Einführung:
Nach längerer Zeit veröffentlichen wir endlich wieder eine Blogserie zu unserer Monitoring-Plattform bei Instaclustr. Beim letzten Mal stellten wir eine technische Lösung zur Unterstützung einer Plattform vor, auf der mehr als 500 Nodes laufen. Mittlerweile sprechen wir von etwa 7.000 verwalteten Instanzen.
Für diesen Anwendungsfall haben wir diverse Änderungen an der Architektur unserer internen Infrastruktur vorgenommen. Dabei mussten wir zunehmend auf die Nutzung unserer eigenen internen Dienste zurückgreifen – sie also selbst ausprobieren. Im ersten Blog dieser speziellen Serie wird beschrieben, wie wir im Entwicklungsteam von Instaclustr unsere eigene Instaclustr Managed Service Platform verwenden, um in Sachen Big Data optimale Resultate zu erzielen.
Bestehende Infrastruktur
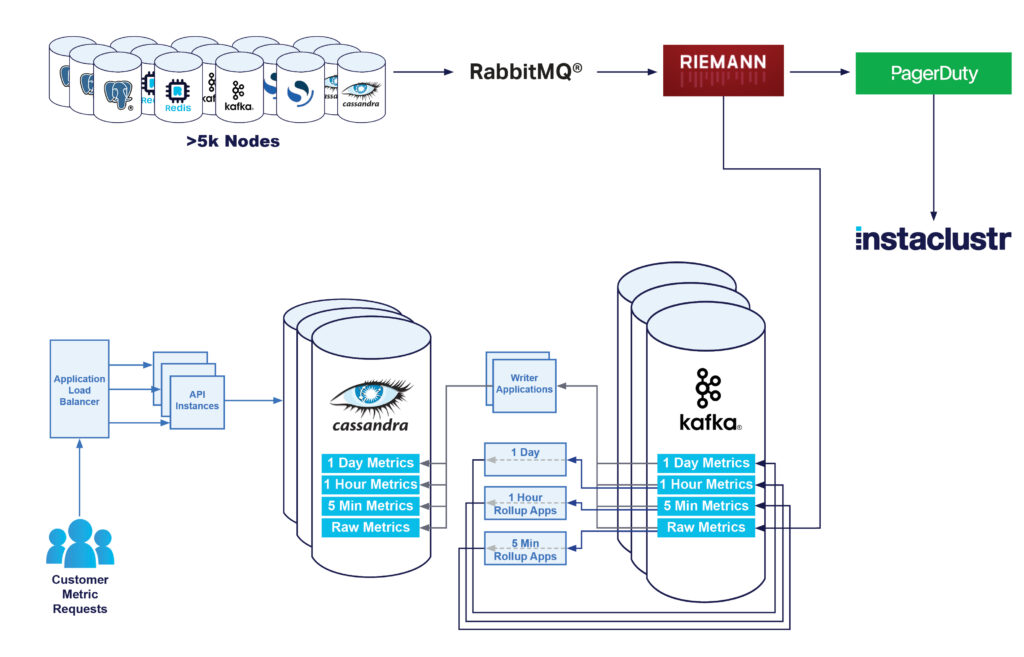
Ursprünglich baute unsere Monitoring-Infrastruktur auf der folgenden Architektur auf:
- Die Knoten sendeten alle Metriken zu einem RabbitMQ® Exchange.
- Unter Verwendung von Riemann-Anwendungen wurden die Messgrößen analysiert und bei Problemen unser technischer Support informiert.
- Diese Rohmetriken wurden auch in unseren Instametrics Cassandra-Cluster geschrieben.
- Anschließend wurden diese Rohdaten zu 5-minütigen, stündlichen und täglichen Mindest-, Durchschnitts- und Höchstwerten „aufbereitet“.
