Einführung
Das Ausführen von ANALYZE (entweder explizit oder über Auto-Analyze) ist sehr wichtig, um aktuelle Datenstatistiken für den Postgres-Query-Planer zu haben. Insbesondere nach In-Place-Upgrades über ANALYZE nur Teile der Blöcke in einer Tabelle abtastet, ähnelt das I/O-Muster eher einem Direktzugriff als einem sequenziellen Lesen. Version 14 von Postgres hat die Möglichkeit maintenenance_io_concurrency gesteuert, der standardmäßig auf 10 gesetzt ist (im Gegensatz zu effective_io_concurrency, der standardmäßig auf 1 gesetzt ist).
Benchmark
Um die Änderungen zwischen Version 13 und 14 zu testen und zu demonstrieren, haben wir einige kurze Benchmarks mit den aktuellen Wartungsversionen (13.16 und 14.13) auf Debian 12 mit Paketen von https://apt.postgresql.org durchgeführt. Hardwareseitig wurde ein ThinkPad T14s Gen 3 mit einer Intel i7-1280P CPU mit 20 Kernen und 32 GB RAM verwendet. Die Basis ist eine pgbench-Datenbank, die mit einem Skalierungsfaktor von 1000 initialisiert wurde:
$ pgbench -i -I dtg -s 1000 -d pgbenchDadurch werden 100 Millionen Zeilen erstellt, was zu einer Datenbankgröße von etwa 15 GB führt. Um pgbench_accounts:
$ vacuumdb -Z -v -d pgbench -t pgbench_accounts
INFO: analyzing "public.pgbench_accounts"
INFO: "pgbench_accounts": scanned 300000 of 1639345 pages,
containing 18300000 live rows and 0 dead rows;
300000 rows in sample, 100000045 estimated total rowsZwischen den Durchläufen wird der Dateisystem-Seitencache über echo 3 | sudo tee /proc/sys/vm/drop_caches gelöscht und alle Durchläufe werden dreimal wiederholt. Die folgende Tabelle listet die Laufzeiten (in Sekunden) des obigen vacuumdb-Befehls für verschiedene Einstellungen von maintenance_io_concurrency auf:
| Version | 0 | 1 | 5 | 10 | 20 | 50 | 100 | 500 |
|---|---|---|---|---|---|---|---|---|
| 13 | 19.557 | 21.610 | 19.623 | 21.060 | 21.463 | 20.533 | 20.230 | 20.537 |
| 14 | 24.707 | 29.840 | 8.740 | 5.777 | 4.067 | 3.353 | 3.007 | 2.763 |
Analyse
Zwei Dinge gehen aus diesen Zahlen deutlich hervor: Erstens ändern sich die Laufzeiten für Version 13 nicht, der Wert von maintenance_io_concurrency hat für diese Version keine Auswirkung. Zweitens, sobald das Prefetching für Version 14 einsetzt (maintenance_io_concurrency=0) oder nur auf 1 gesetzt ist, schlechter sind als bei Version 13, aber da der Standardwert für maintenance_io_concurrency 10 ist, sollte dies in der Praxis niemanden betreffen.
Fazit
Das Aktivieren von Prefetching für ANALYZE in Version 14 von PostgreSQL hat die Statistikabtastung erheblich beschleunigt. Der Standardwert von 10 für ANALYZE.
Übersicht
Tabellen, die bei Bedarf erstellt und gelöscht werden, ob temporär oder regulär, werden von Anwendungsentwicklern in PostgreSQL häufig verwendet, um die Implementierung verschiedener Funktionalitäten zu vereinfachen und Antworten zu beschleunigen. Zahlreiche Artikel im Internet beschreiben die Vorteile der Verwendung solcher Tabellen zum Speichern von Suchergebnissen, zum Vorberechnen von Zahlen für Berichte, zum Importieren von Daten aus externen Dateien und mehr. Man kann sogar eine TEMP TABLE mit der Bedingung ON COMMIT DROP definieren, wodurch das System automatisch bereinigen kann. Wie die meisten Dinge hat diese Lösung jedoch potenzielle Nachteile, da die Größe eine Rolle spielt. Eine Lösung, die für Dutzende paralleler Sitzungen reibungslos funktioniert, kann plötzlich unerwartete Probleme verursachen, wenn die Anwendung während der Stoßzeiten von Hunderten oder Tausenden von Benutzern gleichzeitig verwendet wird. Das häufige Erstellen und Löschen von Tabellen und verwandten Objekten kann zu einer erheblichen Aufblähung bestimmter PostgreSQL-Systemtabellen führen. Dies ist ein bekanntes Problem, das in vielen Artikeln erwähnt wird, denen es jedoch oft an detaillierten Erklärungen und einer Quantifizierung der Auswirkungen mangelt. Mehrere pg_catalog-Systemtabellen können erheblich aufgebläht werden. Die Tabelle pg_attribute ist am stärksten betroffen, gefolgt von pg_attrdef und pg_class.
