PostgreSQL auf Kubernetes mit Hilfe von OpenEBS
| Kategorien: | HowTos PostgreSQL® |
|---|---|
| Tags: | Kubernetes OpenEBS PostgreSQL® |
In diesem Beitrag beschäftigen wir uns mit dem hochverfügbaren Betrieb von PostgreSQL® in einer Kubernetes-Umgebung. Ein Thema, dass für viele unserer PostgreSQL® Anwender sicher von besonderem Interesse ist.
Gemeinsam mit unserem Partnerunternehmen MayaData, demonstrieren wir Ihnen nachfolgend die Einsatzmöglichkeiten und Vorteile des äußerst leistungsfähigen Open Source Projektes – OpenEBS
OpenEBS ist ein frei verfügbares Storage Management System, dessen Entwicklung von MayaData unterstützt und begleitet wird.
Wir bedanken uns ganz besonders bei Murat-Karslioglu von MayaData und unserem Kollegen Adrian Vondendriesch für diesen interessanten und hilfreichen Beitrag, den die Kollegen aufgrund der internationalen Zusammenarbeit diesmal natürlich in englischer Sprach verfasst haben.
PostgreSQL® anywhere — via Kubernetes with some help from OpenEBS and credativ engineering
by Murat Karslioglu, OpenEBS and Adrian Vondendriesch, credativ
Introduction
If you are already running Kubernetes on some form of cloud whether on-premises or as a service, you understand the ease-of-use, scalability and monitoring benefits of Kubernetes — and you may well be looking at how to apply those benefits to the operation of your databases.
PostgreSQL® remains a preferred relational database, and although setting up a highly available Postgres cluster from scratch might be challenging at first, we are seeing patterns emerging that allow PostgreSQL® to run as a first class citizen within Kubernetes, improving availability, reducing management time and overhead, and limiting cloud or data center lock-in.
There are many ways to run high availability with PostgreSQL®; for a list, see the PostgreSQL® Documentation. Some common cloud-native Postgres cluster deployment projects include Crunchy Data’s, Sorint.lab’s Stolon and Zalando’s Patroni/Spilo. Thus far we are seeing Zalando’s operator as a preferred solution in part because it seems to be simpler to understand and we’ve seen it operate well.
Some quick background on your authors:
- OpenEBS is a broadly deployed OpenSource storage and storage management project sponsored by MayaData.
- credativ is a leading open source support and engineering company with particular depth in PostgreSQL®.
In this blog, we’d like to briefly cover how using cloud-native or “container attached” storage can help in the deployment and ongoing operations of PostgreSQL® on Kubernetes. This is the first of a series of blogs we are considering — this one focuses more on why users are adopting this pattern and future ones will dive more into the specifics of how they are doing so.
At the end you can see how to use a Storage Class and a preferred operator to deploy PostgreSQL® with OpenEBS underlying
If you are curious about what container attached storage of CAS is you can read more from the Cloud Native Computing Foundation (CNCF) here.
Conceptually you can think of CAS as being the decomposition of previously monolithic storage software into containerized microservices that themselves run on Kubernetes. This gives all the advantages of running Kubernetes that already led you to run Kubernetes — now applied to the storage and data management layer as well. Of special note is that like Kubernetes, OpenEBS runs anywhere so the same advantages below apply whether on on-premises or on any of the many hosted Kubernetes services.
