Einführung
Das Ausführen von ANALYZE (entweder explizit oder über Auto-Analyze) ist sehr wichtig, um aktuelle Datenstatistiken für den Postgres-Query-Planer zu haben. Insbesondere nach In-Place-Upgrades über ANALYZE nur Teile der Blöcke in einer Tabelle abtastet, ähnelt das I/O-Muster eher einem Direktzugriff als einem sequenziellen Lesen. Version 14 von Postgres hat die Möglichkeit maintenenance_io_concurrency gesteuert, der standardmäßig auf 10 gesetzt ist (im Gegensatz zu effective_io_concurrency, der standardmäßig auf 1 gesetzt ist).
Benchmark
Um die Änderungen zwischen Version 13 und 14 zu testen und zu demonstrieren, haben wir einige kurze Benchmarks mit den aktuellen Wartungsversionen (13.16 und 14.13) auf Debian 12 mit Paketen von https://apt.postgresql.org durchgeführt. Hardwareseitig wurde ein ThinkPad T14s Gen 3 mit einer Intel i7-1280P CPU mit 20 Kernen und 32 GB RAM verwendet. Die Basis ist eine pgbench-Datenbank, die mit einem Skalierungsfaktor von 1000 initialisiert wurde:
$ pgbench -i -I dtg -s 1000 -d pgbenchDadurch werden 100 Millionen Zeilen erstellt, was zu einer Datenbankgröße von etwa 15 GB führt. Um pgbench_accounts:
$ vacuumdb -Z -v -d pgbench -t pgbench_accounts
INFO: analyzing "public.pgbench_accounts"
INFO: "pgbench_accounts": scanned 300000 of 1639345 pages,
containing 18300000 live rows and 0 dead rows;
300000 rows in sample, 100000045 estimated total rowsZwischen den Durchläufen wird der Dateisystem-Seitencache über echo 3 | sudo tee /proc/sys/vm/drop_caches gelöscht und alle Durchläufe werden dreimal wiederholt. Die folgende Tabelle listet die Laufzeiten (in Sekunden) des obigen vacuumdb-Befehls für verschiedene Einstellungen von maintenance_io_concurrency auf:
| Version | 0 | 1 | 5 | 10 | 20 | 50 | 100 | 500 |
|---|---|---|---|---|---|---|---|---|
| 13 | 19.557 | 21.610 | 19.623 | 21.060 | 21.463 | 20.533 | 20.230 | 20.537 |
| 14 | 24.707 | 29.840 | 8.740 | 5.777 | 4.067 | 3.353 | 3.007 | 2.763 |
Analyse
Zwei Dinge gehen aus diesen Zahlen deutlich hervor: Erstens ändern sich die Laufzeiten für Version 13 nicht, der Wert von maintenance_io_concurrency hat für diese Version keine Auswirkung. Zweitens, sobald das Prefetching für Version 14 einsetzt (maintenance_io_concurrency=0) oder nur auf 1 gesetzt ist, schlechter sind als bei Version 13, aber da der Standardwert für maintenance_io_concurrency 10 ist, sollte dies in der Praxis niemanden betreffen.
Fazit
Das Aktivieren von Prefetching für ANALYZE in Version 14 von PostgreSQL hat die Statistikabtastung erheblich beschleunigt. Der Standardwert von 10 für ANALYZE.
Am Donnerstag, den 27. Juni, und Freitag, den 28. Juni 2024, hatte ich die großartige Gelegenheit, am Swiss PGDay 2024 teilzunehmen. Die Konferenz fand an der OST Ostschweizer Fachhochschule, Campus Rapperswil, statt, die wunderschön am Ufer des Zürichsees in einer schönen, grünen Umgebung gelegen ist. Mit etwa 110 Teilnehmern hatte die Veranstaltung hauptsächlich einen B2B-Fokus, wenn auch nicht ausschließlich. Obwohl die Konferenz im Vergleich zu PostgreSQL-Veranstaltungen in größeren Ländern scheinbar kleiner war, spiegelte sie doch perfekt den für die Schweiz relevanten Umfang wider.
Während der Konferenz hielt ich meinen Vortrag „GIN, BTREE_GIN, GIST, BTREE_GIST, HASH & BTREE Indexes on JSONB Data“. Der Vortrag fasste die Ergebnisse meines Langzeitprojekts bei NetApp zusammen, einschließlich neuerer interessanter Erkenntnisse im Vergleich zu der Präsentation,
Ganz am Ende am Freitag hielt ich auch einen Lightning Talk, „Kann PostgreSQL eine prominentere Rolle im KI-Boom spielen?“ (meine Folien befinden sich am Ende der Datei). In diesem kurzen Vortrag stellte ich die Frage, ob es möglich wäre, KI-Funktionalitäten direkt in PostgreSQL zu implementieren, einschließlich der Speicherung von Embedding-Modellen und trainierten neuronalen Netzen innerhalb der Datenbank. Mehrere Personen im Publikum, die mit ML/KI befasst sind, reagierten positiv auf diesen Vorschlag und bestätigten, dass PostgreSQL tatsächlich eine wichtigere Rolle in ML- und KI-Themen spielen könnte.
Die Konferenz bot zwei Vortragsreihen, eine auf Englisch und die andere auf Deutsch, was eine vielfältige Auswahl an Themen und Referenten ermöglichte. Einige davon möchte ich hervorheben:
- Tomas Vondra präsentierte „The Past and the Future of the Postgres Community“, wobei er erklärte, wie die Arbeit an PostgreSQL-Änderungen und -Korrekturen in Commitfests organisiert ist und zukünftige Entwicklungsideen innerhalb der Community diskutierte.
- Laurenz Albes Vortrag, „Sicherheitsattacken auf PostgreSQL“, beleuchtete mehrere potenzielle Angriffsvektoren in PostgreSQL und erregte mit überraschenden Beispielen große Aufmerksamkeit.
- Chris Engelberts Präsentation, „PostgreSQL on Kubernetes: Dos and Don’ts“, behandelte die Hauptprobleme im Zusammenhang mit dem Betrieb von PostgreSQL auf Kubernetes und diskutierte Lösungen, einschließlich der Vor- und Nachteile bestehender PostgreSQL Kubernetes Operatoren.
- Maurizio De Giorgi und Ismael Posada Trobo diskutierten „Solving PostgreSQL Connection Scalability Issues: Insights from CERN’s GitLab Service“ und erläuterten die Herausforderungen und Lösungen für die Skalierbarkeit in CERNs riesiger Datenbankumgebung.
- Dirk Krautschicks Vortrag, „Warum sich PostgreSQL-Fans auch für Kafka und Debezium interessieren sollten?“, zeigte Beispiele für die Verwendung von Debezium-Konnektoren und Kafka mit PostgreSQL für verschiedene Anwendungsfälle, einschließlich Datenmigrationen.
- Patrick Stählin diskutierte „Wie wir einen Datenkorruptions-Bug mit der Hilfe der Community gefunden und gefixt haben“, wobei er Probleme mit Free-Space-Map-Dateien nach der Migration auf PostgreSQL 16 ansprach.
- Marion Baumgartners Präsentation, „Geodaten-Management mit PostGIS“, lieferte interessante Details zur Verarbeitung von Geodaten in PostgreSQL mithilfe der PostGIS-Erweiterung.
- Prof. Stefan Keller, einer der Hauptorganisatoren und Professor für Data Engineering an der OST Universität Rapperswil, präsentierte „PostgreSQL: A Reliable and Extensible Multi-Model SQL Database“, wobei er die Multi-Modell-Struktur von PostgreSQL inmitten des schwindenden Interesses an NoSQL-Lösungen diskutierte.
- Luigi Nardi von DBTune präsentierte „Lessons Learned from Autotuning PostgreSQL“ und beschrieb ein KI-basiertes Performance-Tuning-Tool, das von seinem Unternehmen entwickelt wurde.
- Kanhaiya Lal und Belma Canik gingen auf „Beyond Keywords: AI-powered Text Search with pgvector for PostgreSQL“ ein und untersuchten die Verwendung der pgvector-Erweiterung zur Verbesserung der Volltextsuchfunktionen in PostgreSQL.
- Gabriele Bartolini, der Entwickler des PostgreSQL Kubernetes Operators „CloudNativePG“, diskutierte in seinem Vortrag „Unleashing the Power of PostgreSQL in Kubernetes“ die Geschichte und Fähigkeiten dieses Operators.
Am Ende des ersten Tages wurden alle Teilnehmer zu einem Social Event zum Networking und persönlichen Austausch eingeladen, das sehr gut organisiert war. Ich möchte die harte Arbeit und das Engagement aller Organisatoren würdigen und ihnen für ihre Bemühungen danken. Der Swiss PGDay 2024 war wirklich eine unvergessliche und wertvolle Erfahrung, die großartige Lernmöglichkeiten bot. Ich bin dankbar für die Gelegenheit, an der Konferenz teilzunehmen und dazu beizutragen, und ich freue mich auf zukünftige Ausgaben dieser Veranstaltung. Ich bin auch NetApp-credativ sehr dankbar, dass sie meine Teilnahme an der Konferenz ermöglicht haben.
Fotos von Organisatoren, Gülçin Yıldırım Jelínek und Autor:






On Wednesday, June 5th, I attended the Prague PostgreSQL Developers Day 2024. It is the leading PostgreSQL conference in the Czech Republic, which took place for the 16th time this year. Die Veranstaltung fand in der modernen und komfortablen Umgebung der Tschechischen Technischen Universität statt und wurde von fast 270 Teilnehmern besucht.
Während der Konferenz hielt ich meinen Vortrag „GIN-, BTREE_GIN-, GIST- und BTREE-Indizes für JSONB-Daten”. Dieser Vortrag fasste die aktuellen Ergebnisse meines Projekts bei NetApp (credativ) zusammen, das ich initiiert habe, um unser Verständnis dieser Indizierungsmethoden und ihrer Leistungsergebnisse zu vertiefen. Unser Ziel ist es, unseren Kunden relevante und wertvolle Lösungen anzubieten, die häufig Schwierigkeiten bei der Implementierung von JSONB-Spalten und -Operationen in ihre Anwendungen haben und die verfügbaren Informationen als unzureichend empfinden. Selbst bestehende KI-Modelle sind unzureichend, da sie sich auf dieselben begrenzten öffentlich zugänglichen Daten stützen. Das Projekt konzentriert sich auf JSONB-Daten, jedoch haben die Ergebnisse bereits gezeigt, dass es über diesen Datentyp hinaus anwendbar ist. Die positiven Reaktionen des Publikums zeigten, dass meine Präsentation gut angekommen war. Die Konferenz ist eine zweisprachige Veranstaltung mit Vorträgen auf Tschechisch und Englisch. Da ich aus Tschechien komme, hielt ich meinen Vortrag auf Tschechisch, verwendete jedoch englische Folien.
Die Konferenz bot den ganzen Tag über auch sieben weitere aufschlussreiche Vorträge. Der erste Vortrag von Jan Karremans von Cybertec befasste sich mit dem CloudNativePG-Operator, der PostgreSQL für den Betrieb auf Kubernetes implementiert. Der zweite Vortrag von Jakub Zemanek von initMax bot eine detaillierte Anleitung zur
Die Konferenz war sehr gut organisiert, und ich spreche Tomas Vondra und den anderen Organisatoren meinen Dank für ihre harte Arbeit aus. Insgesamt war es eine sehr erfolgreiche Veranstaltung, gefüllt mit wertvollen Erkenntnissen, anregenden Diskussionen und Networking-Möglichkeiten. Ich freue mich darauf, das hier gewonnene Wissen anzuwenden, und bin gespannt auf zukünftige Ausgaben der P2D2-Konferenz.
Nützliche Links:
- Vorträge des Prague PostgreSQL Developer Day 2024 – Zusammenfassungen mit Links zu den Folien (Englisch / Tschechisch)
- Rückblick auf den Prague PostgreSQL Developer Day 2024 – Tomas Vondra (Englisch)
Fotos von Tomas Vondra (EDB):
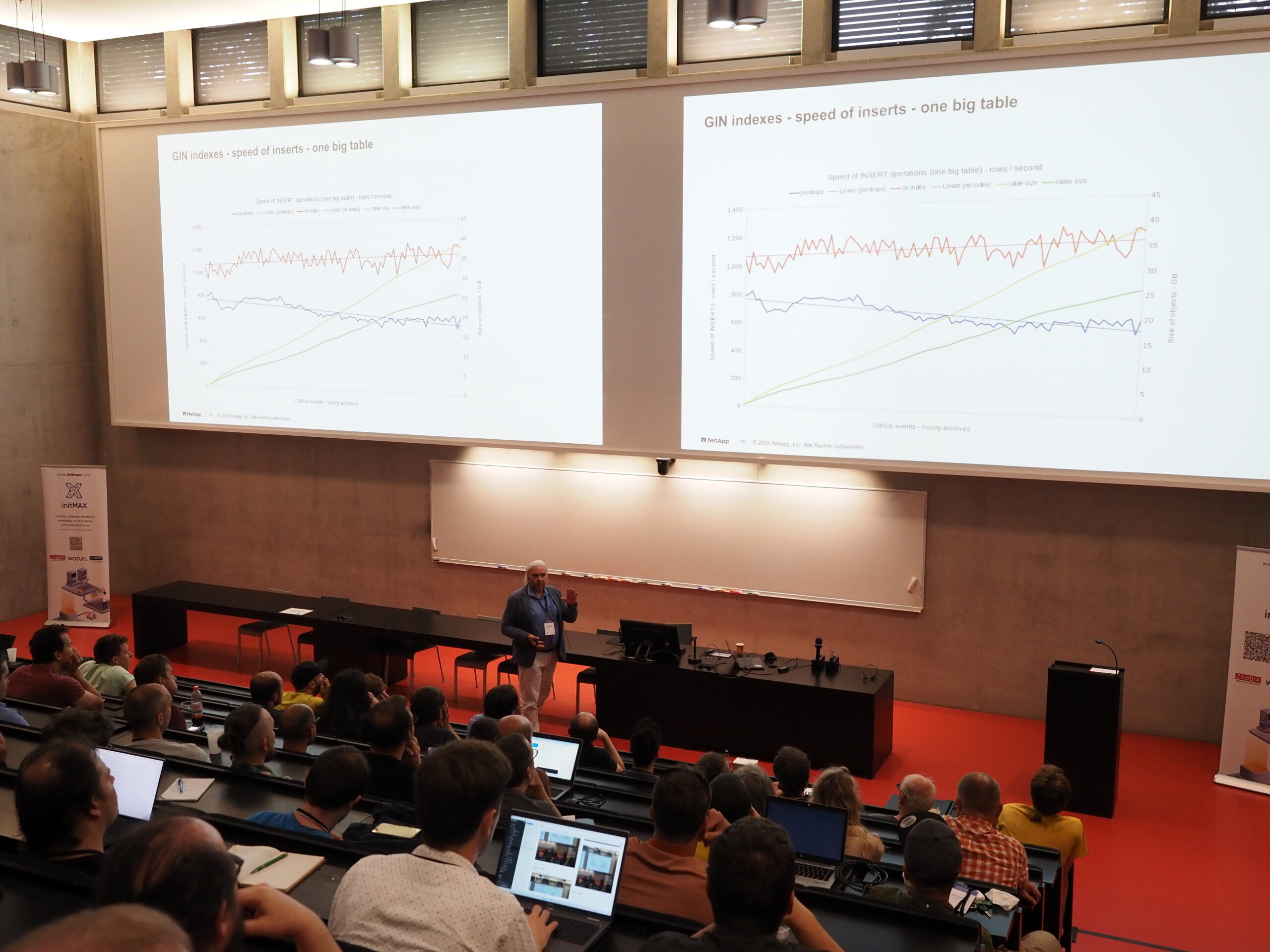

Die Deutsche Postgres Konferenz fand dieses Jahr zum 8. Mal statt, dieses Mal am 12. April in München. Es war die bisher größte PGConf.DE mit 270 Registrierungen, 16 mehr als letztes Jahr. Auf der Konferenz waren wir mit sieben Kollegen vertreten, sodass wir uns über die drei parallelen Tracks plus einen Sponsor-Track aufteilen konnten. Einer der drei Tracks hatte deutschsprachige Vorträge, wo auch Michael Banck in seinem Vortrag die drei führenden Cloud Provider (Amazon RDS, Google Cloud SQL, Microsoft Azure Database) miteinander verglich zudem es auch positives Feedback gab.

Michael Banck bei seinem Vortrag – PostgreSQL-As-A-Service: Vergleich von Cloud Providern
Simon Riggs, eine wichtige Person in der PostgreSQL-Community verstarb leider zwei Wochen vor der Konferenz. In den Vorträgen gab es große Anteilnahme an seinem Verlust und Gülçin Jelinek gedachte seiner gleich zu Beginn der Konferenz. Das letzte mal trafen wir ihn Ende 2023 in Prag auf der PGConf.EU, wo er die Keynote hielt.
Am Tag vor der Konferenz nahm mein Kollege Michael Banck an dem zweiten Patroni Contributor Meeting teil. Das erste Meeting war letztes Jahr vor der letzten Deutschen Postgres Konferenz in Essen. Zu dem Treffen kamen die beiden Patroni-Maintainer Alexander Kukushkin und Polina Bungina, sowie Verteter von EnterpriseDB, Cybertec und Data Egret. Es wurden einige organisatorische Fragen (z.B. über das Logo) geklärt, die Roadmap besprochen sowie einige vorgeschlagene Features für Multi-Site Patroni diskutiert. Nach dem Patroni Meeting war am Abend das Organiser- und Speaker-Dinner im Gasthaus Eder in der Nähe des Konferenz-Hotels.
Der Feature Freeze für PostgreSQL 17 war nur wenige Tage vor der Konferenz am 08. April. Daher wurden die damit verbundenen Verbesserungen in den Vorträgen berücksichtigt oder befassten sich vollständig mit einem neuen Feature. Dazu zählen unter anderem native inkrementelle Backups und Migration von logical replication Slots bei Major Upgrades. Die Veröffentlichung von PostgreSQL 17 ist für September geplant. Bis dahin könnten einzelne Features noch entfernt werden, falls Probleme auftreten, die nicht rechtzeitig gelöst werden können.
Insgesamt war die Qualität der Vorträge sehr hoch, sodass man aus jedem Vortrag etwas interessantes mitnehmen konnte. Deshalb freuen wir uns bereits auf die kommende PGConf.EU im Oktober in Athen.
Übersicht
Tabellen, die bei Bedarf erstellt und gelöscht werden, ob temporär oder regulär, werden von Anwendungsentwicklern in PostgreSQL häufig verwendet, um die Implementierung verschiedener Funktionalitäten zu vereinfachen und Antworten zu beschleunigen. Zahlreiche Artikel im Internet beschreiben die Vorteile der Verwendung solcher Tabellen zum Speichern von Suchergebnissen, zum Vorberechnen von Zahlen für Berichte, zum Importieren von Daten aus externen Dateien und mehr. Man kann sogar eine TEMP TABLE mit der Bedingung ON COMMIT DROP definieren, wodurch das System automatisch bereinigen kann. Wie die meisten Dinge hat diese Lösung jedoch potenzielle Nachteile, da die Größe eine Rolle spielt. Eine Lösung, die für Dutzende paralleler Sitzungen reibungslos funktioniert, kann plötzlich unerwartete Probleme verursachen, wenn die Anwendung während der Stoßzeiten von Hunderten oder Tausenden von Benutzern gleichzeitig verwendet wird. Das häufige Erstellen und Löschen von Tabellen und verwandten Objekten kann zu einer erheblichen Aufblähung bestimmter PostgreSQL-Systemtabellen führen. Dies ist ein bekanntes Problem, das in vielen Artikeln erwähnt wird, denen es jedoch oft an detaillierten Erklärungen und einer Quantifizierung der Auswirkungen mangelt. Mehrere pg_catalog-Systemtabellen können erheblich aufgebläht werden. Die Tabelle pg_attribute ist am stärksten betroffen, gefolgt von pg_attrdef und pg_class.
Was ist das Hauptproblem bei der Aufblähung von Systemtabellen?
