Ende April hatte ich die großartige Gelegenheit, credativ auf der HOW2026 (Hello Open-source World), der PostgreSQL-&-IvorySQL-Eco-Conference in Jinan, China, zu vertreten. IvorySQL ist ein chinesischer Fork von PostgreSQL mit erweiterter Oracle-Kompatibilität. In den letzten Jahren hat es nicht nur in China an Popularität gewonnen. Die Konferenz brachte PostgreSQL- und IvorySQL-Expertinnen und -Experten, Mitwirkende sowie open-source-Datenbank-Enthusiasten aus aller Welt zusammen. Die Atmosphäre war hervorragend, und ich möchte einige Highlights sowie eine Zusammenfassung meiner Beiträge teilen.
Meine Beiträge
Ich hatte die Ehre, mit zwei Sessions zum HOW2026-Programm beizutragen.
Workshop: Die Alchemie der Shared Buffers
Am Sonntagnachmittag leitete ich einen dreistündigen Deep-Dive-Workshop, in dem ich die komplexen Mechanismen der PostgreSQL Shared Buffers beleuchtete. Ich erläuterte, wie Linux Shared-Memory-Operationen über das tmpfs-Dateisystem implementiert, wie Shared Buffers intern funktionieren, welche praktischen Grenzen und Nutzungsmuster es gibt, warum und wie Huge Pages für deren Allokation eingesetzt werden sollten, warum Transparent Huge Pages die Performance negativ beeinflussen und welche praktischen Strategien es gibt, um hohe Parallelität mit optimaler Systemleistung in Einklang zu bringen.
Vortrag: Linux und PostgreSQL im Multiversum der Verbindungen
Am Dienstagnachmittag hielt ich einen Vortrag mit Fokus auf dem Overhead von PostgreSQL-Verbindungen. Ich erläuterte, wie PostgreSQL-Verbindungen mit dem Linux-Kernel interagieren, und behandelte dabei Speicherverbrauch, Mapping der physischen Speicherallokation, Context-Switching-Overhead sowie PostgreSQL-Interna, um zu erklären, warum eine große Anzahl an Verbindungen die Performance deutlich verschlechtern kann.



Ausgewählte Highlights der Konferenz
- The Development Trends of Databases in the Era of Data Intelligence — Aoying Zhou eröffnete die Veranstaltung mit seiner Perspektive auf die zukünftige Ausrichtung von Datenbankarchitekturen in einer datengetriebenen Ära, die von Künstlicher Intelligenz geprägt ist. Er erläuterte, dass eine engere Integration von Datenbanken und KI-Technologien einer der wichtigsten Treiber des künftigen technologischen Fortschritts sein wird.
- Inauguration Ceremony of COSDA & China’s PostgreSQL Industry — Wir erlebten die offizielle Gründung der China Open Source Database Alliance (COSDA), gefolgt von einem strategischen Überblick von Zhongyi Tan zu Chancen und der zukünftigen Roadmap für PostgreSQL in China. Chinesische Unternehmen sehen großes Potenzial in PostgreSQL und IvorySQL als breit einsetzbaren open-source-Datenbanklösungen, die auch international angeboten werden können.
- Databases in the AI Trenches — Bruce Momjian hielt eine aufschlussreiche Keynote darüber, wie sich PostgreSQL an die sich schnell wandelnden Anforderungen von KI-Workloads anpasst.
- Open-Source Foundation, Boundless Intelligence Connection — Xinjie Lv hob die entscheidende Rolle hervor, die open-source-Communities als Fundament moderner intelligenter Anwendungen und Plattformen spielen.
- Make Postgres Yours Again — Alvaro Hernandez präsentierte einen inspirierenden Vortrag über die Erweiterbarkeit von PostgreSQL und darüber, wie man durch eine neue, von seinem Unternehmen entwickelte open-source-Deployment-Umgebung die operative Kontrolle über Datenbank-Deployments zurückgewinnen kann.
- Community Exhibitions & Awards — Der Vormittag endete damit, dass Robert Treat und Mark Wong erklärten, wie PostgreSQL-Konferenzen und Community-Events organisiert werden, sowie mit Möglichkeiten, sich im PostgreSQL-Ökosystem zu engagieren. Anschließend folgte eine besondere Badge-Award-Zeremonie, in der Mitwirkende ausgezeichnet wurden, die an PostgreSQL 18 gearbeitet haben.






Datenbanken und KI
- KI-Durchbruchjahr: Was kann IvorySQL leisten? (Shawn Yan) — Ein Überblick über die praktischen Einsatzmöglichkeiten und Fähigkeiten von IvorySQL zur Unterstützung KI-orientierter Workloads.
- Applications and Practices of PostgreSQL in AI (Dingding Wang) — Dieser Vortrag konzentrierte sich darauf, PostgreSQL und sein Ökosystem zu nutzen, um effiziente und kosteneffektive KI-Datenpipelines und intelligente Anwendungen aufzubauen.
- AI Performance Analysis of the PostgreSQL Database (Shan Bai) und AI-Driven Query Optimization: Tree Transformer Breakthrough (Peng Cui) — Diese Sessions waren sehr technisch. Shan Bai demonstrierte den Einsatz von KI-Techniken für die allgemeine Query-Optimierung, während Peng Cui QPR (Tree Transformer Representation) zur multidimensionalen Merkmalsextraktion und QPSLR (Ranking Learning) für eine rankingbasierte Query-Optimierung vorstellte.
- AI-Native PG Diagnosis (Xiang Zheng) — Eine Präsentation mit Fokus auf operative Aspekte von PostgreSQL, die den Übergang von reaktiver, manuell durch Administratoren durchgeführter Diagnose hin zu KI-nativen Systemen zeigte, die Probleme proaktiv identifizieren können.
- PostgreSQL in AI Applications: Reality Is More Complex Than Similarity Search (Florents Tselai) — Ein sehr praxisnaher Vortrag, der hervorhob, dass pgvector und Similarity Search zwar wertvolle Technologien sind, reale KI-Anwendungen jedoch deutlich breitere und anspruchsvollere Datenmodellierungsansätze erfordern.






Weitere interessante Vorträge
- PostgreSQL Hacker: My Experience and Lessons (Chao Li) — Ein offener Rückblick auf Chao Lis erstes Jahr als PostgreSQL-Contributor. Statt sich primär auf Tools zu konzentrieren, beleuchtete der Vortrag frühe Missverständnisse, technische und kommunikative Fehler sowie Strategien, mit denen die wahrgenommenen Einstiegshürden überwunden wurden, und bot damit wertvolle Orientierung für neue Mitwirkende, die sich in der PostgreSQL-Community engagieren möchten.
- Tracking Vacuum Resource Consumption: From Idea to Patch (Alena Rybakina) — Eine aufschlussreiche Präsentation, die den architektonischen Weg zur Entwicklung von per-Relation-Vacuum-Ressourcenstatistiken in PostgreSQL beschrieb. Der Vortrag zeigte, wie strenge interne Rahmenbedingungen zentrale Designentscheidungen beeinflussten, und vermittelte wertvolle Erkenntnisse darüber, wie sich Observability und Performance-Overhead in komplexen Subsystemen ausbalancieren lassen.
- Zabbix 7.0 PostgreSQL Monitoring Configuration (Yong Ren) — Eine sehr praxisorientierte Session zu den neuesten Funktionen von Zabbix 7.0 und dazu, wie es effektiv für das PostgreSQL-Monitoring konfiguriert wird. Die Präsentation behandelte wesentliche Metriken, Anomalie-Alarmierung, Monitoring der Verbindungsintegrität, Replication Lag, Hardware-Auslastung sowie Strategien zur Sicherstellung hoher Verfügbarkeit.
Fazit
Die HOW2026 war ein unvergessliches Erlebnis. Jinan war eine großartige Gastgeberstadt, und die Tiefe des Wissens, das die PostgreSQL- und IvorySQL-Communities geteilt haben, war wirklich beeindruckend. Vielen Dank an die Organisatoren für die Einladung und die hervorragende Organisation der Konferenz.
Fotos (c) HOW2026-Organisatoren / Josef Machytka
PostgreSQL 18 hat eine sehr wichtige Änderung eingeführt: Datenblock-Prüfsummen sind jetzt standardmäßig für neue Cluster zum Zeitpunkt der Clusterinitialisierung aktiviert. Ich habe bereits in meinem vorherigen Artikel darüber geschrieben. Ich habe auch erwähnt, dass es immer noch viele bestehende PostgreSQL-Installationen ohne aktivierte Datenprüfsummen gibt, da dies in früheren Versionen die Standardeinstellung war. In diesen Installationen kann Datenbeschädigung manchmal zu mysteriösen Fehlern führen und die normale Funktionsweise verhindern. In diesem Beitrag möchte ich gängige PostgreSQL-Datenbeschädigungsmodi analysieren, um zu zeigen, wie man sie diagnostiziert und wie man sie behebt.
Beschädigungen in PostgreSQL-Beziehungen ohne Datenprüfsummen treten als Low-Level-Fehler wie „Ungültige Seite in Block xxx“, Transaktions-ID-Fehler, TOAST-Chunk-Inkonsistenzen oder sogar Backend-Abstürze auf. Leider können einige Backup-Strategien die Beschädigung maskieren. Wenn der Cluster keine Prüfsummen verwendet, können Tools wie pg_basebackup, die Datendateien so kopieren, wie sie sind, keine Validierung der Daten durchführen, sodass beschädigte Seiten unbemerkt in einem Basis-Backup landen können. Wenn Prüfsummen aktiviert sind, überprüft pg_basebackup diese standardmäßig, es sei denn, –no-verify-checksums wird verwendet. In der Praxis werden diese Low-Level-Fehler oft erst sichtbar, wenn wir direkt auf die beschädigten Daten zugreifen. Einige Daten werden selten berührt, was bedeutet, dass Beschädigungen oft erst bei dem Versuch auftreten, pg_dump auszuführen, da pg_dump alle Daten lesen muss.
Typische Fehler sind:
-- invalid page in a table: pg_dump: error: query failed: ERROR: invalid page in block 0 of relation base/16384/66427 pg_dump: error: query was: SELECT last_value, is_called FROM public.test_table_bytea_id_seq -- damaged system columns in a tuple: pg_dump: error: Dumping the contents of table "test_table_bytea" failed: PQgetResult() failed. pg_dump: error: Error message from server: ERROR: could not access status of transaction 3353862211 DETAIL: Could not open file "pg_xact/0C7E": No such file or directory. pg_dump: error: The command was: COPY public.test_table_bytea (id, id2, id3, description, data) TO stdout; -- damaged sequence: pg_dump: error: query to get data of sequence "test_table_bytea_id2_seq" returned 0 rows (expected 1) -- memory segmentation fault during pg_dump: pg_dump: error: Dumping the contents of table "test_table_bytea" failed: PQgetCopyData() failed. pg_dump: error: Error message from server: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. pg_dump: Fehler: Der Befehl war: COPY public.test_table_bytea (id, id2, id3, description, data) TO stdout;
Hinweis: In solchen Fällen beendet pg_dump leider beim ersten Fehler und fährt nicht fort. Aber wir können ein einfaches Skript verwenden, das in einer Schleife Tabellennamen aus der Datenbank liest und jede Tabelle separat in eine separate Datei sichert, wobei Fehlermeldungen in eine tabellenspezifische Protokolldatei umgeleitet werden. Auf diese Weise sichern wir sowohl Tabellen, die noch intakt sind, als auch finden alle beschädigten Objekte.
Fehler verstehen
Der schnellste Weg, diese Symptome zu verstehen, besteht darin, sie der beschädigten Stelle einer 8-KB-Heap-Seite zuzuordnen. Um dies testen zu können, habe ich ein Python-Skript zur „Beschädigungssimulation“ erstellt, das bestimmte Teile eines Datenblocks gezielt beschädigen kann. Damit können wir gängige Beschädigungsmodi testen. Wir werden sehen, wie man jeden einzelnen mit pageinspect diagnostiziert, prüfen, ob amcheck in diesen Fällen helfen kann, und zeigen, wie man Abfragen mit pg_surgery gezielt freigibt, wenn ein einzelnes Tupel eine ganze Tabelle unlesbar macht.
PostgreSQL-Heap-Tabellenformat
- Header: Metadaten für Blockverwaltung und -integrität
- Item-ID-Array (Tupel-Pointer): Einträge, die auf Tupel verweisen (Offset + Länge + Flags)
- Freier Speicherplatz
- Tupel: tatsächliche Zeilendaten, jeweils mit eigenem Tupel-Header (Systemspalten)
- Spezieller Speicherplatz: reserviert für indexspezifische oder andere beziehungsspezifische Daten – Heap-Tabellen verwenden ihn nicht
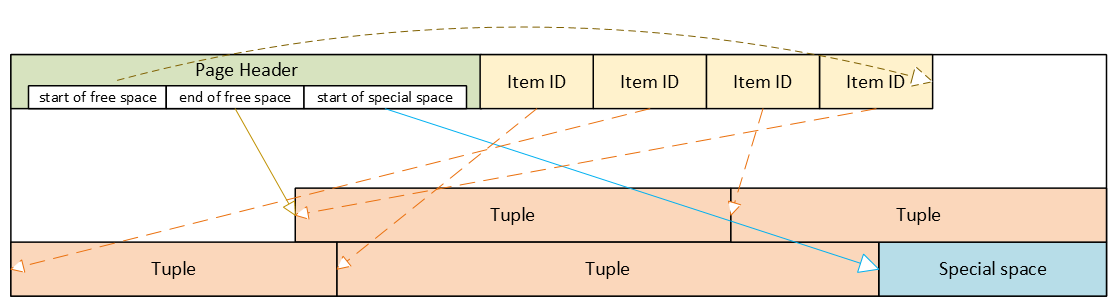
Beschädigter Seitenheader: der gesamte Block wird unzugänglich
Der Seitenheader enthält die Layout-Pointer für die Seite. Die wichtigsten Felder, die wir auch über pageinspect sehen können, sind:
- pd_flags: header flag bits
- pd_lower: offset to the start of free space
- pd_upper: offset to the end of free space
- pd_special: offset to the start of special space
- plus lsn, checksum, pagesize, version, prune_xid
ERROR: invalid page in block 285 of relation base/16384/29724
Dies ist die einzige Klasse von Beschädigungsfehlern, die durch Aktivieren von zero_damaged_pages = on übersprungen werden kann, wenn der Cluster keine Datenblock-Prüfsummen verwendet. Mit zero_damaged_pages = on werden Blöcke mit beschädigten Headern im Speicher „genullt“ und übersprungen, was buchstäblich bedeutet, dass der gesamte Inhalt des Blocks durch Nullen ersetzt wird. AUTOVACUUM entfernt genullte Seiten, kann aber nicht ungescannte Seiten nullen.
Woher der Fehler im PostgreSQL-Quellcode kommt
/* * Die folgenden Überprüfungen beweisen nicht, dass der Header korrekt ist, sondern nur, dass * es vernünftig genug aussieht, um in den Pufferpool aufgenommen zu werden. Spätere Verwendung von * der Block kann immer noch Probleme aufdecken, weshalb wir die * Checksummenoption anbieten. */ if ((p->pd_flags & ~PD_VALID_FLAG_BITS) == 0 && p->pd_lower <= p->pd_upper && p->pd_upper <= p->pd_special && p->pd_special <= BLCKSZ && p->pd_special == MAXALIGN(p->pd_special)) header_sane = true; if (header_sane && !checksum_failure) return true;
SELECT * FROM page_header(get_raw_page('pg_toast.pg_toast_32840', 100));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
------------+----------+-------+-------+-------+---------+----------+---------+-----------
0/2B2FCD68 | 0 | 4 | 40 | 64 | 8192 | 8192 | 4 | 0
Wenn der Header als beschädigt getestet wird, können wir mit SQL nichts diagnostizieren. Mit zero_damaged_pages = off endet jeder Versuch, diese Seite zu lesen, mit einem ähnlichen Fehler wie im obigen Beispiel. Wenn wir zero_damaged_pages = on setzen, wird beim ersten Versuch, diese Seite zu lesen, alles durch Nullen ersetzt, einschließlich des Headers:
SELECT * from page_header(get_raw_page('pg_toast.pg_toast_28740', 578)); WARNING: invalid page in block 578 of relation base/16384/28751; zeroing out page lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid -----+----------+-------+-------+-------+---------+----------+---------+----------- 0/0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
Beschädigtes Item-IDs-Array: Offsets und Längen werden unsinnig
- ERROR: invalid memory alloc request size 18446744073709551594
- DEBUG: server process (PID 76) was terminated by signal 11: Segmentation fault
SELECT lp, lp_off, lp_flags, lp_len, t_xmin, t_xmax, t_field3, t_ctid, t_infomask2, t_infomask, t_hoff, t_bits, t_oid, substr(t_data::text,1,50) as t_data
FROM heap_page_items(get_raw_page('public.test_table', 7));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+----------------------------------------------------
1 | 7936 | 1 | 252 | 29475 | 0 | 0 | (7,1) | 5 | 2310 | 24 | | | \x01010000010100000101000018030000486f742073656520
2 | 7696 | 1 | 236 | 29476 | 0 | 0 | (7,2) | 5 | 2310 | 24 | | | \x020100000201000002010000d802000043756c747572616c
3 | 7504 | 1 | 189 | 29477 | 0 | 0 | (7,3) | 5 | 2310 | 24 | | | \x0301000003010000030100001c020000446f6f7220726563
4 | 7368 | 1 | 132 | 29478 | 0 | 0 | (7,4) | 5 | 2310 | 24 | | | \x0401000004010000040100009d4d6f76656d656e74207374
Hier können wir das Item-IDs-Array gut sehen – Offsets und Längen. Das erste Tupel wird ganz am Ende des Datenblocks gespeichert, daher hat es den größten Offset. Jedes nachfolgende Tupel wird näher und näher am Anfang der Seite gespeichert, sodass die Offsets kleiner werden. Wir können auch die Längen der Tupel sehen, sie sind alle unterschiedlich, da sie einen Textwert variabler Länge enthalten. Wir können auch Tupel und ihre Systemspalten sehen, aber wir werden sie uns später ansehen.