PostgreSQL® plus OpenEBS
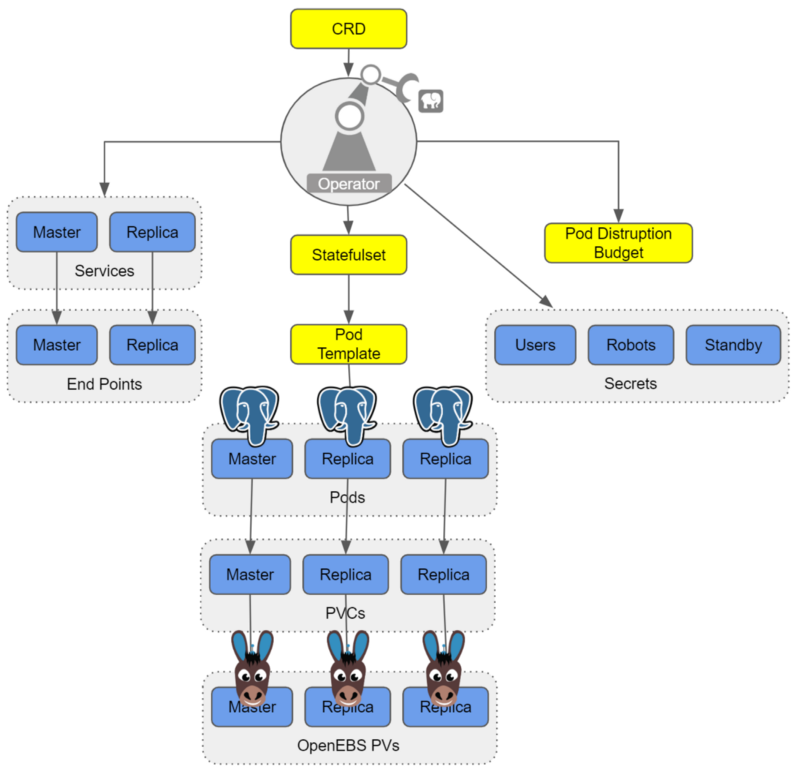
We have seen joint users adopting OpenEBS as a substrate to PostgreSQL® for a variety of reasons. A few that jump out include:
Consistency in underlying disk or cloud volume management:
One of the most annoying things about setting up a system to run PostgreSQL® — even if it is on Kubernetes — is configuring the underlying disks and storage systems as needed. With a solution like OpenEBS, you specify via storage classes how you want the underlying systems configured and OpenEBS with the help of Kubernetes ensures that the system delivers the storage capacity that is needed and that it is configured as you need it. An example of such a storage class is shared below. This automation can remove a source of human error and definitely removes a source of human annoyance.
Thin provisioning and on-demand expansion:
Now that you have turned over to OpenEBS the provisioning and management of the underlying storage hardware and services, you just have to tell it the amount of storage you need for your PostgreSQL® and then everything will work out well, right? Well actually knowing how much data your PostgreSQL® instance or instances will consume is pretty tricky — and arguably somewhat impossible as it is beyond your control.
Here OpenEBS can also help because it supports both thin provisioning and on the fly pool expansion. The thin provisioning allows you to claim more space than you actually can provisioning — this then allows your PostgreSQL® to scale in the usage of space without interruption by allowing for adding more storage to the running system without the need to stop the database.
Thin provisioning though is not a good idea if there is not also on the fly expansion of the underlying capacity for perhaps obvious reasons — as the PostgreSQL® expands you want to make sure it can claim space as needed otherwise at some point you’ll have to interrupt operations and again perform manual tasks. OpenEBS helps here as well — if configured to do so it can expand its underlying pools, whether these are of physical disks, underlying storage systems, or storage services from a cloud. The capacity of the pool can be expanded on demand simply by adding more disks to the cStor pool.
The cStor architecture also supports the resizing of a provisioned volume on the fly and this will be fully automated as of OpenEBS 0.9. Via these enhancements, volumes, as well as underlying pools, will be able to scale automatically on any cloud providing K8s support.
In addition to reducing the risk and hassle of manual operations, the combination of thin provisioning and on-demand scaling can reduce costs because you don’t over-provision capacity to achieve performance for example, which reduces unnecessary cloud service spending and can increase average utilization of usage of your hardware as well.
Disaster recovery and migration:
With a solution like OpenEBS, your storage classes can also include back-up schedules — and these can be easily managed either via Kubectl or via the free to use MayaOnline. Again these storage classes can be applied on a per container basis which is quite a bit of granularity and control by each team running their PostgreSQL®.
Additionally, we are working together to add tighter integration with PostgreSQL® to this per snapshot based workload, per container back-up capability, which is called DMaaS by MayaData and OpenEBS. With this additional integration, an option will be added to the storage classes and to OpenEBS to flush active transactions before taking the snapshot. The additional integration of storage snapshots in conjunction with Write Ahead Log (WAL) archiving will provide additional PITR functionality. DMaaS leverages the open source Velero from Heptio and marries it to the COW based capabilities of the cStor OpenEBS engine to deliver extremely efficient backups and migrations.
With DMaaS backups taken to one location can be recovered from another. This can prove useful for a variety of use cases including the use of relatively ephemeral clusters as a part of a rolling upgrade for example of an environment. Additionally, the same capability can be used to move workloads from one Kubernetes environment to another thereby reducing lock-in.