Wir sind bereits in den PostgreSQL-Protokollen eines unserer Kunden auf dieses Problem gestoßen. Als die Aufblähung der Systemtabellen zu groß wurde, beschloss PostgreSQL, während eines Autovacuum-Vorgangs freien Speicherplatz zurückzugewinnen. Diese Aktion verursachte exklusive Sperren auf der Tabelle und blockierte alle anderen Operationen für mehrere Sekunden. PostgreSQL konnte keine Informationen über die Strukturen aller Beziehungen lesen. Infolgedessen mussten selbst die einfachsten Select-Operationen verzögert werden, bis die Operation abgeschlossen war. Dies ist natürlich ein extremes und seltenes Szenario, das nur unter außergewöhnlich hoher Last auftreten kann. Dennoch ist es wichtig, sich dessen bewusst zu sein und beurteilen zu können, ob dies auch in unserer Datenbank passieren könnte.
Beispiel für eine Berichtstabelle in einer Buchhaltungssoftware
CREATE TEMP TABLE pivot_temp_table ( id serial PRIMARY KEY, inserted_at timestamp DEFAULT current_timestamp, client_id INTEGER, name text NOT NULL, address text NOT NULL, loyalty_program BOOLEAN DEFAULT false, loyalty_program_start TIMESTAMP, orders_202301_count_of_orders INTEGER DEFAULT 0, orders_202301_total_price NUMERIC DEFAULT 0, ... orders_202312_count_of_orders INTEGER DEFAULT 0, orders_202312_total_price NUMERIC DEFAULT 0);
CREATE INDEX pivot_temp_table_idx1 ON pivot_temp_table (client_id); CREATE INDEX pivot_temp_table_idx2 ON pivot_temp_table (name); CREATE INDEX pivot_temp_table_idx3 ON pivot_temp_table (loyalty_program); CREATE INDEX pivot_temp_table_idx4 ON pivot_temp_table (loyalty_program_start);
- Eine temporäre Tabelle, pivot_temp_table, mit 31 Spalten, von denen 27 Standardwerte haben.
- Einige der Spalten haben den Datentyp TEXT, was zur automatischen Erstellung einer TOAST-Tabelle führt.
- Die TOAST-Tabelle benötigt einen Index für chunk_id und chunk_seq.
- Die ID ist der Primärschlüssel, was bedeutet, dass automatisch ein eindeutiger Index für die ID erstellt wurde.
- Die ID ist als SERIAL definiert, was zur automatischen Erstellung einer Sequenz führt, die im Wesentlichen eine weitere Tabelle mit einer speziellen Struktur ist.
- Wir haben auch vier zusätzliche Indizes für unsere temporäre Tabelle definiert.
Lassen Sie uns nun untersuchen, wie diese Beziehungen in PostgreSQL-Systemtabellen dargestellt werden.
Tabelle pg_attribute
- Jede Zeile in unserer pivot_temp_table enthält sechs versteckte Spalten (tableoid, cmax, xmax, cmin, xmin, ctid) und 31 ’normale‘ Spalten. Dies ergibt insgesamt 37 eingefügte Zeilen für die temporäre Haupttabelle.
- Indizes fügen für jede im Index verwendete Spalte eine Zeile hinzu, was in unserem Fall fünf Zeilen entspricht.
- Es wurde automatisch eine TOAST-Tabelle erstellt. Sie hat sechs versteckte Spalten und drei normale Spalten (chunk_id, chunk_seq, chunk_data) sowie einen Index für chunk_id und chunk_seq, was insgesamt 11 Zeilen ergibt.
- Es wurde eine Sequenz für die ID erstellt, die im Wesentlichen eine weitere Tabelle mit einer vordefinierten Struktur ist. Sie hat sechs versteckte Spalten und drei normale Spalten (last_value, log_cnt, is_called), was weitere neun Zeilen hinzufügt.
Tabelle pg_attrdef
SELECT c.relname as table_name, o.rolname as table_owner, c.relkind as table_type, a.attname as column_name, a.attnum as column_number, a.atttypid::regtype as column_data_type, pg_get_expr(adbin, adrelid) as sql_command FROM pg_attrdef ad JOIN pg_attribute a ON ad.adrelid = a.attrelid AND ad.adnum = a.attnum JOIN pg_class c ON c.oid = ad.adrelid JOIN pg_authid o ON o.oid = c.relowner WHERE c.relname = 'pivot_temp_table' ORDER BY table_name, column_number;
table_name | table_owner | table_type | column_name | column_number | column_data_type | sql_command
------------------+-------------+------------+-------------------------------+---------------+-----------------------------+----------------------------------------------
pivot_temp_table | postgres | r | id | 1 | integer | nextval('pivot_temp_table_id_seq'::regclass)
pivot_temp_table | postgres | r | inserted_at | 2 | timestamp without time zone | CURRENT_TIMESTAMP
pivot_temp_table | postgres | r | loyalty_program | 6 | boolean | false
pivot_temp_table | postgres | r | orders_202301_count_of_orders | 8 | integer | 0
pivot_temp_table | postgres | r | orders_202301_total_price | 9 | numeric | 0
--> bis zur Spalte "orders_202312_total_price"Tabelle pg_class
Die Tabelle pg_class speichert primäre Informationen über Beziehungen. Dieses Beispiel erstellt neun Zeilen: eine für die temporäre Tabelle, eine für die Toast-Tabelle, eine für den Toast-Tabellenindex, eine für den eindeutigen Index des ID-Primärschlüssels, eine für die Sequenz und vier für die benutzerdefinierten Indizes.
Zusammenfassung dieses Beispiels
Unser erstes Beispiel erzeugte eine scheinbar kleine Anzahl von Zeilen – 62 in pg_attribute, 27 in pg_attrdef und 9 in pg_class. Dies sind sehr niedrige Zahlen, und wenn eine solche Lösung nur von einem Unternehmen verwendet würde, würden wir kaum Probleme sehen. Stellen Sie sich jedoch ein Szenario vor, in dem ein Unternehmen Buchhaltungssoftware für kleine Unternehmen hostet und Hunderte oder sogar Tausende von Benutzern die App während der Stoßzeiten nutzen. In einer solchen Situation würden viele temporäre Tabellen und verwandte Objekte relativ schnell erstellt und gelöscht. In der Tabelle pg_attribute könnten wir innerhalb weniger Stunden zwischen einigen Tausend und sogar Hunderttausenden von Datensätzen sehen, die eingefügt und dann gelöscht werden. Dies ist jedoch immer noch ein relativ kleiner Anwendungsfall. Lassen Sie uns nun etwas noch Größeres vorstellen und benchmarken.
Beispiel für einen Online-Shop
- Die Tabelle „session_events“ speichert ausgewählte Aktionen, die der Benutzer während der Sitzung durchgeführt hat. Ereignisse werden für jede Aktion erfasst, die der Benutzer auf der Website ausführt, sodass mindestens Hunderte, aber häufig Tausende von Ereignissen aus einer Sitzung aufgezeichnet werden. Diese werden alle parallel in die Hauptereignistabelle gesendet. Die Haupttabelle ist jedoch enorm. Daher speichert diese benutzerspezifische Tabelle nur einige Ereignisse, was eine schnelle Analyse der letzten Aktivitäten usw. ermöglicht. Die Tabelle hat 25 verschiedene Spalten, von denen einige vom Typ TEXT und eine Spalte vom Typ JSONB sind – was bedeutet, dass eine TOAST-Tabelle mit einem Index erstellt wurde. Die Tabelle hat einen Primärschlüssel vom Typ Serial, der die Reihenfolge der Aktionen angibt – d. h. ein eindeutiger Index, eine Sequenz und ein Standardwert wurden erstellt. Es gibt keine zusätzlichen Standardwerte. Die Tabelle hat auch drei zusätzliche Indizes für einen schnelleren Zugriff, jeder für eine Spalte. Ihr Nutzen könnte fraglich sein, aber sie sind Teil der Implementierung.
- Zusammenfassung der Zeilen in Systemtabellen – pg_attribute – 55 Zeilen, pg_class – 8 Zeilen, pg_attrdef – 1 Zeile
- Die Tabelle „last_visited“ speichert eine kleine Teilmenge von Ereignissen aus der Tabelle „session_events“, um schnell anzuzeigen, welche Artikel der Benutzer während dieser Sitzung besucht hat. Entwickler haben sich aus Gründen der Bequemlichkeit für diese Implementierung entschieden. Die Tabelle ist klein und enthält nur 10 Spalten, aber mindestens eine ist vom Typ TEXT. Daher wurde eine TOAST-Tabelle mit einem Index erstellt. Die Tabelle hat einen Primärschlüssel vom Typ TIMESTAMP, daher hat sie einen eindeutigen Index, einen Standardwert, aber keine Sequenz. Es gibt keine zusätzlichen Indizes.
- Zeilen in Systemtabellen – pg_attribute – 28 Zeilen, pg_class – 4 Zeilen, pg_attrdef – 1 Zeile
- Die Tabelle „last_purchases“ wird beim Anmelden aus der Haupttabelle gefüllt, die alle Käufe speichert. Diese benutzerspezifische Tabelle enthält die letzten 50 Artikel, die der Benutzer in früheren Sitzungen gekauft hat, und wird vom Empfehlungsalgorithmus verwendet. Diese Tabelle enthält vollständig denormalisierte Daten, um ihre Verarbeitung und Visualisierung zu vereinfachen, und hat daher 35 Spalten. Viele dieser Spalten sind vom Typ TEXT, sodass eine TOAST-Tabelle mit einem Index erstellt wurde. Der Primärschlüssel dieser Tabelle ist eine Kombination aus dem Kaufzeitstempel und der Ordnungszahl des Artikels in der Bestellung, was zur Erstellung eines eindeutigen Index, aber keiner Standardwerte oder Sequenzen führt. Im Laufe der Zeit hat der Entwickler vier Indizes für diese Tabelle für verschiedene Sortierzwecke erstellt, jeder für eine Spalte. Der Wert dieser Indizes kann in Frage gestellt werden, aber sie existieren immer noch.
- Zeilen in Systemtabellen – pg_attribute – 57 Zeilen, pg_class – 8 Zeilen
- Die Tabelle „selected_but_not_purchased“ wird beim Anmelden aus der entsprechenden Haupttabelle gefüllt. Sie zeigt die letzten 50 Artikel an, die noch im Shop verfügbar sind, die der Benutzer zuvor in Betracht gezogen hat, aber später aus dem Warenkorb entfernt oder die Bestellung überhaupt nicht abgeschlossen hat, und der Inhalt des Warenkorbs ist abgelaufen. Diese Tabelle wird vom Empfehlungsalgorithmus verwendet und hat sich als erfolgreiche Ergänzung der Marketingstrategie erwiesen, die die Käufe um einen bestimmten Prozentsatz erhöht. Die Tabelle hat die gleiche Struktur und verwandte Objekte wie „last_purchases“. Die Daten werden getrennt von den Käufen gespeichert, um Fehler bei der Dateninterpretation zu vermeiden, und auch, weil dieser Teil des Algorithmus viel später implementiert wurde.
- Zeilen in Systemtabellen – pg_attribute – 57 Zeilen, pg_class – 8 Zeilen
- Die Tabelle „cart_items“ speichert Artikel, die für den Kauf in der aktuellen Sitzung ausgewählt, aber noch nicht gekauft wurden. Diese Tabelle wird mit der Haupttabelle synchronisiert, aber auch eine lokale Kopie in der Sitzung wird verwaltet. Die Tabelle enthält normalisierte Daten und hat daher nur 15 Spalten, von denen einige vom Typ TEXT sind, was zur Erstellung einer TOAST-Tabelle mit einem Index führt. Sie hat eine Primärschlüssel-ID vom Typ UUID, um Kollisionen über alle Benutzer hinweg zu vermeiden, was zur Erstellung eines eindeutigen Index und eines Standardwerts, aber keiner Sequenz führt. Es gibt keine zusätzlichen Indizes.
- Zeilen in Systemtabellen – pg_attribute – 33 Zeilen, pg_class – 4 Zeilen, pg_attrdef – 1 Zeile
Die Erstellung all dieser benutzerspezifischen Tabellen führt zum Einfügen der folgenden Anzahl von Zeilen in die PostgreSQL-Systemtabellen – pg_attribute: 173 Zeilen, pg_class: 32 Zeilen, pg_attrdef: 3 Zeilen.
Analyse des Datenverkehrs
Als ersten Schritt stellen wir eine Analyse des Business Use Case und der Saisonalität des Datenverkehrs bereit. Stellen wir uns vor, unser Einzelhändler ist in mehreren EU-Ländern tätig und richtet sich hauptsächlich an Personen im Alter von 15 bis 35 Jahren. Der Online-Shop ist relativ neu und hat derzeit 100.000 Konten. Basierend auf Whitepapers, die im Internet verfügbar sind, können wir folgende Benutzeraktivität annehmen:
| Aktivitätsniveau des Benutzers | Verhältnis der Benutzer [%] | Gesamtzahl der Benutzer | Besuchshäufigkeit auf der Seite |
|---|---|---|---|
| sehr aktiv | 10% | 10.000 | 2x bis 4x pro Woche |
| normale Aktivität | 30% | 30.000 | ~1 Mal pro Woche |
| geringe Aktivität | 40% | 40.000 | 1x bis 2x pro Monat |
| fast keine Aktivität | 20% | 20.000 | wenige Male im Jahr |
Da es sich um einen Online-Shop handelt, ist der Datenverkehr stark saisonabhängig. Artikel werden hauptsächlich von Einzelpersonen für den persönlichen Gebrauch gekauft. Daher überprüfen sie den Shop während des Arbeitstages zu ganz bestimmten Zeiten, z. B. während der Reise oder der Mittagspause. Der Hauptverkehr während des Arbeitstages liegt zwischen 19:00 und 21:00 Uhr. Freitage haben in der Regel einen viel geringeren Datenverkehr, und das Wochenende folgt diesem Beispiel. Die verkehrsreichsten Tage sind in der Regel am Ende des Monats, wenn die Leute ihr Gehalt erhalten. Der Shop verzeichnet den stärksten Datenverkehr am Thanksgiving Thursday und am Black Friday. Die übliche Praxis in den letzten Jahren ist es, den Shop für ein oder zwei Stunden zu schließen und dann zu einer bestimmten Stunde mit reduzierten Preisen wieder zu eröffnen. Dies führt zu einer großen Anzahl von Beziehungen, die in relativ kurzer Zeit erstellt und später gelöscht werden. Die Dauer der Verbindung eines Benutzers kann von wenigen Minuten bis zu einer halben Stunde reichen. Benutzerspezifische Tabellen werden erstellt, wenn sich der Benutzer im Shop anmeldet. Sie werden später von einem speziellen Prozess gelöscht, der einen ausgeklügelten Algorithmus verwendet, um zu bestimmen, ob Beziehungen bereits abgelaufen sind oder nicht. Dieser Prozess umfasst verschiedene Kriterien und wird in unterschiedlichen Abständen ausgeführt, sodass wir eine große Anzahl von Beziehungen sehen können, die in einem Durchgang gelöscht werden. Lassen Sie uns diese Beschreibungen quantifizieren:
| Datenverkehr an verschiedenen Tagen | Anmeldungen pro 30 min | pg_attribute [Zeilen] | pg_class [Zeilen] | pg_attrdef [Zeilen] |
|---|---|---|---|---|
| Zahlen aus der Analyse pro 1 Benutzer | 1 | 173 | 32 | 3 |
| Durchschnittlicher Datenverkehr am Nachmittag | 1.000 | 173.000 | 32.000 | 3.000 |
| Normaler Arbeitstagabend mit hohem Datenverkehr | 3.000 | 519.000 | 96.000 | 9.000 |
| Abend nach Gehaltszahlung, geringer Datenverkehr | 8.000 | 1.384.000 | 256.000 | 24.000 |
| Abend nach Gehaltszahlung, hoher Datenverkehr | 15.000 | 2.595.000 | 480.000 | 45.000 |
| Singles‘ Day, Abenderöffnung | 40.000 | 6.920.000 | 1.280.000 | 120.000 |
| Thanksgiving Donnerstag, Abenderöffnung | 60.000 | 10.380.000 | 1.920.000 | 180.000 |
| Black Friday, Abenderöffnung | 50.000 | 8.650.000 | 1.600.000 | 150.000 |
| Black Friday Wochenende, höchster Datenverkehr | 20.000 | 3.460.000 | 640.000 | 60.000 |
| Theoretisches Maximum – alle Benutzer verbunden | 100.000 | 17.300.000 | 3.200.000 | 300.000 |
Jetzt können wir sehen, was Skalierbarkeit bedeutet. Unsere Lösung wird an normalen Tagen definitiv angemessen funktionieren. Der Datenverkehr an den Abenden, nachdem die Leute ihr Gehalt erhalten haben, kann jedoch sehr hoch sein. Thanksgiving Donnerstag und Black Friday testen die Grenzen wirklich aus. Zwischen 1 und 2 Millionen benutzerspezifische Tabellen und zugehörige Objekte werden an diesen Abenden erstellt und gelöscht. Und was passiert, wenn unser Shop noch erfolgreicher wird und die Anzahl der Konten auf 500 000, 1 Million oder mehr ansteigt? Die Lösung würde an einigen Stellen definitiv an die Grenzen der vertikalen Skalierung stoßen, und wir müssten über Möglichkeiten nachdenken, sie horizontal zu skalieren.
Wie man Bloat untersucht
WITH tablenames AS (SELECT tablename FROM (VALUES('pg_attribute'),('pg_attrdef'),('pg_class')) as t(tablename))
SELECT
tablename,
now() as checked_at,
pg_relation_size(tablename) as relation_size,
pg_relation_size(tablename) / (8*1024) as relation_pages,
a.*,
s.*
FROM tablenames t
JOIN LATERAL (SELECT * FROM pgstattuple(t.tablename)) s ON true
JOIN LATERAL (SELECT last_autovacuum, last_vacuum, last_autoanalyze, last_analyze, n_live_tup, n_dead_tup
FROM pg_stat_all_tables WHERE relname = t.tablename) a ON true
ORDER BY tablenametablename | pg_attribute checked_at | 2024-02-18 10:46:34.348105+00 relation_size | 44949504 relation_pages | 5487 last_autovacuum | 2024-02-16 20:07:15.7767+00 last_vacuum | 2024-02-16 20:55:50.685706+00 last_autoanalyze | 2024-02-16 20:07:15.798466+00 last_analyze | 2024-02-17 22:05:43.19133+00 n_live_tup | 3401 n_dead_tup | 188221 table_len | 44949504 tuple_count | 3401 tuple_len | 476732 tuple_percent | 1.06 dead_tuple_count | 107576 dead_tuple_len | 15060640 dead_tuple_percent| 33.51 free_space | 28038420 free_percent | 62.38
WITH pages AS (
SELECT * FROM generate_series(0, (SELECT pg_relation_size('pg_attribute') / 8192) -1) as pagenum),
tuples_per_page AS (
SELECT pagenum, nullif(sum((t_xmin is not null)::int), 0) as tuples_per_page
FROM pages JOIN LATERAL (SELECT * FROM heap_page_items(get_raw_page('pg_attribute',pagenum))) a ON true
GROUP BY pagenum)
SELECT
count(*) as pages_total,
min(tuples_per_page) as min_tuples_per_page,
max(tuples_per_page) as max_tuples_per_page,
round(avg(tuples_per_page),0) as avg_tuples_per_page,
mode() within group (order by tuples_per_page) as mode_tuples_per_page
FROM tuples_per_pagepages_total | 5487 min_tuples_per_page | 1 max_tuples_per_page | 55 avg_tuples_per_page | 23 mode_tuples_per_page | 28
Hier können wir sehen, dass wir in unserer pg_attribute-Systemtabelle durchschnittlich 23 Tupel pro Seite haben. Jetzt können wir die theoretische Größenzunahme dieser Tabelle für unterschiedlichen Datenverkehr berechnen. Die typische Größe dieser Tabelle beträgt in der Regel nur wenige hundert MB. Ein theoretischer Bloat von etwa 3 GB während der Black Friday Tage ist also eine ziemlich bedeutende Zahl für diese Tabelle.
| Logins | pg_attribute Zeilen | Datenseiten | Größe in MB |
|---|---|---|---|
| 1 | 173 | 8 | 0.06 |
| 1.000 | 173.000 | 7.522 | 58.77 |
| 3.000 | 519.000 | 22.566 | 176.30 |
| 15.000 | 2.595.000 | 112.827 | 881.46 |
| 20.000 | 3.460.000 | 150.435 | 1.175.27 |
| 60.000 | 10.380.000 | 451.305 | 3.525.82 |
| 100.000 | 17.300.000 | 752.174 | 5.876.36 |
Zusammenfassung
Wir haben ein Reporting-Beispiel aus einer Buchhaltungssoftware und ein Beispiel für benutzerspezifische Tabellen aus einem Online-Shop vorgestellt. Obwohl beide theoretisch sind, soll die Idee Muster veranschaulichen. Wir haben auch den Einfluss der saisonalen Hochsaison auf die Anzahl der Einfügungen und Löschungen in Systemtabellen diskutiert. Wir haben ein Beispiel für eine extrem erhöhte Last in einem Online-Shop an großen Verkaufstagen gegeben. Wir glauben, dass die Ergebnisse der Analyse Aufmerksamkeit verdienen. Es ist auch wichtig zu bedenken, dass die ohnehin schon schwierige Situation in diesen Spitzenzeiten noch schwieriger sein kann, wenn unsere Anwendung auf einer Instanz mit niedrigen Festplatten-IOPS läuft. All diese neuen Objekte würden Schreibvorgänge in WAL-Protokolle und die Synchronisierung mit der Festplatte verursachen. Bei geringem Festplattendurchsatz kann es zu erheblichen Latenzzeiten kommen, und viele Operationen können erheblich verzögert werden. Was ist also die Quintessenz dieser Geschichte? Erstens sind die Autovacuum-Prozesse von PostgreSQL so konzipiert, dass sie die Auswirkungen auf das System minimieren. Wenn die Autovacuum-Einstellungen in unserer Datenbank gut abgestimmt sind, werden wir in den meisten Fällen keine Probleme feststellen. Wenn diese Einstellungen jedoch veraltet sind, auf einen viel geringeren Datenverkehr zugeschnitten sind und unser System über einen längeren Zeitraum ungewöhnlich stark belastet wird, wodurch Tausende von Tabellen und zugehörigen Objekten in relativ kurzer Zeit erstellt und gelöscht werden, können die PostgreSQL-Systemtabellen schließlich erheblich aufgebläht werden. Dies verlangsamt bereits Systemabfragen, die Details über alle anderen Beziehungen lesen. Und irgendwann könnte das System beschließen, diese Systemtabellen zu verkleinern, was zu einer exklusiven Sperre für einige dieser Beziehungen für Sekunden oder sogar Dutzende von Sekunden führt. Dies könnte eine große Anzahl von Selects und anderen Operationen auf allen Tabellen blockieren. Basierend auf der Analyse des Datenverkehrs können wir eine ähnliche Analyse für andere spezifische Systeme durchführen, um zu verstehen, wann sie am anfälligsten für solche Vorfälle sind. Aber eine effektive Überwachung ist absolut unerlässlich.
