… mit Kafka® Connect und dem Debezium PostgreSQL® Quellconnector
Moderne, verteilte ereignis- und streamingbasierte Systeme machen sich die Idee zu eigen, dass Änderungen unvermeidlich und sogar wünschenswert sind! Ohne Änderungsbewusstsein sind Systeme unflexibel, können sich nicht weiterentwickeln oder reagieren und sind schlichtweg nicht in der Lage, mit Echtzeitdaten aus der realen Welt Schritt zu halten. In einer früheren 2-teiligen Blogserie (Teil 1, Teil 2) haben wir herausgefunden, wie man mit dem Debezium Cassandra Connector Änderungsdaten aus einer Apache Cassandra®-Datenbank erfasst und Echtzeit-Ereignis-Streams in Apache Kafka® erzeugt.
Aber wie kann man einen „Elefanten“ (PostgreSQL®) auf das Tempo eines „Geparden“ (Kafka) bringen?

Geparden sind die schnellsten Landtiere (Spitzengeschwindigkeit 120 km/h, Beschleunigung von 0 auf 100 km/h in 3 Sekunden) – 3-mal schneller als Elefanten (40 km/h). (Quelle: Shutterstock)
1. Der Debezium PostgreSQL Connector
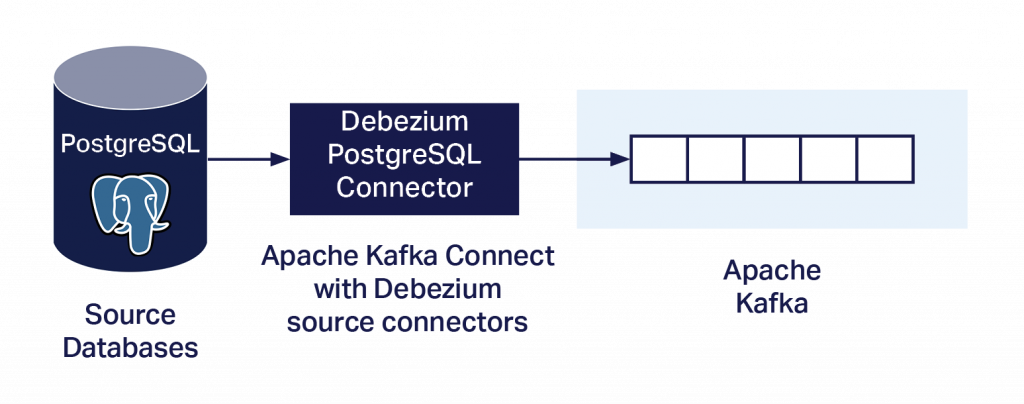
Ähnlich wie der Debezium Cassandra Connector (Blog Teil 1, Teil 2) erfasst auch der Debezium PostgreSQL Connector Datenbankänderungen auf Zeilenebene und überträgt den Stream über Kafka Connect an Kafka. Ein wesentlicher Unterschied besteht jedoch darin, dass dieser Connector als Kafka-Quellconnector ausgeführt wird. Wie lässt sich also vermeiden, dass auf dem PostgreSQL-Server benutzerdefinierter Code ausgeführt werden muss? Aus der Dokumentation geht Folgendes hervor:
„Ab PostgreSQL 10 gibt es einen logischen Replikations-Stream-Modus, genannt
pgoutput, der nativ von PostgreSQL unterstützt wird. Das bedeutet, dass ein Debezium PostgreSQL Connector diesen Replikations-Stream nutzen kann, ohne dass zusätzliche Plug-ins erforderlich sind.“
Somit kann der Connector einfach als PostgreSQL Streaming Replication Client ausgeführt werden. Um den Connector auszuführen, müssen Sie ihn herunterladen, in Ihrer Kafka Connect-Umgebung installieren, konfigurieren, PostgreSQL einrichten und dann wie folgt ausführen.
1.1. Debezium PostgreSQL Connector herunterladen
Der Connector kann hier heruntergeladen werden.
