Drohnen fliegen lassen mit Cadence® - Wie viele Drohnen können wir fliegen lassen?
In diesem nächsten Teil der Blog-Reihe über die Cadence-Drohnen-Demonstrationsanwendung stellen wir ein neues und verbessertes Cadence+Kafka-Integrationsmuster vor. Wir haben die Grenzen der Skalierbarkeit von Cadence getestet, um herauszufinden, wie viele Drohnen wir gleichzeitig fliegen lassen können.
1. Neu und verbessert: ein Matching-Service für Drohnenaufträge

In New York kann es schwierig sein ein Taxi zu bekommen. – (Quelle: Shutterstock)
Wenn ich sehe, dass Produkte als „neu und verbessert“ angepriesen werden, frage ich mich oft, was vorher nicht mit ihnen in Ordnung war (Warum muss etwas verbessert werden, was nicht fehlerhaft war?). Angelehnt an diese Theorie hat sich herausgestellt, dass mein bisheriger Cadence-Anwendungscode für die Demo für Drohnenlieferungen „fehlerhaft“ war.
In einem vorherigen Blogbeitrag (Abschnitt 4: Drohne erhält nächste Bestellung zur Lieferung) haben wir eines der Cadence+Kafka-Integrationsmuster erläutert, das es Drohnen ermöglichen soll, eine Bestellung abzuholen, die zur Auslieferung bereit ist. Wir haben einen einfachen Warteschlangenansatz mit einem einzelnen Kafka-Consumer verwendet, der wie folgt eng mit jedem Drohnen-Workflow gekoppelt war. Der Drohnen-Workflow umfasst eine Aktivität waitForOrder(). Diese umschließt einen Kafka-Consumer, der tatsächlich im Cadence-Aktivitäts-Thread läuft. Er ist also vorübergehend und dauert nur so lange, wie die Aktivität ausgeführt wird. Der Workflow fragt das Topic „Bestellungen bereit“ ab, bis eine einzelne Bestellung zurückgegeben wird, wodurch die Aktivität abgeschlossen wird und die Drohne mit der Auslieferung beginnt.
Dieser Ansatz hat den Vorteil, dass er einfach ist. Er birgt jedoch ein potenzielles Problem. Da der Kafka-Consumer regelmäßig erstellt und beendet wird, entsteht ein ständiger Overhead bei der Consumer-Neuverteilung (in diesem Blog finden Sie weitere Informationen zu Rebalancing-Storms). Bei bis zu 100 Drohnen gleichzeitig war dies kein praktisches Problem, aber nachdem ich für diesen Blogbeitrag einige ernsthaftere Lasttests durchgeführt hatte, musste ich feststellen, dass es genau in diesem Teil des Workflows zu erheblichen Verzögerungen kam, wobei manchmal mehrere Dutzend Sekunden zwischen der Bereitschaft einer Drohne und der Erfassung einer Bestellung durch diese Drohne verstrichen. Es war also Zeit für einen neuen und verbesserten „Matching-Service“.

(Quelle: Shutterstock)
Um die Performance zu verbessern, habe ich einen „Vermittlungsdienst“ eingeführt, ähnlich dem, was man an belebten Taxiständen an Flughäfen sieht, wo ein Vermittler die Fahrgäste und Taxis koordiniert, indem er die Fahrgäste zu bestimmten Standplätzen leitet, wo sie auf das nächste verfügbare Taxi warten. Ich gehe davon aus, dass Ride-Share-Apps heutzutage ähnlich arbeiten.
So funktioniert der neue Matching-Service. Wie bisher werden (1) lieferbereite Bestellungen durch einen Bestellungs-Workflow zum Topic „Bestellungen bereit“ hinzugefügt. Wir fügen nun ein neues Kafka-Topic hinzu – das Topic „Drohne bereit“. Wenn eine Drohne für eine Bestellung bereit ist, sendet sie nun eine Nachricht an das Topic „Drohne bereit“ unter Verwendung eines Kafka-Producers (2) – diese Nachricht enthält die Drohnen-ID – und wartet auf ein Signal. Es gibt auch (3) einen neuen permanenten Kafka-Consumer („Auftrag an Drohne zuweisen“), der aus den Topics „Bestellungen bereit“ und „Drohne bereit“ liest. Dieser Consumer läuft unabhängig und kontinuierlich außerhalb der Cadence-Workflows und verhindert so die bisherigen Neuverteilungsprobleme. Wenn der Consumer eine Nachricht von beiden Topics erhält, sendet er ein Signal mit der Bestell-ID an den richtigen Drohnen-Workflow (4), der der Drohne mitteilt, welche Bestellung sie nun ausliefern soll, und den Auslieferungsteil des Workflows in Gang setzt. Siehe das folgende aktualisierte Diagramm.
