The Linux® installation for beginners may seem complex at first glance, but with the right guidance, switching to the open-source operating system is entirely achievable. Linux® offers security and stability, as well as full cost transparency with no licensing fees. This guide walks you through the key steps for a successful Linux® installation: from choosing the right distribution and partitioning to the first configuration after booting. (more…)
The Linux® market share is expected to continue growing through 2026, particularly in the areas of servers, cloud computing, and enterprise solutions. While Linux® still occupies a niche in desktop systems, it is already widely adopted in servers and cloud infrastructures. This development significantly influences corporate decisions, as Linux & Open Source solutions offer both cost savings and technical flexibility.
What does the current Linux market share mean for companies?
Linux® currently holds approximately 3% of the desktop market, but is represented with over 70% in the server sector and nearly 100% of the world’s top 500 supercomputers. This distribution clearly shows in which areas Linux & Open Source is deployed and what strategic opportunities companies can derive from this.
In the server segment, companies use Linux® due to its stability, security, and cost efficiency. Cloud providers such as Amazon Web Services®, Google Cloud®, and Microsoft® Azure® base their infrastructures largely on Linux systems. This widespread adoption makes Linux expertise relevant for IT teams.
For business decisions, this specifically means:
- Reduced licensing costs by eliminating proprietary operating system licenses
- Flexibility in adapting systems to specific requirements
- Security through transparent source code and rapid patch cycles
- Independence from individual vendors and their licensing policies
Mobile devices further reinforce this trend, as Android® is based on the Linux kernel and thus accounts for a large share of mobile operating systems. This widespread adoption creates an ecosystem in which Linux competencies are becoming increasingly relevant.
How is Linux developing compared to other operating systems?
Linux® shows different development patterns compared to Windows® and macOS® depending on the area of deployment. While Windows continues to lead the desktop market, Linux is continuously gaining market share in the server sector with distributions such as Ubuntu®, Red Hat® Enterprise Linux, and SUSE®.
In enterprise environments, Linux is valued for its adaptability and the ability to tailor systems precisely to corporate requirements. Windows remains established in office environments, but comes with licensing costs.
The characteristics of Linux are particularly evident in:
- Container technologies and microservice architectures
- Cloud-native applications and DevOps environments
- IoT devices and embedded systems
- High-performance computing and scientific applications
macOS® maintains its position in creative industries, while Linux grows in technical and development-oriented environments. This specialization leads many companies to pursue hybrid approaches, deploying different operating systems depending on the use case.
The trend shows: Linux gains market share wherever technical flexibility, cost efficiency, and adaptability are relevant. Linux & Open Source technologies thus become a strategic option for forward-thinking companies.
Which factors will influence Linux growth until 2026?
Linux growth through 2026 will be primarily driven by cloud computing, containerization, and digital transformation. These technology trends increase demand for flexible, cost-effective, and secure operating systems, making Linux & Open Source solutions increasingly relevant.
Cloud computing remains a key growth driver. Since most cloud infrastructures are based on Linux, Linux usage automatically increases with cloud adoption. Companies migrating their workloads to the cloud inevitably encounter Linux systems.
Container technologies such as Docker® and Kubernetes® or virtualization with, for example, Proxmox®, which primarily run on Linux, are changing how applications are developed and deployed. These technologies enable companies to scale and manage applications more efficiently.
Other decisive factors include:
- Internet of Things (IoT) – Linux runs on many IoT devices due to its adaptability
- Cost savings – no license fees and reduced hardware requirements
- Security aspects – transparent code and fast security updates
- Edge Computing – Linux is well-suited for decentralized computing architectures
- Artificial Intelligence – most AI frameworks run on Linux
The growing importance of open source in digital transformation further reinforces this development. Companies are increasingly recognizing the value of open standards and vendor-independent solutions for their long-term IT strategy.
Why are more and more German companies relying on Linux?
German companies are increasingly turning to Linux because it complies with the strict data protection requirements of the GDPR and allows full control over data processing and storage. The transparency of Linux & Open Source systems significantly facilitates the fulfillment of compliance requirements.
Regulatory aspects play a decisive role. German authorities and companies value the ability to audit the source code and ensure that no hidden functions or backdoors exist. This transparency is particularly important for critical infrastructures and sensitive data processing.
Cost factors further reinforce Linux adoption in Germany. Small and medium-sized enterprises can achieve significant savings by eliminating licensing costs, which can then be invested in other areas of digitalization.
Specific aspects for German companies:
- Data sovereignty through full control over IT systems
- Independence from individual technology vendors
- Support for the European digital strategy
- Promotion of local IT expertise and innovation
- Long-term planning security without licensing surprises
The German preference for engineering excellence and technical perfection aligns with the Linux philosophy. Open source enables German companies to optimize systems according to their exact requirements while meeting high quality standards.
How credativ® helps with Linux migration and support
credativ® has been supporting companies since 1999 in the successful introduction and operation of Linux systems through comprehensive consulting, professional migration, and continuous 24/7 support. As a vendor-independent company, we offer tailored Linux & Open Source solutions for every company size.
Our Linux services include:
- Strategic consulting for Linux migrations and system architectures
- Professional migration of existing systems to Linux platforms
- 24/7 support for Debian Linux, PostgreSQL®, and other open-source projects
- Training and knowledge transfer for internal IT teams
- Long-term maintenance and optimization of Linux infrastructures
As a German company, we understand the specific requirements of the German market, including data protection regulations and compliance requirements. Our support team consists exclusively of permanent specialists without an intermediate call center.
Would you like to leverage the possibilities of Linux for your company? Contact us for a no-obligation consultation and learn how we can successfully implement your Linux migration. Schedule an appointment with our Linux experts today.
Transparency notice
credativ® is an authorized reseller for Red Hat® (Red Hat Inc.) and PostgreSQL® Competence Center (PostgreSQL Community). Linux® is a registered trademark of Linus Torvalds. Windows®, Microsoft®, and Azure® are registered trademarks of Microsoft Corporation. Amazon Web Services® is a registered trademark of Amazon.com Inc. Google Cloud® is a registered trademark of Google LLC. Android® is a registered trademark of Google LLC. Ubuntu® is a registered trademark of Canonical Ltd. SUSE® is a registered trademark of SUSE LLC. Docker® is a registered trademark of Docker Inc. Kubernetes® is a registered trademark of the Cloud Native Computing Foundation. macOS® is a registered trademark of Apple Inc.
The mention of trademarks serves solely for the factual description of migration scenarios and services of credativ GmbH. There is no business relationship with the mentioned trademark owners.
Foreman is clearly rooted in an IPv4 world. You can see it everywhere. Like it does not want to give you a host without IPv4, but without IPv6 is fine. But it does not have to be this way, so let’s go together on a journey to bring Foreman and the things around it into the present.
(more…)
From July 14 to 19, 2025, this year’s Debian Conference (DebConf25) is taking place in Brest, Western France, with over 450 participants – the central meeting of the global Debian community. The DebConf annually brings together developers, maintainers, contributors, and enthusiasts to collaboratively work on the free Linux distribution Debian and exchange ideas on current developments.
credativ is once again participating as a sponsor this year – and is also represented on-site by several employees.
A Week Dedicated to Free Software
DebConf25 offers a diverse program with over 130 sessions: technical presentations, discussion panels, workshops, and BoF sessions (“Birds of a Feather”) on a wide variety of topics from the Debian ecosystem. Some key topics this year:
- Progress surrounding Debian 13 “Trixie”, whose release is currently being actively worked on
- Reproducible Builds, System Integration, and Security Topics
- Debian in Cloud Environments and Container Contexts
- Improved CI/CD Infrastructure and New Tools for Maintainers
Many of the presentations will, as always, be recorded and are publicly available on video.debian.net, or can be viewed live via https://debconf25.debconf.org/.
Credativ’s Commitment – not just On-Site
As a long-standing part of the Debian community, it is natural for credativ to contribute as a sponsor to DebConf again in 2025. Furthermore, our colleagues Bastian, Martin, and Noël are on-site to exchange ideas with other developers, attend presentations or BoFs, and experience current trends in the community.
Especially for companies focused on professional open-source services, Debian remains a cornerstone – whether in data centers, in the embedded sector, or in complex infrastructure projects.
Debian Remains Relevant – both Technically and Culturally
Debian is not only one of the most stable and reliable Linux distributions but also represents a special form of community and collaboration. The open, transparent, and decentralized organization of the project remains exemplary to this day.
For us at credativ, the Debian project has always been a central element of our work – and at the same time, a community to which we actively contribute through technical contributions, package maintenance, and long-term commitment.
Thank You, DebConf Team!
Heartfelt thanks go to the DebConf25 organizing team, as well as to all helpers who made this great conference possible. Brest is a beautiful and fitting venue with fresh Atlantic air, a relaxed atmosphere, and ample space for exchange and collaboration.
Outlook for 2026
Planning for DebConf26 is already underway. We look forward to the next edition of DebConf, which will take place in Santa Fe, Argentina – and to continuing to be part of this vibrant and important community in the future.
Introduction
When it comes to providing extended support for end-of-life (EOL) Linux distributions, the traditional method of building packages from sources may present certain challenges. One of the biggest challenges is the need for individual developers to install build dependencies on their own build environments. This often leads to different build dependencies being installed, resulting in issues related to binary compatibility. Additionally, there are other challenges to consider, such as establishing an isolated and clean build environment for different package builds in parallel, implementing an effective package validation strategy, and managing repository publishing, etc.
To overcome these challenges, it is highly recommended to have a dedicated build infrastructure that enables the building of packages in a consistent and reproducible way. With such an infrastructure, teams can address these issues effectively, and ensures that the necessary packages and dependencies are available, eliminating the need for individual developers to manage their own build environments.
OpenSUSE’s Open Build Service (OBS) provides a widely recognized public build infrastructure that supports RPM-based, Debian-based, and Arch-based package builds. This infrastructure is well-regarded among users who require customized package builds on major Linux distributions. Additionally, OBS can be deployed as a private instance, offering a robust solution for organizations engaged in private software package builds. With its extensive feature set, OBS serves as a comprehensive build infrastructure that meets the requirements of teams to build security-patched package on top of already existing packages in order to extend the support of end-of-life (EOL) Linux distributions, for example.
Facts
On June 30, 2024, two major Linux distributions, Debian 10 “Buster” and CentOS 7, have reached their End-of-Life (EOL) status. These distributions gained widespread adoption in numerous large enterprise environments. However, due to various factors, organizations may face challenges in completing migration processes in a timely manner, requiring temporary extended support for these distributions.
When a distribution reaches its End-of-Life (EOL) support from upstream, mirrors and corresponding infrastructure are typically removed. This creates a significant challenge for organizations still using those distributions and seeking extended support, as they not only require access to a local offline mirror but also need the infrastructure to rebuild packages in such a way that is consistent with their former original upstream builds whenever there is a need to rebuild packages for security reasons.
Goal
To provide utilities that support teams building packages, OBS is able to help them. Thereby, it also helps them to have a build infrastructure that builds all existing source and binary packages along with their security patches in a semi-original build environment, further extending their support of EOL Linux distributions. This is achieved by keeping package builds at a similar level of quality and compatibility to their former original upstream builds.
Requirements
To achieve the goal mentioned above, two essential components are required:
- Local mirror of the EOL Linux distribution
- Private OBS instance.
In order to set up a private OBS instance, you can fetch OBS from the upstream GitHub repository and install as well as build it on your local machine, or alternatively, you can simply download the OBS Appliance Installer to integrate a private OBS instance as a new build infrastructure.
Keep in mind that the local mirror typically doesn’t contain the security patches to properly extend the support of the EOL distribution. Just rebuilding the existing packages won’t automatically extend the support of such distributions. Either those security patches must be maintained by the teams themselves and added to the package update by hand, or they are obtained from an upstream project that provides those patches already.
Nevertheless, once the private OBS instance is successfully installed, it can then be linked with the local offline mirror that the team wants to extend the support for, and be configured as a semi-original build environment. By doing so, the build environment can be configured as close as possible to the original upstream build environment to keep a similar level of quality and compatibility although packages might get built for security update with new patches.
This way, the already ended support of a Linux distribution can be extended because a designated team can not only build packages on their own but also provide patches for packages that are affected by bugs or security vulnerabilities.
Achievement
The OBS build infrastructure provides a semi-original build environment to simplify the package building process, reduce inconsistencies, and achieve reproducibility. By adopting this approach, teams can simplify their development and testing workflows and enhance the overall quality and reliability of the generated packages.
Demonstrates
Allow us to demonstrate how OBS can be utilized as a build infrastructure for teams in order to provide the build and publish infrastructure needed for extending the support of End-of-Life (EOL) Linux distributions. However, please note that the following examples are purely for demonstration purposes and may not precisely reflect the specific approach.
