PostgreSQL 18 hat eine sehr wichtige Änderung eingeführt: Datenblock-Prüfsummen sind jetzt standardmäßig für neue Cluster zum Zeitpunkt der Clusterinitialisierung aktiviert. Ich habe bereits in meinem vorherigen Artikel darüber geschrieben. Ich habe auch erwähnt, dass es immer noch viele bestehende PostgreSQL-Installationen ohne aktivierte Datenprüfsummen gibt, da dies in früheren Versionen die Standardeinstellung war. In diesen Installationen kann Datenbeschädigung manchmal zu mysteriösen Fehlern führen und die normale Funktionsweise verhindern. In diesem Beitrag möchte ich gängige PostgreSQL-Datenbeschädigungsmodi analysieren, um zu zeigen, wie man sie diagnostiziert und wie man sie behebt.
Beschädigungen in PostgreSQL-Beziehungen ohne Datenprüfsummen treten als Low-Level-Fehler wie „Ungültige Seite in Block xxx“, Transaktions-ID-Fehler, TOAST-Chunk-Inkonsistenzen oder sogar Backend-Abstürze auf. Leider können einige Backup-Strategien die Beschädigung maskieren. Wenn der Cluster keine Prüfsummen verwendet, können Tools wie pg_basebackup, die Datendateien so kopieren, wie sie sind, keine Validierung der Daten durchführen, sodass beschädigte Seiten unbemerkt in einem Basis-Backup landen können. Wenn Prüfsummen aktiviert sind, überprüft pg_basebackup diese standardmäßig, es sei denn, –no-verify-checksums wird verwendet. In der Praxis werden diese Low-Level-Fehler oft erst sichtbar, wenn wir direkt auf die beschädigten Daten zugreifen. Einige Daten werden selten berührt, was bedeutet, dass Beschädigungen oft erst bei dem Versuch auftreten, pg_dump auszuführen, da pg_dump alle Daten lesen muss.
Typische Fehler sind:
-- invalid page in a table: pg_dump: error: query failed: ERROR: invalid page in block 0 of relation base/16384/66427 pg_dump: error: query was: SELECT last_value, is_called FROM public.test_table_bytea_id_seq -- damaged system columns in a tuple: pg_dump: error: Dumping the contents of table "test_table_bytea" failed: PQgetResult() failed. pg_dump: error: Error message from server: ERROR: could not access status of transaction 3353862211 DETAIL: Could not open file "pg_xact/0C7E": No such file or directory. pg_dump: error: The command was: COPY public.test_table_bytea (id, id2, id3, description, data) TO stdout; -- damaged sequence: pg_dump: error: query to get data of sequence "test_table_bytea_id2_seq" returned 0 rows (expected 1) -- memory segmentation fault during pg_dump: pg_dump: error: Dumping the contents of table "test_table_bytea" failed: PQgetCopyData() failed. pg_dump: error: Error message from server: server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. pg_dump: Fehler: Der Befehl war: COPY public.test_table_bytea (id, id2, id3, description, data) TO stdout;
Hinweis: In solchen Fällen beendet pg_dump leider beim ersten Fehler und fährt nicht fort. Aber wir können ein einfaches Skript verwenden, das in einer Schleife Tabellennamen aus der Datenbank liest und jede Tabelle separat in eine separate Datei sichert, wobei Fehlermeldungen in eine tabellenspezifische Protokolldatei umgeleitet werden. Auf diese Weise sichern wir sowohl Tabellen, die noch intakt sind, als auch finden alle beschädigten Objekte.
Fehler verstehen
Der schnellste Weg, diese Symptome zu verstehen, besteht darin, sie der beschädigten Stelle einer 8-KB-Heap-Seite zuzuordnen. Um dies testen zu können, habe ich ein Python-Skript zur „Beschädigungssimulation“ erstellt, das bestimmte Teile eines Datenblocks gezielt beschädigen kann. Damit können wir gängige Beschädigungsmodi testen. Wir werden sehen, wie man jeden einzelnen mit pageinspect diagnostiziert, prüfen, ob amcheck in diesen Fällen helfen kann, und zeigen, wie man Abfragen mit pg_surgery gezielt freigibt, wenn ein einzelnes Tupel eine ganze Tabelle unlesbar macht.
PostgreSQL-Heap-Tabellenformat
- Header: Metadaten für Blockverwaltung und -integrität
- Item-ID-Array (Tupel-Pointer): Einträge, die auf Tupel verweisen (Offset + Länge + Flags)
- Freier Speicherplatz
- Tupel: tatsächliche Zeilendaten, jeweils mit eigenem Tupel-Header (Systemspalten)
- Spezieller Speicherplatz: reserviert für indexspezifische oder andere beziehungsspezifische Daten – