Verwaltung von Hardware-Ressourcen in Kubernetes
| Kategorien: | HowTos |
|---|---|
| Tags: | Container Kubernetes |
Wer sich mit Containern und deren Orchestrierung für verteilte, skalierbare und hochverfügbare Anwendungen beschäftigt, wird wohl unweigerlich früher oder später auf Kubernetes stoßen. Es gibt genug Gründe, Container und Kubernetes dem traditionelleren Deployment auf virtuellen Maschinen vorzuziehen. Beispielsweise lassen sich verfügbare Hardware-Ressourcen flexibler an die laufenden Anwendungen verteilen.
Doch durch diese Flexibilität ergeben sich leider auch einige Fallstricke, die man beachten sollte. Aus diesem Grund möchte ich mit diesem Artikel einen Überblick bieten, welche Mittel Kubernetes für die Verwaltung von Hardware-Ressourcen bietet und wie Ihr sie einsetzen könnt.
Test-Setup
Für Demonstrationen werde ich einen Kubernetes-Cluster mit einer Control-Plane-Node und zwei Workern auf Basis von Kubernetes 1.18.6. verwenden Wenn Ihr beim Lesen die Beispiele mit nachvollziehen möchtet, solltet Ihr ebenfalls einen Cluster mit mindestens zwei Worker-Nodes zum Testen verwenden. Ein Cluster mit nur einer Node (wie z.B. mit Minikube) reicht nicht aus, weil damit das verschieben von Pods zwischen Nodes nicht nachvollzogen werden kann.
Solltet ihr gerade keinen Kubernetes-Cluster zum Testen zur Hand haben, empfehle ich kubeadm zu verwenden, um einen Cluster mit mehreren Nodes zu installieren. Die in diesem Artikel verwendeten Beispielwerte gehen dabei von Nodes mit jeweils 4GiB Arbeitsspeicher aus.
Kubernetes‘ Standard-Ressourcenverwaltung
Im späteren Verlauf möchte ich darauf eingehen, welche Stellschrauben Kubernetes im Bezug auf Ressourcenmanagement bietet. Zunächst möchte ich jedoch zeigen, wie Kubernetes die Ressourcen ohne weitere Einstellungen verwaltet und welche Probleme dabei auftreten können. Dazu erzeugen wir zunächst einen Prozess, der eine bestimmtem Menge Speicherplatz benötigt, die von einer Node bereitgestellt werden kann.:
$ kubectl label node knode1 load-target=
$ kubectl apply -f - << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress
spec:
replicas: 1
selector:
matchLabels:
app: stress
template:
metadata:
labels:
app: stress
spec:
containers:
- name: stress
image: alexeiled/stress-ng
args:
- --vm=1
- --vm-bytes=2g
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: load-target
operator: Exists
EOF
deployment.apps/stress createdDer gestartete Container, führt das Tool stress-ng aus. Mit den gegebenen Argumenten startet es einen Prozess, der daraufhin 2GiB Arbeitsspeicher alloziert und darauf schreibt. Mithilfe von Node-Affinities sorgen wir dafür, dass der Pod auf knode1 gestartet wird. Dort können wir die verursachte Last auch mit htop beobachten:
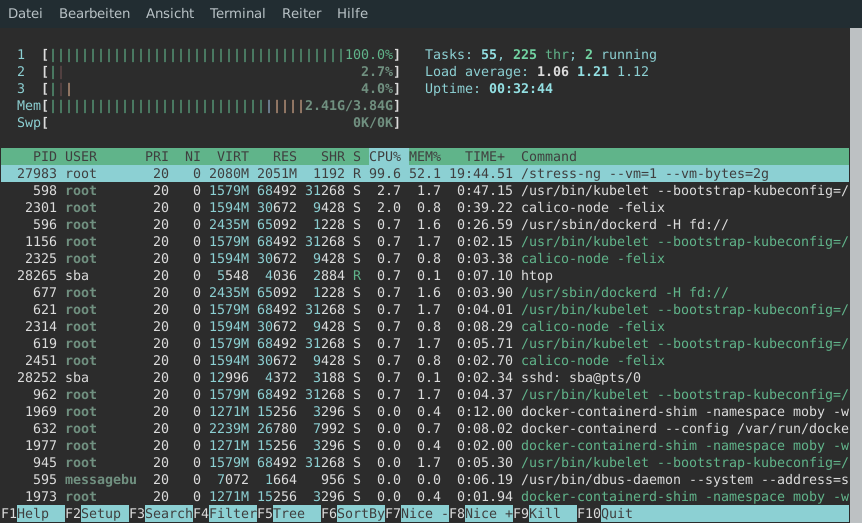
Die Node kann mit der verursachten Last derzeit noch ohne Probleme mithalten. Um zu sehen, was passiert wenn eine Node überlastet wird, müssen wir einen zweiten Pod erzeugen. Dazu erhöhen wir die Anzahl der Replicas des eben erstellten Deployments. Die Platzierung des zweiten Replicas ist dabei hauptsächlich dem Zufall überlassen. Wir wollen allerdings den Worst-Case betrachten, in dem beide Replicas auf der gleichen Node gestartet werden. Das erzwingen wir mithilfe der vorher schon erstellten Node-Affinities:
$ kubectl patch deployment stress -p '{"spec": {"replicas": 2}}'