Wenn wir nun das Item-IDs-Array beschädigen und diagnostizieren, wie es aussieht, wird die Ausgabe verkürzt, da auch alle anderen Spalten leer sind. Aufgrund des beschädigten Item-IDs-Arrays können wir Tupel nicht richtig lesen. Hier können wir das Problem sofort erkennen: Offsets und Längen enthalten Zufallswerte, von denen die meisten 8192 überschreiten, d. h. weit über die Grenzen der Datenseite hinausgehen:
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax ----+--------+----------+--------+--------+-------- 1 | 19543 | 1 | 16226 | | 2 | 5585 | 2 | 3798 | | 3 | 25664 | 3 | 15332 | | 4 | 10285 | 2 | 17420 | |
SELECT * FROM verify_heapam('test_table', FALSE, FALSE, 'none', 7, 7); blkno | offnum | attnum | msg -------+--------+--------+--------------------------------------------------------------------------- 7 | 1 | | line pointer to page offset 19543 is not maximally aligned 7 | 2 | | line pointer redirection to item at offset 5585 exceeds maximum offset 4 7 | 4 | | line pointer redirection to item at offset 10285 exceeds maximum offset 4
Beschädigte Tupel: Systemspalten können Scans unterbrechen
- 58P01 – could not access status of transaction 3047172894
- XX000 – MultiXactId 1074710815 has not been created yet — apparent wraparound
- WARNING: Concurrent insert in progress within table „test_table“
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid ----+--------+----------+--------+------------+------------+------------+--------------------+-------------+------------+--------+--------+------- 1 | 6160 | 1 | 2032 | 1491852297 | 287039843 | 491133876 | (3637106980,61186) | 50867 | 46441 | 124 | | 2 | 4128 | 1 | 2032 | 3846288155 | 3344221045 | 2002219688 | (2496224126,65391) | 34913 | 32266 | 82 | | 3 | 2096 | 1 | 2032 | 1209990178 | 1861759146 | 2010821376 | (426538995,32644) | 23049 | 2764 | 215 | |
- XX000 – unexpected chunk number -556107646 (expected 20) for toast value 29611 in pg_toast_29580
- XX000 – found toasted toast chunk for toast value 29707 in pg_toast_29580
Umgang mit beschädigten Tupeln mit pg_surgery
Selbst ein einzelnes beschädigtes Tupel kann Selects aus der gesamten Tabelle verhindern. Beschädigung in xmin, xmax und hint bits führt dazu, dass eine Abfrage fehlschlägt, da der MVCC-Mechanismus die Sichtbarkeit dieser beschädigten Tupel nicht bestimmen kann. Ohne Datenblock-Prüfsummen können wir solche beschädigten Seiten nicht einfach nullen, da ihr Header bereits den „Sinnhaftigkeits“-Test bestanden hat. Wir müssten die Zeilen einzeln mit einem PL/pgSQL-Skript retten. Aber wenn eine Tabelle riesig ist und die Anzahl der beschädigten Tupel gering ist, ist dies höchst unpraktisch.
In einem solchen Fall sollten wir über die Verwendung der pg_surgery-Erweiterung nachdenken, um beschädigte Tupel einzufrieren oder zu entfernen. Aber erstens ist die korrekte Identifizierung beschädigter Tupel entscheidend, und zweitens existiert die Erweiterung seit PostgreSQL 14, sie ist in älteren Versionen nicht verfügbar. Ihre Funktionen erfordern ctid, aber wir müssen einen geeigneten Wert basierend auf der Seitennummer und der Ordnungszahl des Tupels auf der Seite erstellen, wir können kein beschädigtes ctid aus dem Tupel-Header verwenden, wie oben gezeigt.
Einfrieren vs. Löschen
Eingefrorene Tupel sind für alle Transaktionen sichtbar und verhindern das Blockieren von Lesevorgängen. Sie enthalten aber immer noch beschädigte Daten: Abfragen geben Müll zurück. Daher wird uns das bloße Einfrieren beschädigter Tupel höchstwahrscheinlich nicht helfen, und wir müssen beschädigte Tupel löschen. Das vorherige Einfrieren kann jedoch hilfreich sein, um sicherzustellen, dass wir die richtigen Tupel anvisieren. Einfrieren bedeutet einfach, dass die Funktion heap_force_freeze (mit dem richtigen ctid) t_xmin durch den Wert 2 (eingefrorenes Tupel) ersetzt, t_xmax durch 0 und t_ctid repariert.
Aber alle anderen Werte bleiben so, wie sie sind, d. h. immer noch beschädigt. Die Verwendung der pageinspect-Erweiterung, wie oben gezeigt, bestätigt, dass wir mit einem richtigen Tupel arbeiten. Nach dieser Überprüfung können wir beschädigte Tupel mit der Funktion heap_force_kill mit den gleichen Parametern löschen. Diese Funktion überschreibt den Pointer im Item-ID-Array für dieses spezifische Tupel und markiert es als tot.
Warnung: Funktionen in pg_surgery gelten per Definition als unsicher, verwenden Sie sie daher mit Vorsicht. Sie können sie wie jede andere Funktion aus SQL aufrufen, aber es handelt sich nicht um MVCC-transaktionale Operationen. Ihre Aktionen sind irreversibel: ROLLBACK kann ein Einfrieren oder Löschen nicht „rückgängig machen“, da diese Funktionen eine Heap-Seite in gemeinsam genutzten Puffern direkt modifizieren und die Änderung im WAL-Protokoll protokollieren. Daher sollten wir sie zuerst auf einer Kopie dieser spezifischen Tabelle (wenn möglich) oder auf einer Testtabelle testen. Das Löschen des Tupels kann auch zu Inkonsistenzen in Indizes führen, da das Tupel nicht mehr existiert, aber in einem Index referenziert werden könnte. Sie schreiben Änderungen in das WAL-Protokoll; daher wird die Änderung an Standbys repliziert.
Zusammenfassung
 PostgreSQL 17 führte Streaming-E/A ein – das Gruppieren mehrerer Seitenlesevorgänge in einen einzigen Systemaufruf und die Verwendung intelligenterer posix_fadvise()-Hinweise. Allein das führte in einigen Workloads zu bis zu ~30 % schnelleren sequenziellen Scans, aber es war immer noch strikt synchron: Jeder Backend-Prozess führte einen Lesevorgang aus und wartete dann darauf, dass der Kernel Daten zurückgab, bevor er fortfuhr. Vor PG17 las PostgreSQL typischerweise eine 8-kB-Seite gleichzeitig.
PostgreSQL 17 führte Streaming-E/A ein – das Gruppieren mehrerer Seitenlesevorgänge in einen einzigen Systemaufruf und die Verwendung intelligenterer posix_fadvise()-Hinweise. Allein das führte in einigen Workloads zu bis zu ~30 % schnelleren sequenziellen Scans, aber es war immer noch strikt synchron: Jeder Backend-Prozess führte einen Lesevorgang aus und wartete dann darauf, dass der Kernel Daten zurückgab, bevor er fortfuhr. Vor PG17 las PostgreSQL typischerweise eine 8-kB-Seite gleichzeitig.
- Sequenzielle Heap-Scans, wie einfache SELECT- und COPY-Operationen, die viele Daten streamen
- VACUUM auf großen Tabellen und Indizes
- ANALYZE-Stichproben
- Bitmap-Heap-Scans
Autovacuum profitiert ebenfalls von dieser Änderung, da seine Worker dieselben VACUUM/ANALYZE-Codepfade verwenden. Andere Operationen bleiben vorerst synchron:
- B‑Baum-Indexscans / Index‑Only-Scans
- Wiederherstellung & Replikation
- Alle Schreiboperationen INSERT, UPDATE, DELETE, WAL-Schreibvorgänge
- Kleine OLTP-Lookups, die eine einzelne Heap-Seite berühren
Es wird erwartet, dass zukünftige Arbeiten die Abdeckung erweitern, insbesondere Index‑Only-Scans und einige Optimierungen des Schreibpfads.
Signifikante Verbesserungen für Cloud-Volumes
Community-Benchmarks zeigen, dass PostgreSQL 18 AIO die Kaltcache-Datenlesevorgänge in Cloud-Setups mit netzwerkgebundenem Speicher, bei denen die Latenz hoch ist, deutlich verbessert. Die AWS-Dokumentation besagt, dass die durchschnittliche Latenz von Block Express-Volumes „unter 500 Mikrosekunden für 16 KiB E/A-Größe“ liegt, während die Latenz von General Purpose-Volumes 800 Mikrosekunden überschreiten kann. Einige Artikel legen nahe, dass unter hoher Last jeder physische Block, der von der Festplatte gelesen wird, etwa 1 ms kosten kann, während die Seitenverarbeitung in PostgreSQL viel günstiger ist. Indem wir viele Seiten in einem Lesevorgang kombinieren, kosten alle diese Seiten zusammen jetzt etwa 1 ms. Und indem wir mehrere Leseanforderungen gleichzeitig parallel ausführen, zahlen wir diese 1 ms Latenz effektiv nur einmal pro Batch.
Asynchrone E/A-Methoden
Das neue Subsystem kann in einem von drei Modi ausgeführt werden, die über den Parameter io_method mit den möglichen Werten „worker“ (Standard), „io_uring“ und „sync“ konfiguriert werden. Wir werden erläutern, wie die einzelnen Modi funktionieren, und dann zeigen, wie die asynchrone E/A in unserer Umgebung überwacht werden kann.
io_method = sync
Dieser Modus schaltet AIO effektiv aus. Lesevorgänge werden über dieselbe AIO-API, aber synchron ausgeführt, wobei reguläre preadv- oder pwritev-Methoden auf dem Backend-Prozess verwendet werden, der die E/A ausgegeben hat. Diese Methode verwendet keinen zusätzlichen gemeinsam genutzten Speicher und ist hauptsächlich für Regressionstests gedacht oder wenn wir vermuten, dass sich AIO falsch verhält. Sie wird auch intern als Fallback auf die synchrone E/A für Operationen verwendet, die keine asynchrone E/A verwenden können. PostgreSQL-Kernfunktionen geben einen Fehler aus, wenn eine Erweiterung versuchen würde, die asynchrone E/A über die AIO-API zu erzwingen, wenn die globale io_method auf „sync“ gesetzt ist. Verfügbare Benchmarks zeigen, dass dieser PostgreSQL 18-Modus ähnlich wie die Streaming-E/A von PostgreSQL 17 funktioniert.
io_method = io_uring (Linux only)
SELECT pg_config FROM pg_config() where pg_config::text ilike ’%liburing%’;
- Backends schreiben Anforderungen über die API in einen Submission-Ring im gemeinsam genutzten Speicher
- Der Kernel führt E/A asynchron aus und schreibt Ergebnisse in einen Completion-Ring
- Der Inhalt des Completion-Rings wird vom Backend mit weniger Kontextwechseln verarbeitet
Die Ausführung erfolgt weiterhin im selben Prozess wie bei der Methode „sync„, aber es werden Kernel-Worker-Threads für die parallele Verarbeitung verwendet. Dies ist typischerweise bei sehr schnellen NVMe-SSDs von Vorteil.
Die io_uring-Linux-Funktion hatte jedoch auch eine schwierige Sicherheitshistorie. Sie umgeht traditionelle Syscall-Audit-Pfade und war daher an einem großen Teil der Linux-Kernel-Exploits beteiligt. Google berichtete, dass 60 % der Linux-Kernel-Schwachstellen im Jahr 2022 io_uring betrafen und einige Sicherheitstools diese Art von Angriffen nicht aufdecken konnten. Daher deaktivieren einige Containerumgebungen io_uring vollständig.
io_method = worker
Dies ist die plattformübergreifende, „sichere“ Implementierung und der Standard in PostgreSQL 18. Der Mechanismus ist dem bestehenden parallelen Abfrageverarbeitung sehr ähnlich. Der Hauptunterschied besteht darin, dass Hintergrund-E/A-Worker langlebige, unabhängige Prozesse sind, die beim Serverstart erstellt werden, nicht kurzlebige Prozesse, die pro Abfrage erzeugt werden.
- Beim Serverstart erstellt der Postmaster einen Pool von E/A-Worker-Prozessen. Die Anzahl wird durch den Parameter io_workers mit einem Standardwert von 3 gesteuert. Benchmarks legen jedoch nahe, dass diese Zahl auf vielen Kernmaschinen höher sein sollte, typischerweise zwischen ¼ und ½ der verfügbaren CPU-Threads. Der beste Wert hängt von der Workload und der Speicherlatenz ab.
- Backends übermitteln Leseanforderungen in eine gemeinsam genutzte Speicher-Submission-Queue. Diese Submission-Queue ist im Allgemeinen ein Ringpuffer, in den mehrere Backends gleichzeitig schreiben können. Sie enthält nur Metadaten über die Anforderung – Handle-Indizes, nicht den vollständigen Anforderungsdatensatz. Es gibt nur eine Submission-Queue für den gesamten Cluster, nicht pro Datenbank oder pro Backend. Die tatsächlichen Details der Anforderung werden in einer separaten Speicherstruktur gespeichert.
- Es wird geprüft, ob die Anforderung synchron ausgeführt werden muss oder asynchron verarbeitet werden kann. Die synchrone Ausführung kann auch gewählt werden, wenn die Submission-Queue voll ist. Dies vermeidet Probleme mit der gemeinsam genutzten Speichernutzung unter extremer Last. Im Falle einer synchronen Ausführung verwendet der Code den Pfad für die oben beschriebene „sync“-Methode.
- Die Anforderungsübermittlung im gemeinsam genutzten Speicher weckt einen E/A-Worker auf, der die Anforderung abruft und traditionelle blockierende read() / pread()-Aufrufe ausführt. Wenn die Queue noch nicht leer ist, kann der aufgeweckte Worker 2 zusätzliche Worker aufwecken, um sie parallel zu verarbeiten. Im Code wird erwähnt, dass dies in Zukunft auf konfigurierbare N Worker erweitert werden kann. Dieses Limit hilft, das sogenannte „Thundering Herd Problem“ zu vermeiden, bei dem ein einzelner Submitter zu viele Worker aufwecken würde, was zu Chaos und Sperren für andere Backends führen würde.
- Eine Einschränkung für die asynchrone E/A ist die Tatsache, dass Worker nicht einfach von Backends geöffnete Dateideskriptoren wiederverwenden können, sondern Dateien in ihrem eigenen Kontext neu öffnen müssen. Wenn dies für einige Arten von Operationen nicht möglich ist, wird für diese spezifische Anforderung der synchrone E/A-Pfad verwendet.
- Wenn Worker eine Anforderung ohne Fehler abschließen, schreiben sie Datenblöcke in gemeinsam genutzte Puffer, legen das Ergebnis in eine Completion-Queue und signalisieren das Backend.
- Aus der Perspektive des Backends wird die E/A „asynchron“, da das „Warten“ in Worker-Prozessen stattfindet, nicht im Abfrageprozess selbst.
- Funktioniert auf allen unterstützten Betriebssystemen
- Einfache Fehlerbehandlung: Wenn ein Worker abstürzt, werden Anforderungen als fehlgeschlagen markiert, der Worker beendet und ein neuer Worker vom Postmaster erzeugt
- Vermeidet die Sicherheitsbedenken bezüglich der Linux io_uring-Schnittstelle
- Der Nachteil sind zusätzliche Kontextwechsel und mögliche Konflikte in der gemeinsam genutzten Speicher-Queue, aber für viele Workloads macht die Möglichkeit, Lesevorgänge einfach zu überlappen, das leicht wett.