Ressourcen
Die PostgreSQL 2024Q1 Back-Branch-Releases 16.2, 15.6, 14.11, 13.14 und 12.18 wurden am 8. Februar 2024 veröffentlicht. Neben der Behebung eines Sicherheitsproblems (CVE-2024-0985) und der üblichen Fehler sind sie insofern einzigartig, als sie zwei Leistungsprobleme durch das Backporting von Korrekturen beheben, die bereits zuvor in den Master-Branch eingeführt wurden. In diesem Blogbeitrag beschreiben wir zwei kurze Benchmarks, die zeigen, wie sich die neuen Punkt-Releases verbessert haben. Die Benchmarks wurden auf einem ThinkPad T14s Gen 3 durchgeführt, das über eine Intel i7-1280P CPU mit 20 Kernen und 32 GB RAM verfügt.
Skalierbarkeitsverbesserungen bei hoher Konkurrenz
Die Leistungsverbesserungen in den 2024Q1 Punkt-Releases betreffen Verbesserungen der Locking-Skalierbarkeit bei hohen Client-Zahlen, d.h. wenn das System unter starker Konkurrenz steht. Benchmarks hatten gezeigt, dass die Leistung bei einem pgbench-Lauf mit mehr als 128 Clients dramatisch abnahm. Der ursprüngliche
Der von uns verwendete Benchmark ist an diesen Beitrag des Patch-Autors angepasst und besteht aus einem engen pgbench-Lauf, der einfach SELECT txid_current() für jeweils fünf Sekunden bei steigender Client-Anzahl ausführt und die Transaktionen pro Sekunde misst:
$ cat /tmp/txid.sql
SELECT txid_current();
$ for c in 1 2 4 8 16 32 64 96 128 192 256 384 512 768 1024 1536;
> do echo -n "$c ";pgbench -n -M prepared -f /tmp/txid.sql -c$c -j$c -T5 2>&1|grep '^tps'|awk '{print $3}';
> doneDie folgende Grafik zeigt die durchschnittlichen Transaktionen pro Sekunde (tps) über 3 Läufe mit steigender Client-Anzahl (1-1536 Clients), unter Verwendung der Debian 12 Pakete für Version 15, wobei das 2023Q4-Release (15.5, Paket postgresql-15_15.5-0+deb12u1) mit dem 2024Q1-Release (15.6, Paket postgresql-15_15.6-0+deb12u1) verglichen wird:
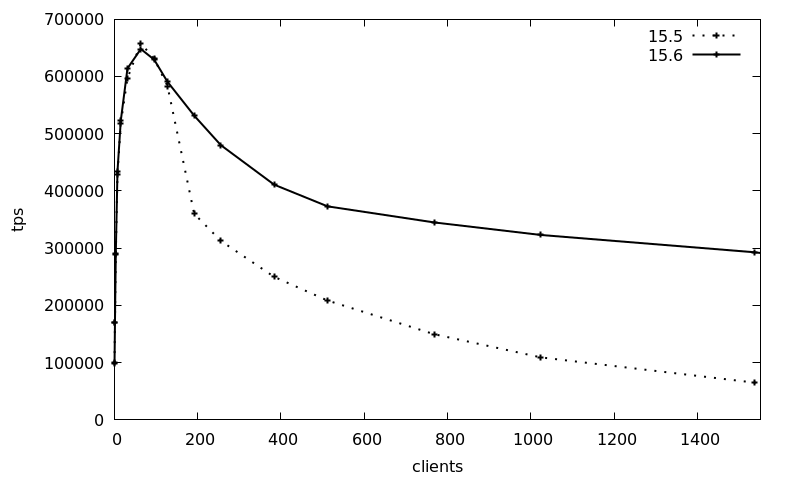
Die tps-Werte sind im Wesentlichen bis zu 128 Clients gleich, während danach die Transaktionszahlen von 15.5 vom Spitzenwert von 650.000 um das 10-fache auf 65.000 sinken. Das neue 15.6-Release hält die Transaktionszahl wesentlich besser und erreicht immer noch etwa 300.000 tps bei 1536 Clients, was eine 4,5-fache Steigerung des 2024Q1-Releases im Vergleich zu zuvor darstellt.
Dieser Benchmark ist natürlich ein Best-Case, ein künstliches Szenario, aber er zeigt, dass das neueste Punkt-Release von Postgres die Skalierbarkeit bei stark umkämpften Locking-Szenarien dramatisch verbessern kann.
JIT-Speicherverbrauchsverbesserungen
JIT (Just-in-Time-Kompilierung mit LLVM) wurde in Version 11 von Postgres eingeführt und in Version 13 zum Standard gemacht. Seit langem ist bekannt, dass lang laufende PostgreSQL-Sitzungen, die wiederholt JIT-Abfragen ausführen, Speicherlecks aufweisen. Es gab mehrere Fehlerberichte dazu, darunter einige weitere im Debian-Bugtracker und wahrscheinlich auch anderswo.
Dies wurde als auf JIT-Inlining zurückzuführen diagnostiziert, und ein Workaround besteht darin, jit_inline_above_cost von dem Standardwert 500.000 auf -1 zu setzen. Dies deaktiviert jedoch das JIT-Inlining vollständig. Die 2024Q1 Back-Branch-Releases enthalten einen Backport einer Änderung, die in Version 17 enthalten sein wird: Nach jeweils 100 Abfragen werden die LLVM-Caches gelöscht und neu erstellt, wodurch das Speicherleck behoben wird.
Um zu zeigen, wie sich der Speicherverbrauch verbessert hat, verwenden wir den Testfall aus diesem Fehlerbericht. Der Benchmark wird wie folgt vorbereitet:
CREATE TABLE IF NOT EXISTS public.leak_test
(
id integer NOT NULL,
CONSTRAINT leak_test_pkey PRIMARY KEY (id)
);
INSERT INTO leak_test(id)
SELECT id
FROM generate_series(1,100000) id
ON CONFLICT DO NOTHING;Anschließend wird die Prozess-ID des Backends notiert und die im Fehlerbericht erwähnte SQL-Abfrage 5000 Mal in einer Schleife ausgeführt:
=> SELECT pg_backend_pid();
pg_backend_pid
----------------
623404
=> DO $$DECLARE loop_cnt integer;
-> BEGIN
-> loop_cnt := 5000;
-> LOOP
-> PERFORM
-> id,
-> (SELECT count(*) FROM leak_test x WHERE x.id=l.id) as x_result,
-> (SELECT count(*) FROM leak_test y WHERE y.id=l.id) as y_result
-> /* Leaks memory around 80 kB on each query, but only if two sub-queries are used. */
-> FROM leak_test l;
-> loop_cnt := loop_cnt - 1;
-> EXIT WHEN loop_cnt = 0;
-> END LOOP;
-> END$$;Dabei wird der Speicherverbrauch des Postgres-Backends über pidstat aufgezeichnet:
pidstat -r -hl -p 623404 2 | tee -a leak_test.log.15.6
Linux 6.1.0-18-amd64 (mbanck-lin-0.credativ.de) 15.02.2024 _x86_64_ (20 CPU)
# Time UID PID minflt/s majflt/s VSZ RSS %MEM Command
12:48:56 118 623404 0,00 0,00 381856 91504 0,28 postgres: 15/main: postgres postgres [local] SELECT
12:48:58 118 623404 0,00 0,00 381856 91504 0,28 postgres: 15/main: postgres postgres [local] SELECT
12:49:00 118 623404 0,00 0,00 381856 91504 0,28 postgres: 15/main: postgres postgres [local] SELECT
12:49:02 118 623404 0,00 0,00 381856 91504 0,28 postgres: 15/main: postgres postgres [local] SELECT
12:49:04 118 623404 7113,00 0,00 393632 109252 0,34 postgres: 15/main: postgres postgres [local] SELECT
12:49:06 118 623404 13219,00 0,00 394556 109508 0,34 postgres: 15/main: postgres postgres [local] SELECT
12:49:08 118 623404 14376,00 0,00 395384 108228 0,33 postgres: 15/main: postgres postgres [local] SELECT
[...]Der Benchmark wird erneut für die Debian 12 Pakete 15.5 und 15.6 wiederholt (die beide gegen LLVM-14 gelinkt sind) und der RSS-Speicherverbrauch, wie von pidstat berichtet, wird gegen die Zeit aufgetragen:
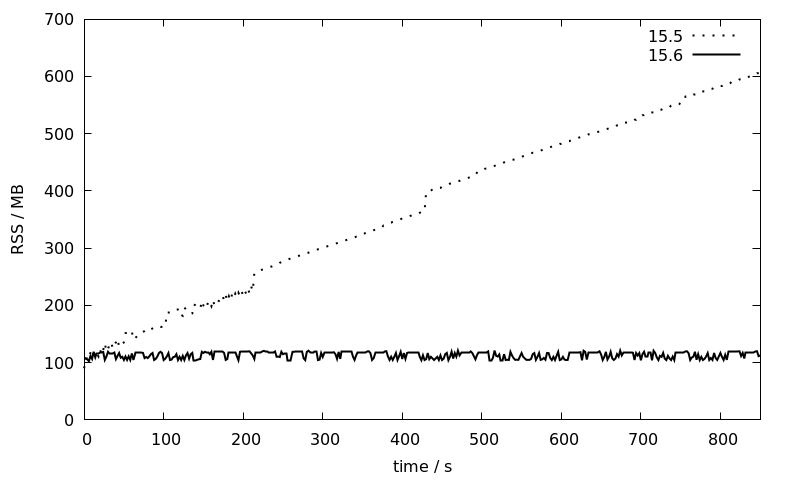
Während der Speicherverbrauch der 15.5-Sitzung linear über die Zeit von 100 auf 600 MB ansteigt, bleibt er bei 15.6 mehr oder weniger konstant bei etwa 100 MB. Dies ist eine große Verbesserung, die JIT für größere Installationen mit lang laufenden Sitzungen, bei denen bisher die übliche Empfehlung darin bestand, JIT vollständig zu deaktivieren, wesentlich nutzbarer machen wird.
Fazit
Das 2024Q1 Patch-Release enthält wichtige Leistungsverbesserungen für die Lock-Skalierbarkeit und den JIT-Speicherverbrauch, die wir in diesem Blogbeitrag demonstriert haben. Darüber hinaus enthält das Patch-Release weitere wichtige Fehlerbehebungen und einen Sicherheitspatch für CVE-2024-0985. Dieses Sicherheitsproblem ist auf materialisierte Views beschränkt, und ein Administrator muss dazu verleitet werden, eine bösartige materialisierte View im Namen eines Angreifers neu zu erstellen. Es hat jedoch einige
Mit der Volltextsuche von PostgreSQL® werden die Indizierung von Dokumenten in natürlicher Sprache und die Identifizierung von indizierten Dokumenten, die einer bestimmten Anfrage entsprechen, erleichtert. Übereinstimmende Dokumente können nach ihrer Relevanz für die Suchanfrage sortiert werden, und es können Auszüge aus den Dokumenten erstellt werden, in denen die übereinstimmenden Begriffe hervorgehoben sind. Es wird eine Reihe von SQL-Datentypen, -Operatoren und -Funktionen bereitgestellt, um die Indizierung, Abfrage und Einstufung von Dokumenten zu unterstützen.
PostgreSQL verwendet den Begriff Dokument für jedes Textfragment in natürlicher Sprache – im Wesentlichen Zeichenfolgen, die lesbare Wörter enthalten und durch Leerzeichen und Interpunktion getrennt sind. Dokumente sind oft als Text-Spalten gespeichert, können aber auch dynamisch erzeugt werden, z. B. durch Verkettung mehrerer Spalten (auch aus mehreren Tabellen).
-- concatenating multiple columns to form a document.
-- the table contains chapters from eBooks, one row per chapter
SELECT book_title || ' ' || book_author || ' ' || title || ' ' || body_html AS document
FROM chapters
Einige Beispiele für natürlichsprachliche Texte sind Blogbeiträge (wie der, den Sie gerade lesen), Bücher, Aufsätze, Benutzerkommentare, Forenbeiträge, Nachrichten in sozialen Medien, E-Mails, Newsgroup- und Chat-Nachrichten, Zeitungs- und Zeitschriftenartikel sowie Produktbeschreibungen in Katalogen. Diese Arten von Dokumenten sind typische Kandidaten für die Indizierung durch die Volltextsuche.
Beachten Sie, dass nicht alle lesbaren Zeichenfolgen natürliche Sprache enthalten. So sind beispielsweise Benutzernamen, Kennwörter und URLs oft lesbar, enthalten aber in der Regel keine natürliche Sprache.
Was gibt es an LIKE nicht zu mögen?
Der Datentyp Text verfügt über mehrere Operatoren zur Durchführung grundlegender Zeichenfolgenmuster-Abgleiche, insbesondere LIKE/ ILIKE (SQL-Platzhalterübereinstimmung unter Beachtung bzw. Nichtbeachtung von Groß- und Kleinschreibung), SIMILAR TO (SQL-Regex) und ~ (POSIX-Regex).
Zwar können mit diesen Operatoren sehr einfache Suchvorgänge durchgeführt werden, jedoch ist der Musterabgleich aufgrund verschiedener Einschränkungen nicht gerade ideal für die Implementierung nützlicher Suchvorgänge. Diesen Operatoren mangelt es an linguistischer Unterstützung, z. B. dem Verstehen der Textstruktur (einschließlich Zeichensetzung), dem Erkennen von Wortvarianten und Synonymen und dem Ignorieren häufig verwendeter Wörter. Sie sind zudem nicht in der Lage, die Ergebnisse nach ihrer Relevanz für die Abfrage zu ordnen, und vor allem können sie aufgrund der begrenzten Indizierungsunterstützung langsam sein.
Um uns mit einigen dieser Einschränkungen zu befassen, sehen wir uns ein paar typische Anforderungen an eine umfassende Suchfunktion einer Anwendung/Website an:
- Die Benutzer geben Suchbegriffe ein, die in Abfragen an die Datenbank umgewandelt werden. Anschließend werden dem Benutzer die Ergebnisse angezeigt.
- Die Suche sollte unabhängig von Groß- und Kleinschreibung erfolgen.
- Wörter in der Abfrage sollten mit Varianten (wie z. B. Suffixen) dieses Wortes im Dokument übereinstimmen, z. B. „cat“ sollte mit „cats“ übereinstimmen (und umgekehrt).
- Dokumente mit verwandten Wörtern/Synonymen sollten gefunden werden, z. B. Dokumente, die „feline“ oder „kitten“ enthalten, sollten bei der Suche nach „cat“ ebenfalls gefunden werden.
- Es kann nach Phrasen gesucht werden (oft in doppelten Anführungszeichen, z. B.
„the fat black cat“). - Die Benutzer können bestimmte Wörter markieren, die ausgeschlossen werden sollen (z. B., indem sie dem Wort einen Bindestrich voranstellen:
cat -fat). - Die Ergebnisse sind nach einer Art Relevanzmetrik geordnet, die sich auf die Suchanfrage des Nutzers bezieht. Wenn z. B. ein Dokument das Wort „cat“ (oder Varianten davon) mehrfach enthält und ein anderes Dokument „cat“ nur einmal erwähnt, wird das erste Dokument höher eingestuft.
Diese Anforderungen wurden absichtlich vage gehalten, da sie oft von den Details der Anwendung abhängen.
Für die folgenden Beispielabfragen wurden folgende Tabellendefinition und Daten verwendet:
CREATE TABLE example AS
SELECT * FROM (
VALUES ('the fat black cat chased after the rat'),
('one cat, two cats, many cats!'),
('the kitten and the dog played together'),
('that is one fine feline'),
('it is raining cats and dogs'),
('after eating the whole lasagne, he was a fat cat.'),
('don''t go into the catacombs after dark'),
('the bobcat has a spotted coat'),
('check the library catalog'),
('for a filesystem with deduplication look at zfs'),
('add one or more predicates to the query')
) AS t (document);
Würde die Anwendung Suchvorgänge mit dem ILIKE-Operator (der die Groß- und Kleinschreibung nicht berücksichtigt) durchführen, könnte die Abfrage eines Benutzers nach „cat“ in SQL wie folgt umgeschrieben werden: ILIKE '%cat%'. Damit würde jedes Dokument gefunden werden, das die Zeichenfolge „cat“ enthält. Diese Abfrage findet jedoch auch Dokumente mit Wörtern, die die Teilzeichenfolge „cat“ enthalten. Einige Übereinstimmungen, wie z. B. „cats“ wären relevant für die Anfrage. Andere, wie „cathode“, „catalog“, „deduplication“ und „predicate“, sind jedoch eher keine relevanten Ergebnisse.
-- this finds too many irrelevant results.
SELECT document, document ILIKE '%cat%' AS matches FROM example;
+-------------------------------------------------+-------+
|document |matches|
+-------------------------------------------------+-------+
|the cat chased after the rat |true |
|one cat, two cats, many cats! |true |
|the kitten and the dog played together |false |
|that is one fine feline |false |
|it is raining cats and dogs |true |
|after eating the whole lasagne, he was a fat cat.|true |
|don't go into the catacombs after dark |true |
|the bobcat has a spotted coat |true |
|check the library catalog |true |
|for a filesystem with deduplication look at zfs |true |
|add one or more predicates to the query |true |
+-------------------------------------------------+-------+
Der Versuch, die Abfrage mit ILIKE '% cat %' einzugrenzen, macht die Sache auch nicht besser. Wörter wie „catacombs“ und „deduplication“ sind zwar keine Treffer mehr. Aber auch wird „cats“ nicht mehr gefunden, und Sätze, die mit „cat“ beginnen und enden, sowie Satzzeichen außer Leerzeichen verursachen ebenfalls Probleme – „cat!“, „cat,“ und „cat.“ werden ignoriert.
-- too specific. doesn't even match 'cats'.