Config OBS
Once your private OBS instance is set up, you can log in to OBS by using its WebUI. You must use the ‘Admin‘ account with its default password ‘opensuse‘. After that, you can create a new project for the EOL Linux distribution as well as add users and groups for teams that are going to work on this project. In addition, you must link your project with a local mirror of the EOL Linux distribution and customize your OBS project to replicate the former upstream build environment.
OBS supports the Download on Demand (DoD) feature that can establish a connection with a local mirror on the OBS instance with the designated project within OBS to fetch build dependencies on-demand during the build process. This simplifies the build workflow and reduces the need for manual intervention.
Note: some configurations are only available with the Admin account, including Manage Users, Groups and Add Download on Demand (DoD) Repository.
Now, let’s dive into the OBS configuration of such a project.
Where to Add DoD Repository
After you created a new project in OBS, you may find the “Add DoD Repository” option in the Repositories tab under the ‘Admin’ account.
There, you must click the Add DoD Repository button as shown below:
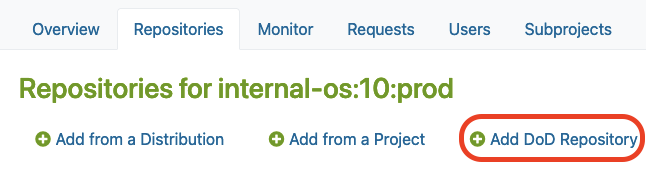
Link your local mirror via DoD
Next, you can provide a URL to link your local mirror via “Add DoD Repository“.
By doing so, you are going to configure the DoD repository. For this, you have to:
- Name the DoD Repo
- Provide a URL that points to the local mirror that is going to be used as a base for building packages in our project
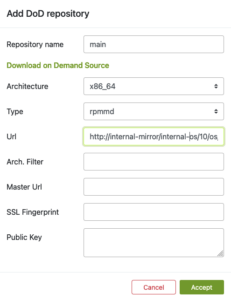
The build dependencies should now be available for OBS to download automatically via the DoD feature.
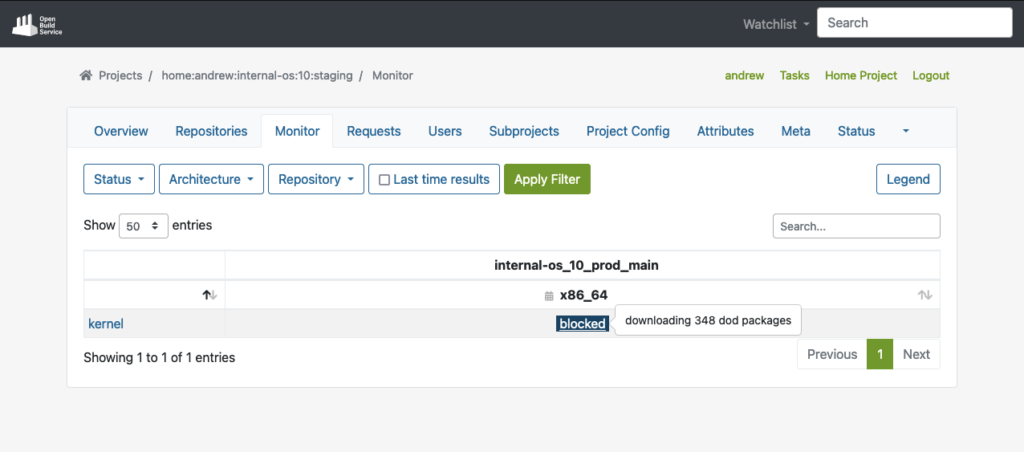
As you can see in the example below, OBS was able to fetch all the build dependencies for the shown “kernel” package via DoD before it actually started to build the package:
However, after you connected the local mirror with the EOL Linux Distribution, we should also customize the project configuration to re-create the semi-original build environment of the former upstream project in our OBS project.
Project Config
OBS offers a customizable build environment via Project Config, allowing teams to meet specific project requirements.
It allows teams to customize the build environment through the project configuration, enabling them to define macros, packages, flags, and other build-related settings. This helps to adapt their project to all requirements needed to keep the compatibility with the original packages.
You can find the Project Config here:
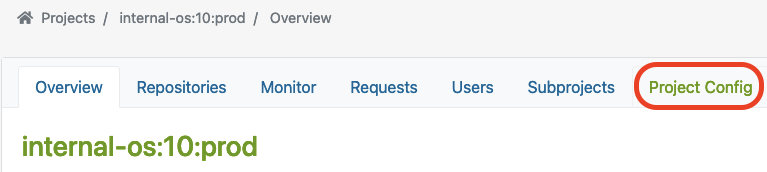
Let’s have a closer look at some examples showing how the project configuration could look like for building RPM-based packages or Debian-based packages.
Depending on the actual package type that has been used by the EOL Linux distribution, the project configuration must be adjusted accordingly.
RPM-based config
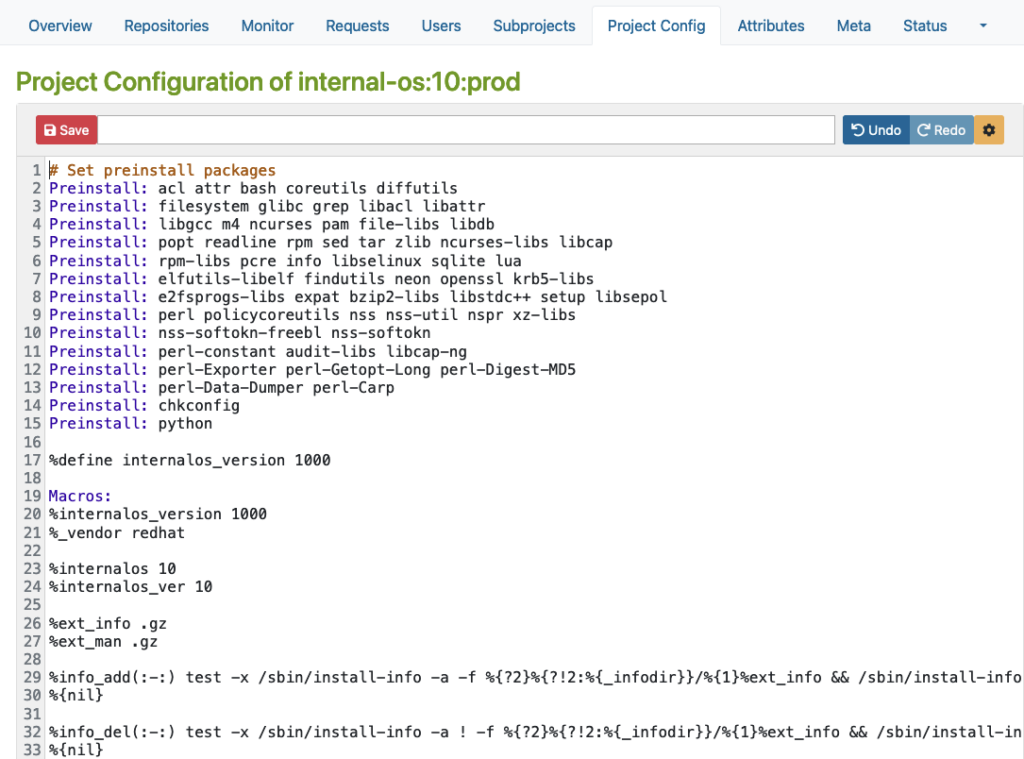
Here is an example for an RPM-based distribution where you can define macros, packages, flags, and other build-related settings.
Please note that this example is only for demonstration purposes:
Debian based config
Then, there is another example for Debian-based distribution where you can specify Repotype: debian, define preinstalled packages, and build-related settings in the build environment.
Again, please note that this example is for demonstration purposes only:
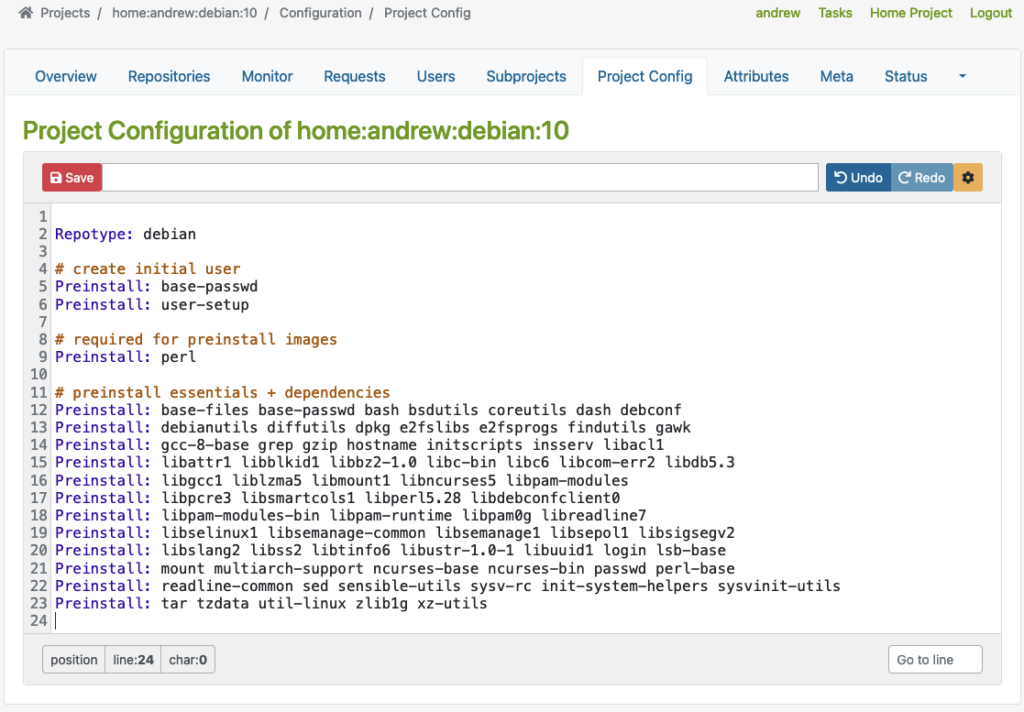
As you can see in the examples above, the Repotype defines the repository format for the published repositories. Preinstall defines packages that should be available in the build environment while building other packages. You may find more details about the syntax in the Build Configuration chapter in the manual provided by OpenSuSE.
With this customizable build environment feature, each build starts in a clean chroot or KVM environment, providing consistency and reproducibility in the build process. Teams may have different build environments in different projects that are isolated and can be built in parallel. The separated projects together, with dedicated chroot or KVM environments for building packages prevent interference or conflicts between builds.
User Management
In addition to projects, OBS offers flexible access control, allowing team members to have different roles and permissions for various projects or distributions. This ensures efficient collaboration and streamlined workflow management.
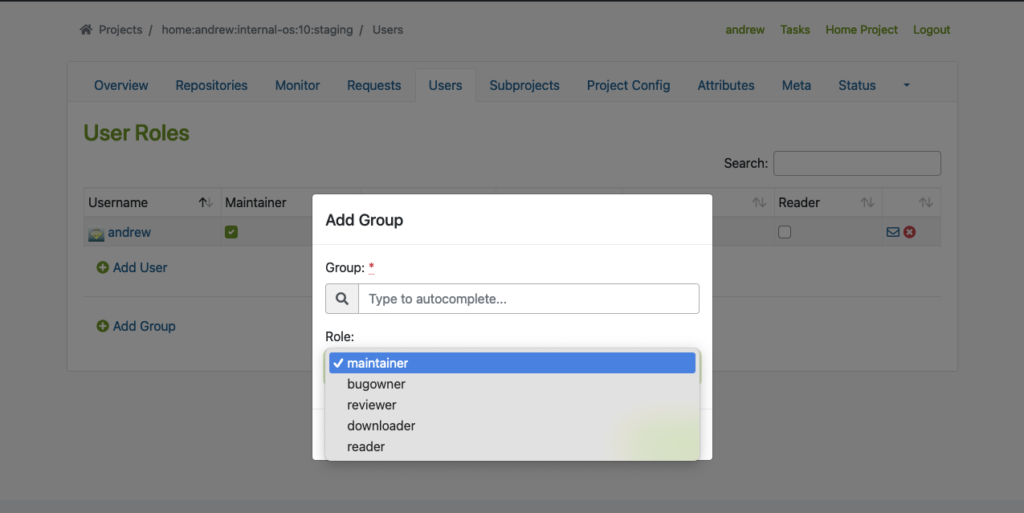
To use this feature properly, we must create Users and Groups by using the Admin account in OBS. You may find the ‘Users‘ tab within the project where you can add users and groups with different roles.