- Diese Methode verbessert die Leistung auch dann, wenn alle Blöcke nur aus dem lokalen Linux-Speichercache kopiert werden, da dies jetzt parallel erfolgt
Tuning der neuen E/A-Parameter
PostgreSQL 18 fügt mehrere Parameter im Zusammenhang mit Festplatten-E/A hinzu oder aktualisiert sie. Wir haben bereits io_method und io_workers behandelt; sehen wir uns die anderen an. Weitere neue Parameter sind io_combine_limit und io_max_combine_limit. Sie steuern, wie viele Datenseiten PostgreSQL in einer einzigen AIO-Anforderung gruppiert. Größere Anforderungen führen typischerweise zu einem besseren Durchsatz, können aber auch die Latenz und die Speichernutzung erhöhen. Werte ohne Einheiten werden in 8-kB-Datenblöcken interpretiert. Mit Einheiten (kB, MB) stellen sie direkt die Größe dar – sollten jedoch Vielfache von 8 kB sein.
Der Parameter io_max_combine_limit ist eine feste Obergrenze beim Serverstart, io_combine_limit ist der vom Benutzer einstellbare Wert, der zur Laufzeit geändert werden kann, aber das Maximum nicht überschreiten darf. Die Standardwerte für beide sind 128 kB (16 Datenseiten). Die Dokumentation empfiehlt jedoch, unter Unix bis zu 1 MB (128 Datenseiten) und unter Windows 128 kB (16 Datenseiten – aufgrund von Einschränkungen in internen Windows-Puffern) einzustellen. Wir können mit höheren Werten experimentieren, aber basierend auf HW- und OS-Limits erreichen die AIO-Vorteile nach einer bestimmten Chunk-Größe ein Plateau; ein zu hohes Einstellen hilft nicht und kann sogar die Latenz erhöhen.
PostgreSQL 18 führt auch die Einstellung io_max_concurrency ein, die die maximale Anzahl von E/As steuert, die ein Prozess gleichzeitig ausführen kann. Die Standardeinstellung -1 bedeutet, dass der Wert automatisch basierend auf anderen Einstellungen ausgewählt wird, aber er darf 64 nicht überschreiten.
Ein weiterer verwandter Parameter ist effective_io_concurrency – die Anzahl der gleichzeitigen E/A-Operationen, die gleichzeitig auf dem Speicher ausgeführt werden können. Der Wertebereich liegt zwischen 1 und 1000, der Wert 0 deaktiviert asynchrone E/A-Anforderungen. Der Standardwert ist jetzt 16, einige Community-Artikel empfehlen, auf modernen SSDs bis zu 200 zu gehen. Die beste Einstellung hängt von der spezifischen Hardware und dem Betriebssystem ab, einige Artikel warnen jedoch auch davor, dass ein zu hoher Wert die E/A-Latenz für alle Abfragen erheblich erhöhen kann.
So überwachen Sie asynchrone E/A
pg_stat_activity
SELECT pid, backend_start, wait_event_type, wait_event, backend_type FROM pg_stat_activity WHERE backend_type = 'io worker'; pid | backend_start. | wait_event_type | wait_event | backend_type ------+-------------------------------+-----------------+--------------+-------------- 34 | 2025-12-09 11:44:23.852461+00 | Activity | IoWorkerMain | io worker 35 | 2025-12-09 11:44:23.852832+00 | Activity | IoWorkerMain | io worker 36 | 2025-12-09 11:44:23.853119+00 | IO | DataFileRead | io worker 37 | 2025-12-09 11:44:23.8534+00 | IO | DataFileRead | io worker
SELECT a.pid, a.usename, a.application_name, a.backend_type, a.state, a.query, ai.operation, ai.state AS aio_state, ai.length AS aio_bytes, ai.target_desc FROM pg_aios ai JOIN pg_stat_activity a ON a.pid = ai.pid ORDER BY a.backend_type, a.pid, ai.io_id; -[ RECORD 1 ]----+------------------------------------------------------------------------ pid | 58 usename | postgres application_name | psql backend_type | client backend state | active query. | explain analyze SELECT ........ operation | readv aio_state | SUBMITTED aio_bytes | 704512 target_desc | blocks 539820..539905 in file "pg_tblspc/16647/PG_18_202506291/5/16716" -[ RECORD 2 ]----+------------------------------------------------------------------------ pid | 159 usename | postgres application_name | psql backend_type | parallel worker state | active query | explain analyze SELECT ........ operation | readv aio_state | SUBMITTED aio_bytes | 704512 target_desc | blocks 536326..536411 in file "pg_tblspc/16647/PG_18_202506291/5/16716"
pg_aios: Current AIO handles
- pid: Backend, das die E/A ausgibt
- io_id, io_generation: identifizieren ein Handle über die Wiederverwendung hinweg
- state: HANDED_OUT, DEFINED, STAGED, SUBMITTED, COMPLETED_IO, COMPLETED_SHARED, COMPLETED_LOCAL
- operation: invalid, readv (vektorisierter Lesevorgang) oder writev (vektorisierter Schreibvorgang)
- off, length: Offset und Größe der E/A-Operation
- target, target_desc: was wir lesen/schreiben (typischerweise Relationen)
- result: UNKNOWN, OK, PARTIAL, WARNING, ERROR
-- Zusammenfassung der aktuellen AIO-Handles nach Status und Ergebnis SELECT state, result, count(*) AS cnt, pg_size_pretty(sum(length)) AS total_size FROM pg_aios GROUP BY state, result ORDER BY state, result; state | result | cnt | total_size ------------------+---------+-----+------------ COMPLETED_SHARED | OK | 1 | 688 kB SUBMITTED | UNKNOWN | 6 | 728 kB -- In-flight async I/O handles SELECT COUNT(*) AS aio_handles, SUM(length) AS aio_bytes FROM pg_aios; aio_handles | aio_bytes -------------+----------- 7 | 57344 -- Sessions currently waiting on I/O SELECT COUNT(*) AS sessions_waiting_on_io FROM pg_stat_activity WHERE wait_event_type = 'IO'; sessions_waiting_on_io ------------------------ 9
SELECT pid, state, operation, pg_size_pretty(length) AS io_size, target_desc, result FROM pg_aios ORDER BY pid, io_id; pid | state | operation | io_size | target_desc | result -----+-----------+-----------+------------+-------------------------------------------------------------------------+--------- 51 | SUBMITTED | readv | 688 kB | blocks 670470..670555 in file "pg_tblspc/16647/PG_18_202506291/5/16716" | UNKNOWN 63 | SUBMITTED | readv | 8192 bytes | block 1347556 in file "pg_tblspc/16647/PG_18_202506291/5/16719" | UNKNOWN 65 | SUBMITTED | readv | 688 kB | blocks 671236..671321 in file "pg_tblspc/16647/PG_18_202506291/5/16716" | UNKNOWN 66 | SUBMITTED | readv | 8192 bytes | block 1344674 in file "pg_tblspc/16647/PG_18_202506291/5/16719" | UNKNOWN 67 | SUBMITTED | readv | 8192 bytes | block 1337819 in file "pg_tblspc/16647/PG_18_202506291/5/16719" | UNKNOWN 68 | SUBMITTED | readv | 688 kB | blocks 672002..672087 in file "pg_tblspc/16647/PG_18_202506291/5/16716" | UNKNOWN 69 | SUBMITTED | readv | 688 kB | blocks 673964..674049 in file "pg_tblspc/16647/PG_18_202506291/5/16716" | UNKNOWN
pg_stat_io: Cumulative I/O stats
SELECT backend_type, context, sum(reads) AS reads,
pg_size_pretty(sum(read_bytes)) AS read_bytes,
round(sum(read_time)::numeric, 2) AS read_ms, sum(writes) AS writes,
pg_size_pretty(sum(write_bytes)) AS write_bytes,
round(sum(write_time)::numeric, 2) AS write_ms, sum(extends) AS extends,
pg_size_pretty(sum(extend_bytes)) AS extend_bytes
FROM pg_stat_io
WHERE object = 'relation' AND backend_type IN ('client backend')
GROUP BY backend_type, context
ORDER BY backend_type, context;
backend_type | context | reads | read_bytes | read_ms | writes | write_bytes | write_ms | extends | extend_bytes
----------------+-----------+---------+------------+-----------+--------+-------------+----------+---------+--------------
client backend | bulkread | 13833 | 9062 MB | 124773.28 | 0 | 0 bytes | 0.00 | |
client backend | bulkwrite | 0 | 0 bytes | 0.00 | 0 | 0 bytes | 0.00 | 0 | 0 bytes
client backend | init | 0 | 0 bytes | 0.00 | 0 | 0 bytes | 0.00 | 0 | 0 bytes
client backend | normal | 2265214 | 17 GB | 553940.57 | 0 | 0 bytes | 0.00 | 0 | 0 bytes
client backend | vacuum | 0 | 0 bytes | 0.00 | 0 | 0 bytes | 0.00 | 0 | 0 bytes
-- Top-Tabellen nach gelesenen Heap-Blöcken und Cache-Trefferrate
SELECT relid::regclass AS table_name, heap_blks_read, heap_blks_hit,
ROUND( CASE WHEN heap_blks_read + heap_blks_hit = 0 THEN 0
ELSE heap_blks_hit::numeric / (heap_blks_read + heap_blks_hit) * 100 END, 2) AS cache_hit_pct
FROM pg_statio_user_tables
ORDER BY heap_blks_read DESC LIMIT 20;
table_name | heap_blks_read | heap_blks_hit | cache_hit_pct
----------------------+----------------+---------------+---------------
table1 | 18551282 | 3676632 | 16.54
table2 | 1513673 | 102222970 | 98.54
table3 | 19713 | 1034435 | 98.13
...
-- Top-Indizes nach gelesenen Indexblöcken und Cache-Trefferrate
SELECT relid::regclass AS table_name, indexrelid::regclass AS index_name,
idx_blks_read, idx_blks_hit
FROM pg_statio_user_indexes
ORDER BY idx_blks_read DESC LIMIT 20;
table_name | index_name | idx_blks_read | idx_blks_hit
------------+-----------------+---------------+--------------
table1 | idx_table1_date | 209289 | 141
table2 | table2_pkey | 37221 | 1223747
table3 | table3_pkey | 9825 | 3143947
...
SELECT pg_stat_reset_shared(‚io‘);
Führen Sie dann unsere Arbeitslast aus und fragen Sie
pg_stat_io
erneut ab, um zu sehen, wie viele Bytes gelesen/geschrieben wurden und wie viel Zeit für das Warten auf E/A aufgewendet wurde.
Fazit
PostgreSQL ist ein eingetragenes Warenzeichen der PostgreSQL Community Association of Canada.
In der Vergangenheit gab es viele Diskussionen über die Verwendung von UUID als Primärschlüssel in PostgreSQL. Für einige Anwendungen reicht selbst eine BIGINT-Spalte nicht aus: Es handelt sich um eine vorzeichenbehaftete 8-Byte-Ganzzahl mit einem Bereich von −9.223.372.036.854.775.808 bis +9.223.372.036.854.775.807. Obwohl diese Werte groß genug erscheinen, wird diese Zahl weniger beeindruckend, wenn wir an Webdienste denken, die täglich Milliarden oder mehr Datensätze sammeln. Einfache Ganzzahlwerte können auch zu Wertkonflikten in verteilten Systemen, in Data Lakehouses beim kombinieren von Daten aus mehreren Quelldatenbanken usw. führen.
Das Hauptproblem bei UUIDv4 als Primärschlüssel in PostgreSQL war jedoch nicht der fehlende Bereich, sondern die vollständige Zufälligkeit der Werte. Diese Zufälligkeit führt zu häufigen B-Baum-Seitenaufteilungen, einem stark fragmentierten Primärschlüsselindex und somit zu vielen zufälligen Festplatten-I/Os. Es gab bereits viele Artikel und Konferenzvorträge, die dieses Problem beschrieben haben. Was viele dieser Ressourcen jedoch nicht taten, war, tief in die On-Disk-Strukturen einzutauchen. Das wollte ich hier untersuchen.

Was sind UUIDs
UUID (Universally Unique Identifier) ist ein 16-Byte-Ganzzahlwert (128 Bit), der 2^128 mögliche Kombinationen aufweist (ungefähr 3,4 × 10^38). Dieser Bereich ist so groß, dass für die meisten Anwendungen die Wahrscheinlichkeit einer doppelten UUID praktisch null ist. Wikipedia zeigt eine Berechnung, die demonstriert, dass die Wahrscheinlichkeit, ein Duplikat innerhalb von 103 Billionen Version-4-UUIDs zu finden, etwa eins zu einer Milliarde beträgt. Eine weitere oft zitierte Faustregel besagt, dass man, um eine 50%ige Chance auf eine Kollision zu haben, etwa 1 Milliarde UUIDs pro Sekunde über etwa 86 Jahre generieren müsste.
Werte werden üblicherweise als 36-stelliger String mit Hexadezimalziffern und Bindestrichen dargestellt, zum Beispiel: f47ac10b-58cc-4372-a567-0e02b2c3d479. Das kanonische Layout ist 8-4-4-4-12 Zeichen. Das erste Zeichen im dritten Block und das erste Zeichen im vierten Block haben eine besondere Bedeutung: xxxxxxxx-xxxx-Vxxx-Wxxx-xxxxxxxxxxxx – V kennzeichnet die UUID-Version (4 für UUIDv4, 7 für UUIDv7 usw.), W kodiert die Variante in ihren oberen 2 oder 3 Bits (die Layout-Familie der UUID).
Bis PostgreSQL 18 war die gängige Methode zur Generierung von UUIDs in PostgreSQL die Verwendung von Version 4 (zum Beispiel über gen_random_uuid() oder uuid_generate_v4() aus Erweiterungen). PostgreSQL 18 führt native Unterstützung für die neue zeitlich geordnete UUIDv7 über die Funktion uuidv7() ein und fügt auch uuidv4() als integrierten Alias für die ältere Funktion gen_random_uuid() hinzu. UUID Version 4 wird vollständig zufällig generiert (abgesehen von den festen Versions- und Variantenbits), sodass es keine inhärente Reihenfolge in den Werten gibt. UUID Version 7 generiert Werte, die zeitlich geordnet sind, da die ersten 48 Bits einen Big-Endian Unix-Epoch-Zeitstempel mit ungefähr Millisekunden-Granularität enthalten, gefolgt von zusätzlichen Sub-Millisekunden-Bits und Zufälligkeit.

Testaufbau in PostgreSQL 18
Ich werde konkrete Ergebnisse anhand eines einfachen Testaufbaus zeigen – 2 verschiedene Tabellen mit der Spalte „id“, die einen generierten UUID-Wert (entweder v4 oder v7) enthält, der als Primärschlüssel verwendet wird, und der Spalte „ord“ mit sequenziell generiertem Bigint, wobei die Reihenfolge der Zeilenerstellung beibehalten wird.
-- UUIDv4 (completely random keys)
CREATE TABLE uuidv4_demo (
id uuid PRIMARY KEY DEFAULT uuidv4(), -- alias of gen_random_uuid()
ord bigint GENERATED ALWAYS AS IDENTITY
);
-- UUIDv7 (time-ordered keys)
CREATE TABLE uuidv7_demo (
id uuid PRIMARY KEY DEFAULT uuidv7(),
ord bigint GENERATED ALWAYS AS IDENTITY
);
-- 1M rows with UUIDv4
INSERT INTO uuidv4_demo (id) SELECT uuidv4() FROM generate_series(1, 1000000);
-- 1M rows with UUIDv7
INSERT INTO uuidv7_demo (id) SELECT uuidv7() FROM generate_series(1, 1000000);
VACUUM ANALYZE uuidv4_demo;
VACUUM ANALYZE uuidv7_demo;
Performance auf Abfrageebene: EXPLAIN ANALYZE
Als ersten Schritt vergleichen wir die Kosten der Sortierung nach UUID für die beiden Tabellen:
-- UUIDv4 EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM uuidv4_demo ORDER BY id; Index Scan using uuidv4_demo_pkey on uuidv4_demo (cost=0.42..60024.31 rows=1000000 width=24) (actual time=0.031..301.163 rows=1000000.00 loops=1) Index Searches: 1 Buffers: shared hit=1004700 read=30 Planning Time: 0.109 ms Execution Time: 318.005 ms -- UUIDv7 EXPLAIN (ANALYZE, BUFFERS) SELECT * FROM uuidv7_demo ORDER BY id; Index Scan using uuidv7_demo_pkey on uuidv7_demo (cost=0.42..36785.43 rows=1000000 width=24) (actual time=0.013..96.177 rows=1000000.00 loops=1) Index Searches: 1 Buffers: shared hit=2821 read=7383 Planning Time: 0.040 ms Execution Time: 113.305 ms
Die genauen Pufferzahlen hängen von Cache-Effekten ab, aber eines ist in diesem Durchlauf klar: Der Index-Scan über UUIDv7 benötigt etwa 100-mal weniger Puffer-Treffer und ist etwa dreimal schneller (113 ms vs. 318 ms) für dieselbe Million-Zeilen-ORDER BY id. Dies ist das erste Anzeichen dafür, dass UUIDv7 eine sehr praktikable Lösung für einen Primärschlüssel ist, wenn wir eine BIGINT-Spalte durch etwas ersetzen müssen, das einen viel größeren Speicherplatz und eine höhere Einzigartigkeit bietet, während es sich aus Sicht des Index immer noch wie ein sequenzieller Schlüssel verhält.