1.2. Debezium PostgreSQL Connector installieren
Ich werde hier den Dienst Instaclustr Managed Kafka Connect verwenden. Mit diesem Dienst können benutzerdefinierte Connectors verwendet werden, allerdings müssen sie zunächst in einen AWS S3 Bucket geladen und dann über die Instaclustr-Verwaltungskonsole synchronisiert werden. (Ich habe in meinem S3 Bucket einen Ordner mit dem Namen debezium-connector-postgres erstellt und alle Jars aus dem ursprünglichen Download in diesen Ordner hochgeladen.)
Wenn alles funktioniert hat, sehen Sie in der Liste der verfügbaren Connectors auf der Konsole einen neuen Connector mit dem Namen io.debezium.connector.postgresql.PostgresConnector.
1.3. PostgreSQL konfigurieren
Hier sind die erforderlichen PostgreSQL-Servereinstellungen:
- Prüfen Sie
wal_level. Wenn dies nicht auflogicalsteht, setzen Sie es auflogical. (Dazu ist ein Server-Neustart und bei einem verwalteten Dienst ggf. Unterstützung erforderlich.) - Für PostgreSQL > 10+ sind keine zusätzlichen Plug-ins erforderlich, da
pgoutputverwendet wird (Sie müssen jedoch das Standard-Plug-inplugin.namein der Konfiguration des Connectors überschreiben, siehe unten). - Benutzerberechtigungen konfigurieren
a. Laut Anweisungen soll ein Debezium-Benutzer erstellt werden, der über die erforderlichen Mindestrechte verfügt (REPLICATION-undLOGIN-Rechte),
b. und umpgoutputzu verwenden, benötigen Sie weitere Berechtigungen.
Beachten Sie, dass für diese Einstellungen Administratorrechte für PostgreSQL nötig sind. Wenn Sie also einen verwalteten Dienst verwenden, müssen Sie möglicherweise die Hilfe Ihres Dienstanbieters in Anspruch nehmen, um die notwendigen Änderungen vorzunehmen.
1.4. Debezium PostgreSQL Connector konfigurieren und ausführen
Damit Sie den Connector ausführen können, finden Sie hier ein Beispiel für eine Connector-Konfiguration. Beachten Sie, dass der Standardwert von plugin.name nicht pgoutput ist, weshalb Sie ihn explizit angeben müssen (geben Sie die IP-Adresse, den Benutzernamen und das Passwort für den Kafka Connect-Cluster und die IP-Adresse, den Benutzernamen und das Passwort für die PostgreSQL-Datenbank an):
curl https://KafkaConnectIP:8083/connectors -X POST -H 'Content-Type: application/json' -k -u kc_username:kc_password -d '{
"name": "debezium-test1",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "PG_IP",
"database.port": "5432",
"database.user": "pg_username",
"database.password": "pg_password",
"database.dbname" : "postgres",
"database.server.name": "test1",
"plugin.name": "pgoutput"
}
}
Wenn das korrekt funktioniert hat, sehen Sie in der Instaclustr Kafka Connect-Konsole einen einzelnen laufenden Task für debezium-test1. Beachten Sie, dass der Standardwert und auch der einzige zulässige Wert für tasks.max genau 1 ist, sodass Sie ihn nicht explizit festlegen müssen.
1.5. Tabellen-Themen-Zuordnungen mit Debezium PostgreSQL Connector
Vielleicht fällt Ihnen auf, dass in der Konfiguration keine Tabellennamen oder Themen angegeben sind. Das liegt daran, dass der Connector standardmäßig Änderungen für alle Nicht-System-Tabellen erfasst und Ereignisse für eine einzelne Tabelle in ein einzelnes Kafka-Thema schreibt.
Standardmäßig lautet der Name des Kafka-Themas serverName.schemaName.tableName, wobei:
• serverName der logische Name des Connectors wie im Konfigurationsmerkmal des Connectors database.server.name angegeben ist (und eindeutig sein muss)
• schemaName der Name des Datenbankschemas ist
• tableName der Name der Datenbanktabelle ist
Es gibt eine Reihe von Konfigurationsoptionen zum Ein- oder Ausschließen von Schemata, Tabellen und Spalten. (Verwenden Sie nur eine für jedes Objekt.)