The following example shows how to add users and groups in a given project:
Flexible Project Setup
OBS allows teams to create separate projects for development, staging, and publishing purposes. This controlled workflow ensures thorough testing and validation of packages before they are submitted to the production project for publishing.
Testing Strategy with Projects
Before packages are released and published, proper testing of those packages is crucial. To achieve this, OBS offers repository publish integration that helps to implement a Testing Strategy. Developers may get their packages published in a corresponding Staging repository first before starting the validation process of the packages, so that they can be submitted to the Production project. From there, they will then be published and made available to other systems.
It seamlessly integrates with local repository publishing, ensuring that all packages in the build process are readily available. This eliminates the need for additional configuration on internal or external repositories.
The next example shows a ‘home:andrew:internal-os:10:staging’ project, which is used as a staging purposed repository. There, we import the nginx source package to build and validate it afterward.
Start the Build Process
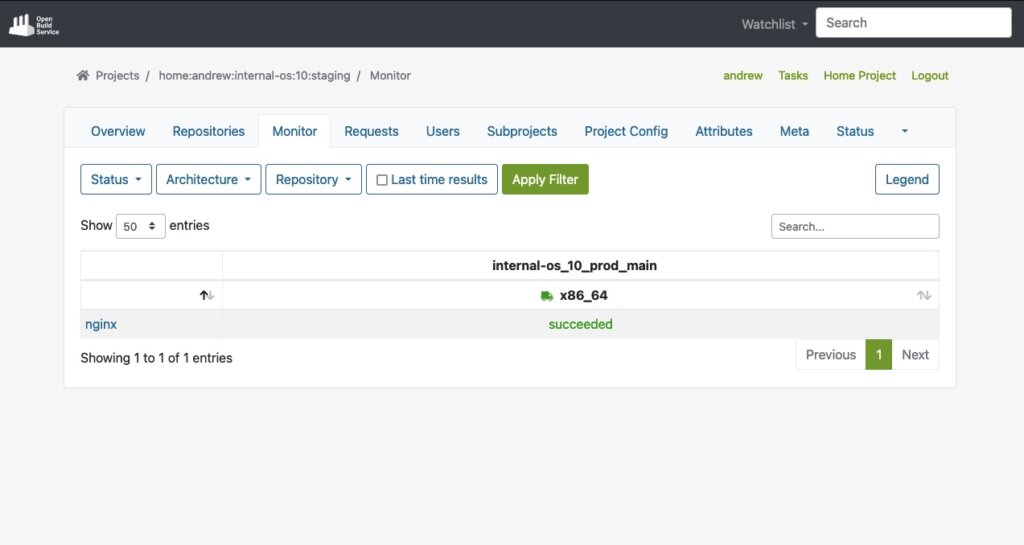
Once the build dependencies are downloaded via DoD, the build process starts automatically.

As soon as the build process for a package like ‘nginx’ succeeds, we will also see it in the interface:
Last but not least, the package will automatically be published into a repository that is ready to be used with package managers like YUM. In our test case, the YUM-ready repository helps us to easily perform validation by conducting tests on VM or actual hardware.
Below, you can see an example of this staging repository (Index of the YUM-ready staging repository):
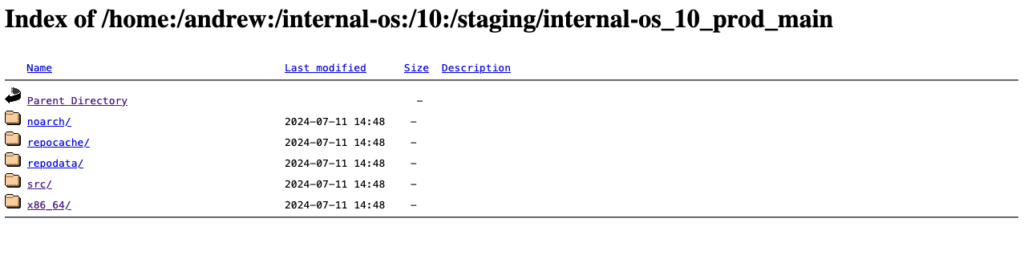
Please note: To meet the testing strategy in our example, packages should only be submitted to the Prod project once they have successfully passed the validation process in the Staging repository.
Submit to Prod after Validation
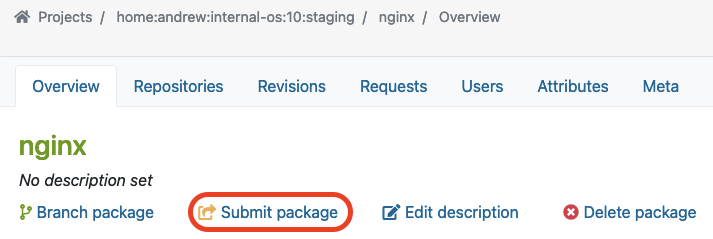
As soon as we validate the functionality of a package in the staging project and repository, we can move on by submitting the package to the production project. Underneath the package overview page (e.g., in our case, the ‘nginx’ package), you can find the Submit Package button to start this process:
In our example, we use the ‘internal-os:10:prod’ project for the Production repository. Previously, we built and validated the ‘nginx’ package in the Staging repository. Now we want to submit this package into the Production project which we call ‘internal-os:10:prod’.
Once you click “Submit package“, the following dialog should pop up. Here, you can fill out the form to submit the newly built package to production:
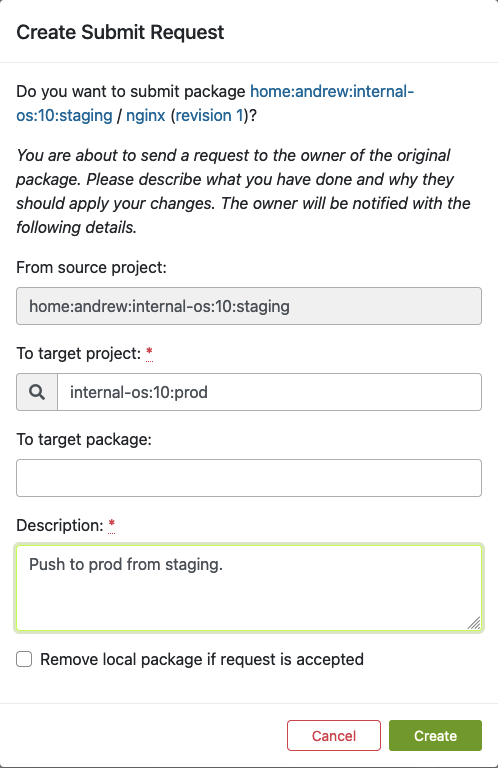
Fill out this form and click ‘Create’ as soon as you are ready to submit the new package to the production project.
Find Requests
Next to submitting a package, a so-called repository master must approve the newly created requests for the designated project. This master can find a list of all requests in the Requests tab, where he/she can do the Request Review Control.
The master can find ‘Requests‘ in the project overview page like this:
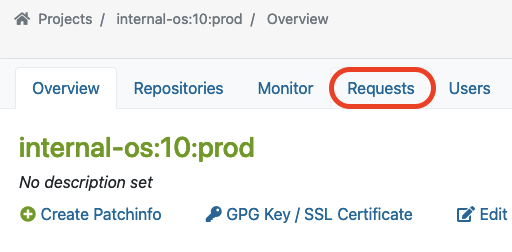
Here, you can see an example of a package that was submitted from Staging to the Prod project.
The master must click on the link marked with a red circle to perform the Request Review Control:
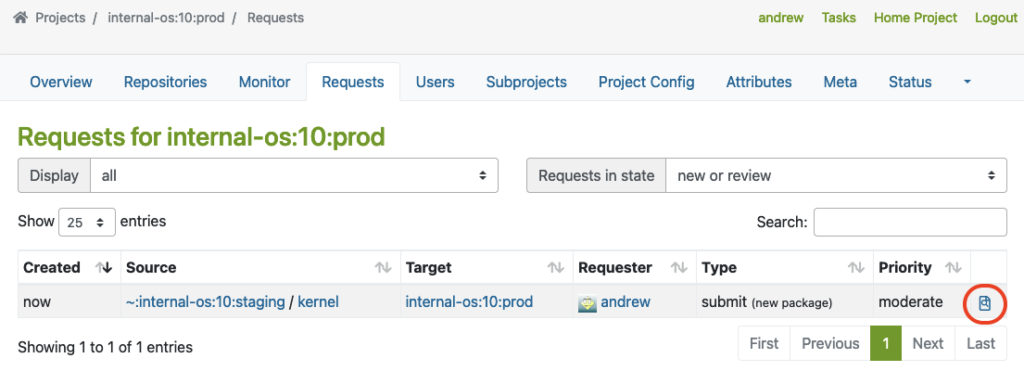
This will bring up the interface for Request Review Control, in which the repository master from the production project may decline or accept the package request:
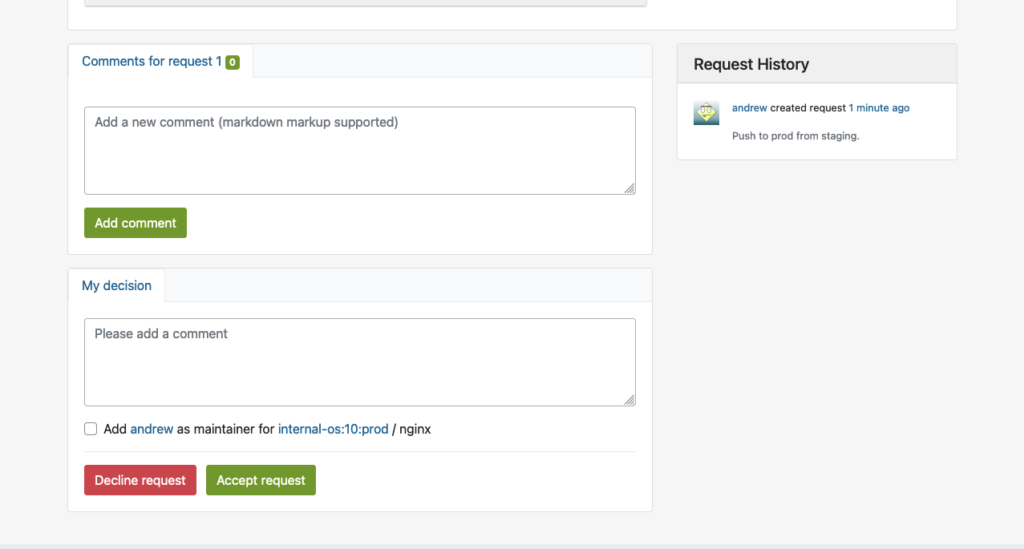
Reproduce in Prod Project
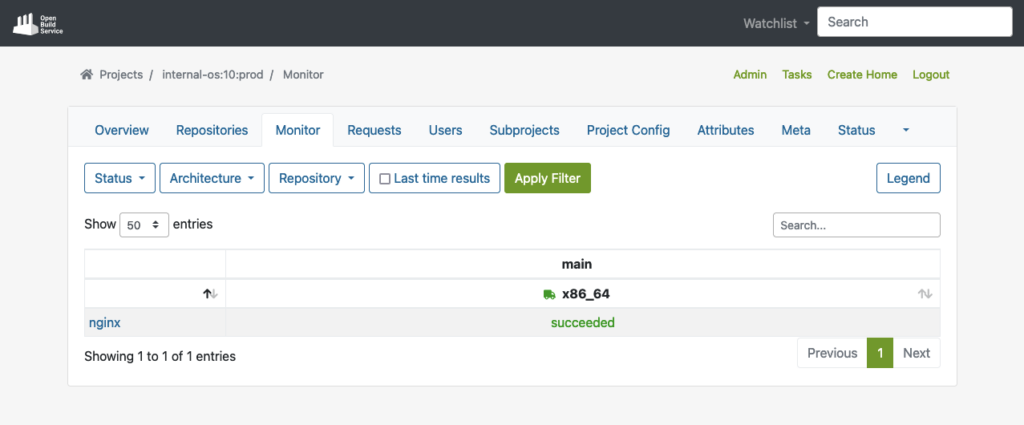
Once the package is accepted into the production project, it will automatically download all required dependencies from DoD, and reproduce the build process.
