Mit dem Ende des Support-Zyklus für den Long Term Support für Debian Squeeze endet auch das PostgreSQL®-LTS-Projekt für 8.4, das credativ seit dem offiziellen EOL von PostgreSQL® 8.4 im Juli 2014 betreut hatte.
Die letzte Version „8.4.22lts6“ wurde jetzt kurz vor Ende der Squeeze-LTS-Laufzeit hochgeladen. Sie korrigiert eine Sicherheitslücke im Zusammenhang mit regulären Ausdrücken (CVE-2016-0773). Außerdem wurde eine Änderung aus der Version 9.1.20 zurück portiert, die verhindert, dass bei fehlenden PID-Dateien mehrere Instanzen der Datenbank gleichzeitig laufen.
Neben den Paketen in Debian Squeeze-LTS, stehen die 8.4-LTS-Tarballs auch auf Github zum Download bereit.
Die Debian-Version nach Squeeze – Wheezy – enthält die Version 9.1 von PostgreSQL®, für die der Upstream-Support im September 2016 ausläuft. Für Wheezy-LTS wird credativ dann wieder LTS-Pakete für diese PostgreSQL®-Version erstellen.
Maschinen, die jetzt noch mit Debian Squeeze oder PostgreSQL® 8.4 laufen, sollten dringend auf eine neuere Version aktualisiert werden. Die credativ unterstützt ihre Kunden natürlich gerne bei der Planung und Durchführung von Migrationsprojekten.
PostgreSQL® Version 9.5 ist fertig! Die neue Hauptversion glänzt mit einer Vielzahl an neuen, nützlichen Features, massiven Verbesserungen an der Geschwindigkeit vor allem auf Systemen mit vielen CPU-Kernen, aber auch einigen Änderungen, die sich auf die Kompatibilität älterer Anwendungen auswirken. Im Folgenden findet sich eine Zusammenfassung der wichtigsten Merkmale der neuen Version.
Upsert
Die wohl prominenteste Neuerung findet sich in PostgreSQL® 9.5 in der Erweiterung der INSERT-Syntax um die Möglichkeit, bei Konflikt eine alternative Aktion bezüglich des betroffenen Tupels auszuführen. Dieses Verfahren, umgangssprachlich auch unter der Bezeichnung Upsert bekannt, ist ein von der PostgreSQL®-Community schon sehr lange gewünschtes Feature. Anwendungen mussten bisher entweder die Fehler bei Konflikten selbst behandeln, z.B. bei einem INSERT-Konflikt die Transaktion mit einem UPDATE wiederholen (mit entsprechenden Maßnahmen gegenüber nebenläufigen Transaktionen), oder umständliche Prozeduren verwenden, die die entsprechende Funktionalität kapselten.
An dieser Stelle gab es bereits einen Blogartikel, der sich mit den Möglichkeiten dieser neuen Funktionalität detailliert beschäftigt hat und beispielhaft die Syntax illustriert.
Block Range Indexe
Block Range Index (verkürzt BRIN genannt), waren ebenfalls bereits Thema eines vorangegangenen Artikels.
Zum Verständnis sei hier noch einmal darauf verwiesen, dass PostgreSQL® Daten innerhalb von Tabellen in festen physikalischen Blöcken innerhalb von Dateisegmenten organisiert. Ein solcher Block hat eine feste Größe von jeweils 8KB. Zusammenfassend kann ein Block Range Index so beschrieben werden, dass er keine absoluten Werte und deren Position in der Tabelle indiziert, sondern das Auftreten eines bestimmten Wertebereiches eines Blocks einer Tabelle erfasst. Mit anderen Worten, ein Eintrag in einem Block Range Index speichert Minimal- und Maximalwerte für jeden Tabellenblock. Daher ist ein BRIN-Index sehr kompakt und kann im speziellen Fall von geclusterten Daten einer Tabelle massive Vorteile bringen. Für Details sei an dieser Stelle nochmals auf den Blogartikel zum Thema verwiesen.
Row Level Security (RLS)
Für bestimmte Einsatzzwecke ergibt sich manchmal der Bedarf, Zeilen einer Tabelle beispielsweise vor spezifischen Datenbankrollen zu verstecken. Früher war es für diese Szenarien gebräuchlich, entsprechende Views anzulegen, die die Zeilen für diese Datenbankrollen entsprechend ausblendeten, was allerdings erst mit sogenannten SECURITY BARRIER-Views ab PostgreSQL® 9.2 wirklich sicher ist. Ferner ist dieses Verfahren ein wenig umständlich, da entsprechende Views gepflegt werden müssen, die durch die SECURITY BARRIER Direktive unter Umständen auch langsamer werden. Der Blogartikel RLS bietet einen detaillierten Überblick über dieses neue Feature, das weit über die bisherigen Möglichkeiten hinausgeht. RLS ist hierbei transparent und vermeidet das Erstellen umständlicher Zugriffspfade wie Views oder Funktionen.
Konfigurationsparameter checkpoint_segments
Der für die Gesamtperformance immanent wichtige Konfigurationsparameter checkpoint_segments wird durch eine bessere und deutlich angenehmere Infrastruktur ersetzt. Mit checkpoint_segments war es immer schwierig, eine bestimmte Größe des Transaktionslogs in PostgreSQL® zu konfigurieren. Zwar gab es die einschlägige Formel ((2 + checkpoint_completion_target) * checkpoint_segments) + 1 für die Anzahl vorzuhaltender Transaktionslogsegmente. Für die Anwender war es jedoch immer ungewöhnlich hier im Kontext von Segmentanzahl zu konfigurieren, anstatt einfach minimale und maximale Größen (beispielsweise in Megabyte) vorzugeben. Die neuen Konfigurationsparameter min_wal_size und max_wal_size ersetzen nun den Konfigurationsparameter und erlauben das Festsetzen minimaler und maximaler Größen des Transaktionslogs. max_wal_size ist jedoch (genau wie vormals checkpoint_segments) keine feste Grenze, sondern ein Softlimit, das bei Lastspitzen durchaus diese Grenzen überschreiten kann. Die Standardeinstellungen für min_wal_size und max_wal_size sind 80MB bzw. 1GB. Dabei werden die Transaktionslogsegmente nur bei Bedarf allokiert, bis max_wal_size erreicht ist. Bleibt die generierte Transaktionsloggröße unter der konfigurierten min_wal_size werden auch keine weiteren Transaktionslogsegmente verwendet.
Für den Umstieg der gewohnten Einstellungen von checkpoint_segments kann folgende Formel verwendet werden:
max_wal_size = (3 * checkpoint_segments) * 16MB
Zu beachten ist allerdings, dass die Standardeinstellung in PostgreSQL® 9.5 schon deutlich höher gewählt sind als bisher.
Index-Only Scans für GiST-Indexe
PostgreSQL® muss in der Regel jeden Indextreffer evaluieren, ob dieser für die aktuelle Transaktion noch relevant ist. Unter bestimmten Voraussetzungen kann man sich jedoch das zusätzliche (und unter Umständen teure) Lesen der Tabellenzeile sparen. Bisher war dies BTree-Indexe vorbehalten, mit PostgreSQL® 9.5 ist diese Zugriffsmethode nun auch für GiST-basierte Indextypen möglich. Ein Beispiel hierfür ist das contrib-Modul btree_gist, dass einige Anwendungsmöglichkeiten demonstriert.
Verbesserte Skalierbarkeit
Wie bei fast jedem Release bietet auch die neue Version einige Verbesserungen hinsichtlich der vertikalen Skalierbarkeit. So wurde unter anderem der Zugriff auf die LWLock Infrastruktur verbessert, indem das Anfordern derartiger Sperren nun über atomare Zugriffspfade realisiert wird, anstatt hierfür ebenfalls wiederum eine exklusive Sperre anzufordern. Da LWLocks in erster Linie für den Zugriff auf Datenstrukturen im Shared Memory verwendet werden, erhöht dies die Skalierbarkeit insbesondere auf Maschinen mit sehr vielen CPU-Kernen. Auch Seitenersetzungen im PostgreSQL®-eigenen Shared Buffer sind nun aufgrund der Verwendung von Spinlocks und verbessertem Lockingalgorithmus deutlich granularer. Desweiteren wurde für bestimmte Datentypen (text und numeric) die Geschwindigkeit für Sortieroperationen verbessert. Anstatt gleich die volle Länge des Sortierschlüssels zu benutzen, wird zunächst eine abgekürzte, feste Schlüssellänge verwendet, um Unterschiede schneller festzustellen. Daneben gibt es noch viele weitere, kleinere Verbesserungen.
Inkompatiblitäten
Mit Erscheinen der Version 9.5 werden in PostgreSQL® auch Inkompatibilitäten eingeführt, die alte Funktionalität ersetzt oder wegrationalisiert. Die wichtigsten Änderungen im Überblick:
Änderung von Operator-Präzedenzen
Die Präzedenz von Operatoren definiert, welche Priorität diesen beim Evaluieren innerhalb von Ausdrücken eingeräumt bekommen. Ein gutes Beispiel ist immer der Vergleich von Subtraktion/Addition und Multiplikation. Der Multiplikation muss eine höhere Präzedenz eingeräumt werden, da mathematisch immer Punkt-vor-Strich eingehalten werden muss. So ist es auch in PostgreSQL®, der *-Operator ist in der Präzedenz eine Stufe höher definiert als die +– bzw. --Operatoren.
Die Operatoren <=, >= und <> besitzen nun dieselbe Präzedenz wie die Operatoren <, > und =. Dies ist eine Änderung gegenüber den Vorgängerversionen von PostgreSQL® 9.5, in denen letztere in der Präzedenz eine Stufe höher eingeordnet waren.
Außerdem wurde die Präzedenz der IS-Operatoren herabgesetzt, diese befindet sich jetzt unterhalb der genannten Operatoren. Die Konsequenz sollte relativ überschaubar sein, allerdings gibt es dennoch SQL-Ausdrücke, die in ihrer Konstruktion aufgrund der geänderten Präzedenzen nun unterschiedliche Ergebnisse zur Folge haben. Ein Beispiel wäre folgender, zugegebenermaßen sehr konstruierter Fall. In PostgreSQL® 9.4:
SELECT f1 <= f2 || f3 FROM (VALUES('abc', 'ab', 'c')) AS t(f1, f2, f3);
?column?
----------
falsec
(1 row)Das falsec ist ein Ergebnis der Konvertierung des boolschen Werts in text und der anschließenden Text-Konkatenation. Durch die angesprochenen Änderungen ergibt sich jedoch in PostgreSQL® 9.5 folgendes Bild:
#= SELECT f1 <= f2 || f3 FROM (VALUES('abc', 'ab', 'c')) AS t(f1, f2, f3);
?column?