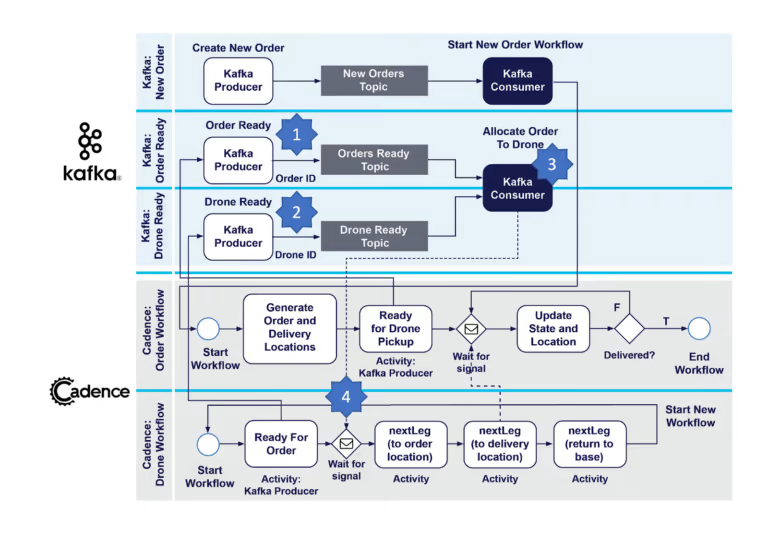
Der Cadence-Drohnen-Demonstrationscode wurde aktualisiert, und es gibt eine neue Klasse für den neuen Kafka-Consumer MatchOrderToDrone.java.
2. Experimente zur Cadence-Skalierbarkeit
2.1 Cluster-Details
Cadence ist für die skalierbare Ausführung von Workflows mit hohem Durchsatz konzipiert. Jetzt wollen wir sehen, wie viele Drohnen wir tatsächlich fliegen lassen können. Natürlich hängt die Skalierbarkeit von der verfügbaren Hardware und anderen Infrastrukturen ab. Für diese Experimente habe ich einen betriebsbereiten, von Instaclustr verwalteten Cadence-Service (auf AWS) mit den folgenden Ressourcen bereitgestellt:
Cadence-Cluster: 3 Knoten von CAD-PRD-m5ad.large-75-Instanzen (2 VCPUs) = 6 VCPUs
Cassandra-Cluster: 9 Knoten von m5l-250-v2-Instanzen (2 VCPUs) = 18 VCPUs
Gesamt Anzahl Cluster-Kerne = 24
Ich habe auch eine EC2-Instanz gestartet, um den Code für den Cadence-Client und -Worker auszuführen (8 VCPUs). Also, insgesamt 24+8 = 32 VCPUs. Das Verhältnis der Ressourcen im gesamten End-to-End-System (Client:Cadence:Cassandra) war also 1:1:3.
Zunächst habe ich Cassandra-Cluster mit 3 und 6 Knoten ausprobiert, die aber offensichtlich einen Engpass darstellten, sodass unsere Cadence-Ops-Gurus vorschlugen, die Anzahl der Knoten auf 9 zu erhöhen (also die dreifache Anzahl der Cadence-Knoten). Das entspricht dem empfohlenen Verhältnis von Cadence- zu Cassandra-Ressourcen von 1:3.
Der Cadence-Client wurde über einen Load Balancer mit dem verwalteten Cadence-Cluster verbunden, um eine ausgewogene Auslastung der Cadence-Cluster-Knoten zu gewährleisten (auf AWS wird automatisch einer von diesen bereitgestellt).