The example below shows the successfully built package in the production repo after the build process has been completed:
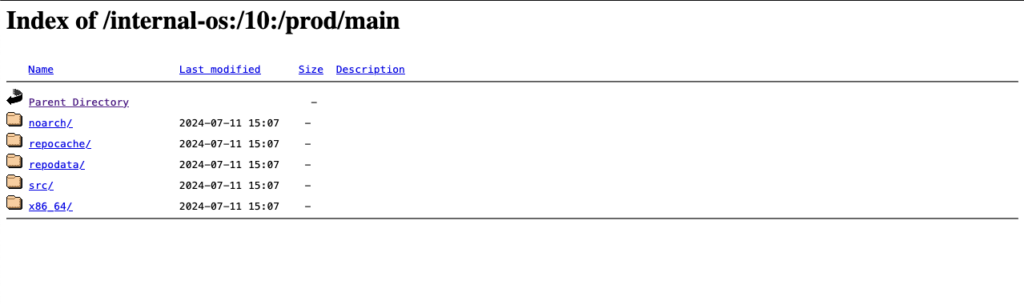
Publish to YUM-ready repository for Prod
Finally, the package will then also be published to the YUM-ready Prod repository as soon as the package has been built successfully. Here, you can see an example of the YUM-ready Prod repository that OBS handles.
(Note: you can name the project and repository name on your preferences):
Extras
In this chapter, we want to have a look at some possible extra customizations for OBS in your build infrastructures.
Automated Build Pipelines
OBS supports automated builds that may seamlessly integrate into delivery pipelines. Teams can set up CI triggers to commit new packages into OBS to initiate builds automatically based on predefined criteria, reducing manual effort and ensuring timely delivery of updated packages.
Packages get automated builds when committed into an OBS project, which enables administrators to easily integrate automated builds via pipelines:

OBS Worker
Further, the Open Build Service is capable of configuring multiple workers (builders) in multiple architectures. If you want to build with other architectures, just install the ‘obs-worker’ package on another hardware with a different architecture and then simply edit the /etc/sysconfig/obs-server file.
In that file, you must set at least those parameters on the worker node:
- OBS_SRC_SERVER
- OBS_REPO_SERVERS
- OBS_WORKER_INSTANCES
This method may also be useful if you want to have more workers in the same architecture available in OBS. The OpenSUSE’s public OBS instance has a large-scale setup which is a good example of this.
Emulated Build
In Open Build Service, it is also possible to configure emulated builds for cross-architecture build capabilities via QEMU. By using this feature, almost no changes are needed in package sources. Developers can build on target architectures without the need for other hardware architectures to be available. However, you might encounter problems with bugs or missing support in QEMU, and emulation may slow down the build process significantly. For instance, see how OpenSuSE managed this on RISC-V when they didn’t have the real hardware in the initial porting stage.
Conclusion
Integrating a private OBS instance as the build infrastructure provides teams a robust and comprehensive solution to build security-patched package for extended support of end-of-life (EOL) Linux distributions. By doing so, teams can unify the package building process, reduce inconsistencies, and achieve reproducibility. This approach simplifies the development and testing workflow while enhancing the overall quality and reliability of the generated packages. Additionally, by replicating the semi-original build environment, the resulting packages builds in the similar level of quality and compatibility to upstream builds.
If you are interested in integrating a private build infrastructure, or require extended support for any EOL Linux distribution. Please reach out to us. Our team is equipped with the expertise to assist you in integrating a private OBS instance into your exist infrastructure.
This article was originally written by Andrew Lee.
DebConf 2024 from 28. July to 4. Aug 2024 https://debconf24.debconf.org/
Last week the annual Debian Community Conference DebConf happend in Busan, South Korea. Four NetApp employees (Michael, Andrew, Christop and Noël) participated the whole week at the Pukyong National University. The camp takes place before the conference, where the infrastructure is set up and the first collaborations take place. The camp is described in a separate article: https://www.credativ.de/en/blog/credativ-inside/debcamp-bootstrap-for-debconf24/
There was a heat wave with high humidity in Korea at the time but the venue and accommodation at the University are air conditioned so collaboration work, talks and BoF were possible under the circumstances.
Around 400 Debian enthusiasts from all over the world were onsite and additional people attended remotly with the video streaming and the Matrix online chat #debconf:matrix.debian.social
The content team created a schedule with different aspects of Debian; technical, social, political,….
https://debconf24.debconf.org/schedule/
There were two bigger announcements during DebConf24:
- the new distribution eLxr https://elxr.org/ based on Debian initiated by Windriver
https://debconf24.debconf.org/talks/138-a-unified-approach-for-intelligent-deployments-at-the-edge/
Two takeaway points I understood from this talk is Windriver wants to exchange CentOS and preferes a binary distribution. - The Debian package management system will get a new solver https://debconf24.debconf.org/talks/8-the-new-apt-solver/
The list of interesting talks is much longer from a full conference week. Most talks and BoF were streamed live and the recordings can be found in the video archive:
https://meetings-archive.debian.net/pub/debian-meetings/2024/DebConf24/
It is a tradtion to have a Daytrip for socializing and get a more interesting view of the city and the country. https://wiki.debian.org/DebConf/24/DayTrip/ (sorry the details of the three Daytrip are on the website for participants).
For the annual conference group photo we have to go outsite into the heat with high humidity but I hope you will not see us sweeting.
{kind=link}
The Debian Conference 2025 will be in July in Brest, France: https://wiki.debian.org/DebConf/25/ and we will be there.:) Maybe it will be a chance for you to join us.
See also Debian News: DebConf24 closes in Busan and DebConf25 dates announced
With version 256, systemd introduced run0. Lennart Poettering describes run0 as an alternative to sudo and explains on Mastodon at the same time what he sees as the problem with sudo.
In this blog post, however, we do not want to go into the strengths or weaknesses of sudo, but take a closer look at run0 and use it as a sudo alternative.
Unlike sudo, run0 uses neither the configuration file /etc/sudoers nor a SUID bit to extend user permissions. In the background, it uses systemd-run to start new processes, which has been in systemd for several years.
PolKit is used when it comes to checking whether a user has the appropriate permissions to use run0. All rules that the configuration of PolKit provides can be used here. In our example, we will concentrate on a simple variant.
Experimental Setup
For our example, we use an t2.micro EC2 instance with Debian Bookworm. Since run0 was only introduced in systemd version 256 and Debian Bookworm is still delivered with version 252 at the current time, we must first add the Debian Testing Repository.
❯ ssh admin@2a05:d014:ac8:7e00:c4f4:af36:3938:206e … admin@ip-172-31-15-135:~$ sudo su - root@ip-172-31-15-135:~# cat < /etc/apt/sources.list.d/testing.list > deb https://deb.debian.org/debian testing main > EOF root@ip-172-31-15-135:~# apt update Get:1 file:/etc/apt/mirrors/debian.list Mirrorlist [38 B] Get:5 file:/etc/apt/mirrors/debian-security.list Mirrorlist [47 B] Get:7 https://deb.debian.org/debian testing InRelease [169 kB] Get:2 https://cdn-aws.deb.debian.org/debian bookworm InRelease [151 kB] … Fetched 41.3 MB in 6s (6791 kB/s) Reading package lists... Done Building dependency tree... Done Reading state information... Done 299 packages can be upgraded. Run 'apt list --upgradable' to see them. root@ip-172-31-15-135:~# apt-cache policy systemd systemd: Installed: 252.17-1~deb12u1 Candidate: 256.1-2 Version table: 256.1-2 500 500 https://deb.debian.org/debian testing/main amd64 Packages 254.5-1~bpo12+3 100 100 mirror+file:/etc/apt/mirrors/debian.list bookworm-backports/main amd64 Packages 252.22-1~deb12u1 500 500 mirror+file:/etc/apt/mirrors/debian.list bookworm/main amd64 Packages *** 252.17-1~deb12u1 100 100 /var/lib/dpkg/status root@ip-172-31-15-135:~# apt-get install systemd … root@ip-172-31-15-135:~# dpkg -l | grep systemd ii libnss-resolve:amd64 256.1-2 amd64 nss module to resolve names via systemd-resolved ii libpam-systemd:amd64 256.1-2 amd64 system and service manager - PAM module ii libsystemd-shared:amd64 256.1-2 amd64 systemd shared private library ii libsystemd0:amd64 256.1-2 amd64 systemd utility library ii systemd 256.1-2 amd64 system and service manager ii systemd-cryptsetup 256.1-2 amd64 Provides cryptsetup, integritysetup and veritysetup utilities ii systemd-resolved 256.1-2 amd64 systemd DNS resolver ii systemd-sysv 256.1-2 amd64 system and service manager - SysV compatibility symlinks ii systemd-timesyncd 256.1-2 amd64 minimalistic service to synchronize local time with NTP servers root@ip-172-31-15-135:~# reboot …
The user admin is used for the initial login. This user has already been stored in the file /etc/sudoers.d/90-cloud-init-users by cloud-init and can therefore execute any sudo commands without being prompted for a password.
sudo cat /etc/sudoers.d/90-cloud-init-users # Created by cloud-init v. 22.4.2 on Thu, 27 Jun 2024 09:22:48 +0000 # User rules for admin admin ALL=(ALL) NOPASSWD:ALL
Analogous to sudo, we now want to enable run0 for the user admin.
Without further configuration, the user admin receives a login prompt asking for the root password. This is the default behavior of PolKit.
admin@ip-172-31-15-135:~$ run0 ==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ==== Authentication is required to manage system services or other units. Authenticating as: Debian (admin) Password: Since this does not correspond to the behavior we want, we have to help a little in the form of a PolKit rule. Additional PolKit rules are stored under /etc/polkit-1/rules.d/.
root@ip-172-31-15-135:~# cat <
/etc/polkit-1/rules.d/99-run0.rules
polkit.addRule(function(action, subject) {
if (action.id = "org.freedesktop.systemd1.manage-units") {
if (subject.user === "admin") {
return polkit.Result.YES;
}
}
});
> EOF
The rule used is structured as follows: First, it is checked whether the action listed is org.freedesktop.systemd1.manage-units. If this is the case, it is checked whether the executing user is the user
Alternatively, it could also be checked whether the executing user belongs to a specific group, such as admin or sudo (if (subject.isInGroup("admin")). It would also be conceivable to ask the user for their own password instead of the root password.
The new rule is automatically read in by PolKit and can be used immediately. Via admin can now execute run0 analogously to our initial sudo configuration.
Process Structure
The following listing shows the difference in the call stack between sudo and run0 While in the case of sudo, separate child processes are started, run0 starts a new process via systemd-run.
root@ip-172-31-15-135:~# sudo su - root@ip-172-31-15-135:~# ps fo tty,ruser,ppid,pid,sess,cmd TT RUSER PPID PID SESS CMD pts/2 admin 1484 1514 1484 sudo su - pts/0 admin 1514 1515 1515 \_ sudo su - pts/0 root 1515 1516 1515 \_ su - pts/0 root 1516 1517 1515 \_ -bash pts/0 root 1517 1522 1515 \_ ps fo tty,ruser,ppid,pid,sess,cmd
admin@ip-172-31-15-135:~$ run0 root@ip-172-31-15-135:/home/admin# ps fo tty,ruser,ppid,pid,sess,cmd TT RUSER PPID PID SESS CMD pts/0 root 1 1562 1562 -/bin/bash pts/0 root 1562 1567 1562 \_ ps fo tty,ruser,ppid,pid,sess,cmd
Conclusion and Note
As the example above has shown, run0 can generally be used as a simple sudo alternative and offers some security-relevant advantages. If run0 prevails over sudo, this will not happen within the next year. Some distributions simply lack a sufficiently up-to-date systemd version. In addition, the configuration of PolKit is not one of the daily tasks for some admins and know-how must first be built up here in order to transfer any existing sudo “constructs”.
In addition, a decisive advantage of run0 should not be ignored: By default, it colors the background red! 😉

If you had the choice, would you rather take Salsa or Guacamole? Let me explain, why you should choose Guacamole over Salsa.
In this blog article, we want to take a look at one of the smaller Apache projects out there called Apache Guacamole. Apache Guacamole allows administrators to run a web based client tool for accessing remote applications and servers. This can include remote desktop systems, applications or terminal sessions. Users can simply access them by using their web browsers. No special client or other tools are required. From there, they can login and access all pre-configured remote connections that have been specified by an administrator.
Thereby, Guacamole supports a wide variety of protocols like VNC, RDP, and SSH. This way, users can basically access anything from remote terminal sessions to full fledged Graphical User Interfaces provided by operation systems like Debian, Ubuntu, Windows and many more.
Convert every window application to a web application
If we spin this idea further, technically every window application that isn’t designed to run as an web application can be transformed to a web application by using Apache Guacamole. We helped a customer to bring its legacy application to Kubernetes, so that other users could use their web browsers to run it. Sure, implementing the application from ground up, so that it follows the Cloud Native principles, is the preferred solution. As always though, efforts, experience and costs may exceed the available time and budget and in that cases, Apache Guacamole can provide a relatively easy way for realizing such projects.
