Die zweitägigen Kubernetes Community Days in München brachten Kubernetes-Nutzer, Entwickler und Experten aus ganz Deutschland zusammen. Am 01.07 und 02.07 bot die Konferenz die Gelegenheit, einen Einblick in die neuesten Entwicklungen des Kubernetes Mikrokosmos zu erhalten, sowie Herausforderungen und Lösungen zu teilen und Kontakte zu Kollegen zu knüpfen. Die lebendige Atmosphäre und die gemeinsame Begeisterung für Kubernetes boten eine ideale Umgebung, sich fortzubilden, inspirieren zu lassen und Denkanstöße zu erhalten.

In der Keynote der Veranstaltung „Reflections on a decade of Kubernetes. How it has been and what the future is holding for us“ wurde der Wandel der IT-Branche betrachtet. Vor etwa 10 Jahren wurde durch Kubernetes die Art und Weise, wie Workflows bereitgestellt und verwaltet werden, revolutioniert. Dies wird in der Keynote ausgeführt.
Ursprünglich für Orchestrierung von Microservices und Backend-Dienste konzipiert, wurde Kubernetes stetig weiterentwickelt und hat sich somit in immer mehr Bereichen der IT etabliert. Derzeit liegt der Fokus auf neuen Technologien wie GenAI, Gaming und Edge Computing, die mittlerweile in breiten Teilen der Gesellschaft genutzt werden.
Unser Team informierte sich in verschiedenen Vorträgen zu den aktuellen Herausforderungen im Platform Engineering.

Alteingesessene Entwickler betrachten moderne Betriebsteams oft mit Skepsis und hinterfragen die Notwendigkeit Cloud-nativer Konzepte. In einem der angebotenen Vorträge der Tagung wurde die Bedeutung der Übernahme von Produktmanagement-Praktiken betont und die Vorteile von Container-Plattformen für Entwickler und Stakeholder verdeutlicht.
Aus der Frage „Stellt Platform-Engineering die nächste Stufe der DevOps-Evolution dar oder handelt es sich nur um eine Umbenennung bestehender Praktiken?“ ergab sich eine angeregte Diskussion. Ebenso wurden die gemeinsamen Herausforderungen, die sich aus der Einführung von Platform Engineering ergeben, besprochen. Wir diskutierten intern die Integration von Platform Engineering in DevOps-Praktiken und die Vorteile dieses Ansatzes für unsere eigenen Projekte.
Die Evolution der Bereitstellung von Diensten über die Grenze von Kubernetes hinweg, wurde in einem Beitrag thematisiert, der sich mit den Netzwerkfähigkeiten in Kubernetes, insbesondere dem Vergleich zwischen der Ingress-API und der neuen Gateway-API befasste. Obwohl die Ingress-API Einschränkungen unterliegt, ist sie weit verbreitet. Diese soll durch Kubernetes im Rahmen der Gateway-API abgelöst werden. Der Vortrag hob die Unterschiede und Vorteile von Gateway-API hervor, was zu Überlegungen und Gesprächen über Migrationsstrategien und praktische Implementierungen führte.
Die Diskussion führte zu der Erkenntnis, dass das Wissen bezüglich Gateway-API und der damit verbundene Mehrwert gegenüber Ingress-Controllern intern vertieft werden sollte.
Die Installation einer Kubernetes-Plattform mit der Cluster-API kann eine hohe Komplexität aufweisen. In einem Vortrag wurde das Framework Cluster Stack vorgestellt. Es stellt eine Lösung dar, Kubernetes Add-Ons zu bündeln und den Lebenszyklus von diesen mit Hilfe des Cluster Stack Operator zu verwalten. Wir diskutierten mögliche Vorteile und Herausforderungen für die Nutzung des Cluster Stack Frameworks in verschiedenen Umgebungen.
Der Vortrag „OCI Registry: Beyond Container Images – Migrating from GitOps to RegistryOps“ veranschaulichte die Unterschiede zwischen beiden Technologien. Auch Security Aspekte wurden thematisiert. Es wurde erklärt, wie Artefakte signiert und validiert werden können, um somit Supply-Chain-Attacks vorzubeugen. Zudem wurde hervorgehoben, wie Flux und ORAS Helm-Charts und Kubernetes-Manifeste in OCI-Registries speichern können.
Dies regte Diskussionen zwischen den Kollegen über praktische Anwendungsfälle und das Potenzial zur Verbesserung der Software-Supplychain in unseren eigenen Projekten an.
Das Debuggen von CloudNative Anwendungen mit innovativen Tools wie Mirrord wurde in einem weiteren Vortrag vorgestellt. Dieses Tool stellt einen innovativen Ansatz dar und vereinfacht das Debuggen von Cloud Applikationen, indem es Entwicklern ermöglicht, ihren Code lokal auszuführen, während sie in der Cloud-Umgebung testen. Sowohl die Live-Demonstration von Mirrord wie auch die anschließenden Diskussionen regten dazu an, dieses Tool in Zukunft im Rahmen interner Entwicklungs-Workflows zu testen. Der Vortrag zeigte außerdem die kontinuierliche Innovation im Kubernetes-Ökosystem und die praktischen Vorteile neuer Tools auf.
Das Skalieren zustandsbehafteter Anwendungen auf Kubernetes stellt Entwickler und Platformbetreiber teils vor große Herausforderungen, so auch bei Entwicklern einer EV-Lade-Plattform, wie es in einem weiteren Vortrag vorgestellt wurde. Es wurden Zusammenhänge beim Management von plötzlich auftretenden WebSocket-Wiederverbindungen und Lastspitzen sowie die damit verbundenen Probleme aufgezeigt. Verschiedene Herangehensweisen zur Lösung dieser Probleme wurden beleuchtet, aus denen schließlich praktische Lösungen abgeleitet wurden. Diese Ansätze führten zu Gesprächen über Skalierungsstrategien und das Potenzial zur Implementierung ähnlicher Architekturen in unseren eigenen Projekten.
Die Komplexität von Kubernetes hindert Entwicklungsteams häufig daran, das volle Potenzial zu nutzen. Ein Vortrag von Mitarbeitern einer Tochtergesellschaft von Mercedes-Benz stellte deren Ansatz zur Ausführung von Kubernetes vor, der es Tausenden von Entwicklern ermöglicht, Kubernetes ohne Expertenwissen und in einem sicheren Rahmen effektiv nutzen zu können. Besonders interessant war, mit welchen Herausforderungen Entwickler und Administratoren einer so großen Kubernetes-Umgebung konfrontiert sind. Die Vortragenden sprachen darüber, wie sie ihren eigenen Operator und CRD schreiben, um die Installation gängiger Addons zu erleichtern und Sicherheitsstandards festzulegen. Dieser praktische Ansatz wurde von vielen Teilnehmern mit Interesse verfolgt und führte zu Diskussionen über die Standardisierung bei der Installation komplexer Tools und Beachtung der Sicherheitsstandards.
Die Kubernetes Community Days verschafften einen umfassenden Überblick über die aktuellen Herausforderungen und Lösungen im Kubernetes-Ökosystem. Der Austausch und die Diskussionen zu Tech-Stacks regten Teilnehmende dazu an, sich tiefer mit Themen wie Mirrord und die Gateway-API zu beschäftigen.
Es entstanden zahlreiche neue Ideen und Perspektiven, wie wir die Herausforderungen in unseren eigenen Projekten angehen oder was wir an bestehenden
Lösungen verbessern können.

Wenn Sie die Wahl hätten, würden Sie eher Salsa oder Guacamole nehmen? Lassen Sie mich erklären, warum Sie Guacamole Salsa vorziehen sollten.
In diesem Blog-Artikel möchten wir uns eines der kleineren Apache-Projekte namens Apache Guacamole. Apache Guacamole ermöglicht Administratoren die Ausführung eines webbasierten Client-Tools für den Zugriff auf Remote-Anwendungen und -Server. Dies kann Remote-Desktop-Systeme, Anwendungen oder Terminalsitzungen umfassen. Benutzer können einfach über ihren Webbrowser darauf zugreifen. Es werden kein spezieller Client oder andere Tools benötigt. Von dort aus können sie sich anmelden und auf alle vorkonfigurierten Remote-Verbindungen zugreifen, die von einem Administrator festgelegt wurden.
Dabei unterstützt Guacamole eine Vielzahl von Protokollen wie VNC, RDP und SSH. Auf diese Weise können Benutzer im Grunde auf alles zugreifen, von Remote-Terminal-Sitzungen bis hin zu vollwertigen grafischen Benutzeroberflächen, die von Betriebssystemen wie Debian, Ubuntu, Windows und vielen mehr bereitgestellt werden.
Konvertieren Sie jede Windows-Anwendung in eine Webanwendung
Wenn wir diese Idee weiter spinnen, kann technisch gesehen jede Windows-Anwendung, die nicht für die Ausführung als Webanwendung konzipiert ist, mithilfe von Apache Guacamole in eine Webanwendung umgewandelt werden. Wir haben einem Kunden geholfen, seine Legacy-Anwendung zu Kubernetes zu bringen, sodass andere Benutzer ihre Webbrowser verwenden konnten, um sie auszuführen. Sicher, die Implementierung der Anwendung von Grund auf, sodass sie den Cloud-Native-Prinzipien folgt, ist die bevorzugte Lösung. Wie immer können jedoch Aufwand, Erfahrung und Kosten die verfügbare Zeit und das Budget übersteigen, und in diesen Fällen kann Apache Guacamole eine relativ einfache Möglichkeit zur Realisierung solcher Projekte bieten.
In diesem Blog-Artikel möchte ich Ihnen zeigen, wie einfach es ist, eine Legacy-Windows-Anwendung als Web-App auf Kubernetes auszuführen. Dazu verwenden wir einen Kubernetes-Cluster, der von kind erstellt wurde, und erstellen ein Kubernetes-Deployment, um kate – einen KDE-basierten Texteditor – zu unserer eigenen Webanwendung zu machen. Es ist nur ein Beispiel, daher gibt es möglicherweise bessere Anwendungen zum Transformieren, aber diese sollte ausreichen, um Ihnen die Konzepte hinter Apache Guacamole zu zeigen.
Also, ohne weiteres, erstellen wir unsere kate Webanwendung.
Vorbereitung von Kubernetes
Bevor wir beginnen können, müssen wir sicherstellen, dass wir einen Kubernetes-Cluster haben, auf dem wir testen können. Wenn Sie bereits einen Cluster haben, überspringen Sie diesen Abschnitt einfach. Wenn nicht, starten wir einen mit kind.
kind ist eine schlanke Implementierung von Kubernetes, die auf jeder Maschine ausgeführt werden kann. Es ist in Go geschrieben und kann wie folgt installiert werden:
# For AMD64 / x86_64
[ $(uname -m) = x86_64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.22.0/kind-linux-amd64
# For ARM64
[ $(uname -m) = aarch64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.22.0/kind-linux-arm64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind
Als Nächstes müssen wir einige Abhängigkeiten für unseren Cluster installieren. Dazu gehören beispielsweise docker und kubectl.
$ sudo apt install docker.io kubernetes-client
Durch die Erstellung unseres Kubernetes-Clusters mit kind benötigen wir docker, da der Kubernetes-Cluster innerhalb von Docker-Containern auf Ihrem Host-Rechner läuft. Die Installation von kubectl ermöglicht uns den Zugriff auf Kubernetes nach der Erstellung.
Sobald wir diese Pakete installiert haben, können wir mit der Erstellung unseres Clusters beginnen. Zuerst müssen wir eine Clusterkonfiguration definieren. Sie definiert, welche Ports von unserem Host-Rechner aus zugänglich sind, sodass wir auf unsere Guacamole-Anwendung zugreifen können. Denken Sie daran, dass der Cluster selbst innerhalb von Docker-Containern betrieben wird, daher müssen wir sicherstellen, dass wir von unserem Rechner aus darauf zugreifen können. Dazu definieren wir die folgende Konfiguration, die wir in einer Datei namens cluster.yaml speichern:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
listenAddress: "127.0.0.1"
protocol: TCP
Hierbei ordnen wir im Grunde den Port 30000 des Containers dem Port 30000 unseres lokalen Rechners zu, sodass wir später problemlos darauf zugreifen können. Behalten Sie dies im Hinterkopf, da dies der Port sein wird, den wir mit unserem Webbrowser verwenden werden, um auf unsere kate Instanz zuzugreifen.
Letztendlich wird diese Konfiguration von kind verwendet. Damit können Sie auch mehrere andere Parameter Ihres Clusters anpassen, abgesehen von der reinen Änderung der Portkonfiguration, die hier nicht erwähnt werden. Es lohnt sich, einen Blick in die Dokumentation von Kate zu werfen.
Sobald Sie die Konfiguration in cluster.yaml gespeichert haben, können wir nun mit der Erstellung unseres Clusters beginnen:
$ sudo kind create cluster --name guacamole --config cluster.yaml
Creating cluster "guacamole" ...
✓ Ensuring node image (kindest/node:v1.29.2) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-guacamole"
You can now use your cluster with:
kubectl cluster-info --context kind-guacamole
Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community 🙂
Da wir nicht alles im Root-Kontext ausführen möchten, exportieren wir die kubeconfig, sodass wir sie mit kubectl mit unserem nicht privilegierten Benutzer verwenden können:
$ sudo kind export kubeconfig \
--name guacamole \
--kubeconfig $PWD/config
$ export KUBECONFIG=$PWD/config
$ sudo chown $(logname): $KUBECONFIG
Dadurch sind wir bereit und können jetzt mit kubectl auf unseren Kubernetes-Cluster zugreifen. Dies ist unsere Grundlage, um mit der Migration unserer Anwendung zu beginnen.
Erstellung des Guacamole-Deployments
Um unsere Anwendung auf Kubernetes auszuführen, benötigen wir eine Art Workload-Ressource. Typischerweise könnten Sie einen Pod, ein Deployment, ein Statefulset oder ein Daemonset erstellen, um Workloads auf einem Cluster auszuführen.
Erstellen wir das Kubernetes-Deployment für unsere eigene Anwendung. Das unten gezeigte Beispiel zeigt die allgemeine Struktur des Deployments. Jede Containerdefinition wird anschließend ihre eigenen Beispiele haben, um sie detaillierter zu erklären.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web-based-kate
name: web-based-kate
spec:
replicas: 1
selector:
matchLabels:
app: web-based-kate
template:
metadata:
labels:
app: web-based-kate
spec:
containers:
# The guacamole server component that each
# user will connect to via their browser
- name: guacamole-server
image: docker.io/guacamole/guacamole:1.5.4
...
# The daemon that opens the connection to the
# remote entity
- name: guacamole-guacd
image: docker.io/guacamole/guacd:1.5.4
...
# Our own self written application that we
# want to make accessible via the web.
- name: web-based-kate
image: registry.example.com/own-app/web-based-kate:0.0.1
...
volumes:
- name: guacamole-config
secret:
secretName: guacamole-config
- name: guacamole-server
emptyDir: {}
- name: web-based-kate-home
emptyDir: {}
- name: web-based-kate-tmp
emptyDir: {}
Wie Sie sehen können, benötigen wir drei Container und einige Volumes für unsere Anwendung. Die ersten beiden Container sind Apache Guacamole selbst gewidmet. Erstens ist es die Serverkomponente, die der externe Endpunkt für Clients ist, um auf unsere Webanwendung zuzugreifen. Sie dient dem Webserver sowie der Benutzerverwaltung und -konfiguration, um Apache Guacamole auszuführen.
Daneben gibt es den guacd Daemon. Dies ist die Kernkomponente von Guacamole, die die Remote-Verbindungen zur Anwendung basierend auf der Konfiguration des Servers erstellt. Dieser Daemon leitet die Remote-Verbindung an die Clients weiter, indem er sie für den Guacamole-Server zugänglich macht, der die Verbindung dann an den Endbenutzer weiterleitet.
Schließlich haben wir unsere eigene Anwendung. Sie bietet einen Verbindungsendpunkt zum guacd Daemon unter Verwendung eines der von Guacamole unterstützten Protokolle und stellt die grafische Benutzeroberfläche (GUI) bereit.
Guacamole-Server
Lassen Sie uns nun tief in jede Containerspezifikation eintauchen. Wir beginnen mit der Guacamole-Serverinstanz. Diese verwaltet die Sitzungs- und Benutzerverwaltung und enthält die Konfiguration, die definiert, welche Remote-Verbindungen verfügbar sind und welche nicht.
- name: guacamole-server
image: docker.io/guacamole/guacamole:1.5.4
env:
- name: GUACD_HOSTNAME
value: "localhost"
- name: GUACD_PORT
value: "4822"
- name: GUACAMOLE_HOME
value: "/data/guacamole/settings"
- name: HOME
value: "/data/guacamole"
- name: WEBAPP_CONTEXT
value: ROOT
volumeMounts:
- name: guacamole-config
mountPath: /data/guacamole/settings
- name: guacamole-server
mountPath: /data/guacamole
ports:
- name: http
containerPort: 8080
securityContext:
allowPrivilegeEscalation: false
privileged: false
readOnlyRootFilesystem: true
capabilities:
drop: ["all"]
resources:
limits:
cpu: "250m"
memory: "256Mi"
requests:
cpu: "250m"
memory: "256Mi"
Da sie sich mit dem guacd Daemon verbinden muss, müssen wir die Verbindungsinformationen für guacd bereitstellen, indem wir sie über Umgebungsvariablen wie GUACD_HOSTNAME oder GUACD_PORT an den Container übergeben. Darüber hinaus wäre Guacamole normalerweise über http://<your domain>/guacamole zugänglich.
Dieses Verhalten kann jedoch durch Ändern der Umgebungsvariable WEBAPP_CONTEXT angepasst werden. In unserem Fall möchten wir beispielsweise nicht, dass ein Benutzer /guacamole eingibt, um darauf zuzugreifen, sondern es einfach so verwendet: http://<your domain>/
Guacamole guacd
Dann gibt es den guacd Daemon.
- name: guacamole-guacd
image: docker.io/guacamole/guacd:1.5.4
args:
- /bin/sh
- -c
- /opt/guacamole/sbin/guacd -b 127.0.0.1 -L $GUACD_LOG_LEVEL -f
securityContext:
allowPrivilegeEscalation: true
privileged: false
readOnlyRootFileSystem: true
capabilities:
drop: ["all"]
resources:
limits:
cpu: "250m"
memory: "512Mi"
requests:
cpu: "250m"
memory: "512Mi"
Es ist erwähnenswert, dass Sie die Argumente ändern sollten, die zum Starten des guacd Containers verwendet werden. In dem obigen Beispiel möchten wir, dass guacd aus Sicherheitsgründen nur auf localhost hört. Alle Container innerhalb desselben Pods teilen sich denselben Netzwerk-Namespace. Infolgedessen können sie über localhost aufeinander zugreifen. Dies gesagt, es besteht keine Notwendigkeit, diesen Dienst für andere Dienste zugänglich zu machen, die außerhalb dieses Pods laufen, sodass wir ihn auf localhost beschränken können. Um dies zu erreichen, müssen Sie den Parameter -b 127.0.0.1 setzen, der die entsprechende Listener-Adresse festlegt. Da Sie den gesamten Befehl überschreiben müssen, vergessen Sie nicht, auch die Parameter
Webbasiertes Kate
Um alles abzuschließen, haben wir die kate Anwendung, die wir in eine Webanwendung umwandeln möchten.
- name: web-based-kate
image: registry.example.com/own-app/web-based-kate:0.0.1
env:
- name: VNC_SERVER_PORT
value: "5900"
- name: VNC_RESOLUTION_WIDTH
value: "1280"
- name: VNC_RESOLUTION_HEIGHT
value: "720"
securityContext:
allowPrivilegeEscalation: true
privileged: false
readOnlyRootFileSystem: true
capabilities:
drop: ["all"]
volumeMounts:
- name: web-based-kate-home
mountPath: /home/kate
- name: web-based-kate-tmp
mountPath: /tmp
Konfiguration unseres Guacamole-Setups
Nachdem das Deployment eingerichtet ist, müssen wir die Konfiguration für unser Guacamole-Setup vorbereiten. Um zu wissen, welche Benutzer existieren und welche Verbindungen angeboten werden sollen, müssen wir Guacamole eine Mapping-Konfiguration bereitstellen.
In diesem Beispiel wird eine einfache Benutzerzuordnung zu Demonstrationszwecken gezeigt. Es verwendet eine statische Zuordnung, die in einer XML-Datei definiert ist, die an den Guacamole-Server übergeben wird. Typischerweise würden Sie stattdessen andere Authentifizierungsmethoden wie eine Datenbank oder LDAP verwenden.