Was ist das Hauptproblem bei der Aufblähung von Systemtabellen?
Wir sind bereits in den PostgreSQL-Protokollen eines unserer Kunden auf dieses Problem gestoßen. Als die Aufblähung der Systemtabellen zu groß wurde, beschloss PostgreSQL, während eines Autovacuum-Vorgangs freien Speicherplatz zurückzugewinnen. Diese Aktion verursachte exklusive Sperren auf der Tabelle und blockierte alle anderen Operationen für mehrere Sekunden. PostgreSQL konnte keine Informationen über die Strukturen aller Beziehungen lesen. Infolgedessen mussten selbst die einfachsten Select-Operationen verzögert werden, bis die Operation abgeschlossen war. Dies ist natürlich ein extremes und seltenes Szenario, das nur unter außergewöhnlich hoher Last auftreten kann. Dennoch ist es wichtig, sich dessen bewusst zu sein und beurteilen zu können, ob dies auch in unserer Datenbank passieren könnte.
Beispiel für eine Berichtstabelle in einer Buchhaltungssoftware
CREATE TEMP TABLE pivot_temp_table ( id serial PRIMARY KEY, inserted_at timestamp DEFAULT current_timestamp, client_id INTEGER, name text NOT NULL, address text NOT NULL, loyalty_program BOOLEAN DEFAULT false, loyalty_program_start TIMESTAMP, orders_202301_count_of_orders INTEGER DEFAULT 0, orders_202301_total_price NUMERIC DEFAULT 0, ... orders_202312_count_of_orders INTEGER DEFAULT 0, orders_202312_total_price NUMERIC DEFAULT 0);
CREATE INDEX pivot_temp_table_idx1 ON pivot_temp_table (client_id); CREATE INDEX pivot_temp_table_idx2 ON pivot_temp_table (name); CREATE INDEX pivot_temp_table_idx3 ON pivot_temp_table (loyalty_program); CREATE INDEX pivot_temp_table_idx4 ON pivot_temp_table (loyalty_program_start);
- Eine temporäre Tabelle, pivot_temp_table, mit 31 Spalten, von denen 27 Standardwerte haben.
- Einige der Spalten haben den Datentyp TEXT, was zur automatischen Erstellung einer TOAST-Tabelle führt.
- Die TOAST-Tabelle benötigt einen Index für chunk_id und chunk_seq.
- Die ID ist der Primärschlüssel, was bedeutet, dass automatisch ein eindeutiger Index für die ID erstellt wurde.
- Die ID ist als SERIAL definiert, was zur automatischen Erstellung einer Sequenz führt, die im Wesentlichen eine weitere Tabelle mit einer speziellen Struktur ist.
- Wir haben auch vier zusätzliche Indizes für unsere temporäre Tabelle definiert.
Lassen Sie uns nun untersuchen, wie diese Beziehungen in PostgreSQL-Systemtabellen dargestellt werden.
Tabelle pg_attribute
- Jede Zeile in unserer pivot_temp_table enthält sechs versteckte Spalten (tableoid, cmax, xmax, cmin, xmin, ctid) und 31 ’normale‘ Spalten. Dies ergibt insgesamt 37 eingefügte Zeilen für die temporäre Haupttabelle.
- Indizes fügen für jede im Index verwendete Spalte eine Zeile hinzu, was in unserem Fall fünf Zeilen entspricht.
- Es wurde automatisch eine TOAST-Tabelle erstellt. Sie hat sechs versteckte Spalten und drei normale Spalten (chunk_id, chunk_seq, chunk_data) sowie einen Index für chunk_id und chunk_seq, was insgesamt 11 Zeilen ergibt.
- Es wurde eine Sequenz für die ID erstellt, die im Wesentlichen eine weitere Tabelle mit einer vordefinierten Struktur ist. Sie hat sechs versteckte Spalten und drei normale Spalten (last_value, log_cnt, is_called), was weitere neun Zeilen hinzufügt.
Tabelle pg_attrdef
SELECT c.relname as table_name, o.rolname as table_owner, c.relkind as table_type, a.attname as column_name, a.attnum as column_number, a.atttypid::regtype as column_data_type, pg_get_expr(adbin, adrelid) as sql_command FROM pg_attrdef ad JOIN pg_attribute a ON ad.adrelid = a.attrelid AND ad.adnum = a.attnum JOIN pg_class c ON c.oid = ad.adrelid JOIN pg_authid o ON o.oid = c.relowner WHERE c.relname = 'pivot_temp_table' ORDER BY table_name, column_number;
table_name | table_owner | table_type | column_name | column_number | column_data_type | sql_command
------------------+-------------+------------+-------------------------------+---------------+-----------------------------+----------------------------------------------
pivot_temp_table | postgres | r | id | 1 | integer | nextval('pivot_temp_table_id_seq'::regclass)
pivot_temp_table | postgres | r | inserted_at | 2 | timestamp without time zone | CURRENT_TIMESTAMP
pivot_temp_table | postgres | r | loyalty_program | 6 | boolean | false
pivot_temp_table | postgres | r | orders_202301_count_of_orders | 8 | integer | 0
pivot_temp_table | postgres | r | orders_202301_total_price | 9 | numeric | 0
--> bis zur Spalte "orders_202312_total_price"Tabelle pg_class
Die Tabelle pg_class speichert primäre Informationen über Beziehungen. Dieses Beispiel erstellt neun Zeilen: eine für die temporäre Tabelle, eine für die Toast-Tabelle, eine für den Toast-Tabellenindex, eine für den eindeutigen Index des ID-Primärschlüssels, eine für die Sequenz und vier für die benutzerdefinierten Indizes.