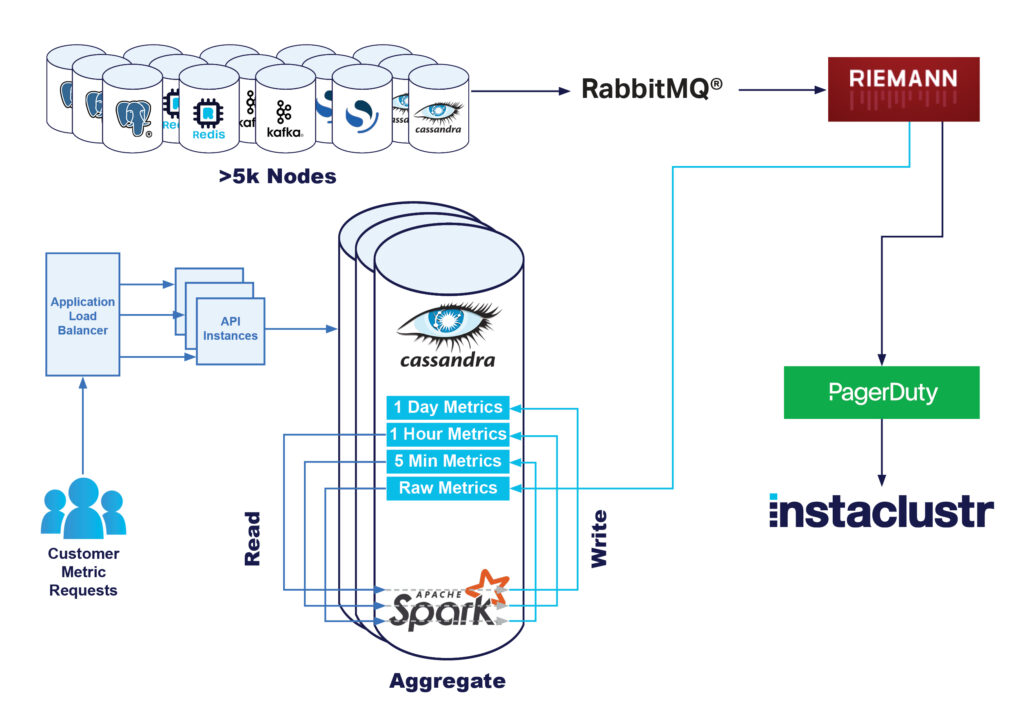
Bei kundenseitiger Datenanforderung entweder über Konsole oder API werden diese Daten von unserem Apache Cassandra®-Cluster abgerufen und an den Kunden zurückgesendet. Diese Lösung funktioniert mit minimalem technischem Aufwand insgesamt sehr gut und ist gut skalierbar.
Die zunehmende Anzahl von Instanzen bedeutete, dass wir die Größe unseres Cassandra-Clusters deutlich erhöhen mussten – zwischenzeitlich hatten wir einen i3.2xlarge Cassandra-Cluster mit 90 Knoten und 15 Riemann-Instanzen, um etwa 7.000 Instanzen zu unterstützen, die etwa eine Million metrische Schreibvorgänge pro Sekunde abwickelten.
Uns waren jedoch einige Schwachstellen dieser aktuellen Lösung bekannt. In den vergangenen drei Jahren haben wir eine Verbesserung unserer Metrikpipeline in Angriff genommen, mit dem Ziel, durch eine bessere Darstellung der Metriken höhere Kundenzufriedenheit zu erzielen und unsere Kosten für die Infrastruktur zu senken.
Das erste Problem war die hohe Belastung unseres Cassandra-Clusters durch unsere Apache Spark™-Rollup-Aufträge. Bei der Verarbeitung einer großen Anzahl von Schreibvorgängen ist Cassandra äußerst leistungsstark, sodass eine Million Schreibvorgänge pro Sekunde keine große Belastung für den Cluster darstellten. Eine unnötige Belastung stellten jedoch die Spark-Aggregationsaufträge dar. Bei diesen Aufträgen werden alle 5 Minuten alle Rohdaten, die in den Cluster geschrieben werden, gelesen und es wird eine einfache Aggregation durchgeführt. Anschließend werden stündlich alle 5-Minuten-Aggregate ausgelesen und so aggregiert, dass die Stundenwerte unverändert bleiben. Zum Schluss werden jeden Tag alle stündlichen Aggregate gelesen und ein tägliches Aggregat erstellt.
Verwirrt? Kurz gesagt, wir lesen jede Rohgröße praktisch dreimal. Auf einem schreiborientierten System wie Cassandra führte dies zu einem erheblichen Leistungsengpass. Das bedeutet auch, dass Kunden, die unser Dashboard oder unsere Metrik-API zu Zeiten nutzten, in denen wir diese Aggregationsvorgänge durchführten, eine längere Latenzzeit bei ihren Anfragen feststellten und ihnen manchmal sogar der Fehlerstatus 429 angezeigt wurde. Grund dafür waren Anfrage-Timeouts, da Cassandra mit Leseanfragen überlastet war.
Kurzfristig war die Erweiterung der Cluster-Kapazitäten die einfachste Lösung. Tatsächlich konnten wir mit steigender Anzahl der verwalteten Knoten und der geschriebenen Rohmetriken eine lineare Leistungssteigerung feststellen. Aber wir wussten, dass wir auf lange Sicht vermutlich einige größere strukturelle Änderungen vornehmen müssen.
Neben der mangelnden Leseleistung wollten wir auch einige andere Aspekte der Plattform langfristig verbessern. Uns war es wichtig, dass unsere Monitoring-Plattform flexibel und erweiterbar ist, d. h. dass wir zusätzliche Tools hinzufügen, Metriken im Bedarfsfall neu verarbeiten, Blue-/Green-Tests mit Live-Daten durchführen und einen Puffer an Metriken bei einem möglichen Anwendungsausfall haben.