Dies gesagt, fahren wir jedoch mit unserer statischen fort. Dazu definieren wir einfach ein Kubernetes Secret, das in den Guacamole-Server gemountet wird. Hierbei werden zwei Konfigurationsdateien definiert. Eine ist die sogenannte guacamole.properties. Dies ist die Hauptkonfigurationsdatei von Guacamole. Daneben definieren wir auch die user-mapping.xml, die alle verfügbaren Benutzer und ihre Verbindungen enthält.
apiVersion: v1
kind: Secret
metadata:
name: guacamole-config
stringData:
guacamole.properties: |
enable-environment-properties: true
user-mapping.xml: |
<user-mapping>
<authorize username="admin" password="PASSWORD" encoding="sha256">
<connection name="web-based-kate">
<protocol>vnc</protocol>
<param name="hostname">localhost</param>
<param name="port">5900</param>
</connection>
</authorize>
</user-mapping>
Wie Sie sehen können, haben wir nur einen bestimmten Benutzer namens admin definiert, der eine Verbindung namens web-based-kate verwenden kann. Um auf die kate Instanz zuzugreifen, würde Guacamole VNC als konfiguriertes Protokoll verwenden. Damit dies geschieht, muss unsere Webanwendung auf der anderen Seite einen VNC-Server-Port anbieten, sodass der
$ echo -n "test" | sha256sum
9f86d081884c7d659a2feaa0c55ad015a3bf4f1b2b0b822cd15d6c15b0f00a08 -
Als Nächstes referenziert der Hostname-Parameter den entsprechenden VNC-Server unseres kate Containers. Da wir unseren Container zusammen mit unseren Guacamole-Containern innerhalb desselben Pods starten, können der Guacamole-Server sowie der guacd auf den VNC-Server zugreift und die Remote-Sitzung über HTTP an Clients weiterleitet, die über ihre Webbrowser auf Guacamole zugreifen. Schließlich müssen wir auch den VNC-Server-Port angeben, der typischerweise 5900 ist, aber dies könnte bei Bedarf angepasst werden.
Die entsprechende guacamole.properties ist recht kurz. Durch Aktivieren des Konfigurationsparameters enabling-environment-properties stellen wir sicher, dass jeder Guacamole-Konfigurationsparameter auch über Umgebungsvariablen festgelegt werden kann. Auf diese Weise müssen wir diese Konfigurationsdatei nicht jedes Mal ändern, wenn wir die Konfiguration anpassen möchten, sondern wir müssen dem Guacamole-Server-Container nur aktualisierte Umgebungsvariablen bereitstellen.
Guacamole zugänglich machen
Zu guter Letzt müssen wir den Guacamole-Server für Clients zugänglich machen. Obwohl jeder bereitgestellte Dienst über localhost aufeinander zugreifen kann, gilt dies nicht für Clients, die versuchen, auf Guacamole zuzugreifen. Daher müssen wir den Server-Port 8080 von Guacamole für die Außenwelt verfügbar machen. Dies kann durch Erstellen eines Kubernetes-Dienstes vom Typ NodePort erreicht werden. Dieser Dienst leitet jede Anfrage von einem lokalen Node-Port an den entsprechenden Container weiter, der den konfigurierten Zielport anbietet. In unserem Fall wäre dies der Guacamole-Server-Container, der Port 8080 anbietet.
apiVersion: v1
kind: Service
metadata:
name: web-based-kate
spec:
type: NodePort
selector:
app: web-based-kate
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
nodePort: 30000
Dieser spezifische Port wird dann dem Port 30000 des Knotens zugeordnet, für den wir auch den kind Cluster so konfiguriert haben, dass er seinen Node-Port 30000 an den Port 30000 des Host-Systems weiterleitet. Dieser Port ist derjenige, den wir verwenden müssten, um mit unseren Webbrowsern auf Guacamole zuzugreifen.
Vorbereitung des Anwendungscontainers
Bevor wir mit der Bereitstellung unserer Anwendung beginnen können, müssen wir unseren kate Container vorbereiten. Dazu erstellen wir einfach einen Debian-Container, der kate ausführt. Beachten Sie, dass Sie typischerweise schlanke Basis-Images wie alpine verwenden würden, um solche Anwendungen auszuführen. Für diese Demonstration verwenden wir jedoch die Debian-Images, da es einfacher ist, sie zu starten, aber im Allgemeinen benötigen Sie nur einen kleinen Bruchteil der Funktionalität, die von diesem Basis-Image bereitgestellt wird. Darüber hinaus möchten Sie – aus Sicherheitsgründen – Ihre Images klein halten, um die Angriffsfläche zu minimieren und sicherzustellen, dass sie einfacher zu warten sind. Für den Moment werden wir jedoch mit dem Debian-Image fortfahren.
In dem Beispiel unten sehen Sie eine Dockerfile für den kate Container.
FROM debian:12
# Install all required packages
RUN apt update && \
apt install -y x11vnc xvfb kate
# Add user for kate
RUN adduser kate --system --home /home/kate -uid 999
# Copy our entrypoint in the container
COPY entrypoint.sh /opt
USER 999
ENTRYPOINT [ "/opt/entrypoint.sh" ]
Hier sehen Sie, dass wir einen dedizierten Benutzer namens kate (Benutzer-ID 999) erstellen, für den wir auch ein Home-Verzeichnis erstellen. Dieses Home-Verzeichnis wird für alle Dateien verwendet, die kate während der Laufzeit erstellt. Da wir readOnlyRootFilesystem auf true gesetzt haben, müssen wir sicherstellen, dass wir eine Art beschreibbares Volume (z. B. EmptyDir) in das Home-Verzeichnis von Kate mounten. Andernfalls könnte Kate dann keine Laufzeitdaten schreiben.
Darüber hinaus müssen wir die folgenden drei Pakete installieren:
- x11vnc
- xvfb
- kate
Dies sind die einzigen Pakete, die wir für unseren Container benötigen. Darüber hinaus müssen wir auch ein Entrypoint-Skript erstellen, um die Anwendung zu starten und den Container entsprechend vorzubereiten. Dieses Entrypoint-Skript erstellt die Konfiguration für kate, startet es in einer virtuellen Anzeige mit xvfb-run und stellt diese virtuelle Anzeige Endbenutzern mit dem VNC-Server über x11vnc bereit. In der Zwischenzeit wird xdrrinfo verwendet, um zu überprüfen, ob die virtuelle Anzeige nach dem Start von kate erfolgreich hochgefahren wurde. Wenn es zu lange dauert, schlägt das Entrypoint-Skript fehl, indem es den Exit-Code 1 zurückgibt.
Dadurch stellen wir sicher, dass der Container bei einem Fehler nicht in einer Endlosschleife hängen bleibt und Kubernetes den Container neu startet, wenn er die Anwendung nicht erfolgreich starten konnte. Darüber hinaus ist es wichtig zu überprüfen, ob die virtuelle Anzeige vor der Übergabe an den VNC-Server hochgefahren wurde, da der VNC-Server abstürzen würde, wenn die virtuelle Anzeige nicht betriebsbereit ist, da er etwas zum Teilen benötigt. Andererseits wird unser Container beendet, wenn
#!/bin/bash
set -e
# If no resolution is provided
if [ -z $VNC_RESOLUTION_WIDTH ]; then
VNC_RESOLUTION_WIDTH=1920
fi
if [ -z $VNC_RESOLUTION_HEIGHT ]; then
VNC_RESOLUTION_HEIGHT=1080
fi
# If no server port is provided
if [ -z $VNC_SERVER_PORT ]; then
VNC_SERVER_PORT=5900
fi
# Prepare configuration for kate
mkdir -p $HOME/.local/share/kate
echo "[MainWindow0]
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: Height=$VNC_RESOLUTION_HEIGHT
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: Width=$VNC_RESOLUTION_WIDTH
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: XPosition=0
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: YPosition=0
Active ViewSpace=0
Kate-MDI-Sidebar-Visible=false" > $HOME/.local/share/kate/anonymous.katesession
# We need to define an XAuthority file
export XAUTHORITY=$HOME/.Xauthority
# Define execution command
APPLICATION_CMD="kate"
# Let's start our application in a virtual display
xvfb-run \
-n 99 \
-s ':99 -screen 0 '$VNC_RESOLUTION_WIDTH'x'$VNC_RESOLUTION_HEIGHT'x16' \
-f $XAUTHORITY \
$APPLICATION_CMD &
# Let's wait until the virtual display is initalize before
# we proceed. But don't wait infinitely.
TIMEOUT=10
while ! (xdriinfo -display :99 nscreens); do
sleep 1
let TIMEOUT-=1
done
# Now, let's make the virtual display accessible by
# exposing it via the VNC Server that is listening on
# localhost and the specified port (e.g. 5900)
x11vnc \
-display :99 \
-nopw \
-localhost \
-rfbport $VNC_SERVER_PORT \
-forever
Nachdem wir diese Dateien vorbereitet haben, können wir nun unser Image erstellen und es mit den folgenden Befehlen in unseren Kubernetes-Cluster importieren:
# Do not forget to give your entrypoint script
# the proper permissions do be executed
$ chmod +x entrypoint.sh
# Next, build the image and import it into kind,
# so that it can be used from within the clusters.
$ sudo docker build -t registry.example.com/own-app/web-based-kate:0.0.1 .
$ sudo kind load -n guacamole docker-image registry.example.com/own-app/web-based-kate:0.0.1
Das Image wird in kind importiert, sodass jede Workload-Ressource, die in unserem kind Cluster betrieben wird, darauf zugreifen kann. Wenn Sie einen anderen Kubernetes-Cluster verwenden, müssen Sie diesen in eine Registry hochladen, von der Ihr Cluster Images abrufen kann.
Schließlich können wir auch unsere zuvor erstellten Kubernetes-Manifeste auf den Cluster anwenden. Nehmen wir an, wir haben alles in einer Datei namens
$ kubectl apply -f kubernetes.yaml
deployment.apps/web-based-kate configured
secret/guacamole-config configured
service/web-based-kate unchanged
Auf diese Weise werden ein Kubernetes-Deployment, ein Secret und ein Service erstellt, die letztendlich einen Kubernetes-Pod erstellen, auf den wir anschließend zugreifen können.
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
web-based-kate-7894778fb6-qwp4z 3/3 Running 0 10m
Überprüfung unseres Deployments
Jetzt ist es Showtime! Nach der Vorbereitung von allem sollten wir in der Lage sein, mit unserem Webbrowser auf unsere webbasierte kate Anwendung zuzugreifen. Wie bereits erwähnt, haben wir NodePort aufgenommen wird. Dieser leitet dann alle Anfragen an unseren dafür vorgesehenen Guacamole-Server-Container weiter, der den Webserver für den Zugriff auf Remote-Anwendungen über Guacamole anbietet.
Wenn alles klappt, sollten Sie den folgenden Anmeldebildschirm sehen:
Nach erfolgreicher Anmeldung wird die Remote-Verbindung hergestellt und Sie sollten den Willkommensbildschirm von kate sehen:
Wenn Sie auf New klicken, können Sie eine neue Textdatei erstellen:
Diese Textdateien können sogar gespeichert werden, aber denken Sie daran, dass sie nur so lange existieren, wie unser Kubernetes-Pod existiert. Sobald er gelöscht wird, wird auch das entsprechende EmptyDir, das wir in unseren kate Container gemountet haben, gelöscht und alle Dateien darin gehen verloren. Darüber hinaus ist der Container auf schreibgeschützt gesetzt, was bedeutet, dass ein Benutzer nur Dateien in die Volumes (z. B. EmptyDir) schreiben kann, die wir in unseren Container gemountet haben.
Fazit
Nachdem wir gesehen haben, dass es relativ einfach ist, jede Anwendung mithilfe von Apache Guacamole in eine webbasierte Anwendung umzuwandeln, bleibt nur noch eine wichtige Frage offen…
Was bevorzugen Sie am meisten? Salsa oder Guacamole?

Wieder einmal ist eine KubeCon zu Ende gegangen
Dieses Jahr veranstaltete die CNCF das Treffen in der französischen Hauptstadt. Im Süden von Paris, an der PARIS EXPO PORTE DE VERSAILLES, kamen dieses Jahr erneut über 12.000 Teilnehmer zusammen.
Neben verschiedenen Vorträgen und Unkonferenzen gab es auch eine große Auswahl an Contribfests-Slots, die es Interessierten erleichterten, sich an verschiedenen Projekten zu beteiligen. Der thematische Schwerpunkt lag dieses Jahr eindeutig auf Künstlicher Intelligenz und Maschinellem Lernen.
Der Mittwochmorgen begann um 9 Uhr. Alle Keynotes hatten eines gemeinsam: das Thema KI/ML! Hier sind einige Titel: „Accelerating AI Workloads with GPUs in Kubernetes“, „Build an open source Platform for AI/ML“ oder „Optimizing Performance and Sustainability for AI“. Zusätzlich zu den Keynotes wurden den Teilnehmern auch zahlreiche Vorträge zum Thema KI und ML angeboten. Wer sich für dieses Thema interessierte, konnte während der drei Tage jederzeit im Raum „Paris“ fündig werden. Das neue Whitepaper zu „Cloud Native AI“ wurde ebenfalls während der Keynotes angekündigt.
Ort



Wer die Konferenz betreten wollte, musste zuerst eine Sicherheitskontrolle passieren, bestehend aus Metalldetektoren und möglichen Taschenkontrollen.
Leider gab es dieses Jahr wieder das Problem überfüllter Räume. Mehrmals am Tag war es notwendig, spontan umzuplanen, da der ausgewählte Vortrag leider bereits überfüllt war und kein Einlass mehr möglich war. Dies galt leider auch für einige Keynotes am Morgen.
Einige Impressionen

Der CNCF Storage TAG und die Storage SIG berichteten über aktuelle Entwicklungen im Speicherbereich und erwähnten verschiedene Whitepaper („CNCF Storage Whitepaper, Performance and Benchmarking Whitepaper, Cloud Native Disaster Recovery Whitepaper und das Data on Kubernetes Whitepaper.“). Unter anderem wurde gezeigt, wie „PersistentVolumeAttributes“ verwendet werden können, um PersistentVolume-Attribute anzupassen, beispielsweise um die Anzahl der IOPS für ein Volume während des Betriebs anzupassen.
Im Contribfest-Slot zu Metal3 (Metal Kubed) gaben die Maintainer des Projekts einen ersten Einblick und zeigten, wie eine Entwicklungsumgebung eingerichtet werden kann. Unter anderem bietet Metal3 eine ClusterAPI (CAPI)-Implementierung, die zur Verwaltung von Bare-Metal-Systemen verwendet werden kann. Ironic, das aus dem OpenStack-Projekt stammt, wird im Hintergrund verwendet.
Beim Vortrag „From UI to Storage“ gaben Thanos-Maintainer einen Einblick in die aktuelle Implementierung und potenzielle zukünftige Verbesserungen.
In der „CRI-O Odyssey“ sprachen die CRI-O-Maintainer über Innovationen innerhalb der Container Runtime. Dazu gehörten die Themen „Confidential Containers“ und „Podman-in-Kubernetes“. Auch das Thema WASM-Integration stand auf der Agenda.
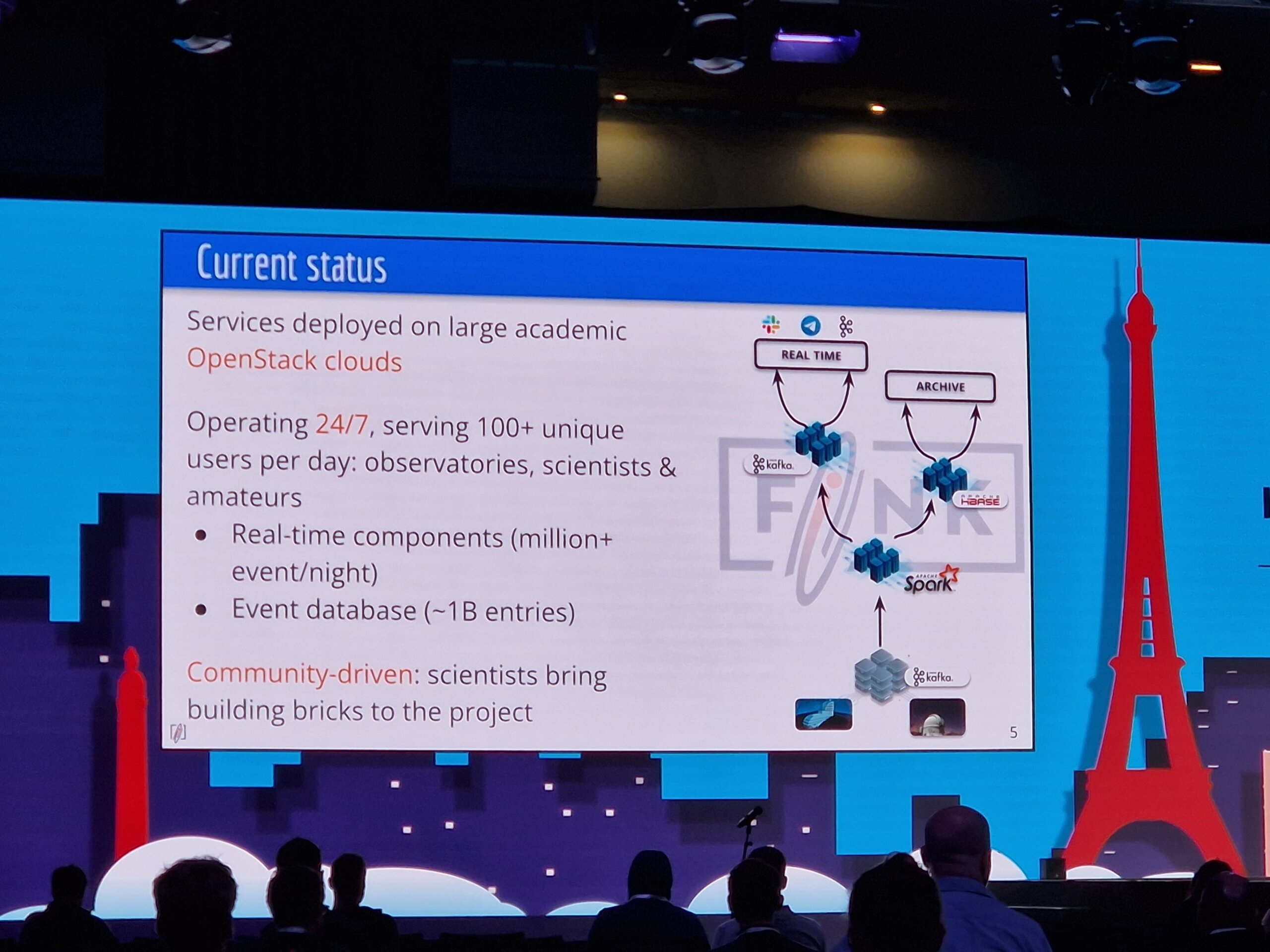
Die Maintainer von Fink berichteten über „Fink on Kubernetes“ und wie das System zur Klassifizierung von Objekten wie Asteroiden oder Supernovae im Bereich der Astronomie eingesetzt wird.
Im Vortrag „eBPF: Abilities and Limitations“ wurden nicht nur allgemeine Missverständnisse geklärt, sondern auch Wege aufgezeigt, bestehende Einschränkungen zu umgehen. Zudem wurde die Frage aufgeworfen, ob eBPF Turing-vollständig ist und eine Version von Conways „Game of Life“ in eBPF vorgestellt.
Wer schon immer wissen wollte, wie Istio mTLS in Multi-Cluster-Umgebungen mithilfe von SPIRE implementiert werden kann, wurde in Raum D fündig. Nach einer kurzen Einführung in SPIFFE und SPIRE wurde gezeigt, wie Istio-Komponenten mit dem SPIRE-Agenten verbunden werden können.
Die Maintainer von operator-sdk sprachen über aktuelle Innovationen im operator-SDK und OLM V1. Besonders interessant waren die Änderungen im Operator Lifecycle Manager, die in Version 1 (zuvor Version 0) eingeführt wurden. Unter anderem ist OLM v1 nun in der Lage, verpackte Operatoren über Helm zu verwalten, auch ohne vorherige Vorbereitung durch die Operator-Maintainer.
Fazit
Neben vielen interessanten Vorträgen gab es zahlreiche Gelegenheiten für angeregte Diskussionen mit anderen Konferenzteilnehmern und zum Austausch mit Ausstellern oder Projekt-Maintainern.
Wir freuen uns schon auf die KubeCon 2025 in London!



















Nach unseren Beiträgen zu Podman und Buildah widmen wir uns heute dem dritten Tool aus der Sammlung von RedHat-Container Tools: Skopeo.