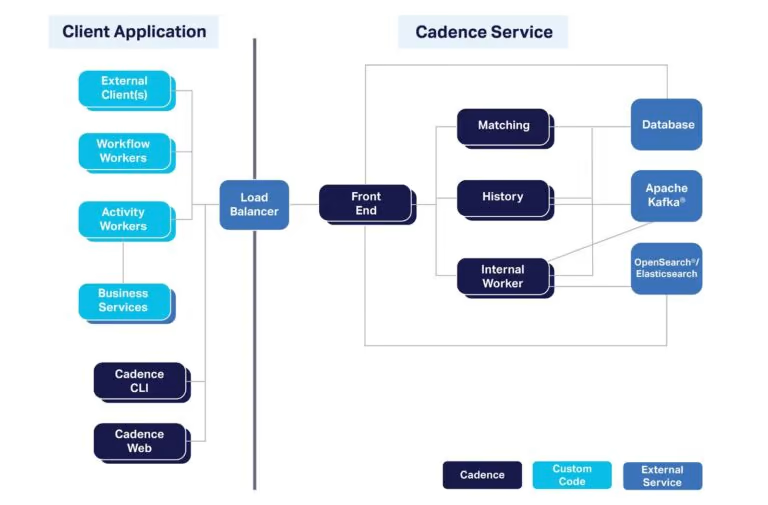
Hier finden Sie einen Überblick über die verschiedenen Komponenten, aus denen ein komplettes Cadence-System besteht. Apache Kafka und OpenSearch sind optional, bieten aber eine „erweiterte Einsicht“ in laufende Cadence-Workflows.
2.2. Experiment 1: Mit Vollgas
Meine Cadence-Demoanwendung für Drohnenlieferungen war nicht speziell für eine Benchmark konzipiert. Daher habe ich einige Tricks angewendet, um Benchmark-Ergebnisse zu erhalten. Für meinen ersten Versuch beschloss ich, die Fluggeschwindigkeit der Drohnen auf 100 km/h anzupassen und die Drohnen mit Vollgas laufen zu lassen (d. h., schneller als in Echtzeit, ohne Wartezeiten zwischen den Ereignissen). So konnte ich in kurzer Zeit eine große Anzahl von Benchmark-Tests durchführen und die Anzahl der gleichzeitigen Drohnen-Workflows auf die maximale Clusterkapazität erhöhen. Ich habe einen „Benchmarking“-Modus zum Code hinzugefügt, der bei jeder Lieferung für identische Lieferentfernungen sorgt (die maximal zulässige Entfernung), da die Abweichungen für ein wiederholbares Benchmarking sonst möglicherweise zu groß gewesen wären. Außerdem war die Anzahl der Bestellungen zehnmal so hoch wie die Anzahl der Drohnen. Um den Durchsatz des Drohnen-Workflows zu messen, messe ich einfach die Zeit jedes Laufs (aus den Protokollen) und teile die Gesamtzahl der Bestellungen durch die Gesamtzeit, um die abgeschlossenen Bestellungen pro Sekunde zu erhalten. Das folgende Diagramm zeigt die Anzahl der gleichzeitigen Drohnen im Vergleich zu den Bestellungen pro Sekunde. Es zeigt deutlich, dass der Durchsatz ansteigt, bei 50 gleichzeitigen Drohnen-Workflows einen Spitzenwert erreicht und dann wieder abfällt. Für das Ergebnis bei 50 Drohnen lag die CPU-Auslastung des Cadence-Clusters zwischen 53–93 % (d. h., einige Knoten waren stärker ausgelastet als andere).
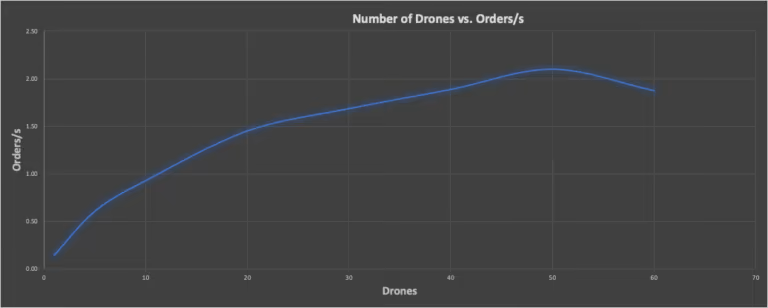
Gleichzeitige Drohnen im Vergleich zu Bestellungen/s, mit einem Höchstwert von 50 Drohnen
2.3. Experiment 2: Echtzeit
Für mein zweites Experiment wollte ich herausfinden, wie viele Drohnen ich in „Echtzeit“ fliegen lassen kann, d. h., wenn sie die tatsächliche Flugzeit benötigen: maximal 30 Minuten pro Lieferung (bei 10 s Wartezeit zwischen den einzelnen Bewegungen, 60 s für Abhol- und Absetzvorgänge und zusätzlicher Zeit zum Aufladen). Für das Benchmarking dieses Experiments habe ich einen modifizierten Code verwendet, der die Anzahl der Drohnen langsam ansteigen lässt. Warum? Es gibt einen erheblichen Overhead bei der Erstellung von Cadence-Workflows. Deshalb musste ich nach der Erstellung des Workflows genügend Zeit lassen, bevor ich den Drohnen Lieferaufträge erteilte, um sicherzustellen, dass genügend Cadence-Cluster-Ressourcen für die normale Workflow-Ausführung verfügbar waren. Und das Endergebnis war …
3. 2.000 Drohnen!