Apache Kafka „Dogfooding“
Kafka bietet genau die Möglichkeiten, nach denen wir gesucht haben. Wir nutzen Kafka als Nachrichtenwarteschlange zwischen unseren Riemann-Servern und unserem Cassandra-Cluster. Unser Kafka-Cluster speichert nun alle Rohmetriken von allen Knoten in der Flotte. Auf diese Weise lassen sich alle Funktionen einer verteilten und fehlertoleranten Nachrichtenplattform nutzen, und es besteht die Möglichkeit, mehrere Consumers denselben Metriken zuzuordnen. Einer dieser Consumers ist eine Kafka-Anwendung, die als Ersatz für die Spark-Aufgaben die Rollups für die Metriken durchführt und die Leselast des Cassandra-Clusters reduziert.
Für die Konfiguration des Clusters und die Bereitstellung unserer Verwaltungsinfrastruktur verwenden wir intern Terraform. Mit der Nutzung des Terraform Provider von Instaclustr lässt sich der Cluster bereitstellen und ihn korrekt für die Nutzung durch unsere Anwendungen konfigurieren. Alle Tools und das gesamte Know-how unseres Entwicklungsteams stehen auch allen unseren Managed Service Kafka-Kunden zur Verfügung.
Im ersten Entwicklungsschritt wurden Daten durch unsere Riemann-Anwendungen in den Cassandra-Cluster und einen Kafka-Cluster geschrieben. So konnten wir etwaige Probleme im Kafka-Schreibsystem evaluieren und gleichzeitig die Folgen für die Kunden minimieren. Da die Konfiguration für jede Anwendung einzeln möglich ist, ließen sich auch einige unserer Riemann-Anwendungen so konfigurieren, dass sie Metriken an Kafka senden. So konnten wir die Arbeitslast unseres Kafka-Clusters langsam erhöhen und prüfen, ob er die Leistungsanforderungen erfüllen kann.
Das Schreiben von Rohmetriken war relativ einfach. Es musste nur die Konfiguration des Producers geringfügig angepasst werden, wobei vor allem die Batching-Einstellungen wie Verweildauer und Batch-Größe erhöht werden mussten. Nach erfolgreicher Änderung konnten wir feststellen, dass unsere einzelne Riemann-Anwendung die Produktionslast problemlos bewältigte, ohne dass sich die Latenzzeit erhöhte.
Da wir jetzt in der Lage waren, Rohdaten an unseren Kafka-Cluster zu senden, überlegten wir, welche Größe der Cluster zur Bewältigung der Produktionslast haben sollte. Als immer mehr Datenverkehr auf den Cluster geleitet wurde, wandten wir uns an unser Kafka-Supportteam, das zentrale Leistungskennzahlen wie CPU-Auslastung, I/O Wait und Festplattennutzung auswertete. Mit ihrer Hilfe konnten wir unsere Aufbewahrungsdauer verkürzen, die Komprimierung aktivieren und die Replikationsstrategie je nach Wichtigkeit unserer Daten ändern.
Bei der Knotengröße haben wir uns für i3en.xl entschieden, da diese eine hohe Speicherleistung bieten und wir von den Preisen für reservierte Instanzen profitieren können. Wir haben 12 Kafka-Knoten und 3 dedizierte Apache ZooKeeper™ -Instanzen für unsere Produktionsumgebung. Kundenseitig initiierte Funktionen zur Größenanpassung und unser engagiertes Supportteam ermöglichten ein einfaches Arbeiten mit verschiedenen Knotengrößen.
Als sichergestellt war, dass der Kafka-Cluster und die Producer entsprechend konfiguriert waren und unsere Benachrichtigungs-Pipeline nicht beeinträchtigten, aktivierten wir die Schreibfunktion auf unseren gesamten Riemann-Servern.
In einem späteren Blog können Sie lesen, dass durch die Verwendung von Kafka und seiner Topologie mit mehreren Consumer-Gruppen unser RedisTM-Team nun in der Lage war, mit dem Caching von Metriken für unsere Monitoring-API zu beginnen.
Hinzufügung eines Cassandra Writer
Als nächstes wurde eine kleine Anwendung entwickelt, die Rohdaten aus dem Kafka-Topic ausliest und diese direkt in Cassandra schreibt.
Die Auslagerung dieser Aufgabe in eine eigene Anwendung ist zwar etwas komplexer, bringt aber auch Vorteile mit sich, da das Schreiben der Daten nun asynchron zur Verarbeitung der Daten erfolgt. So können eventuelle Ausfälle separat in unser zeitkritischeres Warnsystem übertragen werden. Bei Bedarf lässt sich die Schreiblast drosseln, damit unsere Systeme nicht überlastet werden. Außerdem können wir durch den Einsatz von Kafka-Consumer-Gruppen die Skalierbarkeit und Hochverfügbarkeit unserer Schreibanwendungen gewährleisten.