In this blog article, I want to show you, how easy it is to run a legacy window application as a web app on Kubernetes. For this, we will use a Kubernetes cluster created by kind and create a Kubernetes Deployment to make kate – a KDE based text editor – our own web application. It’s just an example, so there might be better application to transform but this one should be fine to show you the concepts behind Apache Guacamole.
So, without further ado, let’s create our kate web application.
Preparation of Kubernetes
Before we can start, we must make sure that we have a Kubernetes cluster, that we can test on. If you already have a cluster, simply skip this section. If not, let’s spin one up by using kind.
kind is a lightweight implementation of Kubernetes that can be run on every machine. It’s written in Go and can be installed like this:
# For AMD64 / x86_64
[ $(uname -m) = x86_64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.22.0/kind-linux-amd64
# For ARM64
[ $(uname -m) = aarch64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.22.0/kind-linux-arm64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind
Next, we need to install some dependencies for our cluster. This includes for example docker and kubectl.
$ sudo apt install docker.io kubernetes-client
By creating our Kubernetes Cluster with kind, we need docker because the Kubernetes cluster is running within Docker containers on your host machine. Installing kubectl allows us to access the Kubernetes after creating it.
Once we installed those packages, we can start to create our cluster now. First, we must define a cluster configuration. It defines which ports are accessible from our host machine, so that we can access our Guacamole application. Remember, the cluster itself is operated within Docker containers, so we must ensure that we can access it from our machine. For this, we define the following configuration which we save in a file called cluster.yaml:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
listenAddress: "127.0.0.1"
protocol: TCP
Hereby, we basically map the container’s port 30000 to our local machine’s port 30000, so that we can easily access it later on. Keep this in mind because it will be the port that we will use with our web browser to access our kate instance.
Ultimately, this configuration is consumed by kind . With it, you can also adjust multiple other parameters of your cluster besides of just modifying the port configuration which are not mentioned here. It’s worth to take a look kate’s documentation for this.
As soon as you saved the configuration to cluster.yaml, we can now start to create our cluster:
$ sudo kind create cluster --name guacamole --config cluster.yaml
Creating cluster "guacamole" ...
✓ Ensuring node image (kindest/node:v1.29.2) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-guacamole"
You can now use your cluster with:
kubectl cluster-info --context kind-guacamole
Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community 🙂
Since we don’t want to run everything in root context, let’s export the kubeconfig, so that we can use it with kubectl by using our unpriviledged user:
$ sudo kind export kubeconfig \
--name guacamole \
--kubeconfig $PWD/config
$ export KUBECONFIG=$PWD/config
$ sudo chown $(logname): $KUBECONFIG
By doing so, we are ready and can access our Kubernetes cluster using kubectl now. This is our baseline to start migrating our application.
Creation of the Guacamole Deployment
In order to run our application on Kubernetes, we need some sort of workload resource. Typically, you could create a Pod, Deployment, Statefulset or Daemonset to run workloads on a cluster.
Let’s create the Kubernetes Deployment for our own application. The example shown below shows the deployment’s general structure. Each container definition will have their dedicated examples afterwards to explain them in more detail.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web-based-kate
name: web-based-kate
spec:
replicas: 1
selector:
matchLabels:
app: web-based-kate
template:
metadata:
labels:
app: web-based-kate
spec:
containers:
# The guacamole server component that each
# user will connect to via their browser
- name: guacamole-server
image: docker.io/guacamole/guacamole:1.5.4
...
# The daemon that opens the connection to the
# remote entity
- name: guacamole-guacd
image: docker.io/guacamole/guacd:1.5.4
...
# Our own self written application that we
# want to make accessible via the web.
- name: web-based-kate
image: registry.example.com/own-app/web-based-kate:0.0.1
...
volumes:
- name: guacamole-config
secret:
secretName: guacamole-config
- name: guacamole-server
emptyDir: {}
- name: web-based-kate-home
emptyDir: {}
- name: web-based-kate-tmp
emptyDir: {}
As you can see, we need three containers and some volumes for our application. The first two containers are dedicated to Apache Guacamole itself. First, it’s the server component which is the external endpoint for clients to access our web application. It serves the web server as well as the user management and configuration to run Apache Guacamole.
Next to this, there is the guacd daemon. This is the core component of Guacamole which creates the remote connections to the application based on the configuration done to the server. This daemon forwards the remote connection to the clients by making it accessible to the Guacamole server which then forwards the connection to the end user.
Finally, we have our own application. It will offer a connection endpoint to the guacd daemon using one of Guacamole’s supported protocols and provide the Graphical User Interface (GUI).
Guacamole Server
Now, let’s deep dive into each container specification. We are starting with the Guacamole server instance. This one handles the session and user management and contains the configuration which defines what remote connections are available and what are not.
- name: guacamole-server
image: docker.io/guacamole/guacamole:1.5.4
env:
- name: GUACD_HOSTNAME
value: "localhost"
- name: GUACD_PORT
value: "4822"
- name: GUACAMOLE_HOME
value: "/data/guacamole/settings"
- name: HOME
value: "/data/guacamole"
- name: WEBAPP_CONTEXT
value: ROOT
volumeMounts:
- name: guacamole-config
mountPath: /data/guacamole/settings
- name: guacamole-server
mountPath: /data/guacamole
ports:
- name: http
containerPort: 8080
securityContext:
allowPrivilegeEscalation: false
privileged: false
readOnlyRootFilesystem: true
capabilities:
drop: ["all"]
resources:
limits:
cpu: "250m"
memory: "256Mi"
requests:
cpu: "250m"
memory: "256Mi"
Since it needs to connect to the guacd daemon, we have to provide the connection information for guacd by passing them into the container using environment variables like GUACD_HOSTNAME or GUACD_PORT. In addition, Guacamole would usually be accessible via http://<your domain>/guacamole.
This behavior however can be adjusted by modifying the WEBAPP_CONTEXT environment variable. In our case for example, we don’t want a user to type in /guacamole to access it but simply using it like this http://<your domain>/
Guacamole Guacd
Then, there is the guacd daemon.
- name: guacamole-guacd
image: docker.io/guacamole/guacd:1.5.4
args:
- /bin/sh
- -c
- /opt/guacamole/sbin/guacd -b 127.0.0.1 -L $GUACD_LOG_LEVEL -f
securityContext:
allowPrivilegeEscalation: true
privileged: false
readOnlyRootFileSystem: true
capabilities:
drop: ["all"]
resources:
limits:
cpu: "250m"
memory: "512Mi"
requests:
cpu: "250m"
memory: "512Mi"
It’s worth mentioning that you should modify the arguments used to start the guacd container. In the example above, we want guacd to only listen to localhost for security reasons. All containers within the same pod share the same network namespace. As a a result, they can access each other via localhost. This said, there is no need to make this service accessible to over services running outside of this pod, so we can limit it to localhost only. To achieve this, you would need to set the -b 127.0.0.1 parameter which sets the corresponding listen address. Since you need to overwrite the whole command, don’t forget to also specify the -L and -f parameter. The first parameter sets the log level and the second one set the process in the foreground.
Web Based Kate
To finish everything off, we have the kate application which we want to transform to a web application.
- name: web-based-kate
image: registry.example.com/own-app/web-based-kate:0.0.1
env:
- name: VNC_SERVER_PORT
value: "5900"
- name: VNC_RESOLUTION_WIDTH
value: "1280"
- name: VNC_RESOLUTION_HEIGHT
value: "720"
securityContext:
allowPrivilegeEscalation: true
privileged: false
readOnlyRootFileSystem: true
capabilities:
drop: ["all"]
volumeMounts:
- name: web-based-kate-home
mountPath: /home/kate
- name: web-based-kate-tmp
mountPath: /tmp
Configuration of our Guacamole setup
After having the deployment in place, we need to prepare the configuration for our Guacamole setup. In order to know, what users exist and which connections should be offered, we need to provide a mapping configuration to Guacamole.
In this example, a simple user mapping is shown for demonstration purposes. It uses a static mapping defined in a XML file that is handed over to the Guacamole server. Typically, you would use other authentication methods instead like a database or LDAP.
This said however, let’s continue with our static one. For this, we simply define a Kubernetes Secret which is mounted into the Guacamole server. Hereby, it defines two configuration files. One is the so called guacamole.properties. This is Guacamole’s main configuration file. Next to this, we also define the user-mapping.xml which contains all available users and their connections.
apiVersion: v1
kind: Secret
metadata:
name: guacamole-config
stringData:
guacamole.properties: |
enable-environment-properties: true
user-mapping.xml: |
<user-mapping>
<authorize username="admin" password="PASSWORD" encoding="sha256">
<connection name="web-based-kate">
<protocol>vnc</protocol>
<param name="hostname">localhost</param>
<param name="port">5900</param>
</connection>
</authorize>
</user-mapping>
As you can see, we only defined on specific user called admin which can use a connection called web-based-kate. In order to access the kate instance, Guacamole would use VNC as the configured protocol. To make this happen, our web application must offer a VNC Server port on the other side, so that the guacd daemon can then access it to forward the remote session to clients. Keep in mind that you need to replace the string PASSWORD to a proper sha256 sum which contains the password. The sha256 sum could look like this for example:
$ echo -n "test" | sha256sum
9f86d081884c7d659a2feaa0c55ad015a3bf4f1b2b0b822cd15d6c15b0f00a08 -
Next, the hostname parameter is referencing the corresponding VNC server of our kate container. Since we are starting our container alongside with our Guacamole containers within the same pod, the Guacamole Server as well as the guacd daemon can access this application via localhost. There is no need to set up a Kubernetes Service in front of it since only guacd will access the VNC server and forward the remote session via HTTP to clients accessing Guacamole via their web browsers. Finally, we also need to specify the VNC server port which is typically 5900 but this could be adjusted if needed.
The corresponding guacamole.properties is quite short. By enabling the enabling-environment-properties configuration parameter, we make sure that every Guacamole configuration parameter can also be set via environment variables. This way, we don’t need to modify this configuration file each and every time when we want to adjust the configuration but we only need to provide updated environment variables to the Guacamole server container.
Make Guacamole accessible
Last but not least, we must make the Guacamole server accessible for clients. Although each provided service can access each other via localhost, the same does not apply to clients trying to access Guacamole. Therefore, we must make Guacamole’s server port 8080 available to the outside world. This can be achieved by creating a Kubernetes Service of type NodePort. This service is forwarding each request from a local node port to the corresponding container that is offering the configured target port. In our case, this would be the Guacamole server container which is offering port 8080.
apiVersion: v1
kind: Service
metadata:
name: web-based-kate
spec:
type: NodePort
selector:
app: web-based-kate
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
nodePort: 30000
This specific port is then mapped to the Node’s 30000 port for which we also configured the kind cluster in such a way that it forwards its node port 30000 to the host system’s port 30000. This port is the one that we would need to use to access Guacamole with our web browsers.
Prepartion of the Application container
Before we can start to deploy our application, we need to prepare our kate container. For this, we simply create a Debian container that is running kate. Keep in mind that you would typically use lightweight base images like alpine to run applications like this. For this demonstration however, we use the Debian images since it is easier to spin it up but in general you only need a small friction of the functionality that is provided by this base image. Moreover – from an security point of view – you want to keep your images small to minimize the attack surface and make sure it is easier to maintain. For now however, we will continue with the Debian image.
In the example below, you can see a Dockerfile for the kate container.
FROM debian:12
# Install all required packages
RUN apt update && \
apt install -y x11vnc xvfb kate
# Add user for kate
RUN adduser kate --system --home /home/kate -uid 999
# Copy our entrypoint in the container
COPY entrypoint.sh /opt
USER 999
ENTRYPOINT [ "/opt/entrypoint.sh" ]
Here you see that we create a dedicated user called kate (User ID 999) for which we also create a home directory. This home directory is used for all files that kate is creating during runtime. Since we set the readOnlyRootFilesystem to true, we must make sure that we mount some sort of writable volume (e.g EmptyDir) to kate’s home directory. Otherwise, kate wouldn’t be able to write any runtime data then.
Moreover, we have to install the following three packages:
- x11vnc
- xvfb
- kate
These are the only packages we need for our container. In addition, we also need to create an entrypoint script to start the application and prepare the container accordingly. This entrypoint script creates the configuration for kate, starts it in a virtual display by using xvfb-run and provides this virtual display to end users by using the VNC server via x11vnc. In the meantime, xdrrinfo is used to check if the virtual display came up successfully after starting kate. If it takes to long, the entrypoint script will fail by returning the exit code 1.