Ich konnte keine PostgreSQL Connector-spezifischen Konfigurationsoptionen finden, um die standardmäßige Tabellen-Thema-Zuordnung zu ändern; das liegt jedoch daran, dass Sie generische Debezium Single Message Transforms, SMTs für benutzerdefiniertes Topic Routing, verwenden müssen.
2. Daten-Änderungsereignisse von Debezium PostgreSQL Connector kennenlernen

Ein furchterregender „Giraffosaurus“! (Oder eine T-Raffe?) (Quelle: Shutterstock)
Wenn alles richtig funktioniert, sehen Sie einige Daten-Änderungsereignisse in einem Kafka-Thema. Bei einer Tabelle mit dem Namen test1 lautet der Themenname beispielsweise test1.public.test1. Die Tabelle hat 3 ganzzahlige Spalten (id, v1, v2); id ist der Primärschlüssel.
Wie sehen nun die Kafka-Daten aus? Auf den ersten Blick sehen sie etwas unheimlich aus – in was haben sich die einfachen CRUD-Operationen der Datenbank verwandelt? Dies ist das Ereignis für eine Einfügung:
Struct{after=Struct{id=1,v1=2,v2=3},source=Struct{version=1.6.1.Final,connector=postgresql,name=test1,ts_ms=1632457564326,db=postgres,sequence=["1073751912","1073751912"],schema=public,table=test1,txId=612,lsn=1073751968},op=c,ts_ms=1632457564351}
Für eine Aktualisierung erhalten wir dieses Ereignis:
Struct{after=Struct{id=1,v1=1000,v2=3},source=Struct{version=1.6.1.Final,connector=postgresql,name=test1,ts_ms=1632457801633,db=postgres,sequence=["1140858536","1140858536"],schema=public,table=test1,txId=627,lsn=1140858592},op=u,ts_ms=1632457801973}
Und nach einer Löschung erhalten wir dieses Ereignis:
Struct{before=Struct{id=1},source=Struct{version=1.6.1.Final,connector=postgresql,name=test1,ts_ms=1632457866810,db=postgres,sequence=["1140858720","1140858720"],schema=public,table=test1,txId=628,lsn=1140858776},op=d,ts_ms=1632457867187}
NullWas fällt uns bei diesen Ereignissen auf? Wie erwartet, entspricht der Operationstyp (c, u, d) der PostgreSQL-Operationssemantik (create – für ein insert, update, delete). Für create und update gibt es einen after-Datensatz, der die ID und die Werte anzeigt, nachdem die Transaktion durchgeführt wurde. Für delete gibt es einen before-Datensatz, der nur die ID enthält, und ein Null für die after-Werte. Außerdem gibt es viele Metadaten, darunter die Zeit, datenbankspezifische Sequenz- und „lsn“-Informationen und eine Transaktions-ID. Mehrere Ereignisse können sich eine Transaktions-ID teilen, wenn sie im selben Transaktionskontext aufgetreten sind. Wofür ist die Transaktions-ID nützlich? Transaktions-Metadaten , die der txId entsprechen, können in topics mit dem Postfix .transaction geschrieben werden (provide.transaction.metadata ist standardmäßig false).