Einfügegeschwindigkeit – einfaches Benchmarking
Ursprünglich wollte ich ausgefeiltere Tests durchführen, aber selbst ein sehr einfacher, naiver Benchmark zeigte einen enormen Unterschied in der Einfügegeschwindigkeit. Ich verglich die Zeit, die benötigt wurde, um 50 Millionen Zeilen in eine leere Tabelle einzufügen, und dann noch einmal in eine Tabelle mit 50 Millionen vorhandenen Zeilen.
INSERT INTO uuidv4_demo (id) SELECT uuidv4() FROM generate_series(1, 50000000); INSERT INTO uuidv7_demo (id) SELECT uuidv7() FROM generate_series(1, 50000000); -- UUID v4 -- UUID v7 Empty table Insert time: 1239839.702 ms (20:39.840) Insert time: 106343.314 ms (01:46.343) Table size: 2489 MB Table size: 2489 MB Index size: 1981 MB Index size: 1504 MB Table with 50M rows Insert time: 2776880.790 ms (46:16.881) Insert time: 100354.087 ms (01:40.354) Table size: 4978 MB Table size: 4978 MB Index size: 3956 MB Index size: 3008 MB
Wie wir sehen können, ist die Einfügegeschwindigkeit radikal unterschiedlich. Das Einfügen der ersten 50 Millionen Zeilen in eine leere Tabelle dauerte für UUIDv7 nur 1:46 Minuten, aber bereits 20 Minuten für UUIDv4. Die zweite Charge zeigte sogar einen 2-mal größeren Unterschied.
Wie Werte in der Tabelle verteilt sind
Diese Ergebnisse deuten auf enorme Unterschiede in den Indizes hin. Lassen Sie uns dies analysieren. Zuerst werden wir überprüfen, wie die Werte in der Tabelle verteilt sind. Ich verwende die folgende Abfrage für beide Tabellen (nur den Tabellennamen wechseln):
SELECT row_number() OVER () AS seq_in_uuid_order, id, ord, ctid FROM uuidv4_demo ORDER BY id LIMIT 20;
Die Spalte seq_in_uuid_order ist lediglich die Zeilennummer in UUID-Reihenfolge, ord ist die Einfügereihenfolge, ctid zeigt den physischen Speicherort jedes Tupels im Heap an: (block_number, offset_in_block).
UUIDv4: random UUID order ⇒ random heap access
Wie sehen die Ergebnisse für UUIDv4 aus?
seq_in_uuid_order | id | ord | ctid
-------------------+--------------------------------------+--------+------------
1 | 00000abf-cc8e-4cb2-a91a-701a3c96bd36 | 673969 | (4292,125)
2 | 00001827-16fe-4aee-9bce-d30ca49ceb1d | 477118 | (3038,152)
3 | 00001a84-6d30-492f-866d-72c3b4e1edff | 815025 | (5191,38)
4 | 00002759-21d1-4889-9874-4a0099c75286 | 879671 | (5602,157)
5 | 00002b44-b1b5-473f-b63f-7554fa88018d | 729197 | (4644,89)
6 | 00002ceb-5332-44f4-a83b-fb8e9ba73599 | 797950 | (5082,76)
7 | 000040e2-f6ac-4b5e-870a-63ab04a5fa39 | 160314 | (1021,17)
8 | 000053d7-8450-4255-b320-fee8d6246c5b | 369644 | (2354,66)
9 | 00009c78-6eac-4210-baa9-45b835749838 | 463430 | (2951,123)
10 | 0000a118-f98e-4e4a-acb3-392006bcabb8 | 96325 | (613,84)
11 | 0000be99-344b-4529-aa4c-579104439b38 | 454804 | (2896,132)
12 | 00010300-fcc1-4ec4-ae16-110f93023068 | 52423 | (333,142)
13 | 00010c33-a4c9-4612-ba9a-6c5612fe44e6 | 82935 | (528,39)
14 | 00011fa2-32ce-4ee0-904a-13991d451934 | 988370 | (6295,55)
15 | 00012920-38c7-4371-bd15-72e2996af84d | 960556 | (6118,30)
16 | 00014240-7228-4998-87c1-e8b23b01194a | 66048 | (420,108)
17 | 00014423-15fc-42ca-89bd-1d0acf3e5ad2 | 250698 | (1596,126)
18 | 000160b9-a1d8-4ef0-8979-8640025c0406 | 106463 | (678,17)
19 | 0001711a-9656-4628-9d0c-1fb40620ba41 | 920459 | (5862,125)
20 | 000181d5-ee13-42c7-a9e7-0f2c52faeadb | 513817 | (3272,113)
Die Werte sind vollständig zufällig verteilt. Das Lesen von Zeilen in UUID-Reihenfolge ist hier praktisch sinnlos und führt direkt zu zufälligen Heap-Zugriffen bei Abfragen, die den Primärschlüsselindex verwenden.
UUIDv7: UUID-Reihenfolge folgt der Einfügereihenfolge
Andererseits werden UUIDv7-Werte in einer klaren Reihenfolge generiert:
seq_in_uuid_order | id | ord | ctid
-------------------+--------------------------------------+-----+--------
1 | 019ad94d-0127-7aba-b9f6-18620afdea4a | 1 | (0,1)
2 | 019ad94d-0131-72b9-823e-89e41d1fad73 | 2 | (0,2)
3 | 019ad94d-0131-7384-b03d-8820be60f88e | 3 | (0,3)
4 | 019ad94d-0131-738b-b3c0-3f91a0b223a8 | 4 | (0,4)
5 | 019ad94d-0131-7391-ab84-a719ca98accf | 5 | (0,5)
6 | 019ad94d-0131-7396-b41d-7f9f27a179c4 | 6 | (0,6)
7 | 019ad94d-0131-739b-bdb3-4659aeaafbdd | 7 | (0,7)
8 | 019ad94d-0131-73a0-b271-7dba06512231 | 8 | (0,8)
9 | 019ad94d-0131-73a5-8911-5ec5d446c8a9 | 9 | (0,9)
10 | 019ad94d-0131-73aa-a4a3-0e5c14f09374 | 10 | (0,10)
11 | 019ad94d-0131-73af-ac4b-3710e221390e | 11 | (0,11)
12 | 019ad94d-0131-73b4-85d6-ed575d11e9cf | 12 | (0,12)
13 | 019ad94d-0131-73b9-b802-d5695f5bf781 | 13 | (0,13)
14 | 019ad94d-0131-73be-bcb0-b0775dab6dd4 | 14 | (0,14)
15 | 019ad94d-0131-73c3-9ec8-c7400b5c8983 | 15 | (0,15)
16 | 019ad94d-0131-73c8-b067-435258087b3a | 16 | (0,16)
17 | 019ad94d-0131-73cd-a03f-a28092604fb1 | 17 | (0,17)
18 | 019ad94d-0131-73d3-b4d5-02516d5667b5 | 18 | (0,18)
19 | 019ad94d-0131-73d8-9c41-86fa79f74673 | 19 | (0,19)
20 | 019ad94d-0131-73dd-b9f1-dcd07598c35d | 20 | (0,20)
Hier folgen seq_in_uuid_order, ord und ctid alle schön aufeinander – ord erhöht sich für jede Zeile um 1, ctid bewegt sich sequenziell durch die erste Heap-Seite, und die UUIDs selbst sind aufgrund des Zeitstempelpräfixes monoton. Für Index-Scans auf dem Primärschlüssel bedeutet dies, dass Postgres den Heap viel sequenzieller durchlaufen kann als mit UUIDv4.
Wie sequenziell sind diese Werte statistisch?
Nach VACUUM ANALYZE frage ich den Planer, was er über die Korrelation zwischen ID und der physischen Reihenfolge denkt:
SELECT
tablename,
attname,
correlation
FROM pg_stats
WHERE tablename IN ('uuidv4_demo', 'uuidv7_demo')
AND attname = 'id'
ORDER BY tablename, attname;
Ergebnis:
tablename | attname | correlation
-------------+---------+---------------
uuidv4_demo | id | -0.0024808696
uuidv7_demo | id | 1
Die Statistiken bestätigen, was wir gerade gesehen haben:
- Für uuidv4_demo.id ist die Korrelation im Wesentlichen 0 ⇒ Werte sind zufällig in Bezug auf die Heap-Reihenfolge.
- Für uuidv7_demo.id ist die Korrelation 1 ⇒ perfekte Übereinstimmung zwischen UUID-Reihenfolge und physischer Zeilenreihenfolge in diesem Testlauf.
Diese hohe Korrelation ist genau der Grund, warum UUIDv7 als Primärschlüssel für B-Baum-Indizes so attraktiv ist.
Primärschlüsselindizes: Größe, Leaf Pages, Dichte, Fragmentierung
Als Nächstes betrachte ich die Primärschlüsselindizes – ihre Größe, Anzahl der Leaf Pages, Dichte und Fragmentierung – mithilfe von pgstatindex:
SELECT 'uuidv4_demo_pkey' AS index_name, (pgstatindex('uuidv4_demo_pkey')).*;
index_name | uuidv4_demo_pkey
version | 4
tree_level | 2
index_size | 40026112
root_block_no. | 295
internal_pages | 24
leaf_pages. | 4861
empty_pages | 0
deleted_pages | 0
avg_leaf_density | 71
leaf_fragmentation | 49.99
SELECT 'uuidv7_demo_pkey' AS index_name, (pgstatindex('uuidv7_demo_pkey')).*;
index_name | uuidv7_demo_pkey
version | 4
tree_level | 2
index_size | 31563776
root_block_no | 295
internal_pages. | 20
leaf_pages | 3832
empty_pages | 0
deleted_pages | 0
avg_leaf_density | 89.98 -- i.e. standard 90% fillfactor
leaf_fragmentation | 0
Wir können sofort erkennen, dass der Primärschlüsselindex auf UUIDv4 etwa 26–27 % größer ist:
- index_size beträgt ~40 MB vs. ~31,6 MB
- leaf_pages sind 4861 vs. 3832 (wiederum etwa 26–27 % mehr)
- Leaf Pages im v4-Index haben eine geringere durchschnittliche Dichte (71 vs. ~90)
- leaf_fragmentation für v4 beträgt etwa 50 %, während sie für v7 0 ist
UUIDv4 zwingt den B-Baum also dazu, mehr Pages zu allozieren und diese weniger voll zu halten, und fragmentiert die Blattebene wesentlich stärker.
Tiefere Indexanalyse mit bt_multi_page_stats
Um tiefer einzusteigen, habe ich die B-Baum-Indizes Seite für Seite untersucht und einige Statistiken erstellt. Ich habe die folgende Abfrage für beide Indizes verwendet (nur den Indexnamen im CTE ändern). Die Abfrage berechnet die minimale, maximale und durchschnittliche Anzahl von Tupeln pro Index-Pages und überprüft auch, wie sequenziell Pages in der Indexdatei gespeichert sind:
WITH leaf AS (
SELECT *
FROM bt_multi_page_stats('uuidv4_demo_pkey', 1, -1) -- from block 1 to end
WHERE type = 'l'
)
SELECT
count(*) AS leaf_pages,
min(blkno) AS first_leaf_blk,
max(blkno) AS last_leaf_blk,
max(blkno) - min(blkno) + 1 AS leaf_span,
round( count(*)::numeric / (max(blkno) - min(blkno) + 1), 3) AS leaf_density_by_span,
min(live_items) AS min_tuples_per_page,
max(live_items) AS max_tuples_per_page,
avg(live_items)::numeric(10,2) AS avg_tuples_per_page,
sum(CASE WHEN btpo_next = blkno + 1 THEN 1 ELSE 0 END) AS contiguous_links,
sum(CASE WHEN btpo_next 0 AND btpo_next blkno + 1 THEN 1 ELSE 0 END) AS non_contiguous_links
FROM leaf;Ergebnisse für UUIDv4:
-- uuidv4_demo_pkey
leaf_pages | 4861
first_leaf_blk | 1
last_leaf_blk | 4885
leaf_span | 4885
leaf_density_by_span | 0.995
min_tuples_per_page | 146
max_tuples_per_page | 291
avg_tuples_per_page | 206.72
contiguous_links | 0
non_contiguous_links | 4860
Ergebnisse für UUIDv7:
-- uuidv7_demo_pkey
leaf_pages | 3832
first_leaf_blk | 1
last_leaf_blk | 3852
leaf_span | 3852
leaf_density_by_span | 0.995
min_tuples_per_page | 109
max_tuples_per_page | 262
avg_tuples_per_page | 261.96
contiguous_links | 3812
non_contiguous_links | 19
Wie wir sehen können, hat der UUIDv4-Index mehr Pages, die sich über einen größeren Bereich von Blöcken verteilen, und obwohl er eine höhere minimale und maximale Anzahl von Tupeln pro Seite aufweist, ist seine durchschnittliche Anzahl von Tupeln pro Page (206,72) signifikant niedriger als für UUIDv7 (261,96).
Diese Zahlen können jedoch das Gesamtbild verschleiern. Schauen wir uns also Histogramme an, die die Anzahl der Tupel in Pages visualisieren. Dafür werde ich die folgende Abfrage mit Buckets zwischen 100 und 300 verwenden und nur nicht-leere Ergebnisse auflisten:
WITH leaf AS (
SELECT live_items
FROM bt_multi_page_stats('uuidv4_demo_pkey', 1, -1)
WHERE type = 'l'
),
buckets AS (
-- bucket lower bounds: 100, 110, ..., 290
SELECT generate_series(100, 290, 10) AS bucket_min
)
SELECT
b.bucket_min AS bucket_from,
b.bucket_min + 9 AS bucket_to,
COUNT(l.live_items) AS page_count
FROM buckets b
LEFT JOIN leaf l
ON l.live_items BETWEEN b.bucket_min AND b.bucket_min + 9
GROUP BY b.bucket_min HAVING count(l.live_items) > 0
ORDER BY b.bucket_min;Ergebnis für UUIDv4:
bucket_from | bucket_to | page_count
-------------+-----------+------------
140 | 149 | 159
150 | 159 | 435
160 | 169 | 388
170 | 179 | 390
180 | 189 | 427
190 | 199 | 466
200 | 209 | 430
210 | 219 | 387
220 | 229 | 416
230 | 239 | 293
240 | 249 | 296
250 | 259 | 228
260 | 269 | 214
270 | 279 | 171
280 | 289 | 140
290 | 299 | 21
Ergebnis für UUIDv7:
bucket_from | bucket_to | page_count
-------------+-----------+------------
100 | 109 | 1
260 | 269 | 3831
Diese Ergebnisse demonstrieren eindrucksvoll die enorme Fragmentierung des UUIDv4-Index und die stabile, kompakte Struktur des UUIDv7-Index. Die niedrigsten Buckets im UUIDv4-Histogramm zeigen Fälle von halb leeren Blattindexseiten (leaf index pages), andererseits überschreiten Seiten mit mehr als 270 Tupeln den 90 % Füllfaktor, da PostgreSQL den verbleibenden freien Speicherplatz nutzt, um Splits zu vermeiden. Im UUIDv7-Index sind alle Pages bis auf eine (die allerletzte im Baum) bis zum 90 % Standard-Füllfaktor gefüllt.
Ein weiteres wichtiges Ergebnis findet sich in den letzten beiden Spalten der Indexstatistiken:
- Für UUIDv4: contiguous_links = 0, non_contiguous_links = 4860
- Für UUIDv7: contiguous_links = 3812, non_contiguous_links = 19
btpo_next = blkno + 1 bedeutet, dass die nächste Page in der logischen B-Baum-Reihenfolge auch der nächste physische Block ist. Bei UUIDv4 geschieht dies in diesem Test nie – die Page sind vollständig fragmentiert und zufällig über die Indexstruktur verteilt. Bei UUIDv7 sind fast alle Pages zusammenhängend, d.h. sie folgen schön aufeinander.
Wenn wir den tatsächlichen Inhalt der Pages untersuchen, können wir sofort die Zufälligkeit von UUIDv4 im Vergleich zum sequenziellen Verhalten von UUIDv7 erkennen: UUIDv4-Pages verweisen auf Heap-Tupel, die über die gesamte Tabelle verstreut sind, während UUIDv7-Pages dazu neigen, auf enge Bereiche von Heap-Seiten zu verweisen. Das Ergebnis ist dasselbe Muster, das wir zuvor beim direkten Betrachten von ctid aus der Tabelle gesehen haben, daher werde ich die Roh-Dumps hier nicht wiederholen.
Ein kleiner Haken: eingebetteter Zeitstempel in UUIDv7
Es gibt einen kleinen Haken bei UUIDv7-Werten: Sie legen einen Zeitstempel der Erstellung offen. PostgreSQL 18 macht dies explizit über uuid_extract_timestamp():
SELECT
id,
uuid_extract_timestamp(id) AS created_at_from_uuid
FROM uuidv7_demo
ORDER BY ord
LIMIT 5;
Beispielergebnisse:
id | created_at_from_uuid
--------------------------------------+----------------------------
019ad94d-0127-7aba-b9f6-18620afdea4a | 2025-12-01 09:44:53.799+00
019ad94d-0131-72b9-823e-89e41d1fad73 | 2025-12-01 09:44:53.809+00
019ad94d-0131-7384-b03d-8820be60f88e | 2025-12-01 09:44:53.809+00
019ad94d-0131-738b-b3c0-3f91a0b223a8 | 2025-12-01 09:44:53.809+00
019ad94d-0131-7391-ab84-a719ca98accf | 2025-12-01 09:44:53.809+00
Betrachten wir die gesamte Wertefolge, können wir die Zeitdifferenzen zwischen den Datensatz-Erstellungen direkt aus den UUIDs analysieren, ohne eine separate Zeitstempelspalte. Für einige Anwendungen könnte dies als potenzielles Informationsleck angesehen werden (z. B. die Offenlegung ungefährer Erstellungszeiten oder Anfrageraten), während es vielen anderen höchstwahrscheinlich egal sein wird.
Zusammenfassung
- UUIDs bieten einen enormen Bezeichnerraum (128 Bit, ~3,4 × 10^38 Werte), bei dem die Wahrscheinlichkeit einer Kollision für reale Workloads vernachlässigbar ist.
- Traditionelle UUIDv4-Schlüssel sind vollständig zufällig. Wenn sie als Primärschlüssel in PostgreSQL verwendet werden, neigen sie dazu:
- B-Baum-Indizes zu fragmentieren
- die Dichte der Pages zu verringern
- stark zufällige Heap-Zugriffsmuster und mehr zufällige I/O zu verursachen
- UUIDv7, nativ in PostgreSQL 18 als uuidv7() eingeführt, behält den 128-Bit-Raum bei, ordnet die Bits jedoch so neu an, dass:
- die höchstwertigen Bits einen Unix-Zeitstempel mit Millisekundenpräzision (plus Sub-Millisekunden-Bruchteil) enthalten
- die restlichen Bits zufällig bleiben
- In praktischen Tests mit 1 Million Zeilen pro Tabelle:
- Der UUIDv7-Primärschlüsselindex war etwa 26–27 % kleiner, mit weniger Pages und einer viel höheren durchschnittlichen Blattdichte
- Pages im UUIDv7-Index waren überwiegend physisch zusammenhängend, während die UUIDv4-Pages vollständig fragmentiert waren
- Eine ORDER BY id-Abfrage über UUIDv7 war in meinem Durchlauf etwa dreimal schneller als dieselbe Abfrage über UUIDv4, dank besserer Indexlokalität und sequenziellerem Heap-Zugriff
Der Kompromiss besteht darin, dass UUIDv7 einen Zeitstempel einbettet, der ungefähre Erstellungszeiten offenlegen könnte, aber für die meisten Anwendungsfälle ist dies akzeptabel oder sogar nützlich. UUIDv7 verbessert also die Leistung und das physische Layout von UUID-Primärschlüsseln in PostgreSQL erheblich, nicht indem es die Zufälligkeit aufgibt, sondern indem es ein zeitlich geordnetes Präfix hinzufügt. In PostgreSQL 18 bietet uns das das Beste aus beiden Welten: den riesigen Bezeichnerraum und die Vorteile der verteilten Generierung von UUIDs, mit einem Indexverhalten, das einem klassischen sequenziellen BIGINT-Primärschlüssel viel näher kommt.
PostgreSQL ist eine Open-Source-Datenbank, die von den PostgreSQL-Entwicklern bereitgestellt wird. Das PostgreSQL-Elefantenlogo („Slonik“), Postgres und PostgreSQL sind eingetragene Marken der PostgreSQL Community Association.
Wir bei credativ bieten umfassende Support- und Beratungsleistungen für den Betrieb von PostgreSQL und anderen Open-Source-Systemen an.
Die European PostgreSQL Conference (PGConf.EU) ist eine der größten PostgreSQL-Veranstaltungen weltweit. Dieses Jahr fand sie vom 21. bis 24. Oktober in Riga, Lettland, statt. Unser Unternehmen, die credativ GmbH, war Bronzesponsor der Konferenz, und ich hatte das Privileg, credativ mit meinem Vortrag „Database in Distress: Testing and Repairing Different Types of Database Corruption“ zu vertreten. Zusätzlich war ich am Donnerstag und Freitag als Session-Host tätig. Die Konferenz selbst deckte ein breites Spektrum an PostgreSQL-Themen ab – von Cloud-nativen Bereitstellungen bis zur KI-Integration, von großen Migrationen bis zur Ausfallsicherheit. Nachfolgend finden Sie Höhepunkte der von mir besuchten Sessions, nach Tagen geordnet.
Mein Vortrag über Datenbankkorruption
Ich präsentierte meinen Vortrag am Freitagnachmittag. Darin tauchte ich in reale Fälle von PostgreSQL-Datenbankkorruption ein, denen ich in den letzten zwei Jahren begegnet bin. Um diese Probleme zu untersuchen, entwickelte ich ein Python-Tool, das Datenbankseiten absichtlich beschädigt, und untersuchte anschließend die Ergebnisse mithilfe der PostgreSQL-Erweiterung pageinspect. Während des Vortrags demonstrierte ich verschiedene Korruptionsszenarien und die von ihnen erzeugten Fehler und erklärte, wie jeder Fall zu diagnostizieren ist. Ein wichtiger Punkt war, dass PostgreSQL 18 Daten-Checksums standardmäßig bei initdb aktiviert. Checksums ermöglichen es, beschädigte Seiten während der Wiederherstellung zu erkennen und sicher „auf Null zu setzen“ (beschädigte Daten zu überspringen). Ohne Checksums können nur Seiten mit eindeutig beschädigten Headern automatisch mit der Einstellung zero_damaged_pages = on entfernt werden. Andere Arten von Korruption erfordern eine sorgfältige manuelle Wiederherstellung. Abschließend schlug ich Verbesserungen (im Code oder in den Einstellungen) vor, um die Wiederherstellung auf Clustern ohne Checksums zu erleichtern.


Dienstag: Kubernetes- und KI-Gipfel
Der Dienstag begann mit zwei halbtägigen Gipfeltreffen. Der PostgreSQL on Kubernetes Summit untersuchte den Betrieb von Postgres in Cloud-nativen Umgebungen. Die Referenten verglichen Kubernetes-Operatoren (CloudNativePG, Crunchy, Zalando usw.), Backup/Recovery in Kubernetes, Skalierungsstrategien, Monitoring und Zero-Downtime-Upgrades. Sie diskutierten Operator-Architekturen und Multi-Tenant-DBaaS-Anwendungsfälle. Die Teilnehmer erhielten praktische Einblicke in die Kompromisse verschiedener Operatoren und wie Kubernetes-basiertes Postgres für Hochverfügbarkeit betrieben werden kann.
Im PostgreSQL & AI Summit untersuchten Experten die Rolle von Postgres in KI-Anwendungen. Zu den Themen gehörten Vektorsuche (z. B. pgvector), hybride Suche, die Nutzung von Postgres als Kontextspeicher für KI-Agenten, konversationelle Abfrageschnittstellen und sogar die Optimierung von Postgres mit maschinellem Lernen. Die Referenten teilten Best Practices und Integrationsstrategien für den Aufbau KI-gesteuerter Lösungen mit Postgres. Kurz gesagt, der Gipfel untersuchte, wie PostgreSQL KI-Workloads dienen kann (und umgekehrt) und welche neuen Funktionen oder Erweiterungen für KI-Anwendungsfälle entstehen.
Mittwoch: Migrationen, Modellierung und Performance
Joaquim Oliveira (European Space Agency) erörterte die Verlagerung von Astronomie-Datensätzen (von den ESA-Missionen Gaia und Euclid) von Greenplum. Das Team erwog sowohl die Skalierung mit Citus als auch den Umzug in das neue Greenplum-basierte Cloud-Warehouse von EDB. Er behandelte die praktischen Vor- und Nachteile jedes Ansatzes sowie die betrieblichen Änderungen, die für die Neugestaltung solcher Exascale-Workloads erforderlich sind. Die wichtigste Erkenntnis war die Notwendigkeit, Architektur, Tools und administrative Änderungen zu planen, bevor eine Petabyte-Skala-Migration durchgeführt wird.
Boriss Mejias (EDB) betonte, dass die Datenmodellierung für Softwareprojekte von grundlegender Bedeutung ist. Anhand einer Schach-Turnier-Anwendung zeigte er, wie PostgreSQL die Datenintegrität durchsetzen kann. Durch die sorgfältige Auswahl von Datentypen und Constraints können Entwickler einen Großteil der Geschäftslogik direkt im Schema einbetten. Der Vortrag demonstrierte, wie man „PostgreSQL die Datenintegrität garantieren lässt“ und Anwendungslogik auf der Datenbankebene aufbaut.
Roberto Mello (Snowflake) beleuchtete die vielen Verbesserungen bei Optimierern und der Ausführung in Postgres 18. Zum Beispiel eliminiert der Planer nun automatisch unnötige Self-Joins, wandelt IN (VALUES…) Klauseln in effizientere Formen um und transformiert OR-Klauseln in Arrays für schnellere Index-Scans. Er beschleunigt auch Mengenoperationen (INTERSECT, EXCEPT), Window-Aggregates und optimiert SELECT DISTINCT und GROUP BY durch Neuanordnung von Schlüsseln und Ignorieren redundanter Spalten. Roberto verglich Query-Benchmarks über Postgres 16, 17 und 18 hinweg, um diese Fortschritte hervorzuheben.
Nelson Calero (Pythian) teilte einen „praktischen Leitfaden“ für die Migration von über 100 PostgreSQL-Datenbanken (von Gigabytes bis zu Multi-Terabytes) in die Cloud. Sein Team migrierte Hunderte von lokalen VM-Datenbanken zu Google Cloud SQL. Er erörterte Planung, Minimierung von Ausfallzeiten, Instanzdimensionierung, Tools und Post-Migrations-Tuning. Insbesondere wies er auf Herausforderungen wie die Handhabung von Upgrades älterer Versionen, Vererbungsschemata, PostGIS-Daten und Änderungen an Dienstkonten hin. Caleros Ratschläge umfassten die Auswahl der richtigen Cloud-Instanztypen, die Optimierung von Massendatenladungen und die Validierung der Performance nach der Migration.
Jan Wieremjewicz (Percona) berichtete über die Implementierung von Transparent Data Encryption (TDE) für Postgres über die pg_tde-Erweiterung. Er führte das Publikum durch die gesamte Reise – von der ersten Idee über Patch-Vorschläge bis hin zu Community-Feedback und Design-Kompromissen. Er erklärte, warum bestehende PostgreSQL-Hooks nicht ausreichten, welche Schwierigkeiten auftraten und wie Kundenfeedback das endgültige Design prägte. Dieser Vortrag diente als „Tagebuch“ darüber, was es braucht, um eine zentrale Verschlüsselungsfunktion durch den PostgreSQL-Entwicklungsprozess zu liefern.
Stefan Fercot (Data Egret) demonstrierte, wie Patroni (für Hochverfügbarkeit) zusammen mit pgBackRest (für Backups) verwendet wird. Er führte durch YAML-Konfigurationsbeispiele, die zeigten, wie pgBackRest in einen Patroni-verwalteten Cluster integriert wird. Stefan zeigte, wie Standby-Replikate aus pgBackRest-Backups wiederhergestellt und Point-in-Time Recovery (PITR) unter der Kontrolle von Patroni durchgeführt werden. Der Vortrag hob praktische operative Erkenntnisse hervor: Die Kombination dieser Tools bietet eine automatisierte, wiederholbare Notfallwiederherstellung für Postgres-Cluster.

Donnerstag: Cloud, EXPLAIN und Resilienz
Maximilian Stefanac und Philipp Thun (SAP SE) erklärten, wie SAP PostgreSQL innerhalb von Cloud Foundry (SAPs Open-Source-PaaS) einsetzt. Sie diskutierten Optimierungen und Skalierungsherausforderungen beim Betrieb von Postgres für die SAP Business Technology Platform. Im Laufe der Jahre hat das Cloud Foundry-Team von SAP Postgres auf AWS, Azure, Google Cloud und Alibaba Cloud bereitgestellt. Die Angebote der einzelnen Anbieter unterscheiden sich, daher ist die Vereinheitlichung von Automatisierung und Monitoring über Clouds hinweg eine große Herausforderung. Der Vortrag hob hervor, wie SAP Postgres-Performance-Verbesserungen an die Community zurückgibt und was es braucht, um große, Cloud-neutrale Postgres-Cluster zu betreiben.
In „EXPLAIN: Make It Make Sense“ half Aivars Kalvāns (Ebury) Entwicklern bei der Interpretation von Abfrageplänen. Er betonte, dass man nach der Identifizierung einer langsamen Abfrage verstehen muss, warum der Planer einen bestimmten Plan gewählt hat und ob dieser optimal ist. Aivars führte durch die EXPLAIN-Ausgabe und teilte Faustregeln zum Erkennen von Ineffizienzen – zum Beispiel das Aufspüren fehlender Indizes oder kostspieliger Operatoren. Er illustrierte gängige Abfrage-Anti-Patterns, die er in der Praxis gesehen hat, und zeigte, wie man sie datenbankfreundlicher umschreibt. Die Session gab praktische Tipps zum Dekodieren von EXPLAIN und zum Optimieren von Abfragen.
Chris Ellis (Nexteam) hob integrierte Postgres-Funktionen hervor, die die Anwendungsentwicklung vereinfachen. Anhand realer Anwendungsfälle – wie Ereignisplanung, Aufgabenwarteschlangen, Suche, Geolocation und die Handhabung heterogener Daten – zeigte er, wie Funktionen wie Bereichstypen, Volltextsuche und JSONB die Anwendungskomplexität reduzieren können. Für jeden Anwendungsfall demonstrierte Chris, welche Postgres-Funktion oder welcher Datentyp das Problem lösen könnte. Diese „Tipps & Tricks“-Tour bekräftigte, dass die Nutzung des reichhaltigen Funktionsumfangs von Postgres oft bedeutet, weniger benutzerdefinierten Code zu schreiben.
Andreas Geppert (Zürcher Kantonalbank) beschrieb ein Cross-Cloud-Replikations-Setup für Katastrophenresilienz. Angesichts der Anforderung, dass bei Ausfall eines Cloud-Anbieters höchstens 15 Minuten Daten verloren gehen dürfen, konnten sie keine physische Replikation verwenden (da ihre Cloud-Anbieter diese nicht unterstützen). Stattdessen bauten sie eine Multi-Cloud-Lösung unter Verwendung logischer Replikation auf. Der Vortrag behandelte, wie sie logische Replikate auch bei Schemaänderungen aktuell halten (wobei angemerkt wurde, dass die logische Replikation DDL nicht automatisch kopiert). Kurz gesagt, die logische Replikation ermöglichte einen resilienten Betrieb mit niedrigem RPO über Anbieter hinweg, trotz Schema-Evolution.
Derk van Veen (Adyen) beleuchtete die tiefere Logik hinter der Tabellenpartitionierung. Er betonte die Bedeutung, den richtigen Partitionsschlüssel zu finden – die „Leitfigur“ in Ihren Daten – und dann Partitionen über alle verwandten Tabellen hinweg auszurichten. Wenn Partitionen einen gemeinsamen Schlüssel und ausgerichtete Grenzen teilen, ergeben sich mehrere Vorteile: gute Performance, vereinfachte Wartung, integrierte Unterstützung für PII-Compliance, einfache Datenbereinigung und sogar transparentes Data Tiering. Derk warnte, dass schlecht geplante Partitionen die Performance erheblich beeinträchtigen können. In seinem Fall führte der Wechsel zu korrekt ausgerichteten Partitionen (und die Aktivierung von enable_partitionwise_join/_aggregate) zu einer 70-fachen Beschleunigung bei über 100 TB großen Finanztabellen. Alle von ihm vorgestellten Strategien wurden in Adyens mehreren Hundert TB großen Produktionsdatenbank erprobt.