SELECT document, document ILIKE '% cat %' AS matches FROM example
+-------------------------------------------------+-------+ |document |matches| +-------------------------------------------------+-------+ |the cat chased after the rat |true | |one cat, two cats, many cats! |false | |the kitten and the dog played together |false | |that is one fine feline |false | |it is raining cats and dogs |false | |after eating the whole lasagne, he was a fat cat.|false | |don't go into the catacombs after dark |false | |the bobcat has a spotted coat |false | |check the library catalog |false | |for a filesystem with deduplication look at zfs |false | |add one or more predicates to the query |false | +-------------------------------------------------+-------+
ILIKE ist ebenfalls wenig hilfreich bei der Suche nach Synonymen oder verwandten Wörtern. Wenn die Anwendung für die Abfrage „cat“ Dokumente finden möchte, die „feline“, „kitten“ und „cat“ enthalten, müssen in SQL zusätzliche ILIKE-Operatoren mit OR verbunden werden. Einige Wörter können viele Varianten haben, was diesen Ansatz mühsam macht.
-- this still has all the other shortcomings to, such as '%cat%' matching too many results
SELECT document, (document ILIKE '%cat%' OR document ILIKE '%kitten%' OR document ILIKE '%feline%') AS matches FROM example;
Und schließlich gibt ILIKE nur einen booleschen Wert zurück, der angibt, ob eine Zeichenfolge mit dem Muster übereinstimmt. Er liefert keine Bewertungsmetrik, mit der die Ergebnisse nach Relevanz eingestuft werden können.
Ähnliche Probleme gibt es mit den Regex-Operatoren. Sie sind zwar leistungsfähiger als LIKE, und bestimmte Schwachpunkte von LIKE können mit kreativen Regex-Mustern behoben werden, aber sie führen noch immer einen Musterabgleich durch und haben die gleichen grundlegenden Einschränkungen.
Um die Einschränkungen dieser Operatoren zu umgehen, müsste man wahrscheinlich große Teile der in PostgreSQL integrierten Volltextsuche neu implementieren! Sehen wir uns stattdessen an, was PostgreSQL zu bieten hat.
Grundlagen der Volltextsuche
Dokumente für die Suche vorbereiten
Die Volltextsuche von PostgreSQL arbeitet nicht direkt mit Dokumenten, die mit dem Datentyp text gespeichert sind. Stattdessen müssen die Dokumente zunächst in den Datentyp tsvector, ein für die Suche optimiertes Format, konvertiert werden.
Um ein Dokument, das als text gespeichert ist, in tsvector zu konvertieren, sollte die Funktion to_tsvector verwendet werden:
to_tsvector([ config regconfig, ] document text) → tsvector
Die Funktion to_tsvector führt eine Reihe von Verarbeitungsschritten am Dokumententext durch. Auf oberster Ebene unterteilt to_tsvector das Dokument zunächst mit einem Parser in Wörter. Jedes Wort wird dann in einem oder mehreren Wörterbüchern nachgeschlagen. Ein Wörterbuch ist eine Zuordnung von Wörtern zu ihren normalisierten Formen. Diese normalisierten Formen werden Lexeme genannt. Wenn das Wort mit einem Wörterbucheintrag übereinstimmt, wird das Lexem dieses Eintrags dem tsvector hinzugefügt.
Der resultierende tsvector ist eine alphabetisch geordnete Sammlung von Lexemen, die im Quelldokument vorhanden sind. Jedes Lexem im tsvector enthält außerdem Positionsinformationen. Dies ist eine Liste von Ganzzahlen, die die Position jedes Quellworts angeben. Diese Positionsinformationen sind für die Suche nach Phrasen erforderlich und dienen dazu, Übereinstimmungen anhand ihrer Nähe in eine Rangfolge zu bringen.
Der Prozess der Normalisierung von Wörtern in Lexeme ist wörterbuchspezifisch, umfasst aber fast immer eine Umwandlung aller Großbuchstaben in Kleinbuchstaben und die Entfernung von Suffixen, um Wörter auf ihre Stammform zu reduzieren (aus „cats“ wird z. B. „cat“). Es können anwendungsspezifische Wörterbücher erstellt werden, mit denen der Normalisierungsprozess angepasst werden kann (z. B., um domänenspezifische Synonyme und Phrasen einem gemeinsamen Begriff zuzuordnen, wie „kitten“ und „feline“ zu „cat“). Dieser Normalisierungsprozess beschleunigt und vereinfacht das Auffinden aller Varianten eines Wortes, ohne dass jede Variante in der Abfrage angegeben werden muss.
Wörterbücher enthalten zudem in der Regel keine Einträge für sehr häufig gebrauchte Wörter (wie „der“ oder „und“). Diese allgemeinen Wörter werden Stoppwörter genannt und sind für die Suche nicht besonders nützlich. Indem sie übersprungen werden, wird der generierte tsvector kleiner, was die Leistung verbessert.
Die Wahl des Parsers und der Wörterbücher wird als Konfiguration bezeichnet und kann mit dem Parameter config für to_tsvector angegeben werden. Dieser Parameter ist optional, es empfiehlt sich aber, ihn immer anzugeben, um sicherzustellen, dass die richtige Konfiguration verwendet wird. Wird er weggelassen, kommt der globale Wert default_text_search_config zum Einsatz. Zwar gibt es verschiedene Standardkonfigurationen ( \dF in psql zeigt eine Liste an), aber meist sollte die Konfiguration angepasst werden.
In Abschnitt 20.11.2 und Abschnitt 12.1.3 der PostgreSQL-Dokumentation finden Sie genauere Details über die Option default_text_search_config und zur Konfiguration der Textsuche im Allgemeinen.
Hier ist ein Beispiel für den Aufruf von to_tsvector für ein Textfragment mithilfe der integrierten Konfiguration english:
SELECT to_tsvector('english', 'Hello world. ' ||
'The quick brown fox jumped over the lazy dog. ' ||
'Cats and kittens (and dogs too) love to chase mice. ' ||
'Hello world!')
Das Ergebnis ist der folgende tsvector:
'brown':5 'cat':12 'chase':20 'dog':11,16 'fox':6 'hello':1,22 'jump':7 'kitten':14 'lazi':10 'love':18 'mice':21 'quick':4 'world':2,23
Alle Lexeme wurden in Kleinbuchstaben umgewandelt, und mehrere Wörter wurden auf ihren Wortstamm reduziert („cats“ → „cat“). Die Satzzeichen („!“ und „.“) und Stoppwörter („the“, „and“ und „to“) wurden entfernt. Wörter, die mehrfach in der Eingabe vorkommen („dog“, „hello“ und „world“), haben mehr als einen Positionseintrag.
Die Erstellung von benutzerdefinierten Konfigurationen und Wörterbüchern ist nicht Gegenstand dieses Artikels.
Abfragen schreiben
Die Volltextsuche von PostgreSQL verwendet eine spezialisierte Mini-Abfragesprache (DSL), die das Schreiben komplexer und fortgeschrittener Abfragen ermöglicht, wobei boolesche Logik, Gruppierung und Phrasen-/Umgebungssuche kombiniert werden. Eine in dieser DSL geschriebene Abfrage wird mit dem Datentyp tsquery gespeichert. Abfragen, die als tsquery gespeichert sind, können hinsichtlich des tsvector eines Dokuments ausgewertet werden, um festzustellen, ob das Dokument der Abfrage entspricht.
Die DSL besteht aus einzelnen Lexemen, die durch Operatoren getrennt werden. Mithilfe von Klammern können Operatoren und Lexeme gruppiert werden, um Vorrang/Bindung zu erzwingen. In Abschnitt 8.11.2 der PostgreSQL-Dokumentation finden Sie eine detaillierte Dokumentation der tsquery-DSL.
| Symbol | Operator | Arity | Precedence |
& | Boolean AND | Binary | Lowest |
| | Boolean OR | Binary | Lowest |
!</ | Boolean NOT | Unary | Highest |
<N> | Followed By (where N is a positive number) | Binary | High |
<-> | Followed By (equivalent to <1>) | Binary | High |
Boolesches UND prüft, ob beide Lexeme im Dokument vorhanden sind. Es wird eine Übereinstimmung gefunden, wenn beide Lexeme vorhanden sind.
Boolesches ODER prüft, ob eines oder beide Lexeme im Dokument vorhanden sind. Eine Übereinstimmung wird gefunden, wenn eines der beiden Lexeme vorhanden ist.
Boolesches NICHT prüft, ob das Lexem nicht im Dokument vorhanden ist. Eine Übereinstimmung wird gefunden, wenn das Lexem nicht vorhanden ist.
Followed by prüft, ob beide Lexeme im Dokument vorhanden sind und ob der Abstand zwischen den beiden Lexemen dem angegebenen Wert entspricht. Eine Übereinstimmung wird gefunden, wenn die beiden Lexeme existieren und genau N Wörter voneinander entfernt sind.
Es gibt eine Reihe von Funktionen zur Umwandlung von Abfragetext in eine tsquery: to_tsquery, plainto_tsquery, phraseto_tsquery und websearch_to_tsquery.
Jede dieser Funktionen führt eine Normalisierung und die Entfernung von Stoppwörtern am eingegebenen Abfragetext durch, und zwar mit dem gleichen Verfahren wie bei to_tsvector. Das Parsen des Abfragetextes ist von der Funktion abhängig.
to_tsquery
to_tsquery([ config regconfig, ] querytext text) → tsquery
to_tsquery versteht die vollständige DSL. Die Funktion erwartet, dass die Eingabe wohlgeformt ist und der Syntax von tsquery folgt. Alle Syntaxfehler werden zu SQL-Ausnahmen.
SELECT to_tsquery('english', 'The & Quick & Brown & Foxes')
'quick' & 'brown' & 'fox'
plainto_tsquery
plainto_tsquery([ config regconfig, ] querytext text) → tsquery
plainto_tsquery gibt eine Abfrage zurück, die prüft, ob alle Nicht-Stoppwort-Lexeme im Dokument vorhanden sind. Die Funktion analysiert den Abfragetext mit demselben Verfahren wie to_tsvector. Die resultierenden Lexeme werden mit dem booleschen Operator UND kombiniert.
SELECT plainto_tsquery('english', 'Jumped Over The Lazy Dogs')
'jump' & 'lazi' & 'dog'
phraseto_tsquery
phraseto_tsquery([ config regconfig, ] querytext text) → tsquery
phraseto_tsquery gibt eine Abfrage zurück, die prüft, ob die angegebene Phrase im Dokument existiert. Dies ist nützlich für die „Phrasensuche“. Es verhält sich ähnlich wie phraseto_tsquery mit dem Unterschied, dass die Lexeme mit dem Operator Followed By kombiniert werden. Wenn zwischen den Lexemen im Dokument Stoppwörter vorhanden sind, wird dies durch den Operator Followed By berücksichtigt.
SELECT phraseto_tsquery('english', 'Jumped Over The Lazy Dogs')
'jump' <3> 'lazi' <-> 'dog'
In diesem Beispiel werden „over“ und „the“ als Stoppwörter betrachtet. „lazy“ ist das dritte Wort nach „jumped“, daher hat der Followed By Operator zwischen den Lexemen „jump“ und „lazi“ einen Distanzwert von 3. „dogs“ folgt unmittelbar auf „lazy“, so dass der Operator Followed By zwischen den Lexemen „lazi“ und „dog“ einen Abstand von 1 hat.
websearch_to_tsquery
websearch_to_tsquery([ config regconfig, ] querytext text) → tsquery
websearch_to_tsquery funktioniert ein wenig anders als die anderen to_tsquery-Funktionen. Sie versteht eine alternative Syntax, bei der es sich um eine grundlegende Variante dessen handelt, was üblicherweise in Web-Suchmaschinen verfügbar ist. Sie kombiniert Teile von plainto_tsquery und phraseto_tsquery, wobei sie auch einige grundlegende Operatoren versteht.
Phrasen ohne Anführungszeichen werden in Lexeme umgewandelt, die mit dem Booleschen UND (wie in plainto_tsquery) verbunden sind. Phrasen mit doppelten Anführungszeichen werden in Lexeme umgewandelt, die mit Followed By (wie in phraseto_tsquery) verbunden sind. or und - (ein Bindestrich) werden in Boolesches ODER bzw. Boolesches NICHT umgewandelt.
SELECT query_text, websearch_to_tsquery(query_text)
FROM (VALUES
('the quick brown fox'),
('"the quick brown fox"'),
('brown or fox'),
('"quick brown" fox -jumped')
) AS t(query_text)
+-------------------------+-------------------------------------+
|query_text |websearch_to_tsquery |
+-------------------------+-------------------------------------+
|the quick brown fox |'quick' & 'brown' & 'fox' |
|"the quick brown fox" |'quick' <-> 'brown' <-> 'fox' |
|brown or fox |'brown' | 'fox' |
|"quick brown" fox -jumped|'quick' <-> 'brown' & 'fox' & !'jump'|
+-------------------------+-------------------------------------+
websearch_to_tsquery ist wahrscheinlich die am besten geeignete integrierte Funktion für die Erstellung einer tsquery aus Benutzereingaben.
Beachten Sie, dass „Phrasensuche“-Abfragen, die Followed By Operatoren verwenden, wie die von phraseto_tsquery und websearch_to_tsquery, manchmal unerwartete Ergebnisse liefern können. Näheres hierzu unter Ungenaue Phrasensuche weiter unten.
Abfragen auswerten
Eine tsquery kann hinsichtlich eines tsvector ausgewertet werden, um festzustellen, ob das Dokument der Abfrage entspricht. Die Auswertung erfolgt mithilfe des SQL-Operators @@. Dieser Operator nimmt eine tsquery und einen tsvector (in beliebiger Reihenfolge) als Operanden und gibt einen booleschen Wert zurück, der angibt, ob eine Übereinstimmung vorliegt.
tsvector @@ tsquery → boolean
tsquery @@ tsvector → boolean
Hier wird beispielsweise ein Dokument über eine tsquery mit einem einzelnem Lexem nach einem Wort durchsucht:
WITH input AS (
SELECT to_tsvector('english', 'The quick brown fox jumped over the lazy dog.') AS document,
to_tsquery('english', 'Dogs') AS query
)
SELECT document, query, document @@ query AS matches FROM input;
+-----------------------------------------------------+-----+-------+
|document |query|matches|
+-----------------------------------------------------+-----+-------+
|'brown':3 'dog':9 'fox':4 'jump':5 'lazi':8 'quick':2|'dog'|true |
+-----------------------------------------------------+-----+-------+
In diesem Fall entspricht „dogs“ dem Wort „dog“, da „dogs“ in der Abfrage auf das Lexem „dog“ normalisiert ist, das auch im Dokument vorhanden ist.
Wie erwartet, wenn die tsquery nicht mit dem tsvector übereinstimmt, gibt der Operator @@ false zurück.
WITH input AS (
SELECT to_tsvector('english', 'The quick brown fox jumped over the lazy dog.') AS document,
websearch_to_tsquery('english', 'cats or kittens') AS query
)
SELECT document, query, document @@ query AS matches FROM input;
+-----------------------------------------------------+----------------+-------+
|document |query |matches|
+-----------------------------------------------------+----------------+-------+
|'brown':3 'dog':9 'fox':4 'jump':5 'lazi':8 'quick':2|'cat' | 'kitten'|false |
+-----------------------------------------------------+----------------+-------+
Um die Abfrage etwas komplexer zu gestalten, wird hier ein Dokument nach einer Phrase durchsucht:
WITH input AS (
SELECT to_tsvector('english', 'The quick brown fox jumped over the lazy dog.') AS document,
phraseto_tsquery('english', 'Jumped Over The Lazy') AS query
)
SELECT document, query, document @@ query AS matches FROM input;
+-----------------------------------------------------+-----------------+-------+
|document |query |matches|
+-----------------------------------------------------+-----------------+-------+
|'brown':3 'dog':9 'fox':4 'jump':5 'lazi':8 'quick':2|'jump' <3> 'lazi'|true |
+-----------------------------------------------------+-----------------+-------+
Und wie erwartet, wird eine Übereinstimmung gefunden.
Dokumente ablegen und indizieren
Bislang haben wir gesehen, wie man Dokumente in tsvector sowie Abfragetext in tsquery konvertiert und wie man sie miteinander kombiniert, um festzustellen, ob ein Dokument einer Abfrage entspricht. Die Beispiele waren jedoch nur auf ein einziges Dokument bezogen, und der Text des Dokuments wurde immer linear eingefügt.
Typischer bei der Volltextsuche ist es jedoch, eine ganze Tabelle von Dokumenten in einem Durchgang zu durchsuchen:
SELECT title FROM documents WHERE to_tsvector(body) @@ to_tsquery('...')
Ohne die entsprechenden Indizes wird nun to_tsvector bei jedem SELECT auf den Inhalt der Spalte angewendet. Die Ausführung in jeder Zeile einer großen Tabelle bei jeder Suche führt zu einer miserablen Leistung.
Einen Ausdrucksindex hinzuzufügen, ist eine Möglichkeit, die Leistung zu verbessern. Wie dies im Einzelnen erfolgt, soll jedoch dem Leser überlassen bleiben (siehe Abschnitt 12.2.2. Creating Indexes der PostgreSQL-Dokumentation). Wir betrachten den unten beschriebenen Ansatz, bei dem eine separate, generierte tsvector-Spalte verwendet wird, der eine Reihe von Vorteilen gegenüber einem reinen Ausdrucksindex-basierten Ansatz bietet, insbesondere eine bessere Leistung. Bei der Verwendung von Indizes muss to_tsvector möglicherweise erneut ausgeführt werden, um Indexübereinstimmungen zu überprüfen.
Da tsvector ein Datentyp ist, kann in einer Tabelle eine Spalte vom Typ tsvector erstellt werden, in der die Ergebnisse von to_tsvector gespeichert werden. Deshalb ist es üblich, den tsvector des Dokuments zusammen mit dem Original zu speichern:
CREATE TABLE documents (
name text PRIMARY KEY,
body text NOT NULL,
tsv tsvector NOT NULL
);
Die tsvector-Spalte als GENERATED (PostgreSQL 12 und höher) zu markieren, vereinfacht die Dinge für Client-Anwendungen, wenn sie ein INSERT oder UPDATE durchführen. Bei älteren Versionen von PostgreSQL, die keine Unterstützung für generierte Spalten bieten, sind zwei Trigger-Funktionen enthalten, die dazu dienen, den tsvector aus anderen Spalten in einer Tabelle zu generieren (siehe Abschnitt 12.4.3. Triggers for Automatic Updates der PostgreSQL-Dokumentation). Natürlich kann auch eine benutzerdefinierte Trigger-Funktion verwendet werden. Die spezifischen Vor- und Nachteile von GENERATED-Spalten im Vergleich zu BEFORE INSERT- ODER UPDATE-Triggern sind nicht Gegenstand dieses Artikels. Wir sind jedoch der Meinung, dass generierte Spalten einfacher zu verstehen sind und verwendet werden sollten, solange die Einschränkungen der generierten Spalten die Verwendung von Trigger-Funktionen erzwingen.
-- using GENERATED
CREATE TABLE documents_generated (
name text PRIMARY KEY,
body text NOT NULL,
tsv tsvector NOT NULL GENERATED ALWAYS AS (to_tsvector('english', name || ' ' || body)) STORED
);
Anschließend kann ein Index über die tsvector-Spalte generiert werden, um Abfragen zu beschleunigen:
CREATE INDEX textsearch_idx ON documents USING GIN (tsv);
Sobald die tsvector-Spalte eingerichtet ist, kann sie ganz normal in Abfragen verwendet werden:
SELECT title FROM documents WHERE tsv @@ to_tsquery('...')
Und das war es auch schon mit der einfachen Textsuche. Zusammenfassend kann man sagen, dass es 3 Hauptschritte gibt:
- Jedes Dokument wird in einen
tsvectorkonvertiert, wofürto_tsvectorverwendet wird. Normalerweise wird dies einmal bei INSERT/UPDATE durchgeführt, und der resultierendetsvectorwird in einer Spalte neben dem Originaldokument gespeichert. Indizes für diese Spalte beschleunigen die Suche. - Der Abfragetext wird in eine
tsquerymit einer der...to_tsquery-Funktionen konvertiert. - Die
tsquerywird hinsichtlich destsvectordes Dokuments ausgewertet, wofür der Operator@@verwendet wird.
Einige Fallstricke
Text in tsvector/tsquery umwandeln
Es ist möglich, Text direkt in tsvector und tsquery umzuwandeln. Das Ergebnis ist allerdings nicht, was Sie erwarten!