Diese Daten haben mich zunächst überrascht, da ich nach der ersten Lektüre der Dokumentation etwas besser lesbare (JSON) Änderungsereignisdaten einschließlich Schlüssel- und Wertschemata sowie Nutzdaten erwartet hatte. Aber das „Kleingedruckte“ besagt:
„Daraus, wie Sie den Kafka Connect Converter konfigurieren, den Sie in Ihrer Anwendung verwenden möchten, ergibt sich die Darstellung dieser vier Teile in Änderungsereignissen.“
Offensichtlich war also meine Konfiguration unvollständig. Mit ein bisschen Suchen entdeckte ich die folgenden zusätzlichen Konfigurationseinstellungen: key/value.converter und key/value.schemas.enable werden benötigt, um die Schlüssel- und Werteschemata in die Daten aufzunehmen, und das JSON-Format sollte verwendet werden:
"value.converter": "org.apache.kafka.connect.json.JsonConverter""value.converter.schemas.enable": "true""key.converter": "org.apache.kafka.connect.json.JsonConverter""key.converter.schemas.enable": "true"Nach der Änderung der Konfiguration und einem Neustart des Connectors sind die generierten Daten zwar viel ausführlicher, aber zumindest jetzt wie erwartet im JSON-Format. Bei einer insert-Operation erhalten wir zum Beispiel dieses lange Ereignis:
{"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"int32","optional":true,"field":"v1"},{"type":"int32","optional":true,"field":"v2"}],"optional":true,"name":"test1.public.test1.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"int32","optional":true,"field":"v1"},{"type":"int32","optional":true,"field":"v2"}],"optional":true,"name":"test1.public.test1.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":false,"field":"schema"},{"type":"string","optional":false,"field":"table"},{"type":"int64","optional":true,"field":"txId"},{"type":"int64","optional":true,"field":"lsn"},{"type":"int64","optional":true,"field":"xmin"}],"optional":false,"name":"io.debezium.connector.postgresql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"test1.public.test1.Envelope"},"payload":{"before":null,"after":{"id":10,"v1":10,"v2":10},"source":{"version":"1.6.1.Final","connector":"postgresql","name":"test1","ts_ms":1632717503331,"snapshot":"false","db":"postgres","sequence":"[\"1946172256\",\"1946172256\"]","schema":"public","table":"test1","txId":1512,"lsn":59122909632,"xmin":null},"op":"c","ts_ms":1632717503781,"transaction":null}}Die expliziten Schema-Metadaten machen die Sache ziemlich komplex, also schalten wir sie folgendermaßen ab:
"value.converter.schemas.enable": "false""key.converter.schemas.enable": "false"Dies ergibt einen besser lesbaren Datensatz, der nur die Nutzdaten enthält (oben hervorgehoben, aber beachten Sie, dass „payload“ nicht mehr angezeigt wird):
{"before":null,"after":{"id":10,"v1":10,"v2":10},"source":{"version":"1.6.1.Final","connector":"postgresql","name":"test1","ts_ms":1632717503331,"snapshot":"false","db":"postgres","sequence":"[\"1946172256\",\"1946172256\"]","schema":"public","table":"test1","txId":1512,"lsn":59122909632,"xmin":null},"op":"c","ts_ms":1632717503781,"transaction":null}Beachten Sie, dass wir jetzt ein before-Feld und ein after-Feld für create-Operationen haben.
Beachten Sie auch, dass ohne explizites Schema der Kafka-Sink-Connector in der Lage sein muss, die Nutzdaten ohne zusätzlichen Kontext zu verstehen, oder Sie müssen alternativ eine Schema Registry verwenden und konfigurieren. Hier sind die Anweisungen für die Verwendung einer Kafka Schema Registry mit dem von Instaclustr verwalteten Kafka-Dienst. Änderungen an der Konfiguration des Debezium-Quellconnectors müssen Folgendes enthalten:
"value.converter": "io.confluent.connect.avro.AvroConverter""value.converter.schema.registry.url": "http://schema-registry:8081"Ich war neugierig, was nach einer truncate-Operation an einer Tabelle passieren würde, aber überraschenderweise wurden überhaupt keine Ereignisse generiert. Ist ein truncate nicht semantisch gleichwertig mit mehreren delete-Operationen? Wie sich herausstellt, sind truncate-Ereignisse standardmäßig ausgeschaltet („truncate.handling.mode“ : „skip“ – nicht „bytes“, wie fälschlicherweise dokumentiert; „include“, um sie einzuschalten).