Zunächst hofften wir, einen handelsüblichen Kafka-Connect-Connector zum Schreiben in Cassandra verwenden zu können, aber wir konnten nichts finden, das die Stapelverarbeitung oder Schreiboptimierungen genauso unterstützt wie unser vorhandener Writer. Einer unserer Gründer hielt 2016 einen Vortrag auf dem Cassandra Summit über genau diese Optimierungen. Wir haben stattdessen eine sehr einfache Java-basierte Anwendung entwickelt, die von Kafka liest und in Cassandra schreibt und dabei unsere vorhandenen modellspezifischen Datenbankoptimierungen nutzt.
Erst als wir mit der Leistung unserer Writer-Anwendung zufrieden waren, deaktivierten wir das direkte Schreiben von Riemann in Cassandra und verließen uns auf unseren Kafka-basierten Cassandra-Writer.
Zu diesem Zeitpunkt sah unsere Architektur so aus:
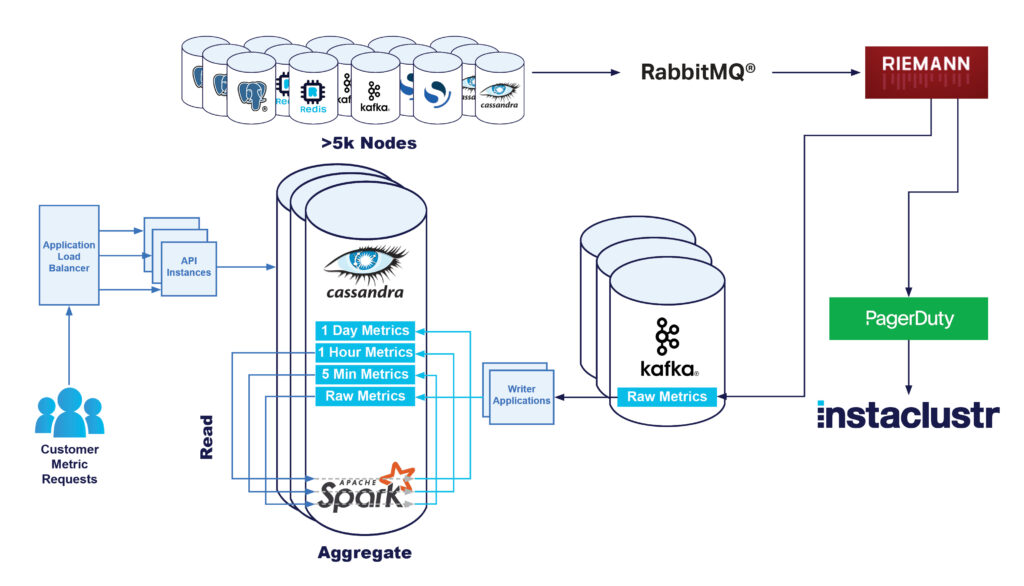
Kafka-basierte Rollups
Der nächste Schritt war die Verwendung von Kafka zur Umstrukturierung unseres Metrik-Rollup-Systems. Durch die korrekte Partitionierung der Metriken in Kafka war es möglich, kleinere Kafka-Streams-Anwendungen zu entwickeln, die alle Aggregationen durchführen, ohne in Cassandra zu lesen.
Diese Anwendungen aggregieren Kennzahlen und speichern die Durchschnitts-, Minimal- und Maximalwerte für jeweils fünf Minuten, eine Stunde und einen Tag. Ursprünglich hatten wir uns für das Kafka-Streams-Framework entschieden, da es für derartige Arbeitslasten ausgelegt zu sein schien. Eine Anwendung in unserer Testumgebung einzurichten und auszuführen war recht einfach. Die eigentliche Schwierigkeit lag in der Skalierung der Anwendung zur Bewältigung der Produktionslast.
Mit zunehmender Belastung der Streams-Anwendung wurde die Verbindung zum Broker unterbrochen und es kam zu einer Schleife aus Wiederverbinden, Wiederherstellen und Trennen der Verbindung. Es schien keinen Unterschied zu machen, egal wie sehr man die Parameter der Consumer veränderte. Nach einigen Profilerhebungen und Versuchen wurde deutlich, dass die Anwendung nicht mehr genügend Speicherplatz hatte. Wenn der Speicherbedarf höher wurde, verfehlten die Consumer den Heartbeat, schieden aus dem Broker aus, gaben Speicher frei, stellten die Verbindung wieder her und begannen den Zyklus erneut.
Wir hofften zunächst, dass diese Systeme extrem ressourcenschonend arbeiten würden, doch wir mussten mehrere R5.4xl mit jeweils 128 GB RAM einsetzen, damit die Aggregationsanwendung unter unserer Produktionslast überhaupt laufen konnte. Es gelang uns, die Parameter der Rocks DB weiter anzupassen. So ließ sich die freie Nutzung des Off-Heap-Speichers verhindern, und die Anwendung lief endlich stabil.
