PostgreSQL® 13 Bits: Deduplication in B-tree Indexe
| Kategorien: | Aktuelles PostgreSQL® |
|---|---|
| Tags: | PostgreSQL® PostgreSQL® 13 PostgreSQL® Competence Center |
Mit der kommenden Version 13 von PostgreSQL® werden B-tree Indexe in der Lage sein, mehrfach identisch vorkommende Spaltenwerte physikalisch kompakter abzuspeichern. Bereits mit Version 12 wurde eine Optimierung eingeführt, die B-tree Indexe ein effizienteres Speichern von wiederholt vorkommenden Spaltenwerten gestattet. Hierzu werden diese Spalten in derselben Reihenfolge auch im Index abgelegt, wie diese auch physikalisch im sogenannten Heap, also der physischen Repräsentation der Tabelle, vorkommen. Dies vereinfacht die Verwaltung dieser Indexeinträge und kann auch bereits mit dieser Maßnahme das Wachstum eines Indexes positiv beeinflussen.
In Version 13 werden nun effektiv wiederholt vorkommende Spaltenwerte zusammengefasst im B-tree Index gespeichert, Deduplication genannt. Eine sogenannte Posting List verwaltet dabei, als alternative Repräsentation eines Index Tupel die physischen Positionen an welcher Stelle in der Tabelle der jeweilige Spaltenwert zu finden ist. Diese Repräsentation ist deutlich kompakter als die Spaltenwerte jeweils für sich zu speichern. Ferner ermöglicht es auch das schnellere Auffinden von entsprechenden Spaltenwerten und VACUUM kann solche Indexe auch effizienter warten.
In schreibenden Workloads, die wenige oder gar keine mehrfach identischen Spaltenwerte enthalten, können unter Umständen kleinere Auswirkungen auf die Performance beobachtet werden. Die Deduplication Funktionalität kann beim Erzeugen eines Indexes mit dem Indexattribut deduplication_items abgeschaltet werden. In der aktuellen Beta 2 von PostgreSQL® 13 ist Deduplication standardmässig aktiviert, was sich jedoch bis zum finalen Release noch ändern kann. Die folgende Syntax schaltet das Feature explizit beim Anlegen eines Index aus:
CREATE INDEX ON table (spalte) WITH(deduplicate_items=off);
Üblicherweise jedoch speichern Anwendungen in der Regel Spaltenwerte pro Spalte häufiger mehrfach ab. Ausnahme sind UNIQUE Constraints oder Primary Keys, aber selbst bei diesen kann Deduplication Vorteile bieten. Kommen mehrere Versionen einer Zeile mit dem spezifischen eindeutigen Spaltenwert vor, kann Deduplication unnötigen Bloat im Index ebenfalls verhindern.
Beispiel von Deduplication
Das Ergebnis der kompakteren Indexstruktur lässt sich mit nachfolgendem Beispiel illustrieren. Die Query in diesem Beispiel erzeugt eine Datenmenge aus 10.000.000 numerischen Werten, die zufällig per random() auf 1000 unterschiedliche Werte begrenzt wird. Dadurch ist die jeweilige Größe der mehrfach vorkommenden Spaltenwerte ungleich verteilt.
INSERT INTO unique_test SELECT floor(generate_series(1, 10000000) % (random() * 1000)::numeric);
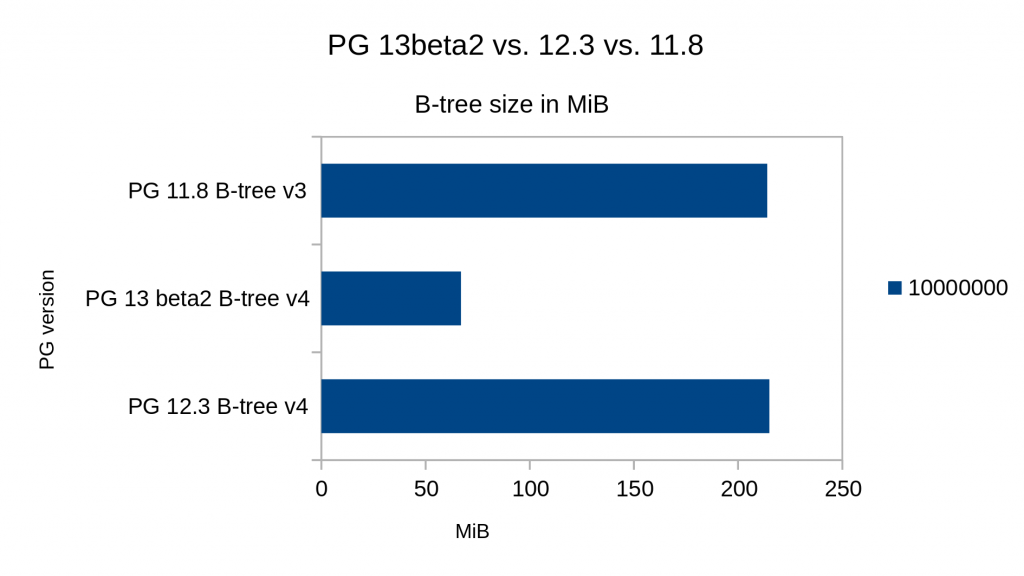
Vergleicht man in PostgreSQL® 11.8, 12.3 und 13beta2 nun die Indexgrößen, ergibt sich folgendes Bild:
 pg_upgrade, um eine bestehende PostgreSQL® Instanz von beispielsweise PostgreSQL® 12 auf 13 zu aktualisieren, werden alle physische Objekte in den neuen Cluster übernommen. Da Deduplication in PostgreSQL® auf jeden Fall eine neue Indexstruktur verwendet, können bestehende Indexe aus dem alten Cluster daher nicht ohne weiteres die Deduplication Funktionalität verwenden und müssen neu angelegt werden. Dies kann beispielsweise mit dem PostgreSQL® Kommando REINDEX oder dem äquivalenten Kommandozeilentool reindexdb erreicht werden. Dies gilt für Upgrades von allen älteren Major-Releases. Auch für Migrationen auf PostgreSQL® 12 müssen B-tree Indexe, die von den dort angesprochenen Optimierungen profitieren möchten, neu angelegt werden. In PostgreSQL® 13 hilft dabei auch die neue Option –jobs von reindexdb diesen Prozess zu beschleunigen, indem Indexe parallel mit der angebenen Anzahl an Prozessen aufgebaut werden können.
