PostgreSQL® 10 Bits - WAL-Logged Hashindex
| Kategorien: | PostgreSQL® |
|---|---|
| Tags: | PostgreSQL® |
Neben anderen Indextypen wie B-tree und BRIN, gibt es in PostgreSQL® seit langer Zeit den Hashindex. Von diesem wurde jedoch bisher oft abgeraten, da dieser Index keine REDO-Informationen im Transaktionslog (Write Ahead Log, WAL) unterstützte und damit weder Crash noch Replikationssicher war. Stürzte die PostgreSQL® unter Umständen ab, musste der Hashindex mit dem REINDEX Kommando neu erzeugt werden, da ansonsten Inkonistenzen auftreten konnten. PostgreSQL® Standbysysteme konnten bei Abfragen entsprechende Hashindexe nicht verwenden, da durch das Fehlen jeglicher Protokollierungen über das WAL diese nicht repliziert wurden.
In PostgreSQL®10 ändert sich dies, denn mit den Patch write-ahead logging support to hash indexes hat der Hashindex fehlende Funktionen dazugelernt und steht für das Featurerelease 10 bereit. Grund genug die Funktionsweise und Usecases zu beleuchten.
Theorie
In der Theorie sind Hashindexe zunächst recht simpel. Die Voraussetzung ist, dass das Hashing eines Wertes eine Position im Index definiert, welche die Zielinformation beinhaltet. Dadurch kann, mittels nur eines Indexschrittes, die Position im Heap bestimmt werden. Die Laufzeit in Relation zur Datenmenge ist demnach O(1), also somit sind die Zugriffszeiten im Hashindex im Ideal konstant. Ein sortierter Index, wie etwa der B-tree, erreicht dieses Ziel auch, jedoch in der Regel in O(log(n) ), denn hier muss eine Baumstruktur von Wurzel bis Blatt traversiert werden. Dies bedeutet in der Regel mehrere Zugriffszyklen, bis das richtige Blatt gefunden wurde.
Die PostgreSQL® Implementierung des Hashindex basiert dabei auf dem Paper A new Hashing Package for UNIX von Selzer und Yigit. Diese Implementierung erreicht durch die Verwendung einer Metapage, den Zielbuckets sowie Overflowbuckets, dynamisches Wachstum des Indexes, behält jedoch das typische Laufzeitcharakteristikum der Hashindexe bei.
Laufzeit
In der Praxis divergiert primär die Rechenzeit. Hierbei gewinnt der Hash dann, wenn das Hashing des Wertes selbst billiger wird, als die notwendigen Vergleiche und Sprünge im B-tree. Hier ist eine Differenzierung des Vergleiches notwendig, denn der Vergleich zweier Ganzzahltypen ist beispielsweise deutlich billiger als der alphanumerische Vergleich zweier Zeichenketten, wie das folgende Beispiel anhand einer Sortierung illustriert.
EXPLAIN ANALYZE SELECT id FROM generate_series(1,100000)id ORDER BY 1 DESC Time: 0.3s EXPLAIN ANALYZE SELECT id::text FROM generate_series(1,100000)id ORDER BY 1 DESC Time: 2.4s
Überträgt man diese Gegebenheit auf die Kosten der notwendigen Vergleiche eines Indexlookups, ergibt sich folgendes Bild:
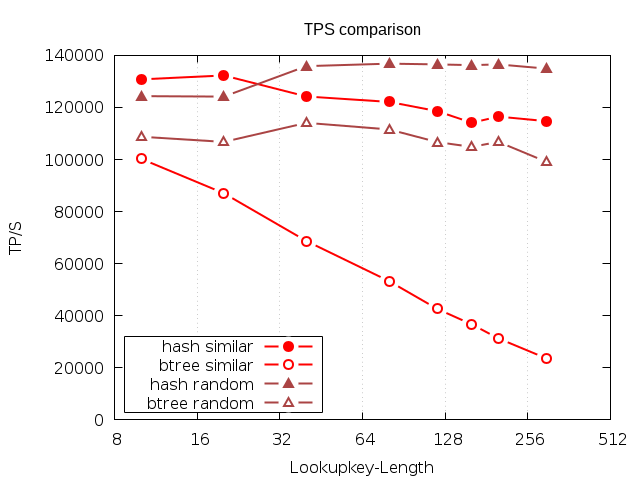
Der hier beschriebene Benchmark basiert auf vier nebenläufigen Verbindungen, welche zufällige Elemente aus einer Tabelle selektieren. Diese Elemente sind Textfelder. Bei der Testgruppe ’similar‘, sind die ersten Stellen des Keys identisch, bei ‚random‘ ist die gesamte Zeichenfolge zufällig. Der Datenbestand ist komplett gecached. Gemessen wird die hauptsächlich durch Rechenoperationen bedingte Laufzeit der Abfragen. Die Keys der Lookups werden in den Abfragen durch Funktionen definiert, dadurch sind die beiden Testsets in dem konkreten Durchsatz durch den unterschiedlichen Aufwand nicht miteinander vergleichbar.