Bei Skopeo handelt es sich um ein vergleichsweise kleines Tool, das hauptsächlich Anwendung in der Container-Erstellung und -Nutzung findet und damit prädestiniert für folgende Aufgaben und Bereiche ist:
- Kopieren von Images zwischen verschiedenen Registries
- Synchronisieren von Images zwischen verschiedenen Stellen
- Inspizieren von Images in einer Registry ohne vorherigen Download
- Löschen von Images
Hierbei ist noch zu erwähnen, dass Skopeo auch einen lokalen Docker-Daemon wie eine Registry behandelt und dies als Quelle genutzt werden kann. Auch wird, wenn nicht anders angegeben, immer auch für die Images von der aktuell für Skopeo genutzten Architektur ausgegangen. Dies lässt sich jedoch durch Parameter ändern bzw. erweitern.
Entwicklung
Die Skopeo Version 1.0 wurde am 18.05.2020 veröffentlicht und wird aktuell, wie auch die anderen RHEL-Container-Tools, unter der Apache 2.0 Lizenz angeboten. Es wird ebenfalls in Golang entwickelt, hat keinen festen Release-Zyklus und wird von der containers-group betreut. Der Code kann auf Github eingesehen werden.
Installation
Die Installation von Skopeo ist mittlerweile auf fast allen Linux-Distributionen recht trivial über eine einfache Paketinstallation erledigt, da alle gängigen Distributionen das Paket mittlerweile in den Repositories hinterlegt haben. Sollte eine bestimmte Version benötigt werden, oder es nicht möglich sein Pakete zu installieren, so wird Skopeo auch als dedizierter Container zur Verfügung gestellt.
Auch ist hier wie üblich zu beachten, dass nicht jede Distribution auch die aktuellste Version bereit stellt und damit ggf. Dritt-Repositories hinzugefügt werden müssen.
Eine detaillierte Dokumentation dazu findet sich auf Github.
Konfiguration
Skopeo nutzt hier, ebenso wie podman und buildah, folgende Dateien als Standard:
- /etc/containers/policy.json – Für, falls benötigt, Image-Policies. Kann auch per Parameter
--policyübergeben werden. - /etc/containers/registries.d – Standardverzeichnis für die eventuell spezielle Konfiguration von Image-Registries. Als prominentes Beispiel wäre hier z.B. das SSL-Verifiy für eigene Entwicklungsregistries. Kann auch per Parameter
--registries.düberschrieben werden.
Arbeiten mit Skopeo
In den hier verwendeten Beispielen nutzen wir die aktuell unter CentOS 8 Streams verfügbare Version 1.5.0.
Inspizieren eines Images
Mittels skopeo inspect können die Details zu einem Image bzw. dem Repository eingesehen werden ohne sich die Daten vorher herunterladen zu müssen. Es werden unter anderem alle verfügbaren Tags des Repositorys sowie verschiedene Details zum angefragten Image beziehungsweise Image-Tag.
Es werden hierbei noch verschiedene Parameter angeboten um bestimmte Details anzufragen oder die Ausgabe anzupassen.
Folgend ein paar Beispiele:
--config– Liefert mehr Details zum eigentlichen Image das angefragt wird. So werden zum Beispiel angelegte Volumes, Ports usw. direkt ersichtlich.--creds– Übergabe von Logindaten (username:password) der Zielregistry--tls-verify– Gibt an ob das SSL Zertifikat der Registry validiert werden soll oder nicht (Boolean)--no-tags– Unterbindet die Ausgabe aller Tags des angefragten Images
Alle Optionen für inspect sowie diverse Beispiele finden sich in der Dokumentation.
Hierzu ein Beispiel für ein generisches skopeo inspect:
$ skopeo inspect docker://docker.io/library/postgres:latest
{
"Name": "docker.io/library/postgres",
"Digest": "sha256:f91f537eb66b6f80217bb6921cd3dd4035b81a5bd1291e02cfa17ed55b7b9d28",
"RepoTags": [
"10",
...
"bullseye",
"buster",
"latest"
],
"Created": "2022-01-04T01:19:59.244463885Z",
"DockerVersion": "20.10.7",
"Labels": null,
"Architecture": "amd64",
"Os": "linux",
"Layers": [
"sha256:a2abf6c4d29d43a4bf9fbb769f524d0fb36a2edab49819c1bf3e76f409f953ea",
...
],
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/lib/postgresql/14/bin",
"GOSU_VERSION=1.14",
"LANG=en_US.utf8",
"PG_MAJOR=14",
"PG_VERSION=14.1-1.pgdg110+1",
"PGDATA=/var/lib/postgresql/data"
]
}
Und ein Bespiel für ein skopeo inspect --config:
$ skopeo inspect --config docker://docker.io/library/postgres:latest
{
"created": "2022-01-04T01:19:59.244463885Z",
"architecture": "amd64",
"os": "linux",
"config": {
"ExposedPorts": {
"5432/tcp": {}
},
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/lib/postgresql/14/bin",
"GOSU_VERSION=1.14",
"LANG=en_US.utf8",
"PG_MAJOR=14",
"PG_VERSION=14.1-1.pgdg110+1",
"PGDATA=/var/lib/postgresql/data"
],
"Entrypoint": [
"docker-entrypoint.sh"
],
"Cmd": [
"postgres"
],
"Volumes": {
"/var/lib/postgresql/data": {}
},
"StopSignal": "SIGINT"
},
"rootfs": {
"type": "layers",
"diff_ids": [
"sha256:2edcec3590a4ec7f40cf0743c15d78fb39d8326bc029073b41ef9727da6c851f",
...
]
},
"history": [
{
"created": "2021-12-21T01:22:43.418913408Z",
"created_by": "/bin/sh -c #(nop) ADD file:09675d11695f65c55efdc393ff0cd32f30194cd7d0fbef4631eebfed4414ac97 in / "
},
...
{
"created": "2022-01-04T01:19:59.244463885Z",
"created_by": "/bin/sh -c #(nop) CMD [\"postgres\"]",
"empty_layer": true
}
]
}
Um eine dedizierte Liste aller im Repository verfügbaren Image-Tags zu bekommen eignet sich der Befehl skopeo list-tags. Skopeo braucht nur die URL zum Repository, zum Beispiel docker://docker.io/library/postgres, und kann so die ganze Liste aller Image-Tags auslesen und verfügbar machen.
Die Dokumentation ist selbst-erklärend und fällt entsprechend kompakt aus.
Kopieren von Images
Mittels skopeo copy können Images entweder zwischen verschiedenen Registries kopiert werden, oder auch zum Beispiel von einer Registry in ein lokales Verzeichnis.
Hierbei stehen vielfältige Parameter zur Verfügung, wobei hier wieder nur ein paar Beispiele genannt werden sollen:
--additional-tag– Versieht das Image in der Ziel-Registry mit zusätzlichen Tags--all– Kopiert alle Architektur-Versionen des Images. Nicht nur das zur aktuellen Architektur passende.--sign-by– Signiert das Image in der Ziel-Registry mit einem angegebenen Schlüssel--dest-compress-format– Bestimmt die Kompressionsmethode für das Zielimage. Auch das Level ist als Parameter verfügbar--encryption-key– Gibt Protokoll und Key für eine Verschlüsselung der Layer in der Ziel-Registry an
Hierbei kann es natürlich nötig sein Login-Informationen anzugeben. Details dazu werden weiter unten beschrieben.
Generelle Dokumentation zu den Copy-Möglichkeiten findet sich in der Dokumentation.
Löschen von Images
Mit Skopeo ist es ebenfalls möglich Images einer Registry remote als “gelöscht” zu markieren. Hierbei ist zu beachten, dass das Image erst dann tatsächlich im Dateisystem entfernt wird, wenn die Löschroutine / Garbage-Collection des Registry ihren Lauf hatte. Neben der Authentifizierung sind hier keine weiteren Optionen möglich.
Alle Informationen finden sich inkl. Beispielen in der offiziellen Dokumentation.
Synchronisieren von Images
Skopeo bietet die Möglichkeit alle Images eines Repositories entweder mit einem anderen Repository oder einem lokalen Ordner zu synchronisieren. Hierbei werden alle Images des Quellpfades in den Zielpfad übernommen.
Anwendung findet diese Synchronisierungsmöglichkeit zum Beispiel bei lokalen Entwicklungsumgebung deren Images in einem Repository liegen und dort automatisch synchronisiert werden können. Auch der umgekehrte Weg, die Synchronisierung aller Images aus einem internen Repository auf eine lokale Umgebung ist hiermit einfach umzusetzen.
Es ist sogar möglich als Quelle eine yaml-Datei anzugeben in welcher als Liste verschiedene Images aus verschiedenen Repositories hinterlegt sind und diese dann einmal auf einen bestimmten Host oder eine andere Registry zu kopieren. Hierbei ist zu beachten, dass in der YAML-Version keine lokalen Pfade als Quelle erlaubt sind. Natürlich können in der yaml-Datei auch verschiedene zusätzliche Parameter wie zum Beispiel Logindaten hinterlegt werden.
Eine volle Übersicht der Parameter und verschiedene Beispiele finden sich wie gewohnt in der Dokumentation.
Authentifizierung
In fast allen Fällen ist es möglich die Parameter für die Authentifizierung direkt im skopeo-Aufruf mit anzugeben.
Bei Befehlen welche Quelle und Ziel beinhalten gibt es die Möglichkeit für --src-creds sowie --dest-creds. Beim Arbeiten an einer einzelnen Registry wird meist nur --creds genutzt. Gleichermaßen gibt es auch diverse Einzelparameter für username und password.
Alternativ kann ein Login auch mittels skopeo login manuell gestartet werden. Dieser Aufruf erfragt die Logindaten interaktiv und erstellt ein Auth-file (Im Standard ${XDG_RUNTIME_DIR}/containers/auth.json), welches dann ebenfalls als Parameter an die einzelnen Skopeo-Aufrufe weitergereicht werden kann. So müssen Authentifizierungsdaten nicht zwangsläufig im Code selbst hinterlegt werden sondern können, angepasst an die Vorliebe des Nutzers, interaktiv erfragt werden. Diese Auth-Datei teilt sich Skopeo auch mit Podman und Buildah und reiht sich damit nahtlos in die Sammlung von RedHat-Container Tools ein.
Um Datensätze wieder zu entfernen kann skopeo logout genutzt werden.
Fazit
Skopeo ist eine sinnvolle Ergänzung zu den beiden anderen Container-Tools und bietet einige Features bei denen sich der Autor schon länger fragt warum diese nicht auch an andere Stelle zur Verfügung stehen.
Besonders die inspect und copy Funktionen von Skopeo können viele verschiedene andere Schritte und auch eine Menge Zeit einsparen wenn man viel mit verschiedenen Repositories arbeitet. Allein sich die verschiedenen Tags eines Images und deren Details anzuschauen ist durchaus eine große Hilfe in der alltäglichen Arbeit und erspart diverse Suchanfragen und Recherchen über UIs.
Auch das einfache Kopieren eines Images von einer Registry (z.B. Docker-Hub) in eine interne Registry ist gerade nach den Limitierung von Dockerhub eine willkommene Funktion, auch wenn die nach und nach Einzug haltende Funktion des Cache-Proxies bei einigen Registries wie zum Beispiel Harbor dies auch ablösen kann.
Wir unterstützen Sie gerne
Mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich, kann die credativ GmbH Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell Begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Die credativ GmbH ist ein herstellerunabhängiges Beratungs- und Dienstleistungs- unternehmen mit Standort in Mönchengladbach.
Wer sich mit Containern und deren Orchestrierung für verteilte, skalierbare und hochverfügbare Anwendungen beschäftigt, wird wohl unweigerlich früher oder später auf Kubernetes stoßen. Es gibt genug Gründe, Container und Kubernetes dem traditionelleren Deployment auf virtuellen Maschinen vorzuziehen. Beispielsweise lassen sich verfügbare Hardware-Ressourcen flexibler an die laufenden Anwendungen verteilen.
Doch durch diese Flexibilität ergeben sich leider auch einige Fallstricke, die man beachten sollte. Aus diesem Grund möchte ich mit diesem Artikel einen Überblick bieten, welche Mittel Kubernetes für die Verwaltung von Hardware-Ressourcen bietet und wie Ihr sie einsetzen könnt.
Test-Setup
Für Demonstrationen werde ich einen Kubernetes-Cluster mit einer Control-Plane-Node und zwei Workern auf Basis von Kubernetes 1.18.6. verwenden Wenn Ihr beim Lesen die Beispiele mit nachvollziehen möchtet, solltet Ihr ebenfalls einen Cluster mit mindestens zwei Worker-Nodes zum Testen verwenden. Ein Cluster mit nur einer Node (wie z.B. mit Minikube) reicht nicht aus, weil damit das verschieben von Pods zwischen Nodes nicht nachvollzogen werden kann.
Solltet ihr gerade keinen Kubernetes-Cluster zum Testen zur Hand haben, empfehle ich kubeadm zu verwenden, um einen Cluster mit mehreren Nodes zu installieren. Die in diesem Artikel verwendeten Beispielwerte gehen dabei von Nodes mit jeweils 4GiB Arbeitsspeicher aus.
Kubernetes‘ Standard-Ressourcenverwaltung
Im späteren Verlauf möchte ich darauf eingehen, welche Stellschrauben Kubernetes im Bezug auf Ressourcenmanagement bietet. Zunächst möchte ich jedoch zeigen, wie Kubernetes die Ressourcen ohne weitere Einstellungen verwaltet und welche Probleme dabei auftreten können. Dazu erzeugen wir zunächst einen Prozess, der eine bestimmtem Menge Speicherplatz benötigt, die von einer Node bereitgestellt werden kann.:
$ kubectl label node knode1 load-target=
$ kubectl apply -f - << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress
spec:
replicas: 1
selector:
matchLabels:
app: stress
template:
metadata:
labels:
app: stress
spec:
containers:
- name: stress
image: alexeiled/stress-ng
args:
- --vm=1
- --vm-bytes=2g
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: load-target
operator: Exists
EOF
deployment.apps/stress created
Der gestartete Container, führt das Tool stress-ng aus. Mit den gegebenen Argumenten startet es einen Prozess, der daraufhin 2GiB Arbeitsspeicher alloziert und darauf schreibt. Mithilfe von Node-Affinities sorgen wir dafür, dass der Pod auf knode1 gestartet wird. Dort können wir die verursachte Last auch mit htop beobachten:
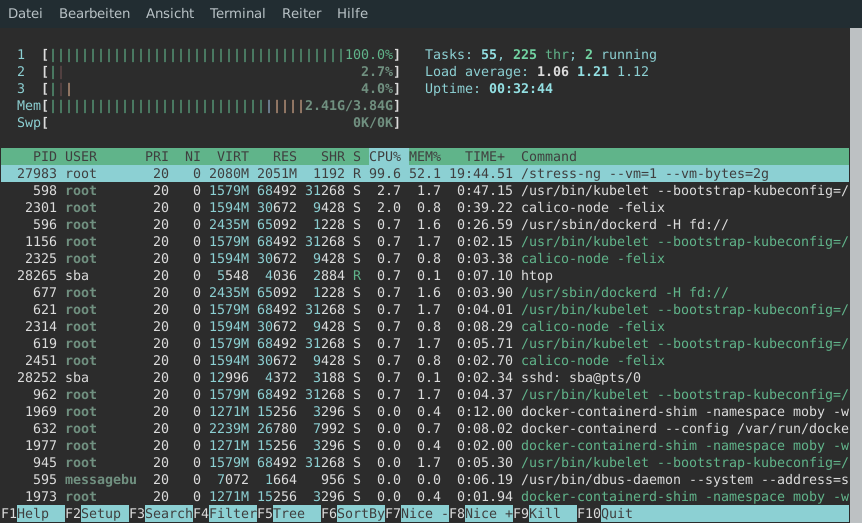
Die Node kann mit der verursachten Last derzeit noch ohne Probleme mithalten. Um zu sehen, was passiert wenn eine Node überlastet wird, müssen wir einen zweiten Pod erzeugen. Dazu erhöhen wir die Anzahl der Replicas des eben erstellten Deployments. Die Platzierung des zweiten Replicas ist dabei hauptsächlich dem Zufall überlassen. Wir wollen allerdings den Worst-Case betrachten, in dem beide Replicas auf der gleichen Node gestartet werden. Das erzwingen wir mithilfe der vorher schon erstellten Node-Affinities:
$ kubectl patch deployment stress -p '{"spec": {"replicas": 2}}'
deployment.apps/stress patched
Wenn wir uns nun die Lastsituation auf knode1 erneut anschauen, hat sich die Situation im Gegensatz zu vorher geändert. Der Speicherverbrauch schwankt drastisch und wenn wir mit dmesg | tail in das Kernel-Log schauen, sehen wir wiederholt Nachrichten der folgenden Art:
[ 3248.919030] Out of memory: Killed process 105727 (stress-ng-vm) total-vm:3179200kB, anon-rss:2312000kB, file-rss:0kB, shmem-rss:44kB, UID:0 pgtables:4592kB oom_score_adj:1000 [ 3248.951392] oom_reaper: reaped process 105727 (stress-ng-vm), now anon-rss:0kB, file-rss:0kB, shmem-rss:44kB
Das liegt daran, dass die beiden Pods zusammen mehr Speicher belegen wollen, als auf der Node zur Verfügung steht. Der Kernel versucht Speicher freizugeben, indem er Prozesse tötet (SIGKILL). Für eine laufende Applikation wäre dieser Zustand nicht akzeptabel, weil Prozesse der Applikation im laufenden Betrieb getötet werden, was die Verfügbarkeit und Stabilität der Applikation beeinflusst. Bisher können wir allerdings auch kein anderes Ergebnis erwarten, weil wir per Node-Affinity explizit angegeben haben, dass beide Replicas auf knode1 ausgeführt werden sollen. Wenn wir knode2 ebenfalls für die Ausführung der Replicas freigeben, wäre zu erwarten, dass einer der Pods evicted wird. Damit ist gemeint, dass der Pod von seiner derzeitigen Node entfernt wird um Ressourcen zu sparen. Das erstellte Deployment wäre dann dafür verantwortlich, den Pod auf einer anderen Node neu zu erstellen. Probieren wir das also aus:
$ kubectl label node knode2 load-target= node/knode2 labeled
Überprüfen wir nun, wo die beiden Pods ausgeführt werden:
$ kubectl describe pod -l app=stress | grep '^Node:' Node: knode1/192.168.122.228 Node: knode1/192.168.122.228
Wie wir sehen, werden beide Pods weiterhin auf knode1 ausgeführt. Auch wenn wir die Situation länger beobachten, werden wir feststellen, dass Kubernetes keinen der Pods evicten wird. Stattdessen wird es die darin laufenden Prozesse weiterhin auf der überlasteten Node laufen lassen wird. Warum Kubernetes hier nicht einschreitet und was wir dagegen tun können, behandle ich im nächsten Abschnitt. Doch zunächst entfernen wir noch das erstellte Deployment und das Label von knode2 um den Basisstand für die nächsten Test wiederherzustellen:
$ kubectl label node knode2 load-target- node/knode2 labeled $ kubectl delete deployment stress deployment.apps "stress" deleted
Ressourcenverwaltung im Kubelet
Grundsätzlich sollte Kubernetes in einer solchen Situation reagieren. Wenn ein Kubelet (die Software die für die Ausführung von Pods auf den Nodes zuständig ist) meldet, dass die Ressourcen auf der Node knapp werden, sollte Kubernetes einen oder mehrere Pods von dieser Node „evicten“ und auf einer anderen Node neu starten. Das ist in unserem Test allerdings nicht passiert. Um herauszufinden wieso, schauen wir uns zunächst mit kubectl describe node knode1 die Informationen zu der Node an. Dabei erhalten wir unter Anderem eine Menge Informationen, die für die Ressourcenverwaltung relevant sind:
Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 250m (8%) 0 (0%) memory 0 (0%) 0 (0%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%)
Diese Tabelle sieht erst mal so aus, als ob sie den Ressourcenverbrauch auf der Node anzeigt. Sie zeigt allerdings nur Ressourcen auf der Node, die für bestimmtem Pods reserviert wurden und gibt uns deshalb keinen Aufschluss darüber, wie viele Ressourcen tatsächlich gerade verbraucht werden.
Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- MemoryPressure False Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletReady kubelet is posting ready status. AppArmor enabled
Hier sehen wir, dass das kubelet der Meinung ist, es hätte genug Speicherplatz zur Verfügung. Das ist zwar unerwartet, erklärt aber warum Kubernetes nichts gegen die zu hohe Last unternommen hat. Solange das Kubelet nicht meldet, dass die Ressourcen knapp werden, sieht Kubernetes keinen Grund etwas an der Ressourcenverteilung zu ändern.