Snapshots and clones for development and troubleshooting:
DBAs have been using snapshots and clones for a long time to assist in troubleshooting and to enable teams to develop and test against a read-only copy of production data. For example, via OpenEBS you can easily use Kubernetes to invoke a snapshot and then promote that snapshot to a clone and then spawn a container from that clone. You now can do anything you want with that container and the data set contained within it, and of course, destroy it when you are done.
One use case that clones can support is improved reporting. For example, let’s say you do computationally expensive analytical queries and build roll-up queries for monthly reports. It is simple with OpenEBS to clone the underlying OLTP system, allowing you to work on a static copy of your database, thereby removing load from your production DBs and ensuring you have a verifiable source of information for those reports.
Closing the loop with per workload visibility and optimization:
In addition to the benefits of using OpenEBS, there are additional benefits from using MayaOnline for the management of stateful workloads. We may address these in future blogs examining common day 2 operations and optimization of your PostgreSQL® on Kubernetes.
Running Postgres-Operator on OpenEBS
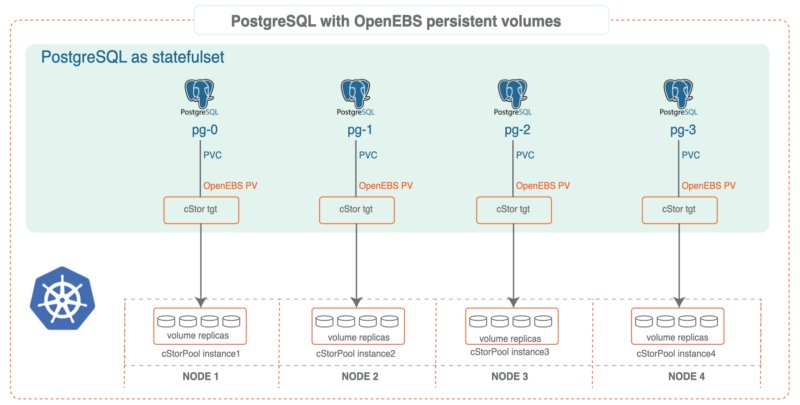
Software Prerequisites
- Postgres-Operator (for cluster deployment)
- Docker installed
- Kubernetes 1.9+ cluster installed
- kubectl installed
- OpenEBS installed
Install OpenEBS
- If OpenEBS is not installed in your K8s cluster, this can be done from here. If OpenEBS is already installed, go to the next step.
- Connect to MayaOnline (Optional): Connecting the Kubernetes cluster to MayaOnline provides good visibility of storage resources. MayaOnline has various support options for enterprise customers.
Configure cStor Pool
- If cStor Pool is not configured in your OpenEBS cluster, this can be done from here. As PostgreSQL® is a StatefulSet application, it requires a single storage replication factor. If you prefer additional redundancy you can always increase the replica count to 3.
During cStor Pool creation, make sure that the maxPools parameter is set to >=3. If a cStor pool is already configured, go to the next step. Sample YAML named openebs-config.yaml for configuring cStor Pool is provided in the Configuration details below.
openebs-config.yaml
#Use the following YAMLs to create a cStor Storage Pool. # and associated storage class. apiVersion: openebs.io/v1alpha1 kind: StoragePoolClaim metadata: name: cstor-disk spec: name: cstor-disk type: disk poolSpec: poolType: striped # NOTE — Appropriate disks need to be fetched using `kubectl get disks` # # `Disk` is a custom resource supported by OpenEBS with `node-disk-manager` # as the disk operator # Replace the following with actual disk CRs from your cluster `kubectl get disks` # Uncomment the below lines after updating the actual disk names. disks: diskList: # Replace the following with actual disk CRs from your cluster from `kubectl get disks` # — disk-184d99015253054c48c4aa3f17d137b1 # — disk-2f6bced7ba9b2be230ca5138fd0b07f1 # — disk-806d3e77dd2e38f188fdaf9c46020bdc # — disk-8b6fb58d0c4e0ff3ed74a5183556424d # — disk-bad1863742ce905e67978d082a721d61 # — disk-d172a48ad8b0fb536b9984609b7ee653 — -
Create Storage Class
- You must configure a StorageClass to provision cStor volume on a cStor pool. In this solution, we are using a StorageClass to consume the cStor Pool which is created using external disks attached on the Nodes. The storage pool is created using the steps provided in the Configure StoragePool section. In this solution, PostgreSQL® is a deployment. Since it requires replication at the storage level the cStor volume replicaCount is 3. Sample YAML named openebs-sc-pg.yaml to consume cStor pool with cStorVolume Replica count as 3 is provided in the configuration details below.