Freitag: Weitere fortgeschrittene Themen
Nicholas Meyer (Academia.edu) stellte Thin Cloning vor, eine Technik, die Entwicklern echte Produktionsdaten-Snapshots zum Debuggen zur Verfügung stellt. Mit Tools wie DBLab Engine oder der Klonfunktion von Amazon Aurora erstellt Thin Cloning kostengünstig beschreibbare Kopien von Live-Daten. Dies ermöglicht es Entwicklern, Produktionsprobleme – einschließlich datenabhängiger Fehler – exakt zu reproduzieren, indem sie diese Klone realer Daten debuggen. Nicholas erklärte, wie Academia.edu Thin Clones verwendet, um subtile Fehler frühzeitig zu erkennen, indem Entwicklungs- und QA-Teams mit nahezu produktionsnahen Daten arbeiten.
Dave Pitts (Adyen) erklärte, warum zukünftige Postgres-Anwendungen sowohl B-Baum- als auch LSM-Baum- (log-strukturierte) Indizes verwenden könnten. Er skizzierte die grundlegenden Unterschiede: B-Bäume eignen sich hervorragend für Punktabfragen und ausgewogene Lese-/Schreibvorgänge, während LSM-Bäume einen hohen Schreibdurchsatz und Bereichs-Scans optimieren. Dave diskutierte „Fallstricke“ beim Wechsel von Workloads zwischen Indextypen. Der Vortrag verdeutlichte, wann welche Struktur vorteilhaft ist, und half Entwicklern und DBAs, den richtigen Index für ihre Workload zu wählen.

Ein von Jimmy Angelakos geleitetes Panel befasste sich mit dem Thema „How to Work with Other Postgres People“. Die Diskussion konzentrierte sich auf psychische Gesundheit, Burnout und Neurodiversität in der PostgreSQL-Community. Die Panelisten hoben hervor, dass ungelöste psychische Gesundheitsprobleme Stress und Fluktuation in Open-Source-Projekten verursachen. Sie teilten praktische Strategien für eine unterstützendere Kultur: persönliche „README“-Leitfäden zur Erklärung individueller Kommunikationspräferenzen, respektvolle und empathische Kommunikationspraktiken sowie konkrete Techniken zur Konfliktlösung. Ziel war es, die Postgres-Community einladender und resilienter zu gestalten, indem unterschiedliche Bedürfnisse verstanden und Mitwirkende effektiv unterstützt werden.

Lukas Fittl (pganalyze) präsentierte neue Tools zur Verfolgung von Änderungen an Abfrageplänen über die Zeit. Er zeigte, wie stabile Plan-IDs (analog zu Query-IDs) zugewiesen werden können, damit DBAs überwachen können, welche Abfragen welche Planformen verwenden. Lukas stellte die neue pg_stat_plans-Erweiterung (die die Funktionen von Postgres 18 nutzt) zur ressourcenschonenden Erfassung von Planstatistiken vor. Er erklärte, wie diese Erweiterung funktioniert und verglich sie mit älteren Tools (dem ursprünglichen pg_stat_plans, pg_store_plans usw.) und Cloud-Anbieter-Implementierungen. Dies erleichtert das Erkennen, wenn sich der Ausführungsplan einer Abfrage in der Produktion ändert, und unterstützt die Performance-Fehlerbehebung.

Ahsan Hadi (pgEdge) beschrieb pgEdge Enterprise PostgreSQL, eine zu 100 % Open-Source-verteilte Postgres-Plattform. pgEdge Enterprise Postgres bietet integrierte Hochverfügbarkeit (unter Verwendung von Patroni und Read Replicas) und die Möglichkeit, über globale Regionen hinweg zu skalieren. Ausgehend von einem Single-Node-Postgres können Benutzer zu einem Multi-Region-Cluster mit geo-verteilten Replikaten für extreme Verfügbarkeit und geringe Latenz wachsen. Ahsan demonstrierte, wie pgEdge für Organisationen konzipiert ist, die von einzelnen Instanzen auf große verteilte Bereitstellungen skalieren müssen, alles unter der Standard-Postgres-Lizenz.
Fazit
Die PGConf.EU 2025 war eine ausgezeichnete Veranstaltung zum Wissensaustausch und zum Lernen von der globalen PostgreSQL-Community. Ich war stolz, credativ zu vertreten und als Freiwilliger zu helfen, und ich bin dankbar für die vielen gewonnenen Erkenntnisse. Die oben genannten Sessions stellen nur eine Auswahl der reichhaltigen Inhalte dar, die auf der Konferenz behandelt wurden. Insgesamt machen die starke Community und die schnelle Innovation von PostgreSQL diese Konferenzen weiterhin sehr wertvoll. Ich freue mich darauf, das Gelernte in meiner Arbeit anzuwenden und zukünftige PGConf.EU-Veranstaltungen zu besuchen.
Wie ich in meinem Vortrag auf der PostgreSQL Conference Europe 2025 erläutert habe, kann Datenbeschädigung unbemerkt in jeder PostgreSQL-Datenbank vorhanden sein und bleibt unentdeckt, bis wir beschädigte Daten physisch lesen. Es kann viele Gründe geben, warum einige Datenblöcke in Tabellen oder anderen Objekten beschädigt werden können. Selbst moderne Speicherhardware ist alles andere als unfehlbar. Binäre Backups, die mit dem pg_basebackup-Tool erstellt wurden – einer sehr gängigen Backup-Strategie in der PostgreSQL-Umgebung – lassen diese Probleme verborgen. Denn sie prüfen keine Daten, sondern kopieren ganze Datendateien so, wie sie sind. Mit der Veröffentlichung von PostgreSQL 18 hat die Community beschlossen, Daten-Checksummen standardmäßig zu aktivieren – ein wichtiger Schritt zur frühzeitigen Erkennung dieser Fehler. Dieser Beitrag untersucht, wie PostgreSQL Checksummen implementiert, wie es Checksummenfehler behandelt und wie wir sie auf bestehenden Clustern aktivieren können.
Viele Unternehmen denken heutzutage darüber nach, ihre Datenbanken von Legacy- oder proprietären Systemen auf PostgreSQL zu migrieren. Das primäre Ziel ist es, die Kosten zu senken, die Fähigkeiten zu verbessern und die langfristige Nachhaltigkeit zu gewährleisten. Doch allein die Vorstellung, auf PostgreSQL zu migrieren, kann schon überwältigend sein. Sehr oft ist das Wissen über die Altanwendungen begrenzt oder sogar verloren gegangen. In einigen Fällen nimmt die Unterstützung durch den Hersteller ab, und der Expertenpool und die Unterstützung durch die Community schrumpfen. Außerdem laufen alte Datenbanken oft auf veralteter Hardware und alten Betriebssystemen, was weitere Risiken und Einschränkungen mit sich bringt. (mehr …)
Die PGConf.DE 2025, die 9. jährliche PostgreSQL-Konferenz in Deutschland, fand vom 8. bis 9. Mai 2025 im Marriott Hotel in der Nähe des Potsdamer Platzes in Berlin statt. Die Veranstaltung brachte zwei Tage lang PostgreSQL-Enthusiasten, Entwickler, DBAs und Industriesponsoren zu faszinierenden Vorträgen in vier parallelen Tracks zusammen. Mit 347 Teilnehmern war es die bisher größte Veranstaltung. Die gesamte Konferenz war sehr gut organisiert, und daher gebührt allen Organisatoren – insbesondere Andreas Scherbaum, dem Hauptorganisator – ein besonderer Dank für ihre Bemühungen und ihre harte Arbeit.
Unser Unternehmen, die credativ GmbH, ist wieder unabhängig und nahm als Gold-Sponsor teil. Der CTO von credativ, Alexander Wirt, der Head of Sales & Marketing, Peter Dreuw, und der Teamleiter des Datenbank-Teams, Dr. Tobias Kauder, standen den Teilnehmern am Stand von credativ zur Verfügung. Vielen Dank an unseren Teamkollegen Sascha Spettmann für die Lieferung aller Utensilien und Werbetafeln zur Konferenz und zurück.



Insgesamt hielten wir vier Vorträge auf der Konferenz. Michael Banck, technischer Leiter unseres Datenbank-Teams, präsentierte den deutschsprachigen Vortrag „PostgreSQL Performance Tuning“. Er gab einen tiefen und umfassenden Überblick über die wichtigsten Performance-Tuning-Parameter in PostgreSQL und erklärte, wie sie das Verhalten der Datenbank beeinflussen. Sein Vortrag zog ein großes Publikum an und wurde sehr gut aufgenommen.


Ich hatte die absolut einzigartige Gelegenheit, drei verschiedene Vorträge im englischen Track zu halten. In meinem regulären Vortrag „PostgreSQL Connections Memory Usage: How Much, Why and When“ präsentierte ich die Ergebnisse meiner Forschung und Tests zum Speicherverbrauch von PostgreSQL-Verbindungen. Nachdem ich die wichtigsten Aspekte des Linux-Speichermanagements und die Messungen des Speicherverbrauchs, die von Standardbefehlen gemeldet werden, erläutert hatte, beschrieb ich detailliert den Speicherverbrauch von PostgreSQL-Verbindungen während der Abfrageausführung basierend auf den Zahlen, die in smaps-Dateien gemeldet wurden. Ich plane hierzu detaillierte Blogbeiträge über meine Erkenntnisse zu veröffentlichen. Mein anderer Vortrag, „Building a Data Lakehouse with PostgreSQL“, wurde ursprünglich als Reservevortrag für den Fall einer kurzfristigen Absage ausgewählt. Der Vortrag „Creating a Board Game Chatbot with Postgres, AI, and RAG“ von Matt Cornillon musste ersetzt werden. Der Sprecher konnte nicht teilnehmen, da sein Flug sehr kurzfristig und unerwartet annulliert wurde.


Im Sponsor-Track präsentierten der CTO von credativ, Alexander Wirt, und ich einen Vortrag mit dem Titel „Your Data Deserves the Best: Migration to PostgreSQL“. Darin stellten wir unser neues Migrationstool „credativ-pg-migrator“ vor. Es ist in der Lage, Datenmodelle (Tabellen, Daten, Indizes, Constraints und Views) von Informix, IBM DB2 LUW, MS SQL Server, Sybase ASE, SQL Anywhere und MySQL/MariaDB zu migrieren. Im Falle von Informix kann es auch Stored Procedures, Funktionen und Trigger in PostgreSQL PL/pgSQL konvertieren. Weitere Details zu diesem Tool werden wir in einem separaten Blogbeitrag mitteilen.

Da es immer drei oder vier parallele Vorträge gab, musste ich sorgfältig auswählen, an welchen Sessions ich teilnehmen wollte. Besonders gefallen hat mir der Vortrag „András in Windowsland – a DBA’s (mis)adventures“ von András Váczi von Cybertec. Der Sprecher gab viele nützliche Tipps für den Zugriff auf und die Fehlerbehebung von PostgreSQL unter Windows. Mir gefiel auch der deutsche Vortrag „Modern VACUUM“ von Christoph Berg von Cybertec. Er gab wertvolle Einblicke in die Geschichte und Implementierungsdetails des VACUUM-Befehls und der Autovacuum-Hintergrundprozesse. Ein weiterer sehr interessanter Vortrag war die deutsche Präsentation „Modernes SSL ideal einsetzen“ von Peter Eisentraut von EDB. Der Vortrag behandelte die Auswahl geeigneter Protokollversionen und kryptografischer Cipher Suites, die Verwaltung von Schlüsseln und Zertifikaten sowie die Konfiguration von Client-/Server-Einstellungen zur Erfüllung zeitgemäßer Sicherheitsstandards. Der Vortrag „Comparing the Oracle and PostgreSQL transaction systems“ von Laurenz Albe von Cybertec erhielt viel wohlverdiente Aufmerksamkeit. Zu den Kernthemen gehörten der Undo/Redo-Mechanismus von Oracle im Vergleich zum MVCC-Ansatz von PostgreSQL, Unterschiede bei den Standard-Isolationsstufen und Anomalien sowie die Art und Weise, wie jede Datenbank Constraints und transaktionale DDL implementiert. Nicht zuletzt möchte ich den Vortrag „What is an SLRU anyway?“ erwähnen, der von einem wichtigen PostgreSQL-Contributor, Álvaro Herrera, gehalten wurde. Er erklärte, dass SLRUs im Wesentlichen zirkuläre Logs mit einem In-Memory-Cache sind, die zur Nachverfolgung von Informationen wie committeden Transaktionen oder Snapshot-Daten verwendet werden, und hob die Bedeutung der Innovationen in PostgreSQL 17 hervor, die SLRU-Cache-Größen konfigurierbar machten. Leider wurden die Vorträge nicht aufgezeichnet, aber die Folien für die Mehrheit der Vorträge sind bereits auf der Konferenz-Website verfügbar.
Die gesamte Veranstaltung war sehr informativ und bot hervorragende Möglichkeiten zum Networking. Wir freuen uns schon auf die nächste PGConf.DE. In der Zwischenzeit bleiben Sie auf dem Laufenden über alle Neuigkeiten der credativ und folgen Sie uns auf den sozialen Medien – LinkedIn und Mastodon.
Wenn Sie mehr über unsere Angebote zu PostgreSQL-Services wissen möchten, klicken Sie bitte hier!
PostgreSQL Version 17 wurde vor einiger Zeit veröffentlicht. Eine der vielen Funktionen ist eine Änderung von Tom Lane mit dem Titel „Rearrange pg_dump’s handling of large objects for better efficiency“. In der Vergangenheit haben wir beobachtet, dass eine große Anzahl von großen Objekten bei unseren Kunden zu Performance-Problemen beim Dump/Restore führte. Der Hauptgrund dafür ist, dass große Objekte sich stark von TOAST (The Oversized Attribute Storage Technique) unterscheiden: Während TOAST-Daten für den Benutzer völlig transparent sind, werden große Objekte außerhalb der Zeile in einer pg_largeboject Tabelle gespeichert, wobei ein Link zur jeweiligen Zeile in dieser Tabelle eine OID in der Tabelle selbst ist.
Einführung in große
Objekte
Hier ist ein Beispiel, wie große Objekte verwendet werden können:
postgres=# CREATE TABLE test(id BIGINT, blob OID);
CREATE TABLE
postgres=# INSERT INTO test VALUES (1, lo_import('/etc/issue.net'));
INSERT 0 1
postgres=# SELECT * FROM test;
id | blob
----+-------
1 | 33280
(1 row)
postgres=# SELECT * FROM pg_largeobject;
loid | pageno | data
-------+--------+--------------------------------------------
33280 | 0 | \x44656269616e20474e552f4c696e75782031320a
(1 row)
postgres=# SELECT lo_export(test.blob, '/tmp/foo') FROM test;
lo_export
-----------
1
(1 row)
postgres=# SELECT pg_read_file('/tmp/foo');
pg_read_file
---------------------
Debian GNU/Linux 12+
(1 row)
postgres=# INSERT INTO test VALUES (1, lo_import('/etc/issue.net'));
INSERT 0 1Wenn wir nun die Datenbank im Custom-Format mit den Versionen 16 und 17 von pg_dump dumpen und dann pg_restore -l verwenden, um das Inhaltsverzeichnis (TOC) anzuzeigen, sehen wir einen Unterschied:
$ for version in 16 17; do /usr/lib/postgresql/$version/bin/pg_dump -Fc -f lo_test_$version.dmp; \
> pg_restore -l lo_test_$version.dmp | grep -v ^\; > lo_test_$version.toc; done
$ diff -u lo_test_{16,17}.toc
--- lo_test_16.toc 2024-12-11 09:05:46.550667808 +0100
+++ lo_test_17.toc 2024-12-11 09:05:46.594670235 +0100
@@ -1,5 +1,4 @@
215; 1259 33277 TABLE public test postgres
-3348; 2613 33280 BLOB - 33280 postgres
-3349; 2613 33281 BLOB - 33281 postgres
+3348; 2613 33280 BLOB METADATA - 33280..33281 postgres
3347; 0 33277 TABLE DATA public test postgres
-3350; 0 0 BLOBS - BLOBS
+3349; 0 0 BLOBS - 33280..33281 postgresDer Dump mit Version 17 kombiniert die Metadaten der großen Objekte in BLOB METADATA, wodurch nur ein Eintrag im Inhaltsverzeichnis (TOC) für sie erstellt wird.
Ferner, wenn wir das Directory-Dump-Format verwenden, sehen wir, dass pg_dump für jedes große Objekt eine Datei erstellt:
$ pg_dump -Fd -f lo_test.dir
$ ls lo_test.dir/
3347.dat.gz blob_33280.dat.gz blob_33281.dat.gz blobs.toc toc.datWenn es nur wenige große Objekte gibt, ist dies kein Problem. Wenn aber der Mechanismus für große Objekte verwendet wird, um Hunderttausende oder Millionen von großen Objekten zu erstellen, wird dies zu einem ernsthaften Problem für pg_dump/pg_restore.