Wir wollten Spark-Aufträge lieber heute als morgen abschalten, um die Belastung des Cassandra-Clusters zu verringern. Deshalb haben wir diese Anwendungsversion in der Produktion eingesetzt. Der Plan war, die Anwendung später zu überarbeiten und zu optimieren, um sie auf kleineren Instanzen ausführen zu können.
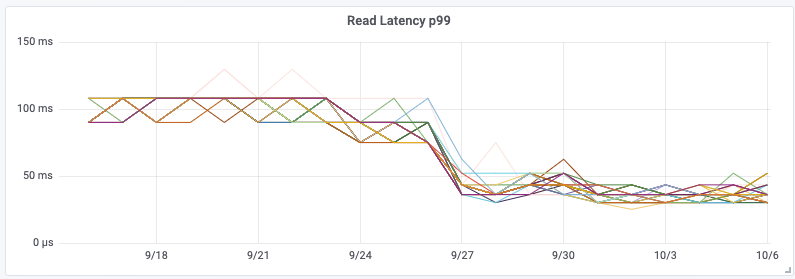
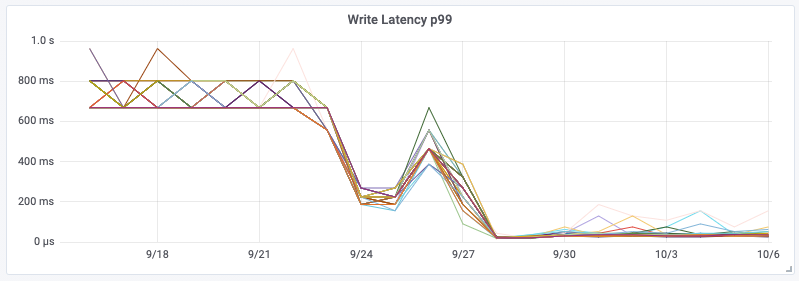
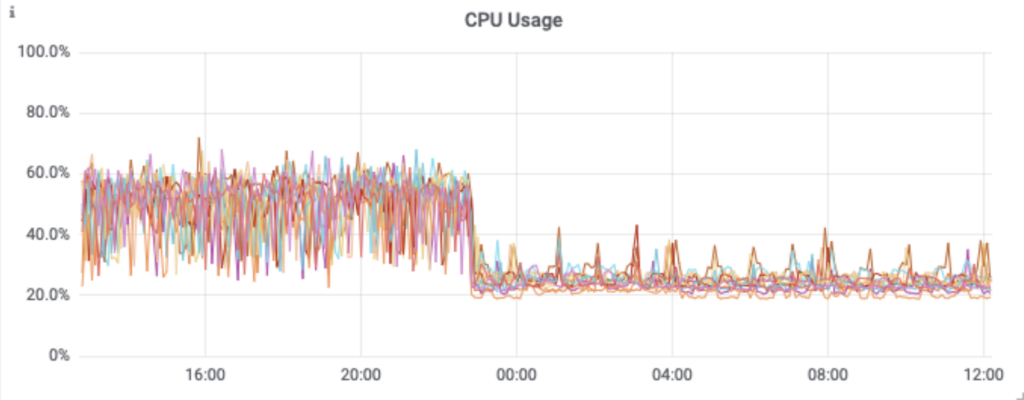
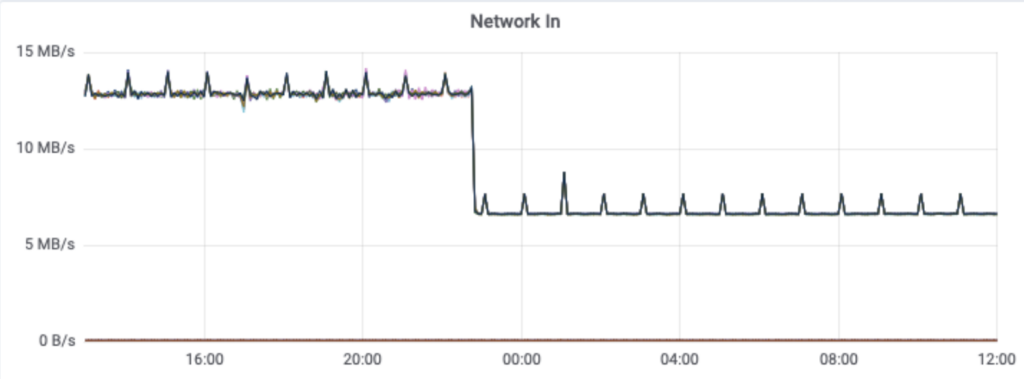
Die zusätzliche Bereitstellung spezieller Aggregationsinstanzen und des Kafka-Clusters selbst erhöht zwar die Gesamtkomplexität, bedeutet aber, dass wir dadurch den Cassandra-Cluster von einer großen Rechenlast befreien konnten. Diese Änderung hatte zur Folge, dass die CPU-Auslastung von Cassandra um 30 % sank und die Latenz für synthetische Cassandra-Transaktionen auf ein ⅓ des ursprünglichen Wertes zurückging – eine Halbierung der P99-Latenz von Cassandra. Viel wichtiger ist allerdings die Reduzierung der API-Latenzzeiten für Kunden und die deutliche Verringerung der Zahl der an Kunden zurückgesandten Statusbenachrichtigungen vom Typ 429. Die Änderung erfolgte am 28. September.