Wie die meisten PostgreSQL-Datentypen haben tsvector und tsquery ein kompaktes binäres Format und eine textuelle Darstellung. Die Umwandlung von Text erwartet eine Zeichenfolge im textuellen Darstellungsformat von tsvector/ tsquery (siehe Abschnitt 8.11. Text Search Types der PostgreSQL-Dokumentation). Wenn die Zeichenfolge wohlgeformt ist, klappt die Umwandlung, aber es werden keine Stoppwörter entfernt, Wörter normalisiert oder andere Vorverarbeitungsschritte durchgeführt – es wird davon ausgegangen, dass die Lexeme in der Eingabe bereits normalisiert wurden.
WITH input AS (
SELECT 'the QuIcK brown!! fox'::tsvector AS document,
plainto_tsquery('quick brown fox') AS query
)
SELECT document, query, document @@ query AS matches FROM input
+-----------------------------+-------------------------+-------+
|document |query |matches|
+-----------------------------+-------------------------+-------+
|'QuIcK' 'brown!!' 'fox' 'the'|'quick' & 'brown' & 'fox'|false |
+-----------------------------+-------------------------+-------+
Ungenaue Phrasensuche
Die Phrasensuche verhält sich möglicherweise nicht wie erwartet, wenn der Abfragetext Stoppwörter enthält.
Im folgenden Beispiel berücksichtigt die integrierte english-Konfiguration „over“ und „the“ als Stoppwörter, und phraseto_tsquery ersetzt sie durch den Operator Followed By mit Distanz 3 ( <3>). Folglich stimmt diese Abfrage mit jedem Dokument überein, in dem das Lexem „jump“, gefolgt von zwei beliebigen Wörtern, z. B. „lazi“, vorkommt:
WITH input AS (
SELECT to_tsvector('english', 'The quick brown fox jumped past a lazy dog. ') AS document,
phraseto_tsquery('english', 'Jumped Over The Lazy') AS query
)
SELECT document, query, document @@ query AS matches FROM input;
+--------------------------------------------------------------+-----------------+-------+
|document |query |matches|
+--------------------------------------------------------------+-----------------+-------+
|'brown':3 'dog':9 'fox':4 'jump':5 'lazi':8 'past':6 'quick':2|'jump' <3> 'lazi'|true |
+--------------------------------------------------------------+-----------------+-------+
Hier passt „jumped over the lazy“ zu „jumped past a lazy dog“. Der Abgleich ist erfolgreich, weil der tsvector die Lexeme „jump“ und „lazi“ an den Positionen 5 bzw. 8 enthält – ein Abstand von 3 Wörtern.
Einschränkungen
| Limit | Value | Behaviour |
| Size of each individual lexeme | 2047 bytes | SQL ERROR raised |
Total size of a tsvector.This includes lexemes and positional information. (type binary repr/on-disk size, for details see ts_type.h) | 1048575 bytes (~1MiB) | SQL ERROR raised |
Total number of lexemes per tsvector | 264 | unknown (size limit is reached first) |
Total number of position entries per lexeme per tsvector | 255 | Position entries after 255th are discarded |
| Maximum value of a lexeme position entry | 16383 | Values greater than 16383 are rounded to 16383 |
Total number of lexemes and operators (nodes) per tsquery | 32768 | SQL ERROR raised |
Bei der Verwendung der PostgreSQL-Volltextsuche gibt es eine Reihe von Einschränkungen zu beachten.
Solange Sie nicht versuchen, einen Artikel über das längste englische Wort der Welt zu indizieren (der chemische Name für Titin, der ~189819 Buchstaben lang ist!), ist es unwahrscheinlich, dass Sie die Grenze der Lexemgröße erreichen. Die Indizierung großer Textfragmente kann jedoch die Größenbeschränkung für tsvector von ~1 MiB überschreiten. Beachten Sie, dass diese Grenze auf der Größe der Binärdarstellung basiert (die zur Speicherung eines tsvector im Speicher und auf der Festplatte verwendet wird). Eine typische Abhilfemaßnahme ist, das Dokument in einzelne Abschnitte aufzuteilen (z. B. bei Büchern in Kapitel).
Wenn Ihre Anwendung die Phrasensuche verwenden soll, achten Sie sorgfältig auf die Beschränkungen von tsvector im Hinblick auf Lexempositionen. Es wird kein Fehler und keine Warnung ausgegeben, wenn einer dieser Grenzwerte bei der Generierung von tsvector erreicht wird. Ein tsvector kann nur 255 Positionseinträge pro Lexem speichern. Wenn ein Lexem mehr als 255-mal in einem Dokument vorkommt, werden nur die ersten 255 Positionen gespeichert. Jeder dieser Positionseinträge hat zudem einen Maximalwert, der auf 16.383 begrenzt ist. Wenn ein Lexem nach der 16.383. Position im Dokument auftritt, wird seine Position auf 16.383 gerundet. Beachten Sie, dass Stoppwörter zwar nicht im tsvector enthalten sind, die Lexempositionen jedoch beeinflussen.
Gesamtzahl der Lexeme pro tsvector
Im folgenden Beispiel wird das Wort „fox“ 300-mal im Quelldokument wiederholt, aber nur 255 Positionen werden im tsvector aufgezeichnet. ( unnest ist eine integrierte Hilfsfunktion, die einen tsvector in eine Tabelle umwandelt, sodass verschiedene Abfragen darauf durchgeführt werden können.)
WITH document AS (
SELECT repeat('fox ', 300) as body
), lexemes AS (
SELECT (unnest(to_tsvector(document.body))).* FROM document
), positions AS (
SELECT lexeme, unnest(positions) AS position FROM lexemes
)
SELECT * FROM positions
+------+--------+
|lexeme|position|
+------+--------+
|fox |1 |
|fox |2 |
|fox |3 |
|fox |4 |
|fox |254 |
|fox |255 |
+------+--------+
Maximaler Wert eines Eintrags für eine Lexemposition
Hier wird ein Dokument, bestehend aus „hello“, gefolgt von 20.000 Kopien von „the“ und endend mit „world“, in einen tsvector umgewandelt. „the“ wurde als Lückenfüller gewählt, weil es ein Stoppwort ist. Wenngleich kein Lexem für „the“ im tsvector vorhanden ist, beeinflusst es dennoch die Lexempositionen von „hello“ und „world“. „world“ ist das 20.001. Wort im Dokument, doch da die maximale Positionswertgrenze erreicht ist, rundet PostgreSQL den Positionswert auf 16.383:
WITH document AS (
SELECT 'hello ' || repeat('the ', 20000) || 'world' as body
), lexemes AS (
SELECT (unnest(to_tsvector(document.body))).* FROM document
), positions AS (
SELECT lexeme, unnest(positions) AS position FROM lexemes
)
SELECT * FROM positions
+------+--------+
|lexeme|position|
+------+--------+
|hello |1 |
|world |16383 |
+------+--------+
Beispiel für Einschränkungen der Phrasensuche und großer Dokumente
Die Phrasensuche arbeitet bei großen Textfragmenten möglicherweise unzuverlässig, da die Informationen zur Lexemposition entweder falsch sind (auf 16.383 gerundet) oder ganz fehlen, wie das folgende Beispiel zeigt:
SELECT name,
to_tsvector(t.body) @@ phraseto_tsquery('hello world') AS phrase_matches,
to_tsvector(t.body) @@ plainto_tsquery('hello world') AS plain_matches
FROM (
VALUES ('phrase', 'hello world'),
('positions discarded', repeat('hello ', 300) || ' hello world'),
('positions rounded', repeat('the ', 20000) || ' hello world')
) AS t(name, body)
+-------------------+--------------+-------------+
|name |phrase_matches|plain_matches|
+-------------------+--------------+-------------+
|phrase |true |true |
|positions discarded|false |true |
|positions rounded |false |true |
+-------------------+--------------+-------------+
In den beiden Tests positions discarded und positions rounded steht phrase_matches auf false, weil der Operator Followed By (wie von phraseto_tsquery generiert) den tsvector prüft und auf der Grundlage der verfügbaren Informationen fälschlicherweise schlussfolgert, dass es keinen Fall gibt, in dem ein „world“-Lexem direkt auf ein „hello“ folgt (d. h. eine Positionsdifferenz von 1 hat).
Der Phrasentest für positions discarded schlägt fehl, weil nur die ersten 255 Positionseinträge des Lexems „hello“ im tsvector behalten werden. Die letzte aufgezeichnete „hello“-Position ist 255, aber „world“ hat eine Position von 301, was eine Differenz von 46 ergibt.
Der Phrasentest positions rounded schlägt fehl, weil die 20.000 Instanzen des Stoppworts „the“ die Positionswerte der Lexeme „hello“ und „world“ beeinflussen. Beide Positionswerte überschreiten 16.383 und werden auf diesen Wert gerundet, sodass sie eine Differenz von 0 haben.
Erweiterte Ranking-Strategien
Ein wesentlicher Vorteil der PostgreSQL-Volltextsuche gegenüber einfachen LIKE-Operatoren ist die Möglichkeit, Suchergebnisse nach ihrer Relevanz zu bewerten und zu sortieren. PostgreSQL bietet hierfür mehrere integrierte Ranking-Funktionen, die verschiedene Aspekte der Dokumentenrelevanz berücksichtigen.
ts_rank() – Grundlegendes Relevanz-Scoring
Die Funktion ts_rank() berechnet einen numerischen Relevanz-Score basierend auf der Häufigkeit der übereinstimmenden Lexeme im Dokument:
ts_rank([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) → float4Hier ist ein praktisches Beispiel, das zeigt, wie Dokumente nach Relevanz sortiert werden können:
WITH documents AS (
SELECT * FROM (VALUES
('Ein Artikel über Katzen und ihre Gewohnheiten'),
('Katzen sind wunderbare Haustiere. Katzen lieben es zu spielen.'),
('Der Hund und die Katze spielten zusammen im Garten'),
('Katzenfutter ist wichtig für die Gesundheit von Katzen')
) AS t(content)
)
SELECT
content,
ts_rank(to_tsvector('german', content),
to_tsquery('german', 'Katzen')) as relevance_score
FROM documents
WHERE to_tsvector('german', content) @@ to_tsquery('german', 'Katzen')
ORDER BY relevance_score DESC;
+----------------------------------------------------------+----------------+
|content |relevance_score |
+----------------------------------------------------------+----------------+
|Katzen sind wunderbare Haustiere. Katzen lieben es zu... |0.30396757 |
|Katzenfutter ist wichtig für die Gesundheit von Katzen |0.15198378 |
|Ein Artikel über Katzen und ihre Gewohnheiten |0.15198378 |
|Der Hund und die Katze spielten zusammen im Garten |0.15198378 |
+----------------------------------------------------------+----------------+ts_rank_cd() – Cover Density Ranking
Die Funktion ts_rank_cd() verwendet einen anderen Algorithmus, der die „Cover Density“ berechnet – wie dicht die Suchbegriffe im Dokument beieinander stehen:
ts_rank_cd([ weights float4[], ] vector tsvector, query tsquery [, normalization integer ]) → float4Diese Funktion ist besonders nützlich für Phrasensuchen oder wenn die Nähe der Suchbegriffe zueinander wichtig ist:
SELECT
content,
ts_rank_cd(to_tsvector('german', content),
to_tsquery('german', 'Katzen & Hund')) as density_score
FROM documents
WHERE to_tsvector('german', content) @@ to_tsquery('german', 'Katzen & Hund')
ORDER BY density_score DESC;Gewichtete Suche für verschiedene Dokumentbereiche
In realen Anwendungen haben verschiedene Teile eines Dokuments unterschiedliche Wichtigkeit. Ein Treffer im Titel sollte höher bewertet werden als ein Treffer im Fließtext. PostgreSQL unterstützt dies durch gewichtete tsvector-Erstellung:
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title TEXT,
summary TEXT,
content TEXT,
search_vector tsvector GENERATED ALWAYS AS (
setweight(to_tsvector('german', coalesce(title,'')), 'A') ||
setweight(to_tsvector('german', coalesce(summary,'')), 'B') ||
setweight(to_tsvector('german', coalesce(content,'')), 'C')
) STORED
);Die Gewichtungen A, B, C, D entsprechen verschiedenen Wichtigkeitsstufen, wobei A die höchste Priorität hat. Bei der Ranking-Berechnung können diese Gewichtungen berücksichtigt werden:
SELECT title,
ts_rank('{0.1, 0.2, 0.4, 1.0}', search_vector, query) as weighted_rank
FROM articles, to_tsquery('german', 'PostgreSQL') query
WHERE search_vector @@ query
ORDER BY weighted_rank DESC;Benutzerdefinierte Ranking-Algorithmen
Für komplexere Anwendungsfälle können Sie eigene Ranking-Algorithmen entwickeln, die mehrere Faktoren kombinieren:
SELECT
title,
content,
(
ts_rank(search_vector, query) * 0.5 + -- Grundrelevanz
(CASE WHEN title ILIKE '%PostgreSQL%' THEN 0.3 ELSE 0 END) + -- Titel-Boost
(extract(days from (CURRENT_DATE - created_at)) * -0.01) -- Aktualitäts-Faktor
) as custom_score
FROM articles, to_tsquery('german', 'PostgreSQL') query
WHERE search_vector @@ query
ORDER BY custom_score DESC;Normalisierung und Performance-Optimierung
Beide Ranking-Funktionen unterstützen einen optionalen Normalisierungsparameter, der die Scores an die Dokumentlänge anpasst:
- 0 (Standard): Keine Normalisierung
- 1: Durch 1 + Logarithmus der Dokumentlänge dividieren
- 2: Durch Dokumentlänge dividieren
- 4: Durch mittlere harmonische Distanz zwischen Extents dividieren
- 8: Durch Anzahl eindeutiger Wörter im Dokument dividieren
- 16: Durch 1 + Logarithmus der eindeutigen Wörter dividieren
- 32: Durch Rang + 1 dividieren
Diese Werte können kombiniert werden, indem sie addiert werden:
SELECT title,
ts_rank(search_vector, query, 1|2|8) as normalized_rank
FROM articles, to_tsquery('german', 'PostgreSQL') query
WHERE search_vector @@ query
ORDER BY normalized_rank DESC;Für optimale Performance bei großen Datenmengen sollten Sie Indizes auf den berechneten Ranking-Werten in Betracht ziehen und die Ranking-Berechnung nur für bereits gefilterte Ergebnisse durchführen.
Testen Sie die PostgreSQL®-Volltextsuche
Die in PostgreSQL integrierten Volltextsuchfunktionen sind mehr als geeignet, um grundlegende Textsuchfunktionen für eine Anwendung zur Verfügung zu stellen. Entwickler greifen oft zuerst zu schwergewichtigen Lösungen, wie OpenSearch. Wenn Sie PostgreSQL bereits als Datenspeicher für Ihre Anwendung verwenden, sollten Sie zunächst die integrierte Textsuche ausprobieren, bevor Sie weitere Abhängigkeiten zu Ihrer Anwendung hinzufügen. Es ist einfacher, die indizierten Dokumente mit den Originalen zu synchronisieren, wenn sie zusammen gespeichert sind, und generierte Spalten vereinfachen dies noch weiter. Volltext-Suchabfragen können mit anderen SQL-Operatoren kombiniert werden, was leistungsstarke Abfrage-, Filter- und Sortierfunktionen innerhalb einer Datenbank ermöglicht.
Der Originalartikel stammt von Adam Zegelin und wurde auf Instaclustr.com am 9. November 2022 publiziert und von Carsten Meskes ins Deutsche übertragen.
… mit Kafka® Connect und dem Debezium PostgreSQL® Quellconnector
Moderne, verteilte ereignis- und streamingbasierte Systeme machen sich die Idee zu eigen, dass Änderungen unvermeidlich und sogar wünschenswert sind! Ohne Änderungsbewusstsein sind Systeme unflexibel, können sich nicht weiterentwickeln oder reagieren und sind schlichtweg nicht in der Lage, mit Echtzeitdaten aus der realen Welt Schritt zu halten. In einer früheren 2-teiligen Blogserie (Teil 1, Teil 2) haben wir herausgefunden, wie man mit dem Debezium Cassandra Connector Änderungsdaten aus einer Apache Cassandra®-Datenbank erfasst und Echtzeit-Ereignis-Streams in Apache Kafka® erzeugt.
Aber wie kann man einen „Elefanten“ (PostgreSQL®) auf das Tempo eines „Geparden“ (Kafka) bringen?

Geparden sind die schnellsten Landtiere (Spitzengeschwindigkeit 120 km/h, Beschleunigung von 0 auf 100 km/h in 3 Sekunden) – 3-mal schneller als Elefanten (40 km/h). (Quelle: Shutterstock)
1. Der Debezium PostgreSQL Connector
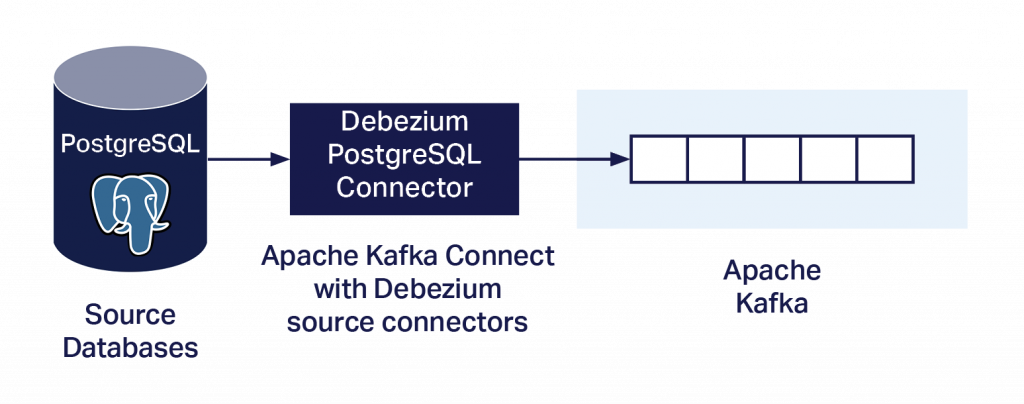
Ähnlich wie der Debezium Cassandra Connector (Blog Teil 1, Teil 2) erfasst auch der Debezium PostgreSQL Connector Datenbankänderungen auf Zeilenebene und überträgt den Stream über Kafka Connect an Kafka. Ein wesentlicher Unterschied besteht jedoch darin, dass dieser Connector als Kafka-Quellconnector ausgeführt wird. Wie lässt sich also vermeiden, dass auf dem PostgreSQL-Server benutzerdefinierter Code ausgeführt werden muss? Aus der Dokumentation geht Folgendes hervor:
„Ab PostgreSQL 10 gibt es einen logischen Replikations-Stream-Modus, genannt
pgoutput, der nativ von PostgreSQL unterstützt wird. Das bedeutet, dass ein Debezium PostgreSQL Connector diesen Replikations-Stream nutzen kann, ohne dass zusätzliche Plug-ins erforderlich sind.“
Somit kann der Connector einfach als PostgreSQL Streaming Replication Client ausgeführt werden. Um den Connector auszuführen, müssen Sie ihn herunterladen, in Ihrer Kafka Connect-Umgebung installieren, konfigurieren, PostgreSQL einrichten und dann wie folgt ausführen.
1.1. Debezium PostgreSQL Connector herunterladen
Der Connector kann hier heruntergeladen werden.
1.2. Debezium PostgreSQL Connector installieren
Ich werde hier den Dienst Instaclustr Managed Kafka Connect verwenden. Mit diesem Dienst können benutzerdefinierte Connectors verwendet werden, allerdings müssen sie zunächst in einen AWS S3 Bucket geladen und dann über die Instaclustr-Verwaltungskonsole synchronisiert werden. (Ich habe in meinem S3 Bucket einen Ordner mit dem Namen debezium-connector-postgres erstellt und alle Jars aus dem ursprünglichen Download in diesen Ordner hochgeladen.)
Wenn alles funktioniert hat, sehen Sie in der Liste der verfügbaren Connectors auf der Konsole einen neuen Connector mit dem Namen io.debezium.connector.postgresql.PostgresConnector.