Was ist schlimmer als eine Lieferdrohne, die gelegentlich über unsere Köpfe summt? Stellen Sie sich 2.000 Lieferdrohnen vor, die Sie ständig umschwirren! (NASA/New Scientist haben nachgewiesen, dass das Summen von Drohnen lästiger ist als Geräusche anderer Fahrzeuge.) Ja, wir haben es geschafft, 2.000 Lieferdrohnen gleichzeitig einzusetzen! Dazu waren eine CPU-Auslastung der Cadence-Knoten von 50–88 %, eine Cassandra-Cluster-Auslastung von 80 % sowie 6 von 8 EC2-Instanzkernen für den Client/Worker-Code nötig. Da es für jeden Drohnen-Workflow einen Bestell-Workflow gibt, lag die Gesamtzahl der gleichzeitig ausgeführten Cadence-Workflows sogar bei 4.000 – also doppelt so hoch.
Cadence ist jedoch auch in der Lage, mehr Workflows als diese auszuführen, sogar auf denselben Ressourcen. Wie? Nun, Cadence ist für lang laufende Workflows konzipiert. Meine Workflows hatten Wartezeiten zwischen 10 und 60 Sekunden (plus Zeit zum Aufladen), die Drohnen waren also nicht die ganze Zeit über beschäftigt (im Gegensatz zum ersten „Vollgas“-Experiment). In einem Durchlauf habe ich versehentlich mehr Drohnen erstellt als ich brauchte, nämlich 23.151 Stück. Nach ihrer Erstellung verbrauchten sie überhaupt keine Cadence-Ressourcen, da sie nur auf Bestellungen warteten, also untätig waren. Je nachdem, wie ausgelastet Ihre Cadence-Workflows sind, können Sie also potenziell Millionen von Daten auf einem Cluster dieser Größe ausführen.
Wie würden 2.000 Drohnen aussehen? Erinnern Sie sich an die riesige rotierende Erde bei den Olympischen Spielen 2020 in Tokio? Offenbar wurden bei der Eröffnungsfeier fast 2.000 Drohnen (1.824) dafür eingesetzt! Wir könnten diese Drohnen-Präsentation mit unserem Cadence-Cluster betreiben (und mit einem Workflow-Orchestrator eine Drohnen-Choreografie schaffen). Und wenn Sie noch mehr Drohnen einsetzen möchten, können Sie natürlich einen größeren Cadence-/Cassandra-Cluster bereitstellen (oder Knoten zu bestehenden Clustern hinzufügen).

https://commons.wikimedia.org/wiki/File:Drones_durante_a_abertura_das_Olimp%C3%ADadas_de_T%C3%B3quio.jpg Rede do Esporte, CC BY 3.0 BR <https://creativecommons.org/licenses/by/3.0/br/deed.en>, via Wikimedia Commons
{kind=link}
4. Animation – zehn fliegende Drohnen
Möchten Sie unsere Drohnen fliegen sehen? Hier ist eine Animation, die eine Webseite (dronepaths.html) mit Javascript und Mapbox für die Karte verwendet. Dabei werden Daten aus einem tatsächlichen Lauf der Drohnendemonstration verwendet. Es werden nur 10 Drohnen (schwarze Markierungen) angezeigt (leider nicht 2.000), die von der Drohnenbasis (lila Markierung, in der Nähe meines Hinterhofs) ausfliegen. Die Drohnen fliegen zu den verschiedenen Auftragsorten, um die Bestellungen abzuholen (orangefarbene Markierungen), sie an den rot markierten Lieferorten abzuliefern (die nach der Lieferung grün werden) und dann zur Basis zurückzukehren und das Ganze zu wiederholen (jede Drohne hat im Durchschnitt 2 Bestellungen). Theoretisch könnte der Javascript-/Mapbox-Code so erweitert werden, dass er einen Kafka-Consumer verwendet (hier eine mögliche Lösung), um die tatsächlichen Echtzeitdaten zum Drohnenstandort zu nutzen.