![]()
![]()
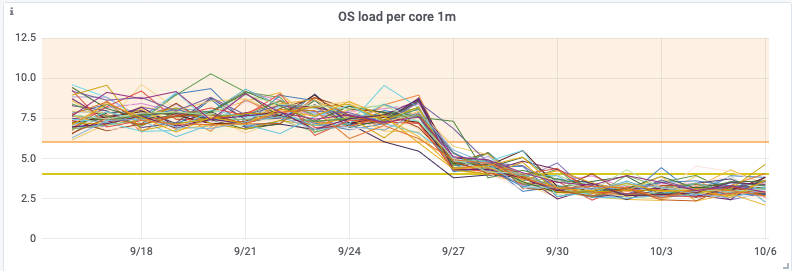
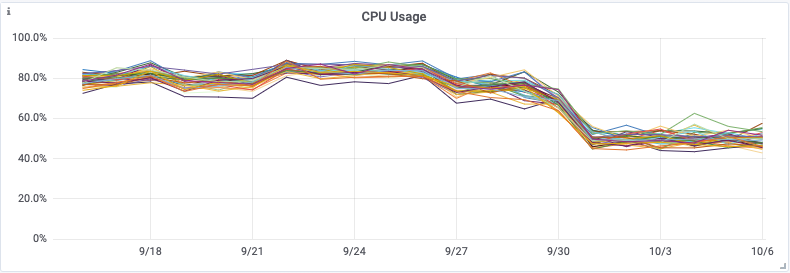
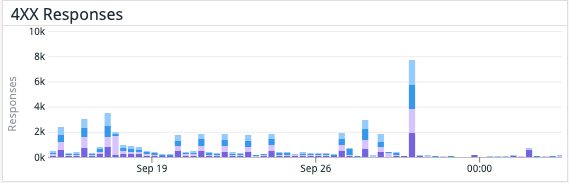
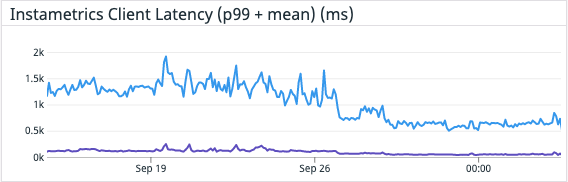
Durch die Verwendung von Kafka-Consumer-Gruppen können wir weiterhin unsere Aggregationsanwendung bzw. unsere Writer-Anwendung skalieren, und zwar unabhängig von allen anderen Diensten. Das bedeutet auch, dass etwaige Verzögerungen in der Schreib-Pipeline unsere Pipeline für Problemmeldungen und -lösungen nicht ausbremsen!
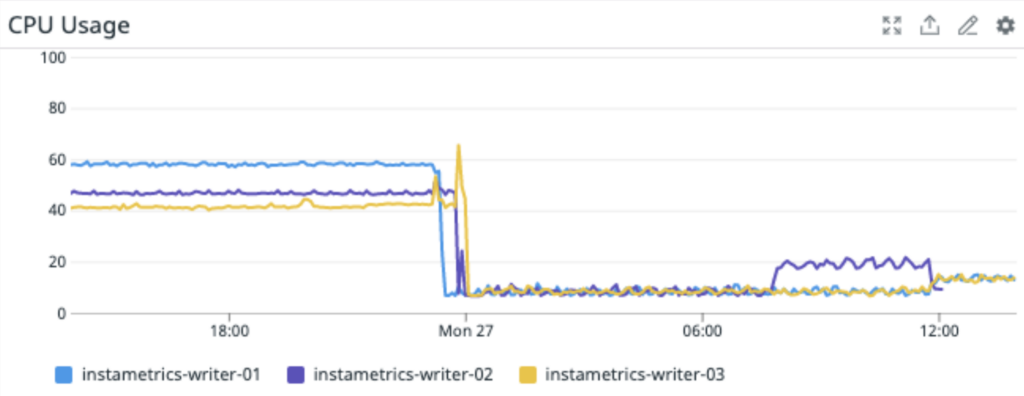
Überarbeitung der Cassandra Writers
Bei der Ausführung der Rollup-Anwendung trat ein Problem bei der Implementierung unseres Cassandra-Writers auf. Er konnte die schnelle Ausführung der Rollup-Anwendung nicht verarbeiten und es kam beim Schreiben in Cassandra zu Zeitüberschreitungen. Wir haben uns entschlossen, die Writer-Anwendung durch eine Begrenzung der Ausgaberate zu ergänzen, damit die Schreiblast konstanter wird.
