Analyse von PostgreSQL-Datenbeschädigung
| Kategorien: | PostgreSQL® |
|---|---|
| Tags: | planetpostgres planetpostgresql postgresql 18 |
PostgreSQL 18 hat eine sehr wichtige Änderung eingeführt: Datenblock-Prüfsummen sind jetzt standardmäßig für neue Cluster zum Zeitpunkt der Clusterinitialisierung aktiviert. Ich habe bereits in meinem vorherigen Artikel darüber geschrieben. Ich habe auch erwähnt, dass es immer noch viele bestehende PostgreSQL-Installationen ohne aktivierte Datenprüfsummen gibt, da dies in früheren Versionen die Standardeinstellung war. In diesen Installationen kann Datenbeschädigung manchmal zu mysteriösen Fehlern führen und die normale Funktionsweise verhindern. In diesem Beitrag möchte ich gängige PostgreSQL-Datenbeschädigungsmodi analysieren, um zu zeigen, wie man sie diagnostiziert und wie man sie behebt.
Beschädigungen in PostgreSQL-Beziehungen ohne Datenprüfsummen treten als Low-Level-Fehler wie „Ungültige Seite in Block xxx“, Transaktions-ID-Fehler, TOAST-Chunk-Inkonsistenzen oder sogar Backend-Abstürze auf. Leider können einige Backup-Strategien die Beschädigung maskieren. Wenn der Cluster keine Prüfsummen verwendet, können Tools wie pg_basebackup, die Datendateien so kopieren, wie sie sind, keine Validierung der Daten durchführen, sodass beschädigte Seiten unbemerkt in einem Basis-Backup landen können. Wenn Prüfsummen aktiviert sind, überprüft pg_basebackup diese standardmäßig, es sei denn, –no-verify-checksums wird verwendet. In der Praxis werden diese Low-Level-Fehler oft erst sichtbar, wenn wir direkt auf die beschädigten Daten zugreifen. Einige Daten werden selten berührt, was bedeutet, dass Beschädigungen oft erst bei dem Versuch auftreten, pg_dump auszuführen, da pg_dump alle Daten lesen muss.
Typische Fehler sind:
-- invalid page in a table: pg_dump: error: query failed: ERROR: invalid page in block 0 of relation base/16384/66427 pg_dump: error: query was: SELECT last_value, is_called FROM public.test_table_bytea_id_seq -- damaged system columns in a tuple: pg_dump: error: Dumping the contents of table "test_table_bytea" failed: PQgetResult() failed. pg_dump: error: Error message from server: ERROR: could not access status of transaction 3353862211 DETAIL: Could not open file "pg_xact/0C7E": No such file or directory. pg_dump: error: The command was: COPY public.test_table_bytea (id, id2, id3, description, data) TO stdout; -- damaged sequence: pg_dump: error: query to get data of sequence "test_table_bytea_id2_seq" returned 0 rows (expected 1) -- memory segmentation fault during pg_dump: pg_dump: error: Dumping the contents of table "test_table_bytea" failed: PQgetCopyData() failed. pg_dump: error: Error message from server: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. pg_dump: Fehler: Der Befehl war: COPY public.test_table_bytea (id, id2, id3, description, data) TO stdout;
Hinweis: In solchen Fällen beendet pg_dump leider beim ersten Fehler und fährt nicht fort. Aber wir können ein einfaches Skript verwenden, das in einer Schleife Tabellennamen aus der Datenbank liest und jede Tabelle separat in eine separate Datei sichert, wobei Fehlermeldungen in eine tabellenspezifische Protokolldatei umgeleitet werden. Auf diese Weise sichern wir sowohl Tabellen, die noch intakt sind, als auch finden alle beschädigten Objekte.
Fehler verstehen
Der schnellste Weg, diese Symptome zu verstehen, besteht darin, sie der beschädigten Stelle einer 8-KB-Heap-Seite zuzuordnen. Um dies testen zu können, habe ich ein Python-Skript zur „Beschädigungssimulation“ erstellt, das bestimmte Teile eines Datenblocks gezielt beschädigen kann. Damit können wir gängige Beschädigungsmodi testen. Wir werden sehen, wie man jeden einzelnen mit pageinspect diagnostiziert, prüfen, ob amcheck in diesen Fällen helfen kann, und zeigen, wie man Abfragen mit pg_surgery gezielt freigibt, wenn ein einzelnes Tupel eine ganze Tabelle unlesbar macht.