Warum das Kubelet keine Speicherknappheit meldet hängt mit dem folgenden Block zusammen:
Capacity: cpu: 3 ephemeral-storage: 20480580Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 4030888Ki pods: 110 Allocatable: cpu: 3 ephemeral-storage: 18874902497 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 3928488Ki pods: 110
Die Capacity zeigt uns an, wie viele Ressourcen eine Node insgesamt zur Verfügung hat. Der angezeigt Wert von memory: 4030888Ki entspricht dabei genau dem auf der Hardware verfügbaren Arbeitsspeicher. In Allocatable steht hingegen der Speicher, den die Node auch gestarteten Pods zur Verfügung stellt. Solange alle gestarteten Pods weniger als diese Menge an Speicher verbrauchen, ist für das Kubelet alles im grünen Bereich.
Dass das Kubelet in unserem Fall keinen Alarm wegen fehlendem Speicher schlägt, liegt daran, dass das Betriebssystem und das Kubelet selbst Speicherplatz verbrauchen, der dann für die Pods nicht zur Verfügung steht. Dadurch ist es für die gestarteten Pods praktisch gar nicht möglich die gesetzte Grenze zu überschreiten. Als Beispiel: Wenn unser Betriebssystem und das Kubelet zusammen ca. 300MiB belegen, bleiben vom verfügbaren Speicher noch ca. 3600MiB übrig. Wenn nun Pods gestartet werden und diese übrigen 3600MiB belegen, ist der physische Speicher voll. Unsere Pods bleiben aber unter dem gesetzen Limit von 3928488KiB (ca. 3836MiB) und unser Kubelet ist der Meinung es wäre genug Speicher vorhanden.
Die in Allocatable gesetzte Grenze ist also zu hoch gesetzt. Um das zu beheben, bietet das Kubelet die Möglichkeit, Speicher für das Betriebssystem und das Kubelet selbst zu reservieren und dadurch die Allocatable-Grenze für Pods zu verringern. Die entsprechenden Optionen dafür müssen in der Konfigurationsdatei des Kubelet gesetzt werden. Wenn ihr euren Cluster mit kubeadm installiert habt, befindet sich die Konfigurationsdatei auf der Node unter /var/lib/kubelet/config.yaml. Auf beiden Nodes müssen dort die folgenden Optionen eingefügt werden:
systemReserved: memory: 256Mi kubeReserved: memory: 256Mi evictionHard: memory.available: 128Mi evictionSoft: memory.available: 256Mi evictionSoftGracePeriod: memory.available: 5m
Damit Teilen wir dem Kubelet mehrere Dinge mit:
systemReservedsagt, dass für das System 256MiB Arbeitsspeicher reserviert werden sollen.kubeReservedsagt, dass für das Kubelet 256MiB Arbeitsspeicher reserviert werden sollen.evictionHardsagt, dass sobald für Pods weniger als 128MiB verbleiben, sofort Pods evicted werden sollen.evictionSoftundevictionSoftGracePeriodsagen, dass wenn länger als 5 Minuten für Pods weniger als 256MiB verfügbar sind Pods evicted werden sollen.
Mit diesen Werten sollte das Kubelet früh genug Alarm schlagen, wenn der Speicher knapp wird, um zu verhindern, dass unsere Node vollständig überlastet wird. Um die Optionen zu übernehmen, muss die entsprechende Node komplett rebootet werden. Normalerweise reicht ein Neustart des Kubelets aus, um Änderungen in der Konfiguration zu übernehmen. Bei Änderungen an Ressourcen-Limits muss das Kubelet allerdings Änderungen an bestehenden CGroups vornehmen, was nicht immer möglich ist. Ein Neustart garantiert deswegen schneller, dass die gesetzten Limits tatsächlich effektiv sind. Den Effekt können wir in den Node-Informationen bobachten:
$ kubectl describe node knode1 Capacity: [...] memory: 4030896Ki [...] Allocatable: [...] memory: 3375536Ki [...]
Hier sehen wir nun, dass der für Pods verfügbare Arbeitsspeicher weiter verringert wurde. Er ist nun exakt 768MiB geringer, als der Verfügbare Speicherplatz. Diese Zahl ergibt sich aus der Summe des für das System und Kubelet reservierten Speicherplatzes und der Soft-Eviction-Threshold.
Nun können wir nochmal testen, ob unsere Pods bei Ressourcenknappheit korrekt evicted werden. Dazu erstellen wir erneut ein Deployment um Last zu erzeugen:
$ kubectl apply -f - << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress
spec:
replicas: 2
selector:
matchLabels:
app: stress
template:
metadata:
labels:
app: stress
spec:
containers:
- name: stress
image: alexeiled/stress-ng
args:
- --vm=1
- --vm-bytes=2g
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: load-target
operator: Exists
EOF
deployment.apps/stress created
Wenn wir nun die gestarteten Pods betrachten, werden wir nach einer Weile sehen, dass einer der Pods evicted wurde:
$ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES stress-7c4bb6fdbd-nrm5d 1/1 Running 0 9s fd49:7f8a:1714:14fc:6f39:9d7d:8f25:721a knode2 <none> <none> stress-7c4bb6fdbd-nw6lk 1/1 Running 0 119s fd49:7f8a:1714:14fc:7dc6:67af:9a64:c3ac knode1 <none> <none> stress-7c4bb6fdbd-z8p6c 0/1 Evicted 0 119s <none> knode1 <none> <none>
Als Ersatz für den Pod, der evicted wurde, wurde ein neuer erstellt, der nach einer Weile auf einer Node neu gestartet werden soll. Dabei kann es vorkommen, dass der Pod auf der Node neu gestartet wird, von der er gerade evicted worden ist. Das führt dann dazu, dass der Pod direkt im Anschluss wieder evicted wird. Das liegt daran, dass Kubernetes bei der Zuordnung der Pods zu den Nodes weiterhin zufällig vorgeht, weil es vor der Ausführung eines Pods nicht abschätzen kann, wieviele Ressourcen der Pod zur Laufzeit benötigen werden. Solange insgesamt genug Ressourcen vorhanden sind, sollte jedoch jeder Pod früher oder später eine Node finden, auf der er genug Ressourcen bekommt.
Ressourcen für Pods und Container verwalten
Nun wissen wir, wie wir unsere Pods vor der vollkommenen Überladung schützen. Wie wir gesehen haben, werden Pods von Nodes, die zu wenige Ressourcen haben, auch einfach wieder evicted. Dadurch wird der Pod beendet und womöglich erst zeitverzögert wieder gestartet. Wenn der Pod dabei eigentlich einen kritischen Service ausführen sollte, wäre dieser Ausfall sehr unerwünscht. Für diesen Fall bietet Kubernetes allerdings auch an, Ressourcen für Pods fest zu reservieren. Analog dazu kann man den Ressourcenverbrauch bestimmter Pods auch auf eine Maximum begrenzen. Um das zu demonstrieren, legen wir das folgende Deployment an:
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress
spec:
replicas: 3
selector:
matchLabels:
app: stress
template:
metadata:
labels:
app: stress
spec:
containers:
- name: stress
image: alexeiled/stress-ng
args:
- --vm=1
- --vm-bytes=2g
resources:
requests:
memory: 3G
limits:
memory: 3.5G
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: load-target
operator: Exists
Die in resources festgelegten Ressourcen werden fest für den Container reserviert. Wir können uns also sicher sein, dass sie immer zur Verfügung stehen. Die in limit definierten Ressourcen sind eine harte Grenze für den Container, die nicht überschritten werden darf. Durch die Angabe dieser Werte stellen wir einerseits sicher, dass unser Pod die in requests angegeben Ressourcen immer zur Verfügung hat. Andererseits helfen wir auch Kubernetes, eine Node auszuwählen, die die benötigten Ressourcen auch bereitstellen kann. Nachdem wir das Deployment angelegt haben erscheinen die folgenden Pods:
$ kubectl get pod NAME READY STATUS RESTARTS AGE stress-8485c6dd5d-58m4s 1/1 Running 0 3m56s stress-8485c6dd5d-bznmn 0/1 Pending 0 3m56s stress-8485c6dd5d-jddd7 1/1 Running 0 3m56s
Wie wir sehen, sind zwei der Pods Running, während einer immer noch Pending ist. Wenn wir uns den Pod genau ansehen, sehen wir auch warum:
$ kubectl describe pod stress-8485c6dd5d-bznmn
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 Insufficient memory.
Wie wir sehen, wird der Pod nicht scheduled, weil es keine Node gibt, die den nötigen Speicherplatz zur Verfügung stellen könnte.
Ressourcen die per request zugesichert wurden, stehen dem Container, der sie angefragt hat immer zur Verfügung. Während wir die angefragten Ressourcen verwenden, kann ein anderer Container sie zwar „borgen“. Wenn der Container, der die Ressourcen reserviert hat, die Ressourcen aber selber braucht, werden sie ihm immer zur Verfügung gestellt. Notfalls werden die Pods, die die Ressourcen geborgt haben, dafür auch evicted.
Was passiert, wenn ein Container versucht, das Limit einer Ressource zu überschreiten, hängt von der Ressource ab. Für Speicher-Limits werden ggf. Prozesse im Container getötet, bis das Limit wieder eingehalten wird. CPU-Limits werden durchgesetzt, indem Prozesse die am Limit sind, gedrosselt werden und entsprechend weniger Zeit auf der CPU erhalten.
Das setzen von Memory-Limits und -Requests beeinflusst ebenfalls die Priorität mit der Pods von Nodes evicted werden, wenn die Ressourcen knapp werden. Pods werden dabei in drei unterschiedliche Klassen unterteilt. Diese Klasse kann mit kubectl describe pod <pod> im Feld „QoS Class“ eingesehen werden. Die jeweilige Klasse leitet sich aus der Kombination an Ressourcen-Requests und -Limits nach den folgenden Regeln ab:
- Best Effort: Gilt für Pods deren Container keine Ressourcen-Anfragen haben. Sie werden als erstes evicted.
- Burstable: Gilt für Pods deren Container mindestens eine Ressourcen-Anfrage haben. Sie werden evicted, sobald es keine Pods mit der Klasse Best Effort mehr gibt. Dabei werden zuerst die Pods evicted, die ihre Resource-Requests am weitesten überschreiten
- Guaranteed: Gilt für Pods in denen alle Container Limits für sowohl CPU als auch Memory gesetzt haben. Die Requests und Limits müssen dabei jeweils genau gleich sein. Diese Pods werden nur evicted, wenn es keine andere Wahl gibt.
Fazit
Auch wenn die Standard-Einstellungen zunächst zu nicht ganz so dynamischen Ergebnissen führen, bietet Kubernetes doch eine Reihe von Möglichkeiten mit denen sich sehr flexible Ressourcenzuteilungen realisieren lassen. Von Pods, die vollständig flexibel Ressourcen zugeteilt bekommen, bis zu Pods, die ein strikt definiertes Kontingent an Ressourcen zur Verfügung haben, ist vieles möglich.
In diesem Artikel habe ich für Beispiele nur die Verwaltung von Arbeitsspeicher beachtet. Natürlich lassen sich analog dazu noch weitere Hardware-Ressourcen verwalten. Welche Ressourcen das sind und wie sie gemessen werden, kann man in der Kubernetes-Dokumentation nachlesen.
Bei Fragen rund um den Einsatz von Kubernetes stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an!
Seit einiger Zeit spricht ein Großteil der IT-Landschaft nur noch nur von „Containern“, „Microservices“ und „Kubernetes“.
Doch was sind Container eigentlich und auf welcher technischen Grundlage bauen sie auf?
Allgemeines
Ein Container ist, einfach erklärt, eine abgekapselte Laufzeitumgebung für Prozesse. Es gibt verschiedene Bereiche, die getrennt werden können – die wichtigsten dabei sind Prozesse (pid), Netzwerk (net), Volumes / Festplatten (mnt) und User / Gruppen-IDs (user).
Die Technologie dahinter nennt sich „Namespaces“ und ist im Linux Kernel seit Version 2.4.19 (2002) erstmals implementiert und später erweitert, jedoch erst seit der Version 3.8 (2013) im Userspace, also für die Nutzer sinnvoll nutzbar. Zusätzlich spielt hier die cgroups-Technologie eine große Rolle. Diese ermöglicht es den getrennten Bereichen Ressourcen wie CPU und RAM zur Verfügung zu stellen, bzw. diese zu definieren.
Eine bekannte und frühe Implementierung dieser Features ist lxc (linux containers) welche auch heute noch weiterentwickelt wird und diese Features systemnah umsetzt.
Linux Namespaces
Ein Namespace ist eine Möglichkeit, Ressourcen und Objekte in logische Gruppen zu unterteilen. Man könnte es auch als System-Kontext beschreiben in dem ein Prozess gestartet wird. Dabei ist es kein Problem innerhalb eines Namespaces eigene Namespaces für neu gestartete Prozesse zu erstellen.
Ein Beispiel aus der täglichen Praxis:
Wenn ein Linux Host startet, dann wird je Namespace-Typ eine Instanz erstellt. Der Init-Prozess mit der PID 1 (heute meist systemd) wird dann entsprechend den Instanzen zugeteilt. Dies ist soweit transparent und für die meisten Nutzer auch nur begrenzt relevant. Denn diesen Namespaces stehen alle Ressourcen des Systems zur Verfügung und auch neue Ressourcen werden diesem initial zugeordnet.
Um sich eine Liste der aktuell auf dem System laufenden Namespaces anzusehen gibt es das Tool lsns.
Im folgenden Beispiel sehen wir die initial erstellen Namespaces und die Zuweisung des init-Prozesses.
[root@buildah ~]# lsns -p1
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531836 pid 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531837 user 95 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531838 uts 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531839 ipc 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531840 mnt 90 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531992 net 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
Ein Prozess kann immer nur einem Namespace pro Typ zugewiesen sein. So kann dem Prozess mit der PID 1 aus dem obigen Beispiel kein zusätzlicher pid-Namespace zugewiesen werden.
Die verschiedenen Typen haben untereinander keine Wechselwirkungen oder Abhängigkeiten. So kann man einem neuen Prozess (z.B. einer Shell) auch nur einen eigenen net-namespace zuordnen.
Um als Nutzer einen neuen Namespace zu erstellen, gibt es das Tool unshare. Mittels Parameter ist es hier möglich festzulegen, welche Namespacetypen für den Prozess erstellt werden sollen.
Folgend ein Beispiel wie eine Container-ähnliche Umgebung (in der alle möglichen Bereiche vom Hostsystem separiert werden) manuell erstellt werden kann.
Dazu starten wir mit einem normalen Nutzer ohne root-Berechtigungen eine Bash-Shell mit den gezeigten Parametern.
[podmanager@buildah ~]$ unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
[root@buildah ~]# id
uid=0(root) gid=0(root) Gruppen=0(root) Kontext=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
[root@buildah ~]# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@buildah ~]# lsns
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026531836 pid 1 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532192 user 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532193 mnt 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532194 uts 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532196 ipc 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532198 pid 2 953 root /bin/bash
4026532200 net 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
Wie zu sehen ist, befindet sich der Prozess nun in einem gekapselten Bereich mit eigenen IDs und Netzwerkbereich. Es wurde jedoch die gesamte Festplattenkonfiguration mit in den neuen Bereich übernommen, und somit auch der Ordner /proc, in dem die Prozesse des Hostsystems aufgelistet sind.
[root@buildah ~]# ps -ef f | head
UID PID PPID C STIME TTY STAT TIME CMD
nobody 2 0 0 14:22 ? S 0:00 [kthreadd]
nobody 3 2 0 14:22 ? I< 0:00 \_ [rcu_gp]
nobody 4 2 0 14:22 ? I< 0:00 \_ [rcu_par_gp]
nobody 6 2 0 14:22 ? I< 0:00 \_ [kworker/0:0H-kblockd]
nobody 8 2 0 14:22 ? I< 0:00 \_ [mm_percpu_wq]
nobody 9 2 0 14:22 ? S 0:00 \_ [ksoftirqd/0]
nobody 10 2 0 14:22 ? I 0:00 \_ [rcu_sched]
nobody 11 2 0 14:22 ? S 0:00 \_ [migration/0]
nobody 12 2 0 14:22 ? S 0:00 \_ [watchdog/0]
Um dies noch zu berichtigen ist ein mount -t proc proc /proc nötig. Dieses überlagert das /proc des Host-Systems wodurch nun ausschließlich die Prozesse der neuen Umgebung sichtbar sind.
[root@buildah ~]# mount -t proc proc /proc
[root@buildah ~]# ps -ef f
UID PID PPID C STIME TTY STAT TIME CMD
root 1 0 0 15:05 pts/1 S 0:00 /bin/bash
root 27 1 0 15:11 pts/1 R+ 0:00 ps -ef f
Um die Umgebung zu verlassen genügt ein exit, oder die Tastenkombination STRG+D.
[root@buildah ~]# exit
exit
[podmanager@buildah ~]$
cgroups
Control Groups (kurz cgroups) sind kein direkter Namespace, sondern ermöglichen es Prozesse in einer Art Namespace zu gruppieren und die zur Verfügung stehenden Ressourcen wie CPU und / oder RAM zu begrenzen bzw. zu priorisieren.
Es gibt mittlerweile eine aktualisierte Version der cgroups (cgroupsV2) im Kernel. Jedoch wird diese produktiv wohl nur von Fedora >= 31 genutzt, da es hier einige Inkompatibilitäten mit Docker, jedoch nicht mit Podman gibt.
Die Einrichtung ist jedoch etwas komplexer und soll daher hier nicht erläutert werden, sondern wird Gegenstand eines eigenen Artikels.
Weiterführende Information dazu finden sich jedoch für Interessierte hier (cgroupsv1) und hier (cgroupsv2)
Das Dateisystem eines Containers
Jeder Container beinhaltet alle für den Betrieb der Binaries notwendigen Komponenten, wie Bibliotheken und Binaries.
Die einzige Abhängigkeit zum Hostsystem besteht im Allgemeinen darin, dass die Applikationen auf dem Kernel des Hostsystems lauffähig sein müssen.
Das Dateisystem ist dabei jedoch keine separate Festplatte oder ähnliches, sondern lediglich ein Archiv, das einen Verzeichnisbaum enthält.
Dieses Archiv wird dann spätestens beim Start eines Containers in einen Ordner entpackt und mittels eines mnt-Namespaces und chroot auf diesen Ordner als neues Dateisystem genutzt. Das chroot ändert dabei den Einstiegspunkt für das Dateisystem auf das der Nutzer Zugriff hat. So wird z.B. /var/lib/docker/container1/dateisystem auf dem Host zum neuen / innerhalb des Containers.
Auch dazu ein Beispiel mit der separierten Umgebung aus dem vorherigen Abschnitt.
Zuerst exportieren wir das Dateisystem des Postgres-Containers als tar-Archiv und entpacken es anschließend in einen Unterordner.
[podmanager@buildah ~]$ podman export 3b62694339c6 -o postgres_container.tar
[podmanager@buildah ~]$ ls -l postgres_container.tar
-rw-r--r--. 1 podmanager podmanager 313597440 31. Mär 15:31 postgres_container.tar
[podmanager@buildah ~]$ mkdir postgres_root
[podmanager@buildah ~]$ tar -xf postgres_container.tar -C postgres_root/
[podmanager@buildah ~]$ ls -l postgres_root/
insgesamt 12
drwxr-xr-x. 2 podmanager podmanager 4096 3. Mär 01:27 bin
drwxr-xr-x. 2 podmanager podmanager 6 1. Feb 18:09 boot
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 dev
drwxr-xr-x. 2 podmanager podmanager 6 3. Mär 01:27 docker-entrypoint-initdb.d
lrwxrwxrwx. 1 podmanager podmanager 34 4. Mär 18:35 docker-entrypoint.sh -> usr/local/bin/docker-entrypoint.sh
drwxr-xr-x. 37 podmanager podmanager 4096 31. Mär 14:24 etc
drwxr-xr-x. 2 podmanager podmanager 6 1. Feb 18:09 home
drwxr-xr-x. 8 podmanager podmanager 96 26. Feb 01:54 lib
drwxr-xr-x. 2 podmanager podmanager 34 24. Feb 01:00 lib64
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 media
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 mnt
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 opt
drwxr-xr-x. 2 podmanager podmanager 6 1. Feb 18:09 proc
drwx------. 2 podmanager podmanager 76 31. Mär 14:44 root
drwxr-xr-x. 5 podmanager podmanager 84 31. Mär 14:24 run
drwxr-xr-x. 2 podmanager podmanager 4096 3. Mär 01:27 sbin
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 srv
drwxr-xr-x. 2 podmanager podmanager 6 1. Feb 18:09 sys
drwxrwxr-x. 2 podmanager podmanager 6 3. Mär 01:27 tmp
drwxr-xr-x. 10 podmanager podmanager 105 24. Feb 01:00 usr
drwxr-xr-x. 11 podmanager podmanager 139 24. Feb 01:00 var
Nun erstellen wir wieder eine Shell mit eigenen Namespaces und führen das chroot aus.