deployment.apps/stress patchedWenn wir uns nun die Lastsituation auf knode1 erneut anschauen, hat sich die Situation im Gegensatz zu vorher geändert. Der Speicherverbrauch schwankt drastisch und wenn wir mit dmesg | tail in das Kernel-Log schauen, sehen wir wiederholt Nachrichten der folgenden Art:
[ 3248.919030] Out of memory: Killed process 105727 (stress-ng-vm) total-vm:3179200kB, anon-rss:2312000kB, file-rss:0kB, shmem-rss:44kB, UID:0 pgtables:4592kB oom_score_adj:1000 [ 3248.951392] oom_reaper: reaped process 105727 (stress-ng-vm), now anon-rss:0kB, file-rss:0kB, shmem-rss:44kB
Das liegt daran, dass die beiden Pods zusammen mehr Speicher belegen wollen, als auf der Node zur Verfügung steht. Der Kernel versucht Speicher freizugeben, indem er Prozesse tötet (SIGKILL). Für eine laufende Applikation wäre dieser Zustand nicht akzeptabel, weil Prozesse der Applikation im laufenden Betrieb getötet werden, was die Verfügbarkeit und Stabilität der Applikation beeinflusst. Bisher können wir allerdings auch kein anderes Ergebnis erwarten, weil wir per Node-Affinity explizit angegeben haben, dass beide Replicas auf knode1 ausgeführt werden sollen. Wenn wir knode2 ebenfalls für die Ausführung der Replicas freigeben, wäre zu erwarten, dass einer der Pods evicted wird. Damit ist gemeint, dass der Pod von seiner derzeitigen Node entfernt wird um Ressourcen zu sparen. Das erstellte Deployment wäre dann dafür verantwortlich, den Pod auf einer anderen Node neu zu erstellen. Probieren wir das also aus:
$ kubectl label node knode2 load-target= node/knode2 labeled
Überprüfen wir nun, wo die beiden Pods ausgeführt werden:
$ kubectl describe pod -l app=stress | grep '^Node:' Node: knode1/192.168.122.228 Node: knode1/192.168.122.228
Wie wir sehen, werden beide Pods weiterhin auf knode1 ausgeführt. Auch wenn wir die Situation länger beobachten, werden wir feststellen, dass Kubernetes keinen der Pods evicten wird. Stattdessen wird es die darin laufenden Prozesse weiterhin auf der überlasteten Node laufen lassen wird. Warum Kubernetes hier nicht einschreitet und was wir dagegen tun können, behandle ich im nächsten Abschnitt. Doch zunächst entfernen wir noch das erstellte Deployment und das Label von knode2 um den Basisstand für die nächsten Test wiederherzustellen:
$ kubectl label node knode2 load-target- node/knode2 labeled $ kubectl delete deployment stress deployment.apps "stress" deleted
Ressourcenverwaltung im Kubelet
Grundsätzlich sollte Kubernetes in einer solchen Situation reagieren. Wenn ein Kubelet (die Software die für die Ausführung von Pods auf den Nodes zuständig ist) meldet, dass die Ressourcen auf der Node knapp werden, sollte Kubernetes einen oder mehrere Pods von dieser Node „evicten“ und auf einer anderen Node neu starten. Das ist in unserem Test allerdings nicht passiert. Um herauszufinden wieso, schauen wir uns zunächst mit kubectl describe node knode1 die Informationen zu der Node an. Dabei erhalten wir unter Anderem eine Menge Informationen, die für die Ressourcenverwaltung relevant sind:
Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 250m (8%) 0 (0%) memory 0 (0%) 0 (0%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%)
Diese Tabelle sieht erst mal so aus, als ob sie den Ressourcenverbrauch auf der Node anzeigt. Sie zeigt allerdings nur Ressourcen auf der Node, die für bestimmtem Pods reserviert wurden und gibt uns deshalb keinen Aufschluss darüber, wie viele Ressourcen tatsächlich gerade verbraucht werden.
Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- MemoryPressure False Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletReady kubelet is posting ready status. AppArmor enabled
Hier sehen wir, dass das kubelet der Meinung ist, es hätte genug Speicherplatz zur Verfügung. Das ist zwar unerwartet, erklärt aber warum Kubernetes nichts gegen die zu hohe Last unternommen hat. Solange das Kubelet nicht meldet, dass die Ressourcen knapp werden, sieht Kubernetes keinen Grund etwas an der Ressourcenverteilung zu ändern.
Warum das Kubelet keine Speicherknappheit meldet hängt mit dem folgenden Block zusammen:
Capacity: cpu: 3 ephemeral-storage: 20480580Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 4030888Ki pods: 110 Allocatable: cpu: 3 ephemeral-storage: 18874902497 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 3928488Ki pods: 110
Die Capacity zeigt uns an, wie viele Ressourcen eine Node insgesamt zur Verfügung hat. Der angezeigt Wert von memory: 4030888Ki entspricht dabei genau dem auf der Hardware verfügbaren Arbeitsspeicher. In Allocatable steht hingegen der Speicher, den die Node auch gestarteten Pods zur Verfügung stellt. Solange alle gestarteten Pods weniger als diese Menge an Speicher verbrauchen, ist für das Kubelet alles im grünen Bereich.
Dass das Kubelet in unserem Fall keinen Alarm wegen fehlendem Speicher schlägt, liegt daran, dass das Betriebssystem und das Kubelet selbst Speicherplatz verbrauchen, der dann für die Pods nicht zur Verfügung steht. Dadurch ist es für die gestarteten Pods praktisch gar nicht möglich die gesetzte Grenze zu überschreiten. Als Beispiel: Wenn unser Betriebssystem und das Kubelet zusammen ca. 300MiB belegen, bleiben vom verfügbaren Speicher noch ca. 3600MiB übrig. Wenn nun Pods gestartet werden und diese übrigen 3600MiB belegen, ist der physische Speicher voll. Unsere Pods bleiben aber unter dem gesetzen Limit von 3928488KiB (ca. 3836MiB) und unser Kubelet ist der Meinung es wäre genug Speicher vorhanden.
Die in Allocatable gesetzte Grenze ist also zu hoch gesetzt. Um das zu beheben, bietet das Kubelet die Möglichkeit, Speicher für das Betriebssystem und das Kubelet selbst zu reservieren und dadurch die Allocatable-Grenze für Pods zu verringern. Die entsprechenden Optionen dafür müssen in der Konfigurationsdatei des Kubelet gesetzt werden. Wenn ihr euren Cluster mit kubeadm installiert habt, befindet sich die Konfigurationsdatei auf der Node unter /var/lib/kubelet/config.yaml. Auf beiden Nodes müssen dort die folgenden Optionen eingefügt werden:
systemReserved: memory: 256Mi kubeReserved: memory: 256Mi evictionHard: memory.available: 128Mi evictionSoft: memory.available: 256Mi evictionSoftGracePeriod: memory.available: 5m
Damit Teilen wir dem Kubelet mehrere Dinge mit:
systemReservedsagt, dass für das System 256MiB Arbeitsspeicher reserviert werden sollen.kubeReservedsagt, dass für das Kubelet 256MiB Arbeitsspeicher reserviert werden sollen.evictionHardsagt, dass sobald für Pods weniger als 128MiB verbleiben, sofort Pods evicted werden sollen.evictionSoftundevictionSoftGracePeriodsagen, dass wenn länger als 5 Minuten für Pods weniger als 256MiB verfügbar sind Pods evicted werden sollen.