Zusammenfassung dieses Beispiels
Unser erstes Beispiel erzeugte eine scheinbar kleine Anzahl von Zeilen – 62 in pg_attribute, 27 in pg_attrdef und 9 in pg_class. Dies sind sehr niedrige Zahlen, und wenn eine solche Lösung nur von einem Unternehmen verwendet würde, würden wir kaum Probleme sehen. Stellen Sie sich jedoch ein Szenario vor, in dem ein Unternehmen Buchhaltungssoftware für kleine Unternehmen hostet und Hunderte oder sogar Tausende von Benutzern die App während der Stoßzeiten nutzen. In einer solchen Situation würden viele temporäre Tabellen und verwandte Objekte relativ schnell erstellt und gelöscht. In der Tabelle pg_attribute könnten wir innerhalb weniger Stunden zwischen einigen Tausend und sogar Hunderttausenden von Datensätzen sehen, die eingefügt und dann gelöscht werden. Dies ist jedoch immer noch ein relativ kleiner Anwendungsfall. Lassen Sie uns nun etwas noch Größeres vorstellen und benchmarken.
Beispiel für einen Online-Shop
- Die Tabelle „session_events“ speichert ausgewählte Aktionen, die der Benutzer während der Sitzung durchgeführt hat. Ereignisse werden für jede Aktion erfasst, die der Benutzer auf der Website ausführt, sodass mindestens Hunderte, aber häufig Tausende von Ereignissen aus einer Sitzung aufgezeichnet werden. Diese werden alle parallel in die Hauptereignistabelle gesendet. Die Haupttabelle ist jedoch enorm. Daher speichert diese benutzerspezifische Tabelle nur einige Ereignisse, was eine schnelle Analyse der letzten Aktivitäten usw. ermöglicht. Die Tabelle hat 25 verschiedene Spalten, von denen einige vom Typ TEXT und eine Spalte vom Typ JSONB sind – was bedeutet, dass eine TOAST-Tabelle mit einem Index erstellt wurde. Die Tabelle hat einen Primärschlüssel vom Typ Serial, der die Reihenfolge der Aktionen angibt – d. h. ein eindeutiger Index, eine Sequenz und ein Standardwert wurden erstellt. Es gibt keine zusätzlichen Standardwerte. Die Tabelle hat auch drei zusätzliche Indizes für einen schnelleren Zugriff, jeder für eine Spalte. Ihr Nutzen könnte fraglich sein, aber sie sind Teil der Implementierung.
- Zusammenfassung der Zeilen in Systemtabellen – pg_attribute – 55 Zeilen, pg_class – 8 Zeilen, pg_attrdef – 1 Zeile
- Die Tabelle „last_visited“ speichert eine kleine Teilmenge von Ereignissen aus der Tabelle „session_events“, um schnell anzuzeigen, welche Artikel der Benutzer während dieser Sitzung besucht hat. Entwickler haben sich aus Gründen der Bequemlichkeit für diese Implementierung entschieden. Die Tabelle ist klein und enthält nur 10 Spalten, aber mindestens eine ist vom Typ TEXT. Daher wurde eine TOAST-Tabelle mit einem Index erstellt. Die Tabelle hat einen Primärschlüssel vom Typ TIMESTAMP, daher hat sie einen eindeutigen Index, einen Standardwert, aber keine Sequenz. Es gibt keine zusätzlichen Indizes.
- Zeilen in Systemtabellen – pg_attribute – 28 Zeilen, pg_class – 4 Zeilen, pg_attrdef – 1 Zeile
- Die Tabelle „last_purchases“ wird beim Anmelden aus der Haupttabelle gefüllt, die alle Käufe speichert. Diese benutzerspezifische Tabelle enthält die letzten 50 Artikel, die der Benutzer in früheren Sitzungen gekauft hat, und wird vom Empfehlungsalgorithmus verwendet. Diese Tabelle enthält vollständig denormalisierte Daten, um ihre Verarbeitung und Visualisierung zu vereinfachen, und hat daher 35 Spalten. Viele dieser Spalten sind vom Typ TEXT, sodass eine TOAST-Tabelle mit einem Index erstellt wurde. Der Primärschlüssel dieser Tabelle ist eine Kombination aus dem Kaufzeitstempel und der Ordnungszahl des Artikels in der Bestellung, was zur Erstellung eines eindeutigen Index, aber keiner Standardwerte oder Sequenzen führt. Im Laufe der Zeit hat der Entwickler vier Indizes für diese Tabelle für verschiedene Sortierzwecke erstellt, jeder für eine Spalte. Der Wert dieser Indizes kann in Frage gestellt werden, aber sie existieren immer noch.