----------
t
(1 row)Hier erkennt man auch die Gründe für die Änderungen, das Ergebnis des letzten Ausdrucks ist korrekt. Solche Konstrukte waren in der Vergangenheit schon immer problematisch, so dass die Mehrzahl der Anwendungen explizite Klammern benutzt haben, um korrekte Ergebnisse zu erzielen. Wer sich bei der Evaluierung von PostgreSQL® 9.5 in seiner Umgebung nicht sicher ist, nicht doch irgendwelche Probleme zu bekommen, kann in PostgreSQL® 9.5 den Konfigurationsparameter operator_precedence_warning benutzen, der Hinweise auf entsprechende Fälle gibt:
SET operator_precedence_warning TO on;
SELECT f1 <= f2 || f3 FROM (VALUES('abc', 'ab', 'c')) AS t(f1, f2, f3);
WARNING: operator precedence change: <= is now lower precedence than ||
LINE 1: SELECT f1 <= f2 || f3 FROM (VALUES('abc', 'ab', 'c')) AS t(f...
^
?column?
----------
t
(1 row)Änderung in pg_ctl
Bis einschließlich PostgreSQL® 9.4 verwendete pg_ctl den Shutdownmodus smartstandardmässig, falls nicht explizit abweichend per -m-Kommandozeilenschalter definiert. Mit PostgreSQL® 9.5 ändert sich der Standardmodus nun zu fast, was ein sofortiges Zurückrollen aller laufenden Transaktion und Beenden offener Datenbankverbindungen beinhaltet. Dies steht im Kontrast zum smart-Shutdownmodus, was solange mit dem Stoppen der PostgreSQL®-Instanz wartete, bis alle offenen Transaktionen und Datenbankverbindungen explizit beendet wurden.
PL/pgSQL mit geänderten Typcasts
PL/pgSQL verwendete seither intern immer die Umwandlung über text-Typen für die Datentypkonvertierung. Mit PostgreSQL® 9.5 ändert sich das Verhalten, indem PL/pgSQL nun direkt die Typecasts für den jeweiligen Zieltyp verwendet, falls vorhanden. Dies ändert das Verhalten von PL/pgSQL in bestimmten Fällen, wie die folgenden Beispiele illustrieren. Ein Fall ist die Zuweisung von numeric-Werten an integer-Typen, in PostgreSQL® 9.4 ergab sich bisher folgende Situation:
DO LANGUAGE plpgSQL
$$
DECLARE
i integer;
n numeric;
BEGIN
n := 1.6;
i := n;
RAISE NOTICE 'i = %', i;
END;
$$;
ERROR: invalid input syntax for integer: "1.6"
CONTEXT: PL/pgSQL function inline_code_block line 1 at assignmentDie Konvertierung ist nicht möglich, da der Umweg über die Text-I/O Routinen wiederum den Wert 1.6 an die integer-Variable i übergibt. Mit der Verwendung über die integrierten Typcast-Funktionen ändert sich das Verhalten in PostgreSQL® 9.5:
NOTICE: i = 2
Das Runden entspricht dem Verhalten von numeric-nach-integer-Umwandlungen aus der SQL-Welt, wenn die Typcastroutinen des entsprechenden Zieltyps direkt verwendet werden (int4() ist die für den Cast von numeric auf integer verwendete Routine), ohne den zusätzlichen Schritt über text:
SELECT int4(1.6);
int4
------
2
(1 row)Eine weitere Auswirkung dieser Änderung ist die Repräsentation von boolean, die sich bei der Konvertierung direkt in einen text-Typ von t/fauf true/false ändert:
DO LANGUAGE plpgSQL
$$
DECLARE
b boolean := TRUE;
t text;
BEGIN
t := b;
RAISE NOTICE 't value = %', t;
END;
$$;
NOTICE: t value = tDas Ergebnis in PostgreSQL® 9.5 ist dagegen:
NOTICE: t value = true
Anwendungen, die sich in irgendeiner Form auf das alte Verhalten verlassen, sollten sorgfältig auf entsprechende Auswirkungen überprüft werden.
Wegfall des Parameters ssl_renegotiation_limit
Zwar akzeptiert PostgreSQL® nach wie vor die pure Existenz des Parameters, allerdings zeigt er in PostgreSQL® 9.5 keine Wirkung mehr, bzw. muss zwingend auf „0“ stehen.
Zusammenfassung
Mit Erscheinen der Version 9.5 liefert das Datenbanksystem PostgreSQL® wieder eine Fülle von Neuerungen und verspricht insbesondere auf Systemen mit vielen CPU-Kernen deutliche Geschwindigkeitssteigerungen. Selbstverständlich stehen ebenfalls fertige Pakete für alle gängigen RPM-basierten Linuxdistributionen auf yum.postgresql.org sowie für Debian und Ubuntu auf apt.postgresql.org bereit. Das Supportteam der credativ GmbH unterstützt Sie gerne bei der Planung, Einsatz oder Migration der neuen PostgreSQL® Version.
Dieser Artikel wurde initial von Bernd Helmle verfasst.
BRIN ist ein in PostgreSQL® 9.5 neu eingeführter Indextyp, der Name steht für Block Range INdex.
Was ist ein Block Range Index?
Die meisten Indexe werden als Baumstruktur realisiert mit deren Hilfe gesuchte Einträge sehr schnell gefunden werden können. Der Aufwand für Suchanfragen in derartig organisierten Indexstrukturen beträgt in der Regel O(log(Anzahl der Einträge)). Ein solcher Baum skaliert mit wachsender Datenmengen, bezogen auf die Abfragezeit folglich logarithmisch. Es spielt für das Auffinden eines bestimmten Eintrags keine große Rolle, ob eine Tabelle 100.000 oder 100.000.000 Zeilen enthält ( log(100.000) ≈ 11,5 | log(100.000.000) ≈ 18,4). Der Speicherbedarf des Baumes wächst jedoch linear mit den Daten, was dazu führt, dass Indexe sehr groß und entsprechend „unhandlich“ werden. Sollen bei einer Tabelle mehr als eine Spalte indiziert werden kann das schnell dazu führen, dass die Indexe ein vielfaches des Speicherplatz der Daten selbst benötigen. Doch auch der Verzicht auf weitere Indexe ist bei großen Datenmengen nicht praktikabel, da beim sequentiellem Zugriff im Zweifel sämtliche Daten gelesen werden müssen.
BRIN Indexe schaffen an dieser Stelle sehr attraktive Einsatzmöglichkeiten. Wie der Name vermuten lässt, werden nicht sämtliche Einträge einzeln im Index aufgeführt, sondern ganze Blöcke. Da ein Block nicht durch einen einzelnen Wert dargestellt werden kann, wird für jeden Block ein Minimal- und Maximalwert abgelegt. Verwendet nun eine Abfrage eine indizierte Spalte muss nicht der gesamte Datenbestand durchsucht werden, sondern nur die Blöcke in denen der gesuchte Wert überhaupt enthalten sein kann.
Einschränkungen
Hier offenbart sich allerdings auch gleichzeitig ein Nachteil dieses Indextyps. Sind die Daten völlig zufällig verteilt, kann es nötig sein, sehr viele Blöcke zu durchsuchen und der Geschwindigkeitsvorteil fällt nur gering aus. Sind die Daten jedoch natürlich sortiert, z.B. Rechnungsnummer oder Bestelldatum in einer Bestelltabelle, oder bilden natürliche Gruppen mit gleichen bzw. ähnlichen Werten, kann das volle Potenzial genutzt werden. Abfragen mit einfachen Vergleichsoperationen werden je nach Datenstruktur und Blockgröße eher weniger von den Vorteilen eines BRIN-Index profitieren. Bereichsabfragen auf günstig verteilten oder gar sortierten Datenbeständen werden im Vergleich zu herkömmlichen sequentiellen Abfragestrategien massiv beschleunigt.
Klein, kleiner, BRIN
Der Hauptvorteil ist jedoch der Speicherverbrauch, so ist ein BRIN z.T. um den Faktor 10.000 kleiner als ein entsprechender Btree. Nachfolgend ein Beispiel von zwei Indexen auf der gleichen Spalte vom Typ timestamp einer 7300 MB großen Tabelle. Zuerst ein Btree- und anschließend der BRIN-Index, der Größenunterschied beträgt etwa Faktor 7000:
# \di+
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------------+-------+----------+-----------+---------+-------------
public | brin_test_time_btree | index | postgres | brin_test | 2142 MB |
public | brin_test_time_brin | index | postgres | brin_test | 288 kB |Blockgröße
Die Blockgröße kann an die zugrunde liegenden Daten angepasst werden. Bei natürlich sortierten Spalten ist die genaue Blockgröße nicht ganz unkritisch. Hier sind größere Blöcke und damit ein noch kleinerer Index je nach Abfragen von Vorteil. Gibt es im Datenbestand jedoch häufig Ausreißer oder sind die Einträge nicht natürlich sortiert, kann die Wahl einer kleineren Blockgröße die Performance stark verbessern. Beim Anlegen des Index kann die Anzahl an indizierten Tabellenblöcken pro BRIN-Block angegeben werden. Der Vorgabewert ist 128, bei der Standardpagegröße von 8 kB ergibt sich eine indizierte Tabellenblockgröße von 1 MB. Nachfolgend Beispiele für Indexe zwischen 8 Pages (64 kB) und 2048 Pages (16 MB) großen Blöcken:
# \di+
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+--------------------------+-------+----------+-----------+---------+-------------
public | brin_test_time_btree | index | postgres | brin_test | 2142 MB |
public | brin_test_time_brin_8 | index | postgres | brin_test | 3936 kB |
public | brin_test_time_brin_32 | index | postgres | brin_test | 1016 kB |
public | brin_test_time_brin_128 | index | postgres | brin_test | 288 kB | Standard
public | brin_test_time_brin_256 | index | postgres | brin_test | 160 kB |
public | brin_test_time_brin_512 | index | postgres | brin_test | 104 kB |
public | brin_test_time_brin_1024 | index | postgres | brin_test | 72 kB |
public | brin_test_time_brin_2048 | index | postgres | brin_test | 56 kB |Abfrageperformance
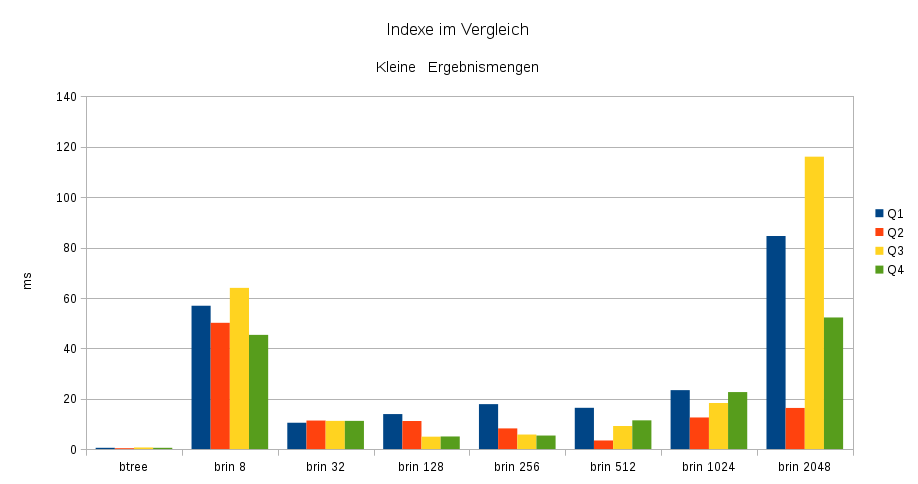
Die nachfolgenden Diagramme zeigen die Ausführungszeiten von fünf SQL-Abfragen und deren Nutzung der verschiedenen Indexe. Die Abfragen Q1 bis Q4 liefern nur kleine Ergebnismengen zurück. Hier zeigt sich die Effektivität des Btree-Indexes sowie der Overhead durch die kleine Blockgröße beim 8-Page-BRIN. Mit steigender Blockgröße sinkt dieser Overhead, doch die Menge an zu durchsuchenden und durch nur ein Min/Max-Paar repräsentierten Daten steigt. Dieser negative Effekt lässt sich an den Indexen mit Blockgröße ab 1024 Pages erkennen. Die von PostgreSQL® verwendete Standardgröße von 128 Pages pro Block ist bei den hier verwendeten Testdaten ein sehr guter Wert, auch wenn z.B. Q2 von einer etwas höheren Blockgröße profitieren würde. Je nach Abfrage und Daten, kann die sinnvollste Blockgröße natürlich variieren.
