, dass die Ergebnisse der Analyse Aufmerksamkeit verdienen. Es ist auch wichtig zu bedenken, dass die ohnehin schon schwierige Situation in diesen Spitzenzeiten noch schwieriger sein kann, wenn unsere Anwendung auf einer Instanz mit niedrigen Festplatten-IOPS läuft. All diese neuen Objekte würden Schreibvorgänge in WAL-Protokolle und die Synchronisierung mit der Festplatte verursachen. Bei geringem Festplattendurchsatz kann es zu erheblichen Latenzzeiten kommen, und viele Operationen können erheblich verzögert werden. Was ist also die Quintessenz dieser Geschichte? Erstens sind die Autovacuum-Prozesse von PostgreSQL so konzipiert, dass sie die Auswirkungen auf das System minimieren. Wenn die Autovacuum-Einstellungen in unserer Datenbank gut abgestimmt sind, werden wir in den meisten Fällen keine Probleme feststellen. Wenn diese Einstellungen jedoch veraltet sind, auf einen viel geringeren Datenverkehr zugeschnitten sind und unser System über einen längeren Zeitraum ungewöhnlich stark belastet wird, wodurch Tausende von Tabellen und zugehörigen Objekten in relativ kurzer Zeit erstellt und gelöscht werden, können die PostgreSQL-Systemtabellen schließlich erheblich aufgebläht werden. Dies verlangsamt bereits Systemabfragen, die Details über alle anderen Beziehungen lesen. Und irgendwann könnte das System beschließen, diese Systemtabellen zu verkleinern, was zu einer exklusiven Sperre für einige dieser Beziehungen für Sekunden oder sogar Dutzende von Sekunden führt. Dies könnte eine große Anzahl von Selects und anderen Operationen auf allen Tabellen blockieren. Basierend auf der Analyse des Datenverkehrs können wir eine ähnliche Analyse für andere spezifische Systeme durchführen, um zu verstehen, wann sie am anfälligsten für solche Vorfälle sind. Aber eine effektive Überwachung ist absolut unerlässlich.