Anmerkung 1: In der vorherigen Version des Drohnen-Codes habe ich einen Kafka-Consumer verwendet, der im Cadence-Drohnen-Workflow, waitForOrder()-Aktivität , läuft. Kafka-Consumer verwenden einen abfragebasierten Ansatz, um Datensätze aus Kafka-Topics zu lesen und so Skalierbarkeit zu ermöglichen. Dieser Ansatz war also eigentlich ein Beispiel für einen Abfrage-Anwendungsfall für Cadence. Wie oben erklärt, habe ich dies aus der neuesten Version des Codes entfernt. Sie können jedoch ein anderes Beispiel für einen Abfrage-Anwendungsfall in unserem Cadence Polling Cookbook finden. Die neueste Version des Drohnen-Codes ist jedoch ein gutes Beispiel für einen Cadence-Anwendungsfall für eine ereignisgesteuerte Anwendung.
Anmerkung 2: Damit bleiben uns 2 Kafka-Consumer in der aktuellen Version. Interessant ist, dass theoretisch beide Consumer im Kafka Connect-Framework als Kafka Connect Cadence sink connector implementiert und ausgeführt werden könnten, um Zuverlässigkeit und Skalierbarkeit zu gewährleisten. Der Consumer „Neuen Bestellungs-Workflow starten“ könnte in einen allgemeinen sink connector „Neuen Workflow starten“ zum Starten neuer Workflows umgewandelt werden, und der Consumer „Auftrag an Drohne zuweisen“ könnte zu einem spezielleren sink connector gemacht werden, um Signale an Workflows mit einer bestimmten Nutzlast zu senden.
Wir unterstützen Sie gerne
Ob Cadence, Debian oder PostgreSQL: mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich, können credativ und Instaclustr Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Sie möchten mehr über Cadence lernen und über die Vorteile die es Ihrer Organisation bietet. Dann laden Sie sich unser englischsprachiges Whitepaper runter.
Sollten Sie Fragen zu unserem Artikel haben oder würden sich wünschen, dass unsere Spezialisten sich Ihr System angucken und Ihre Infrastruktur optimieren, dann schauen Sie doch vorbei und melden sich über unser Kontaktformular oder schreiben uns eine E-mail an info@credativ.de.
Über unsere Mutterfirma Instaclustr bieten wir auch eine komplett verwaltete Plattform für Cadence an.
Original englischsprachige Artikel auf Instaclustr.com
- Part 1: Spinning Your Workflows With Cadence!
- Part 2: Spinning Apache Kafka® Microservices With Cadence Workflows
- Part 3: Spinning your drones with Cadence
- Part 4: Architecture, Order and Delivery Workflows
- Part 5: Integration Patterns and New Cadence Features
- Part 6: How Many Drones Can We Fly?
Folgen Sie der Reihe auf credativ.de: Drohnen fliegen lassen mit Cadence
- Teil 1: Workflows mit Cadence optimieren
- Teil 2: Apache Kafka® Microservices mit Cadence-Workflows optimieren
- Teil 3: Drohnen fliegen lassen mit Cadence
- Teil 4: Architektur, Bestellungs- und Lieferungs-Workflows
- Teil 5: Integrationsmuster und neue Cadence-Funktionen
- Teil 6: Wie viele Drohnen können wir fliegen lassen?
| Kategorien: | HowTos |
|---|---|
| Tags: | cadence Kafka |

über den Autor
Paul Brebner
zur Person
Paul is the Technology Evangelist at Instaclustr/Spot by NetApp. For the past five years, he has been learning new scalable Big Data technologies, solving realistic problems, building applications, and blogging and talking about Apache Cassandra, Apache Spark, Apache Kafka, Redis, Elasticsearch, PostgreSQL, Cadence, and many more open source technologies. Since learning to program on a VAX 11/780, Paul has extensive R&D, teaching, and consulting experience in distributed systems, technology innovation, software architecture and engineering, software performance and scalability, grid and cloud computing, and data analytics and machine learning. Paul has also worked at Waikato University (NZ), UNSW, CSIRO, UCL (UK), NICTA/ANU, and several tech start-ups. Paul has an MSc in Machine Learning and a BSc (Computer Science and Philosophy).