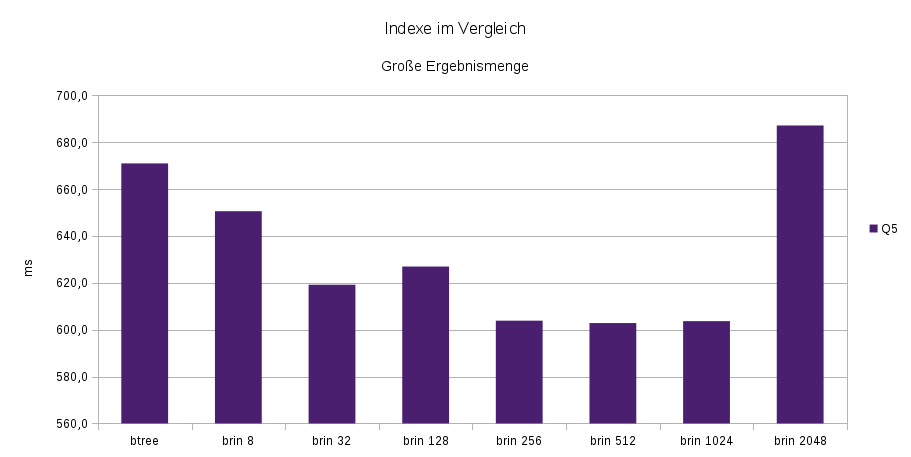
Abfrage Q5 liefert wesentlich mehr Ergebnisse zurück, wodurch das Auffinden der einzelnen Ergebnisse weit weniger die Gesamtzeit beeinflusst. Die Wahl des Indexes spielt hier eine untergeordnete Rolle. Durch die einfachere Möglichkeit ganze Blöcke zurückzuliefern haben Block Range Indexe hier einen Vorteil.
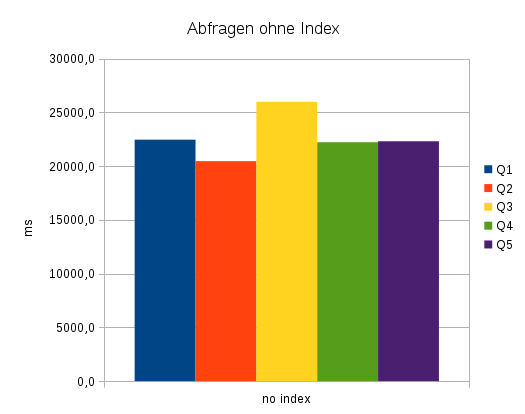
Um keine logarithmische Skala verwenden zu müssen, sind die Ausführungen ohne Indexnutzung in einem zusätzlichen Diagramm dargestellt. Die Ausführungszeiten liegen hier alle im Bereich von 20 s bis 26 s.
Wartung
Block Range Indexe werden nicht automatisch aktualisiert und die Minimal- und Maximalangaben pro Spalte sind nicht zwingend genau, sondern verstehen sich als obere und untere Schranken. Wird eine Tabelle ständig erweitert (INSERT) verschlechtert dies die Qualität des Index nicht. Werden jedoch die vorhandenen Daten Umstrukturiert oder geändert (UPDATE, DELETE), kann es nötig werden einen BRIN-Index neu zu erzeugen. Ob PostgreSQL® hier um einen automatischen Mechanismus erweitert wird, ist noch nicht abschließend geklärt.
Fazit / tl;dnr
Die Verwendung von BRIN ist nicht überall sinnvoll, bei der Analyse sehr großer Datenbestände, die in irgendeiner Form gruppiert oder sortiert sind, spielen Block Range Indexe jedoch ihre Vorteile aus. Durch die stetig wachsende Datenmengen ergeben sich hier viele spannende Anwendungsfälle. Beim gezielten Einsatz von Block Range Indexen unterstützt unser PostgreSQL® Competence Center Sie natürlich genauso gerne wie bei allen anderen Themen und Problemstellungen rund um PostgreSQL®.
Anhang
Wenn Sie bereits eine Vorabversion von PostgreSQL® 9.5 testen und 10 GB freien Speicherplatz haben, können Sie die oben gezeigten Beispiele leicht selbst nachstellen. Für eigene Experimente sind Tabellen- und Indexdefinitionen sowie die verwendeten Abfragen angehängt.
-- Tabelle
CREATE TABLE brin_test AS
SELECT
series AS id,
md5(series::TEXT) AS value,
'2015-10-31 13:37:00.313370+01'::TIMESTAMP + (series::TEXT || ' Minute')::INTERVAL AS time
FROM
generate_series(0,100000000) AS series;
-- Indexe
CREATE INDEX brin_test_time_btree ON brin_test USING btree (time);
CREATE INDEX brin_test_time_brin_8 ON brin_test USING brin (time) WITH (pages_per_range=8);
CREATE INDEX brin_test_time_brin_32 ON brin_test USING brin (time) WITH (pages_per_range=32);
CREATE INDEX brin_test_time_brin_128 ON brin_test USING brin (time) WITH (pages_per_range=128);
CREATE INDEX brin_test_time_brin_256 ON brin_test USING brin (time) WITH (pages_per_range=256);
CREATE INDEX brin_test_time_brin_512 ON brin_test USING brin (time) WITH (pages_per_range=512);
CREATE INDEX brin_test_time_brin_1024 ON brin_test USING brin (time) WITH (pages_per_range=1024);
CREATE INDEX brin_test_time_brin_2048 ON brin_test USING brin (time) WITH (pages_per_range=2048);
-- Abfragen
SELECT * FROM brin_test WHERE time = '2100-11-11 13:37:00.31337'; -- Q1
SELECT * FROM brin_test WHERE time = '2205-12-19 00:16:00.31337'; -- Q2
SELECT * FROM brin_test WHERE time >= '2016-11-11' AND time <= '2016-11-12'; -- Q3
SELECT * FROM brin_test WHERE time >= '2100-11-11' AND time <= '2100-11-12'; -- Q4
SELECT * FROM brin_test WHERE time >= '2200-01-01 00:00:00.00000'; -- Q5
-- Ergebnisse
-- btree brin1 brin 8 brin 32 brin 128 brin 256 brin 512 brin 1024 brin 2048 no index
-- Q1 0,5 348,6 56,9 10,5 13,9 17,8 16,4 23,4 84,6 22450,3
-- Q2 0,4 318,4 50,1 11,3 11,1 8,2 3,4 12,6 16,3 20455,7
-- Q3 0,6 327,2 64,0 11,2 4,9 5,8 9,1 18,3 116,1 25972,1
-- Q4 0,5 316,9 45,3 11,2 5,0 5,4 11,4 22,6 52,2 22216,3
-- Q5 670,9 902,2 650,5 619,2 626,9 603,8 602,8 603,6 687,1 22305,2Weiterführende Informationen: BRIN Indexes
Dieser Artikel wurde ursprünglich von Alexander Sosna verfasst.
Hintergrund
Mehrsprachige Unterstützung ist seit jeher in PostgreSQL® fester Bestandteil. PostgreSQL® nutzt dabei die Funktionen, die vom Betriebssystem zur Verfügung gestellt werden. Dies hat den Vorteil, dass PostgreSQL® sich hinsichtlich der Behandlung von Zeichenketten identisch zu allen anderen Programmen verhält, die ebenfalls auf den Betriebssystemroutinen basieren. Unter Linux ist hierfür maßgeblich die in der glibc vorhandene Unterstützung verantwortlich. So verhalten sich alle aus der Unixwelt bekannten Tools für Textverarbeitung analog zu den Vorgaben, die die jeweilige Locale-Einstellung in der aktuellen Linuxumgebung vorgibt. Die Locale-Einstellungen umfassen mehrere Elemente:
- Sortierung
- Interpretation von Stringliteralen
- Interpretation von Zahlen
- Interpretation von Zeitwerten
- Währungssymbole
- Ausgabe von Programmmeldungen
Die Liste erhebt keinen Anspruch von Vollständigkeit und kann sicherlich noch erweitert werden. Sie sollte jedoch alle insbesondere für PostgreSQL® relevanten Attribute abdecken. Vor allem die ersten beiden Eigenschaften sind für PostgreSQL® interessant, da beim Anlegen einer Datenbank vornherein entschieden werden muss, welche Sprache für Zeichenketten interessant sind. In der Regel übernimmt PostgreSQL® die Standardeinstellung hierfür direkt vom Betriebssystem, jedoch kann beispielsweise auch das CREATE DATABASE Kommando verwendet werden, um hier alternative Attribute pro Datenbank zu verwenden. Die relevanten Einstellungen werden über das LC_CTYPE Argument für Zeicheninterpretation (was ist eine Zahl und was ein Buchstabe) sowie LC_COLLATE (wie wird sortiert) für die gesamte Datenbank permanent festgelegt. Diese Einstellungen entscheiden auch, wie entsprechende Werte im Index abgelegt werden und wie Vergleiche mit Zeichenketten interpretiert werden.