Mit diesen Werten sollte das Kubelet früh genug Alarm schlagen, wenn der Speicher knapp wird, um zu verhindern, dass unsere Node vollständig überlastet wird. Um die Optionen zu übernehmen, muss die entsprechende Node komplett rebootet werden. Normalerweise reicht ein Neustart des Kubelets aus, um Änderungen in der Konfiguration zu übernehmen. Bei Änderungen an Ressourcen-Limits muss das Kubelet allerdings Änderungen an bestehenden CGroups vornehmen, was nicht immer möglich ist. Ein Neustart garantiert deswegen schneller, dass die gesetzten Limits tatsächlich effektiv sind. Den Effekt können wir in den Node-Informationen bobachten:
$ kubectl describe node knode1 Capacity: [...] memory: 4030896Ki [...] Allocatable: [...] memory: 3375536Ki [...]
Hier sehen wir nun, dass der für Pods verfügbare Arbeitsspeicher weiter verringert wurde. Er ist nun exakt 768MiB geringer, als der Verfügbare Speicherplatz. Diese Zahl ergibt sich aus der Summe des für das System und Kubelet reservierten Speicherplatzes und der Soft-Eviction-Threshold.
Nun können wir nochmal testen, ob unsere Pods bei Ressourcenknappheit korrekt evicted werden. Dazu erstellen wir erneut ein Deployment um Last zu erzeugen:
$ kubectl apply -f - << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress
spec:
replicas: 2
selector:
matchLabels:
app: stress
template:
metadata:
labels:
app: stress
spec:
containers:
- name: stress
image: alexeiled/stress-ng
args:
- --vm=1
- --vm-bytes=2g
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: load-target
operator: Exists
EOF
deployment.apps/stress createdWenn wir nun die gestarteten Pods betrachten, werden wir nach einer Weile sehen, dass einer der Pods evicted wurde:
$ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES stress-7c4bb6fdbd-nrm5d 1/1 Running 0 9s fd49:7f8a:1714:14fc:6f39:9d7d:8f25:721a knode2 <none> <none> stress-7c4bb6fdbd-nw6lk 1/1 Running 0 119s fd49:7f8a:1714:14fc:7dc6:67af:9a64:c3ac knode1 <none> <none> stress-7c4bb6fdbd-z8p6c 0/1 Evicted 0 119s <none> knode1 <none> <none>
Als Ersatz für den Pod, der evicted wurde, wurde ein neuer erstellt, der nach einer Weile auf einer Node neu gestartet werden soll. Dabei kann es vorkommen, dass der Pod auf der Node neu gestartet wird, von der er gerade evicted worden ist. Das führt dann dazu, dass der Pod direkt im Anschluss wieder evicted wird. Das liegt daran, dass Kubernetes bei der Zuordnung der Pods zu den Nodes weiterhin zufällig vorgeht, weil es vor der Ausführung eines Pods nicht abschätzen kann, wieviele Ressourcen der Pod zur Laufzeit benötigen werden. Solange insgesamt genug Ressourcen vorhanden sind, sollte jedoch jeder Pod früher oder später eine Node finden, auf der er genug Ressourcen bekommt.
Ressourcen für Pods und Container verwalten
Nun wissen wir, wie wir unsere Pods vor der vollkommenen Überladung schützen. Wie wir gesehen haben, werden Pods von Nodes, die zu wenige Ressourcen haben, auch einfach wieder evicted. Dadurch wird der Pod beendet und womöglich erst zeitverzögert wieder gestartet. Wenn der Pod dabei eigentlich einen kritischen Service ausführen sollte, wäre dieser Ausfall sehr unerwünscht. Für diesen Fall bietet Kubernetes allerdings auch an, Ressourcen für Pods fest zu reservieren. Analog dazu kann man den Ressourcenverbrauch bestimmter Pods auch auf eine Maximum begrenzen. Um das zu demonstrieren, legen wir das folgende Deployment an:
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress
spec:
replicas: 3
selector:
matchLabels:
app: stress
template:
metadata:
labels:
app: stress
spec:
containers:
- name: stress
image: alexeiled/stress-ng
args:
- --vm=1
- --vm-bytes=2g
resources:
requests:
memory: 3G
limits:
memory: 3.5G
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: load-target
operator: ExistsDie in resources festgelegten Ressourcen werden fest für den Container reserviert. Wir können uns also sicher sein, dass sie immer zur Verfügung stehen. Die in limit definierten Ressourcen sind eine harte Grenze für den Container, die nicht überschritten werden darf. Durch die Angabe dieser Werte stellen wir einerseits sicher, dass unser Pod die in requests angegeben Ressourcen immer zur Verfügung hat. Andererseits helfen wir auch Kubernetes, eine Node auszuwählen, die die benötigten Ressourcen auch bereitstellen kann. Nachdem wir das Deployment angelegt haben erscheinen die folgenden Pods:
$ kubectl get pod NAME READY STATUS RESTARTS AGE stress-8485c6dd5d-58m4s 1/1 Running 0 3m56s stress-8485c6dd5d-bznmn 0/1 Pending 0 3m56s stress-8485c6dd5d-jddd7 1/1 Running 0 3m56s
Wie wir sehen, sind zwei der Pods Running, während einer immer noch Pending ist. Wenn wir uns den Pod genau ansehen, sehen wir auch warum:
$ kubectl describe pod stress-8485c6dd5d-bznmn
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 Insufficient memory.Wie wir sehen, wird der Pod nicht scheduled, weil es keine Node gibt, die den nötigen Speicherplatz zur Verfügung stellen könnte.