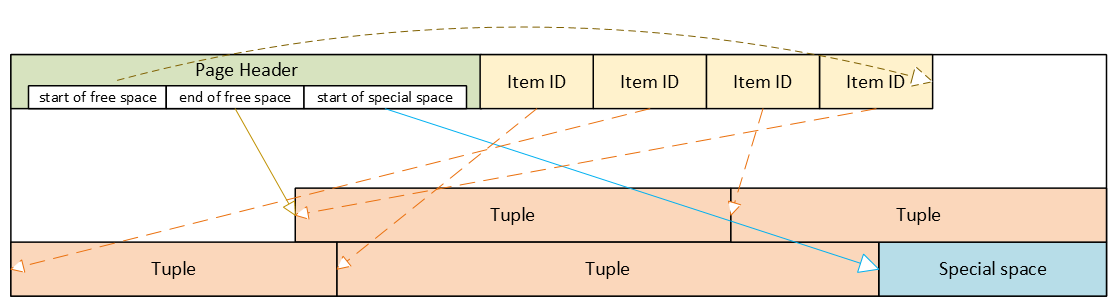
PostgreSQL-Heap-Tabellenformat
- Header: Metadaten für Blockverwaltung und -integrität
- Item-ID-Array (Tupel-Pointer): Einträge, die auf Tupel verweisen (Offset + Länge + Flags)
- Freier Speicherplatz
- Tupel: tatsächliche Zeilendaten, jeweils mit eigenem Tupel-Header (Systemspalten)
- Spezieller Speicherplatz: reserviert für indexspezifische oder andere beziehungsspezifische Daten – Heap-Tabellen verwenden ihn nicht
Beschädigter Seitenheader: der gesamte Block wird unzugänglich
Der Seitenheader enthält die Layout-Pointer für die Seite. Die wichtigsten Felder, die wir auch über pageinspect sehen können, sind:
- pd_flags: header flag bits
- pd_lower: offset to the start of free space
- pd_upper: offset to the end of free space
- pd_special: offset to the start of special space
- plus lsn, checksum, pagesize, version, prune_xid
ERROR: invalid page in block 285 of relation base/16384/29724
Dies ist die einzige Klasse von Beschädigungsfehlern, die durch Aktivieren von zero_damaged_pages = on übersprungen werden kann, wenn der Cluster keine Datenblock-Prüfsummen verwendet. Mit zero_damaged_pages = on werden Blöcke mit beschädigten Headern im Speicher „genullt“ und übersprungen, was buchstäblich bedeutet, dass der gesamte Inhalt des Blocks durch Nullen ersetzt wird. AUTOVACUUM entfernt genullte Seiten, kann aber nicht ungescannte Seiten nullen.
Woher der Fehler im PostgreSQL-Quellcode kommt
/* * Die folgenden Überprüfungen beweisen nicht, dass der Header korrekt ist, sondern nur, dass * es vernünftig genug aussieht, um in den Pufferpool aufgenommen zu werden. Spätere Verwendung von * der Block kann immer noch Probleme aufdecken, weshalb wir die * Checksummenoption anbieten. */ if ((p->pd_flags & ~PD_VALID_FLAG_BITS) == 0 && p->pd_lower <= p->pd_upper && p->pd_upper <= p->pd_special && p->pd_special <= BLCKSZ && p->pd_special == MAXALIGN(p->pd_special)) header_sane = true; if (header_sane && !checksum_failure) return true;
SELECT * FROM page_header(get_raw_page('pg_toast.pg_toast_32840', 100));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
------------+----------+-------+-------+-------+---------+----------+---------+-----------
0/2B2FCD68 | 0 | 4 | 40 | 64 | 8192 | 8192 | 4 | 0
Wenn der Header als beschädigt getestet wird, können wir mit SQL nichts diagnostizieren. Mit zero_damaged_pages = off endet jeder Versuch, diese Seite zu lesen, mit einem ähnlichen Fehler wie im obigen Beispiel. Wenn wir zero_damaged_pages = on setzen, wird beim ersten Versuch, diese Seite zu lesen, alles durch Nullen ersetzt, einschließlich des Headers:
SELECT * from page_header(get_raw_page('pg_toast.pg_toast_28740', 578)); WARNING: invalid page in block 578 of relation base/16384/28751; zeroing out page lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid -----+----------+-------+-------+-------+---------+----------+---------+----------- 0/0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
Beschädigtes Item-IDs-Array: Offsets und Längen werden unsinnig
- ERROR: invalid memory alloc request size 18446744073709551594
- DEBUG: server process (PID 76) was terminated by signal 11: Segmentation fault
SELECT lp, lp_off, lp_flags, lp_len, t_xmin, t_xmax, t_field3, t_ctid, t_infomask2, t_infomask, t_hoff, t_bits, t_oid, substr(t_data::text,1,50) as t_data
FROM heap_page_items(get_raw_page('public.test_table', 7));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+----------------------------------------------------
1 | 7936 | 1 | 252 | 29475 | 0 | 0 | (7,1) | 5 | 2310 | 24 | | | \x01010000010100000101000018030000486f742073656520
2 | 7696 | 1 | 236 | 29476 | 0 | 0 | (7,2) | 5 | 2310 | 24 | | | \x020100000201000002010000d802000043756c747572616c
3 | 7504 | 1 | 189 | 29477 | 0 | 0 | (7,3) | 5 | 2310 | 24 | | | \x0301000003010000030100001c020000446f6f7220726563
4 | 7368 | 1 | 132 | 29478 | 0 | 0 | (7,4) | 5 | 2310 | 24 | | | \x0401000004010000040100009d4d6f76656d656e74207374
Hier können wir das Item-IDs-Array gut sehen – Offsets und Längen. Das erste Tupel wird ganz am Ende des Datenblocks gespeichert, daher hat es den größten Offset. Jedes nachfolgende Tupel wird näher und näher am Anfang der Seite gespeichert, sodass die Offsets kleiner werden. Wir können auch die Längen der Tupel sehen, sie sind alle unterschiedlich, da sie einen Textwert variabler Länge enthalten. Wir können auch Tupel und ihre Systemspalten sehen, aber wir werden sie uns später ansehen.
Wenn wir nun das Item-IDs-Array beschädigen und diagnostizieren, wie es aussieht, wird die Ausgabe verkürzt, da auch alle anderen Spalten leer sind. Aufgrund des beschädigten Item-IDs-Arrays können wir Tupel nicht richtig lesen. Hier können wir das Problem sofort erkennen: Offsets und Längen enthalten Zufallswerte, von denen die meisten 8192 überschreiten, d. h. weit über die Grenzen der Datenseite hinausgehen:
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax ----+--------+----------+--------+--------+-------- 1 | 19543 | 1 | 16226 | | 2 | 5585 | 2 | 3798 | | 3 | 25664 | 3 | 15332 | | 4 | 10285 | 2 | 17420 | |
SELECT * FROM verify_heapam('test_table', FALSE, FALSE, 'none', 7, 7); blkno | offnum | attnum | msg -------+--------+--------+--------------------------------------------------------------------------- 7 | 1 | | line pointer to page offset 19543 is not maximally aligned 7 | 2 | | line pointer redirection to item at offset 5585 exceeds maximum offset 4 7 | 4 | | line pointer redirection to item at offset 10285 exceeds maximum offset 4
Beschädigte Tupel: Systemspalten können Scans unterbrechen
- 58P01 – could not access status of transaction 3047172894
- XX000 – MultiXactId 1074710815 has not been created yet — apparent wraparound
- WARNING: Concurrent insert in progress within table „test_table“
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid ----+--------+----------+--------+------------+------------+------------+--------------------+-------------+------------+--------+--------+------- 1 | 6160 | 1 | 2032 | 1491852297 | 287039843 | 491133876 | (3637106980,61186) | 50867 | 46441 | 124 | | 2 | 4128 | 1 | 2032 | 3846288155 | 3344221045 | 2002219688 | (2496224126,65391) | 34913 | 32266 | 82 | | 3 | 2096 | 1 | 2032 | 1209990178 | 1861759146 | 2010821376 | (426538995,32644) | 23049 | 2764 | 215 | |
- XX000 – unexpected chunk number -556107646 (expected 20) for toast value 29611 in pg_toast_29580
- XX000 – found toasted toast chunk for toast value 29707 in pg_toast_29580
Umgang mit beschädigten Tupeln mit pg_surgery
Selbst ein einzelnes beschädigtes Tupel kann Selects aus der gesamten Tabelle verhindern. Beschädigung in xmin, xmax und hint bits führt dazu, dass eine Abfrage fehlschlägt, da der MVCC-Mechanismus die Sichtbarkeit dieser beschädigten Tupel nicht bestimmen kann. Ohne Datenblock-Prüfsummen können wir solche beschädigten Seiten nicht einfach nullen, da ihr Header bereits den „Sinnhaftigkeits“-Test bestanden hat. Wir müssten die Zeilen einzeln mit einem PL/pgSQL-Skript retten. Aber wenn eine Tabelle riesig ist und die Anzahl der beschädigten Tupel gering ist, ist dies höchst unpraktisch.