CREATE TABLE test(key_1 text, key_2 text);
CREATE INDEX ON test USING HASH(key_1);
CREATE INDEX on test(key_2);
Sorted:
INSERT INTO test SELECT repeat('x', :width )||id , repeat('x', :width )|| id FROM generate_series(1, :scale ) id;
Random:
INSERT INTO test SELECT substr(md5(id::text)||repeat('x', :width -32 ), 0, :width ) , substr(md5(id::text) || repeat('x', :width -32),0, :width ) FROM generate_series(1, :scale ) id;
Es wird deutlich, dass die Kosten der Schlüsselsuche im B-tree mit seiner Länge skalieren. Da ein B-tree von Links nach Rechts vergleicht, ist eine deutliche Regression bei Keys zu erkennen, die über viele Zeichen ähnlich sind, wie es beispielsweise für URIs typisch sein kann.
PageFetches
Die Laufzeit des Hashindex beruht auf der Annahme, das Zieltupel könne durch die vom Hash des Keys berechnete Indexseite bestimmt werden. Die zusätzliche Metapage und gegebenenfalls auftretenden Overflowpages fallen ebenfalls ins Gewicht, doch die Metapage ist immer im Cache, und die Overflowpage statistisch eher unwahrscheinlich.
Dadurch erreicht der Hashindex eine sehr gute Laufzeit bei langsamen Random-Reads und eignet sich damit für Indexe, die selten verwendet werden, für den verfügbaren RAM deutlich zu groß, oder aus anderen Gründen nicht im RAM sind.
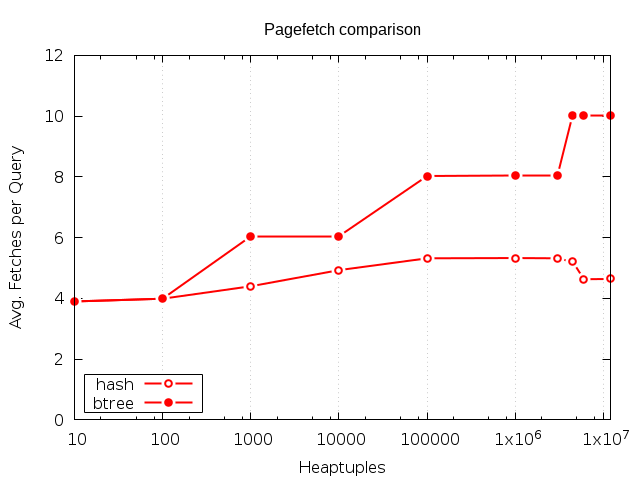
Der Benchmark zeigt, dass die Pagefetches des Hashindex bei vielen Tupeln weit unter denen des B-tree liegt. Betrachtet man eine Fetchdifferenz von vier mit einer durchschnittlichen IO-Wartezeit der Reads von 8ms wie es für 7200rpm HDDs typisch ist, würden hier Latenzunterschiede von bis zu 32ms pro Abfrage verzeichnet werden. Zudem ist der Randomread Durchsatz jedes Systems technisch limitiert, wodurch der Hash durch bessere Ressourcennutzung mehr Nebenläufigkeit erlauben kann.