Die andere Überlegung ist, dass der Kafka-Sink-Connector in der Lage sein muss, truncate-Ereignisse vernünftig zu verarbeiten, was anwendungsspezifisch und/oder Sink-system-spezifisch sein kann. (Z. B. könnte es für Elasticsearch sinnvoll sein, als Reaktion auf ein truncate-Ereignis einen gesamten Index zu löschen. Für die Stream-Verarbeitung hingegen ist es nicht offensichtlich, was eine sinnvolle Reaktion wäre. Allerdings tritt das gleiche Problem vielleicht auch bei Löschungen und Aktualisierungen auf.)
3. Durchsatz des Debezium PostgreSQL Connectors

Wie schnell kann ein Debezium PostgreSQL Connector ausgeführt werden? (Quelle: Shutterstock)
Eine Einschränkung des Debezium PostgreSQL Connectors ist, dass er nur als einzelner Task ausgeführt werden kann. Ich habe einige Auslastungstests durchgeführt und festgestellt, dass ein einzelner Task maximal 7.000 Daten-Änderungsereignisse pro Sekunde verarbeiten kann. Dies entspricht auch den Transaktionen pro Sekunde, solange es nur ein Änderungsereignis pro Transaktion gibt. Bei mehreren Ereignissen pro Transaktion ist der Transaktionsdurchsatz geringer. In einem früheren Blog (Pipeline-Blogserie Teil 9) haben wir 41.000 Einfügungen pro Sekunde in PostgreSQL erreicht. Davon sind 7.000 lediglich 17 %. Dieser Teil der CDC-Pipeline ist also in der Praxis eher ein Elefant als ein Gepard. Typische PostgreSQL-Workloads bestehen jedoch aus eine Mischung an Schreib- und Lesevorgängen, sodass die Schreibrate wesentlich geringer sein kann, was den Debezium PostgreSQL Connector zu einer praktikableren Lösung macht.
Ich habe noch ein weiteres, etwas merkwürdiges Verhalten festgestellt, das Sie vielleicht beachten sollten. Wenn zwei (oder mehr) Tabellen auf Änderungsereignisse überwacht werden und die Last nicht gleichmäßig auf die Tabellen verteilt ist (z. B., wenn ein Batch von Änderungen in einer Tabelle kurz vor der nächsten auftritt), dann verarbeitet der Connector alle Änderungen der ersten Tabelle, bevor er mit den Änderungen für die zweite Tabelle beginnt. Bei dem von mir entdeckten Beispiel kam es zu einer Verzögerung von 10 Minuten. Ich bin mir nicht ganz sicher, was da vor sich geht, aber es sieht so aus, als ob der Connector alle Änderungen für eine Tabelle verarbeiten muss, bevor er zur nächsten Tabelle übergeht. Bei normalen, ausgeglichenen Workloads mag dies in Ordnung sein, aber bei Spitzen-/Batch-Lasten, die eine einzelne Tabelle stark auslasten, kann es Probleme bei der rechtzeitigen Verarbeitung von Änderungsereignissen aus anderen Tabellen verursachen.
Eine mögliche Lösung ist, mehrere Connectors zu verwenden. Dies scheint möglich zu sein (siehe z. B. diesen nützlichen Blog) und kann auch dazu beitragen, das Limit für die Verarbeitung von 7.000 Ereignissen pro Sekunde zu beseitigen. Allerdings würde es wahrscheinlich nur funktionieren, wenn sich die Tabellen zwischen den Connectors nicht überschneiden, und Sie müssten mehrere Replication-Slots haben, damit es funktioniert (es gibt eine Konfigurationsoption des Connectors für slot.name).
4. Debezium PostgreSQL Connector Datenänderungs-Erfassungsereignisse mit Kafka Sink-Connectors in Elasticsearch streamen

Die endgültige Metamorphose – vom Gepard (Kafka) zum Nashorn! (Sink-System, z. B. Elasticsearch) (Quelle: Shutterstock)
Es ist natürlich nicht das Ziel, genügend Daten-Änderungsereignisse in Kafka zu erhalten und sie zu verstehen, sondern sie in ein oder mehrere Sink-Systems zu streamen.