Ressourcen die per request zugesichert wurden, stehen dem Container, der sie angefragt hat immer zur Verfügung. Während wir die angefragten Ressourcen verwenden, kann ein anderer Container sie zwar „borgen“. Wenn der Container, der die Ressourcen reserviert hat, die Ressourcen aber selber braucht, werden sie ihm immer zur Verfügung gestellt. Notfalls werden die Pods, die die Ressourcen geborgt haben, dafür auch evicted.
Was passiert, wenn ein Container versucht, das Limit einer Ressource zu überschreiten, hängt von der Ressource ab. Für Speicher-Limits werden ggf. Prozesse im Container getötet, bis das Limit wieder eingehalten wird. CPU-Limits werden durchgesetzt, indem Prozesse die am Limit sind, gedrosselt werden und entsprechend weniger Zeit auf der CPU erhalten.
Das setzen von Memory-Limits und -Requests beeinflusst ebenfalls die Priorität mit der Pods von Nodes evicted werden, wenn die Ressourcen knapp werden. Pods werden dabei in drei unterschiedliche Klassen unterteilt. Diese Klasse kann mit kubectl describe pod <pod> im Feld „QoS Class“ eingesehen werden. Die jeweilige Klasse leitet sich aus der Kombination an Ressourcen-Requests und -Limits nach den folgenden Regeln ab:
- Best Effort: Gilt für Pods deren Container keine Ressourcen-Anfragen haben. Sie werden als erstes evicted.
- Burstable: Gilt für Pods deren Container mindestens eine Ressourcen-Anfrage haben. Sie werden evicted, sobald es keine Pods mit der Klasse Best Effort mehr gibt. Dabei werden zuerst die Pods evicted, die ihre Resource-Requests am weitesten überschreiten
- Guaranteed: Gilt für Pods in denen alle Container Limits für sowohl CPU als auch Memory gesetzt haben. Die Requests und Limits müssen dabei jeweils genau gleich sein. Diese Pods werden nur evicted, wenn es keine andere Wahl gibt.
Fazit
Auch wenn die Standard-Einstellungen zunächst zu nicht ganz so dynamischen Ergebnissen führen, bietet Kubernetes doch eine Reihe von Möglichkeiten mit denen sich sehr flexible Ressourcenzuteilungen realisieren lassen. Von Pods, die vollständig flexibel Ressourcen zugeteilt bekommen, bis zu Pods, die ein strikt definiertes Kontingent an Ressourcen zur Verfügung haben, ist vieles möglich.
In diesem Artikel habe ich für Beispiele nur die Verwaltung von Arbeitsspeicher beachtet. Natürlich lassen sich analog dazu noch weitere Hardware-Ressourcen verwalten. Welche Ressourcen das sind und wie sie gemessen werden, kann man in der Kubernetes-Dokumentation nachlesen.
Bei Fragen rund um den Einsatz von Kubernetes stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an!
| Kategorien: | HowTos |
|---|---|
| Tags: | Container Kubernetes |
über den Autor
Sven Bartscher
Senior Berater
zur Person
Sven Bartscher arbeitet seit 2017 bei credativ im Operations-Solutions-Team und ist dort unter anderem an der Entwicklung und Pflege des Open Security Filters beteiligt. Er arbeitet ebenfalls als Debian-Entwickler an dem freien Betriebssystem Debian.