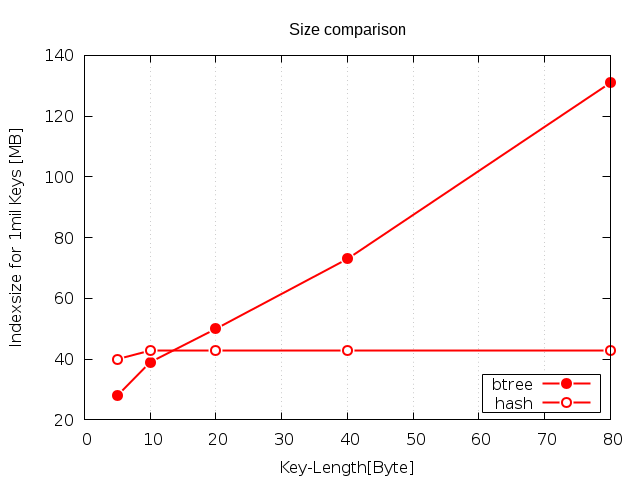
Größe
Hashindexe verwenden eine feste Keygröße. Damit ist die Größe des Index nur mit der Tupelmenge und nicht der Tupelgröße korelliert, was einen deutlichen Unterschied zu dem B-tree darstellt. Ein Hashindex ist bei der Betrachtung von Ganzzahltypen zwar bis zu 40% größer, bei variabler Keygröße wie sie bei Zeichenketten oft vorkommt dann jedoch deutlich kleiner.
Upgrade von früheren PostgreSQL® Versionen mit pg_upgrade
Aufgrund der beschriebenen Änderungen ist die physische Repräsentation von Hashindexe zwischen älteren PostgreSQL® Versionen (< 10) und PostgreSQL® 10 nicht mehr kompatibel. Wählt man als Upgradepfad den Weg über physisches Upgrade per pg_upgrade, so müssen alle Hashindexe per REINDEX neu erzeugt werden. pg_upgrade erkennt alle verwendeten Hashindexe in einer Instanz und invalidiert diese. Daher sind diese nicht mehr unmittelbar von der Datenbank nutzbar. pg_upgrade gibt bei der Überprüfung des Datenbankclusters einen Hinweis aus, ob Hashindexe verwendet werden und diese überführt werden müssen:
Your installation contains hash indexes. These indexes have different internal formats between your old and new clusters, so they must be reindexed with the REINDEX command. After upgrading, you will be given REINDEX instructions.
Nach dem pg_upgrade-Lauf findet man Arbeitsverzeichnis ein SQL-Skript reindex_hash.sql, das die notwendigen REINDEX-Kommandos für das Wiederaufbauen der Hashindexe enthält.
Zusammenfassung
Hashindexe bieten sich also besonders dort an, wo teure Operatoren oder große Datensätze den Index definieren. Die Verteilung der zugrundeliegenden Daten sollte zudem zufällig sein, denn der Hashindex unterstützt keine Bereichsabfragen (<, > sowie >= und <=) und auch eine Cacheaffinität ähnlicher Werte ist nicht gegeben. Können diese Annahmen über die Datenmenge getroffen werden, können die Vorteile des Hashindex einen deutlichen Mehrwert erreichen.
Weiterführende Links:
Dieser Artikel wurde ursprünglich geschrieben von Julian Schauder.
| Kategorien: | PostgreSQL® |
|---|---|
| Tags: | PostgreSQL® |
über den Autor
credativ Redaktion
zur Person
Dieser Account dient als Sammelpunkt für die wertvollen Beiträge ehemaliger Mitarbeiter von credativ. Wir bedanken uns für ihre großartigen Inhalte, die das technische Wissen in unserem Blog über die Jahre hinweg bereichert haben. Ihre Artikel bleiben hier weiterhin für unsere Leser zugänglich.