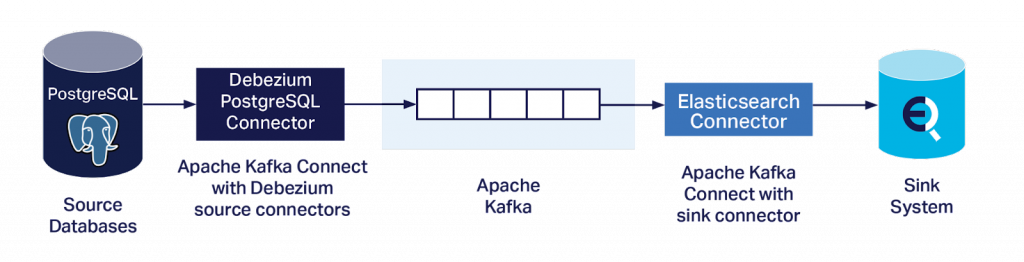
Ich wollte jedoch eine einfache Möglichkeit haben, das komplette End-to-End-System zu testen. Insbesondere mit einem Ansatz, der keine benutzerdefinierten Kafka Connect Sink-Connectors benötigt, um komplexe Daten-Änderungsereignisse und die Semantik des Sink-Systems zu interpretieren, oder eine Schema Registry betreiben muss (was wahrscheinlich auch einen benutzerdefinierten Quellconnector erfordern würde). Deshalb habe ich die Elasticsearch Sink-Connectors aus der letzten Pipeline-Blogserie wiederverwendet. Dieser Ansatz hat sich bereits beim Lesen von JSON-Daten ohne Schema bewährt und schien daher auch für diesen Anwendungsfall ideal.
Das „erste Taxi in der Schlange“ (in Zeiten von Fahrgemeinschafts-Apps eine anachronistische Wendung) ist der Apache Camel Kafka Elasticsearch Sink-Connector. Dies war der Connector, der sich bei früheren Experimenten als am robustesten erwiesen hatte. Leider fehlte dieses Mal eine Klasse (org.elasticsearch.rest.BytesRestResponse), was ich nicht weiter zu beheben versucht habe. Wahrscheinlich wäre ich kein guter Spion, denn jeder, der sich im Spionagehandwerk auskennt, weiß, dass man nicht das erstbeste Taxi nehmen sollte, das um die Ecke kommt!
Für meinen zweiten Versuch verwendete ich einen weiteren quelloffenen Elasticsearch Sink-Connector von lenses.io, der standardmäßig im Managed Kafka Connect-Dienst von Instaclustr enthalten ist.
Hier eine Beispielkonfiguration für diesen Connector (geben Sie die IP-Adressen von Kafka Connect und Elasticsearch sowie Benutzernamen und Passwörter an):
curl https://KC_IP:8083/connectors/elastic-sink-tides/config -k -u KC_user:KC_password -X PUT -H 'Content-Type: application/json' -d '
{
"connector.class" : "com.datamountaineer.streamreactor.connect.elastic7.ElasticSinkConnector",
"tasks.max" : 100,
"topics" : "test1.public.test1",
"connect.elastic.hosts" : "ES_IP",
"connect.elastic.port" : 9201,
"connect.elastic.kcql" : "INSERT INTO test-index SELECT * FROM test1.public.test",
"connect.elastic.use.http.username" : "ES_user",
"connect.elastic.use.http.password" : "ES_password"
}
}'
Der Task wurde korrekt ausgeführt. Beachten Sie, dass wir für die Verarbeitung von 7.000 Ereignissen pro Sekunde mehrere Sink-Connector-Tasks benötigen, und Sie müssen auch die Anzahl der Kafka-Partitionen entsprechend erhöhen (Partitionen >= Tasks).
