[Howto] Zentrales und semantisches Logging für PostgreSQL®
| Kategorien: | HowTos PostgreSQL® |
|---|---|
| Tags: | Logging PostgreSQL® |
Einleitung
Heute muss nicht mehr argumentiert werden, warum zentrales Logging sinnvoll oder sogar notwendig ist. Die meisten mittelständischen Unternehmen haben mittlerweile ein zentrales Logging oder führen dieses gerade ein.
Wenn die Infrastruktur einmal geschaffen ist, gilt es diese sinnvoll und effizient zu nutzen! Gerade als Infrastrukturbetreiber oder Dienstleister geht es darum verschiedene Akteure, mit verschiedenen Anforderungen, bestmöglich zu unterstützen. So sollte z.B. die Entwicklungsabteilung kontinuierlich Zugriff auf alle Logs ihrer Testsysteme haben. Aus der Produktion werden aber vielleicht nur alle Fehlermeldungen in Echtzeit benötigt, auf Freigabe jedoch auch mehr.
Solche Modelle lassen sich mit graylog® oder Kibana® leicht umsetzen und testen. Die Klassifizierung und Auswertung mag im Testbetrieb oder in kleinen Umgebungen auch mit den PostgreSQL®-Standardeinstellungen gut und performant funktionieren. Werden jedoch sehr viele Datenbanken betrieben oder die Logs lange aufgehoben, kann die Nutzung schnell schwierig werden.
Problemstellung
Die Logeinträge sind zentral erfasst und können prinzipiell verwendet werden. In der Praxis ist es jedoch schwierig bis unmöglich alle relevanten Informationen zeitnah zu extrahieren. Die Suche nach bestimmten Einträgen erfordert Volltextsuchen mit Wildcards, dies ist bei großen Datenbeständen nicht mehr praktikabel ist.
Möchte man beispielsweise bestimmten Gruppen ausschließlich Zugriff auf Logs geben, die bestimmten fachlichen Kriterien entsprechen, z.B. Datenbankname, error_severity oder der gleichen, muss dies über Volltextsuche und fehleranfällige Filter realisiert werden.
Möchte ein DBA z.B. alle Meldungen eines bestimmten Users, einer bestimmten Query oder einer Session sehen, wird hierzu eine besonders aufwendige Indizierung für Wildcard-Suchen benötigt. Alternativ sind solche Anfragen sehr langsam und können nicht sofort beantwortet werden.
| Ausgangspunkt: | Es wurde bereits ein Zentrales Logging eingeführt, z.B. ELK-Stack oder graylog®. |
| Ziel: | Wir möchten die PostgreSQL®-Logmeldungen semantisch erfassen und dadurch effizient: klassifizieren, gruppieren und auswerten. |
Alternative
Die Alternative besteht nun darin, die Logmeldungen semantisch zu erfassen und die einzelnen Felder in einer entsprechenden Datenstruktur abzulegen.
Wird das normale stderr-Log verwendet, gestaltet sich das Parsen als schwierig bis unmöglich, da die einzelnen Felder hier nicht zu erkennen sind. PostgreSQL® bietet jedoch auch die Möglichkeit Logmeldungen im CSV-Format zu produzieren (csvlog). Hiermit werden alle Felder Komma separiert ausgegeben.
Exkurs: Die Idee ist nicht neu. Seit Langem laden einige DBAs ihre Logs direkt wieder in eine PostgreSQL®-Tabelle. So können die Logs mit SQL und allen bekannten Boardmitteln durchsuchen und bearbeiten. Die DBAs sind meist sehr zufrieden mit diesem Konstrukt, es stellt jedoch eine Insellösung dar. Beispieltabelle PostgreSQL® 9.5:CREATE TABLE postgres_log ( log_time timestamp(3) with time zone, user_name text, database_name text, process_id integer, connection_from text, session_id text, session_line_num bigint, command_tag text, session_start_time timestamp with time zone, virtual_transaction_id text, transaction_id bigint, error_severity text, sql_state_code text, message text, detail text, hint text, internal_query text, internal_query_pos integer, context text, query text, query_pos integer, location text, application_name text, PRIMARY KEY (session_id, session_line_num) ); |
Aufbau
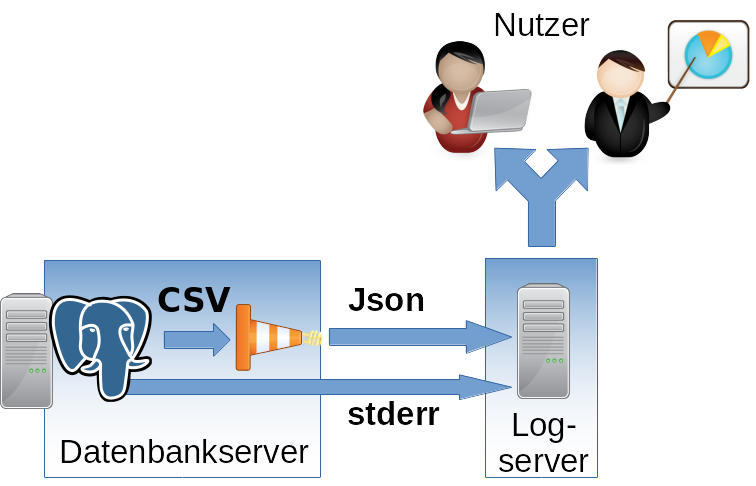
Umsetzung
Das csvlog kann als Grundlage für das effiziente Befüllen eines zentralen Loggingsystems dienen. Um hier die weitere Verarbeitung möglichst einfach zu gestalten und um sich auf kein Loggingsystem festlegen zu müssen, übersetzen wir das Log von CSV nach Json. Im Anschluss kann es dann beliebig eingespeist werden. Im folgenden Beispiel wird TCP verwendet.