Problematik
In letzter Zeit hat sich herauskristallisiert, dass Betriebssysteme beim Wechsel in eine neue Version vermehrt Probleme bekommen, die Konsistenz dieser Locales zu garantieren. Dies führt insbesondere bei PostgreSQL® dazu, dass beim Upgrade auf eine neue Betriebssystemversion sehr stark auf die Kompatibilität zwischen den verwendeten Locales geachtet werden muss. Ein prominentes Beispiel ist Red Hat und damit in Verbindung auch das sehr häufig verwendete freie Derivat CentOS. Beim Wechsel von auf CentOS 5.11 auf CentOS 6.6 ändern sich die Sortierreihenfolgen für bestimmte Zeichenketten in einigen Locales. Betroffen hiervon ist u.a. auch die Locale für de_DE.UTF-8. Bestimmte Zeichenketten werden bei der Sortierung unterschiedlich behandelt. CentOS 5.11 sortiert zum Beispiel Zeichenketten im Format 9-9-0 und 999 wie folgt:
echo -e '9-9-9\n999\n110\n1-1-0' | LANG=de_DE.UTF-8 sort
110
1-1-0
999
9-9-9
In CentOS 6.6 ändert sich die Sortierreihenfolge:
echo -e '9-9-9\n999\n110\n1-1-0' | LANG=de_DE.UTF-8 sort
1-1-0
110
9-9-9
999
Ausschlaggebend ist hier offensichtlich das zusätzliche, zur Formatierung vorgesehene ‚-‚-Zeichen, dass unter CentOS 5.11 und 6.6 dazu führt, dass solche Zeichenketten unterschiedlich interpretiert werden. Dies hat schwerwiegende Auswirkungen auf die Art und Weise, wie Indexe in PostgreSQL®-Datenbanken mit de_DE.UTF-8 Locale aufgebaut und gelesen werden. Standardmässig benutzt PostgreSQL® für Indexe für Zeichentypen wie text, character oder varchar immer einen sogenannten BTree-Indextyp. Ein BTree ist immer aufsteigend sortiert und PostgreSQL® nutzt BTree-Indexe ebenfalls auch für eindeutige Schlüssel (Primary Key, Unique Constraints). Die Folge sind unter Umständen logische Inkonsistenzen, wenn von CentOS 5 auf CentOS 6 gewechselt wird. Dies ist insbesondere unter folgenden Voraussetzungen der Fall:
- Die Datenbanken verwenden ein Locale, das von Betriebssystemseitigen Änderungen betroffen ist, in diesem Fall
de_DE.UTF-8. - Die Datenbank wurde entweder physisch auf die neue Plattform umgezogen, oder
- ein Upgrade des Betriebssystems wurde vorgenommen.
- Die Datenbank ist ein Streaming Standby auf einer Plattform mit unterschiedlichen Locales.
Logische Inkonsistenzen können hierbei nicht nur in entsprechenden Indexen auftreten, sondern auch fehlerhafte Abfrageergebnisse zur Folge haben. Da gegebenenfalls Sortieroperationen für eine Abfrage genutzt werden, können unterschiedliche Ergebnismengen erzeugt werden. Insbesondere Abfragepläne mit zugrundeliegenden Sortieroperationen wie Merge Join, DISTINCT oder einfaches ORDER BYsind hier Kandidaten. Die Folgen können jedoch noch vielfältiger sein. Auch bei Installationen mit Streaming Standby Servern auf unterschiedlichen Betriebssystemversionen muss daher auf die Kompatibilität der Locales geachtet werden.
Tests haben außerdem ergeben, dass mindestens auch die Versionen 6 und 7 von RedHat Enterprise Linux sowie CentOS 7 die beschriebenen Inkompabilitäten enthalten:
- CentOS 5 und CentOS 7 sowie RHEL 7 verhalten sich hinsichtlich unserer Erkenntnisse für das Locale
de_DE.UTF-8identisch. - RHEL6 und CentOS 6 sind inkompatibel zur
de_DE.UTF-8Locale in den vorhergehenden und nachfolgenden Hauptversionen. - Es gibt Indikatoren, die darauf hindeuten, dass andere Locales ebenfalls betroffen sind: https://bugs.centos.org/view.php?id=7009 und https://bugs.centos.org/view.php?id=6210.
Die Folgende Tabellen zeigt die nach unseren Tests festgestellten Inkompatibilitäten für das deutsche Locale de_DE.UTF-8 zwischen den CentOS-Versionen:
| de_DE.UTF-8 | CentOS 5.11 | CentOS 6.6 | CentOS 7.1 |
| CentOS 5.11 | X | ||
| CentOS 6.6 | X | X | |
| CentOS 7.1 | X |
Maßnahmen
Generell sollte ein gründlicher Test des Betriebes von PostgreSQL® im Falle von Betriebssystemupgrades im Vorfeld erfolgen. Ist ein Upgrade bereits erfolgt, so sollten unbedingt auf jeden Fall alle Indexe auf Charaktertypen überprüft und auf jeden Fall mit REINDEX neu erzeugt werden. Ist das Kind bereits in den Brunnen gefallen und man stellt beispielsweise Dubletten bei eindeutigen Textschlüsseln fest, so sollte man die Daten einer logischen Prüfung unterziehen. In diesem Fall hilft vor dem wiederholten Erzeugen der Textschlüssel nur das Bereinigen der Inkonsistenzen.
Streaming Standby erfordern Binärkompatible Plattformen, jedoch können unterschiedliche Betriebsversionen zum Einsatz kommen. Hier sollte ebenfalls sorgfältig die Zielplattform geprüft werden, da unter Umständen sonst zum Primärserver abweichende Abfrageergebnisse materialisiert werden können. Generell sind die Lösungsmöglichkeiten eines korrekten Betriebes in solchen Fällen für Streaming Standby begrenzt. Da ein Standby eine Blockweise Kopie der Datenbank darstellt und keine schreibenden Transaktionen zulässt, können logische Inkonsistenzen nur bei Abfragen gegen die Datenbasis auftreten. Ein Vorgehen wäre beispielsweise die Localerepräsentation auf den Standbysystemen durch diejenige des Primärservers zu ersetzen.
Wird ein Streaming Standby für ein Upgrade auf eine neue, mit inkompatiblen Locale behaftete Betriebssystemversion verwendet, so sollte nach dem Wechsel und vor Inbetriebnahme in Produktion die Datenbank reindiziert werden.
Zusammenfassung
Unterschiede in den Locales zwischen CentOS 5, CentOS 6 und CentOS 7 sowie RHEL 6 und RHEL 7 können unter bestimmten Voraussetzungen zu logischen Inkonsistenzen in der Datenbasis in PostgreSQL® führen oder Abfrageergebnisse verfälschen. Daher ist bei Upgrades von Betriebssystemen auf jeden Fall eine sorgfältige Prüfung der verwendeten Locales angeraten. Erste Tests zeigen, dass es zumindest für das deutsche Locale de_DE.UTF-8 in CentOS 7 keine Unterschiede zu CentOS 5 gibt. Besondere Vorgehensweisen und Vorkehrungen sind daher zu beachten, sollte eine PostgreSQL®-Datenbank von CentOS 6 auf CentOS 7 oder CentOS 5 auf CentOS 6 umgezogen werden.
Das Team der credativ GmbH unterstützt Sie bei der Planung solcher Upgrades, aber auch bei der Fehlerbehandlung, sollte ein entsprechendes Problem bereits aufgetreten sein.
Neu in PostgreSQL® 9.5 ist das Feature ROW LEVEL SECURITY.
Was ist ROW LEVEL SECURITY
Mit Hilfe von ROW LEVEL SECURITY lässt sich bestimmen, welche Voraussetzungen erfüllt sein müssen, damit ein Datenbankbenutzer ein Tupel sieht, einfügen, löschen oder bearbeiten darf.
Kurz gesagt, es beseht nun die Möglichkeit Zugriffsberechtigungen auf Tupelebene zu vergeben.
Zur Konfiguration dieser Zugriffsberechtigungen kommen die in PostgreSQL® 9.5 eingeführten, SECURITY POLICIES zum Einsatz. Mit Hilfe dieser können feingranulare Regeln definiert werden, die bei den Zugriff auf Tuple ausgewertet werden.
Beispiel
In unserem Beispiel möchten wir den Zugriff auf eine Tabelle einschränken, die die Verkaufszahlen verschiedener Abteilungen beinhaltet. Wir möchten den Benutzern den Zugriff aber nicht komplett entziehen. Jeder Benutzer soll auf die Zahlen der Abteilung zuzugreifen können der er angehört. Die Zahlen der anderen Abteilungen sollen hingegen nicht sichtbar oder veränderbar sein.
Zunächst benötigen wir eine Zuordnung von Benutzern zu Abteilungen:
avo@[local]:5495 [postgres] > CREATE TABLE user_in_department ( username text, dep text, PRIMARY KEY (username, dep));
avo@[local]:5495 [postgres] > INSERT INTO user_in_department
VALUES ('manuel_mueller' , 'games') ,
('michael_schneider' , 'games') ,
('michael_schneider' , 'tv') ,
('bobdan_muel' , 'tv') ,
('tizian_martin' , 'audio');Nachdem wir nun eine Zuordnung von Benutzern zu Abteilungen haben, benötigen wir noch unsere „sales“ Tabelle:
avo@[local]:5495 [postgres] > CREATE TABLE sales ( id SERIAL PRIMARY KEY, department text NOT NULL, target_range tsrange, sum numeric);
Als Beispieldaten dienen uns die Verkaufszahlen vier verschiedener Abteilungen:
avo@[local]:5495 [postgres] > INSERT INTO sales (department, target_range, sum)
VALUES ('tv' , '[2015-01-01 00:00 , 2015-02-01 00:00)' , 120000) ,
('games' , '[2015-01-01 00:00 , 2015-02-01 00:00)' , 140000) ,
('computer' , '[2015-01-01 00:00 , 2015-02-01 00:00)' , 2000) ,
('audio' , '[2015-01-01 00:00 , 2015-02-01 00:00)' , 90000);Die Prüfung der Zugriffsberechtigungen wird über die folgende SECURITY POLICY definiert:
avo@[local]:5495 [postgres] > CREATE POLICY user_in_department
ON sales
FOR ALL
TO public
USING (
(
SELECT COUNT(uid.username) >= 1
FROM user_in_department uid
WHERE uid.username = current_user AND
uid.dep = department
)
);Zu guter Letzt müssen wir ROW LEVEL SECURITY für die Tabelle „sales“ aktivieren, und einen Beispielbenutzer anlegen:
avo@[local]:5495 [postgres] > ALTER TABLE sales ENABLE ROW LEVEL SECURITY; CREATE USER manuel_mueller; GRANT SELECT ON user_in_department TO manuel_mueller; GRANT SELECT, INSERT, UPDATE, DELETE ON sales TO manuel_mueller;
Frag der Benutzer „manuel_mueller“ nun die Verkaufszahlen ab, so erhält er als Ergebnis nur die Verkaufszahlen der Abteilung der er angehört:
manuel_mueller@[local]:5495 [postgres] > SELECT * FROM sales; id | department | target_range | sum ----+------------+-----------------------------------------------+-------- 2 | games | ["2015-01-01 00:00:00","2015-02-01 00:00:00") | 140000 (1 row)
Selbst wenn es ihm ermöglicht ist, selber Eintragungen innerhalb der Tabelle sales vorzunehmen, wird verhindert, dass er Eintragungen für andere Abteilungen vornimmt. Auch ist es Ihm nicht möglich Eintragungen anderer Abteilungen zu bearbeiten:
manuel_mueller@[local]:5495 [postgres] > UPDATE sales SET sum=sum+100; UPDATE 1
Die aktuellen SECURITY POLICIES können mit SELECT * FROM pg_policies; oder mit Hilfe des Backslashcommands \dp abgefragt werden. In unserem Beispiel sieht das Ergebnis wie folgt aus:
avo@[local]:5495 [postgres] > SELECT * FROM pg_policies ;
-[ RECORD 1 ]-------------------------------------------------------------------------------------
schemaname | public
tablename | sales
policyname | user_in_department
roles | {public}
cmd | ALL
qual | ( SELECT (count(uid.username) >= 1) +
| FROM user_in_department uid +
| WHERE ((uid.username = ("current_user"())::text) AND (uid.dep = sales.department)))
with_check | __NULL__Zusätzlich zu USING kann die WITH CHECK Option angegeben werden. Diese greift, sobald ein Benutzer Tupel einfügen, ändern oder entfernen möchte.
Das folgende Beispiel unterbindet die nachträgliche Bearbeitung von Eintragungen:
ALTER POLICY user_in_department ON sales WITH CHECK ( target_range @> NOW()::timestamp );
Technische Details
Neben der Einschränkung aller Operationen können auch spezifische Operationen eingeschränkt werden. Dazu wird bei der Erstellung der SECURITY POLICY nicht das Schlüsselwort ALL, sondern die entsprechende Operation eingetragen (SELECT, INSERT, UPDATE oder DELETE).
In unserem Beispiel wirkt sich die Einschränkung auf alle Benutzer aus (TO). Aber auch dies lässt sich spezifizieren. Soll die Überprüfung nur für einen gewissen Kreis an Benutzern geprüft werden, so kann anstelle von „public“ auch eine spezielle Gruppe angegeben werden. Achtung: allen anderen Benutzern wird der Zugriff ohne Prüfung verwehrt.
public
Mit ROW LEVEL SECURITY wurde der Parameter row_security eingeführt. Dieser nimmt einen von drei möglichen Werten an: off, onund force.
- off deaktiviert die Überprüfung der
SECURITY POLICIES. Dies führt dazu, dass alle Tabellen für dieROW LEVEL SECURITYaktiviert worden ist, für normale Benutzer gesperrt werden. Ein versuchter Zugriff auf solch eine Tabelle wird mir der Fehlermeldung „ERROR: insufficient privilege to bypass row security.“ geblockt. - on aktiviert die Überprüfung. Es ist zugleich die Standardeinstellung.
- force aktiviert die Überprüfung. Im Gegensatz zu
onunterliegen in dieser Einstellung auchTABLE OWNERder Überprüfung, welche normalerweise nicht von der Überprüfung betroffen sind.
SUPERUSER unterliegen der ROW LEVEL SECURITY nicht.
Fazit
Das oben genannte Beispiel ist nur eins von vielen denkbaren Einsatzszenarien. Zwar lassen sich viele Operationen auch mit entsprechenden VIEWS oder TRIGGERN realisieren, jedoch bietet PostgreSQL® mir ROW LEVEL SECURITY nun eine einfacher zu administrierende Methode zur Umsetzung. Zugleich entfällt der zusätzliche Overhead für die Ausführung der entsprechenden Trigger.
Details können der PostgreSQL® Dokumentation entnommen werden.
ROW LEVEL SECURITY ist nur eines von vielen neuen und interessanten Features, die mit Version 9.5 von PostgreSQL® eingeführt werden. Eine Übersicht über die neuen Features bietet das CREATE TABLE vermietungen (
kennzeichen TEXT PRIMARY KEY,
status TEXT NOT NULL
)
Als Beispieldaten dienen uns zwei einfache Datensätze:
INSERT INTO vermietungen
(kennzeichen, status)
VALUES
('MG-CD-5432', 'vermietet'),
('MG-CD-6000', 'nicht vermietet');Nun soll der Status eines neuen Fahrzeugs eingetragen werden. Normalerweise müsste entweder seitens der Anwendung oder durch entsprechende Trigger sichergestellt sein, dass das Fahrzeug bereits in der Tabelle „vermietungen“ vorhanden ist. Erst dann kann der Status entsprechend geändert werden. Es muss also zwischen bereits vorhandenen und noch nicht vorhandenen Fahrzeugen / Datensätzen unterschieden werden. Dies erzeugt eine Reihe von zusätzlichen SQL-Statements. Mit Hilfe von INSERT ... ON CONFLICT ... kann dies vereinfacht werden.
INSERT INTO vermietungen
(kennzeichen, status)
VALUES ('MG-CD-5432', 'nicht vermietet')
ON CONFLICT ON CONSTRAINT vermietungen_pkey DO UPDATE SET status = 'nicht vermietet';
INSERT 0 1Technische Details
Wie im obigen Beispiel bereits gezeigt, muss nicht nur angegeben werden was ausgeführt wird, sondern auch wann. So ist es möglich bei Verletzung unterschiedlicher Constraints unterschiedliche Aktionen auszuführen.
Ein Auszug aus der PostgreSQL® 9.5 Dokumentation zeigt die Syntax:
[ WITH [ RECURSIVE ] with_query [, ...] ]
INSERT INTO table_name [ AS alias ] [ ( column_name [, ...] ) ]
{ DEFAULT VALUES | VALUES ( { expression | DEFAULT } [, ...] ) [, ...] | query }
[ ON CONFLICT [ conflict_target ] conflict_action ]
[ RETURNING * | output_expression [ [ AS ] output_name ] [, ...] ]
where conflict_target can be one of:
( { column_name_index | ( expression_index ) } [ COLLATE collation ] [ opclass ] [, ...] ) [ WHERE index_predicate ]
ON CONSTRAINT constraint_name
and conflict_action is one of:
DO NOTHING
DO UPDATE SET { column_name = { expression | DEFAULT } |
( column_name [, ...] ) = ( { expression | DEFAULT } [, ...] ) |
( column_name [, ...] ) = ( sub-SELECT )
} [, ...]
[ WHERE condition ]Im Gegensatz zu zwei separaten Aktionen (INSERT mit nachfolgendem UPDATE) handelt es sich bei INSERT ... ON CONFLICT DO UPDATE ... um eine atomare Aktion. Das bedeutet, dass keine zusätzlichen Locks benötigt werden, um nebenläufige Aktionen zu berücksichtigen.
UPSERT ist nur eines von vielen neuen und interessanten Features, die mit Version 9.5 von PostgreSQL® eingeführt werden. Ein Übersicht über die neuen Features bietet das Pgloader ist ein Werkzeug, um große Datenmengen schnell und effizient in eine PostgreSQL®-Datenbank zu laden. Eine Vielzahl an Quellformaten wird unterstützt, natürlich CSV, aber auch andere Datenbanken wie MySQL, SQLite, dBase und MSSQL. Die Daten können beim Import flexibel konvertiert werden. Sollten einige Datensätze nicht importierbar sein, weil sie z.B. ein ungültiges Datumsformat benutzen, das von PostgreSQL® zurückgewiesen wird, so bricht nicht der gesamte Import ab, sondern diese Datensätze werden in Reject-Files abgelegt, wo sie später inspiziert und z.B. manuell korrigiert werden können. Hier ein Beispiel, wie man eine CSV-Datei lädt. Man erstellt zunächst eine Beschreibungsdatei für den Import, hier gc.load: … und ruft dann Pgloader auf: Die aktuelle Version 3 von Pgloader wurde in Common Lisp implementiert und ist laut Dimitri Fontaine, dem Autor von Pgloader, um ein Vielfaches schneller als der Vorgänger in Python. Wir haben in der Vergangenheit schon mit Dimitri zusammengearbeitet, um die notwendigen Common Lisp-Pakete ins Debian-Archiv zu bekommen, die beim Kompilieren von Pgloader benötigt werden, und die jetzt auch im aktuellen Debian-Release 8 „Jessie“ enthalten sind. In den letzten Wochen hat die credativ diese Arbeit nun auf apt.postgresql.org ausgedehnt, womit Pgloader nun auch für die ältere Debian-Version 7 „Wheezy“ und die Ubuntu-Versionen 12.04 „precise“, 14.04 „trusty“ und 14.10 „utopic“ verfügbar ist. Hierfür haben wir Backports des benötigten sbcl-Compilers sowie von über 50 Common Lisp-Bibliotheken erstellt. Damit gibt es nun fertige Pgloader-Pakete für diese Linux-Distribtionen.LOAD CSV
FROM 'gc.csv' WITH ENCODING iso-8859-1 (latitude, longitude, description, note)
INTO postgresql:///postgres?geocaches (latitude, longitude, description, note)
WITH fields terminated by ',';
$ pgloader gc.load
table name read imported errors time
------------------------------ --------- --------- --------- --------------
fetch 0 0 0 0.005s
------------------------------ --------- --------- --------- --------------
geocaches 81824 81824 0 1.273s
------------------------------ --------- --------- --------- --------------
Total import time 81824 81824 0 1.278s
Seit PostgreSQL® 9.1 implementiert PostgreSQL® eine Schnittstelle für den Zugriff auf externe Datenquellen. Die im SQL Standard festgelegte Schnittstelle (SQL/MED) gestattet den transparenten Zugriff und Manipulation externer Datenquellen in der gleichen Art und Weise wie mit PostgreSQL®-eigenen Tabellen. Die externen Datenquellen erscheinen als Tabellen in der jeweiligen Datenbank und lassen sich in SQL-Anweisung uneingeschränkt verwenden. Der Zugriff wird über einen sogenannten Foreign Data Wrapper (FDW) implementiert, der die Schnittstelle zwischen PostgreSQL® und der externen Datenquelle bildet. Der FDW ist auch dafür verantwortlich, Datentypen oder nicht-relationale Datenquellen entsprechend auf die Tabellenstruktur abzubilden. Dies ermöglicht somit auch die Anbindung von nicht-relationalen Datenquellen wie Hadoop, Redis u.a. Eine Übersicht einiger verfügbarer Foreign Data Wrapper gibt es im PostgreSQL® Wiki.
Informix FDW
Im Kontext vieler Informix-Migrationen entwickelte die credativ GmbH einen Foreign Data Wrapper (FDW) für Informixdatenbanken. Dies unterstützt die Migration, aber auch die Integration von PostgreSQL® in bestehende Informixinstallationen, um Datenaustausch und -verarbeitung zu erleichtern. Der Informix FDW unterstützt alle PostgreSQL® Versionen mit SQL/MED Implementierung, also von 9.1 bis aktuell 9.3. Der Informix FDW unterstützt mit PostgreSQL® 9.3 darüber hinaus schreibende Operationen auf Foreign Tables.
Installation
Die Installation setzt mindestens ein vorhandenes CSDK von IBM für Informix voraus. Das CSDK kann direkt per Download bezogen werden. Im Folgenden gehen wir davon aus, dass eine CSDK-Installation in /opt/IBM/informix vorhanden ist. Der Pfad kann je nach Installation variieren. Die Quellen des Informix FDW lassen sich direkt vom credativ github Repository klonen, oder man besorgt sich ein Release Tarball (zum Zeitpunkt dieses Artikels Version 0.2.1). Die folgende Installationsbeschreibung geht von einem System mit CentOS 6 aus, kann jedoch mit Abweichungen auf jedem anderen Linuxsystem erfolgen.
% wget 'https://github.com/credativ/informix_fdw/archive/REL0_2_1.tar.gz' % tar -xzf REL0_2_1.tar.gz
Anschließend lässt sich der FDW mit Angabe des CSDK-Installationsordners bauen:
% export INFORMIXDIR=/opt/IBM/informix % export PATH=$INFORMIXDIR/bin:$PATH % PG_CONFIG=/usr/pgsql-9.3/bin/pg_config make
Im Listing wurde die Umgebungsvariable PG_CONFIG explizit auf die PostgreSQL® 9.3 Installation gesetzt. Es handelt sich hierbei um eine Installation von PGDG-RPM Paketen auf CentOS 6, in der pg_config außerhalb des Standardpfades liegt. Ferner muss das Paket postgresql93-devel installiert sein. Wurden alle Pfade richtig gesetzt kann der FDW installiert werden.
% PG_CONFIG=/usr/pgsql-9.3/bin/pg_config make install
Dies installiert alle notwendigen Bibliotheken. Damit diese korrekt funktionieren und beim Laden in die PostgreSQL® Instanz ebenfalls die benötigten Informixbibliotheken finden, müssen letztere noch im Dynamic Linker des Systems konfiguriert werden. Ausgehend von der bereits angesprochenen CentOS 6 Plattform geschieht dies am einfachsten über eine zusätzliche Konfigurationsdatei in /etc/ld.so.conf.d (dies erfordert in diesem Fall root-Berechtigung!):
% vim /etc/ld.so.conf.d/informix.conf
Diese Datei sollte die Pfade zu den benötigten Informixbibliotheken enthalten:
/opt/IBM/informix/lib /opt/IBM/informix/lib/esql
Anschließend muss der Cache des Dynamic Linker erneuert werden:
% ldconfig
Die Installation des Informix FDW sollte nun einsatzbereit sein.
Konfiguration
Um den Informix FDW in einer Datenbank verwenden zu können, muss der FDW in die betreffende Datenbank geladen werden. Der FDW ist eine sogenannte EXTENSION und diese werden mit dem CREATE EXTENSION Kommando geladen:
#= CREATE EXTENSION informix_fdw; CREATE EXTENSION
Um eine Informixdatenbank über den Informix FDW nun anzubinden, benötigt man zunächst eine Definition, wie auf die externe Datenquelle zugegriffen werden soll. Hierzu erstellt man mit dem CREATE SERVER Kommando eine Definition mit dem vom Informix FDW benötigten Informationen. Zu beachten ist, dass die Optionen, die einer SERVER-Direktive mitgegeben werden, vom jeweiligen FDW abhängig ist. Für den Informix FDW benötigt man mindestens folgende Parameter:
- informixdir – Installationsverzeichnis des CSDK
- informixserver – Name der Serververbindung, die über das Informix CSDK konfiguriert wurde (siehe hierzu die Informix Dokumentation, bzw. $INFORMIXDIR/etc/sqlhosts)
Das Erstellen der SERVER-Definition erfolgt dann wie folgt:
=# CREATE SERVER centosifx_tcp
FOREIGN DATA WRAPPER informix_fdw
OPTIONS(informixdir '/opt/IBM/informix',
informixserver 'ol_informix1210');
Die Variable informixserver ist der Instanzname der Informixinstanz, hier muss man einfach den Vorgaben der Informixinstallation folgen. Der nächste Schritt erzeugt nun ein sogenanntes Usermapping, mit der man eine PostgreSQL®-Rolle (bzw. Benutzer) auf die Informixzugangsdaten bindet. Ist diese Rolle am PostgreSQL®-Server angemeldet, so nutzt diese automatisch über das Usermapping die angegebenen Logininformation, um sich am Informixserver centosifx_tcp anzumelden.
=# CREATE USER MAPPING FOR bernd
SERVER centosifx_tcp
OPTIONS(username 'informix',
password 'informix')
Auch hier sind die in der OPTIONS-Direktive spezifizierten Parameter vom jeweiligen FDW abhängig. Nun können sogenannte Foreign Tables zum Einbinden von Informixtabellen angelegt werden. Im folgenden Beispiel wird eine einfache Relation mit Strassennamen vom Informixserver ol_informix1210 in die PostgreSQL®-Instanz eingebunden. Wichtig ist, dass die Konvertierungen von Datentypen von Informix zu PostgreSQL® mit kompatiblen Datentypen erfolgt. Zunächst die Definition der Informixtabelle, wie sie in der Informixinstanz angelegt wurde:
CREATE TABLE osm_roads(id bigint primary key,
name varchar(255),
highway varchar(32),
area varchar(10));
Die Definition in PostgreSQL® sollte analog erfolgen, können Datentypen nicht konvertiert werden wird eine Fehler beim Erzeugen der Foreign Table geworfen. Wichtig beim Konvertieren von Zeichenkettentypen wie bspw. varchar ist auch, dass beim Erzeugen der Foreign Table eine entsprechende Zielkonvertierung definiert wird. Der Informix FDW verlangt daher folgende Parameter beim Anlegen einer Foreign Table:
- client_locale – Locale des Clients (sollte identisch zum Server Encoding der PostgreSQL®-Instanz sein)
- db_locale – Locale des Datenbankservers
- table oder query – Die Tabelle bzw. SQL Abfrage, auf der die Foreign Table basiert. Eine auf einer Abfrage basierende Foreign Table kann keine modifizierenden SQL-Operationen ausführen.
#= CREATE FOREIGN TABLE osm_roads(id bigint,
name varchar(255),
highway varchar(32),
area varchar(10))
SERVER centosifx_tcp
OPTIONS(table 'osm_roads',
database 'kettle',
client_locale 'en_US.utf8',
db_locale 'en_US.819');Wer sich nicht sicher ist, wie die Standardlocale der PostgreSQL® Datenbank aussehen, kann diese sich am einfachsten per SQL anzeigen lassen:
=# SELECT name, setting FROM pg_settings WHERE name IN ('lc_ctype', 'lc_collate');
name | setting
------------+------------
lc_collate | en_US.utf8
lc_ctype | en_US.utf8
(2 rows)
Die Locale- und Encodingeinstellungen sollten unbedingt möglichst übereinstimmend gewählt werden. Sind alle Einstellungen korrekt gewählt worden, kann direkt über PostgreSQL® auf die Datenbestände der Tabelle osm_roads zugegriffen werden:
=# SELECT id, name FROM osm_roads WHERE name = 'Albert-Einstein-Straße'; id | name ------+------------------------ 1002 | Albert-Einstein-Straße (1 row)
Je nach Anzahl an Tupel in der Foreign Table kann das Selektieren eine signifikante Dauer aufweisen, da bei inkompatiblen WHERE-Klauseln die gesamte Datenmenge per Full Table Scan erst an den PostgreSQL®-Server übermittelt werden muss. Der Informix FDW unterstützt jedoch Predicate Pushdown unter bestimmten Voraussetzungen. Darunter versteht man die Fähigkeit, Teile der WHERE-Bedingung, die die Foreign Table betreffen an den Remote Server zu übermitteln und dort bereits die Filterbedingung anzusetzen. Das erspart die Übertragung an sich nutzloser Tupel, da diese ja im PostgreSQL® Server herausgefiltert werden würden. Obiges Beispiel sieht im Ausführungsplan beispielsweise so aus:
#= EXPLAIN (ANALYZE, VERBOSE)
SELECT id, name
FROM osm_roads WHERE name = 'Albert-Einstein-Straße';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Foreign Scan on public.osm_roads (cost=2925.00..3481.13 rows=55613 width=24) (actual time=85.726..4324.341 rows=1 loops=1)
Output: id, name
Filter: ((osm_roads.name)::text = 'Albert-Einstein-Straße'::text)
Rows Removed by Filter: 55612
Informix costs: 2925.00
Informix query: SELECT *, rowid FROM osm_roads
Total runtime: 4325.351 ms
Die Filter-Anzeige in diesem Ausführungsplan zeigt, dass insgesamt 55612 Tuple ausgefiltert wurde, letztlich nur ein einziges Tupel wurde zurückgegeben, da es die Filterbedingung erfüllte. Das Problem liegt hier am impliziten Cast, den PostgreSQL® in der WHERE-Bedingung über die Zeichenkettenspalte name legt. Aktuelle Versionen des Informix FDW berücksichtigen dies noch nicht. Jedoch können Prädikate an den Foreign Server übermittelt werden, wenn diese bspw. Ganzahltypen entsprechen:
#= EXPLAIN (ANALYZE, VERBOSE) SELECT id, name FROM osm_roads WHERE id = 1002;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Foreign Scan on public.osm_roads (cost=2925.00..2980.61 rows=5561 width=40) (actual time=15.849..16.410 rows=1 loops=1)
Output: id, name
Filter: (osm_roads.id = 1002)
Informix costs: 2925.00
Informix query: SELECT *, rowid FROM osm_roads WHERE (id = 1002)
Total runtime: 17.145 ms
(6 rows)
Datenmodifikation
Mit PostgreSQL® 9.3 unterstützt der Informix FDW auch das Manipulieren (UPDATE), Löschen (DELETE) und Einfügen (INSERT) von Daten in die Foreign Table. Darüber hinaus interagieren Transaktionen, die im PostgreSQL® Client gestartet wurden implizit mit Transaktionen auf dem Foreign Server (unter der Voraussetzung, dass die Informixdatenbank mit Logging angelegt wurde und daher transaktionsfähig ist). Folgendes Beispiel demonstriert diese Fähigkeit:
=# BEGIN; BEGIN *=# INSERT INTO osm_roads(id, name, highway) VALUES(55614, 'Hans-Mustermann-Straße', 'no'); INSERT 0 1 *=# SAVEPOINT A; SAVEPOINT *=# UPDATE osm_roads SET area = 'Nordrhein-Westfalen' WHERE id = 55614; ERROR: value too long for type character varying(10) !=# ROLLBACK TO A; ROLLBACK *=# UPDATE osm_roads SET area = 'NRW' WHERE id = 55614; UPDATE 1 *=# COMMIT; COMMIT =# SELECT * FROM osm_roads WHERE id = 55614; id | name | highway | area -------+------------------------+---------+------ 55614 | Hans-Mustermann-Straße | no | NRW (1 row)
Das Beispiel erzeugt zunächst einen neuen Datensatz nach dem Start einer Transaktion. Anschließend wird ein SAVEPOINT gesetzt, um den aktuellen Zustand dieser Transaktion zu sichern. Im nächsten Schritt wird der neue Datensatz noch modifiziert, da man vergessen hatte, die Lokalität des neuen Datensatzes zu spezifizieren. Da jedoch nur Länderkürzel erlaubt sind, schlägt dies aufgrund der Überlänge des neuen Bezeichners fehl, die Transaktion wird ungültig. Durch den SAVEPOINT wird auf den zuletzt angelegten Sicherungspunkt der Transaktion zurückgerollt, der Informix FDW setzt ebenfalls implizit auf diesen SAVEPOINT auf den Foreign Server zurück. Anschließend kann innerhalb dieser Transaktion der korrekte Ländercode eingetragen werden. Nach dem COMMIT bestätigt der Informix FDW ebenfalls die Transaktion auf dem Foreign Server, der Datensatz ist korrekt eingetragen worden.
Zusammenfassung
Foreign Data Wrapper sind ein sehr leistungsfähiges und flexibles Werkzeug, um PostgreSQL® in heterogenen Datenbanklandschaften zu integrieren. Dabei sind diese Schnittstellen keinesfalls auf reine relationale Datenquellen beschränkt. Mit der Unterstützung von modifizierenden SQL-Abfragen (DML) ermöglicht die FDW-API ferner auch die Integration schreibender Datenquellen in PostgreSQL®-Datenbanken.
Dieser Artikel wurde ursprünglich von Bernd Helmle geschrieben.
In den aktuellen Versionen von PostgreSQL® hat sich ein kritischer Fehler eingeschlichen.
Betroffen sind alle aktuellen Versionen der Hauptzweige 9.0, 9.1, 9.2 und alle Versionen für 9.3. Dies sind im einzelnen
- 9.0.14
- 9.1.10
- 9.2.5
- 9.3.0 und 9.3.1
Der Fehler an sich ist relativ schwer zu diagnostizieren und betrifft ausschließlich Standbyserver, die mit dem Parameter hot_standby=on betrieben werden. Betroffene Standbyserver können folgende Symptome aufweisen:
- Fehlende Zeilen in Tabellen auf dem Standbyserver
- Zeilen sind auf dem Standby noch vorhanden obwohl auf dem Master gelöscht
- Alte Werte tauchen in den Zeilen auf Standbyserver auf, obwohl diese auf dem Master aktualisiert wurden
- Index und Constraint Fehler (teilweise auch als Folgefehler)
Durch sogenannte Hintbits können diese Symptome verdeckt werden, so dass die Fehler erst viel später erkannt werden. Die Fehlerbedingung wird durch (Neu-)Starten des Standbyservers ausgelöst, während des Startens werden fälschlicherweise bereits bestätigte Transaktionen als Uncommitted markiert. Auch müssen sehr viele Schreibaktionen innerhalb einer bestimmten Zeit aufgelaufen sein, um diesen Bug auszulösen. Nutzer der Versionen 9.0.13, 9.1.9 und 9.2.4 sollten die nächste Version überspringen und auf die aktualisierten Versionen 9.0.15, 9.1.11 und 9.2.6 warten. Diese werden in der ersten Dezemberwoche veröffentlicht.
Wurde bereits auf ein betroffenes Release aktualisiert, so sollte für die Standbyserver mit den Versionen aus den 9.0, 9.1 und 9.2 Zweigen unbedingt ein Downgrade in Erwägung gezogen werden. Ein anschließendes neues Aufsetzen des Standby ist angeraten. Alternativ kann auch mit einem bereits aktualisiertem Standby nach erneutem Basebackup und Neuaufsetzen der Betrieb fortgesetzt werden. Voraussetzung ist, dass während der Basissicherung für den Standby und bis zu dessem Start keinerlei Schreibaktivität auf dem Primary stattfindet. Der Fehler wird nur während des Starts des Standby ausgelöst, dies bedeutet jedoch eine Downtime für den Master. Anschließend sollte ein Neustart des Standby bei gleichzeitig hohem Schreibaufkommen auf dem Master unbedingt vermieden werden.
Wer auf Leseabfragen verzichten kann, sollte bis zur Verfügbarkeit einer neuen fehlerbereinigten Version auf jeden Fall auch das Abschalten des Parameters hot_standby in Erwägung ziehen. Dies ist auch für alle Versionen des 9.3 Zweiges angeraten, da hier der Fehler in allen verfügbaren Versionen enthalten ist. Auch hier gilt, dass der Standby komplett ohne Schreibaktivität auf dem Master neu aufgebaut werden sollte, um Korruption vorzubeugen.
Nutzer, die direkt aus den Quelltext ihre Systeme aufbauen, können den Patch direkt aus dem git Master in ihre Buildumgebung integrieren. Weiterführende Informationen findet sich auch auf einer eigenen Seite im PostgresQL Wiki.
Sollten Sie unsere Unterstüzung benötigen, dann hilft Ihnen unser Open Source Support Center gerne weiter.
Das Standardtool zur Überwachung von PostgreSQL®-Datenbanken ist check_postgres. Die jetzt veröffentlichte und mit Hilfe von credativ entwickelte Version 2.21.0 unterstützt nun auch PostgreSQL® 9.3. Auf apt.postgresql.org ist die neue Version bereits als Paket für Debian und Ubuntu verfügbar.
check_postgres besteht aus fast 60 einzelnen Tests mit eigenen Namen, z.B. check_postgres_connection. Da die meisten dieser Tests nur für spezielle Setups sinnvoll sind, sollte man sich zunächst auf einige Basistests beschränken.
Wichtige Checks
- check_postgres_archive_ready: Wenn WAL-Archiving aktiviert ist: Die Zahl der noch nicht archivierten xlog-Files sollte in der Regel 0 sein.
- check_postgres_backends: Zahl der Verbindungen. Das Charmante an diesem Check ist, dass er sich über max_connections automatisch einstellt. Ggf. ist 90% aber zu nah am kritischen Wert dran, so dass man in der Praxis evtl. früher gewarnt werden möchte.
- check_postgres_connection: Einfacher Verbindungs-Test. Leider ohne Möglichkeit bei langsamem Verbindungsaufbau zu warnen. (Die Zeit wird aber als „performance data“ angezeigt.)
- check_postgres_hot_standby_delay: Wenn (Streaming-)Replikation benutzt wird: Verzögerung des Slave-Servers. Das Delay wird leider in Transaktionen gemessen, was schwierig einzustellen ist.
- check_postgres_locks: Die Zahl der normalen Locks hängt stark von der Datenbank ab, aber eine übermäßige Zahl sollte eine Warnung ergeben. Sinnvoll erscheint, den Test überall auszurollen, und bei einzelnen Datenbanken zu ändern/deaktivieren, bei denen es falsche Alarme gibt.
- check_postgres_txn_idle: Prüft auf langlaufende „idle“-Transaktionen. Lang laufende Transaktionen, die nichts tun, sind meistens ein Anwendungsfehler oder ein Bedienfehler. Wenn dies über längere Zeit vorliegt, kann Vacuum nicht richtig arbeiten, da die Transaktion die alten Tupel noch sehen kann. Eine Einstellung der Größenordnung zwischen warning=1h/critical=4h bis warning=4h critical=12h erscheint sinnvoll.
- check_postgres_wal_files: Prüft die Zahl WAL-Dateien im pg_xlog-Verzeichnis. Dieser Check prüft etwas ähnliches wie archive_ready; in Hochlast-Situationen kann es allerdings auch ohne WAL-Archiving vorkommen, dass hier viele Files in pg_xlog/ anfallen. Wenn es deutlich mehr sind als 3*checkpoint_segments sollte man die Ursache prüfen. (Der Check konfiguriert sich leider nicht automatisch über diese Einstellung.)
Nützliche Checks
Diese Checks sind nützlich, aber nicht immer anwendbar, oder benötigen spezielle Konfiguration pro Datenbank:
- check_postgres_autovac_freeze: Prüft wie nah Datenbanken an autovacuum_freeze_max_age sind. Normalerweise passiert ein „Freeze“ automatisch, sobald die Datenbank sich autovacuum_freeze_max_age nähert. Falls Transaktionen sehr lange offen sind (mehrere 100 Millionen andere Transaktionen), kann das problematisch werden. In der Praxis tritt das Problem wenn überhaupt nur bei sehr aktiven Datenbanken auf, der Check ist aber sehr leicht zu installieren und benötigt kein Tuning.
- check_postgres_bloat: Tabellen- und Index-Bloat. Vacuum ist meist das größte Thema für den PostgreSQL®-Administrator. Dieser Check überwacht, ob Tabellen größer sind, als sie von der Zahl der Tupel her sein sollten. Die dafür angestellte Berechnung ist aber nur eine sehr grobe Schätzung, und auch die Definition, welcher Overhead (Bloat) für eine gegebene Tabelle noch OK ist, hängt stark von der Benutzung der Tabelle ab. Der Check ist außerdem nicht einfach zu konfigurieren. Auf keinen Fall sollte man sich durch Warnungen verunsichern lassen, sondern diesen Check nur als Hinweis nehmen, ggf. genauer hin zu schauen.
- check_postgres_custom_query: Kein wirklicher Check, aber eine einfache Möglichkeit, eigene SQL-Queries in Warnungen umzusetzen.
- check_postgres_database_size: Prüft auf zu große Datenbanken. Nur sinnvoll, wenn man eine obere Grenze für die DB-Größe hat. Ggf. kann man das am Anfang einstellen, um bei DB-Wachstum benachrichtigt zu werden.
- check_postgres_disabled_triggers: Ggf. sinnvoll, um Trigger zu finden, die bei Wartungsarbeiten abgeschaltet und vergessen wurden.
- check_postgres_disk_space: Alternative zum direkten Check mit anderen Nagios-Plugins.
- check_postgres_hitratio: Dieser Check könnte einen Hinweis geben, dass der DB-Server vielleicht zu wenig RAM (shared_buffers) hat. Je nach Workload kann das aber auch völlig normal sein. Schwierig ohne genauere Kenntnis der Datenbank einzustellen.
- check_postgres_last_analyze: Zeit seit dem ältesten Analyze.
- check_postgres_last_autoanalyze: Zeit seit dem ältesten Autoanalyze.
- check_postgres_last_autovacuum: Zeit seit dem ältesten Autovacuum.
- check_postgres_last_vacuum: Zeit seit dem ältesten Vacuum. Ähnlich wie der Bloat-Checks sind diese Check schwierig einzustellen, Tabellen an denen keine Änderungen passieren müssen nicht jedesmal neu von Analyze oder Vacuum besucht werden. Als Anfang könnte man die Schwellwerte sehr hoch stellen (3 Monate?). Wenn sich in der Praxis herausstellt, dass man hier überwiegend nur falsche Alarme erhält, sollte man den Check einfach weglassen.
- check_postgres_prepared_txns: Offene Prepared Transactions (nicht zu verwechseln mit Prepared Statements) sind ein großes Problem, da sie auch über Server-Neustarts liegen bleiben, und dann Vacuum verhindern und allgemein mit laufenden Transaktionen kollidieren können. Im schlimmsten Fall läuft man in eine Datenbank, die nicht „gefreezt“ werden kann (siehe autovac_freeze). Eigentlich ein wichtiger Check, aber das Feature ist per default in der Server-Config deaktiviert.
- check_postgres_query_runtime: Prüft Laufzeit einer angegebenen Query. Analog custom_query eine Möglichkeit, eigene Checks zu bauen.
- check_postgres_query_time: Prüft, ob es akutell lang laufende Queries gibt. Die Default-Einstellungen sollte man deutlich erhöhen, z.B. auf 4h/24h. (Oder man passt es nach Erfahrung im Betrieb an.)
- check_postgres_sequence: Sequenzen haben per Default ein Maximum (bei bigserial allerdings ziemlich groß). Wenn das Ende erreicht wird, kann die Datenbank keine neuen Werte mehr bekommen.
- check_postgres_txn_time: Prüft, ob es akutell lang laufende Transaktionen gibt. Analog query_time. (Vermutlich ist es nicht sinnvoll, beide Checks zu benutzen.)
- check_postgres_txn_wraparound: Prüft wie nah Datenbanken am Transaktions-ID-Wraparound sind. Analog autovac_freeze prüft dieser Check, wie nah an der maximalen Transaktionszahl die Datenbank ist, bevor „vacuum freeze“ spätestens aufgerufen werden muss (normal passiert das automatisch durch Autovacuum). Beide Checks prüfen das gleiche, autovac_freeze wird viel früher anspringen, das eigentliche Problem wird dann durch txn_wraparound geprüft.
Häufig gab es den Wunsch, auf Debian- und Ubuntu-Systemen eine aktuellere (oder ältere) PostgreSQL®-Version einsetzen zu können, als mit der benutzen Debian- oder Ubuntu-Distribution mitgeliefert wird. Dieses Problem wurde mit Unterstützung der credativ GmbH, gemeinsam von den Debian- und PostgreSQL®-Entwicklern gelöst, indem Ende 2012 apt.postgresql.org ins Leben gerufen wurde. Dieses Apt-Repository bietet PostgreSQL®-Pakete für die aktuell unterstützten Versionen an. Momentan sind dies PostgreSQL® 8.4, 9.0, 9.1, 9.2 und seit letzter Woche auch 9.3, jeweils für Debian Wheezy (7.0), Squeeze (6.0) und Ubuntu Precise (12.04) und Lucid (10.04) für amd64 (64-bit) und i386 (32-bit).
In diesen Pakten ist der PostgreSQL®-Server enthalten, sowie der Client psql, und mit postgresql-contrib eine Sammlung von Zusatzmodulen („Extensions“), die mit dem PostgreSQL®-Source ausgeliefert werden.
Das Repository geht über diese Auswahl hinaus und bietet außerdem vorkompilierte Binärpakete (.deb) und Extensions für die verschiedenen PostgreSQL®-Versionen. Seit dem 9.3-Release arbeiten wir mit anderen in der Community zusammen daran, diese Extensions auch für 9.3 als Pakete zu erstellen. Bisher sind verfügbar:
- postgresql-9.3-ip4r – IPv4 and IPv6 types for PostgreSQL® 9.3
- postgresql-9.3-pgmp – arbitrary precision integers and rationals for PostgreSQL® 9.3
- postgresql-9.3-pgpool2 – connection pool server and replication proxy for PostgreSQL® – modules
- postgresql-9.3-plproxy – database partitioning system for PostgreSQL® 9.3
- postgresql-9.3-plsh – PL/sh procedural language for PostgreSQL® 9.3
- postgresql-9.3-plv8 – Procedural language interface between PostgreSQL® and JavaScript
- postgresql-9.3-slony1-2 – replication system for PostgreSQL®: PostgreSQL® 9.3 server plug-in
- postgresql-9.3-pgmemcache – PostgreSQL® interface to memcached
- postgresql-9.3-postgis-2.1 – Geographic objects support for PostgreSQL® 9.3
Erwähnenswert ist hier insbesondere, dass es bislang nur Pakete für PostGIS 1.5 gab, und jetzt auch PostGIS 2-Pakete zur Verfügung stehen, die ebenfalls in Zusammenarbeit in der Community erstellt wurden.
Jede Anwendung oder Anwender kommt direkt oder indirekt mit ihnen in Berührung: Prepared Statements, oder auf gut Deutsch, Vorbereitete Abfragen. Hierbei handelt es sich einfach erklärt um parametrisierte Abfragen, die einfach wiederverwendet werden können. Ziel ist es, die Analyse und Planerstellung für die späteren Ausführungen der Abfrage nur einmal durchzuführen und den dabei entstehenden Abfrageplan einfach wieder zu verwenden. In PostgreSQL® kommen Prepared Statements in vielfältiger Weise zum Zuge: Per SQL mittels PREPARE und EXECUTE Kommandos oder auf Protokollebene, indem der Datenbanktreiber wie JDBC oder DBD:Pg hierfür per API-Aufrufe mit bspw. execute() diese implizit verwenden.
Fast jede PostgreSQL®-Anwendung nutzt heutzutage daher Prepared Statements. Bis PostgreSQL® 9.1 hatte diese Funktionalität jedoch eine Schwachstelle. Wurde eine Abfrage vorbereitet, so erzeugte der PostgreSQL® Optimizer stets einen sogenannten generischen Plan. Ein Plan ist eine Art Arbeitsanweisung, wie die Abfrage innerhalb der Datenbank abgewickelt werden soll. Mittels PREPARE wird zum Beispiel zur Laufzeit bis PostgreSQL® 9.1 ein generischer Abfrageplan für alle weiteren Ausführungen dieses Prepared Statements festgelegt:
PREPARE ps_get_customerid(text) AS SELECT customerid FROM customers WHERE username LIKE $1;
Dies erzeugt ein Prepared Statement mit dem Bezeichner ps_get_customer_id, das entsprechend mit EXECUTE wiederverwendet werden kann:
EXECUTE ps_get_customerid('user26');Die zugrundeliegende Abfrage nutzt den LIKE Operator, um auch eine Prefixsuche zu ermöglichen:
EXECUTE ps_get_customerid('user26%');Beide Abfragen haben jedoch denselben generischen Abfrageplan:
EXPLAIN EXECUTE ps_get_customerid('user26');
QUERY PLAN
-------------------------------------------------------------
Seq Scan on customers (cost=0.00..738.00 rows=100 width=4)
Filter: ((username)::text ~~ $1)
(2 rows)
EXPLAIN EXECUTE ps_get_customerid('user26%');
QUERY PLAN
-------------------------------------------------------------
Seq Scan on customers (cost=0.00..738.00 rows=100 width=4)
Filter: ((username)::text ~~ $1)
(2 rows)Beide Abfragen könnten jedoch auch einen Index verwenden, denn die customers Tabelle definiert bereits einen Index mit text_pattern_ops Operatorklasse über die username Spalte. Dies ermöglicht die Indexbenutzung auch für LIKE-Operatoren, die das Patternmatching am Ende des Suchbegriffes verwenden. Die verwendete Indexdefinition sei hier der vollständighalber ebenfalls genannt:
CREATE INDEX ON customers (username text_pattern_ops);
Die Abfrage direkt ohne PREPARE auszuführen zeigt das Dilemma:
EXPLAIN SELECT * FROM customers WHERE username LIKE 'user26%';
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on customers (cost=6.30..382.35 rows=202 width=268)
Filter: ((username)::text ~~ 'user26%'::text)
-> Bitmap Index Scan on customers_username_idx (cost=0.00..6.25 rows=200 width=0)
Index Cond: (((username)::text ~>=~ 'user26'::text) AND ((username)::text ~<~ 'user27'::text))
(4 rows)In PostgreSQL® 9.1 kann dieser Index in Prepared Statements jedoch nicht verwendet werden. Der generische Abfrageplan kann eine derartige Parametrisierung nicht berücksichtigen. Ab PostgreSQL® 9.2 jedoch versucht der Optimizer einen spezifischen Abfrageplan für jeden möglichen Zugriffspfad zu erzeugen. Die Tiefe ist jedoch begrenzt, maximal fünf Pläne werden berücksichtigt. Diese Pläne nennen sich Custom Plans und können auch parametrisierte Zugriffspade berücksichtigen. Wiederholt man das Beispiel von oben ergibt sich in PostgreSQL® 9.3 dann folgendes Bild:
EXPLAIN SELECT * FROM customers WHERE username LIKE 'user26%';
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on customers (cost=6.30..382.35 rows=202 width=268)
Filter: ((username)::text ~~ 'user26%'::text)
-> Bitmap Index Scan on customers_username_idx (cost=0.00..6.25 rows=200 width=0)
Index Cond: (((username)::text ~>=~ 'user26'::text) AND ((username)::text ~<~ 'user27'::text))
(4 rows)
EXPLAIN EXECUTE ps_get_customerid('user26%');
QUERY PLAN
--------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on customers (cost=6.30..382.35 rows=202 width=4)
Filter: ((username)::text ~~ 'user26%'::text)
-> Bitmap Index Scan on customers_username_idx (cost=0.00..6.25 rows=200 width=0)
Index Cond: (((username)::text ~>=~ 'user26'::text) AND ((username)::text ~<~ 'user27'::text))
(4 rows)Der Optimizer wählt nun denselben Ausführungsplan für beide Abfragen, analog zur direkt ausgeführten Abfrage.
Besonders interessant ist dies für alle implizit erzeugten Prepared Statements. Diese spielen eine besondere Rolle in PL/pgSQL, da hier jede Abfrage implizit ein Prepared Statement ist. Der Artikel zur Serie CREATE SEQUENCE test_id_seq; CREATE TABLE test AS SELECT nextval('test_id_seq'::regclass), t.datum FROM generate_series('2008-01-01'::timestamptz, '2013-12-31'::timestamptz, interval '1 hour') AS t(datum); CREATE INDEX ON test(datum); CREATE OR REPLACE FUNCTION get_test_datum_ids(p_datum timestamp) RETURNS SETOF integer STABLE LANGUAGE plpgsql AS $$ DECLARE v_id int; BEGIN FOR v_id IN SELECT * FROM test WHERE datum < p_datum LOOP RETURN NEXT v_id; END LOOP; RETURN; END; $$;
Analog zum Artikel wird anschließend die Analyse mittels auto_explain wiederholt:
LOAD 'auto_explain';
SET auto_explain.log_min_duration TO '0ms';
SET auto_explain.log_nested_statements TO 'on';
SELECT get_test_datum_ids('01.02.2008'::timestamp);Ist auto_explain korrekt konfiguriert, findet man den Abfrageplan für den SELECT innerhalb der FOR-Schleife der Prozedur im Logfile der PostgreSQL®-Instanz:
Query Text: SELECT * FROM test WHERE datum < p_datum Index Scan using test_datum_idx on test (cost=0.00..33.89 rows=779 width=16) Index Cond: (datum < '2008-02-01 00:00:00'::timestamp without time zone)
Es zeigt sich, dass der Optimizer nun tatsächlich einen Custom Plan auf Basis eines Indexscan für diesen Parameter wählt. In PostgreSQL® 9.1 wäre dies ein generischer Plan, der in diesem Beispiel einfach wieder einen sequentiellen Scan (SeqScan) der Tabellen zur Folge hätte (sieher hierzu auch das Listing im bereits genannten vorhergehenden Blogartikel dieser Serie). Dies vereinfacht die Entwicklung solcher Prozeduren nun erheblich, da auf dynamische Abfragen mittels EXECUTE in PL/pgSQL verzichtet werden kann.