PostgreSQL® 13 Bits: Parallel VACUUM
| Kategorien: | PostgreSQL® |
|---|---|
| Tags: | Parallel VACUUM PostgreSQL® PostgreSQL® 13 PostgreSQL® Competence Center VACUUM |
Hintergrund
Mit PostgreSQL® 13 lernt das VACUUM–Kommando eine neue Fähigkeit: Das parallele Aufräumen von Indexen. VACUUM in einer PostgreSQL®-Datenbank ist im wesentlichen für mehrere wichtige Aufgaben verantwortlich:
- Garbage Collection, also freigeben von gelöschten Tupel für die Wiederverwendung
- Verhindern von Bloat in einer Datenbank und damit von ausuferndem Plattenplatzbedarfs
- Verhindern des Überlaufs des Transaktionszählers (FREEZE)
- Diverses Aufräumen von Transaktionsinformationen, usw.
Neben dem manuellen VACUUM Kommando gibt es noch den sogenannten Autovacuum Datenbankprozess, der sich automatisch im Hintergrund um diese Aufgaben kümmert. Im Groben entspricht die Arbeitsweise von Autovacuum auch dem Vorgehen bei Ausführung eines manuellem VACUUM-Kommandos. Diese gliedert sich im Wesentlichen in mehrere Phasen:
- Scannen der Tabellenblöcke und Ermitteln von darin enthaltenen, toten Tupeln und, falls notwendig, FREEZE
- Die toten Tupel werden im Speicher gesammelt (maintenance_work_mem ist hier die Obergrenze)
- Löschen der Tupelreferenzen aus entsprechenden Indexen (Vacuum Index Phase)
- Für jeden gescannten Tabellenblock, Löschen der darin enthaltenen toten Tupel
- Für jeden gescannten Tabellenblock, Reorganisieren der lebenden Tupel
- Aktualisieren der Visibility Map und Freespace Map
- Ist maintenance_work_mem voll, bevor das Ende einer Tabelle erreicht wurde, zurück zu 2.)
- Aufräumen (Cleanup Phase), u.a. Aktualisierung der Index-Statistiken für VACUUM
- Löschen von leeren Tabellenblöcken am Ende der Tabelle (falls vorhanden)
- Aktualisieren der Laufzeitstatistiken
- Aufräumen von Transaktionsinformationen
Arbeitsteilung
Mit der neuen Kommandooption PARALLEL kann das VACUUM Kommando nun die Vacuum Index und Cleanup Phase mit mehreren Arbeitsprozessen (Workern) parallel durchführen, z.B.:
VACUUM (ANALYZE, PARALLEL 4) my_table;
Dies führt ein VACUUM mit bis zu vier parallelen Workern mit zusätzlicher Aktualisierung der Optimizer Statistiken durch. Das bisherige Verfahren bleibt für die Tabelle selbst unverändert, mit PARALLEL verarbeitet VACUUM nun mit jeweils einem dedizierten Worker einen spezifischen Index. Zu beachten ist, dass der Leader, also die Session die das VACUUM-Kommando ausführt, ebenfalls entsprechende Arbeit verrichtet. Wird „0“ als Anzahl der Worker spezifiziert, wird die parallele Verarbeitung der Indexe deaktiviert und der bisherige Arbeitsablauf verwendet. Sind weniger als vier Indexe auf der Tabelle vorhanden, so wird die Anzahl der Worker entsprechend angepasst. Auch kann es passieren, dass aufgrund nebenläufiger DDL Kommandos (anderes paralleles VACUUM oder parallelisiertes CREATE INDEX) weniger Worker ausgewählt werden, da die Anzahl der maximal verfügbaren Worker Prozesse entweder durch max_parallel_maintenance_workers oder max_worker_processes begrenzt wird.
Parallel VACUUM als Standardoption
PARALLEL ist in der aktuellen Beta2 von PostgreSQL® 13 als Standardoption aktiviert. Wird die Option weggelassen, richtet sich die Zahl der Worker nach der Anzahl an Indexe pro Tabelle. Ob ein Index überhaupt für die parallele Verarbeitung vorgesehen wird, entscheidet auch der Konfigurationsparameter min_parallel_index_scan_size. Die Standardeinstellung ist 512kB.
Der Administrator sollte bei der Konfiguration von PostgreSQL® darauf achten, entsprechenden Spielraum bei der Parametrisierung von max_worker_processes einzuplanen, da mit dem seit PostgreSQL® 11 verfügbaren parallelisierten CREATE INDEX in PostgreSQL® 13 nun ein neues parallelisierbares DDL-Kommando hinzukommt.