1.3. PostgreSQL konfigurieren
Hier sind die erforderlichen PostgreSQL-Servereinstellungen:
- Prüfen Sie
wal_level. Wenn dies nicht auflogicalsteht, setzen Sie es auflogical. (Dazu ist ein Server-Neustart und bei einem verwalteten Dienst ggf. Unterstützung erforderlich.) - Für PostgreSQL > 10+ sind keine zusätzlichen Plug-ins erforderlich, da
pgoutputverwendet wird (Sie müssen jedoch das Standard-Plug-inplugin.namein der Konfiguration des Connectors überschreiben, siehe unten). - Benutzerberechtigungen konfigurieren
a. Laut Anweisungen soll ein Debezium-Benutzer erstellt werden, der über die erforderlichen Mindestrechte verfügt (REPLICATION-undLOGIN-Rechte),
b. und umpgoutputzu verwenden, benötigen Sie weitere Berechtigungen.
Beachten Sie, dass für diese Einstellungen Administratorrechte für PostgreSQL nötig sind. Wenn Sie also einen verwalteten Dienst verwenden, müssen Sie möglicherweise die Hilfe Ihres Dienstanbieters in Anspruch nehmen, um die notwendigen Änderungen vorzunehmen.
1.4. Debezium PostgreSQL Connector konfigurieren und ausführen
Damit Sie den Connector ausführen können, finden Sie hier ein Beispiel für eine Connector-Konfiguration. Beachten Sie, dass der Standardwert von plugin.name nicht pgoutput ist, weshalb Sie ihn explizit angeben müssen (geben Sie die IP-Adresse, den Benutzernamen und das Passwort für den Kafka Connect-Cluster und die IP-Adresse, den Benutzernamen und das Passwort für die PostgreSQL-Datenbank an):
curl https://KafkaConnectIP:8083/connectors -X POST -H 'Content-Type: application/json' -k -u kc_username:kc_password -d '{
"name": "debezium-test1",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "PG_IP",
"database.port": "5432",
"database.user": "pg_username",
"database.password": "pg_password",
"database.dbname" : "postgres",
"database.server.name": "test1",
"plugin.name": "pgoutput"
}
}
Wenn das korrekt funktioniert hat, sehen Sie in der Instaclustr Kafka Connect-Konsole einen einzelnen laufenden Task für debezium-test1. Beachten Sie, dass der Standardwert und auch der einzige zulässige Wert für tasks.max genau 1 ist, sodass Sie ihn nicht explizit festlegen müssen.
1.5. Tabellen-Themen-Zuordnungen mit Debezium PostgreSQL Connector
Vielleicht fällt Ihnen auf, dass in der Konfiguration keine Tabellennamen oder Themen angegeben sind. Das liegt daran, dass der Connector standardmäßig Änderungen für alle Nicht-System-Tabellen erfasst und Ereignisse für eine einzelne Tabelle in ein einzelnes Kafka-Thema schreibt.
Standardmäßig lautet der Name des Kafka-Themas serverName.schemaName.tableName, wobei:
• serverName der logische Name des Connectors wie im Konfigurationsmerkmal des Connectors database.server.name angegeben ist (und eindeutig sein muss)
• schemaName der Name des Datenbankschemas ist
• tableName der Name der Datenbanktabelle ist
Es gibt eine Reihe von Konfigurationsoptionen zum Ein- oder Ausschließen von Schemata, Tabellen und Spalten. (Verwenden Sie nur eine für jedes Objekt.)
Ich konnte keine PostgreSQL Connector-spezifischen Konfigurationsoptionen finden, um die standardmäßige Tabellen-Thema-Zuordnung zu ändern; das liegt jedoch daran, dass Sie generische Debezium Single Message Transforms, SMTs für benutzerdefiniertes Topic Routing, verwenden müssen.
2. Daten-Änderungsereignisse von Debezium PostgreSQL Connector kennenlernen

Ein furchterregender „Giraffosaurus“! (Oder eine T-Raffe?) (Quelle: Shutterstock)
Wenn alles richtig funktioniert, sehen Sie einige Daten-Änderungsereignisse in einem Kafka-Thema. Bei einer Tabelle mit dem Namen test1 lautet der Themenname beispielsweise test1.public.test1. Die Tabelle hat 3 ganzzahlige Spalten (id, v1, v2); id ist der Primärschlüssel.
Wie sehen nun die Kafka-Daten aus? Auf den ersten Blick sehen sie etwas unheimlich aus – in was haben sich die einfachen CRUD-Operationen der Datenbank verwandelt? Dies ist das Ereignis für eine Einfügung:
Struct{after=Struct{id=1,v1=2,v2=3},source=Struct{version=1.6.1.Final,connector=postgresql,name=test1,ts_ms=1632457564326,db=postgres,sequence=["1073751912","1073751912"],schema=public,table=test1,txId=612,lsn=1073751968},op=c,ts_ms=1632457564351}
Für eine Aktualisierung erhalten wir dieses Ereignis:
Struct{after=Struct{id=1,v1=1000,v2=3},source=Struct{version=1.6.1.Final,connector=postgresql,name=test1,ts_ms=1632457801633,db=postgres,sequence=["1140858536","1140858536"],schema=public,table=test1,txId=627,lsn=1140858592},op=u,ts_ms=1632457801973}
Und nach einer Löschung erhalten wir dieses Ereignis:
Struct{before=Struct{id=1},source=Struct{version=1.6.1.Final,connector=postgresql,name=test1,ts_ms=1632457866810,db=postgres,sequence=["1140858720","1140858720"],schema=public,table=test1,txId=628,lsn=1140858776},op=d,ts_ms=1632457867187}
NullWas fällt uns bei diesen Ereignissen auf? Wie erwartet, entspricht der Operationstyp (c, u, d) der PostgreSQL-Operationssemantik (create – für ein insert, update, delete). Für create und update gibt es einen after-Datensatz, der die ID und die Werte anzeigt, nachdem die Transaktion durchgeführt wurde. Für delete gibt es einen before-Datensatz, der nur die ID enthält, und ein Null für die after-Werte. Außerdem gibt es viele Metadaten, darunter die Zeit, datenbankspezifische Sequenz- und „lsn“-Informationen und eine Transaktions-ID. Mehrere Ereignisse können sich eine Transaktions-ID teilen, wenn sie im selben Transaktionskontext aufgetreten sind. Wofür ist die Transaktions-ID nützlich? Transaktions-Metadaten , die der txId entsprechen, können in topics mit dem Postfix .transaction geschrieben werden (provide.transaction.metadata ist standardmäßig false).
Diese Daten haben mich zunächst überrascht, da ich nach der ersten Lektüre der Dokumentation etwas besser lesbare (JSON) Änderungsereignisdaten einschließlich Schlüssel- und Wertschemata sowie Nutzdaten erwartet hatte. Aber das „Kleingedruckte“ besagt:
„Daraus, wie Sie den Kafka Connect Converter konfigurieren, den Sie in Ihrer Anwendung verwenden möchten, ergibt sich die Darstellung dieser vier Teile in Änderungsereignissen.“
Offensichtlich war also meine Konfiguration unvollständig. Mit ein bisschen Suchen entdeckte ich die folgenden zusätzlichen Konfigurationseinstellungen: key/value.converter und key/value.schemas.enable werden benötigt, um die Schlüssel- und Werteschemata in die Daten aufzunehmen, und das JSON-Format sollte verwendet werden:
"value.converter": "org.apache.kafka.connect.json.JsonConverter""value.converter.schemas.enable": "true""key.converter": "org.apache.kafka.connect.json.JsonConverter""key.converter.schemas.enable": "true"Nach der Änderung der Konfiguration und einem Neustart des Connectors sind die generierten Daten zwar viel ausführlicher, aber zumindest jetzt wie erwartet im JSON-Format. Bei einer insert-Operation erhalten wir zum Beispiel dieses lange Ereignis:
{"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"int32","optional":true,"field":"v1"},{"type":"int32","optional":true,"field":"v2"}],"optional":true,"name":"test1.public.test1.Value","field":"before"},{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"int32","optional":true,"field":"v1"},{"type":"int32","optional":true,"field":"v2"}],"optional":true,"name":"test1.public.test1.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"version"},{"type":"string","optional":false,"field":"connector"},{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"ts_ms"},{"type":"string","optional":true,"name":"io.debezium.data.Enum","version":1,"parameters":{"allowed":"true,last,false"},"default":"false","field":"snapshot"},{"type":"string","optional":false,"field":"db"},{"type":"string","optional":true,"field":"sequence"},{"type":"string","optional":false,"field":"schema"},{"type":"string","optional":false,"field":"table"},{"type":"int64","optional":true,"field":"txId"},{"type":"int64","optional":true,"field":"lsn"},{"type":"int64","optional":true,"field":"xmin"}],"optional":false,"name":"io.debezium.connector.postgresql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"id"},{"type":"int64","optional":false,"field":"total_order"},{"type":"int64","optional":false,"field":"data_collection_order"}],"optional":true,"field":"transaction"}],"optional":false,"name":"test1.public.test1.Envelope"},"payload":{"before":null,"after":{"id":10,"v1":10,"v2":10},"source":{"version":"1.6.1.Final","connector":"postgresql","name":"test1","ts_ms":1632717503331,"snapshot":"false","db":"postgres","sequence":"[\"1946172256\",\"1946172256\"]","schema":"public","table":"test1","txId":1512,"lsn":59122909632,"xmin":null},"op":"c","ts_ms":1632717503781,"transaction":null}}Die expliziten Schema-Metadaten machen die Sache ziemlich komplex, also schalten wir sie folgendermaßen ab:
"value.converter.schemas.enable": "false""key.converter.schemas.enable": "false"Dies ergibt einen besser lesbaren Datensatz, der nur die Nutzdaten enthält (oben hervorgehoben, aber beachten Sie, dass „payload“ nicht mehr angezeigt wird):
{"before":null,"after":{"id":10,"v1":10,"v2":10},"source":{"version":"1.6.1.Final","connector":"postgresql","name":"test1","ts_ms":1632717503331,"snapshot":"false","db":"postgres","sequence":"[\"1946172256\",\"1946172256\"]","schema":"public","table":"test1","txId":1512,"lsn":59122909632,"xmin":null},"op":"c","ts_ms":1632717503781,"transaction":null}Beachten Sie, dass wir jetzt ein before-Feld und ein after-Feld für create-Operationen haben.
Beachten Sie auch, dass ohne explizites Schema der Kafka-Sink-Connector in der Lage sein muss, die Nutzdaten ohne zusätzlichen Kontext zu verstehen, oder Sie müssen alternativ eine Schema Registry verwenden und konfigurieren. Hier sind die Anweisungen für die Verwendung einer Kafka Schema Registry mit dem von Instaclustr verwalteten Kafka-Dienst. Änderungen an der Konfiguration des Debezium-Quellconnectors müssen Folgendes enthalten:
"value.converter": "io.confluent.connect.avro.AvroConverter""value.converter.schema.registry.url": "http://schema-registry:8081"Ich war neugierig, was nach einer truncate-Operation an einer Tabelle passieren würde, aber überraschenderweise wurden überhaupt keine Ereignisse generiert. Ist ein truncate nicht semantisch gleichwertig mit mehreren delete-Operationen? Wie sich herausstellt, sind truncate-Ereignisse standardmäßig ausgeschaltet („truncate.handling.mode“ : „skip“ – nicht „bytes“, wie fälschlicherweise dokumentiert; „include“, um sie einzuschalten).
Die andere Überlegung ist, dass der Kafka-Sink-Connector in der Lage sein muss, truncate-Ereignisse vernünftig zu verarbeiten, was anwendungsspezifisch und/oder Sink-system-spezifisch sein kann. (Z. B. könnte es für Elasticsearch sinnvoll sein, als Reaktion auf ein truncate-Ereignis einen gesamten Index zu löschen. Für die Stream-Verarbeitung hingegen ist es nicht offensichtlich, was eine sinnvolle Reaktion wäre. Allerdings tritt das gleiche Problem vielleicht auch bei Löschungen und Aktualisierungen auf.)
3. Durchsatz des Debezium PostgreSQL Connectors

Wie schnell kann ein Debezium PostgreSQL Connector ausgeführt werden? (Quelle: Shutterstock)
Eine Einschränkung des Debezium PostgreSQL Connectors ist, dass er nur als einzelner Task ausgeführt werden kann. Ich habe einige Auslastungstests durchgeführt und festgestellt, dass ein einzelner Task maximal 7.000 Daten-Änderungsereignisse pro Sekunde verarbeiten kann. Dies entspricht auch den Transaktionen pro Sekunde, solange es nur ein Änderungsereignis pro Transaktion gibt. Bei mehreren Ereignissen pro Transaktion ist der Transaktionsdurchsatz geringer. In einem früheren Blog (Pipeline-Blogserie Teil 9) haben wir 41.000 Einfügungen pro Sekunde in PostgreSQL erreicht. Davon sind 7.000 lediglich 17 %. Dieser Teil der CDC-Pipeline ist also in der Praxis eher ein Elefant als ein Gepard. Typische PostgreSQL-Workloads bestehen jedoch aus eine Mischung an Schreib- und Lesevorgängen, sodass die Schreibrate wesentlich geringer sein kann, was den Debezium PostgreSQL Connector zu einer praktikableren Lösung macht.
Ich habe noch ein weiteres, etwas merkwürdiges Verhalten festgestellt, das Sie vielleicht beachten sollten. Wenn zwei (oder mehr) Tabellen auf Änderungsereignisse überwacht werden und die Last nicht gleichmäßig auf die Tabellen verteilt ist (z. B., wenn ein Batch von Änderungen in einer Tabelle kurz vor der nächsten auftritt), dann verarbeitet der Connector alle Änderungen der ersten Tabelle, bevor er mit den Änderungen für die zweite Tabelle beginnt. Bei dem von mir entdeckten Beispiel kam es zu einer Verzögerung von 10 Minuten. Ich bin mir nicht ganz sicher, was da vor sich geht, aber es sieht so aus, als ob der Connector alle Änderungen für eine Tabelle verarbeiten muss, bevor er zur nächsten Tabelle übergeht. Bei normalen, ausgeglichenen Workloads mag dies in Ordnung sein, aber bei Spitzen-/Batch-Lasten, die eine einzelne Tabelle stark auslasten, kann es Probleme bei der rechtzeitigen Verarbeitung von Änderungsereignissen aus anderen Tabellen verursachen.
Eine mögliche Lösung ist, mehrere Connectors zu verwenden. Dies scheint möglich zu sein (siehe z. B. diesen nützlichen Blog) und kann auch dazu beitragen, das Limit für die Verarbeitung von 7.000 Ereignissen pro Sekunde zu beseitigen. Allerdings würde es wahrscheinlich nur funktionieren, wenn sich die Tabellen zwischen den Connectors nicht überschneiden, und Sie müssten mehrere Replication-Slots haben, damit es funktioniert (es gibt eine Konfigurationsoption des Connectors für slot.name).
4. Debezium PostgreSQL Connector Datenänderungs-Erfassungsereignisse mit Kafka Sink-Connectors in Elasticsearch streamen

Die endgültige Metamorphose – vom Gepard (Kafka) zum Nashorn! (Sink-System, z. B. Elasticsearch) (Quelle: Shutterstock)
Es ist natürlich nicht das Ziel, genügend Daten-Änderungsereignisse in Kafka zu erhalten und sie zu verstehen, sondern sie in ein oder mehrere Sink-Systems zu streamen.
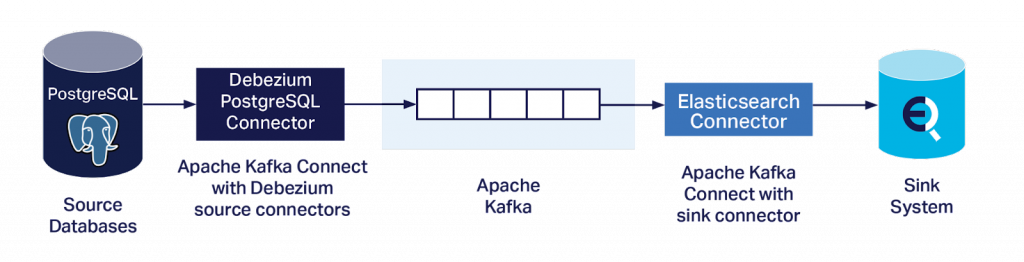
Ich wollte jedoch eine einfache Möglichkeit haben, das komplette End-to-End-System zu testen. Insbesondere mit einem Ansatz, der keine benutzerdefinierten Kafka Connect Sink-Connectors benötigt, um komplexe Daten-Änderungsereignisse und die Semantik des Sink-Systems zu interpretieren, oder eine Schema Registry betreiben muss (was wahrscheinlich auch einen benutzerdefinierten Quellconnector erfordern würde). Deshalb habe ich die Elasticsearch Sink-Connectors aus der letzten Pipeline-Blogserie wiederverwendet. Dieser Ansatz hat sich bereits beim Lesen von JSON-Daten ohne Schema bewährt und schien daher auch für diesen Anwendungsfall ideal.
Das „erste Taxi in der Schlange“ (in Zeiten von Fahrgemeinschafts-Apps eine anachronistische Wendung) ist der Apache Camel Kafka Elasticsearch Sink-Connector. Dies war der Connector, der sich bei früheren Experimenten als am robustesten erwiesen hatte. Leider fehlte dieses Mal eine Klasse (org.elasticsearch.rest.BytesRestResponse), was ich nicht weiter zu beheben versucht habe. Wahrscheinlich wäre ich kein guter Spion, denn jeder, der sich im Spionagehandwerk auskennt, weiß, dass man nicht das erstbeste Taxi nehmen sollte, das um die Ecke kommt!
Für meinen zweiten Versuch verwendete ich einen weiteren quelloffenen Elasticsearch Sink-Connector von lenses.io, der standardmäßig im Managed Kafka Connect-Dienst von Instaclustr enthalten ist.
Hier eine Beispielkonfiguration für diesen Connector (geben Sie die IP-Adressen von Kafka Connect und Elasticsearch sowie Benutzernamen und Passwörter an):
curl https://KC_IP:8083/connectors/elastic-sink-tides/config -k -u KC_user:KC_password -X PUT -H 'Content-Type: application/json' -d '
{
"connector.class" : "com.datamountaineer.streamreactor.connect.elastic7.ElasticSinkConnector",
"tasks.max" : 100,
"topics" : "test1.public.test1",
"connect.elastic.hosts" : "ES_IP",
"connect.elastic.port" : 9201,
"connect.elastic.kcql" : "INSERT INTO test-index SELECT * FROM test1.public.test",
"connect.elastic.use.http.username" : "ES_user",
"connect.elastic.use.http.password" : "ES_password"
}
}'
Der Task wurde korrekt ausgeführt. Beachten Sie, dass wir für die Verarbeitung von 7.000 Ereignissen pro Sekunde mehrere Sink-Connector-Tasks benötigen, und Sie müssen auch die Anzahl der Kafka-Partitionen entsprechend erhöhen (Partitionen >= Tasks).
Eine Einschränkung dieser Connector-Konfiguration besteht darin, dass sie alle Ereignisse als insert-Ereignisse verarbeitet. Unsere Daten-Änderungsereignisse können jedoch before– und after-Felder haben, von denen er nichts weiß, wodurch Sie „Junk“ im Elasticsearch-Index erhalten, den Sie anschließend interpretieren müssen. Eine einfache Lösung ist die Verwendung einer SMT (Single Message Transformation) auf dem Sink-Connector, um nur die after-Felder zu extrahieren. Ich habe den ExtractNewRecordState SMT zum „Abflachen der Ereignisse“ verwendet. Hier ist die endgültige Konfiguration des Debezium PostgreSQL-Quellconnectors einschließlich des SMT:
curl https://KC_IP:8083/connectors -X POST -H 'Content-Type: application/json' -k -u kc_user:kc_password -d '{
"name": "debezium-test1",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "pg_ip",
"database.port": "5432",
"database.user": "pg_user",
"database.password": "pg_password",
"database.dbname" : "postgres",
"database.server.name": "test1",
"plugin.name": "pgoutput",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState"
}
}
'
Um schließlich alles zu überprüfen, habe ich meine ursprünglichen NOAA-Pipeline-Daten und -Themen wiederverwendet. Dadurch konnte ich auch prüfen, ob die JSON-Daten wie erwartet in Elasticsearch indiziert wurden (obwohl ich dieses Mal nur Standard-Zuordnungen verwendet habe), und ich konnte auch prüfen, ob es einen Unterschied im Durchsatz zwischen PostgreSQL JSON- und JSONB-Lesevorgängen (mit einem GIN-Index) gab – ich freue mich, berichten zu können, dass es keinen gab.
Wie ich jedoch in der Pipeline-Blogserie Teil 8 entdeckte, haben Elasticsearch Sink-Connectors Schwierigkeiten, mehr als 1.800 Einfügungen pro Sekunde zu indizieren, was weit unter der Task-Beschränkung bei Single-Thread-Connectors von 7.000 Ereignissen pro Sekunde liegt (in Teil 9 haben wir jedoch mit einem Workaround und der BULK-API bessere Ergebnisse erzielt), womit jeglicher Unterschied zwischen JSON- und JSONB-Performance eventuell maskiert wird, aber das ist sicherlich nicht das Haupt-Performanceproblem.
5. Fazit
In diesem Blog haben wir erfolgreich eine Test-CDC-Pipeline von PostgreSQL zu einem Beispiel-Sink-System (z. B. Elasticsearch) unter Verwendung des Debezium PostgreSQL Connectors und des Instaclustr Managed Kafka Connect und OpenDistro Elasticsearch-Dienst bereitgestellt, konfiguriert und ausgeführt. Für viele Anwendungsfälle werden Sie komplexere Kafka Sink-Connectors benötigen, um die Semantik des Daten-Änderungsereignisses und ihre Anwendung auf verschiedene Sink-Systems zu interpretieren, und es gibt noch viele weitere Konfigurationsoptionen, die ich nicht berücksichtigt habe. In Anbetracht der potenziellen Einschränkungen im Single-Task-Betrieb und anderer potenzieller Eigenarten in Bezug auf die Performance sollten Sie ebenfalls einen geeigneten Leistungs- und Verzögerungstest mit realistischen Daten und angemessen dimensionierten Systemen durchführen, bevor Sie in die Produktion gehen.
Hinweis: Die Experimente in diesem Blog wurden in einer Entwicklungsumgebung durchgeführt. Dabei wurde eine Kombination aus Open-Source-/selbstverwaltetem PostgreSQL (nicht unser verwalteter PostgreSQL-Dienst) in Verbindung mit den verwalteten Diensten Kafka Connect und Elasticsearch von Instaclustr verwendet. Derzeit haben wir Kunden, die Debezium in einer privaten Preview für unseren verwalteten Cassandra-Dienst verwenden, aber zum Zeitpunkt der Veröffentlichung wird Debezium noch nicht für unseren verwalteten PostgreSQL-Dienst angeboten.
Der Orininalartikel stammt von Paul Brebner und wurde auf Instaclustr.com am 9. August 2022 veröffentlicht.
SQLreduce: Reduzieren Sie ausführliche SQL-Abfragen auf minimale Beispiele

Entwickler sehen sich oft sehr großen SQL-Abfragen gegenüber, die Fehler verursachen. SQLreduce ist ein Werkzeug, um diese Komplexität auf eine minimale Abfrage zu reduzieren.
SQLsmith generiert zufällige SQL-Abfragen
SQLsmith ist ein Werkzeug, das zufällige SQL-Abfragen generiert und sie gegen einen PostgreSQL-Server (und andere DBMS-Typen) ausführt. Die Idee ist, dass durch Fuzz-Testing des Query Parsers und Executors Corner-Case-Bugs gefunden werden können, die sonst bei manuellen Tests oder mit dem festen Satz von Testfällen in der PostgreSQL-Regressionstestsuite unbemerkt bleiben würden. Es hat sich als ein effektives Werkzeug erwiesen, mit dem seit 2015 über 100 Bugs in verschiedenen Bereichen des PostgreSQL-Servers und anderer Produkte gefunden wurden, darunter Sicherheitslücken, die von Executor-Bugs bis hin zu Segfaults in Typ- und Indexmethodenimplementierungen reichen. Zum Beispiel fand SQLsmith im Jahr 2018 heraus, dass die folgende Abfrage einen Segfault in PostgreSQL auslöste:
select
case when pg_catalog.lastval() < pg_catalog.pg_stat_get_bgwriter_maxwritten_clean() then case when pg_catalog.circle_sub_pt(
cast(cast(null as circle) as circle),
cast((select location from public.emp limit 1 offset 13)
as point)) ~ cast(nullif(case when cast(null as box) &> (select boxcol from public.brintest limit 1 offset 2)
then (select f1 from public.circle_tbl limit 1 offset 4)
else (select f1 from public.circle_tbl limit 1 offset 4)
end,
case when (select pg_catalog.max(class) from public.f_star)
~~ ref_0.c then cast(null as circle) else cast(null as circle) end
) as circle) then ref_0.a else ref_0.a end
else case when pg_catalog.circle_sub_pt(
cast(cast(null as circle) as circle),
cast((select location from public.emp limit 1 offset 13)
as point)) ~ cast(nullif(case when cast(null as box) &> (select boxcol from public.brintest limit 1 offset 2)
then (select f1 from public.circle_tbl limit 1 offset 4)
else (select f1 from public.circle_tbl limit 1 offset 4)
end,
case when (select pg_catalog.max(class) from public.f_star)
~~ ref_0.c then cast(null as circle) else cast(null as circle) end
) as circle) then ref_0.a else ref_0.a end
end as c0,
case when (select intervalcol from public.brintest limit 1 offset 1)
>= cast(null as "interval") then case when ((select pg_catalog.max(roomno) from public.room)
!~~ ref_0.c)
and (cast(null as xid) <> 100) then ref_0.b else ref_0.b end
else case when ((select pg_catalog.max(roomno) from public.room)
!~~ ref_0.c)
and (cast(null as xid) <> 100) then ref_0.b else ref_0.b end
end as c1,
ref_0.a as c2,
(select a from public.idxpart1 limit 1 offset 5) as c3,
ref_0.b as c4,
pg_catalog.stddev(
cast((select pg_catalog.sum(float4col) from public.brintest)
as float4)) over (partition by ref_0.a,ref_0.b,ref_0.c order by ref_0.b) as c5,
cast(nullif(ref_0.b, ref_0.a) as int4) as c6, ref_0.b as c7, ref_0.c as c8
from
public.mlparted3 as ref_0
where true;
Wie jedoch in diesem 40-zeiligen, 2,2 KB großen Beispiel sind die von SQLsmith generierten Zufallsabfragen, die einen Fehler auslösen, meist sehr groß und enthalten viel Rauschen, das nicht zum Fehler beiträgt. Bisher waren eine manuelle Überprüfung der Abfrage und eine mühsame Bearbeitung erforderlich, um das Beispiel auf einen minimalen Reproducer zu reduzieren, den Entwickler zur Behebung des Problems verwenden können.
Reduzieren Sie die Komplexität mit SQLreduce
Dieses Problem wird durch SQLreduce gelöst. SQLreduce nimmt als Eingabe eine beliebige SQL-Abfrage entgegen, die dann gegen einen PostgreSQL-Server ausgeführt wird. Es werden verschiedene Vereinfachungsschritte angewendet, wobei nach jedem Schritt geprüft wird, ob die vereinfachte Abfrage noch denselben Fehler von PostgreSQL auslöst. Das Endergebnis ist eine SQL-Abfrage mit minimaler Komplexität.
SQLreduce reduziert effektiv die Abfragen aus ursprünglichen Fehlerberichten von SQLsmith auf Abfragen, die manuell reduzierten Abfragen entsprechen. Zum Beispiel kann SQLreduce die obige Monsterabfrage effektiv auf Folgendes reduzieren:
SELECT pg_catalog.stddev(NULL) OVER () AS c5 FROM public.mlparted3 AS ref_0
Beachten Sie, dass SQLreduce nicht versucht, eine Abfrage abzuleiten, die semantisch identisch mit dem Original ist oder dasselbe Abfrageergebnis liefert – die Eingabe wird als fehlerhaft angenommen, und wir suchen nach der minimalen Abfrage, die dieselbe Fehlermeldung von PostgreSQL erzeugt, wenn sie gegen eine Datenbank ausgeführt wird. Wenn die Eingabeabfrage zufällig keinen Fehler erzeugt, ist die von SQLreduce ausgegebene Minimalabfrage nur SELECT.
Wie es funktioniert
Wir werden eine einfachere Abfrage verwenden, um zu demonstrieren, wie SQLreduce funktioniert und welche Schritte unternommen werden, um Rauschen aus der Eingabe zu entfernen. Die Abfrage ist falsch und enthält ein wenig Durcheinander, das wir entfernen wollen:
$ psql -c 'select pg_database.reltuples / 1000 from pg_database, pg_class where 0 < pg_database.reltuples / 1000 order by 1 desc limit 10'
ERROR: column pg_database.reltuples does not exist
Übergeben wir die Abfrage an SQLreduce:
$ sqlreduce 'select pg_database.reltuples / 1000 from pg_database, pg_class where 0 < pg_database.reltuples / 1000 order by 1 desc limit 10'
SQLreduce beginnt mit dem Parsen der Eingabe mit pglast und libpg_query, die den ursprünglichen PostgreSQL-Parser als Bibliothek mit Python-Bindungen bereitstellen. Das Ergebnis ist ein Parse-Baum, der die Grundlage für die nächsten Schritte bildet. Der Parse-Baum sieht wie folgt aus:
selectStmt
├── targetList
│ └── /
│ ├── pg_database.reltuples
│ └── 1000
├── fromClause
│ ├── pg_database
│ └── pg_class
├── whereClause
│ └── <
│ ├── 0
│ └── /
│ ├── pg_database.reltuples
│ └── 1000
├── orderClause
│ └── 1
└── limitCount
└── 10
Pglast enthält auch einen Query Renderer, der den Parse-Baum als SQL zurückgeben kann, wie in der regenerierten Abfrage unten gezeigt. Die Eingabeabfrage wird gegen PostgreSQL ausgeführt, um das Ergebnis zu bestimmen, in diesem Fall ERROR: column pg_database.reltuples does not exist.
Input query: select pg_database.reltuples / 1000 from pg_database, pg_class where 0 < pg_database.reltuples / 1000 order by 1 desc limit 10
Regenerated: SELECT pg_database.reltuples / 1000 FROM pg_database, pg_class WHERE 0 < ((pg_database.reltuples / 1000)) ORDER BY 1 DESC LIMIT 10
Query returns: ✔ ERROR: column pg_database.reltuples does not exist
SQLreduce arbeitet, indem es neue Parse-Bäume ableitet, die strukturell einfacher sind, SQL daraus generiert und diese Abfragen gegen die Datenbank ausführt. Die ersten Vereinfachungsschritte arbeiten auf dem obersten Knoten, wo SQLreduce versucht, ganze Teilbäume zu entfernen, um schnell ein Ergebnis zu finden. Die erste versuchte Reduktion ist das Entfernen von LIMIT 10:
SELECT pg_database.reltuples / 1000 FROM pg_database, pg_class WHERE 0 < ((pg_database.reltuples / 1000)) ORDER BY 1 DESC ✔
Das Abfrageergebnis ist immer noch ERROR: column pg_database.reltuples does not exist, was durch ein ✔ Häkchen angezeigt wird. Als nächstes wird ORDER BY 1 entfernt, wieder erfolgreich:
SELECT pg_database.reltuples / 1000 FROM pg_database, pg_class WHERE 0 < ((pg_database.reltuples / 1000)) ✔
Nun wird die gesamte Zielliste entfernt:
SELECT FROM pg_database, pg_class WHERE 0 < ((pg_database.reltuples / 1000)) ✔
Diese kürzere Abfrage ist immer noch äquivalent zum Original bezüglich der Fehlermeldung, die zurückgegeben wird, wenn sie gegen die Datenbank ausgeführt wird. Nun wird der erste erfolglose Reduktionsschritt versucht, bei dem die gesamte FROM-Klausel entfernt wird:
SELECT WHERE 0 < ((pg_database.reltuples / 1000)) ✘ ERROR: missing FROM-clause entry for table "pg_database"
Diese Abfrage ist auch fehlerhaft, löst aber eine andere Fehlermeldung aus, so dass der vorherige Parse-Baum für die nächsten Schritte beibehalten wird. Wieder wird ein ganzer Teilbaum entfernt, jetzt die WHERE-Klausel:
SELECT FROM pg_database, pg_class ✘ no error
Wir haben die Eingabeabfrage nun so weit reduziert, dass sie keine Fehler mehr ausgibt. Der vorherige Parse-Baum wird weiterhin beibehalten, der nun wie folgt aussieht:
selectStmt
├── fromClause
│ ├── pg_database
│ └── pg_class
└── whereClause
└── <
├── 0
└── /
├── pg_database.reltuples
└── 1000
Nun beginnt SQLreduce, sich in den Baum einzugraben. Es gibt mehrere Einträge in der FROM-Klausel, also versucht es, die Liste zu verkürzen. Zuerst wird pg_database entfernt, aber das funktioniert nicht, also wird pg_class entfernt:
SELECT FROM pg_class WHERE 0 < ((pg_database.reltuples / 1000)) ✘ ERROR: missing FROM-clause entry for table "pg_database"
SELECT FROM pg_database WHERE 0 < ((pg_database.reltuples / 1000)) ✔
Da wir eine neue minimale Abfrage gefunden haben, startet die Rekursion auf oberster Ebene mit einem weiteren Versuch, die WHERE-Klausel zu entfernen. Da das nicht funktioniert, versucht es, den Ausdruck durch NULL zu ersetzen, aber auch das funktioniert nicht.
SELECT FROM pg_database ✘ no error
SELECT FROM pg_database WHERE NULL ✘ no error
Nun wird eine neue Art von Schritt versucht: Expression Pull-up. Wir steigen in die WHERE-Klausel ab, wo wir A < B zuerst durch A und dann durch B ersetzen.
SELECT FROM pg_database WHERE 0 ✘ ERROR: argument of WHERE must be type boolean, not type integer
SELECT FROM pg_database WHERE pg_database.reltuples / 1000 ✔
SELECT WHERE pg_database.reltuples / 1000 ✘ ERROR: missing FROM-clause entry for table "pg_database"
Der erste Versuch hat nicht funktioniert, aber der zweite. Da wir die Abfrage vereinfacht haben, starten wir auf oberster Ebene neu, um zu prüfen, ob die FROM-Klausel entfernt werden kann, aber sie ist immer noch erforderlich.
Von A / B können wir wieder A hochziehen:
SELECT FROM pg_database WHERE pg_database.reltuples ✔
SELECT WHERE pg_database.reltuples ✘ ERROR: missing FROM-clause entry for table "pg_database"
SQLreduce hat die minimale Abfrage gefunden, die immer noch ERROR: column pg_database.reltuples does not exist mit diesem Parse-Baum auslöst:
selectStmt
├── fromClause
│ └── pg_database
└── whereClause
└── pg_database.reltuples
Am Ende des Laufs wird die Abfrage zusammen mit einigen Statistiken ausgegeben:
Minimal query yielding the same error:
SELECT FROM pg_database WHERE pg_database.reltuples
Pretty-printed minimal query:
SELECT
FROM pg_database
WHERE pg_database.reltuples
Seen: 15 items, 915 Bytes
Iterations: 19
Runtime: 0.107 s, 139.7 q/s
Diese minimale Abfrage kann nun überprüft werden, um den Fehler in PostgreSQL oder in der Anwendung zu beheben.
Über credativ
Die credativ GmbH ist ein herstellerunabhängiges Beratungs- und Dienstleistungsunternehmen mit Sitz in Mönchengladbach. Mit über 22 Jahren Entwicklungs- und Serviceerfahrung im open source Bereich kann die credativ GmbH Sie mit beispiellosem und individuell anpassbarem Support unterstützen. Wir sind hier, um Ihnen bei all Ihren open source Infrastruktur-Bedürfnissen zu helfen und Sie zu unterstützen.
Dieser Artikel wurde ursprünglich von Christoph Berg geschrieben.
Das Debian-Projekt hat soeben Version 11 („Bullseye“) ihres freien Betriebssystems veröffentlicht. Insgesamt haben über 6,208 Contributor am neuesten Release mitgearbeitet und zur erfolgreichen Umsetzung beigetragen. Wir möchten allen Beteiligten für ihre gemeinsamen Anstrengungen und harte Arbeit, die sie in den letzten Jahren in die Entwicklung dieser neuen Veröffentlichung investiert haben, danken.
Herzlichen Glückwunsch an die Debian-Community die wieder einmal gezeigt hat, dass internationale Zusammenarbeit für Freie Software einfach spitze sein kann.
Darüber hinaus möchten wir auch unseren eigenen Debian-Entwicklern die Anerkennung geben die sie sich verdient haben. Wir schätzen die Arbeit aller unser Kollegen sehr, und unterstützen sie ganz klar Beiträge zu Open Source und Freie Software Projekten weltweit einzureichen.
Das neue release, Debian 11, kann hier heruntergeladen werden:
https://www.debian.org/devel/debian-installer/index.en.html
Neues in Debian 11 „Bullseye“
Debian 11 kommt mit einer Menge Aktualisierungen und Upgrades. Dieser neue Release enthält über 13.370 komplett neue Pakete, insgesamt also über 57.703 Pakete bei der Veröffentlichung. Von diesen wurden 35.532 Softwarepakete auf neuere Versionen aktualisiert, einschließlich einer Aktualisierung des Kernels von 4.19 in „Buster“ auf 5.10 in „Bullseye“.
Weiterhin erweitert „Bullseye“ die Möglichkeiten des treiberlosen Druckens mit CUPS und des treiberlosen Scannens mit SANE. Während es mit „Buster“ möglich war, CUPS für das treiberlose Drucken zu verwenden, kommt „Bullseye“ mit dem Paket ipp-usb, das es erlaubt, ein USB-Gerät als Netzwerkgerät zu behandeln und damit die Möglichkeiten des treiberlosen Druckens zu erweitern. SANE lässt sich damit verbinden, wenn es korrekt eingerichtet und an einen USB-Port angeschlossen ist.
Wie in den letzten releases kommt Debian 11 auch mit einer Debian Edu / Skolelinux version. Debian Edu stellt seit vielen Jahren eine Komplettlösung für Schulen dar. Das gesamte Schulnetzwerk wird durch Debian Edu bereitgestellt und es müssen nach Installation nur noch Benutzer und Maschinen hinzugefügt werden. Dies kann ganz komfortabel über die Weboberfläche GOsa² erledigt werden.
Für weitere Informationen und technische Details zum neuen Debian 11 Release lesen Sie bitte die offiziellen Release Notes auf Debian.org
https://www.debian.org/releases/bullseye/amd64/release-notes/
Beiträge von credativ Mitarbeitern
credativ war schon immer ein aktiver Teil der Debian-Community und hat seit 2004 jede DebConf besucht. Desweiteren findet Debian Gebrauch als Haupt-Betriebssystem in der Managed Platform von Instaclustr.
credativ Mitarbeiter haben diverse Aufgaben im neuen Release von Debian 11 übernommen. Hier ist ein kleiner Ausschnitt an Beiträgen und Mitarbeit unserer Kollegen:
- 90% der PostgreSQL® Paketierung des neuen Release
- Wartung mitarbeit an verschiedenen Paketen
- Unterstützung als Debian-Sys-Admin
- Mitarbeit and Debian Edu / Skolelinux
- Entwicklungsarbeit an Kernel-Images
- Entwicklungsarbeit an Cloud-Images
- Entwicklungsarbeit für diverse Debian Backports
- Mitarbeit und Unterstützung bei salsa.debian.org
Jeder unserer Kollegen hat einen signifikanten Beitrag zum aktuellen Releasegeleistet und deshalb noch einmal einen herzlichen Dank an alle Debianer:
- Adrian Vondendriesch
- Alexander Wirt (Formorer)
- Bastian Blank (Waldi)
- Christoph Berg (Myon)
- Dominik George (Natureshadow)
- Felix Geyer (fgeyer)
- Martin Zobel-Helas (Zobel)
- Michael Banck (azeem)
- Dr. Michael Meskes (feivel)
- Noël Köthe (Noel)
- Sven Bartscher (kritzefitz)
Wie upgraden Sie am besten von Debian 10 zu Debian 11?
Debian 11 „Bullseye“ ist ein weiteres Major Release und als solches empfehlen wir allen Lesern zeitnah zu upgraden. Debian 10 “Buster” wird zwar noch bis zum Juni 2024 mit LTS supported, dennoch macht es Sinn sich jetzt schon mal mit einem möglichen Upgrade auseinander zu setzen.