Bei der Implementierung dieser Änderung in der Writer-App entschieden wir uns auch, mit Batchverarbeitungen zu experimentieren. Unsere ursprüngliche Implementierung verwendete Tokenaware-Batches. Im Normalfall sind partitionierte Batches in Cassandra sehr kostspielig – wenn Sie Partitionen kombinieren, die zu jedem Knoten gehören, müssen ALLE Knoten koordiniert werden, um diesen Batch zu verarbeiten. Dieses Problem verschlimmert sich je größer der Cluster wird.
Die Lösung besteht darin, Partitionen, die einem einzigen Satz von Replikaten (vnode) angehören, zu einem Stapel zusammenzufassen, so dass der gesamte Stapel nur von dem Koordinator und seinem Replikat bearbeitet werden kann. In den meisten allgemeinen Tipps zu Cassandra wird zwar erklärt, dass dieser Schritt nicht notwendig ist. Für unseren Anwendungsfall ist er jedoch extrem wichtig, sowohl für die CPU-Auslastung des Clients als auch des Clusters.
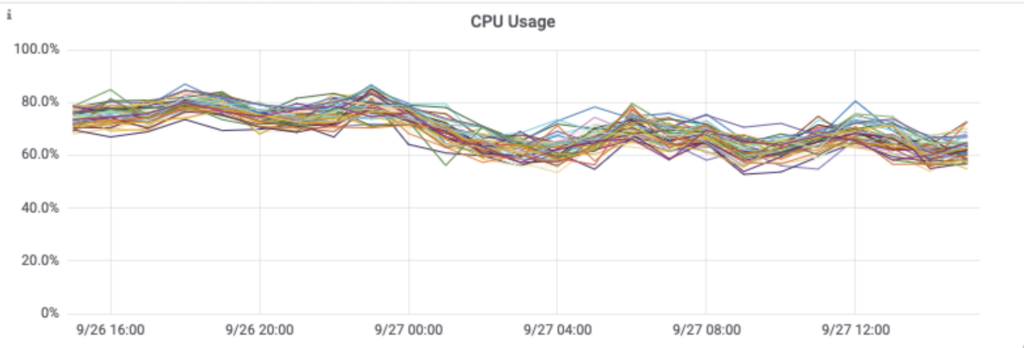
Das Batching wirkte sich auch deutlich auf die Auslastung des Cassandra-Clusters aus.
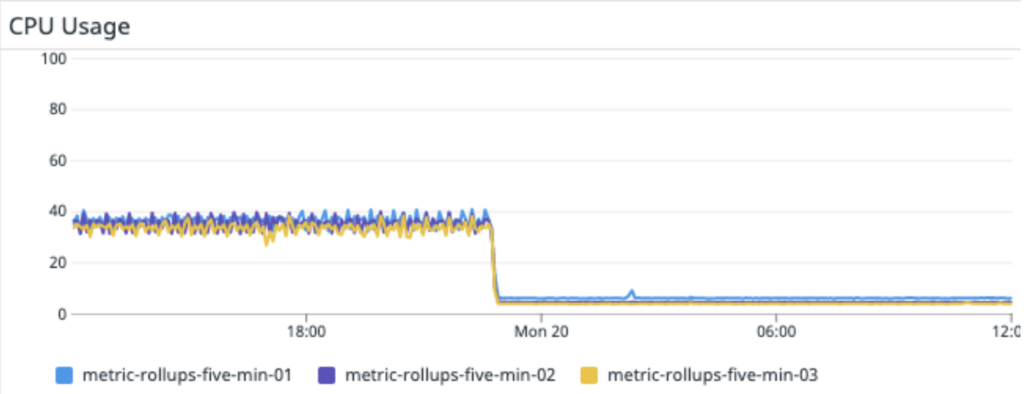
Schließlich gelang es uns, unsere Produktionsinfrastruktur mit 3 m5.2xlarge Cassandra-Writer-Instanzen auszuführen.
Im Folgenden finden Sie ein einfaches Beispiel für Micro-Batching mit dem Cassandra Java-Treiber 4. Sie können es gerne selbst ausprobieren:
public void accept(final BoundStatement bound) {
final TokenMap tokenMap = session.getMetadata().getTokenMap().get();
final Set<Node> replicas =
tokenMap.getReplicas(bound.getRoutingKeyspace(), bound.getRoutingKey());
final List<BatchableStatement<?>> statements =
batches.computeIfAbsent(replicas, t -> new ArrayList<>());
statements.add(bound);
if (statements.size() >= batchSize) {
final BatchStatement batch = BatchStatement.builder(BatchType.UNLOGGED)
.addStatements(statements)
.build();
session.executeAsync(batch);
batch.clear();
}
}Überarbeitung des Rollups
Nachdem nun alles funktionierte, wurde es Zeit, die Rollup-Anwendung zu überarbeiten, um die Anforderungen an Skalierbarkeit, Instanzgröße und einige andere Aspekte zu optimieren.
Nach längerem Ausprobieren implementierten wir die Funktionalität schließlich als reinen Kafka-Consumer, also ohne Verwendung des Kafka-Streams-Frameworks. Durch die Zusammenführung von mehreren Streaming-Stufen in eine einzige ließ sich der Speicherbedarf erheblich reduzieren. Anstatt den Zwischenzustand in ein Kafka-Topic zu übertragen, wie es das Streams-Framework automatisch tut, werden die Daten im Falle eines Neustarts der Anwendung vom Quell-Topic wiedergegeben.
Diese Entscheidung war zwar ein Kompromiss, den wir unter diesen Umständen aber gerne in Kauf nahmen. Da wir davon ausgehen, dass Neustarts nur selten vorkommen, lässt sich der nötige Aufwand für die Speicherung des Zwischenzustands während des Normalbetriebs senken. Im Falle eines Anwendungsausfalls müssen wir dann allerdings mehr Ereignisse wiederholen, um wieder auf die Beine zu kommen.
So wird nicht nur die Belastung der Anwendungsinstanzen verringert,
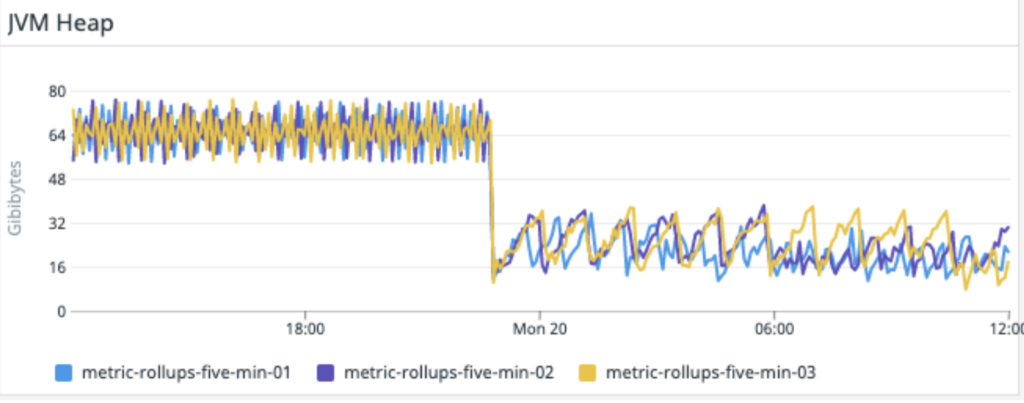
sondern auch für den Kafka-Cluster selbst.
Nächste Schritte und Fazit
Eigentlich hatten wir uns vorgenommen, die Auslastung unseres internen Cassandra-Clusters zu reduzieren. Wir wollten vor allem die Effizienz der Arbeitsabläufe verbessern und gleichzeitig unsere Flexibilität und Erweiterbarkeit erhöhen.
Wie Sie sehen, konnten wir die Auslastung unseres internen Cassandra-Clusters erheblich reduzieren. Gleichzeitig verringern sich die Latenzzeiten und die Fehlerraten für Kunden, die ihre Daten über unsere API abfragen.
In den meisten Anwendungsfällen müssten wir dann sofort mit der Verkleinerung unseres Clusters beginnen, um deutliche Kosteneinsparungen zu erzielen. Wir werden den Cluster jedoch nicht sofort verkleinern, da wir in Kürze weitere Metrik-Anwendungen veröffentlichen und unseren deutlichen Vorsprung bei eventuellen Problemen wahren wollen.
In den kommenden Blogbeiträgen werden wir darüber hinaus aufzeigen, wie wichtig Kafka für die Flexibilität und Erweiterbarkeit unserer gesamten Metrik-Pipeline inzwischen geworden ist. Die erfolgreiche Eliminierung der Spark-Workloads aus unserer Metrik-Pipeline ist bereits zu erkennen.
Bleiben Sie am Ball, und erfahren Sie in Kürze, wie wir durch den Einsatz von Redis unsere Monitoring-API für die Latenzzeit von Kundenanfragen deutlich verbessern und die Leistung unseres Cassandra-Clusters weiter deutlich steigern konnten.
RabbitMQ® ist eine Marke von VMware, Inc. in den USA und anderen Ländern.
Der Originalartikel wurde auf Englisch auf https://www.instaclustr.com/blog/the-introduction-of-apache-kafka-infrastructure/ veröffentlicht und ist geschrieben von Greg Raevski.