[podmanager@buildah ~]$ unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
[root@buildah ~]# cat /etc/redhat-release
CentOS Linux release 8.1.1911 (Core)
[root@buildah ~]# chroot postgres_root
root@buildah:/var/lib/postgresql/data# /bin/cat /etc/issue
Debian GNU/Linux 10 \n \l
Zum Abschluss muss noch das /proc-Dateisystem, wie erwähnt, berichtigt werden.
Ist dies erledigt, haben wir die gleiche Arbeitsumgebung die wir auch in einem Container hätten.
root@buildah:/var/lib/postgresql/data# /bin/mount -t proc proc /proc
root@buildah:/var/lib/postgresql/data# /bin/ps -ef f
UID PID PPID C STIME TTY STAT TIME CMD
root 1 0 0 13:34 ? S 0:00 /bin/bash
root 27 1 0 13:35 ? S 0:00 /bin/bash -i
root 54 27 0 13:43 ? R+ 0:00 \_ /bin/ps -ef f
Fazit
Dies ist natürlich nur ein schneller Überblick über das technische Gerüst der Containertechnologie, das auf bekannten Features des Linux-Kernels baut.
Docker und auch Podman nutzen diese Features, bieten jedoch sehr viel mehr Funktionen und vor allem Komfort-Funktionen im Handling dazu.
Spätestens bei der Nutzung von Containerorchestrierungswerkzeugen wie Kubernetes oder okd kommen ebenfalls einige Schichten an Komplexität hinzu.
Bei Fragen rund um den Einsatz von Containern stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an!
Was ist „GitOps“?
Der Begriff „GitOps“ wird verwendet, wenn zur Einrichtung und Wartung von Infrastruktur und Applikationen eines oder mehrere Code-Repositories (meist Git) als Grundlage dienen. In diesen werden z.B. die Kubernetes-Yamls verwaltet die auf dem einen oder anderen Weg in Kubernetes deployed werden sollen.
Ein anderes Beispiel wären Ansible-Playbooks (kubespray, ansible-ceph), die ebenfalls über ein Git-Repository versioniert werden können. So ist jederzeit ersichtlich, wer welche Änderung zu welchem Zeitpunkt durchgeführt hat. Alte Stände können somit ohne Aufwand wiederhergestellt werden.
Gerade im Kubernetes-Umfeld gibt es zu den Repositories häufig noch eine Pipeline, die die hinterlegten Daten verarbeitet und deployed.
Als Alternative bieten sich hier natürlich Operatoren direkt in Kubernetes an, die die Aufgaben einer separaten Pipeline übernehmen und speziell für die Wartung von Kubernetes-Deployments konzipiert sind. Hierzu zählen Lösungen wie z.B. Flux oder auch Argo CD.
Das Projekt
Flux (oder auch FluxCD) wird primär von Weaveworks (für das CNI-Plugin bekannt) entwickelt. Ursprünglich sollte Flux als Service-Routing-Tool für Container entwickelt werden, was jedoch recht schnell verworfen wurde.
Am 22.08.2017 wurde Flux in der Version 1.0 veröffentlicht. Seitdem werden im Abstand von 1-2 Monaten neue Versionen released. Der Quellcode ist wie üblich auf Github hinterlegt, die Website des Projekts findet sich unter https://fluxcd.io/.
Das Projekt besteht aus zwei Hauptkomponenten, dem fluxd-Daemon, der im Kubernetes-Cluster deployed wird, und dem fluxctl-CLI, die z.B. lokal verwendet werden kann, um den fluxd zu steuern bzw. Flux im Cluster zu installieren. Beide Komponenten sind in golang implementiert.
Funktionsweise
Dankenswerterweise stellt Flux ein übersichtliches Schaubild zur Verfügung, das die Abläufe illustriert:
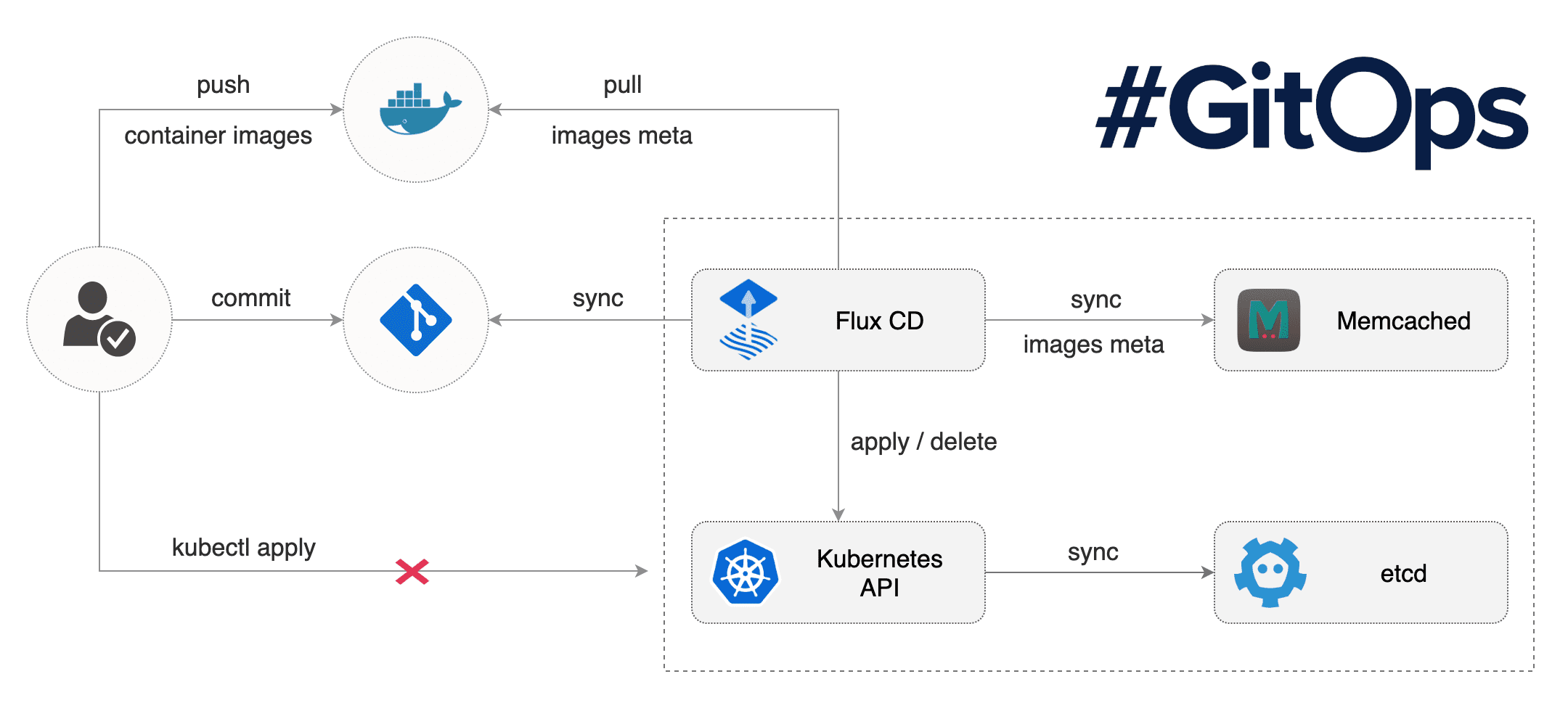
Via fluxctl wird der fluxd+memcache in einem Namespace im Cluster deployed und für ein Git-Repository konfiguriert. Dieses wird dann in regelmäßigen Abständen gepulled und die im Repository enthaltenen Yaml-Files im Cluster deployed.
Zusätzlich bietet Flux die Möglichkeit, automatisiert Images, die in Containern benutzt werden, zu aktualisieren sobald eine neue Version bereitsteht.
Die Details zu den einzelnen Funktionen folgen in einem späteren Abschnitt.
Installation
Die Installation von Flux ist in der Dokumentation entsprechend beschrieben. Vor der Installation sollte man sich jedoch die Einschränkungen genauer anschauen.
So kann Flux z.B. aktuell pro Instanz nur ein einzelnes Git-Repository nutzen. Ausserdem kann es im Vergleich zu den Hosts oder Kubernetes selbst, Unterschiede in der Möglichkeit der Namensauflösung geben, da Flux selbst in einem Container läuft. So können z.B. keine Image-Metadaten ausgelesen werden wenn eine private Registry genutzt wird die auf localhost lauscht.
Die genauen, einzelnen Schritte sollen hier nicht weiter ausgeführt werden, da diese bereits sehr ausführlich dokumentiert sind.
Wichtig: fluxctl benötigt für die Ausführung zwingend ein konfiguriertes kubectl auf dem Host, auf dem es ausgeführt wird. Da während der Installation neue RBACs für den Serviceaccount von fluxd angelegt werden, was entsprechend weitreichende Berechtigungen benötigt, empfiehlt es sich, diese mit cluster-admin Berechtigungen auszuführen. Es ist auch möglich fluxctl beim Aufruf den kubectl-Context mitzuteilen, welchen er nutzen soll, sollte dieser vom Standardcontext abweichen.
Folgend der Ablauf der Installation auf der Kommandozeile. Der Aufruf zur Installation von Flux wurde dabei der Einfachheit halber in ein kurzes Shellskript eingebettet:
#!/bin/bash
GITUSER=""
GITMAIL=""
GITURL=""
GITPATHS="namespaces,workloads"
FLUXNS="flux"
fluxctl install \
--git-user=${GITUSER} \
--git-email=${GITMAIL} \
--git-url=${GITURL} \
--git-path=${GITPATHS} \
--namespace=${FLUXNS} | kubectl apply -f -
$ kubectl create ns flux
namespace/flux created
$ ./install_flux.sh
deployment.apps/flux created
secret/flux-git-deploy created
deployment.apps/memcached created
service/memcached created
serviceaccount/flux created
clusterrole.rbac.authorization.k8s.io/flux created
clusterrolebinding.rbac.authorization.k8s.io/flux created
$ kubectl get all -n flux
NAME READY STATUS RESTARTS AGE
pod/flux-676dcdd787-tbqcw 1/1 Running 0 119s
pod/memcached-86bdf9f56b-8kj46 1/1 Running 0 119s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/memcached ClusterIP 10.106.85.32 <none> 11211/TCP 119s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/flux 1/1 1 1 119s
deployment.apps/memcached 1/1 1 1 119s
NAME DESIRED CURRENT READY AGE
replicaset.apps/flux-676dcdd787 1 1 1 119s
replicaset.apps/memcached-86bdf9f56b 1 1 1 119s
Da Flux sich im Standard mittels SSH am Git-Repository authentifiziert, muss der Public-Key von Flux noch hinterlegt werden.
Diesen kann man sich via fluxctl mit folgendem Befehl ausgeben lassen:
$ fluxctl identity --k8s-fwd-ns flux
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDP3mVuuDYto+lhuxRbZFrAV0jurOgNwxzFnWxHVKP9EZpnUOK0FUPiiTnMvCQK1PrGSHmXoXEgQvx9UU+XgEStOvr3xlU2AjkvFwaH+2MbSrT0HEV/2Nib2YVyeM+4T65BY7E+pkqrSQg86Q3WN7x3d1peMJQI4BeMmsaddPI7dpvy+unxTe0cdS/D6IjH6em9pTKwaWx+h9kp8BpQBI+OTFoL6dEp+ITZi+bCkk43R9zVhw21SroutTvPuIgdDCIn178JgfsJanA9jAn7woGY8D1+cc6R9jlkcnOR5IVQdOl9CC2EQUgvdZu3cyeW5xZvUwxY+10apZrV9tzHyRA9vqyobHn3sixJc8g3fD8ppVe2xBz9aFFUTEKJJbpNnVyhDXx4Q+nUEUVa17sGjUj05Q3UFTS/YW/YVUJYG4+SYIqxX0PZnvZ6gk94EFa37lWsE0Sud4Z6qnn6yMJD0yP0dAJDd6xLG7/sJGJCalvnhsDP1gVwWLJHtYjEjZXkSHk= root@flux-676dcdd787-tbqcw
Es gibt aber auch die Möglichkeit, einen eigenen, spezifischen Key zu hinterlegen. Dies ist hier genauer erläutert.
Ohne zusätzliche Konfiguration wir das Git-Repository aller 5 Minuten gesynced. Allerdings kann man einen Sync auch manuell auslösen:
$ fluxctl sync --k8s-fwd-ns flux
Synchronizing with ssh://git@gitlab.com/XXX
Revision of master to apply is f27a086
Waiting for f27a086 to be applied ...
Done.
Damit ist Flux erfolgreich installiert und zumindest grundlegend konfiguriert. Ein Beispieldeployment um die Funktionalität initial zu testen findet sich auch auf Github.
Nutzung/Konfiguration
Die Konfiguration des fluxd läuft weniger über den Daemon selbst, als mehr über z.B. Annotations an den Deployments.
Bevor damit begonnen werden kann, sollte noch der Begriff des Workloads erklärt werden. Dieser steht im Kontext von Flux für jede Clusterresource, die in irgendeiner Form Container mittels versionierten Images erstellt. Das wäre in Kubernetes neben Deployments z.B. auch Daemonsets, Statefulsets oder (Cron-)Jobs.
Diese können via dem CLI-Tool fluxctl gesteuert bzw. konfiguriert werden.
Generell werden die Workloads über Annotations gesteuert bzw. geben diese fluxd Anweisungen wie mit ihnen zu verfahren ist.
Ein Beispiel aus dem aktuellen Testcluster (Erläuterungen dazu folgen später):
$ kubectl get replicaset.apps/podinfo-7599d75df -n testspace -o yaml | head -12
apiVersion: apps/v1
kind: ReplicaSet
metadata:
annotations:
deployment.kubernetes.io/desired-replicas: "2"
deployment.kubernetes.io/max-replicas: "3"
deployment.kubernetes.io/revision: "1"
fluxcd.io/automated: "true"
fluxcd.io/sync-checksum: 1845334e4ef3156c6a84a2866206bebb626fac6c
fluxcd.io/tag.init: regex:^3.10.*
fluxcd.io/tag.podinfod: semver:~3.1
creationTimestamp: "2020-03-27T09:05:32Z"
Auflisten der Workloads
Eine Liste der Workloads kann man sich mittels fluxctl list-workloads ausgeben lassen. Dabei werden jedoch nur die Workloads im Namespace des fluxd-Container angezeigt. Um sich die Workloads in allen Namespaces anzeigen zu lassen kann hier -a angehangen werden. Für einen bestimmten Namespace steht -n $NS zu Verfügung wobei $NS der Name des Namespaces ist.
Folgend ein Beispiel aus dem Testsetup:
$ fluxctl list-workloads --k8s-fwd-ns flux -a
WORKLOAD CONTAINER IMAGE RELEASE POLICY
testspace:deployment/podinfo podinfod stefanprodan/podinfo:3.1.5 ready automated
init alpine:3.10
flux:deployment/flux flux docker.io/fluxcd/flux:1.18.0 ready
flux:deployment/memcached memcached memcached:1.5.20 ready
kube-system:daemonset/kube-proxy kube-proxy k8s.gcr.io/kube-proxy:v1.17.3 ready
kube-system:deployment/coredns coredns k8s.gcr.io/coredns:1.6.5 ready
$ fluxctl list-workloads --k8s-fwd-ns flux -n testspace
WORKLOAD CONTAINER IMAGE RELEASE POLICY
testspace:deployment/podinfo podinfod stefanprodan/podinfo:3.1.5 ready automated
init alpine:3.10
Um sich alle Instanzen des Containers podinfod anzeigen zu lassen kann folgendes verwendet werden:
$ fluxctl list-workloads --k8s-fwd-ns flux -a -c podinfod
WORKLOAD CONTAINER IMAGE RELEASE POLICY
testspace:deployment/podinfo podinfod stefanprodan/podinfo:3.1.5 ready automated
init alpine:3.10
Da flux nicht im default-Namespace deployed wurde muss entsprechend immer mit --k8s-fwd-ns flux der Namespace mit angegeben werden, in dem die entsprechende fluxd-Instanz zu finden ist.
Details zu den Workload-Images
Flux scannt neben dem Git-Repository auch die Container-Registry aus dem die Images deployed werden nach allen verfügbaren Versionen. Damit kann man sich auch alle Versionen der Images anzeigen lassen.
Hierfür muss man fluxctl nur zu list-images mitteilen welchen Workload in welchem Namespace man genauer untersuchen möchte.
$ fluxctl list-images --k8s-fwd-ns flux -n testspace --workload deployment/podinfo
WORKLOAD CONTAINER IMAGE CREATED
testspace:deployment/podinfo podinfod stefanprodan/podinfo
| 9715769 27 Oct 18 08:52 UTC
| 7181351 25 Mar 19 10:13 UTC
| 2192219 18 Aug 18 11:24 UTC
| 3.2.1 24 Mar 20 12:05 UTC
| 3.2.0 24 Mar 20 10:19 UTC
'-> 3.1.5 21 Jan 20 11:40 UTC
3.1.4 06 Nov 19 22:21 UTC
3.1.3 06 Nov 19 22:16 UTC
3.1.2 06 Nov 19 22:02 UTC
3.1.1 06 Nov 19 22:00 UTC
init alpine
| 3 23 Mar 20 21:19 UTC
| 3.11 23 Mar 20 21:19 UTC
| 3.11.5 23 Mar 20 21:19 UTC
| latest 23 Mar 20 21:19 UTC
| 20200319 20 Mar 20 03:25 UTC
| edge 20 Mar 20 03:25 UTC
| 3.8 23 Jan 20 16:53 UTC
| 3.8.5 23 Jan 20 16:53 UTC
| 3.9 23 Jan 20 16:53 UTC
| 3.9.5 23 Jan 20 16:53 UTC
'-> 3.10 23 Jan 20 16:53 UTC
Dies zeigt alle verfügbaren Versionen für alle Container im Workload. Hier werden standardmäßig die aktuellsten 10 Versionen + die aktuell Laufende angezeigt. Dies kann man mittels dem Parameter -l anpassen (0 bedeutet dabei alle).
Releasen eines Workloads
Um manuell eine Version eines Images zu deployen gibt es die release Funktion von fluxctl, die automatisch das neueste Image für den Container deployed (sofern nicht durch Konfiguration eingeschränkt).
Da im Deployment unseres Demosystems das automatische Update aktiviert ist, hier ein Beispiel aus der Dokumentation:
$ fluxctl release --workload=default:deployment/helloworld --user=phil --message="New version" --update-all-images
Submitting release ...
Commit pushed: 7dc025c
Applied 7dc025c61fdbbfc2c32f792ad61e6ff52cf0590a
WORKLOAD STATUS UPDATES
default:deployment/helloworld success helloworld: quay.io/weaveworks/helloworld:master-a000001 -> master-9a16ff945b9e
Automatische Releases
Um automatisch immer die neueste Version im Workload deployen zu lassen kann das Automation-Feature aktiviert werden.
Dies kann entweder in den Workload-Yamls im Git-Repository mittels der Annotation fluxcd.io/automated: "true" geschehen oder im Nachgang durch das fluxctl-Kommando
fluxctl automate --workload=$Workload.
Die Automatisierung kann entweder via der Annotation fluxcd.io/automated: "false" oder der CLI mit fluxctl deautomate --workload=$workload deaktiviert werden.
Wird eine neue Version eines Container in der Registry released welcher auch Teil eines Workloads ist, so wird bei aktivierter Automatisierung automatisch auch das Deployment des Workloads angepasst und die neue Version deployed.
Diese Änderung wird dann (in der Standardkonfiguration) auch in das Git-Repository gepushed. In der History äußert sich dies durch Einträge wie:
$ git log workloads/podinfo-dep.yaml
commit f27a08637d69d391bc639b62dfc5353b70a9e2e6 (HEAD -> master, origin/master)
Author: Author
Date: Mon Mar 23 11:39:14 2020 +0000
Auto-release stefanprodan/podinfo:3.1.5
commit 9db210a8066141bd5600f399078a79c2ab462b0b
Author: Author
Date: Mon Mar 23 11:39:01 2020 +0000
Auto-release alpine:3.10
Welche Versionen automatisch deployed werden kann natürlich ebenso konfiguriert werden, um z.B.: sicher zu stellen dass man innerhalb einer Major-Version verbleibt.