pg_upgrade, um eine bestehende PostgreSQL® Instanz von beispielsweise PostgreSQL® 12 auf 13 zu aktualisieren, werden alle physische Objekte in den neuen Cluster übernommen. Da Deduplication in PostgreSQL® auf jeden Fall eine neue Indexstruktur verwendet, können bestehende Indexe aus dem alten Cluster daher nicht ohne weiteres die Deduplication Funktionalität verwenden und müssen neu angelegt werden. Dies kann beispielsweise mit dem PostgreSQL® Kommando REINDEX oder dem äquivalenten Kommandozeilentool reindexdb erreicht werden. Dies gilt für Upgrades von allen älteren Major-Releases. Auch für Migrationen auf PostgreSQL® 12 müssen B-tree Indexe, die von den dort angesprochenen Optimierungen profitieren möchten, neu angelegt werden. In PostgreSQL® 13 hilft dabei auch die neue Option –jobs von reindexdb diesen Prozess zu beschleunigen, indem Indexe parallel mit der angebenen Anzahl an Prozessen aufgebaut werden können.Verwendung bestimmer Datentypen
Der numerische Datentyp numeric kann nicht dedupliziert werden, da der Skalierungsfaktor eines jeden Spaltenwertes erhalten bleiben muss. B-tree Indexe auf Spalten dieses Typs werden daher automatisch nicht dedupliziert. Dasselbe gilt im Wesentlichen für den Datentyp jsonb. Da dieser intern numeric verwendet unterliegt jsonb denselben Einschränkungen. Bei dem Datentyp float4 gibt es unterschiedliche Repräsentationen des Wertes 0. Wie bei numeric mit dem entsprechenden scale factor muss bei float4 die jeweils unterschiedliche Repräsentation erhalten bleiben, was die Verwendung von Deduplizierung ausschließt. Spalten vom Typ text die eine Sortierreihenfolge verwenden die nicht-deterministisch ist können ebenfalls nicht dedupliziert werden.
Auch sogenannte Composite, also zusammengesetzte Datentypen, Arrays sowie Range Type verhindern die Nutzung der Funktion, allerdings hat dies keine formalen Gründe, sondern ist aktuell nicht implementiert. B-tree Indexe die mit der INCLUDE Direktive angelegt wurden, können ebenfalls aktuell keine Deduplizierung verwenden.
Bei Fragen rund um den Einsatz von PostgreSQL® 13 stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an! Unser PostgreSQL® Competence Center ist bei Bedarf 24 Stunden am Tag, an 365 Tagen im Jahr für Sie verfügbar.
| Kategorien: | Aktuelles PostgreSQL® |
|---|---|
| Tags: | PostgreSQL® PostgreSQL® 13 PostgreSQL® Competence Center |
über den Autor
Bernd Helmle
Technischer Leiter Datenbanken
zur Person
Bernd Helmle arbeitet als Datenbankberater und -entwickler für die credativ GmbH, Deutschland. Er verfügt über umfassende Erfahrung in der PostgreSQL<sup>®</sup>-Administration, Hochverfügbarkeitslösungen und PostgreSQL<sup>®</sup>-Optimierung und Performance-Tuning. Außerdem war er an verschiedenen Migrationsprojekten von anderen Datenbanken zu PostgreSQL<sup>®</sup> beteiligt. Bernd Helmle entwickelte und betreut die Informix Foreign Data Wrapper Erweiterung für PostgreSQL<sup>®</sup>.
Sie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Brevo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von Turnstile laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Turnstile. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen