Mit der kommenden Version 13 von PostgreSQL® werden B-tree Indexe in der Lage sein, mehrfach identisch vorkommende Spaltenwerte physikalisch kompakter abzuspeichern. Bereits mit Version 12 wurde eine Optimierung eingeführt, die B-tree Indexe ein effizienteres Speichern von wiederholt vorkommenden Spaltenwerten gestattet. Hierzu werden diese Spalten in derselben Reihenfolge auch im Index abgelegt, wie diese auch physikalisch im sogenannten Heap, also der physischen Repräsentation der Tabelle, vorkommen. Dies vereinfacht die Verwaltung dieser Indexeinträge und kann auch bereits mit dieser Maßnahme das Wachstum eines Indexes positiv beeinflussen.
In Version 13 werden nun effektiv wiederholt vorkommende Spaltenwerte zusammengefasst im B-tree Index gespeichert, Deduplication genannt. Eine sogenannte Posting List verwaltet dabei, als alternative Repräsentation eines Index Tupel die physischen Positionen an welcher Stelle in der Tabelle der jeweilige Spaltenwert zu finden ist. Diese Repräsentation ist deutlich kompakter als die Spaltenwerte jeweils für sich zu speichern. Ferner ermöglicht es auch das schnellere Auffinden von entsprechenden Spaltenwerten und VACUUM kann solche Indexe auch effizienter warten.
In schreibenden Workloads, die wenige oder gar keine mehrfach identischen Spaltenwerte enthalten, können unter Umständen kleinere Auswirkungen auf die Performance beobachtet werden. Die Deduplication Funktionalität kann beim Erzeugen eines Indexes mit dem Indexattribut deduplication_items abgeschaltet werden. In der aktuellen Beta 2 von PostgreSQL® 13 ist Deduplication standardmässig aktiviert, was sich jedoch bis zum finalen Release noch ändern kann. Die folgende Syntax schaltet das Feature explizit beim Anlegen eines Index aus:
CREATE INDEX ON table (spalte) WITH(deduplicate_items=off);
Üblicherweise jedoch speichern Anwendungen in der Regel Spaltenwerte pro Spalte häufiger mehrfach ab. Ausnahme sind UNIQUE Constraints oder Primary Keys, aber selbst bei diesen kann Deduplication Vorteile bieten. Kommen mehrere Versionen einer Zeile mit dem spezifischen eindeutigen Spaltenwert vor, kann Deduplication unnötigen Bloat im Index ebenfalls verhindern.
Beispiel von Deduplication
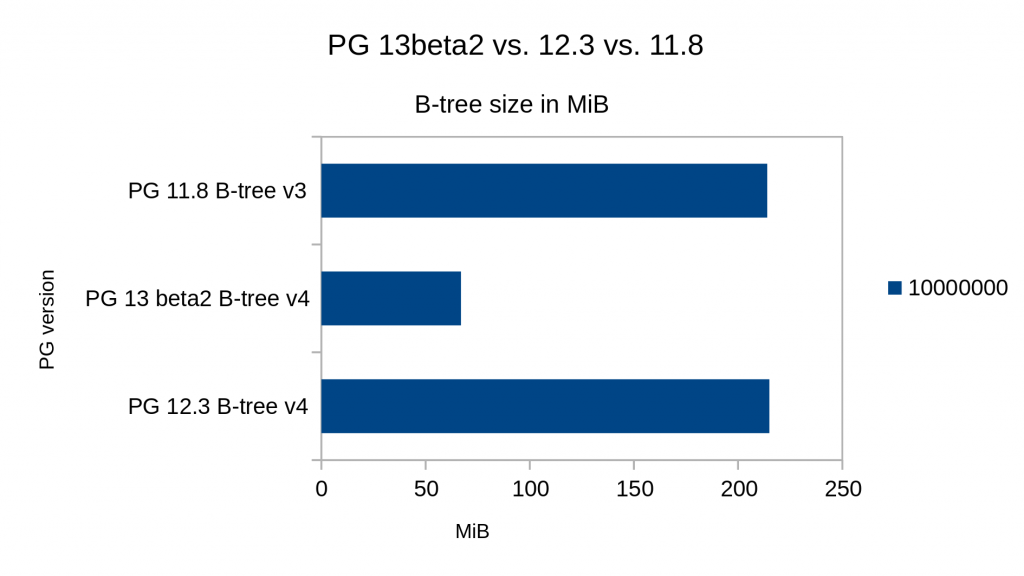
Das Ergebnis der kompakteren Indexstruktur lässt sich mit nachfolgendem Beispiel illustrieren. Die Query in diesem Beispiel erzeugt eine Datenmenge aus 10.000.000 numerischen Werten, die zufällig per random() auf 1000 unterschiedliche Werte begrenzt wird. Dadurch ist die jeweilige Größe der mehrfach vorkommenden Spaltenwerte ungleich verteilt.
INSERT INTO unique_test SELECT floor(generate_series(1, 10000000) % (random() * 1000)::numeric);
Vergleicht man in PostgreSQL® 11.8, 12.3 und 13beta2 nun die Indexgrößen, ergibt sich folgendes Bild:
 pg_upgrade, um eine bestehende PostgreSQL® Instanz von beispielsweise PostgreSQL® 12 auf 13 zu aktualisieren, werden alle physische Objekte in den neuen Cluster übernommen. Da Deduplication in PostgreSQL® auf jeden Fall eine neue Indexstruktur verwendet, können bestehende Indexe aus dem alten Cluster daher nicht ohne weiteres die Deduplication Funktionalität verwenden und müssen neu angelegt werden. Dies kann beispielsweise mit dem PostgreSQL® Kommando REINDEX oder dem äquivalenten Kommandozeilentool reindexdb erreicht werden. Dies gilt für Upgrades von allen älteren Major-Releases. Auch für Migrationen auf PostgreSQL® 12 müssen B-tree Indexe, die von den dort angesprochenen Optimierungen profitieren möchten, neu angelegt werden. In PostgreSQL® 13 hilft dabei auch die neue Option –jobs von reindexdb diesen Prozess zu beschleunigen, indem Indexe parallel mit der angebenen Anzahl an Prozessen aufgebaut werden können.
pg_upgrade, um eine bestehende PostgreSQL® Instanz von beispielsweise PostgreSQL® 12 auf 13 zu aktualisieren, werden alle physische Objekte in den neuen Cluster übernommen. Da Deduplication in PostgreSQL® auf jeden Fall eine neue Indexstruktur verwendet, können bestehende Indexe aus dem alten Cluster daher nicht ohne weiteres die Deduplication Funktionalität verwenden und müssen neu angelegt werden. Dies kann beispielsweise mit dem PostgreSQL® Kommando REINDEX oder dem äquivalenten Kommandozeilentool reindexdb erreicht werden. Dies gilt für Upgrades von allen älteren Major-Releases. Auch für Migrationen auf PostgreSQL® 12 müssen B-tree Indexe, die von den dort angesprochenen Optimierungen profitieren möchten, neu angelegt werden. In PostgreSQL® 13 hilft dabei auch die neue Option –jobs von reindexdb diesen Prozess zu beschleunigen, indem Indexe parallel mit der angebenen Anzahl an Prozessen aufgebaut werden können.Verwendung bestimmer Datentypen
Der numerische Datentyp numeric kann nicht dedupliziert werden, da der Skalierungsfaktor eines jeden Spaltenwertes erhalten bleiben muss. B-tree Indexe auf Spalten dieses Typs werden daher automatisch nicht dedupliziert. Dasselbe gilt im Wesentlichen für den Datentyp jsonb. Da dieser intern numeric verwendet unterliegt jsonb denselben Einschränkungen. Bei dem Datentyp float4 gibt es unterschiedliche Repräsentationen des Wertes 0. Wie bei numeric mit dem entsprechenden scale factor muss bei float4 die jeweils unterschiedliche Repräsentation erhalten bleiben, was die Verwendung von Deduplizierung ausschließt. Spalten vom Typ text die eine Sortierreihenfolge verwenden die nicht-deterministisch ist können ebenfalls nicht dedupliziert werden.
Auch sogenannte Composite, also zusammengesetzte Datentypen, Arrays sowie Range Type verhindern die Nutzung der Funktion, allerdings hat dies keine formalen Gründe, sondern ist aktuell nicht implementiert. B-tree Indexe die mit der INCLUDE Direktive angelegt wurden, können ebenfalls aktuell keine Deduplizierung verwenden.
Bei Fragen rund um den Einsatz von PostgreSQL® 13 stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an! Unser PostgreSQL® Competence Center ist bei Bedarf 24 Stunden am Tag, an 365 Tagen im Jahr für Sie verfügbar.
Das apt.postgresql.org-Repository war ursprünglich mit den beiden Architekturen amd64 und i386 (64- und 32-bit x64) gestartet. Im September 2016 kam dann ppc64el (POWER) hinzu. Über die Zeit gab es immer wieder einzelne Anfragen, ob wir vielleicht auch „arm“ unterstützen würden, womit meistens Raspberry Pi gemeint war. Die sind aber meistens nur 32-bit, und der weit verbreitete „armhf“-Raspbian-Port ist leider nur ARM6, eine ältere Hardware-Version.
Durch HUAWEI Cloud Services wurde der PostgreSQL®-Community jetzt eine „arm64“-Buildmaschine zur Verfügung gestellt, was eine moderne Prozessorarchitektur ist, die auch für PostgreSQL®-Server geeignet ist. Die Maschine wurde dann von uns eingerichtet und das apt.postgresql.org-Repository um diese Architektur erweitert. Bei den unterstützten Distributionen haben wir uns für Debian buster (stable), bullseye (testing) und sid (unstable) sowie Ubuntu bionic (18.04) und focal (20.04) entschieden.
Die Build-Maschine ist sehr performant. Alle Pakete wurden von uns in wenigen Tagen für die neue Architektur gebaut. Spezielle arm-spezifischen Probleme sind dabei nur sehr wenige aufgetreten, was für die Stabilität der Linux-Portierung auf dieser Architektur spricht.
Einem Einsatz von PostgreSQL® auf arm64, auf Debian oder Ubuntu steht damit nichts mehr im Weg.
Parallel haben wir das Repository um den Support für die neue Ubuntu-LTS-Version erweitert: focal (20.04).
Diese Distribution kann damit ab sofort benutzt werden, mit Unterstützung für fünf Jahre bis April 2025.
Über Fragen zum Einsatz von PostgreSQL® auf arm und anderen Architekturen auf Debian, Ubuntu und anderen Betriebssystem freut sich das credativ PostgreSQL® Competence Center natürlich jederzeit. Sprechen Sie uns an!
Dieser Artikel wurde ursprünglich von Christoph Berg geschrieben.
PostgreSQL® ist eine äußerst robuste Datenbank, der auch die meisten unserer Kunden ihre Daten anvertrauen. Kommt es jedoch trotzdem einmal zu Fehlern, so liegen diese meistens am Storage-System, in dem einzelne Bits oder Bytes kippen, oder ganze Blöcke verfälscht werden. Wir zeigen, wie man die Daten aus korrupten Tabellen retten kann.
Der Benutzer ist im Fehlerfall mit Meldungen konfrontiert, die aus dem Storagelayer oder anderen PostgreSQL®-Subsystemen kommen:
postgres=# select * from t;
ERROR: missing chunk number 0 for toast value 192436 in pg_toast_192430
postgres=# select * from a;
ERROR: invalid memory alloc request size 18446744073709551613
Wenn nur einzelne Tupel defekt sind, kann man sich teilweise behelfen, indem man diese einzeln ausliest, z.B. nach id, was in vielen Fällen jedoch auch nicht weiter hilft:
select * from t where id = 1;
Erfolgversprechender ist, die Tupel direkt mit ihrer internen Tupel-ID, in PostgreSQL® ctid genannt, anzusprechen:
select * from t where ctid = '(0,1)';
Um nun alle Tupel auszulesen, nutzen wir eine Schleife in plpgsql:
for page in 0 .. pages-1 loop
for item in 1 .. ??? loop
select * from t where ctid = '('||page||','||item||')' into r;
return next r;
end loop;
end loop;
Wir brauchen noch die Zahl der Seiten in der Tabelle, die bekommen wir von pg_relation_size(), und die Zahl der Tupel auf der Seite, wofür wir die Extension pageinspect bemühen.
select pg_relation_size(relname) / current_setting('block_size')::int into pages;
for page in 0 .. pages-1 loop
for item in select t_ctid from heap_page_items(get_raw_page(relname::text, page)) loop
SELECT * FROM t WHERE ctid=item into r;
if r is not null then
return next r;
end if;
end loop;
end loop;
Jetzt kommt der wichtigste Teil: Der Zugriff auf die beschädigten Tupel oder Seiten verursacht Fehler, die wir mit einem begin..exception..end-Block abfangen müssen. Die Fehlermeldungen geben wir als NOTICE an den Benutzer weiter. Außerdem soll die Funktion nicht nur für eine Tabelle funktionieren, sondern einen Parameter relname erhalten. Die gesamte plpgsql-Funktion sieht dann so aus:
create extension pageinspect;
create or replace function read_table(relname regclass)
returns setof record
as $$
declare
pages int;
page int;
ctid tid;
r record;
sql_state text;
error text;
begin
select pg_relation_size(relname) / current_setting('block_size')::int into pages;
for page in 0 .. pages-1 loop
begin
for ctid in select t_ctid from heap_page_items(get_raw_page(relname::text, page)) loop
begin
execute format('SELECT * FROM %s WHERE ctid=%L', relname, ctid) into r;
if r is not null then
return next r;
end if;
exception -- bad tuple
when others then
get stacked diagnostics sql_state := RETURNED_SQLSTATE;
get stacked diagnostics error := MESSAGE_TEXT;
raise notice 'Skipping ctid %: %: %', ctid, sql_state, error;
end;
end loop;
exception -- bad page
when others then
get stacked diagnostics sql_state := RETURNED_SQLSTATE;
get stacked diagnostics error := MESSAGE_TEXT;
raise notice 'Skipping page %: %: %', page, sql_state, error;
end;
end loop;
end;
$$ language plpgsql;
Da die Funktion „record“ zurück gibt, muss beim Aufruf die Tabellensignatur mitgegeben werden:
postgres =# select * from read_table('t') as t(t text);
NOTICE: Skipping ctid (0,1): XX000: missing chunk number 0 for toast value 192436 in pg_toast_192430
t
───────────────
one
two
three
...
Eine alternative Variante schreibt die gelesenen Daten direkt in eine neue Tabelle:
postgres =# select rescue_table('t');
NOTICE: t: page 0 of 1
NOTICE: Skipping ctid (0,1): XX000: missing chunk number 0 for toast value 192436 in pg_toast_192430
rescue_table
─────────────────────────────────────────────────────────────────────────────────────
rescue_table t into t_rescue: 0 of 1 pages are bad, 1 bad tuples, 100 tuples copied
(1 row)
Die Tabelle t_rescue wurde automatisch angelegt.
create extension pageinspect;
create or replace function rescue_table(relname regclass, savename name default null, "create" boolean default true)
returns text
as $$
declare
pages int;
page int;
ctid tid;
row_count bigint;
good_tuples bigint := 0;
bad_pages bigint := 0;
bad_tuples bigint := 0;
sql_state text;
error text;
begin
if savename is null then
savename := relname || '_rescue';
end if;
if rescue_table.create then
execute format('CREATE TABLE %s (LIKE %s)', savename, relname);
end if;
select pg_relation_size(relname) / current_setting('block_size')::int into pages;
for page in 0 .. pages-1 loop
if page % 10000 = 0 then
raise notice '%: page % of %', relname, page, pages;
end if;
begin
for ctid in select t_ctid from heap_page_items(get_raw_page(relname::text, page)) loop
begin
execute format('INSERT INTO %s SELECT * FROM %s WHERE ctid=%L', savename, relname, ctid);
get diagnostics row_count = ROW_COUNT;
good_tuples := good_tuples + row_count;
exception -- bad tuple
when others then
get stacked diagnostics sql_state := RETURNED_SQLSTATE;
get stacked diagnostics error := MESSAGE_TEXT;
raise notice 'Skipping ctid %: %: %', ctid, sql_state, error;
bad_tuples := bad_tuples + 1;
end;
end loop;
exception -- bad page
when others then
get stacked diagnostics sql_state := RETURNED_SQLSTATE;
get stacked diagnostics error := MESSAGE_TEXT;
raise notice 'Skipping page %: %: %', page, sql_state, error;
bad_pages := bad_pages + 1;
end;
end loop;
error := format('rescue_table %s into %s: %s of %s pages are bad, %s bad tuples, %s tuples copied',
relname, savename, bad_pages, pages, bad_tuples, good_tuples);
raise log '%', error;
return error;
end;
$$ language plpgsql;
Die SQL-Skripte sind auch im git-Repository von pg_dirtyread verfügbar.
Unterstützung
Falls Sie Unterstützung bei der Rettung Ihrer Daten oder dem allgemeinen Einsatz von PostgreSQL® benötigen, steht Ihnen unser PostgreSQL® Competence Center zur Verfügung – Falls gewünscht auch 24 Stunden am Tag, an 365 Tagen im Jahr.
Wir freuen uns auf Ihre Kontaktaufnahme.
Dieser Artikel wurde ursprünglich von Christoph Berg geschrieben.
Der Open Source Summit ist die weltweit größte, allumfassende Open Source Konferenz. Hier werden unter anderem Themen wie aktuelle Infrastruktur-Software, Entwicklungen am Linux-Kernel, aber auch die Arbeit in der Community besprochen. Ein bisher fehlender Bestandteil des Konferenzprogrammes waren Open Source Datenbanken.
Dabei bildet Datenbanksoftware wie PostgreSQL® oder Apache Cassandra eine der wichtigsten Säulen in modernen Open Source Infrastrukturen.
Zusammen mit der Linux Foundation freuen wir uns, ankündigen zu dürfen, dass der diesjährige Open Source Summit North America und Europe jeweils einen eigenen Datenbank-Track haben wird.
Dabei bildet unser Geschäftsführer Dr. Michael Meskes zusammen mit Sunil Kamath (Microsoft) und Divya Bhargov (Pivotal) das Programmkomitee für den neuen Track des Open Source Summit.
In seinem Blog-Beitrag bei der Linux Foundation sagte Dr. Michael Meskes hierzu:
„The open source database track will feature topics specific to databases themselves and their integration to the computing backbone for applications. The track will focus on databases of all kinds, as long as they are open source, and any deployment and integration topics.“
Der vollständige Blogbeitrag kann auf der Seite der Linux Foundation gelesen werden.
Die Linux Foundation und das Programmkomitee freuen sich über alle Einreichungen zum neuen Datenbank-Track. Vorträge können noch bis zum 16. Februar (North America) und 14. Juni (Europe) eingereicht werden.
Der Open Source Summit North America findet in diesem Jahr in Austin, Texas statt. Der Austragungsort des Summit in Europa befindet sich 2020 in Dublin, Irland. Beide Veranstaltungen unterstützt credativ auch in diesem Jahr mit einem Sponsoring.
Dieser Artikel wurde ursprünglich von Philip Haas geschrieben.
Patroni ist eine Cluster-Lösung für PostgreSQL®, die sich gerade im Cloud- und Kubernetes-Umfeld auf Grund seiner Integration mit z.B. Etcd immer größerer Beliebtheit erfreut. Vor einiger Zeit haben wir über die Integration von Patroni in Debian berichtet. Seit kurzem ist auch das eng mit Patroni verzahnte vip-manager Projekt in Debian verfügbar, welches im Folgenden vorgestellt wird.
Patroni verwendet für Leader-Election und Failover einen sogenannten „Distributed Consensus Store“ (DCS). Der momentane Cluster-Leader aktualisiert laufend seinen Leader-Key im DCS. Sobald dieser von Patroni nicht mehr aktualisiert werden kann und obsolet wird, erfolgt eine neue Leader-Election unter den verbleibenden Knoten.
Client-Lösungen für Hochverfügbarkeit
Allerdings muss auch aus Anwendersicht gewährleistet sein, dass die Anwendung mit dem Leader verbunden ist, da sonst keine schreibenden Transaktionen möglich sind. Herkömmliche Hochverfügbarkeits-Lösungen wie Pacemaker verwenden hier virtuelle IPs (VIPs), die im Failover-Fall zum neuen Primary-Knoten geschwenkt werden.
Für Patroni gab es diesen Mechanismus bisher nicht. Üblicherweise wird entweder HAProxy (oder eine ähnliche Lösung) verwendet, welche einen periodischen Health-Check auf die Patroni-API der einzelnen Knoten durchführt und so den aktuellen Leader ermittelt und Client-Anfragen dorthin weiterleitet.
Eine Alternative ist die Verwendung von Client-seitigem Failover, welches seit PostgreSQL® 10 verfügbar ist. Hierbei werden alle Mitglieder des Clusters beim Client konfiguriert. Dieser versucht nach einem Verbindungs-Abbruch reihum die anderen Knoten zu erreichen, bis er erneut einen Primary findet.
vip-manager
Ein komfortabler neuer Ansatz ist vip-manager. Dieser in Go geschriebene Service wird auf allen Cluster-Knoten gestartet und verbindet sich mit dem DCS.
Falls der lokale Knoten den Leader-Key besitzt, startet vip-manager die konfigurierte VIP. Im Fall eines Failovers entfernt vip-manager die VIP vom alten Leader und der entsprechende Service des neuen Leaders startet diese dort. Der Client kann nun für diese VIP konfiguriert werden und wird sich stets mit dem Cluster-Leader verbinden.
Debian-Integration von vip-manager
Für Debian wurde das pg_createconfig_patroni Programm angepasst, so dass es nun auch eine vip-manager Konfiguration erstellen kann:
pg_createconfig_patroni 11 test --vip=10.0.3.2
Den Service starten wir analog zu Patroni für jede Instanz:
systemctl start vip-manager@11-test
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.247 | Leader | running | 1 | |
| 11-test | pg2 | 10.0.3.94 | | running | 1 | 0 |
| 11-test | pg3 | 10.0.3.214 | | running | 1 | 0 |
+---------+--------+------------+--------+---------+----+-----------+
Im Journal von pg1 kann man sehen, dass die VIP konfiguriert wurde:
Dez 09 14:53:38 pg1 vip-manager[9314]: 2019/12/09 14:53:38 IP address 10.0.3.2/24 state is false, desired true
Dez 09 14:53:38 pg1 vip-manager[9314]: 2019/12/09 14:53:38 Configuring address 10.0.3.2/24 on eth0
Dez 09 14:53:38 pg1 vip-manager[9314]: 2019/12/09 14:53:38 IP address 10.0.3.2/24 state is true, desired true
Im Fall von LXC-Containern sieht man dies auch im Output von lxc-ls -f:
NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
pg1 RUNNING 0 - 10.0.3.2, 10.0.3.247 - false
pg2 RUNNING 0 - 10.0.3.94 - false
pg3 RUNNING 0 - 10.0.3.214 - false
Die vip-manager Pakete sind für Debian testing (bullseye) und unstable in den offiziellen Debian-Repositories erhältlich.
Für Debian stable (buster), sowie Ubuntu 19.04 und 19.10 sind Pakete auf dem von credativ gepflegten apt.postgresql.org verfügbar, zusammen mit den aktualisierten Patroni-Paketen mit vip-manager Integration.
Switchover-Verhalten
Im Falle eines geplanten Switchovers wird z.B. pg2 zum neuen Leader:
# patronictl -c /etc/patroni/11-test.yml switchover --master pg1 --candidate pg2 --force
Current cluster topology
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.247 | Leader | running | 1 | |
| 11-test | pg2 | 10.0.3.94 | | running | 1 | 0 |
| 11-test | pg3 | 10.0.3.214 | | running | 1 | 0 |
+---------+--------+------------+--------+---------+----+-----------+
2019-12-09 15:35:32.52642 Successfully switched over to "pg2"
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.247 | | stopped | | unknown |
| 11-test | pg2 | 10.0.3.94 | Leader | running | 1 | |
| 11-test | pg3 | 10.0.3.214 | | running | 1 | 0 |
+---------+--------+------------+--------+---------+----+-----------+
Die VIP wurde nun auf den neuen Leader geschwenkt:
NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
pg1 RUNNING 0 - 10.0.3.247 - false
pg2 RUNNING 0 - 10.0.3.2, 10.0.3.94 - false
pg3 RUNNING 0 - 10.0.3.214 - false
Dies ist auch in den Journals zu sehen, hier vom alten Leader:
Dez 09 15:35:31 pg1 patroni[9222]: 2019-12-09 15:35:31,634 INFO: manual failover: demoting myself
Dez 09 15:35:31 pg1 patroni[9222]: 2019-12-09 15:35:31,854 INFO: Leader key released
Dez 09 15:35:32 pg1 vip-manager[9314]: 2019/12/09 15:35:32 IP address 10.0.3.2/24 state is true, desired false
Dez 09 15:35:32 pg1 vip-manager[9314]: 2019/12/09 15:35:32 Removing address 10.0.3.2/24 on eth0
Dez 09 15:35:32 pg1 vip-manager[9314]: 2019/12/09 15:35:32 IP address 10.0.3.2/24 state is false, desired false
Sowie vom neuen Leader pg2:
Dez 09 15:35:31 pg2 patroni[9229]: 2019-12-09 15:35:31,881 INFO: promoted self to leader by acquiring session lock
Dez 09 15:35:31 pg2 vip-manager[9292]: 2019/12/09 15:35:31 IP address 10.0.3.2/24 state is false, desired true
Dez 09 15:35:31 pg2 vip-manager[9292]: 2019/12/09 15:35:31 Configuring address 10.0.3.2/24 on eth0
Dez 09 15:35:31 pg2 vip-manager[9292]: 2019/12/09 15:35:31 IP address 10.0.3.2/24 state is true, desired true
Dez 09 15:35:32 pg2 patroni[9229]: 2019-12-09 15:35:32,923 INFO: Lock owner: pg2; I am pg2
Wie man sehen kann erfolgt der Schwenk der VIP innerhalb einer Sekunde.
Aktualisiertes Ansible Playbook
Unser Ansible-Playbook für die automatisierte Einrichtung eines Drei-Knoten-Clusters unter Debian wurde ebenfalls aktualisiert und kann nun bei Bedarf eine VIP konfigurieren:
# ansible-playbook -i inventory -e vip=10.0.3.2 patroni.yml
Unterstützung
Falls Sie Unterstützung beim Einsatz von PostgreSQL®, Patroni, vip-manager oder anderer Software für Hochverfügbarkeit benötigen, steht Ihnen unser Open Source Support Center zur Verfügung – Falls gewünscht auch 24 Stunden am Tag, an 365 Tagen im Jahr.
Wir freuen uns auf Ihre Kontaktaufnahme.
Die PostgreSQL® Global Development Group (PGDG) hat Version 12 der populären, freien Datenbank PostgreSQL® freigegeben. Wie unser Artikel für Beta 4 bereits angedeutet hat, sind eine Vielzahl von neuen Features, Verbesserungen und Optimierungen in das Release eingeflossen. Dazu gehören unter anderem:
Optimierte Speicherplatznutzung und Geschwindigkeit bei btree-Indexen
btree-Indexe, der Standardindextyp in PostgreSQL®, hat einige Optimierungen in PostgreSQL® 12 erfahren.
btree Indexe speicherten in der Vergangenheit Doubletten (also mehrfache Einträge mit denselben Schlüsselwerten) in einer unsortierten Reihenfolge. Dies hatte eine suboptimale Nutzung der physischen Repräsentation in betreffenden Indexen zu Folge. Eine Optimierung speichert diese mehrfachen Schlüsselwerte nun in derselben Reihenfolge, wie diese auch physisch in der Tabelle gespeichert sind. Dies verbessert die Speicherplatzausnutzung und die Aufwände für das Verwalten entsprechender Indexe vom Typ btree. Darüber hinaus verwenden Indexe mit mehreren indizierten Spalten eine verbesserte physische Repräsentation, sodass deren Speicherplatznutzung ebenfalls verbessert wird. Um hiervon in PostgreSQL® 12 zu profitieren, müssen diese jedoch, falls per binärem Upgrade mittels pg_upgrade auf die neue Version gewechselt wurde, diese Indexe neu angelegt bzw. reindiziert werden.
Einfügeoperationen in btree-Indexe werden zudem durch verbessertes Locking beschleunigt.
Verbesserungen für pg_checksums
credativ hat eine Erweiterung für pg_checksums beigesteuert, die es ermöglicht Blockprüfsummen in gestoppten PostgreSQL®-Instanzen zu aktivieren oder zu deaktivieren. Vorher konnte dies nur durch ein Neuanlegen der physischen Datenrepräsentation des Clusters per initdb durchgeführt werden.
pg_checksums verfügt nun auch mit dem Parameter --progress über die Möglichkeit, einen Statusverlauf auf der Konsole anzuzeigen. Die entsprechenden Codebeiträge stammen von den Kollegen Michael Banck und Bernd Helmle.
Optimizer Inlining von Common Table Expressions
Bis einschließlich PostgreSQL® 11 war es dem PostgreSQL® Optimizer nicht möglich, Common Table Expressions (auch CTE oder WITH Abfragen genannt) zu optimieren. Wurde ein solcher Ausdruck in einer Abfrage verwendet, so wurde die CTE immer als erstes evaluiert und materialisiert, bevor der Rest der Abfrage abgearbeitet wurde. Dies führte bei komplexeren CTE Ausdrücken zu entsprechend teuren Ausführungsplänen. Folgendes generisches Beispiel illustriert dies anschaulich. Gegeben sei ein Join mit einem CTE Ausdruck, der alle gerade Zahlen aus einer numerischen Spalten filtert:
WITH t_cte AS (SELECT id FROM foo WHERE id % 2 = 0) SELECT COUNT(*) FROM t_cte JOIN bar USING(id);
In PostgreSQL® 11 führt die Verwendung einer CTE immer zu einem CTE Scan, der den CTE Ausdruck als erstes materialisiert:
EXPLAIN (ANALYZE, BUFFERS) WITH t_cte AS (SELECT id FROM foo WHERE id % 2 = 0) SELECT COUNT(*) FROM t_cte JOIN bar USING(id) ;
QUERY PLAN
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Aggregate (cost=2231.12..2231.14 rows=1 width=8) (actual time=48.684..48.684 rows=1 loops=1)
Buffers: shared hit=488
CTE t_cte
-> Seq Scan on foo (cost=0.00..1943.00 rows=500 width=4) (actual time=0.055..17.146 rows=50000 loops=1)
Filter: ((id % 2) = 0)
Rows Removed by Filter: 50000
Buffers: shared hit=443
-> Hash Join (cost=270.00..286.88 rows=500 width=0) (actual time=7.297..47.966 rows=5000 loops=1)
Hash Cond: (t_cte.id = bar.id)
Buffers: shared hit=488
-> CTE Scan on t_cte (cost=0.00..10.00 rows=500 width=4) (actual time=0.063..31.158 rows=50000 loops=1)
Buffers: shared hit=443
-> Hash (cost=145.00..145.00 rows=10000 width=4) (actual time=7.191..7.192 rows=10000 loops=1)
Buckets: 16384 Batches: 1 Memory Usage: 480kB
Buffers: shared hit=45
-> Seq Scan on bar (cost=0.00..145.00 rows=10000 width=4) (actual time=0.029..3.031 rows=10000 loops=1)
Buffers: shared hit=45
Planning Time: 0.832 ms
Execution Time: 50.562 ms
(19 rows)
Dieser Plan materialisiert zunächst die CTE mit einem Sequential Scan mit entsprechendem Filter (id % 2 = 0). Hier wird kein funktionaler Index verwendet, daher ist dieser Scan entsprechend teurer. Danach wird das Ergebnis der CTE per Hash Join mit der entsprechenden Join Bedingung mit der Tabelle bar verknüpft. Mit PostgreSQL® 12 erhält der Optimizer nun die Fähigkeit, diese CTE Ausdrücke ohne vorherige Materialisierung zu inlinen. Der zugrundeliegende, optimierte Plan in PostgreSQL® 12 sieht dann wie folgt aus:
EXPLAIN (ANALYZE, BUFFERS) WITH t_cte AS (SELECT id FROM foo WHERE id % 2 = 0) SELECT COUNT(*) FROM t_cte JOIN bar USING(id) ;
QUERY PLAN
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Aggregate (cost=706.43..706.44 rows=1 width=8) (actual time=9.203..9.203 rows=1 loops=1)
Buffers: shared hit=148
-> Merge Join (cost=0.71..706.30 rows=50 width=0) (actual time=0.099..8.771 rows=5000 loops=1)
Merge Cond: (foo.id = bar.id)
Buffers: shared hit=148
-> Index Only Scan using foo_id_idx on foo (cost=0.29..3550.29 rows=500 width=4) (actual time=0.053..3.490 rows=5001 loops=1)
Filter: ((id % 2) = 0)
Rows Removed by Filter: 5001
Heap Fetches: 10002
Buffers: shared hit=74
-> Index Only Scan using bar_id_idx on bar (cost=0.29..318.29 rows=10000 width=4) (actual time=0.038..3.186 rows=10000 loops=1)
Heap Fetches: 10000
Buffers: shared hit=74
Planning Time: 0.646 ms
Execution Time: 9.268 ms
(15 rows)
Der Vorteil dieser Methode ist, dass das initiale materialisieren des CTE Ausdrucks entfällt. Stattdessen wird die Abfrage direkt mit einem Join ausgeführt.
Dies funktioniert bei allen nicht-rekursiven CTE Ausdrücken ohne Seiteneffekte (beispielsweise CTEs mit Schreibanweisungen) und solchen, die jeweils nur einmal pro Abfrage referenziert sind. Das alte Verhalten des Optimizers kann mit der Anweisung WITH ... AS MATERIALIZED ... forciert werden.
Generated Columns
Neu in PostgreSQL® 12 sind sogenannte Generated Columns, die auf Ausdrücken basierend ein Ergebnis anhand vorhandener Spaltenwerte berechnen. Diese werden mit den entsprechenden Quellwerten im Tupel gespeichert. Der Vorteil ist, dass das Anlegen von Triggern zur nachträglichen Berechnung von Spaltenwerten entfallen kann. Folgendes einfaches Beispiel anhand einer Preistabelle mit Netto und Bruttopreisen illustriert die neue Funktionalität:
CREATE TABLE preise(netto numeric,
brutto numeric GENERATED ALWAYS AS (netto * 1.19) STORED);
INSERT INTO preise VALUES(17.30);
INSERT INTO preise VALUES(225);
INSERT INTO preise VALUES(247);
INSERT INTO preise VALUES(19.15);
SELECT * FROM preise;
netto │ brutto
───────┼─────────
17.30 │ 20.5870
225 │ 267.75
247 │ 293.93
19.15 │ 22.7885
(4 rows)
Die Spalte brutto wird direkt aus dem Nettopreis berechnet. Das Schlüsselwort STORED ist Pflicht. Selbstverständlich können auf Generated Columns auch Indexe erzeugt werden, allerdings können sie nicht Teil eines Primärschlüssels sein. Ferner muss der SQL Ausdruck eindeutig sein, d.h. auch bei gleicher Eingabemenge das dasselbe Ergebnis liefern. Spalten die als Generated Columns deklariert sind, können nicht explizit in INSERT– oder UPDATE-Operationen verwendet werden. Falls eine Spaltenliste unbedingt notwendig ist, kann mit dem Schlüsselwort DEFAULT der entsprechende Wert indirekt referenziert werden.
Wegfall von expliziten OID Spalten
Explizite OID Spalten waren historisch gesehen ein Weg, eindeutige Spaltenwerte zu erzeugen, so dass eine Tabellenzeile Datenbankweit eindeutig identifiziert werden kann. Seit langer Zeit werden diese in PostgreSQL® jedoch nur noch explizit angelegt und deren grundlegende Funktionalität als überholt angesehen. Mit PostgreSQL® wird nun auch die Möglichkeit explizit solche Spalten anzulegen, endgültig abgeschafft. Damit wird es nicht mehr möglich sein, die Direktive WITH OIDS bei Tabellen anzugeben. Systemtabellen, die schon immer per OID Objekte eindeutig referenzieren, geben OID Werte ab sofort ohne explizite Angabe von OID Spalten in der Ergebnismenge zurück. Besonders ältere Software, die sorglos mit Katalogabfragen hantierte, könnte Probleme durch eine doppelte Spaltenausgabe bekommen.
Verschieben der recovery.conf in die postgresql.conf
Bis einschließlich PostgreSQL® 11 konfigurierte man Datenbankrecovery und Streaming Replication Instanzen über eine separate Konfigurationsdatei recovery.conf.
Mit PostgreSQL® 12 wandern nun sämtliche dort getätigte Konfigurationsarbeiten in die postgresql.conf. Die Datei recovery.conf entfällt ab sofort. PostgreSQL® 12 weigert sich zu starten, sobald diese Datei vorhanden ist. Ob Recovery oder ein Streaming Standby gewünscht ist, entscheidet nun entweder eine Datei recovery.signal (für Recovery) oder standby.signal (für Standby Systeme). Letztere hat bei Vorhandensein beider Dateien den Vorrang. Der alte Parameter standby_mode, der dieses Verhalten seither kontrollierte, wurde entfernt.
Für automatische Deployments von hochverfügbaren Systemen bedeutet dies eine große Änderung. Allerdings ist es nun auch möglich, entsprechende Konfigurationsarbeiten fast vollständig per ALTER SYSTEM vorzunehmen, sodass man nur noch eine Konfigurationsdatei pflegen muss.
REINDEX CONCURRENTLY
Mit PostgreSQL® 12 gibt es nun eine Möglichkeit, Indexe mit so geringen Sperren wie möglich neu anzulegen. Dies vereinfacht einer der häufigsten Wartungsaufgaben in sehr schreiblastigen Datenbanken erheblich. Zuvor musste mit einer Kombination aus CREATE INDEX CONCURRENTLY und DROP INDEX CONCURRENTLY gearbeitet werden. Hierbei musste man auch aufpassen, dass Indexnamen entsprechend neu vergeben wurden.
Die Release Notes geben eine noch viel detailliertere Übersicht über alle Neuerungen und vor allem auch Inkompatiblitäten gegenüber den vorangegangenen PostgreSQL® Versionen.
Dieser Artikel wurde ursprünglich von Bernd Helmle geschrieben.
In diesem Beitrag beschäftigen wir uns mit dem hochverfügbaren Betrieb von PostgreSQL® in einer Kubernetes-Umgebung. Ein Thema, dass für viele unserer PostgreSQL® Anwender sicher von besonderem Interesse ist.
Gemeinsam mit unserem Partnerunternehmen MayaData, demonstrieren wir Ihnen nachfolgend die Einsatzmöglichkeiten und Vorteile des äußerst leistungsfähigen Open Source Projektes – OpenEBS
OpenEBS ist ein frei verfügbares Storage Management System, dessen Entwicklung von MayaData unterstützt und begleitet wird.
Wir bedanken uns ganz besonders bei Murat-Karslioglu von MayaData und unserem Kollegen Adrian Vondendriesch für diesen interessanten und hilfreichen Beitrag, den die Kollegen aufgrund der internationalen Zusammenarbeit diesmal natürlich in englischer Sprach verfasst haben.
PostgreSQL® anywhere — via Kubernetes with some help from OpenEBS and credativ engineering
by Murat Karslioglu, OpenEBS and Adrian Vondendriesch, credativ
Introduction
If you are already running Kubernetes on some form of cloud whether on-premises or as a service, you understand the ease-of-use, scalability and monitoring benefits of Kubernetes — and you may well be looking at how to apply those benefits to the operation of your databases.
PostgreSQL® remains a preferred relational database, and although setting up a highly available Postgres cluster from scratch might be challenging at first, we are seeing patterns emerging that allow PostgreSQL® to run as a first class citizen within Kubernetes, improving availability, reducing management time and overhead, and limiting cloud or data center lock-in.
There are many ways to run high availability with PostgreSQL®; for a list, see the PostgreSQL® Documentation. Some common cloud-native Postgres cluster deployment projects include Crunchy Data’s, Sorint.lab’s Stolon and Zalando’s Patroni/Spilo. Thus far we are seeing Zalando’s operator as a preferred solution in part because it seems to be simpler to understand and we’ve seen it operate well.
Some quick background on your authors:
- OpenEBS is a broadly deployed OpenSource storage and storage management project sponsored by MayaData.
- credativ is a leading open source support and engineering company with particular depth in PostgreSQL®.
In this blog, we’d like to briefly cover how using cloud-native or “container attached” storage can help in the deployment and ongoing operations of PostgreSQL® on Kubernetes. This is the first of a series of blogs we are considering — this one focuses more on why users are adopting this pattern and future ones will dive more into the specifics of how they are doing so.
At the end you can see how to use a Storage Class and a preferred operator to deploy PostgreSQL® with OpenEBS underlying
If you are curious about what container attached storage of CAS is you can read more from the Cloud Native Computing Foundation (CNCF) here.
Conceptually you can think of CAS as being the decomposition of previously monolithic storage software into containerized microservices that themselves run on Kubernetes. This gives all the advantages of running Kubernetes that already led you to run Kubernetes — now applied to the storage and data management layer as well. Of special note is that like Kubernetes, OpenEBS runs anywhere so the same advantages below apply whether on on-premises or on any of the many hosted Kubernetes services.
PostgreSQL® plus OpenEBS
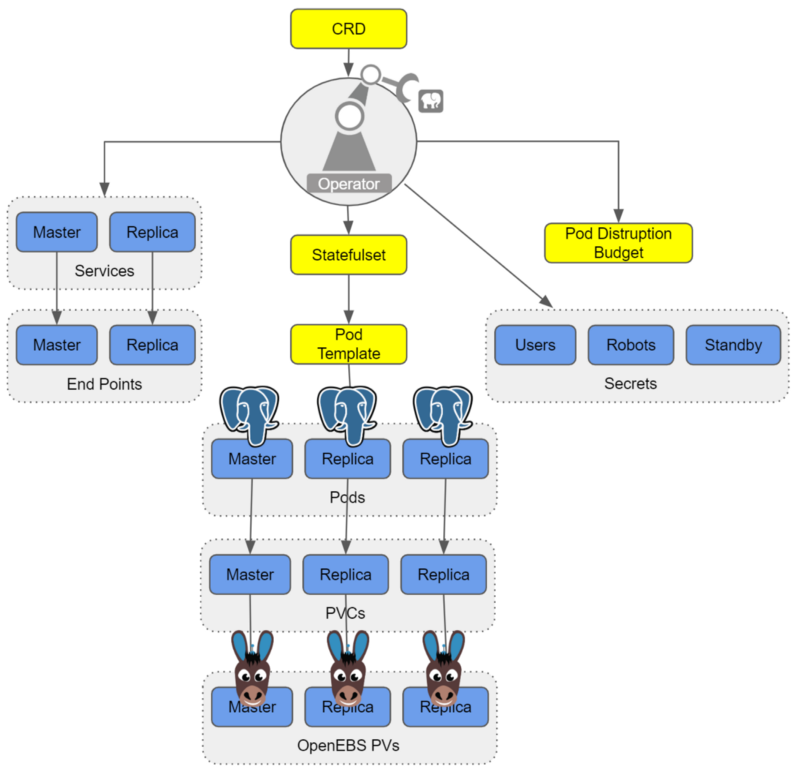
We have seen joint users adopting OpenEBS as a substrate to PostgreSQL® for a variety of reasons. A few that jump out include:
Consistency in underlying disk or cloud volume management:
One of the most annoying things about setting up a system to run PostgreSQL® — even if it is on Kubernetes — is configuring the underlying disks and storage systems as needed. With a solution like OpenEBS, you specify via storage classes how you want the underlying systems configured and OpenEBS with the help of Kubernetes ensures that the system delivers the storage capacity that is needed and that it is configured as you need it. An example of such a storage class is shared below. This automation can remove a source of human error and definitely removes a source of human annoyance.
Thin provisioning and on-demand expansion:
Now that you have turned over to OpenEBS the provisioning and management of the underlying storage hardware and services, you just have to tell it the amount of storage you need for your PostgreSQL® and then everything will work out well, right? Well actually knowing how much data your PostgreSQL® instance or instances will consume is pretty tricky — and arguably somewhat impossible as it is beyond your control.
Here OpenEBS can also help because it supports both thin provisioning and on the fly pool expansion. The thin provisioning allows you to claim more space than you actually can provisioning — this then allows your PostgreSQL® to scale in the usage of space without interruption by allowing for adding more storage to the running system without the need to stop the database.
Thin provisioning though is not a good idea if there is not also on the fly expansion of the underlying capacity for perhaps obvious reasons — as the PostgreSQL® expands you want to make sure it can claim space as needed otherwise at some point you’ll have to interrupt operations and again perform manual tasks. OpenEBS helps here as well — if configured to do so it can expand its underlying pools, whether these are of physical disks, underlying storage systems, or storage services from a cloud. The capacity of the pool can be expanded on demand simply by adding more disks to the cStor pool.
The cStor architecture also supports the resizing of a provisioned volume on the fly and this will be fully automated as of OpenEBS 0.9. Via these enhancements, volumes, as well as underlying pools, will be able to scale automatically on any cloud providing K8s support.
In addition to reducing the risk and hassle of manual operations, the combination of thin provisioning and on-demand scaling can reduce costs because you don’t over-provision capacity to achieve performance for example, which reduces unnecessary cloud service spending and can increase average utilization of usage of your hardware as well.
Disaster recovery and migration:
With a solution like OpenEBS, your storage classes can also include back-up schedules — and these can be easily managed either via Kubectl or via the free to use MayaOnline. Again these storage classes can be applied on a per container basis which is quite a bit of granularity and control by each team running their PostgreSQL®.
Additionally, we are working together to add tighter integration with PostgreSQL® to this per snapshot based workload, per container back-up capability, which is called DMaaS by MayaData and OpenEBS. With this additional integration, an option will be added to the storage classes and to OpenEBS to flush active transactions before taking the snapshot. The additional integration of storage snapshots in conjunction with Write Ahead Log (WAL) archiving will provide additional PITR functionality. DMaaS leverages the open source Velero from Heptio and marries it to the COW based capabilities of the cStor OpenEBS engine to deliver extremely efficient backups and migrations.
With DMaaS backups taken to one location can be recovered from another. This can prove useful for a variety of use cases including the use of relatively ephemeral clusters as a part of a rolling upgrade for example of an environment. Additionally, the same capability can be used to move workloads from one Kubernetes environment to another thereby reducing lock-in.
Snapshots and clones for development and troubleshooting:
DBAs have been using snapshots and clones for a long time to assist in troubleshooting and to enable teams to develop and test against a read-only copy of production data. For example, via OpenEBS you can easily use Kubernetes to invoke a snapshot and then promote that snapshot to a clone and then spawn a container from that clone. You now can do anything you want with that container and the data set contained within it, and of course, destroy it when you are done.
One use case that clones can support is improved reporting. For example, let’s say you do computationally expensive analytical queries and build roll-up queries for monthly reports. It is simple with OpenEBS to clone the underlying OLTP system, allowing you to work on a static copy of your database, thereby removing load from your production DBs and ensuring you have a verifiable source of information for those reports.
Closing the loop with per workload visibility and optimization:
In addition to the benefits of using OpenEBS, there are additional benefits from using MayaOnline for the management of stateful workloads. We may address these in future blogs examining common day 2 operations and optimization of your PostgreSQL® on Kubernetes.
Running Postgres-Operator on OpenEBS
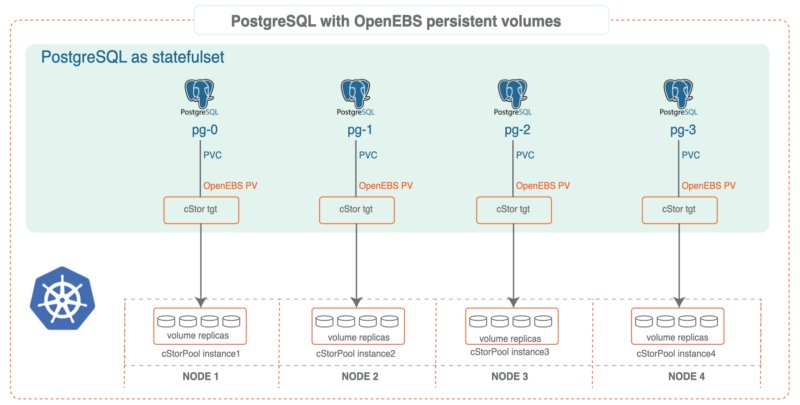
Software Prerequisites
- Postgres-Operator (for cluster deployment)
- Docker installed
- Kubernetes 1.9+ cluster installed
- kubectl installed
- OpenEBS installed
Install OpenEBS
- If OpenEBS is not installed in your K8s cluster, this can be done from here. If OpenEBS is already installed, go to the next step.
- Connect to MayaOnline (Optional): Connecting the Kubernetes cluster to MayaOnline provides good visibility of storage resources. MayaOnline has various support options for enterprise customers.
Configure cStor Pool
- If cStor Pool is not configured in your OpenEBS cluster, this can be done from here. As PostgreSQL® is a StatefulSet application, it requires a single storage replication factor. If you prefer additional redundancy you can always increase the replica count to 3.
During cStor Pool creation, make sure that the maxPools parameter is set to >=3. If a cStor pool is already configured, go to the next step. Sample YAML named openebs-config.yaml for configuring cStor Pool is provided in the Configuration details below.
openebs-config.yaml
#Use the following YAMLs to create a cStor Storage Pool. # and associated storage class. apiVersion: openebs.io/v1alpha1 kind: StoragePoolClaim metadata: name: cstor-disk spec: name: cstor-disk type: disk poolSpec: poolType: striped # NOTE — Appropriate disks need to be fetched using `kubectl get disks` # # `Disk` is a custom resource supported by OpenEBS with `node-disk-manager` # as the disk operator # Replace the following with actual disk CRs from your cluster `kubectl get disks` # Uncomment the below lines after updating the actual disk names. disks: diskList: # Replace the following with actual disk CRs from your cluster from `kubectl get disks` # — disk-184d99015253054c48c4aa3f17d137b1 # — disk-2f6bced7ba9b2be230ca5138fd0b07f1 # — disk-806d3e77dd2e38f188fdaf9c46020bdc # — disk-8b6fb58d0c4e0ff3ed74a5183556424d # — disk-bad1863742ce905e67978d082a721d61 # — disk-d172a48ad8b0fb536b9984609b7ee653 — -
Create Storage Class
- You must configure a StorageClass to provision cStor volume on a cStor pool. In this solution, we are using a StorageClass to consume the cStor Pool which is created using external disks attached on the Nodes. The storage pool is created using the steps provided in the Configure StoragePool section. In this solution, PostgreSQL® is a deployment. Since it requires replication at the storage level the cStor volume replicaCount is 3. Sample YAML named openebs-sc-pg.yaml to consume cStor pool with cStorVolume Replica count as 3 is provided in the configuration details below.
openebs-sc-pg.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-postgres
annotations:
openebs.io/cas-type: cstor
cas.openebs.io/config: |
- name: StoragePoolClaim
value: "cstor-disk"
- name: ReplicaCount
value: "3"
provisioner: openebs.io/provisioner-iscsi
reclaimPolicy: Delete
---Launch and test Postgres Operator
- Clone Zalando’s Postgres Operator.
git clone https://github.com/zalando/postgres-operator.git cd postgres-operator
Use the OpenEBS storage class
- Edit manifest file and add openebs-postgres as the storage class.
nano manifests/minimal-postgres-manifest.yaml
After adding the storage class, it should look like the example below:
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: acid-minimal-cluster
namespace: default
spec:
teamId: "ACID"
volume:
size: 1Gi
storageClass: openebs-postgres
numberOfInstances: 2
users:
# database owner
zalando:
- superuser
- createdb
# role for application foo
foo_user: []
#databases: name->owner
databases:
foo: zalando
postgresql:
version: "10"
parameters:
shared_buffers: "32MB"
max_connections: "10"
log_statement: "all"Start the Operator
- Run the command below to start the operator
kubectl create -f manifests/configmap.yaml # configuration kubectl create -f manifests/operator-service-account-rbac.yaml # identity and permissions kubectl create -f manifests/postgres-operator.yaml # deployment
Create a Postgres cluster on OpenEBS
Optional: The operator can run in a namespace other than default. For example, to use the test namespace, run the following before deploying the operator’s manifests:
kubectl create namespace test kubectl config set-context $(kubectl config current-context) — namespace=test
- Run the command below to deploy from the example manifest:
kubectl create -f manifests/minimal-postgres-manifest.yaml
2. It only takes a few seconds to get the persistent volume (PV) for the pgdata-acid-minimal-cluster-0 up. Check PVs created by the operator using the kubectl get pv command:
$ kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-8852ceef-48fe-11e9–9897–06b524f7f6ea 1Gi RWO Delete Bound default/pgdata-acid-minimal-cluster-0 openebs-postgres 8m44s pvc-bfdf7ebe-48fe-11e9–9897–06b524f7f6ea 1Gi RWO Delete Bound default/pgdata-acid-minimal-cluster-1 openebs-postgres 7m14s
Connect to the Postgres master and test
- If it is not installed previously, install psql client:
sudo apt-get install postgresql-client
2. Run the command below and note the hostname and host port.
kubectl get service — namespace default |grep acid-minimal-cluster
3. Run the commands below to connect to your PostgreSQL® DB and test. Replace the [HostPort] below with the port number from the output of the above command:
export PGHOST=$(kubectl get svc -n default -l application=spilo,spilo-role=master -o jsonpath="{.items[0].spec.clusterIP}")
export PGPORT=[HostPort]
export PGPASSWORD=$(kubectl get secret -n default postgres.acid-minimal-cluster.credentials -o ‘jsonpath={.data.password}’ | base64 -d)
psql -U postgres -c ‘create table foo (id int)’Congrats you now have the Postgres-Operator and your first test database up and running with the help of cloud-native OpenEBS storage.
Partnership and future direction
As this blog indicates, the teams at MayaData / OpenEBS and credativ are increasingly working together to help organizations running PostgreSQL® and other stateful workloads. In future blogs, we’ll provide more hands-on tips.
We are looking for feedback and suggestions on where to take this collaboration. Please provide feedback below or find us on Twitter or on the OpenEBS slack community.
In den letzten Tagen berichteten verschiedene Quellen von einer angeblich schwereren COPY <table> FROM|TO PROGRAM
Die Details hierzu werden in CVE-2019-9193 beschrieben.
Stellungnahme und Erläuterung
Diese Darstellung ist unter sachlicher Betrachtung allerdings keine Sicherheitslücke im eigentlichen Sinn. Vielmehr handelt es sich bei dem betroffenen COPY-Kommando um eine privilegierte Datenbankoperation, die unter allen Umständen entweder Superuserberechtigungen (in der Regel z.B. der Benutzer postgres) oder Mitgliedschaft in der Datenbankrolle pg_execute_server_program erfordert. In dieser Hinsicht enthält der im Link angegebene CVE auch einen Fehler, denn die Rolle pg_read_server_files ist nicht ausreichend, um als unprivilegierter Datenbankbenutzer überhaupt dieses Kommando ausführen zu können.
Gegeben sind in den folgenden Beispielen die Rollen bernd und test, wobei bernd eine Datenbankrolle mit Superuserprivileg ist und test lediglich das LOGIN-Privileg besitzt (also ein normaler Datenbankbenutzer).
bernd@db=# \duS bernd
List of roles
Role name │ Attributes │ Member of
───────────┼────────────────────────────────────────────────────────────┼───────────
bernd │ Superuser, Create role, Create DB, Replication, Bypass RLS │ {}
bernd@db=# \duS test
List of roles
Role name │ Attributes │ Member of
───────────┼────────────┼───────────
test │ │ {}Im Folgenden wird nun versucht, als Benutzer bernd die Ausgabe des Linux-Kommandos echo in eine Tabelle zu schreiben:
bernd@db=# CREATE TABLE test(val text);
CREATE TABLE
bernd@db=# SELECT current_role;
current_role
--------------
bernd
(1 row)
bernd@db=# COPY test FROM PROGRAM '/bin/echo hallo welt';
COPY 1
bernd@db=# SELECT * FROM test;
val
------------
hallo welt
(1 row)Das hat funktioniert, da die Superuserprivilegien des Datenbankrolle bernd dies explizit erlauben. Anders sieht dies mit der unprivilegierten Rolle test aus:
test@db=> SELECT current_role; current_role -------------- test (1 row) test@db=> COPY test FROM PROGRAM 'echo hallo welt'; FEHLER: nur Superuser oder Mitglieder von pg_execute_server_program können COPY mit externen Programmen verwenden HINT: Jeder kann COPY mit STDOUT oder STDIN verwenden. Der Befehl \copy in psql funktioniert auch für jeden.
Das Ausführen von COPY FROM PROGRAM ist der Rolle test nicht gestattet. Man kann es jetzt wie im CVE beschrieben mit der Mitgliedschaft in der Rolle pg_read_server_files versuchen:
bernd@db=# GRANT pg_read_server_files TO test; bernd@db=# SET ROLE test; test@db=> COPY test FROM PROGRAM 'echo hallo welt'; FEHLER: nur Superuser oder Mitglieder von pg_execute_server_program können COPY mit externen Programmen verwenden HINT: Jeder kann COPY mit STDOUT oder STDIN verwenden. Der Befehl \copy in psql funktioniert auch für jeden.
Auch das ist offensichtlich nicht ausreichend. Mit der Mitgliedschaft pg_execute_server_program kommt man dann jedoch an das Ziel:
bernd@db=# GRANT pg_execute_server_program TO test;
bernd@db=# SET ROLE test;
test@db=> COPY test FROM PROGRAM 'echo hallo welt';
test@db=> SELECT * FROM test;
val
────────────
hallo welt
hallo welt
(2 rows)Normale Datenbankrollen mit entsprechend fehlenden Berechtigungen sind folglich nicht in der Lage, dieses Kommando auszuführen. Dies ist das Standardverhalten und benötigt keine entsprechenden Änderungen an der Datenbankkonfiguration. Nur Superuser der PostgreSQL®-Instanz besitzen standardmäßig die Berechtigung für das erfolgreiche Ausführen von COPY TO|FROM PROGRAM. Dieser Sachverhalt ist auch entsprechend in der PostgreSQL® Dokumentation beschrieben.
Das mit COPY TO|FROM angegebene Executable wird immer im Kontext des Betriebssystem-Benutzers ausgeführt, unter dem die jeweilige PostgreSQL®-Instanz läuft (in der Regel eigentlich immer postgres). D.h. die Ausführung des Executable unterliegt immer dem Berechtigungskontexts dieses Benutzers. Dieser ist in der Regel eher eingeschränkt, da PostgreSQL® bspw. als root nicht gestartet werden kann. Das heißt, beliebige Zugriffe sind somit ausgeschlossen. Folgendes Beispiel versucht nun mit der Rolle test die Datei /etc/shadow mit den Passwörtern des Betriebssystems zu lesen:
test@db=> COPY test FROM PROGRAM 'cat /etc/shadow'; FEHLER: Programm »cat /etc/shadow« fehlgeschlagen DETAIL: Kindprozess hat mit Code 1 beendet
Dies schlägt fehl, denn der angesprochene Berechtigungskontext des Betriebsystem-Benutzers, unter dem die PostgreSQL®-Instanz ausgeführt wird, hat keine Zugriffsberechtigung auf /etc/shadow.
Zusammenfassung
Es ist nicht möglich als Standard-Datenbankrolle ohne entsprechend erteilte Berechtigungen ohne weiteres die angebliche Sicherheitslücke wie im CVE beschrieben auszunutzen. Datenbankrollen müssen entgegen der empfohlenen Praxis entweder über SUPERUSER Privilegien verfügen oder explizit die Berechtigung der Rolle pg_execute_server_program erhalten. Daher ist es wichtig bei PostgreSQL® Installationen beim Anlegen und Verteilen von Berechtigungen entsprechend sorgfältig vorzugehen. Der Blogartikel des Core Committee Mitglieds Magnus Hagander (in englischer Sprache) beinhaltet ebenfalls eine entsprechende Erläuterung zum Sachverhalt und empfiehlt sich zur weiteren Lektüre.
An dieser Stelle soll explizit von der Verwendung von Datenbankrollen mit SUPERUSER Privileg für Anwendungen oder Nutzern abgeraten werden. Superuser verfügen noch über viel weitreichendere Berechtigungen als COPY TO|FROM PROGRAM. Sie können beliebige Shared Libraries laden, beliebige Objekte ändern und beliebige Konfigurationsänderungen vornehmen. Daher ist die Verwendung von derart privilegierten Rollen außerhalb des Administrationskontextes dringenst zu vermeiden.
Patroni ist eine Hochverfügbarkeitslösung für PostgreSQL® mit einem Fokus auf Container-Technologie und Kubernetes. Die bisher vorhandenen Debian-Pakete mussten bislang aufwendig von Hand konfiguriert werden und haben sich nicht in die Distribution integriert. Für das bald erscheinende Debian 10 „Buster“ wurde Patroni nun von credativ in das Debian Standard PostgreSQL®-Framework integriert und erlaubt einen einfachen Aufbau von Patroni-Clustern unter Debian.
Aufgrund der Verwendung eines externen „Distributed Consensus Store“ (DCS) wie Etcd, Consul oder Zookeeper kann Patroni zuverlässig Leader-Election und automatisierte Failover durchführen. Dazu kommen planbare Switchover und eine einfache Änderung der Cluster-weiten Konfiguration. Es bietet außerdem eine REST-Schnittstelle, mit der z.B. via HAProxy ein Load-Balancing aufgebaut werden kann. Auf Grund dieser Vorteile hat Patroni in letzter Zeit das früher häufig verwendete Pacemaker als Open Source Projekt der Wahl für die Herstellung einer PostgreSQL®-Hochverfügbarkeit abgelöst.
Viele unserer Kunden verwenden allerdings PostgreSQL® auf Debian- oder Ubuntu-Systemen. Hier hat sich Patroni bisher nicht gut in das System integriert. So verwendete es nicht das postgresql-common Framework und wird nicht wie übliche Instanzen in pg_lsclusters angezeigt.
Integration in Debian
In Zusammenarbeit mit dem Patroni-Hauptentwickler Alexander Kukushkin von Zalando ist es nun gelungen, das Debian Patroni-Paket weitgehend in das postgresql-common-Framework zu integrieren. Dies geschah sowohl durch Änderungen in Patroni, als auch durch zusätzliche Programme im Debian-Paket. Die aktuelle Version 1.5.5 von Patroni, die alle diese Änderungen enthält, ist nun auch in Debian „Buster“ (testing) verfügbar und kann für den Aufbau von Patroni-Clustern unter Debian verwendet werden.
Zur Verfügung stehen die Pakete auch auf apt.postgresql.org und sind damit auch unter Debian 9 „Stretch“ und Ubuntu 18.04 „Bionic Beaver“ LTS benutzbar. Außerdem kann so jede beliebige PostgreSQL®-Version von 9.4 bis 11 verwendet werden.
Wichtigster Punkt ist hierbei die automatische Erstellung einer geeigneten Patroni-Konfiguration mit dem Befehl pg_createconfig_patroni. Der Aufruf erfolgt analog zu pg_createcluster mit der gewünschten Major-Version und dem Instanz-Namen als Parameter:
pg_createconfig_patroni 11 test
Dieser Aufruf erstellt eine Datei /etc/patroni/11-test.yml, wobei die Konfiguration für das DCS aus der Datei /etc/patroni/dcs.yml verwendet wird, die entsprechend dem lokalen Setup angepasst werden muss. Der Rest der Konfiguration entstammt dem Template /etc/patroni/config.yml.in, welches von sich aus lauffähig ist, vom Nutzer aber auch an die eigenen Bedürfnisse angepasst werden kann. Anschließend kann die Patroni-Instanz analog zu regulären PostgreSQL®-Instanzen via systemd gestartet werden:
systemctl start patroni@11-test
Cluster-Aufbau in wenigen Schritten
Ein einfacher 3-Knoten Patroni-Cluster kann also mit den wenigen folgenden Befehlen erstellt und gestartet werden, wobei die drei Knoten pg1, pg2 und pg3 als Hostnamen angenommen werden, sowie dass es eine lokale Datei dcs.yml für die DCS-Konfiguration gibt:
for i in pg1 pg2 pg3; do ssh $i 'apt -y install postgresql-common'; done
for i in pg1 pg2 pg3; do ssh $i 'sed -i "s/^#create_main_cluster = true/create_main_cluster = false/" /etc/postgresql-common/createcluster.conf'; done
for i in pg1 pg2 pg3; do ssh $i 'apt -y install patroni postgresql'; done
for i in pg1 pg2 pg3; do scp ./dcs.yml $i:/etc/patroni; done
for i in pg1 pg2 pg3; do ssh @$i 'pg_createconfig_patroni 11 test' && systemctl start patroni@11-test'; done
Danach kann man den Status des Patroni-Clusters folgendermaßen ansehen:
ssh pg1 'patronictl -c /etc/patroni/11-patroni.yml list'
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.111 | Leader | running | 1 | |
| 11-test | pg2 | 10.0.3.41 | | stopped | | unknown |
| 11-test | pg3 | 10.0.3.46 | | stopped | | unknown |
+---------+--------+------------+--------+---------+----+-----------+
Man sieht, dass eine Leader Election durchgeführt wurde und pg1 der Primary wurde. Dieser hat seine Instanz mit dem Debian-spezifischen pg_createcluster_patroni Programm erstellt, welches im Hintergrund pg_createcluster aufruft. Darauf klonen sich die anderen beiden Instanzen vom Primary mit dem pg_clonecluster_patroni Programm, welches eine Instanz mit pg_createcluster erstellt und dann einen Standby via pg_basebackup vom Primary erstellt. Danach sind alle Knoten im Status running:
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.111 | Leader | running | 1 | 0 |
| 11-test | pg2 | 10.0.3.41 | | running | 1 | 0 |
| 11-test | pg3 | 10.0.3.46 | | running | 1 | 0 |
+---------+--------+------------+--------+---------+----+-----------+
Die altbekannten Debian postgresql-common Befehle funktionieren ebenfalls:
ssh pg1 'pg_lsclusters'
Ver Cluster Port Status Owner Data directory Log file
11 test 5432 online postgres /var/lib/postgresql/11/test /var/log/postgresql/postgresql-11-test.log
Failover-Verhalten
Wenn der Primary Knoten abrupt abgeschaltet wird, wird sein Leader Token nach einiger Zeit auslaufen und Patroni dann einen Failover mit anschließender erneuter Leader Election durchführen:
+---------+--------+-----------+------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+-----------+------+---------+----+-----------+
| 11-test | pg2 | 10.0.3.41 | | running | 1 | 0 |
| 11-test | pg3 | 10.0.3.46 | | running | 1 | 0 |
+---------+--------+-----------+------+---------+----+-----------+
[...]
+---------+--------+-----------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+-----------+--------+---------+----+-----------+
| 11-test | pg2 | 10.0.3.41 | Leader | running | 2 | 0 |
| 11-test | pg3 | 10.0.3.46 | | running | 1 | 0 |
+---------+--------+-----------+--------+---------+----+-----------+
[...]
+---------+--------+-----------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+-----------+--------+---------+----+-----------+
| 11-test | pg2 | 10.0.3.41 | Leader | running | 2 | 0 |
| 11-test | pg3 | 10.0.3.46 | | running | 2 | 0 |
+---------+--------+-----------+--------+---------+----+-----------+
Sobald der alte Primary erneut gestartet wird, kehrt er als Standby in den Cluster-Verbund zurück:
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.111 | | running | | unknown |
| 11-test | pg2 | 10.0.3.41 | Leader | running | 2 | 0 |
| 11-test | pg3 | 10.0.3.46 | | running | 2 | 0 |
+---------+--------+------------+--------+---------+----+-----------+
[...]
+---------+--------+------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+---------+--------+------------+--------+---------+----+-----------+
| 11-test | pg1 | 10.0.3.111 | | running | 2 | 0 |
| 11-test | pg2 | 10.0.3.41 | Leader | running | 2 | 0 |
| 11-test | pg3 | 10.0.3.46 | | running | 2 | 0 |
+---------+--------+------------+--------+---------+----+-----------+
Falls dies aufgrund von zusätzlichen Transaktionen in seiner alten Zeitleiste nicht möglich ist, wird er neu erstellt. Im Falle von sehr großen Datenmengen kann auch pg_rewind verwendet werden, hierfür muss allerdings ein Passwort für den postgres-Nutzer gesetzt und reguläre Datenbank-Verbindungen (im Gegensatz zu Replikations-Verbindungen) zwischen den Cluster-Knoten erlaubt werden.
Weitere Instanzen erstellen
Es ist ferner möglich weitere Instanzen mit pg_createconfig_patroni zu erstellen, dabei kann man entweder einen PostgreSQL® Port explizit mit der --port-Option angeben oder pg_createconfig_patroni den nächsten freien Port (wie von pg_createcluster bekannt) nehmen lassen:
for i in pg1 pg2 pg3; do ssh $i 'pg_createconfig_patroni 11 test2 && systemctl start patroni@11-test2'; done
ssh pg1 'patronictl -c /etc/patroni/11-test2.yml list'
+----------+--------+-----------------+--------+---------+----+-----------+
| Cluster | Member | Host | Role | State | TL | Lag in MB |
+----------+--------+-----------------+--------+---------+----+-----------+
| 11-test2 | pg1 | 10.0.3.111:5433 | Leader | running | 1 | 0 |
| 11-test2 | pg2 | 10.0.3.41:5433 | | running | 1 | 0 |
| 11-test2 | pg3 | 10.0.3.46:5433 | | running | 1 | 0 |
+----------+--------+-----------------+--------+---------+----+-----------+
Ansible Playbook zum Download
Zur einfachen Erstellung eines 3-Wege Patroni Clusters haben wir auch ein Ansible-Playbook auf Github erstellt. Dieses automatisiert die Installation und Einrichtung von PostgreSQL® und Patroni auf den drei Knoten, sowie eines DCS-Servers auf einem vierten Knoten.
Unterstützung
Falls Sie Unterstützung bei PostgreSQL®, Patroni, PostgreSQL® auf Debian oder anderer Aspekte von Hochverfügbarkeit benötigen, steht Ihnen unser PostgreSQL® Competence Center zur Verfügung – Falls gewünscht auch 24 Stunden am Tag, an 365 Tagen im Jahr.
Wir freuen uns über Ihre Kontaktaufnahme.
Viele Nutzer sind durch Herstellervorgaben, Verordnungen oder Arbeitsanweisungen dazu gezwungen, auf sämtlichen IT-Geräten Virenscanner zu betreiben. Diese Verallgemeinerung kann gerade dann, wenn es nicht um klassische Desktops oder Dateiserver geht, zu Problemen führen.
Nach landläufiger Auslegung des BSI Grundschutz ist dieser gewährleistet, wenn auf allen Systemen ein Virenscanner vorhanden ist und die Signaturen aktuell gehalten werden. Die Einhaltung der beiden Kriterien kann über ein klassisches Monitoring überwacht werden.
Probleme treten jedoch oft dann auf, wenn sogenannte On-Access-Scanner aktiv sind und in die Arbeit mit dem Dateisystem eingreifen. Die PostgreSQL®-Entwickler raten sogar dringend von der Verwendung von Antivirensoftware ab!
Virenscanner
Was sind (On-Access-) Virenscanner und weshalb werden sie benötigt? Große Teile der verwendeten (Endanwender-) Software unterscheidet nicht klar zwischen Code und Daten. So enthält eine reine Textdatei ausschließlich Daten und keinen Programmcode, es besteht keine Notwendigkeit je einen Teil einer Textdatei als Code zu interpretieren und auszuführen. Leider wird diese Trennung nicht flächendeckend praktiziert. So können viele Dateien z.B. Office-Dokumente sowohl Daten als auch Code enthalten. Hierdurch ergibt sich ein Angriffsvektor. Angreifer können Code in Daten verstecken, der dann unbemerkt vom Nutzer ausgeführt wird.
Da das zugrundeliegende Problem aufwendig zu lösen und auch keine positive Tendenz ersichtlich ist, bieten Virenscanner in vielen Bereichen eine Linderung der Symptome. So ist es gängige Praxis und sinnvoll, eingehende Fremddaten und nicht vertrauenswürdige Nutzereingaben zu validieren und zu prüfen. Hierbei werden diese mit einer Blacklist von bekannten Angriffsmustern verglichen und im Falle einer Übereinstimmung entsprechend behandelt.
Auch wenn neue, maßgeschneiderte oder unbekannte Angriffe durch solche Systeme nicht erkannt werden können, kann die Kosten-Nutzen-Rechnung doch an einigen Stellen aufgehen.
Arbeiten mit dem Dateisystem
Möchte eine Anwendung (A) Daten lesen oder schreiben erfolgt die Interaktion mit dem Speichermedium (B) über Systemcalls. Die Anwendung übergibt die zu schreibenden Daten und erhält eine Bestätigung zurück, ob die Daten erfolgreich geschrieben wurden, bzw. im Fehlerfall einen entsprechenden Fehlercode.
Funktionsweise Echtzeitscanner
Ein Echtzeitscanner oder On-Access-Scanner greift nun in diesen Ablauf ein und setzt sich selbst als Man-in-the-Middle zwischen Applikation (A) und Hardware (B). Der Linux-Kernel bietet hierfür seit einiger Zeit die API fanotify. Verschiedene Hersteller verwenden aber oft eigene, nicht standardisierte Verfahren, um in den Datenstrom einzugreifen. Es gibt diverse mögliche Eingriffspunkte – z.B. die Applikationen selbst oder verwendete E/A-Bibliotheken. Auch Eingriffe in das Dateisystem werden verwendet.
Problem Performance
Durch den Eingriff in die E/A-Zugriffe werden diese deutlich aufwendiger! Je nach Eingriffspunkt und verwendeter Scanengine werden Speicherzugriffe um Größenordnungen langsamer. Auf Office-Desktopsystemen oder Applicationservern (stateless) sind auf Grund niedriger IO und weniger Writes oft keine starken Auswirkungen spürbar. Auf schreiblastigen Systemen können diese jedoch gravierend sein. Wenn viele kleine Bereiche beschreiben werden und es nicht nur auf den mittleren Datendurchsatz, sondern um das schnelle Abarbeiten einzelner Schreibvorgänge mit niedrigen Latenzen geht, ist mit großen Einbußen zu rechnen.
Durch ihre speziellen Nutzungsmuster und komplexe Dienstfunktionalität sind Datenbanksysteme besonders betroffen. Hinzu kommt noch, dass beim eigentlichen Scanvorgang auch CPU-Zeit benötigt wird. Je nach eingesetzter Antiviren-Lösung kann es auch hier zu Engpässen kommen.
Problem Datensicherheit
Wenn zum Abfangen der E/A-Anfragen nur die kerneleigenen APIs verwendet werden, erhöht sich bereits die theoretische Fehlerwahrscheinlichkeit, da mehr Code ausgeführt wird und die Vorgänge komplexer werden. In der Praxis verkompliziert sich hierdurch zwar Debugging und Fehlersuche, mit deutlichen Einbußen in der Datensicherheit ist jedoch nicht zu rechnen, korrekte API-Verwendung vorausgesetzt. fanotify ist jedoch derzeit in den verbreiteten Antivirenlösungen nicht der Standard.
Durch die eigene Implementierung von E/A-Hooks bietet sich eine ganze Menge Fehlerpotenzial. So konnten wir bei der Ursachenermittlung eines korrupten Datenbanksystems sehen, dass die Antivirenlösung E/A-Fehler von Hardware und Treibern teils nicht weitergeleitet hat.
Fehlerbeispiel:
- Die Datenbank sendet eine Schreib-Anforderung an das Dateisystems (8k-Block schreiben, Herausschreiben auf Platte)
- write() wird von der Antivirenlösung abgefangen
- Der Virenscanner überprüft die Daten (kein Fund)
- write() wird an das Dateisystem weitergegeben
- Das Dateisystem übermittelt die Daten per Treiber an die Hardware
- Es tritt ein Hardwareproblem auf! Daten können nicht geschrieben werden!
- Der Treiber meldet dem Dateisystem den Fehler
- Das Dateisystem meldet dem Virenscanner den Fehler
- Der Virenscanner “verschluckt” den Fehler und meldet der Datenbank das erfolgreiche Schreiben
- Die Datenbank meldet dem Client die erfolgreiche Durchführung einer Transaktion
So entstand eine schleichender Datenverlust, der erst entdeckt wurde als den Nutzern der angeschlossenen Systeme Fehler in den Bestandsdaten auffielen. Der Virenscanner hat hier durch sein nicht standardkonformes Verhalten eine der Kernfunktionalität des Datenbanksystems sabotiert.
PostgreSQL®
PostgreSQL® praktiziert eine strikte Trennung zwischen Daten und Code. Einträge in Tabellen, auch in Binärblöcken, können designbedingt nicht ausgeführt werden.
Aufgrund dieser strikten Trennung ist es für PostgreSQL® selbst nicht notwendig, den eigenen Datenbestand auf Viren zu untersuchen. Für weniger gut differenzierende Anwendungssoftware kann es jedoch sinnvoll sein, Teilmengen zu überprüfen. Werden in der Datenbank beispielsweise Emails oder Dateien, die Code enthalten (z.B. Office-Dokumente), abgelegt, kann es durchaus Mehrwert bieten, diese Spalten auf bekannte Schadsoftware hin zu überprüfen.
In der Praxis wird hier jedoch fast immer ein generischer Echtzeitscanner verwendet, der nicht nur die erforderlichen Bereiche prüft, sondern On-Access-Methoden verwendet, und daher sämtliche im ersten Teil angesprochenen Probleme mit sich bringt.
Schadsoftware gefunden, was nun?
Erschwerend kommt hinzu, dass die Bearbeitung von Schadsoftware-Funden bei einer externen Software sehr schwer ist. Was soll z.B. im Falle eines gefundenen trojanischen Pferds passieren?
Automatischer Eingriff
Auf einem Desktop-System möchte man beispielsweise, dass die betroffene Datei in Quarantäne verschoben oder gelöscht wird. Mit dem Betrieb eines Datenbank-Servers ist solches Verhalten jedoch nicht vereinbar. Da es sich bei den Dateien um die physische Repräsentation der Datenbasis handelt, wird durch diesen Mechanismus Datenkorruption verursacht, die sich z.B. als stiller Datenverlust oder auch Verletzung von Konsistenzbedingungen wie das Nichterkennen von Duplikaten äußern kann.
Alarmierung
In der Praxis ist es daher meist sinnvoll, nur Alarmierungen zu erzeugen, die dann von einem Administrator bearbeitet werden. Doch was ist das geeignete Vorgehen, wenn der Virenscanner gestern Nacht eine Infektion der Datei “/var/lib/postgresql/11/main/base/13090/1255” gemeldet hat?
- Wo ist der infizierte Code in der Datenbank?
- Wo kam er her?
- Ist die Meldung überhaupt richtig? False-Positive?
Gibt es bereits zufriedenstellende Lösungen?
Der beschriebene Status-Quo erfüllt offensichtlich nicht alle Anforderungen. Gibt es für Datenbanken (PostgreSQL®) eine bessere Lösung?
Derzeit bleibt die Überprüfung in der Anwendung oder Fremdsystemen die verbreitetste Methode. Verschiedene Hersteller bieten auch Netzwerk-Virenscanner an, die den Netzwerkverkehr überwachen und durchsuchen. Aber auch hier gibt es viele der bereits angesprochenen konzeptionellen Schwächen, z.B. wie ein Fund behandelt wird.
Lösungsversuch
![]() Wünschenswert wäre es, die Überprüfung auf Schadcode und auch die Behandlung von Funden im Datenbanksystem selbst abzuwickeln. Optimalerweise per SQL-Schnittstelle, so dass Entwickler oder DBAs die Funktionalität in den normalen Anwendungsbetrieb integrieren können.
Wünschenswert wäre es, die Überprüfung auf Schadcode und auch die Behandlung von Funden im Datenbanksystem selbst abzuwickeln. Optimalerweise per SQL-Schnittstelle, so dass Entwickler oder DBAs die Funktionalität in den normalen Anwendungsbetrieb integrieren können.
So könnte genau definiert werden, wann welche Eingabe zu überprüfen ist. Positiv-Funde können dann über die gemeinen SQL-Fehlercodes gemeldet werden, und würden nicht länger die Dienstfunktionalität gefährden. Man könnte sich beispielsweise eine Tabelle mit einer Text-Spalte vorstellen, in der Usereingaben gespeichert werden. Nun kann vor jedem INSERT oder UPDATE überprüft werden, ob bekannter Schadcode vorliegt und die Eintragung per CONSTRAINT verhindert werden.
Um die Machbarkeit einer solch integrierten Antivirenlösung aufzuzeigen, hat credativ die PostgreSQL®-Erweiterung pg_snakeoil veröffentlicht. Diese macht die Funktionen von ClamAV in der SQL-Welt zugänglich, und erlaubt eine Schadcode-Prüfung bei voller ACID-Konformität. pg_snakeoil wurde unter der PostgreSQL®-Lizenz veröffentlicht und kann in der aktuellen Version bei Github gefunden werden.
Unterstützung
Falls Sie Unterstützung bei PostgreSQL®, Malware-Prävention, IT-Grundschutz oder anderer Aspekte der IT-Infrastruktur benötigen, steht Ihnen unser Open Source Support Center zur Verfügung – Falls gewünscht auch 24 Stunden am Tag, an 365 Tagen im Jahr.
Wir freuen uns über Ihre Kontaktaufnahme.
Dieser Artikel wurde ursprünglich von Alexander Sosna verfasst.
In dieser Woche wurde Version 1.3 unserer PostgreSQL®-Appliance Elephant Shed veröffentlicht.
Das Highlight der neuen Version ist die Unterstützung für Red Hat Enterprise Linux 7 und CentOS 7. Wie bereits unter Debian setzt die Appliance auf die postgresql-common-Infrastruktur, für die schon länger ein RPM-Port existiert, der hier nun voll zum Tragen kommt. Die auf RPM-Systemen bekannten PostgreSQL®-Pakete von yum.postgresql.org werden über pg_createcluster in das System integriert und können über die Elephant Shed-Weboberfläche verwaltet werden.
Alle weiteren Elephant Shed-Komponenten, unter anderem pgAdmin4, Grafana, Prometheus, pgbackrest, Cockpit und shellinabox, funktionieren weiterhin wie in der Debian-Version der Appliance. Lediglich für die Nutzung von pgAdmin4 und shellinabox muss die SELinux-Funktion abgeschaltet werden, da die Pakete diese Funktion nicht unterstützen.
Neben der RPM-Portierung wurde vor allem die Infrastruktur der Appliance aktualisiert. Der Prometheus-Node-Exporter ist nun in Version 0.16 verfügbar, in der viele Metrik-Namen an das Prometheus-Namensschema angepasst wurden. Das Grafana-Dashboard wurde ebenfalls entsprechend aktualisiert. In der Apache-Konfiguration wurde von authnz_pam auf authnz_external gewechselt, da ersteres auf CentOS nicht verfügbar ist, und eine stabile Funktion unter Debian Buster nicht mehr garantiert wird.
Die nächsten Punkte auf der Elephant-Shed-Roadmap sind die Integration der REST-API für die Kontrolle einzelner Komponenten, sowie Multi-Host-Support, um mehrere Elephant-Shed-Instanzen gleichzeitig zu kontrollieren. Eine Überarbeitung des User-Interface ist ebenfalls geplant.
Die aktualisierten Pakete stehen über packages.credativ.com zum Download bereit. Wer Elephant Shed bereits installiert hat, kann die Updates wie gewohnt über apt einspielen.
Die von credativ entwickelte, quelloffene PostgreSQL®-Appliance Elephant-Shed erfreut sich größter Beliebtheit bei Anwendern, da die wichtigsten Komponenten für die Administration und Verwaltung einer PostgreSQL®-Instanz bereits integriert sind. Eigene Anpassungen können jederzeit vorgenommen werden.
Für Elephant Shed bietet die credativ einen umfassenden technischen Support mit garantierten Service-Level-Agreements, der optional auch an 365 Tagen im Jahr rund um die Uhr zur Verfügung steht.
In der aktuellen Ausgabe beschäftigt sich das Linux Magazin in einem sehr interessanten Artikel mit einer Frage, die derzeit in vielen Unternehmen intensiv diskutiert wird:
Betreibt man seine Datenbank auf der eigenen Hardware, oder verlagert man sie in die Cloud?
Um die einzelnen Vor- und Nachteile zu untersuchen, wurden Datenbanklösungen diverser Cloud-Anbieter mit einer lokalen PostgreSQL®-Installation verglichen. Für die Tests auf der lokalen Installation wurde auch die von credativ entwickelte PostgreSQL® Appliance „Elephant Shed“ verwendet.
Den vollständigen Artikel inklusive Testergebnissen findet man in der neuesten Ausgabe des Linux Magazins (10/18). Optional kann der Artikel auf der Seite des Linux-Magazins auch online erworben werden.
Über PostgreSQL®
PostgreSQL® ist eines der führenden Open-Source-Datenbanksysteme, mit einer weltweiten Community bestehend aus Tausenden von Nutzern und Mitwirkenden. Das PostgreSQL® Projekt baut auf über 25 Jahre Erfahrung auf, beginnend an der University of California, Berkeley, und ist bald schon in der Version 11 verfügbar.
Für PostgreSQL® bietet credativ umfangreiche Services und einen tiefgehenden Entwicklersupport an. Von der Konzeption, zur Datenbankmigration, Optimierungen und Tunings, bis hin zur Hochverfügbarkeit: Der gesamte PostgreSQL®-Datenbank-Lifecycle wird durch credativ abgedeckt.
Um eine komfortablere und flexiblere Administration zu ermöglichen, hat credativ die Elephant Shed PostgreSQL® Appliance entwickelt.
Über Elephant Shed
Elephant Shed ist eine vollständig freie, leistungsfähige Open Source-Lösung, die eine enorme Erleichterung für den Betrieb von PostgreSQL® im Unternehmenseinsatz bietet.
Elephant Shed baut auf bewährten Komponenten auf, die ausschließlich unter anerkannten Open Source Lizenzen veröffentlicht werden – und bietet somit den vollständigen Softwarestack für die Administration, das Monitoring, die Erstellung von Backups, und vielem mehr für PostgreSQL®-Datenbanken.
Weitere Informationen über PostgreSQL® und Elephant Shed erhalten Sie auf der jeweiligen Projektseite.
Dieser Artikel wurde ursprünglich von Philip Haas geschrieben.