Dafür muss am Workload entsprechend die Version gepinned werden. In diesen ist beschrieben welche Tags die Images haben müssen, um deployed zu werden.
Das Schema dabei ist fluxcd.io/tag.<container-name>: <filter-type>:<filter-value> oder filter.fluxcd.io/<container-name>: <filter-type>:<filter-value>.
Als Filtertypen können folgende Optionen gesetzt werden:
- glob
- Einfache Wildcards mit
* - z.B.
fluxcd.io/tag.podinfod: glob:master-v1.*.*
- Einfache Wildcards mit
- semver
- „Semantic Versioning“. Die Tags müssen also in das Schema X.Y.Z. passen, und es kann ein Filter darauf angegeben werden.
- z.B:
fluxcd.io/tag.podinfod: semver:~3.1um alle Images der Version 3.1.X für das automatische Deployment freizugeben
- regexp / regex
- Reguläre Ausrdrücke, z.B.
fluxcd.io/tag.init: regex:^3.10.* - Wie üblich ist zu beachten, dass um den gesamten Tag abzudecken der regex auch mit
^$eingefasst werden muss.
- Reguläre Ausrdrücke, z.B.
Diese Annotations können entweder auch in den yamls der Workloads hinterlegt werden oder nachträglich via z.B. fluxctl policy --workload=default:deployment/helloworld --tag-all='glob:master-v1.*.*' gesetzt werden.
Eine umfassende Dokumentation dazu findet sich hier.
Rollback
Es ist auch soweit problemlos möglich auf ein älteres Release zurück zu wechseln, insofern dieses in die ggf. gesetzten Filter-Tags passt.
Hierzu muss zuerst die Automation abgeschaltet werden. Anschließend kann mit z.B. folgendem fluxctl release ein bestimmtes Release deployed werden:
$ fluxctl release --workload=default:deployment/helloworld --update-image=quay.io/weaveworks/helloworld:master-a000001
Hier ist natürlich bei Stateful-Applications darauf zu achten, das keine Inkompatibilitäten mit Drittkomponenten auftreten.
Locking/Unlocking
Der Vollständigkeit halber sei noch erwähnt, dass man Workloads auch generell via fluxctl lock --workload=deployment/helloworld für automatische Deployments jeder Art sperren kann. Ein entsperren erfolgt dann entsprechend mit fluxctl unlock --workload=deployment/helloworld.
Generierung/Anpassung von Workloads
Flux hat eine Unterstützung für Kustomize bereits von Haus aus eingebaut, womit es möglich ist in begrenztem Maße Workloads mittels Yaml-Overlays dynamisch anzupassen.
Da die Behandlung dieses Themas jedoch den Rahmen des Artikels sprengen würde sei hier nur die Dokumentation verlinkt.
Bei Interesse können wird dies jedoch gern in einem separaten Artikel genauer ausführen.
Bei Fragen zum Einsatz von Flux stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an!
Wer mit Kubernetes arbeitet, der kommt nicht umhin sich auch mit kubectl zu beschäftigen. Es ist das standard Command-Line-Interface zur Arbeit mit einem Kubernetes Cluster.
Dieser Blogpost soll dazu dienen, den initialen Start mit kubectl zu vereinfachen und den ein oder anderen Hinweis aufzuzeigen. Er orientiert sich dabei an Aufgaben und Problemstellungen, mit denen der reguläre Benutzer eines Clusters konfrontiert wird.
Kubeconfig
Zuerst wird eine sogenannte KUBECONFIG Konfigurationsdatei benötigt. Diese beinhaltet alle Parameter, die für eine oder mehrere Verbindung(en) zu Kubernetes benötigt werden.
Pfad
Standardmäßig prüft kubectl, ob sich unter ~/.kube/config eine Konfigurationsdatei findet. Um alternative Konfigurationsdateien zu nutzen, gibt es zwei Optionen diese zu definieren:
- Command-Line-Argument
--kubeconfig=<filepath>oder aber als - Environment Variable
KUBECONFIG=<filepath>
Aufbau
Für eine Verbindung wird mindestens der Name des Clusters und der Benutzer innerhalb des Clusters benötigt. Diese Informationen werden in einem so genannten Context zusammengefasst. Optional kann an dieser Stelle der Namespace angegeben werden, der verwendet wird, sofern dieser beim Aufruf nicht angegeben wird.
Hier ein Beispiel:
contexts:
- context:
cluster: my-k8s-cluster
namespace: default
user: system-admin
name: default/my-k8s-cluster/system:admin
Der gezeigte Context alleine reicht allerdings noch nicht aus, um Kontakt zu unserem Cluster aufzunehmen. Es fehlen Detailinformationen für cluster und user.
Ein user-Eintrag könnte wie folgt aussehen:
users:
- user:
token: eaBQIVe1jFDpsuD3NwsS6c2Qx7+eGDlat6BF2qlsgtY
name: system-admin
Nun fehlen noch Detailinformationen zu unserem cluster:
clusters:
- cluster:
server: https://my-k8s-cluster.example.com:8443
name: my-k8s-cluster
Je nach Authentifikationsmethode des users und Konfiguration des clusters können sich die benötigten Konfigurationseinstellungen unterscheiden.
Werden alle Teile zusammengesetzt, ergibt sich der folgende Aufbau:
apiVersion: v1
kind: Config
current-context: default/my-k8s-cluster/system:admin
clusters:
- cluster:
server: https://my-k8s-cluster.example.com:8443
name: my-k8s-cluster
users:
- user:
token: eaBQIVe1jFDpsuD3NwsS6c2Qx7+eGDlat6BF2qlsgtY
name: system-admin
contexts:
- context:
cluster: my-k8s-cluster
namespace: default
user: system-admin
name: default/my-k8s-cluster/system:admin
Neben den bereits gezeigten Abschnitten definieren wir den ausgewählten Context.
Auch wenn der Name des Contexts frei gewählt werden kann, empfehlen sich eindeutige Bezeichnungen: default/my-k8s-cluster/system:admin
Dieser beinhaltet alle wichtigen Details zur Verbindung und ist damit eindeutig identifizierbar.
Zusätzliche Einträge wie cluster, user und context können ebenfalls definiert werden.
Somit ist es möglich, verschiedene Konstellationen in der Konfiguration zu hinterlegen, zwischen denen gewechselt werden kann.
Contexts
Die konfigurierten contexts können wir uns mit dem folgenden Befehl anzeigen lassen.
$ kubectl config get-contexts CURRENT NAME CLUSTER AUTHINFO NAMESPACE * default/my-k8s-cluster/system:admin my-k8s-cluster system-admin default
Der ausgewählte context wird durch einen * gekennzeichnet. Sofern mehrere contexts definiert wurden, können diese mit kubectl config use-context <context> gewechselt werden.
kubectl bietet neben der Anzeige und Auswahl der contexts auch die Möglichkeit die ausgewählte KUBECONFIG via Command-Line zu editieren.
Wie dies genau funktioniert, beschreibt die Hilfeausgabe:
$ kubectl config --help
Modify kubeconfig files using subcommands like "kubectl config set current-context my-context"
The loading order follows these rules:
1. If the --kubeconfig flag is set, then only that file is loaded. The flag may only be set once and no merging takes
place.
2. If $KUBECONFIG environment variable is set, then it is used as a list of paths (normal path delimiting rules for
your system). These paths are merged. When a value is modified, it is modified in the file that defines the stanza. When
a value is created, it is created in the first file that exists. If no files in the chain exist, then it creates the
last file in the list.
3. Otherwise, ${HOME}/.kube/config is used and no merging takes place.
Available Commands:
current-context Displays the current-context
delete-cluster Delete the specified cluster from the kubeconfig
delete-context Delete the specified context from the kubeconfig
get-clusters Display clusters defined in the kubeconfig
get-contexts Describe one or many contexts
rename-context Renames a context from the kubeconfig file.
set Sets an individual value in a kubeconfig file
set-cluster Sets a cluster entry in kubeconfig
set-context Sets a context entry in kubeconfig
set-credentials Sets a user entry in kubeconfig
unset Unsets an individual value in a kubeconfig file
use-context Sets the current-context in a kubeconfig file
view Display merged kubeconfig settings or a specified kubeconfig file
Usage:
kubectl config SUBCOMMAND [options]
Use "kubectl <command> --help" for more information about a given command.
Use "kubectl options" for a list of global command-line options (applies to all commands).
Anzeige
Das wohl meistgenutzte Feature von kubectl ist die Anzeige von Objekten innerhalb des Clusters und deren Status. Hierzu stehen gleich mehrere Methoden bereit, je nachdem welche Informationen wir uns anzeigen lassen wollen. Unter anderem:
get: Auflisten und Anzeigen von Objektendescribe: Beschreibung von Objekten und deren Statuslogs: Anzeige der Logs eines Containersexplain: Anzeigen des Aufbaus von Ojekten
get
Mittels der get Methoden kann sich der User alle Objekte innerhalb des Clusters anzeigen lassen, auf die er Zugriff hat.
Hierzu muss mindestens ein Objekttyp angegeben werden, der angezeigt werden soll. Alternativ kann man sich mit all auch mehrere Objekttypen anzeigen lassen.
An dieser Stelle sollte angemerkt werden, dass all nicht all bedeutet. Es werden lediglich die gängigsten Objekte angezeigt.
$ kubectl get pods NAME READY STATUS RESTARTS AGE nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 47s nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 47s
$ kubectl get all NAME READY STATUS RESTARTS AGE pod/nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 100s pod/nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 100s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/nginx-deployment 2/2 2 2 100s NAME DESIRED CURRENT READY AGE replicaset.apps/nginx-deployment-6dd86d77d 2 2 2 100s
Die ausgabe des all Befehls kann in unserem konkreten Fall auch dadurch erreicht werden, dass mehrere Objekttypen gleichzeitig abgefragt werden.
Um alle Instanzen der Objekttypen pod, deployment und replicaset anzuzeigen, können wir auch folgenden Befehl verwenden:
$ kubectl get pods,deployments,replicasets NAME READY STATUS RESTARTS AGE pod/nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 4m35s pod/nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 4m35s NAME READY UP-TO-DATE AVAILABLE AGE deployment.extensions/nginx-deployment 2/2 2 2 4m35s NAME DESIRED CURRENT READY AGE replicaset.extensions/nginx-deployment-6dd86d77d 2 2 2 4m35s
Sobald die Antwort des Servers mehrere Objekttypen beinhaltet, werden die einzelnen Objektnamen mit ihrem Typ gepräfixt.
Soll nur der Status eines spezifischen Objekts ausgegeben werden, so geschieht dies durch Angabe des Objektnamens nach dem Objekttyp:
$ kubectl get pod nginx-deployment-6dd86d77d-5hldn NAME READY STATUS RESTARTS AGE nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 19m
Alternativ kann auch die Syntax <typ>/<name> verwendet werden.
Zum Beispiel: kubectl get pod/nginx-deployment-6dd86d77d-5hldn
Welche Informationen bei der Anzeige ausgegeben werden, hängt sowohl vom Ojekttyp selber, als auch vom Ausgabeformat ab. Neben dem Standardausgabeformat stehen unter anderem die folgenden Formate zur Verfügung:
wide: Darstellung zusätzlicher Informationenyaml: Ausgabe des gesamten Objekts im YAML formatjson: Ausgabe des gesamten Objekts im JSON formatjsonpath: Ausgabe definierter Bereiche
Eine vollständige Liste der Ausgabeformate kann der Ausgabe von kubectl get --help entnommen werden.
Schauen wir uns beispielsweise die Ausgabe der laufenden Pods mithilfe des Ausgabeformats wide an, dann werden neben den bereits bekannten Informationen zusätzliche Laufzeitinformationen angezeigt. Hierzu zählen unter anderem die IP-Adresse des Pods, sowie der Node auf dem der Pod ausgeführt wird.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 112m 10.233.65.109 node-05.example.com <none> <none> nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 112m 10.233.79.238 node-04.example.com <none> <none>
Die Formate yaml sowie json unterscheiden sich – abgesehen vom Format selbst – nicht in ihrem Inhalt. Beide liefern das ausgewählte Objekt und all seine Eigenschaften zurück.
Neben den manuell definierten Eigenschaften liefern die beiden Ausgabeformate zudem sehr detailierte Informationen über den Status des Objekts.
Ausklappen
$ kubectl get pod nginx-deployment-6dd86d77d-5hldn -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2019-08-26T12:18:51Z"
generateName: nginx-deployment-6dd86d77d-
labels:
app: nginx
pod-template-hash: 6dd86d77d
name: nginx-deployment-6dd86d77d-5hldn
namespace: test
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: nginx-deployment-6dd86d77d
uid: aa4125fe-c7fb-11e9-aa70-96000014cd55
resourceVersion: "70713161"
selfLink: /api/v1/namespaces/test/pods/nginx-deployment-6dd86d77d-5hldn
uid: aa452873-c7fb-11e9-aa70-96000014cd55
spec:
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-q2h6q
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: node-05.example.com
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: default-token-q2h6q
secret:
defaultMode: 420
secretName: default-token-q2h6q
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2019-08-26T12:18:51Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: docker://52dfe6498a96a92ec118dbf18705237792c703be33a86498c53676b1028343b7
image: nginx:1.7.9
imageID: docker-pullable://nginx@sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451
lastState: {}
name: nginx
ready: true
restartCount: 0
state:
running:
startedAt: "2019-08-26T12:18:53Z"
hostIP: 10.66.0.5
phase: Running
podIP: 10.233.65.109
qosClass: BestEffort
startTime: "2019-08-26T12:18:51Z"
Das Ausgabeformat jsonpath ist immer dann hilfreich, wenn Abschnitte der Ausgabe weiterverarbeitet werden sollen. Ein Beispiel stellt das Dekodieren eines base64 kodierten secrets dar.
Values innerhalb von secrets werden base64 kodiert gespeichert, was bedeutet, dass wir die Kodierung zunächst durch den Aufruf von base64 -d rückgängig machen müssen. Dank jsonpath können wir das in einem Aufruf bewerkstelligen.
Angenommen, wir wollen den Wert des Keys password als Plaintext darstellen und unser secret ist wie folgt aufgebaut. Dies können wir dann mithilfe des Befehls kubectl get secret mysecret -o jsonpath='{.data.password}' | base64 -d bewerkstelligen.
apiVersion: v1 data: password: c3VwZXJzZWN1cmUxMjM= kind: Secret metadata: creationTimestamp: "2019-08-26T14:38:05Z" name: mysecret namespace: test resourceVersion: "70750555" selfLink: /api/v1/namespaces/test/secrets/mysecret uid: 1d4a2224-c80f-11e9-8df3-96000014cd46 type: Opaque
$ kubectl get secret mysecret -o jsonpath='{.data.password}' | base64 -d
supersecure123
Auch ist es möglich, sich ausschließlich Objekte mit einem bestimmten Label anzeigen zu lassen. Hierzu bietet kubectl für den get Befehl die entsprechende Filteroption. Wollen wir uns beispielsweise alle deployments, replicasets und pods mit dem Label app=nginx anzeigen, so können wir dies mit dem folgenden Befehl bewerkstelligen:
kubectl get deployments,replicasets,pods -l app=nginx NAME READY UP-TO-DATE AVAILABLE AGE deployment.extensions/nginx-deployment 2/2 2 2 7d6h NAME DESIRED CURRENT READY AGE replicaset.extensions/nginx-deployment-6dd86d77d 2 2 2 7d6h NAME READY STATUS RESTARTS AGE pod/nginx-deployment-6dd86d77d-5hldn 1/1 Running 0 7d6h pod/nginx-deployment-6dd86d77d-jr7hk 1/1 Running 0 7d6h
Welches Label ein Objekt besitzt, kann übrigens durch den zusätzlichen get-Parameter --show-labels angezeigt werden.
describe
Neben der einfachen Auflistung der Objekte ist es oftmals hilfreich, sich Objekte beschreiben zu lassen. Hierzu steht der Befehl describe zur Verfügung.
Die Ausgabe des describe-Befehls gibt eine relativ ausführliche Darstellung des Aufbaus und des Zustands des Objektes aus. Die describe-Ausgabe eines Pods gibt beispielsweise Aufschluss über:
- Die priority-class des Pods
- Container des Pods einschließlich:
- Pod-ID
- Image-Hash (sh256-Hash)
- Status
- QoS-Class
- Node-Selectors
- Tolerations
- Events
Vor allem die Events eines Objekts sind oft ein wertvolles Mittel, um eventuellen Fehlern auf die Schliche zu kommen. Als Beispiel sei die Analyse der Fehlermeldung „ImagePullBackOff“ genannt. Oftmals bieten die Events einen Anhaltspunkt wo bei der Fehlanalyse anzusetzten ist.
$ kubectl describe pod nginx-deployment-6dd86d77d-9fm6w
Name: nginx-deployment-6dd86d77d-9fm6w
Namespace: test
Priority: 0
PriorityClassName: <none>
Node: node-05.example.com/10.66.0.5
Start Time: Mon, 02 Sep 2019 20:44:29 +0200
Labels: app=nginx
pod-template-hash=6dd86d77d
Annotations: <none>
Status: Running
IP: 10.233.65.100
Controlled By: ReplicaSet/nginx-deployment-6dd86d77d
Containers:
nginx:
Container ID: docker://7a3e3b51987da42a421d6f965824bfe2ba5d553a9f1d2e93758207c34cd4e31b
Image: nginx:1.7.9
Image ID: docker-pullable://nginx@sha256:e3456c851a152494c3e4ff5fcc26f240206abac0c9d794affb40e0714846c451
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Mon, 02 Sep 2019 20:44:31 +0200
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-q2h6q (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
default-token-q2h6q:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-q2h6q
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 19s default-scheduler Successfully assigned test/nginx-deployment-6dd86d77d-9fm6w to node-05.example.com
Normal Pulled 18s kubelet, node-05.example.com Container image "nginx:1.7.9" already present on machine
Normal Created 18s kubelet, node-05.example.com Created container nginx
Normal Started 17s kubelet, node-05.example.com Started container nginx
logs
Wird die Ausgabe eines Containers benötigt, so steht der Befehl logs zur Verfügung. Sollte sich ein Pod im Status „CrashLoopBackOff“ befinden, gibt die Anzeige der Logs des ensprechenden Containers meist Aufschluss über die Ursache des Problems.
Bei der Verwendung des logs-Befehls müssen wir explizit zwischen Pods und Containern unterscheiden. Da ein Pod mehrere Container beinhalten kann reicht es, dass einer der Container nicht richtig funktioniert, um den Pod in einen fehlerhaften Zustand zu bringen.
Sollen die Logs eines Pods mit ausschließlich einem Container angezeigt werden, so gestaltet sich die Ausgabe der Logs recht einfach:
$ kubectl logs nginx-deployment-6dd86d77d-9fm6w
Beinhaltet der zu analysierende Pod mehrere Container wird Kubernetes auf die gleiche Anfrage mit einem Fehler antworten.
Dabei ist Kubernetes allerdings so freundlich und liefert die entsprechende Lösung gleich mit.
Beinhaltet ein Pod mehrere Container, so muss neben dem Pod-Namen ebenfalls der Container-Name angegeben werden:
$ kubectl logs nginx-deployment-6dd86d77d-9fm6w -c nginx
Oftmals muss die Ausgabe des logs-Befehls allerdings nicht für die akute Fehlerbehebung herangezogen werden, sondern wird bei der Fehleranalyse vergangener Ereignisse benötigt.
Hierzu steht das zusätzliche Flag --previous zur Verfügung. Dabei werden nicht die aktuellen Logs des Containers angezeigt, sondern die der vorangegangenen Instanz des Containers / Pods.
Explain
Wer (wie ich) nicht immer den exakten Namen eines Parameters oder dessen Platzierung innerhalb der Objektstruktur im Kopf hat, kann sich mit Hilfe des explain-Befehls selbst helfen und sich den korrekten Aufbau eines Kubernetes-Objekts in der genutzten API-Version anzeigen zu lassen.
Er gibt neben dem Aufbau von Objekten auch eine kurze Beschreibung zu allen Parametern aus.
Wollen wir uns beispielsweise den Aufbau der Pod-Spezifiation anschauen, so könnnen wir dies mithilfe des folgenden Befehls bewerkstelligen:
$ kubectl explain pod
KIND: Pod
VERSION: v1
DESCRIPTION:
Pod is a collection of containers that can run on a host. This resource is
created by clients and scheduled onto hosts.