By doing this, we ensure that the container is not stuck in an infinite loop during a failure and let Kubernetes restart the container whenever it couldn’t start the application successfully. Furthermore, it is important to check if the virtual display came up prior of handing it over to the VNC server because the VNC server would crash if the virtual display is not up and running since it needs something to share. On the other hand though, our container will be killed whenever kate is terminated because it would also terminate the virtual display and in the end it would then also terminate the VNC server which let’s the container exit, too. This way, we don’t need take care of it by our own.
#!/bin/bash
set -e
# If no resolution is provided
if [ -z $VNC_RESOLUTION_WIDTH ]; then
VNC_RESOLUTION_WIDTH=1920
fi
if [ -z $VNC_RESOLUTION_HEIGHT ]; then
VNC_RESOLUTION_HEIGHT=1080
fi
# If no server port is provided
if [ -z $VNC_SERVER_PORT ]; then
VNC_SERVER_PORT=5900
fi
# Prepare configuration for kate
mkdir -p $HOME/.local/share/kate
echo "[MainWindow0]
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: Height=$VNC_RESOLUTION_HEIGHT
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: Width=$VNC_RESOLUTION_WIDTH
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: XPosition=0
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: YPosition=0
Active ViewSpace=0
Kate-MDI-Sidebar-Visible=false" > $HOME/.local/share/kate/anonymous.katesession
# We need to define an XAuthority file
export XAUTHORITY=$HOME/.Xauthority
# Define execution command
APPLICATION_CMD="kate"
# Let's start our application in a virtual display
xvfb-run \
-n 99 \
-s ':99 -screen 0 '$VNC_RESOLUTION_WIDTH'x'$VNC_RESOLUTION_HEIGHT'x16' \
-f $XAUTHORITY \
$APPLICATION_CMD &
# Let's wait until the virtual display is initalize before
# we proceed. But don't wait infinitely.
TIMEOUT=10
while ! (xdriinfo -display :99 nscreens); do
sleep 1
let TIMEOUT-=1
done
# Now, let's make the virtual display accessible by
# exposing it via the VNC Server that is listening on
# localhost and the specified port (e.g. 5900)
x11vnc \
-display :99 \
-nopw \
-localhost \
-rfbport $VNC_SERVER_PORT \
-forever
After preparing those files, we can now create our image and import it to our Kubernetes cluster by using the following commands:
# Do not forget to give your entrypoint script
# the proper permissions do be executed
$ chmod +x entrypoint.sh
# Next, build the image and import it into kind,
# so that it can be used from within the clusters.
$ sudo docker build -t registry.example.com/own-app/web-based-kate:0.0.1 .
$ sudo kind load -n guacamole docker-image registry.example.com/own-app/web-based-kate:0.0.1
The image will be imported to kind, so that every workload resource operated in our kind cluster can access it. If you use some other Kubernetes cluster, you would need to upload this to a registry that your cluster can pull images from.
Finally, we can also apply our previously created Kubernetes manifests to the cluster. Let’s say we saved everything to one file called kuberentes.yaml. Then, you can simply apply it like this:
$ kubectl apply -f kubernetes.yaml
deployment.apps/web-based-kate configured
secret/guacamole-config configured
service/web-based-kate unchanged
This way, a Kubernetes Deployment, Secret and Service is created which ultimately creates a Kubernetes Pod which we can access afterwards.
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
web-based-kate-7894778fb6-qwp4z 3/3 Running 0 10m
Verification of our Deployment
Now, it’s money time! After preparing everything, we should be able to access our web based kate application by using our web browser. As mentioned earlier, we configured kind in such a way that we can access our application by using our local port 30000. Every request to this port is forwarded to the kind control plane node from where it is picked up by the Kubernetes Service of type NodePort. This one is then forwarding all requests to our designated Guacamole server container which is offering the web server for accessing remote application’s via Guacamole.
If everything works out, you should be able to see the the following login screen:
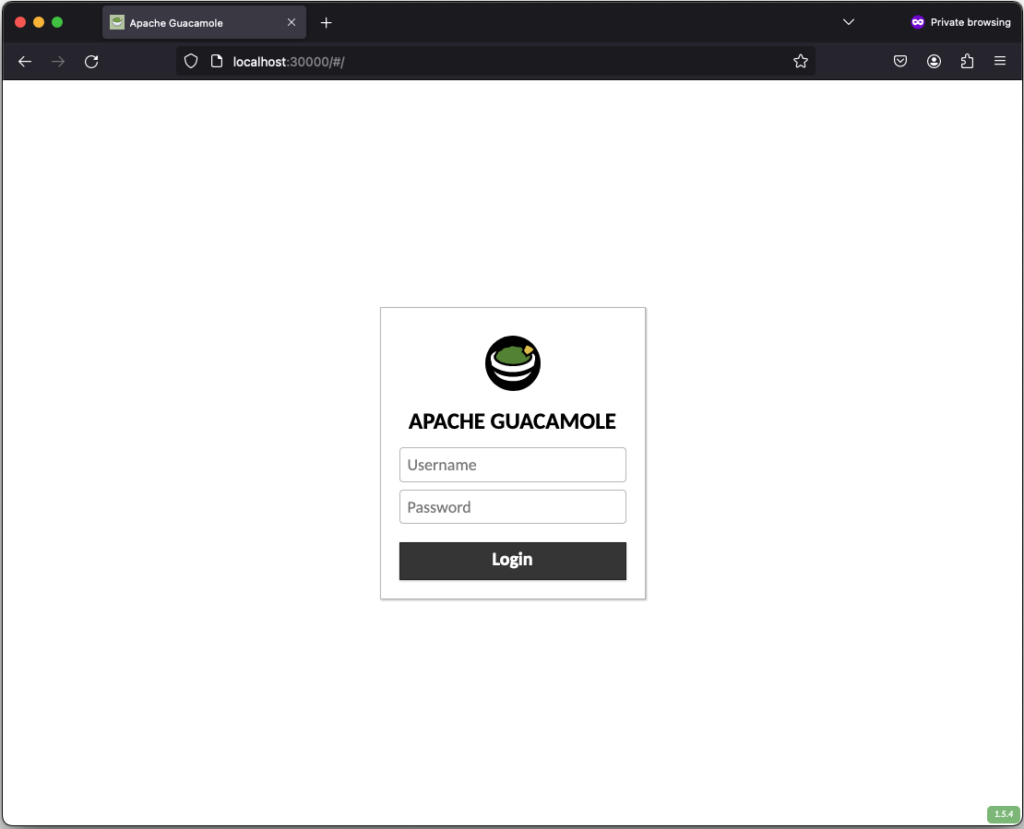
After successfully login in, the remote connection is established and you should be able to see the welcome screen from kate:
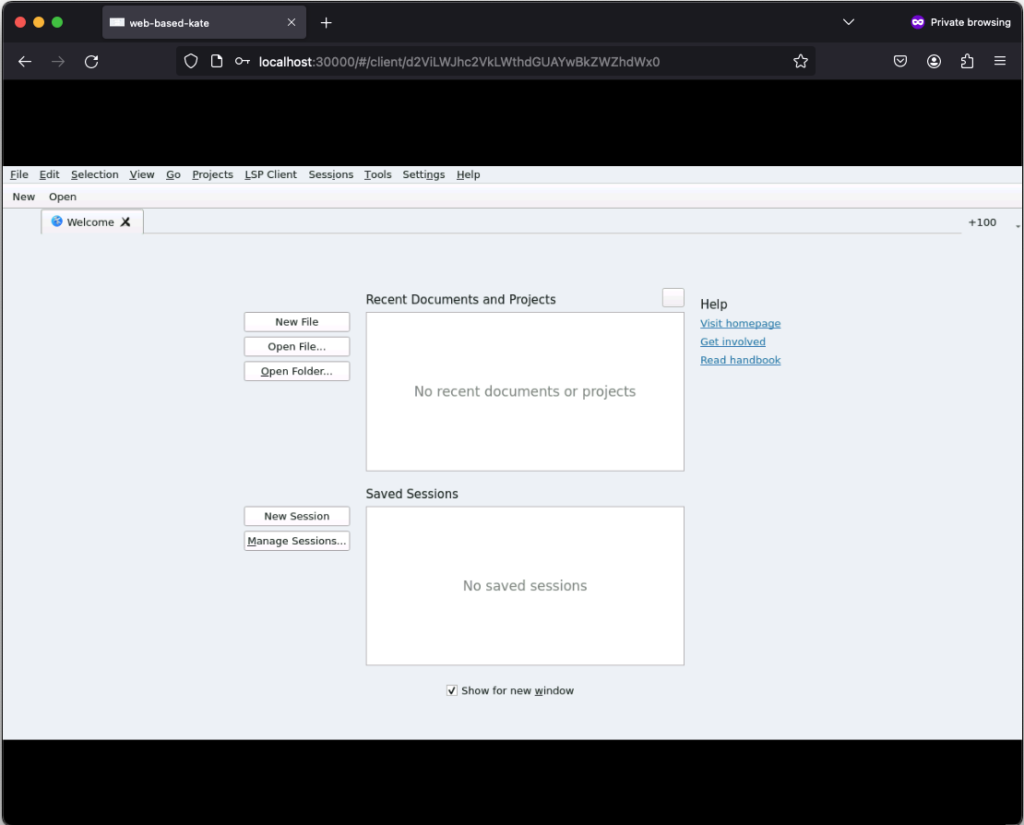
If you click on New, you can create a new text file:
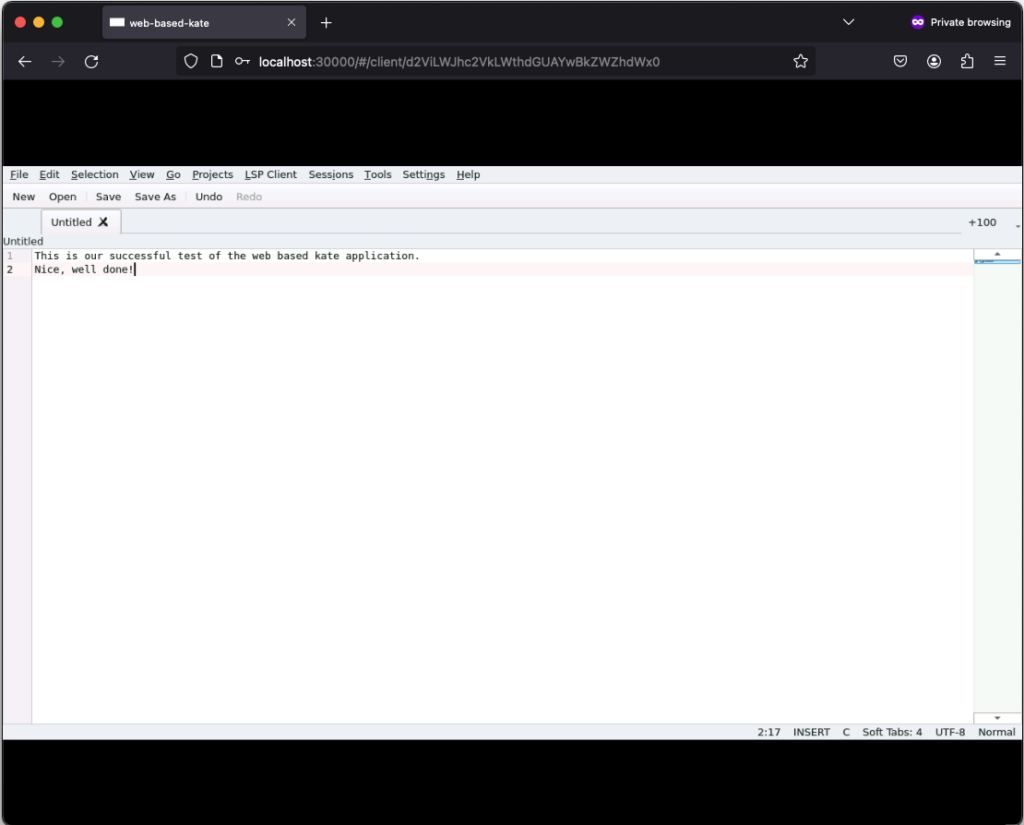
Those text files can even be saved but keep in mind that they will only exist as long as our Kubernetes Pod exists. Once it gets deleted, the corresponding EmptyDir, that we mounted into our kate container, gets deleted as well and all files in it are lost. Moreover, the container is set to read-only meaning that a user can only write files to the volumes (e.g. EmptyDir) that we mounted to our container.
Conclusion
After seeing that it’s relatively easy to convert every application to a web based one by using Apache Guacamole, there is only one major question left…
What do you prefer the most. Salsa or Guacamole?
This years All Systems Go! took place on 2023-09-13 and 2023-09-14 at the nice location of Neue Mälzerei in Berlin, Germany. One Debian Developer and employee of NetApp had the opportunity to attend this conference: Bastian Blank.