openebs-sc-pg.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-postgres
annotations:
openebs.io/cas-type: cstor
cas.openebs.io/config: |
- name: StoragePoolClaim
value: "cstor-disk"
- name: ReplicaCount
value: "3"
provisioner: openebs.io/provisioner-iscsi
reclaimPolicy: Delete
---Launch and test Postgres Operator
- Clone Zalando’s Postgres Operator.
git clone https://github.com/zalando/postgres-operator.git cd postgres-operator
Use the OpenEBS storage class
- Edit manifest file and add openebs-postgres as the storage class.
nano manifests/minimal-postgres-manifest.yaml
After adding the storage class, it should look like the example below:
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: acid-minimal-cluster
namespace: default
spec:
teamId: "ACID"
volume:
size: 1Gi
storageClass: openebs-postgres
numberOfInstances: 2
users:
# database owner
zalando:
- superuser
- createdb
# role for application foo
foo_user: []
#databases: name->owner
databases:
foo: zalando
postgresql:
version: "10"
parameters:
shared_buffers: "32MB"
max_connections: "10"
log_statement: "all"Start the Operator
- Run the command below to start the operator
kubectl create -f manifests/configmap.yaml # configuration kubectl create -f manifests/operator-service-account-rbac.yaml # identity and permissions kubectl create -f manifests/postgres-operator.yaml # deployment
Create a Postgres cluster on OpenEBS
Optional: The operator can run in a namespace other than default. For example, to use the test namespace, run the following before deploying the operator’s manifests:
kubectl create namespace test kubectl config set-context $(kubectl config current-context) — namespace=test
- Run the command below to deploy from the example manifest:
kubectl create -f manifests/minimal-postgres-manifest.yaml
2. It only takes a few seconds to get the persistent volume (PV) for the pgdata-acid-minimal-cluster-0 up. Check PVs created by the operator using the kubectl get pv command:
$ kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-8852ceef-48fe-11e9–9897–06b524f7f6ea 1Gi RWO Delete Bound default/pgdata-acid-minimal-cluster-0 openebs-postgres 8m44s pvc-bfdf7ebe-48fe-11e9–9897–06b524f7f6ea 1Gi RWO Delete Bound default/pgdata-acid-minimal-cluster-1 openebs-postgres 7m14s
Connect to the Postgres master and test
- If it is not installed previously, install psql client:
sudo apt-get install postgresql-client
2. Run the command below and note the hostname and host port.
kubectl get service — namespace default |grep acid-minimal-cluster
3. Run the commands below to connect to your PostgreSQL® DB and test. Replace the [HostPort] below with the port number from the output of the above command:
export PGHOST=$(kubectl get svc -n default -l application=spilo,spilo-role=master -o jsonpath="{.items[0].spec.clusterIP}")
export PGPORT=[HostPort]
export PGPASSWORD=$(kubectl get secret -n default postgres.acid-minimal-cluster.credentials -o ‘jsonpath={.data.password}’ | base64 -d)
psql -U postgres -c ‘create table foo (id int)’Congrats you now have the Postgres-Operator and your first test database up and running with the help of cloud-native OpenEBS storage.
Partnership and future direction
As this blog indicates, the teams at MayaData / OpenEBS and credativ are increasingly working together to help organizations running PostgreSQL® and other stateful workloads. In future blogs, we’ll provide more hands-on tips.
We are looking for feedback and suggestions on where to take this collaboration. Please provide feedback below or find us on Twitter or on the OpenEBS slack community.
| Kategorien: | HowTos PostgreSQL® |
|---|---|
| Tags: | Kubernetes OpenEBS PostgreSQL® |
über den Autor
Adrian Vondendriesch
Technischer Leiter
zur Person
Adrian ist seit 2013 Mitarbeiter der credativ GmbH. Als technischer Leiter des Cloud Infrastructure Teams beschäftigt er sich hauptsächlich mit der Planung, Realisierung und Betreuung verteilter Infrastrukturen wie zum Beispiel Kubernetes und Ceph sowie mit der Erarbeitung von Deployment-Strategien. Zuvor war er Teil des Datenbank-Teams bei credativ und war dort unter anderem mit dem Aufbau und der Verwaltung von hochverfügbaren Datenbank-Systemen betreut. Seit 2015 beteiligt er sich aktiv am Debian-Projekt.