FIELDS:
apiVersion <string>
APIVersion defines the versioned schema of this representation of an
object. Servers should convert recognized schemas to the latest internal
value, and may reject unrecognized values. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#resources
kind <string>
Kind is a string value representing the REST resource this object
represents. Servers may infer this from the endpoint the client submits
requests to. Cannot be updated. In CamelCase. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#types-kinds
metadata <Object>
Standard object's metadata. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#metadata
spec <Object>
Specification of the desired behavior of the pod. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status
status <Object>
Most recently observed status of the pod. This data may not be up to date.
Populated by the system. Read-only. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status
Wer eine rekursive Auflistung aller möglichen Parameter erhalten möchte erlangt diese mithilfe des folgenden Befehls:
kubectl explain --recursive pod.spec
KIND: Pod
VERSION: v1
RESOURCE: spec <Object>
DESCRIPTION:
Specification of the desired behavior of the pod. More info:
https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status
PodSpec is a description of a pod.
FIELDS:
activeDeadlineSeconds <integer>
.. Output Skipped ...
automountServiceAccountToken <boolean>
containers <[]Object>
args <[]string>
command <[]string>
env <[]Object>
name <string>
value <string>
valueFrom <Object>
configMapKeyRef <Object>
key <string>
name <string>
optional <boolean>
fieldRef <Object>
apiVersion <string>
fieldPath <string>
resourceFieldRef <Object>
containerName <string>
divisor <string>
resource <string>
secretKeyRef <Object>
key <string>
name <string>
optional <boolean>
.. Output Skipped ..
name <string>
ports <[]Object>
.. Output Skipped ...
volumes <[]Object>
awsElasticBlockStore <Object>
fsType <string>
partition <integer>
readOnly <boolean>
volumeID <string>
.. output Skipped ..
vsphereVolume <Object>
fsType <string>
storagePolicyID <string>
storagePolicyName <string>
volumePath <string>
Die Ausgabe des explain-Befehls kann so eine Recherche innerhalb der Kubernetes-Dokumentation überflüssig machen. Das spart nicht nur Zeit, sondern oftmals auch Nerven.
Code-Completion
Wer regelmäßig mit der Konsole arbeitet, lernt das autocompletion-Feature zu lieben.
Oftmals ist die Syntax eines Befehles nicht 100 prozentig klar, oder es müssen Argumente vervollständigt werden, deren Namen man sich einfach nicht merken kann oder will. Viele Command-Line-Tools bringen deshalb so genannte completion-files mit und kubectl ist hier keine Ausnahme.
Wer die autocompletion-Funktionalität von kubectl verwenden will, muss dazu den Befehl kubectl completion ... bemühen. Der completion-Befehl gibt die entsprechenden completion-scripts sowohl für bash als auch für zsh aus. Wer die Autovervollständigung ad-hoc nutzten möchte, der kann sich mithilfe der folgenden Befehle behelfen:
bash: source <(kubectl completion bash)
zsh: source <(kubectl completion zsh)
Wer auch nach Beenden des Terminals in den Genuss der Auto-Completion kommen möchte, speichert sich die Ausgabe der Befehle kubectl completion bash/zsh innerhalb einer Datei ab und lädt diese wie gewohnt innerhalb seiner .bashrc oder .zshrc.
Anlegen / Ändern / Löschen
Zum Anlegen, Ändern oder Löschen von Objekten stehen via kubectl unterschiedliche Methoden zur Verfügung. Alle haben gemeinsam, dass sie das zu kontrollierende Objekt anhand ihres Namens und Namespaces (bei namespacesbehafteten Objekten) identifizieren.
Um ein neues Objekt im Cluster anzulegen, können sowohl die Befehle create als auch apply verwendet werden. Dabei setzt create voraus, dass das Zielobjekt noch nicht existiert. Das folgende Beispiel zeigt die Erzeugung eines Deplyoments, welcher den Webserver Nginx als einzigen Pod beinhaltet:
create
$ kubectl create deployment nginx --image=nginx deployment.apps/nginx created
Versuchen wir nun das gleiche Deployment erneut anzulegen, erhalten wir eine Fehlermeldung, weil ein Deployment mit den namen nginx bereits exisiert.
kubectl create deployment nginx --image=nginx Error from server (AlreadyExists): deployments.apps "nginx" already exists
Der create Befehl stellt somit eine konkrete Aktion dar und beschreibt nicht – wie andere Befehle – den Zielzustand.
Des Weiteren wurde die Definition des Objekts nicht lokal gespeichert, sondern lediglich dem Cluster mitgeteilt. Um das Objekt, in unserem Fall das Nginx Deployment, auch in anderen Cluster bereitzustellen, muss nun der gleiche Befehl gegen den neuen Cluster ausgeführt werden.
Oftmals ist es eine bessere Idee, Objekte nicht ad-hoc zu erstellen, sondern den Zwischenweg über eine YAML Datei zu gehen, welche die Definition des Selbigen beinhaltet.
kubectl create kann hierbei Hilfestellung leisten.
Der Parameter --output yaml erstellt nicht nur das Objekt, er generiert auch die Definition des Objekts im YAML Format und gibt diese auf der Konsole aus.
Soll die generierte Definition vor dem Einspielen in den Cluster bearbeitet werden, so kann zwischenzeitlich der Parameter --dry-run genutzt werden.
Beispiel:
$ kubectl create deployment nginx --image=nginx --output=yaml --dry-run
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: nginx
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
Die Ausgabe des oben stehenden Befehls kann nun als Datei abgelegt und beispielsweise durch Git unter Versionskontrolle gestellt werden.
Wer die resultierende Definition via create gegen den Cluster anwenden will, der kann dies mit dem Befehl kubectl create -f nginx-deployment.yaml bewerkstelligen.
Eine Hilfestellung bietet create oft dann, wenn die Alternative zu fehleranfällig wäre. Als Beispiel sei hier die Erstellung eines secrets genannt, dass sowohl ein Serverzertifikat als auch den dazugehörigen Schlüssel beinhalten soll. Secrets enthalten base64 encodete Werte, weshalb eine manuelle Erstellung mehrere Schritte beinhalten würde.
Mit dem Befehl kubectl create secret tls certificate-pair --cert=certificate.pem --key=key.pem -o yaml --dry-run hingegen ist das gewünschte Secret in einem Befehl erstellt.
kubectl create secret tls certificate-pair --cert=certificate.pem --key=key.pem -o yaml --dry-run apiVersion: v1 data: tls.crt: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUQ2ekNDQXRPZ0F3SUJBZ0lVY3NtYWR5R29jRlEvZkVrRVRRM25kTjFxZVhrd0RRWUpLb1pJaHZjTkFRRUwKQlFBd2dZUXhDekFKQmdOVkJBWVRBa1JGTVF3d0NnWURWUVFJREFOT1VsY3hHVEFYQmdOVkJBY01FRTF2Wlc1agphR1Z1WjJ4aFpHSmhZMmd4RURBT0JnTlZCQW9NQjBWNFlXMXdiR1V4R1RBWEJnTlZCQU1NRUhSbGMzUXVaWGhoCmJYQnNaUzVqYjIweEh6QWRCZ2txaGtpRzl3MEJDUUVXRUhSbGMzUkFaWGhoYlhCc1pTNWpiMjB3SGhjTk1Ua3cKT1RJMk1UUXpNVEUyV2hjTk1qQXdPVEkxTVRRek1URTJXakNCaERFTE1Ba0dBMVVFQmhNQ1JFVXhEREFLQmdOVgpCQWdNQTA1U1Z6RVpNQmNHQTFVRUJ3d1FUVzlsYm1Ob1pXNW5iR0ZrWW1GamFERVFNQTRHQTFVRUNnd0hSWGhoCmJYQnNaVEVaTUJjR0ExVUVBd3dRZEdWemRDNWxlR0Z0Y0d4bExtTnZiVEVmTUIwR0NTcUdTSWIzRFFFSkFSWVEKZEdWemRFQmxlR0Z0Y0d4bExtTnZiVENDQVNJd0RRWUpLb1pJaHZjTkFRRUJCUUFEZ2dFUEFEQ0NBUW9DZ2dFQgpBTWtnSmtyd1U5UFhmRGhETW15cDlpblBFdmNiVkI5WUIvb3B6bHF3VzRybkkvbTJnbzFVeXFxZ3FLeDlEZWpWCnI0K3ZPcEtZcUcvTDJVZDlpS1o2bHdHUUZmWnNkaTJKVGRGdjVpSzVyejZPQVhwWTE1THYrTjN4TDRkMU5yN1gKT09DcVIwSmlFKzN0Q0tWN1l0Y1N4RUdsNWJlcStpOEJxK0w0bG1mQTZzS09vdjYwcWhpWi8wOUVUN3JoaXdCMApyYk80b2J4L0t5azZzbVhETW1SY2EvVVBXWk82L3hKSmhQeG9kY1dHOGJJcVE4SGtRM1NOaFpyWjdlekFMMmJoCjcxQSt2WFJOcXFJaHorOTdBRWZaSmozeGJZcm5vSVEwajZITkFZaHI1YzJSWmJ4WHVKL2J5QkUvL0U0Z1NPRmwKUU1EeitrS08rWlE1N25odkVXQWRFK01DQXdFQUFhTlRNRkV3SFFZRFZSME9CQllFRkZLK1JSNVBPVjVReENDOAp1UFM1a3lkMU9vcC9NQjhHQTFVZEl3UVlNQmFBRkZLK1JSNVBPVjVReENDOHVQUzVreWQxT29wL01BOEdBMVVkCkV3RUIvd1FGTUFNQkFmOHdEUVlKS29aSWh2Y05BUUVMQlFBRGdnRUJBSzdGbWFGYWRXei9hdkxxSmI1LzAxZ0UKNUxpNDVuSE5LbjZLa0lGZUdWT2RFS1F2ZWg5eWhyclRGaEJNUDk1aU43UEFVT2R6NVNMNC9tQ0V1QkRKd3dLKwpyc0N3OFJSS0hLaXYvcVdRU29BTDBkdU1LcXVIYU0rRTdINHFHOFVONDk2Q2YrQ3djU0paTjVSNGdROU1JTXp6CmFEL1dhek1qVHlJcFMwMFFaSTd5elBCYlFUMnRnbERLcjRRY0ROblFPNVNiVE5STDgraVR0QnBoZTRWWERjQ24KUTJpRkhweWVtZURvQ0l2YXBUU1k2VUxKM3JxNysrdmhRZmJIYmJtejJ4WHFCSUY5ZUV3RVFhM2NSd2hBeENlZQorMjJEVGoxaXdmeFpNWmRuSnR6UVM5QVRHeTQzSWh4dmJDQ2pxbTNCODBUblBTZGRrcFRDOVFKcEhPdkphTjg9Ci0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K tls.key: LS0tLS1CRUdJTiBQUklWQVRFIEtFWS0tLS0tCk1JSUV2d0lCQURBTkJna3Foa2lHOXcwQkFRRUZBQVNDQktrd2dnU2xBZ0VBQW9JQkFRREpJQ1pLOEZQVDEzdzQKUXpKc3FmWXB6eEwzRzFRZldBZjZLYzVhc0Z1SzV5UDV0b0tOVk1xcW9LaXNmUTNvMWErUHJ6cVNtS2h2eTlsSApmWWltZXBjQmtCWDJiSFl0aVUzUmIrWWl1YTgramdGNldOZVM3L2pkOFMrSGRUYSsxempncWtkQ1loUHQ3UWlsCmUyTFhFc1JCcGVXM3F2b3ZBYXZpK0pabndPckNqcUwrdEtvWW1mOVBSRSs2NFlzQWRLMnp1S0c4ZnlzcE9ySmwKd3pKa1hHdjFEMW1UdXY4U1NZVDhhSFhGaHZHeUtrUEI1RU4wallXYTJlM3N3QzltNGU5UVByMTBUYXFpSWMvdgpld0JIMlNZOThXMks1NkNFTkkraHpRR0lhK1hOa1dXOFY3aWYyOGdSUC94T0lFamhaVURBOC9wQ2p2bVVPZTU0CmJ4RmdIUlBqQWdNQkFBRUNnZ0VCQUxFV1JhRW1DaWswU29PZlp2NldoOUE0SzVLMzFWSGp5T0pUZlFZTTBnMXoKaHhHUHlWTjNuUnF2YXRTMUoxSWpFL21IYUNNN2x0TVl3YTlZc01Fa24yRVk1TDJjc2xGVjI5YlVsK1ZyYVFuRApMem55ajUwby9nOHRGWlJIZUhTQU8reFZBWGxKc2hLRDZtRUtTdlRqNlRtRVFNZC9HOW5YdHVpWnlKU0NJREk4CnBSSzJpQk9sRStPbHRScER3VnNDUDFtY0w2SjA2L0lWRjBnbjFyM3Q2S1o3NmIyMGlkSktPTjVpVmVLTDAxaUUKMWxmQmtKMXluUWgzR1dlSURDSXJyM2RoZ29qRVgvNjcxakJqRHVmcnBHUFpxNW02NXJLSTg4aENVNnVvMERPLwoyU0dqVG02VFNiRytPMUxPUmIzZXl0aFlMUXR2UVRuZHQ0Z3BIWTNoVklFQ2dZRUE2LzhMbEI0NTVwV1pkYTd6CmVKbTI1VWNxUXdjcUlmUzROZGlQWG5VTmxkWEdYVG5xdU1ST2JXd1JjbWtBUTh4aUxsaDJzYVNvQmNMN1ZYWWEKaTZyV081WXhSNjM3QktERjlOWTBxOHhoUDJlTVJ2ZUV2QkUzZkFFRjhvdCsrNUo0M05kbEI5M3lxOWIyUUs3TgpzRnhoVloyRDd3blM1bXRWekNWL3lHa2NNMGtDZ1lFQTJpeHZTeGxmUHpIZXM1THZpK1RseFhZTldsbFJiRVFvCko1amlEM2JDSG5oSENHQVJWU1V1NVVVTVd3b0pUQmxydldoNFczcWhzeDFoQkxmeDVQNVlOdVBBTDhhQlVQMUwKdUl2NlJtRUVFdXVPZ0MwMmhyRXIwNCtBYWIrbHM3SVpPUkZCMWd6M3FSdEUwQVo5UVF6YlJ4Q3ZUUnovS3lXaApjSHhRbk44RUljc0NnWUJPV0p5Q2JzcHdGNGdidnBvTGxwUldaNXJMSjh5Lyt4dFFuUFZ6dVU1cVNNOFMwaEJ2CmlKUTAxV1N4WTlSM3JabUdvMDI4U2RxU0Z4b1RWQ01aN1B3MFNmZFFRWjBNKzBiY3NtUklDSkRjV01jRUpGWUgKalh1ckNqZnNQbzFJZldic2dnR0RiQmFOSDg4ZXlDbDIvQ1JBSlF2UXhxVWlZODNXK1RnRDA0bE9LUUtCZ1FEVQpJMWlrQVN1bjJ1bmNXZ2NxVTR0SGtSNHl0NTZBVTFWb0N6UGtMV2xiRDBDaVdDY0NUNEZsMU5uS3U5dUdiMEZmCmpuRlpJY2lRelFSRS9rYnFqcFZmNmR3NW1CNnRqVjFQT0d4R2VwYm5mcnUwemtHeWZodExQc0Z5RWJNaEl3OTcKZWRnMk5hMnFkS1ZZVUxjQnhXcUJreXVoSTR6SmUzR2FXb1pYd2xIV09RS0JnUURXdjJmd2JTeVc0dkNEYm5rNgpxd1ZWaVVOV1drOHNYR1dDV3d5RXVxalRiYUlHMjVtbTNuWjRCRVJyUTB2Vmx2VWNsMmZwUVkweWxDdkRObTgxCk5jL243SUw0SnN3dU5XeThUWW1lZ0cxWThtcEUxTHo5UVVhWE1tRmpqZGc5TExwWElLM2xWSUVzYUtFRVNnM0sKN0hmUHpaV1h3dkZJUGlLTWRPaldmZ0xoS0E9PQotLS0tLUVORCBQUklWQVRFIEtFWS0tLS0tCg== kind: Secret metadata: creationTimestamp: null name: certificate-pair type: kubernetes.io/tls
Da nicht alle Objekttypen oder Parameter als Argumente an create übergeben werden können, muss teilweise der Weg über eine Manifestdatei gegangen werden.
apply
Neben create können neue Objekte auch mithilfe des apply-Befehls erstellt werden. Hierbei unterscheidet sich apply jedoch leicht im Handling.
apply spielt seine Stärken im Umgang mit YAML-Manifesten aus. Nehmen wir die in create dargestellte Deployment-Definition und nehmen an, dass diese als nginx-deployment.yaml vorliegt. Dann können wir diese mit Hilfe des folgenden Befehls im Cluster einspielen:
kubectl apply -f nginx-deployment.yaml deployment.apps/nginx created
Im Gegensatz zu create verhält sich apply bei erneuter Ausführung des Befehls unterschiedlich.
kubectl apply -f nginx-deployment.yaml deployment.apps/nginx unchanged
Denn durch apply wird keine Aktion sondern ein Zielzustand definiert, welche vom Cluster berücksichtigt wird. In unserem Beispiel also die Existenz eines Deployment-Objekts namens nginx unter Verwendung des Image nginx und einem Replika.
Wollen wir die Anzahl der Replikas nun Beispielsweise auf 2 anheben, so genügt es, die Datei entsprechend zu aktualisieren und erneut den apply-Befehl auszuführen.
kubectl apply -f nginx-deployment.yaml deployment.apps/nginx configured
Das definierte Ziel, unser Objekt, wird dabei immer anhand der apiVersion, Kind, name und namespace identifiziert.
Viele Eigenschafen eines Objekts können auf diese Weise geändert werden. Es gibt jedoch s.g. immutable Eigenschaften oder Felder, die nach der Erstellung des Objekts nicht mehr angepasst werden können. apply liefert dann eine entsprechende Fehlermeldung.
Weil keine Aktion, sondern ein Zielzustand definiert wird, eignet sich apply für mehrere Anwendungsfälle. Ferner ist es dazu geeignet, in Scripts oder Pipelines verwendet zu werden.
patch
Um Eigenschaften eines Objekts anzupassen, steht zusätzlich der Befehl patch zur Verfügung. Dieser enthält die Information, welches Objekt geändert werden soll und wie. Wollen wir z.B. die Anzahl der Replikas auf drei erhöhen, können wir dies mit dem folgenden patch-Befehl bewerkstelligen:
kubectl patch deployment nginx -p '{"spec": {"replicas": 3}}'
deployment.extensions/nginx patched
patch bietet sich vor allem dann an, wenn Objekte den eigenen Vorstellungen nach geändert werden sollen, aber automatisiert erstellt werden. Zum Beispiel node Objekte.
Spezifische Befehle
Neben den generischen Methoden wie apply oder patch stellt kubectl eine Reihe von spezifischen Befehlen bereit. Anhand dieser Befehle können beispielsweise Deployments oder StatefulSets skaliert werden, auf einen früheren Stand eines Deployments zurückgewechselt werden, oder aber der Status eines sogenannten rollouts überprüft werden.
Nachfolgend werden ein paar der gängigen Befehle und deren Verwendung grob skizziert:
label,annotate: Hinzufügen, ändern oder löschen von labels und annotations.
Beispiel:kubectl label deployment nginx comment=awebserverscale: Anpassen der Anzahl derreplica-Eigenschaft.rollout(history, pause, restart, undo): Steuerung vonrollouts. Z.B. Rollback auf eine frühere Version eines Deployments.expose: Erstellung ein Service zu einem gegebenen Objekt.
delete
Früher oder später kommt der Moment, in dem die angelegten Objekte auch wieder gelöscht werden sollen.
Hier kommt der Befehl delete zum Einsatz.
Wie auch bei create kann delete das Zielobjekt auf unterschiedliche Weise identifizieren. Entweder durch Angabe der Typs und des Namens oder aber indirekt über den Parameter -f und eine entsprechende Objektdefinition. Wollen wir unser Nginx Deployment löschen geschieht dies z.B. mit Hilfe des Befehls:
kubectl delete -f nginx-deployment.yaml deployment.apps "nginx" deleted
Alternativ hätten wir das Deployment auch via kubectl delete deployment nginx löschen können.
Exec
Auch wenn keine manuellen Änderungen an Dateien oder Prozessen innerhalb eines Containers vorgenommen weden sollen, kann es manchmal durchaus hilfreich sein, in einen Container hineinzusehen. Besonders bei der Entwicklung bietet der Blick in einen Container oftmals schnelleren Einblick in die Situation als andere Lösungen.