Schließlich, um die großen Objekte vollständig zu entfernen, reicht es nicht aus, die Tabelle zu löschen, das große Objekt muss ebenfalls entlinkt werden:
postgres=# DROP TABLE test;
DROP TABLE
postgres=# SELECT COUNT(*) FROM pg_largeobject;
count
-------
2
(1 row)
postgres=# SELECT lo_unlink(loid) FROM pg_largeobject;
lo_unlink
-----------
1
1
(2 rows)
postgres=# SELECT COUNT(*) FROM pg_largeobject;
count
-------
0
(1 row)Benchmark
Wir generieren eine Million große Objekte in einer PostgreSQL 16 Instanz:
lotest=# SELECT lo_create(id) FROM generate_series(1,1000000) AS id;
lo_create
-----------
1
2
[...]
999999
1000000
(1000000 rows)
lotest=# SELECT COUNT(*) FROM pg_largeobject_metadata;
count
---------
1000000
(1 row)
(1 row)Wir dumpen nun die Datenbank mit pg_dump aus den Versionen 16 und 17, zuerst als Custom- und dann als Directory-Dump, wobei wir das time Dienstprogramm verwenden, um Laufzeit und Speichernutzung zu verfolgen:
$ for version in 16 17; do echo -n "$version: "; \
> /usr/bin/time -f '%E %Mk mem' /usr/lib/postgresql/$version/bin/pg_dump \
> -Fc -f lo_test_$version.dmp lotest; done
16: 0:36.73 755692k mem
17: 0:34.69 217776k mem
$ for version in 16 17; do echo -n "$version: "; \
> /usr/bin/time -f '%E %Mk mem' /usr/lib/postgresql/$version/bin/pg_dump \
> -Fd -f lo_test_$version.dir lotest; done
16: 8:23.48 755624k mem
17: 7:51.04 217980k memDas Dumping im Directory-Format dauert wesentlich länger als im Custom-Format, während der Speicherverbrauch für beide sehr ähnlich ist. Die Laufzeit ist für Version 17 im Vergleich zu Version 16 etwas geringer, aber der große Unterschied liegt im verwendeten Speicher, der 3,5-mal kleiner ist.
Auch wenn man die Dateigröße für den Custom-Dump oder die Dateigröße der Inhaltsverzeichnis-Datei (TOC) betrachtet, wird der Unterschied sehr deutlich:
$ ls -lh lo_test_1?.dmp | awk '{print $5 " " $9}'
211M lo_test_16.dmp
29M lo_test_17.dmp
$ ls -lh lo_test_1?.dir/toc.dat | awk '{print $5 " " $9}'
185M lo_test_16.dir/toc.dat
6,9M lo_test_17.dir/toc.datDer Custom-Dump ist etwa 7-mal kleiner, während die TOC-Datei des Directory-Dumps etwa 25-mal kleiner ist. Wir haben auch verschiedene Anzahlen großer Objekte getestet (von 50.000 bis 1,5 Millionen) und fanden nur eine geringe Abweichung in diesen Verhältnissen: Das Verhältnis des verwendeten Speichers steigt von etwa 2-mal bei 50.000 auf 4-mal bei 1,5 Millionen, während das TOC-Verhältnis von etwa 30-mal bei 50.000 auf 25-mal bei 1,5 Millionen sinkt.
Fazit
Die Änderungen bezüglich des Dumpings großer Objekte in Postgres 17 sind sehr willkommen für Benutzer mit einer großen Anzahl großer Objekte. Der Speicherbedarf ist unter PostgreSQL 17 im Vergleich zu früheren Versionen wesentlich geringer, sowohl für Dumps im Custom- als auch im Directory-Format.
Leider ändern sich weder die Anzahl der Dateien im Verzeichnis noch die Verzeichnisgröße wesentlich, jedes große Objekt wird immer noch als eigene Datei gedumpt, was zu Problemen führen kann, wenn es viele Dateien gibt:
$ for version in 16 17; do echo -n "$version: "; find lo_test_$version.dir/ | wc -l; done
16: 1000003
17: 1001002
$ du -s -h lo_test_??.dir
4,1G lo_test_16.dir
3,9G lo_test_17.dirDies könnte ein Bereich für zukünftige Verbesserungen in Postgres 18 und darüber hinaus sein.
Das Problem des Table- und Index-Bloats aufgrund fehlgeschlagener Einfügungen bei Unique Constraints ist bekannt und wurde in verschiedenen Artikeln im Internet diskutiert. Allerdings mangelt es diesen Diskussionen manchmal an einem klaren, praktischen Beispiel mit Messungen, um die Auswirkungen zu veranschaulichen. Und trotz der Vertrautheit mit diesem Problem sehen wir dieses Designmuster – oder besser gesagt Anti-Pattern – immer noch häufig in realen Anwendungen. Entwickler verlassen sich oft auf Unique Constraints, um zu verhindern, dass doppelte Werte in Tabellen eingefügt werden. Obwohl dieser Ansatz unkompliziert, vielseitig und allgemein als effektiv angesehen wird, führen in PostgreSQL Einfügungen, die aufgrund von Verletzungen von Unique Constraints fehlschlagen, leider immer zu Table- und Index-Bloat. Und auf stark frequentierten Systemen kann dieser unnötige Bloat die Disk-I/O und die Häufigkeit von Autovacuum-Läufen erheblich erhöhen. In diesem Artikel möchten wir dieses Problem noch einmal hervorheben und ein einfaches Beispiel mit Messungen zur Veranschaulichung geben. Wir schlagen eine einfache Verbesserung vor, die dazu beitragen kann, dieses Problem zu mildern und die Autovacuum-Auslastung und die Disk-I/O zu reduzieren.
Zwei Ansätze zur Duplikatsvermeidung
In PostgreSQL gibt es zwei Hauptmethoden, um doppelte Werte mithilfe von Unique Constraints zu verhindern:
1. Standard-Insert-Befehl (INSERT INTO table)
Der übliche INSERT INTO table-Befehl versucht, Daten direkt in die Tabelle einzufügen. Wenn das Einfügen zu einem doppelten Wert führen würde, schlägt es mit einem Fehler „duplicate key value violates unique constraint“ fehl. Da der Befehl keine Duplikatsprüfungen spezifiziert, fügt PostgreSQL intern sofort die neue Zeile ein und beginnt erst dann mit der Aktualisierung der Indizes. Wenn eine Verletzung eines Unique Index auftritt, löst dies den Fehler aus und löscht die neu hinzugefügte Zeile. Die Reihenfolge der Indexaktualisierungen wird durch ihre Beziehungs-IDs bestimmt, sodass das Ausmaß des Index-Bloats von der Reihenfolge abhängt, in der Indizes erstellt wurden. Bei wiederholten Fehlern aufgrund von „unique constraint violation“ sammeln sich sowohl in der Tabelle als auch in einigen Indizes gelöschte Datensätze an, was zu Bloat führt, und die resultierenden Schreiboperationen erhöhen die Disk-I/O, ohne ein nützliches Ergebnis zu erzielen.
2. Konfliktbewusstes Einfügen (INSERT INTO table … ON CONFLICT DO NOTHING)
Der Befehl INSERT INTO table ON CONFLICT DO NOTHING verhält sich anders. Da er spezifiziert, dass ein Konflikt auftreten könnte, prüft PostgreSQL zuerst auf potenzielle Duplikate, bevor versucht wird, Daten einzufügen. Wenn ein Duplikat gefunden wird, führt PostgreSQL die angegebene Aktion aus – in diesem Fall „DO NOTHING“ – und es tritt kein Fehler auf. Diese Klausel wurde in PostgreSQL 9.5 eingeführt, aber einige Anwendungen laufen entweder noch auf älteren PostgreSQL-Versionen oder behalten Legacy-Code bei, wenn die Datenbank aktualisiert wird. Infolgedessen wird diese Option zur Konfliktbehandlung oft zu wenig genutzt.
Testbeispiel
Um Tests durchführen zu können, müssen wir PostgreSQL mit „autovacuum=off“ starten. Andernfalls verarbeitet Autovacuum bei meist inaktiver Instanz aufgeblähte Objekte sofort, und es wäre nicht möglich, Statistiken zu erfassen. Wir erstellen ein einfaches Testbeispiel mit mehreren Indizes:
CREATE TABLE IF NOT EXISTS test_unique_constraints(
id serial primary key,
unique_text_key text,
unique_integer_key integer,
some_other_bigint_column bigint,
some_other_text_column text);
CREATE INDEX test_unique_constraints_some_other_bigint_column_idx ON test_unique_constraints (some_other_bigint_column ); CREATE INDEX test_unique_constraints_some_other_text_column_idx ON test_unique_constraints (some_other_text_column ); CREATE INDEX test_unique_constraints_unique_text_key_unique_integer_key__idx ON test_unique_constraints (unique_text_key, unique_integer_key, some_other_bigint_column ); CREATE UNIQUE test_unique_constraints_unique_integer_key_idx INDEX ON test_unique_constraints (unique_text_key ); CREATE UNIQUE test_unique_constraints_unique_text_key_idx INDEX ON test_unique_constraints (unique_integer_key );
Und nun füllen wir diese Tabelle mit eindeutigen Daten:
DO $$ BEGIN FOR i IN 1..1000 LOOP INSERT INTO test_unique_constraints (unique_text_key, unique_integer_key, some_other_bigint_column, some_other_text_column) VALUES (i::text, i, i, i::text); END LOOP; END; $$;
Im zweiten Schritt verwenden wir ein einfaches Python-Skript, um eine Verbindung zur Datenbank herzustellen, zu versuchen, widersprüchliche Daten einzufügen, und die Sitzung nach einem Fehler zu schließen. Zuerst sendet es 10.000 INSERT-Anweisungen, die mit dem Index „test_unique_constraints_unique_int_key_idx“ in Konflikt stehen, dann weitere 10.000 INSERTs, die mit „test_unique_constraints_unique_text_key_idx“ in Konflikt stehen. Der gesamte Test wird in wenigen Dutzend Sekunden durchgeführt, danach inspizieren wir alle Objekte mit der Erweiterung „pgstattuple“. Die folgende Abfrage listet alle Objekte in einer einzigen Ausgabe auf:
WITH maintable AS (SELECT oid, relname FROM pg_class WHERE relname = 'test_unique_constraints') SELECT m.oid as relid, m.relname as relation, s.* FROM maintable m JOIN LATERAL (SELECT * FROM pgstattuple(m.oid)) s ON true UNION ALL SELECT i.indexrelid as relid, indexrelid::regclass::text as relation, s.* FROM pg_index i JOIN LATERAL (SELECT * FROM pgstattuple(i.indexrelid)) s ON true WHERE i.indrelid::regclass::text = 'test_unique_constraints' ORDER BY relid;
Beobachtete Ergebnisse
Nach mehrmaligem Ausführen des gesamten Tests beobachten wir Folgendes:
- Die Haupttabelle „test_unique_constraints“ hat immer 1.000 Live-Tupel und 20.000 zusätzliche Dead-Records, was zu ca. 85 % Dead-Tupeln in der Tabelle führt
- Der Index auf dem Primärschlüssel zeigt immer 21.000 Tupel an, ohne zu wissen, dass 20.000 dieser Datensätze in der Haupttabelle als gelöscht markiert sind.
- Andere nicht eindeutige Indizes zeigen in verschiedenen Läufen unterschiedliche Ergebnisse, die zwischen 3.000 und 21.000 Datensätzen liegen. Die Zahlen hängen von der Verteilung der Werte ab, die das Skript für die zugrunde liegenden Spalten generiert. Wir haben sowohl wiederholte als auch vollständig eindeutige Werte getestet. Wiederholte Werte führten zu weniger Datensätzen in Indizes, vollständig eindeutige Werte führten zu einer vollständigen Anzahl von 21.000 Datensätzen in diesen Indizes.
- Unique Indizes zeigten wiederholt Tupelanzahlen nur zwischen 1.000 und 1.400 in allen Tests. Der Unique Index auf dem „unique_text_key“ zeigt immer einige Dead-Tupel in der Ausgabe. Eine genaue Erklärung dieser Zahlen würde eine eingehendere Untersuchung dieser Beziehungen und des Codes der pgstattuple-Funktion erfordern, was den Rahmen dieses Artikels sprengen würde. Aber auch hier wird ein geringer Bloat gemeldet.
- Von der pgstattuple-Funktion gemeldete Zahlen warfen Fragen nach ihrer Genauigkeit auf, obwohl die Dokumentation zu dem Schluss zu führen scheint, dass die Zahlen auf Tupelebene genau sein sollten.
- Die anschließende manuelle Vacuum-Operation bestätigt 20.000 Dead-Records in der Haupttabelle und 54 Seiten, die aus dem Primärschlüsselindex entfernt wurden, sowie bis zu mehreren Dutzend Seiten, die aus anderen Indizes entfernt wurden – unterschiedliche Zahlen in jedem Lauf in Abhängigkeit von der Gesamtzahl der Tupel in diesen Beziehungen, wie oben beschrieben.
- Jeder fehlgeschlagene Insert erhöht auch die Transaktions-ID und damit das Transaktionsalter der Datenbank.
Hier ist ein Beispielausgabe aus der oben gezeigten Abfrage nach dem Testlauf, der eindeutige Werte für alle Spalten verwendete. Wie wir sehen können, kann der Bloat von nicht eindeutigen Indizes aufgrund fehlgeschlagener Inserts groß sein.
relid | relation | table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent -------+-----------------------------------------------------------------+-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+-------------- 16418 | test_unique_constraints | 1269760 | 1000 | 51893 | 4.09 | 20000 | 1080000 | 85.06 | 5420 | 0.43 16424 | test_unique_constraints_pkey | 491520 | 21000 | 336000 | 68.36 | 0 | 0 | 0 | 51444 | 10.47 16426 | test_unique_constraints_some_other_bigint_column_idx | 581632 | 16396 | 326536 | 56.14 | 0 | 0 | 0 | 168732 | 29.01 16427 | test_unique_constraints_some_other_text_column_idx | 516096 | 16815 | 327176 | 63.39 | 0 | 0 | 0 | 101392 | 19.65 16428 | test_unique_constraints_unique_text_key_unique_integer_key__idx | 1015808 | 21000 | 584088 | 57.5 | 0 | 0 | 0 | 323548 | 31.85 16429 | test_unique_constraints_unique_text_key_idx | 57344 | 1263 | 20208 | 35.24 | 2 | 32 | 0.06 | 15360 | 26.79 16430 | test_unique_constraints_unique_integer_key_idx | 40960 | 1000 | 16000 | 39.06 | 0 | 0 | 0 | 4404 | 10.75 (7 rows)
In einem zweiten Test modifizieren wir das Skript, um die Klausel ON CONFLICT DO NOTHING in den INSERT-Befehl aufzunehmen, und wiederholen beide Tests. Diesmal führen Inserts nicht zu Fehlern; stattdessen geben sie einfach „INSERT 0 0“ zurück, was anzeigt, dass keine Datensätze eingefügt wurden. Die Überprüfung der Transaktions-ID nach diesem Test zeigt nur einen minimalen Anstieg, der durch Hintergrundprozesse verursacht wird. Versuche, widersprüchliche Daten einzufügen, führten nicht zu einer Erhöhung der Transaktions-ID (XID), da PostgreSQL zuerst nur eine virtuelle Transaktion startete, um auf Konflikte zu prüfen, und weil ein Konflikt gefunden wurde, die Transaktion abbrach, ohne eine neue XID zugewiesen zu haben. Die „pgstattuple“-Ausgabe bestätigt, dass alle Objekte nur Live-Daten enthalten, diesmal ohne Dead-Tupel.
Zusammenfassung
Wie gezeigt, bläht jeder fehlgeschlagene Insert die zugrunde liegende Tabelle und einige Indizes auf und erhöht die Transaktions-ID, da jeder fehlgeschlagene Insert in einer separaten Transaktion erfolgt. Folglich wird Autovacuum gezwungen, häufiger zu laufen, was wertvolle Systemressourcen verbraucht. Daher sollten Anwendungen, die sich immer noch ausschließlich auf einfache INSERT-Befehle ohne ON CONFLICT-Bedingungen verlassen, diese Implementierung überdenken. Aber wie immer sollte die endgültige Entscheidung auf den spezifischen Bedingungen jeder Anwendung basieren.
TOAST (The Oversized Attribute Storage Technique) ist der Mechanismus von PostgreSQL zur Handhabung großer Datenobjekte, die die 8-KB-Datenseitenbegrenzung überschreiten. Eingeführt in PostgreSQL 7.1, ist TOAST eine verbesserte Version des Out-of-Line-Speichermechanismus, der in Oracle-Datenbanken zur Handhabung großer Objekte (LOBs) verwendet wird. Beide Datenbanken speichern Daten variabler Länge entweder inline innerhalb der Tabelle oder in einer separaten Struktur. PostgreSQL begrenzt die maximale Größe eines einzelnen Tupels auf eine Datenseite. Wenn die Größe des Tupels, einschließlich komprimierter Daten in einer Spalte variabler Länge, einen bestimmten Schwellenwert überschreitet, wird der komprimierte Teil in eine separate Datendatei verschoben und automatisch in Chunks aufgeteilt, um die Leistung zu optimieren.