Da es sich jedoch um ein Major Release handelt, erfordert der Upgrade-Prozess ein gewisses Maß an manueller Arbeit, um ein reibungsloses Upgrade zu gewährleisten.
Eine ausführliche Anleitung ist auf debian.org verfügbar, daher werden wir hier nur die fünf wichtigsten Schritte auflisten:
- Zur Vorbereitung sollten Sie alle Daten, die nicht verloren gehen sollen, sichern und sich auf die Wiederherstellung vorbereiten
- Entfernen Sie alle Nicht-Debian-Pakete und bereinigen Sie übrig gebliebene Dateien und alte Versionen
- Führen Sie das ein Upgrade auf die aktuellste minor Version durch
- Überprüfen Sie Ihre APT-Quelldateien und bereiten Sie sie vor, indem Sie die relevanten Internetquellen oder lokalen Spiegelserver hinzufügen
- Aktualisieren Sie Ihre Pakete und aktualisieren Sie dann Ihr System
Alle bestehenden Kunden, die eine auf Debian basierende Installation betreiben, sind natürlich durch unseren Service und Support abgedeckt und können sich jederzeit an uns wenden.
Wenn Sie an einem Upgrade Ihrer alten Debian-Version interessiert sind oder wenn Sie Fragen zu Ihrer eigenen Open-Source-Infrastruktur haben, zögern Sie nicht, uns eine E-Mail zu schreiben oder uns unter info@credativ.de zu kontaktieren.
Oder Sie können in wenigen Minuten mit einer der Open-Source-Technologien wie Apache Cassandra, Apache Kafka, Redis und OpenSearch auf der Instaclustr Managed Platform loslegen. Melden Sie sich noch heute für eine kostenlose Testversion an.
Moodle ist eine beliebte Open Source Online-Lernplattform. Gerade in Zeiten von COVID19 und Distanzunterricht hat sich die Bedeutung von Moodle für Schulen und Universität weiter verstärkt, da ganze Bundesländer ihren Schulunterricht innerhalb weniger Tage auf Moodle und andere Plattformen wie BigBlueButton umgestellt haben. Dies führt unweigerlich zu Skalierungs-Problemen, wenn plötzlich mehrere zehntausend Schüler auf Moodle zugreifen müssen. Neben der Skalierung der Moodle Applikation selber muss auch die Datenbank bedacht werden, hier kann unter anderem PostgreSQL verwendet werden. Im Folgenden werden Möglichkeiten zum Load-Balancing für Moodle unter PostgreSQL vorgestellt.
Hochverfügbarkeit durch Patroni
Eine Online-Lernplattform ist aus Sicht des Bildungssystems kritische Infrastruktur und sollte dementsprechend Hochverfügbar ausgelegt sein, was insbesondere die Datenbank betrifft. Eine gute Lösung für PostgreSQL ist hier Patroni, über dessen Debian-Integration wir bereits früher berichtet haben. Kurz zusammengefasst verwendet Patroni einen “Distributed Consensus Store” (DCS) um aus einem typischerweise 3-Knoten Cluster einen sogenannten Leader zu wählen bzw. bei Ausfalls eines Leaders ein Failover zu initiieren und einen neuen Leader zu wählen, ohne dabei in ein Split-Brain Szenario zu gelangen. Zusätzlich bietet Patroni eine REST-API, die für die Kommunikation der Knoten untereinander und von dem patronictl Programm verwendet wird, z.B. um die Postgres-Konfiguration Online auf allen Knoten zu ändern oder einen Switchover einzuleiten.
Client-Lösungen für Hochverfügbarkeit
Aus Sicht von Moodle muss allerdings zusätzlich gewährleistet sein, dass es mit dem Leader verbunden ist, da sonst keine schreibenden Transaktionen möglich sind. Herkömmliche Hochverfügbarkeits-Lösungen wie Pacemaker verwenden hier virtuelle IPs (VIPs), die im Failover-Fall zum neuen Primary-Knoten geschwenkt werden. Für Patroni gibt es stattdessen das vip-manager Projekt, welches den Leader-Key im DCS überwacht und Cluster-VIP lokal setzt oder entfernt. Dieses ist ebenfalls in Debian integriert.
Eine Alternative ist die Verwendung von Client-seitigem Failover basierend auf der libpq-Bibliothek von PostgreSQL. Hierfür werden alle Cluster-Mitglieder im Verbindungs-String aufgelistet und die Verbindungs-Option target_session_attrs=read-write gewählt. So konfiguriert versucht der Client bei einem Verbindungs-Abbruch die anderen Knoten zu erreichen, bis ein neuer Primary gefunden wird.
Eine andere Möglichkeit ist HAProxy, ein hoch-skalierender TCP/HTTP Load-Balancer. Durch die Möglichkeit periodische Health-Checks auf die Patroni REST-API der einzelnen Knoten durchzuführen kann es den aktuellen Leader ermitteln und Client-Anfragen dorthin weiterleiten.
Datenbank-Konfiguration von Moodle
Die Verbindung von Moodle zu einer PostgreSQL-Datenbank wird in config.php konfiguriert, z.B. für eine einfache Stand-Alone Datenbank:
$CFG->dbtype = 'pgsql';
$CFG->dblibrary = 'native';
$CFG->dbhost = '192.168.1.1';
$CFG->dbname = 'moodle';
$CFG->dbuser = 'moodle';
$CFG->dbpass = 'moodle';
$CFG->prefix = 'mdl_';
$CFG->dboptions = array (
'dbport' => '',
'dbsocket' => ''
);Hier wird der Standard-Port 5432 verwendet.
Falls Streaming-Replication verwendet wird, können die Standbys zusätzlich als readonly definiert werden und einen eigenen Datenbank-Benutzer (der lediglich Leseberechtigungen benötigt) zugeordnet werden:
$CFG->dboptions = array (
[...]
'readonly' => [
'instance' => [
[
'dbhost' => '192.168.1.2',
'dbport' => '',
'dbuser' => 'moodle_safereads',
'dbpass' => 'moodle'
],
[
'dbhost' => '192.168.1.3',
'dbport' => '',
'dbuser' => 'moodle_safereads',
'dbpass' => 'moodle'
]
]
]
);Failover/Load-Balancing mit libpq
Wenn allerdings ein hochverfügbarer Postgres-Cluster mit Patroni verwendet wird kann wie oben beschrieben der Primary im Failover- oder Switchover-Fall wechseln. Moodle bietet hier keine Möglichkeit generische Datenbank-Optionen zu setzen und damit ist die Einstellung von target_session_attrs=read-write direkt nicht möglich. Wir haben hierfür einen Patch entwickelt und in den Moodle Tracker eingestellt. Dieser erlaubt die zusätzliche Option 'dbfailover' => 1, im $CFG->dboptions-Array, was die nötige Verbindungs-Option target_session_attrs=read-write hinzufügt. Eine angepasste config.php sähe damit z.B. so aus:
$CFG->dbtype = 'pgsql';
$CFG->dblibrary = 'native';
$CFG->dbhost = '192.168.1.1,192.168.1.2,192.168.1.3';
$CFG->dbname = 'moodle';
$CFG->dbuser = 'moodle';
$CFG->dbpass = 'moodle';
$CFG->prefix = 'mdl_';
$CFG->dboptions = array (
'dbfailover' => 1,
'dbport' => '',
'dbsocket' => '',
'readonly' => [
'instance' => [
[
'dbhost' => '192.168.1.1',
'dbport' => '',
'dbuser' => 'moodle_safereads',
'dbpass' => 'moodle'
],
[
'dbhost' => '192.168.1.2',
'dbport' => '',
'dbuser' => 'moodle_safereads',
'dbpass' => 'moodle'
],
[
'dbhost' => '192.168.1.3',
'dbport' => '',
'dbuser' => 'moodle_safereads',
'dbpass' => 'moodle'
]
]
]
);Failover/Load-Balancing mit HAProxy
Wenn stattdessen HAProxy verwendet werden soll, dann muss entsprechend der HAProyx-Host als $CFG->dbhost eingetragen werden, z.B. 127.0.0.1 wenn HAProxy lokal auf dem/den Moodle Server(n) läuft. Zusätzlich kann ein zweiter Port (z.B. 65432) für lesende Anfragen definiert werden, der analog zu einem Streaming-Replication Standby als readonly in $CFG->dboptions konfiguriert wird. Die config.php sähe dann z.B. so aus:
$CFG->dbtype = 'pgsql';
$CFG->dblibrary = 'native';
$CFG->dbhost = '127.0.0.1';
$CFG->dbname = 'moodle';
$CFG->dbuser = 'moodle';
$CFG->dbpass = 'moodle';
$CFG->prefix = 'mdl_';
$CFG->dboptions = array (
'dbport' => '',
'dbsocket' => '',
'readonly' => [
'instance' => [
'dbhost' => '127.0.0.1',
'dbport' => '65432',
'dbuser' => 'moodle_safereads',
'dbpass' => 'moodle'
]
]
);Die HAProxy Konfigurations-Datei haproxy.cfg kann beispielhaft folgendermaßen aussehen:
global
maxconn 100
defaults
log global
mode tcp
retries 2
timeout client 30m
timeout connect 4s
timeout server 30m
timeout check 5s
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen postgres_write
bind *:5432
mode tcp
option httpchk
http-check expect status 200
default-server inter 3s fall 3 rise 3 on-marked-down shutdown-sessions
server pg1 192.168.1.1:5432 maxconn 100 check port 8008
server pg2 192.168.1.2:5432 maxconn 100 check port 8008
server pg3 192.168.1.3:5432 maxconn 100 check port 8008HAProxy erwartet eingehende schreibende Verbindungen (postgres_write) auf Port 5432 und sendet sie an Port 5432 der Cluster-Mitglieder weiter. Der Primary wird durch einen HTTP-Check auf Port 8008 (dem Standard Patroni REST-API Port) ermittelt; Patroni gibt hier für den Primary den Status 200 und für Standbys den Status 503 zurück.
Für die lesenden Abfragen (postgres_read) muss entschieden werden, ob der Primary auch read-only Anfragen beantworten soll oder nicht. Wenn dies der Fall ist kann ein einfacher Postgres-Check verwendet werden; allerdings kann dies zu Einträgen im Postgres-Log bzgl. fehlerhafter oder unvollständiger Logins führen:
listen postgres_read
bind *:65432
mode tcp
balance leastconn
option pgsql-check user haproxy
default-server inter 3s fall 3 rise 3 on-marked-down shutdown-sessions
server pg1 192.168.1.1:5432 check
server pg2 192.168.1.2:5432 check
server pg3 192.168.1.3:5432 checkWenn der Primary nicht am Read-Scaling teilnehmen soll kann einfach der gleiche HTTP-Check wie in der postgres_write Sektion verwendet werden, wobei diesmal der HTTP-Status 503 erwartet wird:
listen postgres_read
bind *:65432
mode tcp
balance leastconn
option httpchk
http-check expect status 503
default-server inter 3s fall 3 rise 3 on-marked-down shutdown-sessions
server pg1 192.168.1.1:5432 check port 8008
server pg2 192.168.1.2:5432 check port 8008
server pg3 192.168.1.3:5432 check port 8008Überarbeitetes Ansible Playbook
HAProxy-Unterstützung wurde auch in Version 0.3 unseres Ansible-Playbooks für die automatisierte Einrichtung eines Drei-Knoten-PostgreSQL-Patroni-Clusters unter Debian implementiert. Mit der neuen Variable haproxy_primary_read_scale kann entschieden werden, ob HAProxy Anfragen auf den Read-Only Port auch an den Primary-Knoten oder nur an die Follower geben soll.
Unterstützung
Falls Sie Unterstützung bei PostgreSQL, Patroni, HAProxy, Moodle oder anderer Software benötigen, steht Ihnen unser Open Source Support Center zur Verfügung – Falls gewünscht auch 24 Stunden am Tag, an 365 Tagen im Jahr.
Wir freuen uns über Ihre Kontaktaufnahme.
Hintergrund
Mit PostgreSQL® 13 lernt das VACUUM–Kommando eine neue Fähigkeit: Das parallele Aufräumen von Indexen. VACUUM in einer PostgreSQL®-Datenbank ist im wesentlichen für mehrere wichtige Aufgaben verantwortlich:
- Garbage Collection, also freigeben von gelöschten Tupel für die Wiederverwendung
- Verhindern von Bloat in einer Datenbank und damit von ausuferndem Plattenplatzbedarfs
- Verhindern des Überlaufs des Transaktionszählers (FREEZE)
- Diverses Aufräumen von Transaktionsinformationen, usw.
Neben dem manuellen VACUUM Kommando gibt es noch den sogenannten Autovacuum Datenbankprozess, der sich automatisch im Hintergrund um diese Aufgaben kümmert. Im Groben entspricht die Arbeitsweise von Autovacuum auch dem Vorgehen bei Ausführung eines manuellem VACUUM-Kommandos. Diese gliedert sich im Wesentlichen in mehrere Phasen:
- Scannen der Tabellenblöcke und Ermitteln von darin enthaltenen, toten Tupeln und, falls notwendig, FREEZE
- Die toten Tupel werden im Speicher gesammelt (maintenance_work_mem ist hier die Obergrenze)
- Löschen der Tupelreferenzen aus entsprechenden Indexen (Vacuum Index Phase)
- Für jeden gescannten Tabellenblock, Löschen der darin enthaltenen toten Tupel
- Für jeden gescannten Tabellenblock, Reorganisieren der lebenden Tupel
- Aktualisieren der Visibility Map und Freespace Map
- Ist maintenance_work_mem voll, bevor das Ende einer Tabelle erreicht wurde, zurück zu 2.)
- Aufräumen (Cleanup Phase), u.a. Aktualisierung der Index-Statistiken für VACUUM
- Löschen von leeren Tabellenblöcken am Ende der Tabelle (falls vorhanden)
- Aktualisieren der Laufzeitstatistiken
- Aufräumen von Transaktionsinformationen
Arbeitsteilung
Mit der neuen Kommandooption PARALLEL kann das VACUUM Kommando nun die Vacuum Index und Cleanup Phase mit mehreren Arbeitsprozessen (Workern) parallel durchführen, z.B.:
VACUUM (ANALYZE, PARALLEL 4) my_table;
Dies führt ein VACUUM mit bis zu vier parallelen Workern mit zusätzlicher Aktualisierung der Optimizer Statistiken durch. Das bisherige Verfahren bleibt für die Tabelle selbst unverändert, mit PARALLEL verarbeitet VACUUM nun mit jeweils einem dedizierten Worker einen spezifischen Index. Zu beachten ist, dass der Leader, also die Session die das VACUUM-Kommando ausführt, ebenfalls entsprechende Arbeit verrichtet. Wird „0“ als Anzahl der Worker spezifiziert, wird die parallele Verarbeitung der Indexe deaktiviert und der bisherige Arbeitsablauf verwendet. Sind weniger als vier Indexe auf der Tabelle vorhanden, so wird die Anzahl der Worker entsprechend angepasst. Auch kann es passieren, dass aufgrund nebenläufiger DDL Kommandos (anderes paralleles VACUUM oder parallelisiertes CREATE INDEX) weniger Worker ausgewählt werden, da die Anzahl der maximal verfügbaren Worker Prozesse entweder durch max_parallel_maintenance_workers oder max_worker_processes begrenzt wird.
Parallel VACUUM als Standardoption
PARALLEL ist in der aktuellen Beta2 von PostgreSQL® 13 als Standardoption aktiviert. Wird die Option weggelassen, richtet sich die Zahl der Worker nach der Anzahl an Indexe pro Tabelle. Ob ein Index überhaupt für die parallele Verarbeitung vorgesehen wird, entscheidet auch der Konfigurationsparameter min_parallel_index_scan_size. Die Standardeinstellung ist 512kB.
Der Administrator sollte bei der Konfiguration von PostgreSQL® darauf achten, entsprechenden Spielraum bei der Parametrisierung von max_worker_processes einzuplanen, da mit dem seit PostgreSQL® 11 verfügbaren parallelisierten CREATE INDEX in PostgreSQL® 13 nun ein neues parallelisierbares DDL-Kommando hinzukommt.
Verbesserung bei der Geschwindigkeit
Das parallele Verarbeiten der Indexe sollte VACUUM gerade bei größeren Mengen an gelöschten Tupel bei entsprechender Anzahl an Indexen deutlich beschleunigen. Um diesen theoretischen Vorteil in der Praxis zu zeigen, verwenden wir an dieser Stelle ein Sample Dataset der IMDb Datenbank. Die Tabelle cast_info hat folgendes Schema:
Table "public.cast_info"
Column │ Type │ Collation │ Nullable │ Default
────────────────┼─────────┼───────────┼──────────┼───────────────────────────────────────
id │ integer │ │ not null │ nextval('cast_info_id_seq'::regclass)
person_id │ integer │ │ not null │
movie_id │ integer │ │ not null │
person_role_id │ integer │ │ │
note │ text │ │ │
nr_order │ integer │ │ │
role_id │ integer │ │ not null │
Indexes:
"cast_info_pkey" PRIMARY KEY, btree (id)
"cast_info_idx_cid" btree (person_role_id)
"cast_info_idx_mid" btree (movie_id)
"cast_info_idx_pid" btree (person_id)
"test_idx" btree (note)
Foreign-key constraints:
"movie_id_exists" FOREIGN KEY (movie_id) REFERENCES title(id)
"person_id_exists" FOREIGN KEY (person_id) REFERENCES name(id)
"person_role_id_exists" FOREIGN KEY (person_role_id) REFERENCES char_name(id)
"role_id_exists" FOREIGN KEY (role_id) REFERENCES role_type(id)
Die Tabelle ist ca. 2759 MByte groß und verfügt über insgesamt fünf Indexe, deren Größen sich wie folgt manifestieren:
SELECT indexrelid::regclass, pg_size_pretty(pg_relation_size(indexrelid))
FROM pg_index WHERE indrelid = 'cast_info'::regclass;
indexrelid │ pg_size_pretty
───────────────────┼────────────────
cast_info_pkey │ 1108 MB
cast_info_idx_cid │ 421 MB
cast_info_idx_mid │ 396 MB
cast_info_idx_pid │ 452 MB
test_idx │ 388 MB
(5 rows)
Damit Autovacuum den Test nicht stört, wird er für die Tabelle deaktiviert:
ALTER TABLE cast_info SET(autovacuum_enabled = 'false');
Folgender SQL aktualisiert in der Tabelle ca. 1.05 Mio Tupel in dem es rein fiktiv die Rollenzuordnung von bestimmten Datensätzen ändert. Die Ausgabe ist ein wenig gekürzt, um das Beispiel besser zu veranschaulichen:
UPDATE cast_info SET role_id = 12 WHERE role_id = 6; UPDATE 1055730
Anschließend wird der Parameter max_parallel_maintenance_workers auf 4 gesetzt, um maximal vier parallele Worker für VACUUM zu ermöglichen.
SET max_parallel_maintenance_workers TO 4; VACUUM cast_info ; Time: 6872,329 ms (00:06,872)
Wiederholt man den UPDATE mit umgekehrter Bedingung und anschließendem nicht-parallelisiertem VACUUM ergibt sich folgendes Bild:
UPDATE cast_info SET role_id = 6 WHERE role_id = 12; UPDATE 1055730 VACUUM (PARALLEL 0) cast_info ; Time: 45435,458 ms (00:45,435)
Die parallele Verarbeitung von Indexen in diesem Testfall zeigt einen mehr als deutlichen Vorteil zugunsten des parallelisierten VACUUM. Die folgende Grafik veranschaulicht die Laufzeiten noch einmal:
Fazit
Mit PostgreSQL® 13 lernt VACUUM Indexe parallel zu verarbeiten. Dies sorgt für einen deutlichen Geschwindigkeitsvorteil bei der Wartung von Tabellen. Ein Wermutstropfen aktuell ist, dass der automatische Hintergrundprozess Autovacuum noch nicht von diesem Feature profitieren kann, nur manuelles VACUUM unterstützt aktuell parallele Verarbeitung. Administratoren, die beispielsweise jedoch große Batchverarbeitungen mit Tabellen mit vielen Indexen direkt im Anschluß mit manuellem VACUUM optimieren, können von parallel VACUUM direkt profitieren.
Bei Fragen rund um den Einsatz von PostgreSQL® 13 parallel VACUUM stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an! Unser PostgreSQL® Competence Center ist bei Bedarf 24 Stunden am Tag, an 365 Tagen im Jahr für Sie verfügbar.