- Zeilen in Systemtabellen – pg_attribute – 57 Zeilen, pg_class – 8 Zeilen
- Die Tabelle „selected_but_not_purchased“ wird beim Anmelden aus der entsprechenden Haupttabelle gefüllt. Sie zeigt die letzten 50 Artikel an, die noch im Shop verfügbar sind, die der Benutzer zuvor in Betracht gezogen hat, aber später aus dem Warenkorb entfernt oder die Bestellung überhaupt nicht abgeschlossen hat, und der Inhalt des Warenkorbs ist abgelaufen. Diese Tabelle wird vom Empfehlungsalgorithmus verwendet und hat sich als erfolgreiche Ergänzung der Marketingstrategie erwiesen, die die Käufe um einen bestimmten Prozentsatz erhöht. Die Tabelle hat die gleiche Struktur und verwandte Objekte wie „last_purchases“. Die Daten werden getrennt von den Käufen gespeichert, um Fehler bei der Dateninterpretation zu vermeiden, und auch, weil dieser Teil des Algorithmus viel später implementiert wurde.
- Zeilen in Systemtabellen – pg_attribute – 57 Zeilen, pg_class – 8 Zeilen
- Die Tabelle „cart_items“ speichert Artikel, die für den Kauf in der aktuellen Sitzung ausgewählt, aber noch nicht gekauft wurden. Diese Tabelle wird mit der Haupttabelle synchronisiert, aber auch eine lokale Kopie in der Sitzung wird verwaltet. Die Tabelle enthält normalisierte Daten und hat daher nur 15 Spalten, von denen einige vom Typ TEXT sind, was zur Erstellung einer TOAST-Tabelle mit einem Index führt. Sie hat eine Primärschlüssel-ID vom Typ UUID, um Kollisionen über alle Benutzer hinweg zu vermeiden, was zur Erstellung eines eindeutigen Index und eines Standardwerts, aber keiner Sequenz führt. Es gibt keine zusätzlichen Indizes.
- Zeilen in Systemtabellen – pg_attribute – 33 Zeilen, pg_class – 4 Zeilen, pg_attrdef – 1 Zeile
Die Erstellung all dieser benutzerspezifischen Tabellen führt zum Einfügen der folgenden Anzahl von Zeilen in die PostgreSQL-Systemtabellen – pg_attribute: 173 Zeilen, pg_class: 32 Zeilen, pg_attrdef: 3 Zeilen.
Analyse des Datenverkehrs
Als ersten Schritt stellen wir eine Analyse des Business Use Case und der Saisonalität des Datenverkehrs bereit. Stellen wir uns vor, unser Einzelhändler ist in mehreren EU-Ländern tätig und richtet sich hauptsächlich an Personen im Alter von 15 bis 35 Jahren. Der Online-Shop ist relativ neu und hat derzeit 100.000 Konten. Basierend auf Whitepapers, die im Internet verfügbar sind, können wir folgende Benutzeraktivität annehmen:
| Aktivitätsniveau des Benutzers | Verhältnis der Benutzer [%] | Gesamtzahl der Benutzer | Besuchshäufigkeit auf der Seite |
|---|---|---|---|
| sehr aktiv | 10% | 10.000 | 2x bis 4x pro Woche |
| normale Aktivität | 30% | 30.000 | ~1 Mal pro Woche |
| geringe Aktivität | 40% | 40.000 | 1x bis 2x pro Monat |
| fast keine Aktivität | 20% | 20.000 | wenige Male im Jahr |
Da es sich um einen Online-Shop handelt, ist der Datenverkehr stark saisonabhängig. Artikel werden hauptsächlich von Einzelpersonen für den persönlichen Gebrauch gekauft. Daher überprüfen sie den Shop während des Arbeitstages zu ganz bestimmten Zeiten, z. B. während der Reise oder der Mittagspause. Der Hauptverkehr während des Arbeitstages liegt zwischen 19:00 und 21:00 Uhr. Freitage haben in der Regel einen viel geringeren Datenverkehr, und das Wochenende folgt diesem Beispiel. Die verkehrsreichsten Tage sind in der Regel am Ende des Monats, wenn die Leute ihr Gehalt erhalten. Der Shop verzeichnet den stärksten Datenverkehr am Thanksgiving Thursday und am Black Friday. Die übliche Praxis in den letzten Jahren ist es, den Shop für ein oder zwei Stunden zu schließen und dann zu einer bestimmten Stunde mit reduzierten Preisen wieder zu eröffnen. Dies führt zu einer großen Anzahl von Beziehungen, die in relativ kurzer Zeit erstellt und später gelöscht werden. Die Dauer der Verbindung eines Benutzers kann von wenigen Minuten bis zu einer halben Stunde reichen. Benutzerspezifische Tabellen werden erstellt, wenn sich der Benutzer im Shop anmeldet. Sie werden später von einem speziellen Prozess gelöscht, der einen ausgeklügelten Algorithmus verwendet, um zu bestimmen, ob Beziehungen bereits abgelaufen sind oder nicht. Dieser Prozess umfasst verschiedene Kriterien und wird in unterschiedlichen Abständen ausgeführt, sodass wir eine große Anzahl von Beziehungen sehen können, die in einem Durchgang gelöscht werden. Lassen Sie uns diese Beschreibungen quantifizieren:
| Datenverkehr an verschiedenen Tagen | Anmeldungen pro 30 min | pg_attribute [Zeilen] | pg_class [Zeilen] | pg_attrdef [Zeilen] |
|---|---|---|---|---|
| Zahlen aus der Analyse pro 1 Benutzer | 1 | 173 | 32 | 3 |
| Durchschnittlicher Datenverkehr am Nachmittag | 1.000 | 173.000 | 32.000 | 3.000 |
| Normaler Arbeitstagabend mit hohem Datenverkehr | 3.000 | 519.000 | 96.000 | 9.000 |
| Abend nach Gehaltszahlung, geringer Datenverkehr | 8.000 | 1.384.000 | 256.000 | 24.000 |
| Abend nach Gehaltszahlung, hoher Datenverkehr | 15.000 | 2.595.000 | 480.000 | 45.000 |
| Singles‘ Day, Abenderöffnung | 40.000 | 6.920.000 | 1.280.000 | 120.000 |
| Thanksgiving Donnerstag, Abenderöffnung | 60.000 | 10.380.000 | 1.920.000 | 180.000 |
| Black Friday, Abenderöffnung | 50.000 | 8.650.000 | 1.600.000 | 150.000 |
| Black Friday Wochenende, höchster Datenverkehr | 20.000 | 3.460.000 | 640.000 | 60.000 |
| Theoretisches Maximum – alle Benutzer verbunden | 100.000 | 17.300.000 | 3.200.000 | 300.000 |
Jetzt können wir sehen, was Skalierbarkeit bedeutet. Unsere Lösung wird an normalen Tagen definitiv angemessen funktionieren. Der Datenverkehr an den Abenden, nachdem die Leute ihr Gehalt erhalten haben, kann jedoch sehr hoch sein. Thanksgiving Donnerstag und Black Friday testen die Grenzen wirklich aus. Zwischen 1 und 2 Millionen benutzerspezifische Tabellen und zugehörige Objekte werden an diesen Abenden erstellt und gelöscht. Und was passiert, wenn unser Shop noch erfolgreicher wird und die Anzahl der Konten auf 500 000, 1 Million oder mehr ansteigt? Die Lösung würde an einigen Stellen definitiv an die Grenzen der vertikalen Skalierung stoßen, und wir müssten über Möglichkeiten nachdenken, sie horizontal zu skalieren.
Wie man Bloat untersucht
WITH tablenames AS (SELECT tablename FROM (VALUES('pg_attribute'),('pg_attrdef'),('pg_class')) as t(tablename))
SELECT
tablename,
now() as checked_at,
pg_relation_size(tablename) as relation_size,
pg_relation_size(tablename) / (8*1024) as relation_pages,
a.*,
s.*
FROM tablenames t
JOIN LATERAL (SELECT * FROM pgstattuple(t.tablename)) s ON true
JOIN LATERAL (SELECT last_autovacuum, last_vacuum, last_autoanalyze, last_analyze, n_live_tup, n_dead_tup
FROM pg_stat_all_tables WHERE relname = t.tablename) a ON true
ORDER BY tablenametablename | pg_attribute checked_at | 2024-02-18 10:46:34.348105+00 relation_size | 44949504 relation_pages | 5487 last_autovacuum | 2024-02-16 20:07:15.7767+00 last_vacuum | 2024-02-16 20:55:50.685706+00 last_autoanalyze | 2024-02-16 20:07:15.798466+00 last_analyze | 2024-02-17 22:05:43.19133+00 n_live_tup | 3401 n_dead_tup | 188221 table_len | 44949504 tuple_count | 3401 tuple_len | 476732 tuple_percent | 1.06 dead_tuple_count | 107576 dead_tuple_len | 15060640 dead_tuple_percent| 33.51 free_space | 28038420 free_percent | 62.38
WITH pages AS (
SELECT * FROM generate_series(0, (SELECT pg_relation_size('pg_attribute') / 8192) -1) as pagenum),
tuples_per_page AS (
SELECT pagenum, nullif(sum((t_xmin is not null)::int), 0) as tuples_per_page
FROM pages JOIN LATERAL (SELECT * FROM heap_page_items(get_raw_page('pg_attribute',pagenum))) a ON true
GROUP BY pagenum)
SELECT
count(*) as pages_total,
min(tuples_per_page) as min_tuples_per_page,
max(tuples_per_page) as max_tuples_per_page,
round(avg(tuples_per_page),0) as avg_tuples_per_page,
mode() within group (order by tuples_per_page) as mode_tuples_per_page
FROM tuples_per_pagepages_total | 5487 min_tuples_per_page | 1 max_tuples_per_page | 55 avg_tuples_per_page | 23 mode_tuples_per_page | 28
Hier können wir sehen, dass wir in unserer pg_attribute-Systemtabelle durchschnittlich 23 Tupel pro Seite haben. Jetzt können wir die theoretische Größenzunahme dieser Tabelle für unterschiedlichen Datenverkehr berechnen. Die typische Größe dieser Tabelle beträgt in der Regel nur wenige hundert MB. Ein theoretischer Bloat von etwa 3 GB während der Black Friday Tage ist also eine ziemlich bedeutende Zahl für diese Tabelle.
| Logins | pg_attribute Zeilen | Datenseiten | Größe in MB |
|---|---|---|---|
| 1 | 173 | 8 | 0.06 |
| 1.000 | 173.000 | 7.522 | 58.77 |
| 3.000 | 519.000 | 22.566 | 176.30 |
| 15.000 | 2.595.000 | 112.827 | 881.46 |
| 20.000 | 3.460.000 | 150.435 | 1.175.27 |
| 60.000 | 10.380.000 | 451.305 | 3.525.82 |
| 100.000 | 17.300.000 | 752.174 | 5.876.36 |
Zusammenfassung
Wir haben ein Reporting-Beispiel aus einer Buchhaltungssoftware und ein Beispiel für benutzerspezifische Tabellen aus einem Online-Shop vorgestellt. Obwohl beide theoretisch sind, soll die Idee Muster veranschaulichen. Wir haben auch den Einfluss der saisonalen Hochsaison auf die Anzahl der Einfügungen und Löschungen in Systemtabellen diskutiert. Wir haben ein Beispiel für eine extrem erhöhte Last in einem Online-Shop an großen Verkaufstagen gegeben. Wir glauben, dass die Ergebnisse der Analyse Aufmerksamkeit verdienen. Es ist auch wichtig zu bedenken, dass die ohnehin schon schwierige Situation in diesen Spitzenzeiten noch schwieriger sein kann, wenn unsere Anwendung auf einer Instanz mit niedrigen Festplatten-IOPS läuft. All diese neuen Objekte würden Schreibvorgänge in WAL-Protokolle und die Synchronisierung mit der Festplatte verursachen. Bei geringem Festplattendurchsatz kann es zu erheblichen Latenzzeiten kommen, und viele Operationen können erheblich verzögert werden. Was ist also die Quintessenz dieser Geschichte? Erstens sind die Autovacuum-Prozesse von PostgreSQL so konzipiert, dass sie die Auswirkungen auf das System minimieren. Wenn die Autovacuum-Einstellungen in unserer Datenbank gut abgestimmt sind, werden wir in den meisten Fällen keine Probleme feststellen. Wenn diese Einstellungen jedoch veraltet sind, auf einen viel geringeren Datenverkehr zugeschnitten sind und unser System über einen längeren Zeitraum ungewöhnlich stark belastet wird, wodurch Tausende von Tabellen und zugehörigen Objekten in relativ kurzer Zeit erstellt und gelöscht werden, können die PostgreSQL-Systemtabellen schließlich erheblich aufgebläht werden. Dies verlangsamt bereits Systemabfragen, die Details über alle anderen Beziehungen lesen. Und irgendwann könnte das System beschließen, diese Systemtabellen zu verkleinern, was zu einer exklusiven Sperre für einige dieser Beziehungen für Sekunden oder sogar Dutzende von Sekunden führt. Dies könnte eine große Anzahl von Selects und anderen Operationen auf allen Tabellen blockieren. Basierend auf der Analyse des Datenverkehrs können wir eine ähnliche Analyse für andere spezifische Systeme durchführen, um zu verstehen, wann sie am anfälligsten für solche Vorfälle sind. Aber eine effektive Überwachung ist absolut unerlässlich.
Ressourcen
Die PostgreSQL 2024Q1 Back-Branch-Releases 16.2, 15.6, 14.11, 13.14 und 12.18 wurden am 8. Februar 2024 veröffentlicht. Neben der Behebung eines Sicherheitsproblems (CVE-2024-0985) und der üblichen Fehler sind sie insofern einzigartig, als sie zwei Leistungsprobleme durch das Backporting von Korrekturen beheben, die bereits zuvor in den Master-Branch eingeführt wurden. In diesem Blogbeitrag beschreiben wir zwei kurze Benchmarks, die zeigen, wie sich die neuen Punkt-Releases verbessert haben. Die Benchmarks wurden auf einem ThinkPad T14s Gen 3 durchgeführt, das über eine Intel i7-1280P CPU mit 20 Kernen und 32 GB RAM verfügt.