All Systems Go! focuses on low-level user-space for Linux systems. Everything that is above the kernel, but is so fundamental that systems won’t work without.
A lot of talks happened, ranging from how to use TPM with Linux for measured boot, how to overcome another Y2038 problem, up to just how to actually boot fast. Videos for all talks are kindly provided by the nice people of the C3VOC.
DebConf23 https://debconf23.debconf.org/ took place from 2023-09-10 to –17 in Kochi, India.
Four employees (three Debian developers) from NetApp had the opportunity to participate in the annual event, which is the most important conference in the Debian world: Christoph Senkel, Andrew Lee, Michael Banck and Noël Köthe.




DebCamp
What is DebCamp? DebCamp usually takes place a week before DebConf begins. For participants, DebCamp is a hacking session that takes place just before DebConf. It’s a week dedicated to Debian contributors focusing on their Debian-related projects, tasks, or problems without interruptions.
DebCamps are largely self-organized since it’s a time for people to work. Some prefer to work individually, while others participate in or organize sprints. Both approaches are encouraged, although it’s recommended to plan your DebCamp week in advance.
During this DebCamp, there are the following public sprints:
- Debian Boot Camp: An introduction for newcomers on how to contribute to Debian more deeply.
- GPG keys 101: Get your keys ready for DebConf’s key signing party: An introduction to PGP/GPG keys and the web of trust, primarily targeting those new to Debian who don’t have a GPG key yet.
In addition to the organizational part, our colleague Andrew also attended and arranged private sprints during DebCamp:
- Debian Installer hacking: Debian installer is a complex project with multiple components. We had an on-site d-i hacker, Alper Nebi Yasak, who guided us in addressing issues specific to zh_TW locale users in the Debian installer.
- LXQt/LXDE hacking session: LXQt and LXDE are lightweight desktop environments for Linux users. Our colleague Andrew Lee leads the LXQt team in Debian and also provided assistance to the LXDE team in the absence of their original team leader from Ukraine.
It also allows the DebConf committee to work together with the local team to prepare additional details for the conference. During DebCamp, the organization team typically handles the following tasks:
- Setting up the Frontdesk: This involves providing conference badges (with maps and additional information) and distributing SWAG such as food vouchers, conference t-shirts, and sponsor gifts.
- Setting up the network: This includes configuring the network in conference rooms, hack labs, and video team equipment for live streaming during the event.
- Accommodation arrangements: Assigning rooms for participants to check in to on-site accommodations.
- Food arrangements: Catering to various dietary requirements, including regular, vegetarian, vegan, halal, gluten-free (regular, vegetarian, vegan), and accommodating special religious and allergy-related needs.
- Setting up a conference bar: Providing a relaxed environment for participants to socialize and get to know each other.
- Writing daily announcements: Keeping participants informed about ongoing activities.
- Organizing day trip options.
- Arranging parties.
Conference talks
The conference itself started on Sunday 10. September with an opening, some organizational stuff, GPG keysigning information (the fingerprint was printed on the badge) and a big welcome to everyone onsite and in the world.
Most talks of DebConf were live streamed and are available in the video archive. The topics were broad from very technical (e.g., “What’s new in the Linux kernel”) over organizational (e.g., “DebConf committee”) to social (e.g., “Adulting”).
Schedule: https://debconf23.debconf.org/schedule/
Videos: https://meetings-archive.debian.net/pub/debian-meetings/2023/DebConf23/
Thanks a lot, to the voluntarily organized video team for this video transmission coverage.

Lightning Talks
On the last day of DebConf, the traditional lightning talks were held. One talk in particular was noticed, the presentation of extrepo by Wouter Verhelst. At NetApp, we use bookworm-based Debian ThinkPad’s. However, in a corporate environment, non-packaged software needs to be used from time to time, and extrepo is a very elegant way to solve this problem by providing, maintaining and keeping UpToDate a list of 3rd-party APT repositories like Slack or Docker Desktop.
Sadya
On Tuesday, an incredibly special lunch was offered at DebConf: a traditional Kerala vegetarian banquet (Sadya in Maralayam), which is served on a banana leaf and eaten by hand. It was quite unusual for the European part of the attendees at first, but a wonderful experience once one got into it.

Daytrip
On Wednesday, the Daytrip happened and everybody could choose out of five different trips: https://wiki.debian.org/DebConf/23/DayTrip
The houseboat trip was a bus tour to Alappuzha about 60 km away from the conference venue. It was interesting to see (and hear) the typical bus, car, motorbike and Tuktuk road traffic in action. During the boat trip the participants socialized and visited the local landscape outside the city.

Unfortunately, we had an accident at one of the daytrip options. Abraham a local Indian participant drowned while swimming.
https://debconf23.debconf.org/news/2023-09-14-mourning-abraham/
It was a big shock for everybody and all events including the traditional formal dinner were cancelled for Thursday. The funeral with the family was on Friday morning and DebConf people had the opportunity with organized buses to participate and say goodbye.
NetApp internal dinner on Friday
The NetApp team at DebConf wanted to take the chance to go to a local restaurant (“were the locals go eating”) and enjoyed very tasty food.


DebConf24
Sunday was the last day of DebConf23. As usual, the upcoming DebConf24 was very briefly presented and there was a call for bids for DebConf25.

Maybe see you in Haifa, Israel next year.
https://www.debconf.org/goals.shtml
Authors: Andrew Lee, Michael Banck and Noël Köthe
As described in the previous post, access control on Unix-like systems is traditionally based on the principle of Discretionary Access Control (DAC). Applications and services run under a specific user and group ID and are granted the corresponding access rights to files and folders.
AppArmor implements a Mandatory Access Control for Linux, based on the Linux Security Modules: an access control strategy that allows specific rights to be granted or denied to individual programs. This security layer exists in addition to the traditional DAC.
Since Debian 10 buster, AppArmor has been included and activated in the kernel by default. The packages apparmor and apparmor-utils provide tools for creating and maintaining AppArmor profiles.
Included Profiles
The two packages mentioned do not come with ready-made profiles, but only the Abstractions mentioned in the previous article: collections of rules that can be included in multiple profiles.
Some programs include their profiles in their own packages, while others contain profiles if corresponding modules are installed later – for example, mod_apparmor for the Apache web server.
The packages apparmor-profiles and apparmor-profiles-extra contain AppArmor profiles that can be found after installation in the directories /etc/apparmor.d (for tested profiles) and /usr/share/apparmor/extra-profiles (for experimental profiles), respectively. These profiles can be used as a basis for custom profiles.
Create Profiles Yourself
While at least experimental profiles are available for most common server services, such as the Apache web server, nothing can be found for the nginx web server. However, this is not a major issue, as a new AppArmor profile can be quickly created with the help of apparmor-utils.
Nginx Example
The following assumes a simple base installation of nginx that only serves HTML files under /var/www/html via HTTP. The focus here is primarily on the general approach, so repetitive steps will be skipped.
The described approach can be applied to any other program. To find out about the paths and files used by a program, dpkg can be used with the -L option, which lists all paths of a package. It should be noted that several packages may need to be queried for this; for nginx, the package of the same name provides hardly any useful information; this is only obtained with the nginx-common package:
# dpkg -L nginx-common
For the following steps, it is recommended to have two terminals open with root privileges.
Before the web server process can be observed for profile creation, all its running processes must be terminated:
# systemctl stop nginx
Once all processes are stopped, aa-genprof is called in the second terminal with the path of the web server’s program file:
# aa-genprof /usr/sbin/nginx
Some information about the current call of aa-genprof appears, including the hint Profiling: /usr/sbin/nginx, followed by Please start the application to be profiled in another window and exercise its functionality now.
To comply with this, the web server process is restarted in the first terminal window:
# systemctl start nginx
Before calling the S option in the second window to search the log files for AppArmor events, the web server should run for a few moments, and it should also be accessed from a browser so that as many typical activities of the process as possible are recorded.
Once this is done, the log files can be searched for events by pressing the S key:
[(S)can system log for AppArmor events] / (F)inish Reading log entries from /var/log/syslog. Updating AppArmor profiles in /etc/apparmor.d. Complain-mode changes:
If an event is found, the affected profile and the action recorded by AppArmor are displayed:
Profile: /usr/sbin/nginx Capability: dac_override Severity: 9 [1 - capability dac_override,] (A)llow / [(D)eny] / (I)gnore / Audi(t) / Abo(r)t / (F)inish
Here, the program /usr/sbin/nginx requests the Capability dac_override, which was already described in the last article. It is indispensable for the operation of the web server and is allowed by pressing A. Alternatively, the request can be denied with D or ignored with I. With the Audit option, this request would continue to be recorded in the log file during operation.
Profile: /usr/sbin/nginx Capability: net_bind_service Severity: 8 [1 - #include] 2 - capability net_bind_service,
The next event shows that the process requests the Capability net_bind_service, which is needed to open a port with a port number less than 1024.
Unlike the first query, there are two ways to allow access in the future: the first option involves integrating Abstractions for NIS, the Network Information Service. In this Abstraction, which can be found under /etc/apparmor.d/abstractions/nis, in addition to a rule that allows access to rule sets for NIS, the Capability net_bind_service is also listed.
However, since the HTTP server does not include NIS functionality, it is sufficient to only allow the Capability. By pressing 2 and A, this is adopted into the profile.
The same applies to the Abstractions proposed in the following steps for dovecot and postfix: here it is sufficient to only allow the Capabilities setgid and setuid.
Sometimes the designation of the Abstractions can be somewhat misleading: for example, the Abstraction nameservice contains, in addition to rules that allow read access to common nameservice files like passwd or hosts, also rules that permit network access. It is therefore always worthwhile to take a look at the respective file under /etc/apparmor.d/abstractions/ to see if including the Abstraction is beneficial.
After the web server process has received all necessary Capabilities, it apparently tries to open its error log file /var/log/nginx/log with write permissions. It is noticeable here that, in addition to the usual Allow, Deny, and Ignore, the options Glob and Glob with Extension have been added.
Profile: /usr/sbin/nginx Path: /var/log/nginx/error.log New Mode: w Severity: 8 [1 - /var/log/nginx/error.log w,] (A)llow / [(D)eny] / (I)gnore / (G)lob / Glob with (E)xtension / (N)ew / Audi(t) / Abo(r)t / (F)inish
Entering E adds another suggestion to the list:
1 - /var/log/nginx/error.log w, [2 - /var/log/nginx/*.log w,]
The filename error.log has been replaced by a wildcard and the extension .log. This rule would grant write permissions to the file /var/log/nginx/error.log as well as, for example, to the file /var/log/nginx/access.log – these are (at least) two rules combined into a single one.
These rules would already be sufficient for this example, but it might also be necessary to allow files that do not have the .log file extension to be written in the /var/log directory. By entering G, another suggestion is added to the list:
1 - /var/log/nginx/error.log w, 2 - /var/log/nginx/*.log w, [3 - /var/log/nginx/* w,]
The filename has now been replaced by a single wildcard, meaning the process would be allowed to open any files in /var/log/nginx with write permissions.
As already mentioned, the proposed rules only grant write permissions, but no read permissions, even if the file’s access rights would allow more. However, for a web server’s log file, write permissions are entirely sufficient.
Subsequently, nginx requests read access to various configuration files, for example /etc/nginx/nginx.conf. This file is located in the nginx web server’s configuration directory, which contains other files that should also be readable.
Profile: /usr/sbin/nginx Path: /etc/nginx/nginx.conf New Mode: owner r Severity: unknown [1 - owner /etc/nginx/nginx.conf r,]
Here too, with G, the rule can be extended to all files in the /etc/nginx directory.
1 - owner /etc/nginx/nginx.conf r, [2 - owner /etc/nginx/* r,]
The same applies to the subdirectories of the configuration directory; these can be covered by globbing as /etc/nginx/*/.
A special case for globbing is the files contained in those subdirectories:
Profile: /usr/sbin/nginx Path: /etc/nginx/sites-available/default New Mode: owner r Severity: unknown [1 - owner /etc/nginx/sites-available/default r,]
After entering G twice, the wildcard ** is suggested after the wildcard * known from above, which, as described in the previous article, covers all files located in subdirectories (and their subdirectories).
1 - owner /etc/nginx/sites-available/default r, 2 - owner /etc/nginx/sites-available/* r, [3 - owner /etc/nginx/** r,]
The last steps also all contained the attribute owner: this ensures that a rule only applies if the accessing process is also the owner of the file. If the file exists but belongs to someone else, access is denied.
There are still some other paths and files such as /usr/share/nginx/modules-available/, /run/nginx.pid, and /proc/sys/kernel/random/boot_id, which nginx also requires for proper operation. However, the procedure remains unchanged.