Verbesserung bei der Geschwindigkeit
Das parallele Verarbeiten der Indexe sollte VACUUM gerade bei größeren Mengen an gelöschten Tupel bei entsprechender Anzahl an Indexen deutlich beschleunigen. Um diesen theoretischen Vorteil in der Praxis zu zeigen, verwenden wir an dieser Stelle ein Sample Dataset der IMDb Datenbank. Die Tabelle cast_info hat folgendes Schema:
Table "public.cast_info"
Column │ Type │ Collation │ Nullable │ Default
────────────────┼─────────┼───────────┼──────────┼───────────────────────────────────────
id │ integer │ │ not null │ nextval('cast_info_id_seq'::regclass)
person_id │ integer │ │ not null │
movie_id │ integer │ │ not null │
person_role_id │ integer │ │ │
note │ text │ │ │
nr_order │ integer │ │ │
role_id │ integer │ │ not null │
Indexes:
"cast_info_pkey" PRIMARY KEY, btree (id)
"cast_info_idx_cid" btree (person_role_id)
"cast_info_idx_mid" btree (movie_id)
"cast_info_idx_pid" btree (person_id)
"test_idx" btree (note)
Foreign-key constraints:
"movie_id_exists" FOREIGN KEY (movie_id) REFERENCES title(id)
"person_id_exists" FOREIGN KEY (person_id) REFERENCES name(id)
"person_role_id_exists" FOREIGN KEY (person_role_id) REFERENCES char_name(id)
"role_id_exists" FOREIGN KEY (role_id) REFERENCES role_type(id)
Die Tabelle ist ca. 2759 MByte groß und verfügt über insgesamt fünf Indexe, deren Größen sich wie folgt manifestieren:
SELECT indexrelid::regclass, pg_size_pretty(pg_relation_size(indexrelid))
FROM pg_index WHERE indrelid = 'cast_info'::regclass;
indexrelid │ pg_size_pretty
───────────────────┼────────────────
cast_info_pkey │ 1108 MB
cast_info_idx_cid │ 421 MB
cast_info_idx_mid │ 396 MB
cast_info_idx_pid │ 452 MB
test_idx │ 388 MB
(5 rows)
Damit Autovacuum den Test nicht stört, wird er für die Tabelle deaktiviert:
ALTER TABLE cast_info SET(autovacuum_enabled = 'false');
Folgender SQL aktualisiert in der Tabelle ca. 1.05 Mio Tupel in dem es rein fiktiv die Rollenzuordnung von bestimmten Datensätzen ändert. Die Ausgabe ist ein wenig gekürzt, um das Beispiel besser zu veranschaulichen:
UPDATE cast_info SET role_id = 12 WHERE role_id = 6; UPDATE 1055730
Anschließend wird der Parameter max_parallel_maintenance_workers auf 4 gesetzt, um maximal vier parallele Worker für VACUUM zu ermöglichen.
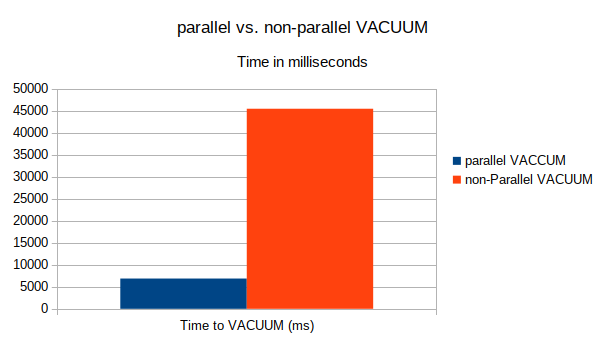
SET max_parallel_maintenance_workers TO 4; VACUUM cast_info ; Time: 6872,329 ms (00:06,872)
Wiederholt man den UPDATE mit umgekehrter Bedingung und anschließendem nicht-parallelisiertem VACUUM ergibt sich folgendes Bild:
UPDATE cast_info SET role_id = 6 WHERE role_id = 12; UPDATE 1055730 VACUUM (PARALLEL 0) cast_info ; Time: 45435,458 ms (00:45,435)
Die parallele Verarbeitung von Indexen in diesem Testfall zeigt einen mehr als deutlichen Vorteil zugunsten des parallelisierten VACUUM. Die folgende Grafik veranschaulicht die Laufzeiten noch einmal:
Fazit
Mit PostgreSQL® 13 lernt VACUUM Indexe parallel zu verarbeiten. Dies sorgt für einen deutlichen Geschwindigkeitsvorteil bei der Wartung von Tabellen. Ein Wermutstropfen aktuell ist, dass der automatische Hintergrundprozess Autovacuum noch nicht von diesem Feature profitieren kann, nur manuelles VACUUM unterstützt aktuell parallele Verarbeitung. Administratoren, die beispielsweise jedoch große Batchverarbeitungen mit Tabellen mit vielen Indexen direkt im Anschluß mit manuellem VACUUM optimieren, können von parallel VACUUM direkt profitieren.
Bei Fragen rund um den Einsatz von PostgreSQL® 13 parallel VACUUM stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an! Unser PostgreSQL® Competence Center ist bei Bedarf 24 Stunden am Tag, an 365 Tagen im Jahr für Sie verfügbar.
| Kategorien: | PostgreSQL® |
|---|---|
| Tags: | Parallel VACUUM PostgreSQL® PostgreSQL® 13 PostgreSQL® Competence Center VACUUM |
über den Autor
Bernd Helmle
Technischer Leiter Datenbanken
zur Person
Bernd Helmle arbeitet als Datenbankberater und -entwickler für die credativ GmbH, Deutschland. Er verfügt über umfassende Erfahrung in der PostgreSQL<sup>®</sup>-Administration, Hochverfügbarkeitslösungen und PostgreSQL<sup>®</sup>-Optimierung und Performance-Tuning. Außerdem war er an verschiedenen Migrationsprojekten von anderen Datenbanken zu PostgreSQL<sup>®</sup> beteiligt. Bernd Helmle entwickelte und betreut die Informix Foreign Data Wrapper Erweiterung für PostgreSQL<sup>®</sup>.