 TOAST kann zur Speicherung von langen Texten, Binärdaten in Bytea-Spalten, JSONB-Daten, langen HSTORE-Schlüssel-Wert-Paaren, großen Arrays, umfangreichen XML-Dokumenten oder benutzerdefinierten zusammengesetzten Datentypen verwendet werden. Sein Verhalten wird von zwei Parametern beeinflusst: TOAST_TUPLE_THRESHOLD und TOAST_TUPLE_TARGET. Der erste ist ein fest codierter Parameter, der im PostgreSQL-Quellcode in der Datei heaptoast.h definiert ist, basierend auf der Funktion MaximumBytesPerTuple, die für vier TOAST-Tupel pro Seite berechnet wird, was zu einer Begrenzung von 2000 Byte führt. Dieser fest codierte Schwellenwert verhindert, dass Benutzer zu kleine Werte im Out-of-Line-Speicher ablegen, was die Leistung beeinträchtigen würde. Der zweite Parameter, TOAST_TUPLE_TARGET, ist ein Speicherparameter auf Tabellenebene, der mit demselben Wert wie TOAST_TUPLE_THRESHOLD initialisiert wird, aber für einzelne Tabellen angepasst werden kann. Er definiert die minimale Tupellänge, die erforderlich ist, bevor versucht wird, lange Spaltenwerte zu komprimieren und in TOAST-Tabellen zu verschieben.
TOAST kann zur Speicherung von langen Texten, Binärdaten in Bytea-Spalten, JSONB-Daten, langen HSTORE-Schlüssel-Wert-Paaren, großen Arrays, umfangreichen XML-Dokumenten oder benutzerdefinierten zusammengesetzten Datentypen verwendet werden. Sein Verhalten wird von zwei Parametern beeinflusst: TOAST_TUPLE_THRESHOLD und TOAST_TUPLE_TARGET. Der erste ist ein fest codierter Parameter, der im PostgreSQL-Quellcode in der Datei heaptoast.h definiert ist, basierend auf der Funktion MaximumBytesPerTuple, die für vier TOAST-Tupel pro Seite berechnet wird, was zu einer Begrenzung von 2000 Byte führt. Dieser fest codierte Schwellenwert verhindert, dass Benutzer zu kleine Werte im Out-of-Line-Speicher ablegen, was die Leistung beeinträchtigen würde. Der zweite Parameter, TOAST_TUPLE_TARGET, ist ein Speicherparameter auf Tabellenebene, der mit demselben Wert wie TOAST_TUPLE_THRESHOLD initialisiert wird, aber für einzelne Tabellen angepasst werden kann. Er definiert die minimale Tupellänge, die erforderlich ist, bevor versucht wird, lange Spaltenwerte zu komprimieren und in TOAST-Tabellen zu verschieben.
In der Quelldatei heaptoast.h erklärt ein Kommentar: „Ist ein Tupel größer als TOAST_TUPLE_THRESHOLD, versuchen wir, es durch Komprimieren komprimierbarer Felder und Verschieben von EXTENDED- und EXTERNAL-Daten Out-of-Line auf nicht mehr als TOAST_TUPLE_TARGET Bytes zu „toasten“. Die Zahlen müssen nicht identisch sein, obwohl sie es derzeit sind. Es ist nicht sinnvoll, dass TARGET THRESHOLD überschreitet, aber es könnte nützlich sein, es kleiner zu machen.“ Das bedeutet, dass in realen Tabellen direkt im Tupel gespeicherte Daten komprimiert sein können oder auch nicht, abhängig von ihrer Größe nach der Komprimierung. Um zu überprüfen, ob Spalten komprimiert sind und welcher Algorithmus verwendet wird, können wir die PostgreSQL-Systemfunktion pg_column_compression verwenden. Zusätzlich hilft die Funktion pg_column_size, die Größe einzelner Spalten zu überprüfen. PostgreSQL 17 führt eine neue Funktion, pg_column_toast_chunk_id, ein, die anzeigt, ob der Wert einer Spalte in der TOAST-Tabelle gespeichert ist.
In den neuesten PostgreSQL-Versionen werden zwei Kompressionsalgorithmen verwendet: PGLZ (PostgreSQL LZ) und LZ4. Beide sind Varianten des LZ77-Algorithmus, wurden aber für unterschiedliche Anwendungsfälle entwickelt. PGLZ eignet sich für gemischte Text- und numerische Daten, wie XML oder JSON in Textform, und bietet ein Gleichgewicht zwischen Kompressionsgeschwindigkeit und -rate. Es verwendet einen Gleitfenstermechanismus, um wiederholte Sequenzen in den Daten zu erkennen, und bietet ein angemessenes Gleichgewicht zwischen Kompressionsgeschwindigkeit und Kompressionsrate. LZ4 hingegen ist eine schnelle Kompressionsmethode, die für Echtzeitszenarien entwickelt wurde. Es bietet Hochgeschwindigkeitskomprimierung und -dekomprimierung, was es ideal für leistungskritische Anwendungen macht. LZ4 ist deutlich schneller als PGLZ, insbesondere bei der Dekomprimierung, und verarbeitet Daten in festen Blöcken (typischerweise 64 KB) unter Verwendung einer Hash-Tabelle, um Übereinstimmungen zu finden. Dieser Algorithmus zeichnet sich bei Binärdaten wie Bildern, Audio- und Videodateien aus.
In meinem internen Forschungsprojekt, das darauf abzielte, die Leistung von JSONB-Daten unter verschiedenen Anwendungsfällen zu verstehen, habe ich mehrere Leistungstests für Abfragen durchgeführt, die JSONB-Daten verarbeiten. Die Ergebnisse einiger Tests zeigten interessante und manchmal überraschende Leistungsunterschiede zwischen diesen Algorithmen. Die vorgestellten Beispiele sind jedoch anekdotisch und können nicht verallgemeinert werden. Ziel dieses Artikels ist es, das Bewusstsein dafür zu schärfen, dass es enorme Leistungsunterschiede geben kann, die je nach spezifischen Daten und Anwendungsfällen sowie der spezifischen Hardware variieren. Daher können diese Ergebnisse nicht blind angewendet werden.
JSONB-Daten werden als binäres Objekt mit einer Baumstruktur gespeichert, wobei Schlüssel und Werte in separaten Zellen gespeichert werden und Schlüssel auf derselben JSON-Ebene in sortierter Reihenfolge abgelegt sind. Verschachtelte Ebenen werden als zusätzliche Baumstrukturen unter ihren entsprechenden Schlüsseln der höheren Ebene gespeichert. Diese Struktur bedeutet, dass das Abrufen von Daten für die ersten Schlüssel in der obersten JSON-Ebene schneller ist als das Abrufen von Werten für stark verschachtelte Schlüssel, die tiefer im Binärbaum gespeichert sind. Obwohl dieser Unterschied normalerweise vernachlässigbar ist, wird er bei Abfragen, die sequentielle Scans über den gesamten Datensatz durchführen, signifikant, da diese kleinen Verzögerungen die Gesamtleistung kumulativ beeinträchtigen können.
Der für die Tests verwendete Datensatz bestand aus historischen GitHub-Ereignissen, die als JSON-Objekte von gharchive.org verfügbar waren und die erste Januarwoche 2023 abdeckten. Ich habe drei verschiedene Tabellen getestet: eine mit PGLZ, eine mit LZ4 und eine mit EXTERNAL-Speicher ohne Komprimierung. Ein Python-Skript lud die Daten herunter, entpackte sie und lud sie in die jeweiligen Tabellen. Jede Tabelle wurde separat geladen, um zu verhindern, dass frühere Operationen das PostgreSQL-Speicherformat beeinflussen.
Die erste bemerkenswerte Beobachtung war der Größenunterschied zwischen den Tabellen. Die Tabelle mit LZ4-Komprimierung war die kleinste mit etwa 38 GB, gefolgt von der Tabelle mit PGLZ mit 41 GB. Die Tabelle mit externem Speicher ohne Komprimierung war mit 98 GB deutlich größer. Da die Testmaschinen nur 32 GB RAM hatten, passte keine der Tabellen vollständig in den Speicher, was die Festplatten-I/O zu einem wichtigen Leistungsfaktor machte. Etwa ein Drittel der Datensätze wurde in TOAST-Tabellen gespeichert, was eine typische Datengrößenverteilung widerspiegelte, wie sie von unseren Kunden beobachtet wird.
Um Caching-Effekte zu minimieren, habe ich mehrere Tests mit mehreren parallelen Sitzungen durchgeführt, die Testabfragen mit jeweils zufällig gewählten Parametern ausführten. Zusätzlich zu Anwendungsfällen mit verschiedenen Indextypen führte ich auch sequentielle Scans über die gesamte Tabelle durch. Die Tests wurden mit unterschiedlicher Anzahl paralleler Sitzungen wiederholt, um genügend Datenpunkte zu sammeln, und dieselben Tests wurden an allen drei Tabellen mit verschiedenen Kompressionsalgorithmen durchgeführt.
Die erste Grafik zeigt die Ergebnisse von SELECT-Abfragen, die sequentielle Scans durchführen und JSON-Schlüssel abrufen, die am Anfang des JSONB-Binärobjekts gespeichert sind. Wie erwartet bietet externer Speicher ohne Komprimierung (blaue Linie) eine nahezu lineare Leistung, wobei die Festplatten-I/O der Hauptfaktor ist. Auf einer 8-Kern-Maschine liefert der PGLZ-Algorithmus (rote Linie) unter geringeren Lasten eine recht gute Leistung. Sobald jedoch die Anzahl der parallelen Abfragen die Anzahl der verfügbaren CPU-Kerne (8) erreicht, beginnt seine Leistung abzunehmen und wird schlechter als die Leistung unkomprimierter Daten. Unter höheren Lasten wird er zu einem ernsthaften Engpass. Im Gegensatz dazu verarbeitet LZ4 (grüne Linie) parallele Abfragen außergewöhnlich gut und behält eine bessere Leistung als unkomprimierte Daten bei, selbst bei bis zu 32 parallelen Abfragen auf 8 Kernen.
Der zweite Test zielte auf JSONB-Schlüssel ab, die an verschiedenen Positionen (Anfang, Mitte und Ende) innerhalb des JSONB-Binärobjekts gespeichert sind. Die Ergebnisse, gemessen auf einer 20-Kern-Maschine, zeigen, dass PGLZ (rote Linie) von Anfang an langsamer ist als die unkomprimierte Tabelle. In diesem Fall verschlechtert sich die Leistung von PGLZ linear statt geometrisch, liegt aber immer noch deutlich hinter LZ4 (grüne Linie). LZ4 übertraf während des gesamten Tests durchweg die unkomprimierten Daten.
Wenn wir uns jedoch entscheiden, den Kompressionsalgorithmus zu ändern, ändert das einfache Erstellen einer neuen Tabelle mit der Einstellung default_toast_compression auf „lz4“ und das Ausführen von INSERT INTO my_table_lz4 SELECT * FROM my_table_pglz; den Kompressionsalgorithmus bestehender Datensätze nicht. Jeder bereits komprimierte Datensatz behält seinen ursprünglichen Kompressionsalgorithmus bei. Sie können die Systemfunktion pg_column_compression verwenden, um zu überprüfen, welcher Algorithmus für jeden Datensatz verwendet wurde. Die Standard-Komprimierungseinstellung gilt nur für neue, unkomprimierte Daten; alte, bereits komprimierte Daten werden unverändert kopiert.
Um alte Daten wirklich in einen anderen Kompressionsalgorithmus zu konvertieren, müssen wir sie über Text umwandeln. Für JSONB-Daten würden wir eine Abfrage wie diese verwenden: INSERT INTO my_table_lz4 (jsonb_data, …) SELECT jsonb_data::text::jsonb, … FROM my_table_pglz; Dies stellt sicher, dass alte Daten mit der neuen LZ4-Komprimierung gespeichert werden. Dieser Prozess kann jedoch zeit- und ressourcenintensiv sein, daher ist es wichtig, die Vorteile abzuwägen, bevor man ihn in Angriff nimmt.
Zusammenfassend lässt sich sagen: Meine Tests zeigten signifikante Leistungsunterschiede zwischen den Algorithmen PGLZ und LZ4 zur Speicherung komprimierter JSONB-Daten. Diese Unterschiede sind besonders ausgeprägt, wenn die Maschine unter hoher paralleler Last steht. Die Tests zeigten eine starke Leistungsverschlechterung bei Daten, die mit dem PGLZ-Algorithmus gespeichert wurden, wenn die Anzahl der parallelen Sitzungen die Anzahl der verfügbaren Kerne überschritt. In einigen Fällen schnitt PGLZ von Anfang an schlechter ab als unkomprimierte Daten. Im Gegensatz dazu übertraf LZ4 sowohl unkomprimierte als auch PGLZ-komprimierte Daten durchweg, insbesondere unter hoher Last. Die Festlegung von LZ4 als Standardkomprimierung für neue Daten scheint die richtige Wahl zu sein, und einige Cloud-Anbieter haben diesen Ansatz bereits übernommen. Diese Ergebnisse sollten jedoch nicht blind auf bestehende Daten angewendet werden. Sie sollten Ihre spezifischen Anwendungsfälle und Daten testen, um festzustellen, ob eine Konvertierung den Zeit- und Ressourcenaufwand wert ist, da die Datenkonvertierung ein Umwandeln erfordert und ein ressourcenintensiver Prozess sein kann.
Einführung
Das Ausführen von ANALYZE (entweder explizit oder über Auto-Analyze) ist sehr wichtig, um aktuelle Datenstatistiken für den Postgres-Query-Planer zu haben. Insbesondere nach In-Place-Upgrades über ANALYZE nur Teile der Blöcke in einer Tabelle abtastet, ähnelt das I/O-Muster eher einem Direktzugriff als einem sequenziellen Lesen. Version 14 von Postgres hat die Möglichkeit maintenenance_io_concurrency gesteuert, der standardmäßig auf 10 gesetzt ist (im Gegensatz zu effective_io_concurrency, der standardmäßig auf 1 gesetzt ist).
Benchmark
Um die Änderungen zwischen Version 13 und 14 zu testen und zu demonstrieren, haben wir einige kurze Benchmarks mit den aktuellen Wartungsversionen (13.16 und 14.13) auf Debian 12 mit Paketen von https://apt.postgresql.org durchgeführt. Hardwareseitig wurde ein ThinkPad T14s Gen 3 mit einer Intel i7-1280P CPU mit 20 Kernen und 32 GB RAM verwendet. Die Basis ist eine pgbench-Datenbank, die mit einem Skalierungsfaktor von 1000 initialisiert wurde:
$ pgbench -i -I dtg -s 1000 -d pgbenchDadurch werden 100 Millionen Zeilen erstellt, was zu einer Datenbankgröße von etwa 15 GB führt. Um pgbench_accounts:
$ vacuumdb -Z -v -d pgbench -t pgbench_accounts
INFO: analyzing "public.pgbench_accounts"
INFO: "pgbench_accounts": scanned 300000 of 1639345 pages,
containing 18300000 live rows and 0 dead rows;
300000 rows in sample, 100000045 estimated total rowsZwischen den Durchläufen wird der Dateisystem-Seitencache über echo 3 | sudo tee /proc/sys/vm/drop_caches gelöscht und alle Durchläufe werden dreimal wiederholt. Die folgende Tabelle listet die Laufzeiten (in Sekunden) des obigen vacuumdb-Befehls für verschiedene Einstellungen von maintenance_io_concurrency auf:
| Version | 0 | 1 | 5 | 10 | 20 | 50 | 100 | 500 |
|---|---|---|---|---|---|---|---|---|
| 13 | 19.557 | 21.610 | 19.623 | 21.060 | 21.463 | 20.533 | 20.230 | 20.537 |
| 14 | 24.707 | 29.840 | 8.740 | 5.777 | 4.067 | 3.353 | 3.007 | 2.763 |
Analyse
Zwei Dinge gehen aus diesen Zahlen deutlich hervor: Erstens ändern sich die Laufzeiten für Version 13 nicht, der Wert von maintenance_io_concurrency hat für diese Version keine Auswirkung. Zweitens, sobald das Prefetching für Version 14 einsetzt (maintenance_io_concurrency=0) oder nur auf 1 gesetzt ist, schlechter sind als bei Version 13, aber da der Standardwert für maintenance_io_concurrency 10 ist, sollte dies in der Praxis niemanden betreffen.
Fazit
Das Aktivieren von Prefetching für ANALYZE in Version 14 von PostgreSQL hat die Statistikabtastung erheblich beschleunigt. Der Standardwert von 10 für ANALYZE.