In einem solchen Fall sollten wir über die Verwendung der pg_surgery-Erweiterung nachdenken, um beschädigte Tupel einzufrieren oder zu entfernen. Aber erstens ist die korrekte Identifizierung beschädigter Tupel entscheidend, und zweitens existiert die Erweiterung seit PostgreSQL 14, sie ist in älteren Versionen nicht verfügbar. Ihre Funktionen erfordern ctid, aber wir müssen einen geeigneten Wert basierend auf der Seitennummer und der Ordnungszahl des Tupels auf der Seite erstellen, wir können kein beschädigtes ctid aus dem Tupel-Header verwenden, wie oben gezeigt.
Einfrieren vs. Löschen
Eingefrorene Tupel sind für alle Transaktionen sichtbar und verhindern das Blockieren von Lesevorgängen. Sie enthalten aber immer noch beschädigte Daten: Abfragen geben Müll zurück. Daher wird uns das bloße Einfrieren beschädigter Tupel höchstwahrscheinlich nicht helfen, und wir müssen beschädigte Tupel löschen. Das vorherige Einfrieren kann jedoch hilfreich sein, um sicherzustellen, dass wir die richtigen Tupel anvisieren. Einfrieren bedeutet einfach, dass die Funktion heap_force_freeze (mit dem richtigen ctid) t_xmin durch den Wert 2 (eingefrorenes Tupel) ersetzt, t_xmax durch 0 und t_ctid repariert.
Aber alle anderen Werte bleiben so, wie sie sind, d. h. immer noch beschädigt. Die Verwendung der pageinspect-Erweiterung, wie oben gezeigt, bestätigt, dass wir mit einem richtigen Tupel arbeiten. Nach dieser Überprüfung können wir beschädigte Tupel mit der Funktion heap_force_kill mit den gleichen Parametern löschen. Diese Funktion überschreibt den Pointer im Item-ID-Array für dieses spezifische Tupel und markiert es als tot.
Warnung: Funktionen in pg_surgery gelten per Definition als unsicher, verwenden Sie sie daher mit Vorsicht. Sie können sie wie jede andere Funktion aus SQL aufrufen, aber es handelt sich nicht um MVCC-transaktionale Operationen. Ihre Aktionen sind irreversibel: ROLLBACK kann ein Einfrieren oder Löschen nicht „rückgängig machen“, da diese Funktionen eine Heap-Seite in gemeinsam genutzten Puffern direkt modifizieren und die Änderung im WAL-Protokoll protokollieren. Daher sollten wir sie zuerst auf einer Kopie dieser spezifischen Tabelle (wenn möglich) oder auf einer Testtabelle testen. Das Löschen des Tupels kann auch zu Inkonsistenzen in Indizes führen, da das Tupel nicht mehr existiert, aber in einem Index referenziert werden könnte. Sie schreiben Änderungen in das WAL-Protokoll; daher wird die Änderung an Standbys repliziert.
Zusammenfassung
| Kategorien: | PostgreSQL® |
|---|---|
| Tags: | planetpostgres planetpostgresql postgresql 18 |