Nehmen wir an, wir wollen unseren Nginx-Web-Service debuggen und prüfen, ob dieser auf bestimmte Requests reagiert, so kann der exec Befehl helfen.
kubectl exec führt den angegebenen Befehl innerhalb des Containers aus. Auch eine interaktive Shell innerhalb des Containers kann mit exec gestartet werden, sofern vorhanden.
Wollen wir beispielsweise sicherstellen, dass der Inhalt einer Datei innerhalb des Containers mit unseren Erwartungen übereinstimmt, dann können wir uns diese Datei mittels cat anzeigen lassen:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-65f88748fd-lt2z5 1/1 Running 0 4m35s
nginx-65f88748fd-mmwl5 1/1 Running 0 4m35s
$ kubectl exec nginx-65f88748fd-lt2z5 cat /etc/nginx/nginx.conf
user nginx;
worker_processes 1;
...
http {
include /etc/nginx/mime.types;
...
include /etc/nginx/conf.d/*.conf;
}
Möchten wir eine interaktive Shell im Container starten, dann müssen wir neben dem Befehl selbst weitere Parameter angeben. Dabei handelt es sich um --stdin und --tty. Andernfalls wird die Shell zwar gestartet, sie beendet sich allerdings direkt wieder falls wir keine Argumente übergeben haben.
Dies ist bereits aus der Verwendung von docker exec bekannt. Das dort verwendete Kürzel -it kann auch bei kubectl exec verwendet werden. Ein vollständiges Beispiel sieht dann wie folgt aus:
kubectl exec -it nginx-65f88748fd-lt2z5 -- bash root@nginx-65f88748fd-lt2z5:/#
Der auszuführende Befehl muss natürlich innerhalb des Containers vorhanden sein. Da die benutzten Images meist auf minimale Größe ausgelegt sind, ist die Auswahl der Tools innerhalb des Containers oft stark begrenzt. Aus Security-Sicht ist dies eine gute Sache.
Sofern der Zielpod mehrere Container beherbergt, oder gar Init-Container verwendet, kann mittels -c der ensprechende Containername angegeben werden.
Port Weiterleitung
Manchmal müssen Services analysiert werden, die nicht direkt der Außenwelt präsentiert werden, oder aber vorgelagerte Proxies und Loadbalancer bei einer Fehleranalyse ausgeschlossen werden sollen.
Hierzu ist es notwenig, dass direkt auf den entsprechenden Service zugegriffen werden kann. Auch wenn dies normalerweise nicht der Fall ist.
Um direkten Zugriff zu ermöglichen stellt kubectl den Befehl port-forward bereit. Dieser dient dazu, einen lokalen Port auf den Port eines Objekts innerhalb des Cluster weiterzuleiten. Als Ziel können unter Anderem Services, Pods auch auch ganze Deployments dienen.
Dabei wird das Ziel in der Form <typ-short>/ angegebenen. Als weiterer Parameter muss eine Kombination aus lokalem Port und Remoteport angegeben werden.
Wollen wir nun direkt auf einen unserer Nginx Pods zugreifen sieht die entsprechende Syntax wie folgt aus:
$ kubectl port-forward pod/nginx-65f88748fd-lt2z5 8080:80 Forwarding from 127.0.0.1:8080 -> 80 Forwarding from [::1]:8080 -> 80
Dabei gibt 8080 den lokal zu öffnenden Port, 80 den den Zielport. Ein Aufruf von http://localhost:8080 zeigt ob der Port-Forward funktioniert hat und wie erwartet unser Nginx antwortet:
$ curl http://localhost:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
...
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
kubectl port-forward bestätigt dabei den Request mit dem Output Handling connection for 8080. Sollte es kubectl aus irgendeinem Grund nicht möglich sein den Request weiterzuleiten, so wird eine entsprechende Fehlermledung ausgegeben.
Alternativ kann der lokale Port auch weggelassen werden, dann versucht kubectl lokal den gleichen Port zu öffnen, auf den weitergeleitet werden soll. Je nach Port-Range benötigt man dazu allerdings lokale Root-Berechtigungen. Wer einen zufälligen, lokalen Port öffnen möchte kann dies anhand der Syntax :<target-port> bewerkstelligen.
Wollen wir die Weiterleitung auf eine dedizierte IP-Adresse binden, dann kann dies mit Hilfe des Parameters --address geschehen. Diese nimmt im Zweifelsfall auch mehrere IP-Adressen als Argument auf.
Weiteres
diff
Anhand des diff Befehls ist es möglich, die Abweichungen des IST mit dem SOLL Zustand anzuzeigen.
Hierzu nimmt der diff Befehl den Parameter -f auf. Das folgende Beispiel zeigt die diff Ausgabe nach Aktualisieren unseres Nginx Deployment YAML und vor dem apply:
k diff -f nginx-deployment.yaml
diff -u -N /tmp/LIVE-265469814/apps.v1.Deployment.test.nginx /tmp/MERGED-783806045/apps.v1.Deployment.test.nginx
--- /tmp/LIVE-265469814/apps.v1.Deployment.test.nginx 2019-09-30 13:17:41.525469492 +0200
+++ /tmp/MERGED-783806045/apps.v1.Deployment.test.nginx 2019-09-30 13:17:41.541469584 +0200
@@ -6,7 +6,7 @@
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"labels":{"app":"nginx","version":"v1"},"name":"nginx","namespace":"test"},"spec":{"replicas":2,"selector":{"matchLabels":{"app":"nginx"}},"strategy":{},"template":{"metadata":{"labels":{"app":"nginx"}},"spec":{"containers":[{"image":"nginx","name":"nginx","resources":{}}]}}},"status":{}}
creationTimestamp: "2019-09-26T16:04:43Z"
- generation: 1
+ generation: 2
labels:
app: nginx
comment: awebserver
@@ -18,7 +18,7 @@
uid: 5a712cb7-e077-11e9-82d3-96000014cd46
spec:
progressDeadlineSeconds: 600
- replicas: 2
+ replicas: 5
revisionHistoryLimit: 10
selector:
matchLabels:
exit status 1
Copy
Wer Daten in oder aus einem laufenden Container kopieren möchte, dem steht mit kubectl cp ein Befehl zur Hand, der genau diese Aufgabe erfüllt. Voraussetzung ist allerdings ein installiertes tar innerhalb des Containers.
Wollen wir Beispielsweise die nginx.conf aus unserem Nginx Container kopieren, dann würde der entsprechende Befehl wie folgt aussehen:
$ kubectl get pods NAME READY STATUS RESTARTS AGE nginx-65f88748fd-lt2z5 1/1 Running 0 3d20h nginx-65f88748fd-mmwl5 1/1 Running 0 3d20h $ kubectl cp nginx-65f88748fd-lt2z5:/etc/nginx/nginx.conf nginx-65f88748fd-lt2z5_nginx.conf tar: Removing leading `/' from member names
Falls innerhalb des Zielpods mehrere Container betrieben werden, so muss mithilfe des Parameter -c <container-name> der Zielcontainer angegeben werden.
wait
Manchmal könnte bestimmte Aktionen erst durchgeführt werden, nachdem andere erfolgreich abgeschlossen wurden. Oder man möchte einfach nur informiert werden sobald eine spezifische Aktion abgeschlossen wurde. Dies kann mit Hilfe des Befehls wait vollbracht werden.
wait nimmt ein Set an Argumenten auf, die sowohl das Zielobjekt als auch den Zielzustand beschreiben.
Wollen wir beispielsweise darauf warten, dass sich einer unserer Pods im Zustand Ready befindet, so sieht der Befehl wie folgt aus:
$ kubectl wait --for=condition=Ready pod/nginx-65f88748fd-lt2z5 pod/nginx-65f88748fd-lt2z5 condition met
Soll auf das endgültige Löschen eines Pods gewartet werden, so kann als Argument --for der Wert delete angegeben werden.
Dies ist insofern nützlich, als dass bei einem delete nicht der Löschvorgang selber durchgeführt wird, sondern das enstprechende Objekt nur als zu löschen makiert wird.
kubectl wait --for=delete pod/nginx-65f88748fd-49qv2 --timeout=120s pod/nginx-65f88748fd-49qv2 condition met
Unterstützung
Falls Sie Unterstützung beim Einsatz von Kubernetes benötigen, steht Ihnen unser Open Source Support Center zur Verfügung – Falls gewünscht auch 24 Stunden am Tag, an 365 Tagen im Jahr.
Wir freuen uns auf Ihre Kontaktaufnahme.
In diesem Beitrag beschäftigen wir uns mit dem hochverfügbaren Betrieb von PostgreSQL® in einer Kubernetes-Umgebung. Ein Thema, dass für viele unserer PostgreSQL® Anwender sicher von besonderem Interesse ist.
Gemeinsam mit unserem Partnerunternehmen MayaData, demonstrieren wir Ihnen nachfolgend die Einsatzmöglichkeiten und Vorteile des äußerst leistungsfähigen Open Source Projektes – OpenEBS
OpenEBS ist ein frei verfügbares Storage Management System, dessen Entwicklung von MayaData unterstützt und begleitet wird.
Wir bedanken uns ganz besonders bei Murat-Karslioglu von MayaData und unserem Kollegen Adrian Vondendriesch für diesen interessanten und hilfreichen Beitrag, den die Kollegen aufgrund der internationalen Zusammenarbeit diesmal natürlich in englischer Sprach verfasst haben.
PostgreSQL® anywhere — via Kubernetes with some help from OpenEBS and credativ engineering
by Murat Karslioglu, OpenEBS and Adrian Vondendriesch, credativ
Introduction
If you are already running Kubernetes on some form of cloud whether on-premises or as a service, you understand the ease-of-use, scalability and monitoring benefits of Kubernetes — and you may well be looking at how to apply those benefits to the operation of your databases.
PostgreSQL® remains a preferred relational database, and although setting up a highly available Postgres cluster from scratch might be challenging at first, we are seeing patterns emerging that allow PostgreSQL® to run as a first class citizen within Kubernetes, improving availability, reducing management time and overhead, and limiting cloud or data center lock-in.
There are many ways to run high availability with PostgreSQL®; for a list, see the PostgreSQL® Documentation. Some common cloud-native Postgres cluster deployment projects include Crunchy Data’s, Sorint.lab’s Stolon and Zalando’s Patroni/Spilo. Thus far we are seeing Zalando’s operator as a preferred solution in part because it seems to be simpler to understand and we’ve seen it operate well.
Some quick background on your authors:
- OpenEBS is a broadly deployed OpenSource storage and storage management project sponsored by MayaData.
- credativ is a leading open source support and engineering company with particular depth in PostgreSQL®.
In this blog, we’d like to briefly cover how using cloud-native or “container attached” storage can help in the deployment and ongoing operations of PostgreSQL® on Kubernetes. This is the first of a series of blogs we are considering — this one focuses more on why users are adopting this pattern and future ones will dive more into the specifics of how they are doing so.
At the end you can see how to use a Storage Class and a preferred operator to deploy PostgreSQL® with OpenEBS underlying
If you are curious about what container attached storage of CAS is you can read more from the Cloud Native Computing Foundation (CNCF) here.
Conceptually you can think of CAS as being the decomposition of previously monolithic storage software into containerized microservices that themselves run on Kubernetes. This gives all the advantages of running Kubernetes that already led you to run Kubernetes — now applied to the storage and data management layer as well. Of special note is that like Kubernetes, OpenEBS runs anywhere so the same advantages below apply whether on on-premises or on any of the many hosted Kubernetes services.
PostgreSQL® plus OpenEBS
®-with-OpenEBS-persistent-volumes.png“> Postgres-Operator (for cluster deployment)
Postgres-Operator (for cluster deployment)
Install OpenEBS
- If OpenEBS is not installed in your K8s cluster, this can be done from here. If OpenEBS is already installed, go to the next step.
- Connect to MayaOnline (Optional): Connecting the Kubernetes cluster to MayaOnline provides good visibility of storage resources. MayaOnline has various support options for enterprise customers.
Configure cStor Pool
- If cStor Pool is not configured in your OpenEBS cluster, this can be done from here. As PostgreSQL® is a StatefulSet application, it requires a single storage replication factor. If you prefer additional redundancy you can always increase the replica count to 3.
During cStor Pool creation, make sure that the maxPools parameter is set to >=3. If a cStor pool is already configured, go to the next step. Sample YAML named openebs-config.yaml for configuring cStor Pool is provided in the Configuration details below.
openebs-config.yaml
#Use the following YAMLs to create a cStor Storage Pool. # and associated storage class. apiVersion: openebs.io/v1alpha1 kind: StoragePoolClaim metadata: name: cstor-disk spec: name: cstor-disk type: disk poolSpec: poolType: striped # NOTE — Appropriate disks need to be fetched using `kubectl get disks` # # `Disk` is a custom resource supported by OpenEBS with `node-disk-manager` # as the disk operator # Replace the following with actual disk CRs from your cluster `kubectl get disks` # Uncomment the below lines after updating the actual disk names. disks: diskList: # Replace the following with actual disk CRs from your cluster from `kubectl get disks` # — disk-184d99015253054c48c4aa3f17d137b1 # — disk-2f6bced7ba9b2be230ca5138fd0b07f1 # — disk-806d3e77dd2e38f188fdaf9c46020bdc # — disk-8b6fb58d0c4e0ff3ed74a5183556424d # — disk-bad1863742ce905e67978d082a721d61 # — disk-d172a48ad8b0fb536b9984609b7ee653 — -
Create Storage Class
- You must configure a StorageClass to provision cStor volume on a cStor pool. In this solution, we are using a StorageClass to consume the cStor Pool which is created using external disks attached on the Nodes. The storage pool is created using the steps provided in the Configure StoragePool section. In this solution, PostgreSQL® is a deployment. Since it requires replication at the storage level the cStor volume replicaCount is 3. Sample YAML named openebs-sc-pg.yaml to consume cStor pool with cStorVolume Replica count as 3 is provided in the configuration details below.
openebs-sc-pg.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-postgres
annotations:
openebs.io/cas-type: cstor
cas.openebs.io/config: |
- name: StoragePoolClaim
value: "cstor-disk"
- name: ReplicaCount
value: "3"
provisioner: openebs.io/provisioner-iscsi
reclaimPolicy: Delete
---
Launch and test Postgres Operator
- Clone Zalando’s Postgres Operator.
git clone https://github.com/zalando/postgres-operator.git cd postgres-operator
Use the OpenEBS storage class
- Edit manifest file and add openebs-postgres as the storage class.
nano manifests/minimal-postgres-manifest.yaml
After adding the storage class, it should look like the example below:
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: acid-minimal-cluster
namespace: default
spec:
teamId: "ACID"
volume:
size: 1Gi
storageClass: openebs-postgres
numberOfInstances: 2
users:
# database owner
zalando:
- superuser
- createdb
# role for application foo
foo_user: []
#databases: name->owner
databases:
foo: zalando
postgresql:
version: "10"
parameters:
shared_buffers: "32MB"
max_connections: "10"
log_statement: "all"
Start the Operator
- Run the command below to start the operator
kubectl create -f manifests/configmap.yaml # configuration kubectl create -f manifests/operator-service-account-rbac.yaml # identity and permissions kubectl create -f manifests/postgres-operator.yaml # deployment
Create a Postgres cluster on OpenEBS
Optional: The operator can run in a namespace other than default. For example, to use the test namespace, run the following before deploying the operator’s manifests:
kubectl create namespace test kubectl config set-context $(kubectl config current-context) — namespace=test
- Run the command below to deploy from the example manifest:
kubectl create -f manifests/minimal-postgres-manifest.yaml
2. It only takes a few seconds to get the persistent volume (PV) for the pgdata-acid-minimal-cluster-0 up. Check PVs created by the operator using the kubectl get pv command:
$ kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-8852ceef-48fe-11e9–9897–06b524f7f6ea 1Gi RWO Delete Bound default/pgdata-acid-minimal-cluster-0 openebs-postgres 8m44s pvc-bfdf7ebe-48fe-11e9–9897–06b524f7f6ea 1Gi RWO Delete Bound default/pgdata-acid-minimal-cluster-1 openebs-postgres 7m14s
Connect to the Postgres master and test
- If it is not installed previously, install psql client:
sudo apt-get install postgresql-client
2. Run the command below and note the hostname and host port.
kubectl get service — namespace default |grep acid-minimal-cluster
3. Run the commands below to connect to your PostgreSQL® DB and test. Replace the [HostPort] below with the port number from the output of the above command:
export PGHOST=$(kubectl get svc -n default -l application=spilo,spilo-role=master -o jsonpath="{.items[0].spec.clusterIP}")
export PGPORT=[HostPort]
export PGPASSWORD=$(kubectl get secret -n default postgres.acid-minimal-cluster.credentials -o ‘jsonpath={.data.password}’ | base64 -d)
psql -U postgres -c ‘create table foo (id int)’
Congrats you now have the Postgres-Operator and your first test database up and running with the help of cloud-native OpenEBS storage.
Partnership and future direction
As this blog indicates, the teams at MayaData / OpenEBS and credativ are increasingly working together to help organizations running PostgreSQL® and other stateful workloads. In future blogs, we’ll provide more hands-on tips.
We are looking for feedback and suggestions on where to take this collaboration. Please provide feedback below or find us on Twitter or on the OpenEBS slack community.
Vom 14.11.2017 bis 17.11.2017 fand die ContainerConf 2017 im Rosengarten Mannheim statt. Es handelt sich hierbei um die zweite jährliche Veranstaltung die parallel zur fünften „Continous Lifecycle“ stattfand.
Beide Konferenzen drehen sich um alle erdenklichen Themen des Spektrums CI/CD, DevOps, Container und deren Tools, Methoden und das soziale System darum. Da beide Konferenzen parallel angeboten wurden, war nur die Anmeldung an einer der beiden Veranstaltungen nötig, um das volle Programm nutzen zu können. Als Veranstalter treten der dpunkt Verlag, Heise Developer und die IX auf.
Ingesamt fanden sich in diesem Jahr 640 Gäste ein. Die Konferenzen wurden in jeweils vier Tracks organisiert, die am 15.11. und 16.11. besucht werden konnten. In den Tagen vor und nach der Konferenz wurden verschieden Workshops u.A. zu den Themen Kubernetes, Monitoring mit Prometheus oder dem Erstellen von CD-Pipelines angeboten. Diese fanden entweder im Rosengarten oder dem angeschlossenen Dorint-Hotel statt.

Die Räumlichkeiten der Veranstaltung waren hochwertig ausgestattet und auch die gastronomische Versorgung der Teilnehmer war zu jedem Zeitpunkt mit kleinen Snacks, einem reichhaltigen Mittagsbuffet, sowie der ganztägigen Versorgung mit verschiedenen Getränken, sichergestellt. Am Abend des ersten eigentlichen Konferenztages wurde ein Social-Event mit verschiedenen Thementischen angeboten, an welcher man zu den angebotenen Themen diskutieren und verschiedene Menschen und Firmen kennenlernen konnte. Natürlich wurde auch hier die Verköstigung und Unterhaltung der Gäste mittels Livemusik sichergestellt.
Durch die vier parallelen Tracks hatte man häufig die Qual der Wahl, wie z.B. zwischen „Die Grenzen von Continuous Delivery“ (Eberhard Wolff, innoQ) und „DockAir – ein Rundflug durch das Kubernetes-Ökosystem“ (Nicolas Byl, codecentric).
Einige Vorträge werden nachträglich noch als Videoaufzeichnung veröffentlicht. Aktuell sind jedoch nur die Keynotes von 2017 verfügbar.
Gerade die Keynotes waren wie gewohnt mehr sozialer und organisatorischer als technischer Natur. So berichtete Jennifer Davis (Chef) von ihren ersten Erfahrungen in der Welt der Container, oder Patrick Kua (N26) vom Umdenken in den Bereichen Architektur und Umgang mit den Systemen. Brandon Philips (CoreOS) erläuterte in der letzten Keynote die Abstufungen verschiedener „Lock-ins“ und wie man diese (teilweise) umgehen kann.

Zwischen dem gebotenen Programm hatte man die Möglichkeit die zahlreichen Stände der Sponsoren zu besuchen und sich die Anbieter verschiedener Dienstleistungen genauer anzuschauen bzw. kennenzulernen. So waren hier z.B. Giant Swarm, CoreOS, Chef, Puppet und die Denic, sowie auch 1&1 vertreten. An vielen Stellen gab es Gewinnspiele, Merchandise oder einfach nur Informationen und Kontakte. Unser persönliches Highlight war eine „Trivial-Pursuit DevOps-Edition“ von automic.
Die ContainerConf 2017 war eine sowohl für Laien wie auch Experten lohnende Veranstaltung. Wir freuen uns schon auf nächstes Jahr!