Um das Logformat zu ändern müssen in PostgreSQL® folgende Optionen angepasst werden:
#------------------------------------------------------------------------------
# ERROR REPORTING AND LOGGING
#------------------------------------------------------------------------------
# - Where to Log -
log_destination = 'csvlog' # Valid values are combinations of
# stderr, csvlog, syslog, and eventlog,
# depending on platform. csvlog
# requires logging_collector to be on.
# This is used when logging to stderr:
logging_collector = on # Enable capturing of stderr and csvlog
# into log files. Required to be on for
# csvlogs.
# (change requires restart)
# These are only used if logging_collector is on:
log_directory = '/var/log/postgresql' # directory where log files are written,
# can be absolute or relative to PGDATAZum Parsen und Übersetzen in Json sowie zum Einliefern ins Loggingsystem verwenden wir logstash® mit folgender Konfiguration als Jinja2-Template:
input {
file {
"path" => "/var/log/postgresql/*.csv"
"sincedb_path" => "/tmp/sincedb_pgsql"
# fix up multiple lines in log output into one entry
codec => multiline {
pattern => "^%{TIMESTAMP_ISO8601}.*"
what => previous
negate => true
}
}
}
# Filter is testet for PostgreSQL® 9.5
filter {
csv {
columns => [ "pg_log_time", "pg_user_name", "pg_database_name",
"pg_process_id", "pg_connection_from", "pg_session_id",
"pg_session_line_num", "pg_command_tag",
"pg_session_start_time", "pg_virtual_transaction_id",
"pg_transaction_id", "pg_error_severity", "pg_sql_state_code",
"pg_sql_message", "pg_detail", "pg_hint", "pg_internal_query",
"pg_internal_query_pos", "pg_context", "pg_query",
"pg_query_pos", "pg_location", "pg_application_name" ]
}
date {
#2014-05-22 17:02:35.069 CDT
match => ["log_time", "YYYY-MM-dd HH:mm:ss.SSS z"]
}
mutate {
add_field => {
"application_name" => "postgres"
}
}
}
output {
tcp {
host => "{{ log_server }}"
port => {{ log_port }}
codec => "json_lines"
}
}Wichtig ist hier, dass der Filter zum Übersetzen der CSV-Felder an die verwendete PostgreSQL®-Hauptversion angepasst wird. Die Felder können sich von Version zu Version unterscheiden. In den meisten Fällen werden neue Felder hinzugefügt.
Auch zu beachten ist, dass logstash® Probleme hat den Timestamp eigenständig zu erkennen. Hier sollte das konkrete Format vorgegeben werden (Zeitzone).
Folgenden Variablen müssen gesetzt werden:
| {{ log_server }} | Logserver, in unserem Fall ein graylog® |
| {{ log_port }} | Port auf dem Logserver |
So konfiguriert, können die Logfiles effizient klassifiziert und durchsucht werden. Auch die Berechtigungen gestalten sich einfacher.
- Berechtigung auf Datenbankebene => pg_database_name
- Severity => pg_error_severity
- Berechtigung für Loggs durch bestimmte Hosts => pg_connection_from
- Berechtigung für Loggs durch bestimmte Anwendungen => pg_application_name
Wichtig: Das normale stderr-Log sollte in jedem Fall noch mit ins zentrale Logging aufgenommen werden. Hier landen zwar nach dem Start keine normalen Betriebsmeldungen von PostgreSQL® mehr, jedoch Fehlerausgaben von beteiligten Prozessen. Hier kann z.B. die stderr-Ausgabe eines fehlgeschlagenen Archivecommands gefunden werden. Dieses Informationen sind für die Administration essentiell.
Wir unterstützen bereits zahlreiche Kunden dabei das beschriebene Verfahren in Produktion zu betreiben. Falls Sie Fragen zu diesem Thema haben oder Unterstützung benötigen, dann können Sie sich selbstverständlich gern an unser PostgreSQL® Competence Center wenden.
Dieser Artikel wurde ursprünglich von Alexander Sosna verfasst.
| Kategorien: | HowTos PostgreSQL® |
|---|---|
| Tags: | Logging PostgreSQL® |
über den Autor
credativ Redaktion
zur Person
Dieser Account dient als Sammelpunkt für die wertvollen Beiträge ehemaliger Mitarbeiter von credativ. Wir bedanken uns für ihre großartigen Inhalte, die das technische Wissen in unserem Blog über die Jahre hinweg bereichert haben. Ihre Artikel bleiben hier weiterhin für unsere Leser zugänglich.