Skalierbarkeitsverbesserungen bei hoher Konkurrenz
Die Leistungsverbesserungen in den 2024Q1 Punkt-Releases betreffen Verbesserungen der Locking-Skalierbarkeit bei hohen Client-Zahlen, d.h. wenn das System unter starker Konkurrenz steht. Benchmarks hatten gezeigt, dass die Leistung bei einem pgbench-Lauf mit mehr als 128 Clients dramatisch abnahm. Der ursprüngliche
Der von uns verwendete Benchmark ist an diesen Beitrag des Patch-Autors angepasst und besteht aus einem engen pgbench-Lauf, der einfach SELECT txid_current() für jeweils fünf Sekunden bei steigender Client-Anzahl ausführt und die Transaktionen pro Sekunde misst:
$ cat /tmp/txid.sql
SELECT txid_current();
$ for c in 1 2 4 8 16 32 64 96 128 192 256 384 512 768 1024 1536;
> do echo -n "$c ";pgbench -n -M prepared -f /tmp/txid.sql -c$c -j$c -T5 2>&1|grep '^tps'|awk '{print $3}';
> doneDie folgende Grafik zeigt die durchschnittlichen Transaktionen pro Sekunde (tps) über 3 Läufe mit steigender Client-Anzahl (1-1536 Clients), unter Verwendung der Debian 12 Pakete für Version 15, wobei das 2023Q4-Release (15.5, Paket postgresql-15_15.5-0+deb12u1) mit dem 2024Q1-Release (15.6, Paket postgresql-15_15.6-0+deb12u1) verglichen wird:
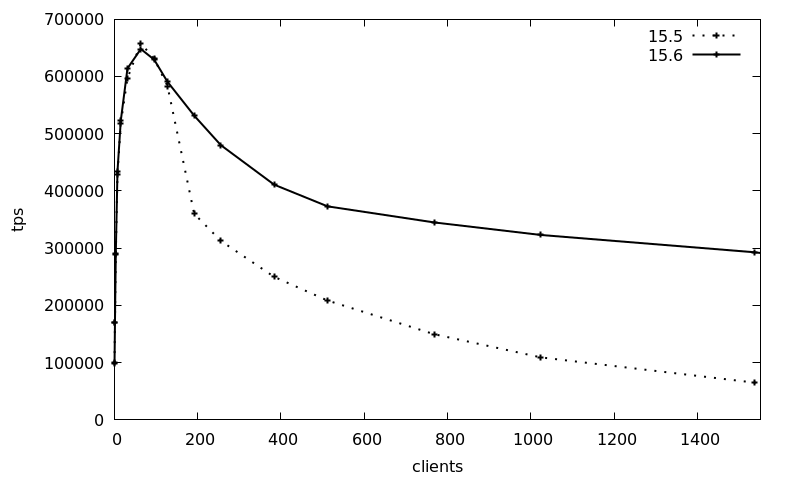
Die tps-Werte sind im Wesentlichen bis zu 128 Clients gleich, während danach die Transaktionszahlen von 15.5 vom Spitzenwert von 650.000 um das 10-fache auf 65.000 sinken. Das neue 15.6-Release hält die Transaktionszahl wesentlich besser und erreicht immer noch etwa 300.000 tps bei 1536 Clients, was eine 4,5-fache Steigerung des 2024Q1-Releases im Vergleich zu zuvor darstellt.
Dieser Benchmark ist natürlich ein Best-Case, ein künstliches Szenario, aber er zeigt, dass das neueste Punkt-Release von Postgres die Skalierbarkeit bei stark umkämpften Locking-Szenarien dramatisch verbessern kann.
JIT-Speicherverbrauchsverbesserungen
JIT (Just-in-Time-Kompilierung mit LLVM) wurde in Version 11 von Postgres eingeführt und in Version 13 zum Standard gemacht. Seit langem ist bekannt, dass lang laufende PostgreSQL-Sitzungen, die wiederholt JIT-Abfragen ausführen, Speicherlecks aufweisen. Es gab mehrere Fehlerberichte dazu, darunter einige weitere im Debian-Bugtracker und wahrscheinlich auch anderswo.
Dies wurde als auf JIT-Inlining zurückzuführen diagnostiziert, und ein Workaround besteht darin, jit_inline_above_cost von dem Standardwert 500.000 auf -1 zu setzen. Dies deaktiviert jedoch das JIT-Inlining vollständig. Die 2024Q1 Back-Branch-Releases enthalten einen Backport einer Änderung, die in Version 17 enthalten sein wird: Nach jeweils 100 Abfragen werden die LLVM-Caches gelöscht und neu erstellt, wodurch das Speicherleck behoben wird.