Eine Einschränkung dieser Connector-Konfiguration besteht darin, dass sie alle Ereignisse als insert-Ereignisse verarbeitet. Unsere Daten-Änderungsereignisse können jedoch before– und after-Felder haben, von denen er nichts weiß, wodurch Sie „Junk“ im Elasticsearch-Index erhalten, den Sie anschließend interpretieren müssen. Eine einfache Lösung ist die Verwendung einer SMT (Single Message Transformation) auf dem Sink-Connector, um nur die after-Felder zu extrahieren. Ich habe den ExtractNewRecordState SMT zum „Abflachen der Ereignisse“ verwendet. Hier ist die endgültige Konfiguration des Debezium PostgreSQL-Quellconnectors einschließlich des SMT:
curl https://KC_IP:8083/connectors -X POST -H 'Content-Type: application/json' -k -u kc_user:kc_password -d '{
"name": "debezium-test1",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "pg_ip",
"database.port": "5432",
"database.user": "pg_user",
"database.password": "pg_password",
"database.dbname" : "postgres",
"database.server.name": "test1",
"plugin.name": "pgoutput",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState"
}
}
'
Um schließlich alles zu überprüfen, habe ich meine ursprünglichen NOAA-Pipeline-Daten und -Themen wiederverwendet. Dadurch konnte ich auch prüfen, ob die JSON-Daten wie erwartet in Elasticsearch indiziert wurden (obwohl ich dieses Mal nur Standard-Zuordnungen verwendet habe), und ich konnte auch prüfen, ob es einen Unterschied im Durchsatz zwischen PostgreSQL JSON- und JSONB-Lesevorgängen (mit einem GIN-Index) gab – ich freue mich, berichten zu können, dass es keinen gab.
Wie ich jedoch in der Pipeline-Blogserie Teil 8 entdeckte, haben Elasticsearch Sink-Connectors Schwierigkeiten, mehr als 1.800 Einfügungen pro Sekunde zu indizieren, was weit unter der Task-Beschränkung bei Single-Thread-Connectors von 7.000 Ereignissen pro Sekunde liegt (in Teil 9 haben wir jedoch mit einem Workaround und der BULK-API bessere Ergebnisse erzielt), womit jeglicher Unterschied zwischen JSON- und JSONB-Performance eventuell maskiert wird, aber das ist sicherlich nicht das Haupt-Performanceproblem.
5. Fazit
In diesem Blog haben wir erfolgreich eine Test-CDC-Pipeline von PostgreSQL zu einem Beispiel-Sink-System (z. B. Elasticsearch) unter Verwendung des Debezium PostgreSQL Connectors und des Instaclustr Managed Kafka Connect und OpenDistro Elasticsearch-Dienst bereitgestellt, konfiguriert und ausgeführt. Für viele Anwendungsfälle werden Sie komplexere Kafka Sink-Connectors benötigen, um die Semantik des Daten-Änderungsereignisses und ihre Anwendung auf verschiedene Sink-Systems zu interpretieren, und es gibt noch viele weitere Konfigurationsoptionen, die ich nicht berücksichtigt habe. In Anbetracht der potenziellen Einschränkungen im Single-Task-Betrieb und anderer potenzieller Eigenarten in Bezug auf die Performance sollten Sie ebenfalls einen geeigneten Leistungs- und Verzögerungstest mit realistischen Daten und angemessen dimensionierten Systemen durchführen, bevor Sie in die Produktion gehen.
Hinweis: Die Experimente in diesem Blog wurden in einer Entwicklungsumgebung durchgeführt. Dabei wurde eine Kombination aus Open-Source-/selbstverwaltetem PostgreSQL (nicht unser verwalteter PostgreSQL-Dienst) in Verbindung mit den verwalteten Diensten Kafka Connect und Elasticsearch von Instaclustr verwendet. Derzeit haben wir Kunden, die Debezium in einer privaten Preview für unseren verwalteten Cassandra-Dienst verwenden, aber zum Zeitpunkt der Veröffentlichung wird Debezium noch nicht für unseren verwalteten PostgreSQL-Dienst angeboten.
Der Orininalartikel stammt von Paul Brebner und wurde auf Instaclustr.com am 9. August 2022 veröffentlicht.