Once all events have been processed, the program concludes with the message:
= Changed Local Profiles = The following local profiles were changed. Would you like to save them? [1 - /usr/sbin/nginx] (S)ave Changes / Save Selec(t)ed Profile / [(V)iew Changes] / View Changes b/w (C)lean profiles / Abo(r)t
The options are clear: S saves changes, while V allows them to be viewed as a Diff beforehand. The following listing shows the profile generated in the run above.
include <tunables/global>
profile nginx /usr/sbin/nginx {
include <abstractions/base>
include <abstractions/nameservice>
capability dac_override,
capability dac_read_search,
capability setgid,
capability setuid,
/usr/sbin/nginx mr,
/var/log/nginx/*.log w,
/var/www/html/** r,
owner /etc/nginx/* r,
owner /etc/nginx/** r,
owner /run/nginx.pid rw,
owner /usr/share/GeoIP/*.mmdb r,
owner /usr/share/nginx/modules-available/*.conf r,
owner /var/cache/nginx/** rw,
owner /var/lib/nginx/** rw,
}After saving the changes, aa-genprof returns to its start screen. Here, one could search for events in log files again or exit the program with F.
The program ends with the message:
Setting /usr/sbin/nginx to enforce mode. Reloaded AppArmor profiles in enforce mode.
The profile just created has therefore been loaded and put into enforce mode. This means that the program can only access what is allowed in the profile; all other access attempts are blocked by AppArmor and recorded in the Syslog.
For simple programs, the creation of a profile is thus complete, and AppArmor can perform its work; more complex programs, however, will show previously unknown behavior later on, which would be prevented by the profile created so far. In such cases, it helps to switch the profile to complain mode using aa-complain.
# aa-complain nginx
Accesses that go beyond the known profile are generally allowed in complain mode but are recorded in the Syslog.
Feb 18 15:25:50 web01 kernel: [ 9908.611408] audit: type=1400 audit(1645197950.338:100): apparmor="ALLOWED" operation="open" profile="nginx" name="/srv/www/index.html" pid=4490 comm="nginx" requested_mask="r" denied_mask="r" fsuid=33 ouid=0
In the excerpt from the Syslog above, the webroot directory on host web01 was changed to /srv/www, but the previously created AppArmor profile was not adjusted. Since the profile is now in complain mode, access was still allowed: apparmor="ALLOWED"; in enforce mode, it would say DENIED and access would be denied.
The remaining information clearly shows what happened: the process with process ID (pid) 4190 tried to open the file /srv/www/index.html (name) for reading (requested_mask), which would, however, be forbidden (denied_mask) due to the profile (profile) nginx.
So, if software secured with AppArmor doesn’t work as expected, the first place to look is the Syslog!
After some time, there will be several entries there that should then be incorporated into the AppArmor profile. For this, the program aa-logprof is used: it searches the Syslog for entries and, in the manner of aa-genprof, asks if and how entries should be created in the profile. This process can be repeated as often as necessary.
If no further entries are found in the Syslog, the profile has been sufficiently adjusted and can be switched back to enforce mode with aa-enforce:
# aa-enforce nginx
This completes the basic creation of a simple AppArmor profile, and the nginx processes are controlled and monitored according to the rules defined within it.
We are Happy to Support You
Whether AppArmor, Debian, or PostgreSQL: with over 22+ years of development and service experience in the open-source sector, credativ GmbH can professionally support you with unparalleled and individually configurable support and assist you fully with all questions regarding your open-source infrastructure.
Do you have questions about our article or would you like credativ’s specialists to look at another software of your choice?
Then visit us and contact us via our contact form or write us an email at info@credativ.de.
About Credativ
credativ GmbH is a vendor-independent consulting and service company based in Mönchengladbach.
Fundamentally, access control under Linux is a simple matter:
Files specify their access rights (execute, write, read) separately for their owner, their group, and finally, other users. Every process (whether a user’s shell or a system service) running on the system operates under a user ID and group ID, which are used for access control.
A web server running with the permissions of user www-data and group www-data can thus be granted access to its configuration file in the directory /etc, its log file under /log, and the files to be delivered under /var/www. The web server should not require more access rights for its operation.
Nevertheless, whether due to misconfiguration or a security vulnerability, it could also access and deliver files belonging to other users and groups, as long as these are readable by everyone, as is technically the case, for example, with /etc/passwd. Unfortunately, this cannot be prevented with traditional Discretionary Access Control (DAC), as used in Linux and other Unix-like systems.
However, since December 2003, the Linux kernel has offered a framework with the Linux Security Modules (LSM), which allows for the implementation of Mandatory Access Control (MAC), where rules can precisely specify which resources a process may access. AppArmor implements such a MAC and has been included in the Linux kernel since 2010. While it was originally only used in SuSE and later Ubuntu, it has also been enabled by default in Debian since Buster (2019).
AppArmor
AppArmor checks and monitors, based on a profile, which permissions a program or script has on a system. A profile typically contains the rule set for a single program. For example, it defines how (read, write) files and directories may be accessed, whether a network socket may be created, or whether and to what extent other applications may be executed. All other actions not defined in the profile are denied.
Profile Structure
The following listing (line numbers are not part of the file and serve only for orientation) shows the profile for a simple web server, whose program file is located under /usr/sbin/httpd is located.
By default, AppArmor profiles are located in the directory /etc/apparmor.d and are conventionally named after the path of the program file. The first slash is omitted, and all subsequent slashes are replaced by dots. The web server’s profile is therefore located in the file /etc/apparmor.d/usr.sbin.httpd.
1 include <tunables/global>
2
3 @{WEBROOT}=/var/www/html
4
5 profile httpd /usr/sbin/httpd {
6 include <abstractions/base>
7 include <abstractions/nameservice>
8
9 capability dac_override,
10 capability dac_read_search,
11 capability setgid,
12 capability setuid,
13
14 /usr/sbin/httpd mr,
15
16 /etc/httpd/httpd.conf r,
17 /run/httpd.pid rw,
18
19 @{WEBROOT}/** r,
20
21 /var/log/httpd/*.log w,
22 }Preamble
The instruction include in line 1 inserts the content of other files in place, similar to the C preprocessor directive of the same name. If the filename is enclosed in angle brackets, as here, the specified path refers to the folder /etc/apparmor.d; with quotation marks, the path is relative to the profile file.
Occasionally, though now outdated, the notation #include can still be found. However, since comments in AppArmor profiles begin with a # and the rest of the line is ignored, the old notation leads to a contradiction: a supposedly commented-out #include instruction would indeed be executed! Therefore, to comment out a include instruction, a space after the # is recommended.
The files in the subfolder tunables typically contain variable and alias definitions that are used by multiple profiles and are defined in only one place, according to the Don’t Repeat Yourself principle (DRY).
In line 2, the variable @{WEBROOT} is created with WEBROOT and assigned the value /var/www/html. If other profiles, in addition to the current one, were to define rules for the webroot directory, it could instead be defined in its own file tunables and included in the respective profiles.
Profile Section
The profile section begins in line 5 with the keyword profile. It is followed by the profile name, here httpd, the path to the executable file, /usr/sbin/httpd, and optionally flags that influence the profile’s behavior. The individual rules of the profile then follow, enclosed in curly braces.
As before, in lines 6 and 7, include also inserts the content of the specified file in place. In the subfolder abstractions, according to the DRY principle, there are files with rule sets that appear repeatedly in the same form, as they cover both fundamental and specific functionalities.
For example, in the file base, access to various file systems such as /dev, /proc, and /sys, as well as to runtime libraries or some system-wide configuration files, is regulated. The file
Starting with line 9, rules with the keyword capability grant a program special privileges, known as capabilities. Among these, setuid and setgid are certainly among the more well-known: they allow the program to change its own uid and gid; for example, a web server can start as root, open the privileged port 80, and then drop its root privileges. dac_override and dac_read_search allow bypassing the checking of read, write, and execute permissions. Without this capability, even a program running under uid root would not be able to access files regardless of their attributes, unlike what one is used to from the shell.
From line 14 onwards, there are rules that determine access permissions for paths (i.e., folders and files). The structure is quite simple: first, the path is specified, followed by a space and the abbreviations for the granted permissions.
Aside: Permissions
The following table provides a brief overview of the most common permissions:
| Abbreviation | Meaning | Description |
|---|---|---|
r | read | read access |
w | write | write access |
a | append | appending data |
x | execute | execute |
m | memory map executable | mapping and executing the file’s content in memory |
k | lock | setting a lock |
l | link | creating a link |
Aside: Globbing
Paths can either be fully written out individually or multiple paths can be combined into one path using wildcards. This process, called globbing, is also used by most shells today, so this notation should not cause any difficulties.
| Expression | Description |
|---|---|
/dir/file | refers to exactly one file |
/dir/* | includes all files within /dir/ |
/dir/** | includes all files within /dir/, including subdirectories |
? | represents exactly one character |
{} | Curly braces allow for alternations |
[] | Square brackets can be used for character classes |
Examples:
| Expression | Description |
|---|---|
/dir/??? | thus refers to all files in /dir whose filename is exactly 3 characters long |
/dir/*.{png,jpg} | refers to all image files in /dir whose file extension is png or jpg |
/dir/[abc]* | refers to all files in /dir whose name begins with the letters a, b, or c |
For access to the program file /usr/sbin/httpd, the web server receives the permissions mr in line 14. The abbreviation r stands for read and means that the content of the file may be read; m stands for memory map executable and allows the content of the file to be loaded into memory and executed.
Anyone who dares to look into the file
/etc/apparmor.d/abstractions/basewill see that the permissionmis also necessary for loading libraries, among other things.
During startup, the web server will attempt to read its configuration from the file /etc/httpd.conf. Since the path has r permission for reading, AppArmor will allow this. Subsequently, httpd writes its PID to the file /run/httpd.pid. The abbreviation w naturally stands for write and allows write operations on the path. (Lines 16, 17)
The web server is intended to deliver files below the WEBROOT directory. To avoid having to list all files and subdirectories individually, the wildcard ** can be used. The expression r.
As usual, all access to the web server is logged in the log files access.log and error.log in the directory /var/log/httpd/. These are only written by the web server, so it is sufficient to set only write permission for the path /var/log/httpd/* with w in line 21.
With this, the profile is complete and ready for use. In addition to those shown here, there are a variety of other rule types with which the allowed behavior of a process can be precisely defined.
Further information on profile structure can be found in the man page for apparmor.d and in the Wiki article on the AppArmor Quick Profile Language; a detailed description of all rules can be found in the AppArmor Core Policy Reference.
Creating a Profile
Some applications and packages already come with ready-made AppArmor profiles, while others still need to be adapted to specific circumstances. Still other packages do not come with any profiles at all – these must be created by the administrator themselves.
To create a new AppArmor profile for an application, a very basic profile is usually created first, and AppArmor is instructed to treat it in the so-called complain mode. Here, accesses that are not yet defined in the profile are recorded in the system’s log files.
Based on these log entries, the profile can then be refined after some time, and if no more entries appear in the logs, AppArmor can be instructed to switch the profile to enforce mode, enforce the rules listed therein, and block undefined accesses.
Even though it is easily possible to create and adapt an AppArmor profile manually in a text editor, the package apparmor-utils contains various helper programs that can facilitate the work: for example, aa-genprof helps create a new profile, aa-complain switches it to complain mode, aa-logprof helps search log files and add corresponding new rules to the profile, and aa-enforce finally switches the profile to enforce mode.
In the next article of this series, we will create our own profile for the web server nginx based on the foundations established here.
We are Happy to Support You
Whether AppArmor, Debian, or PostgreSQL: with over 22+ years of development and service experience in the open source sector, credativ GmbH can professionally support you with unparalleled and individually configurable support, fully assisting you with all questions regarding your open source infrastructure.
Do you have questions about our article or would you like credativ’s specialists to take a look at other software of your choice? Then feel free to visit us and contact us via our contact form or send us an email at info@credativ.de.
About Credativ
credativ GmbH is a vendor-independent consulting and service company based in Mönchengladbach. Since the successful merger with Instaclustr in 2021, credativ GmbH has been the European headquarters of the Instaclustr Group.
The Instaclustr Group helps companies realize their own large-scale applications thanks to managed platform solutions for open source technologies such as Apache Cassandra®, Apache Kafka®, Apache Spark™, Redis™, OpenSearch™, Apache ZooKeeper™, PostgreSQL®, and Cadence. Instaclustr combines a complete data infrastructure environment with practical expertise, support, and consulting to ensure continuous performance and optimization. By eliminating infrastructure complexity, companies are enabled to focus their internal development and operational resources on building innovative, customer-centric applications at lower costs. Instaclustr’s clients include some of the largest and most innovative Fortune 500 companies.