Um zu zeigen, wie sich der Speicherverbrauch verbessert hat, verwenden wir den Testfall aus diesem Fehlerbericht. Der Benchmark wird wie folgt vorbereitet:
CREATE TABLE IF NOT EXISTS public.leak_test
(
id integer NOT NULL,
CONSTRAINT leak_test_pkey PRIMARY KEY (id)
);
INSERT INTO leak_test(id)
SELECT id
FROM generate_series(1,100000) id
ON CONFLICT DO NOTHING;Anschließend wird die Prozess-ID des Backends notiert und die im Fehlerbericht erwähnte SQL-Abfrage 5000 Mal in einer Schleife ausgeführt:
=> SELECT pg_backend_pid();
pg_backend_pid
----------------
623404
=> DO $$DECLARE loop_cnt integer;
-> BEGIN
-> loop_cnt := 5000;
-> LOOP
-> PERFORM
-> id,
-> (SELECT count(*) FROM leak_test x WHERE x.id=l.id) as x_result,
-> (SELECT count(*) FROM leak_test y WHERE y.id=l.id) as y_result
-> /* Leaks memory around 80 kB on each query, but only if two sub-queries are used. */
-> FROM leak_test l;
-> loop_cnt := loop_cnt - 1;
-> EXIT WHEN loop_cnt = 0;
-> END LOOP;
-> END$$;Dabei wird der Speicherverbrauch des Postgres-Backends über pidstat aufgezeichnet:
pidstat -r -hl -p 623404 2 | tee -a leak_test.log.15.6
Linux 6.1.0-18-amd64 (mbanck-lin-0.credativ.de) 15.02.2024 _x86_64_ (20 CPU)
# Time UID PID minflt/s majflt/s VSZ RSS %MEM Command
12:48:56 118 623404 0,00 0,00 381856 91504 0,28 postgres: 15/main: postgres postgres [local] SELECT
12:48:58 118 623404 0,00 0,00 381856 91504 0,28 postgres: 15/main: postgres postgres [local] SELECT
12:49:00 118 623404 0,00 0,00 381856 91504 0,28 postgres: 15/main: postgres postgres [local] SELECT
12:49:02 118 623404 0,00 0,00 381856 91504 0,28 postgres: 15/main: postgres postgres [local] SELECT
12:49:04 118 623404 7113,00 0,00 393632 109252 0,34 postgres: 15/main: postgres postgres [local] SELECT
12:49:06 118 623404 13219,00 0,00 394556 109508 0,34 postgres: 15/main: postgres postgres [local] SELECT
12:49:08 118 623404 14376,00 0,00 395384 108228 0,33 postgres: 15/main: postgres postgres [local] SELECT
[...]Der Benchmark wird erneut für die Debian 12 Pakete 15.5 und 15.6 wiederholt (die beide gegen LLVM-14 gelinkt sind) und der RSS-Speicherverbrauch, wie von pidstat berichtet, wird gegen die Zeit aufgetragen:
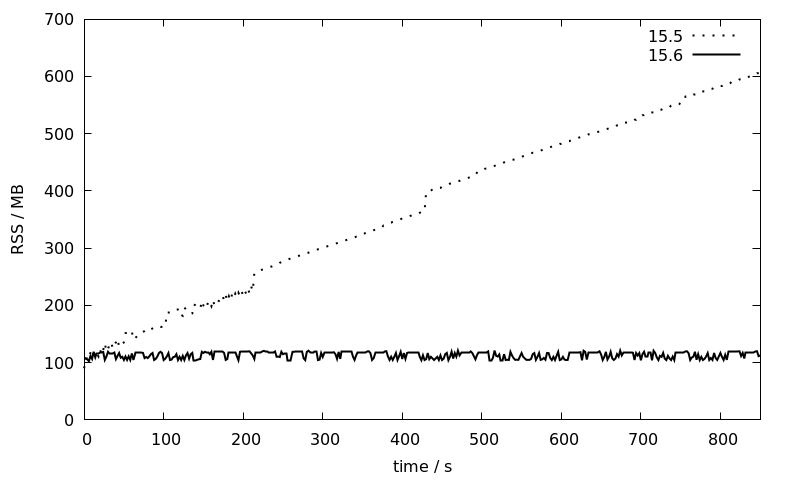
Während der Speicherverbrauch der 15.5-Sitzung linear über die Zeit von 100 auf 600 MB ansteigt, bleibt er bei 15.6 mehr oder weniger konstant bei etwa 100 MB. Dies ist eine große Verbesserung, die JIT für größere Installationen mit lang laufenden Sitzungen, bei denen bisher die übliche Empfehlung darin bestand, JIT vollständig zu deaktivieren, wesentlich nutzbarer machen wird.
Fazit
Das 2024Q1 Patch-Release enthält wichtige Leistungsverbesserungen für die Lock-Skalierbarkeit und den JIT-Speicherverbrauch, die wir in diesem Blogbeitrag demonstriert haben. Darüber hinaus enthält das Patch-Release weitere wichtige Fehlerbehebungen und einen Sicherheitspatch für CVE-2024-0985. Dieses Sicherheitsproblem ist auf materialisierte Views beschränkt, und ein Administrator muss dazu verleitet werden, eine bösartige materialisierte View im Namen eines Angreifers neu zu erstellen. Es hat jedoch einige
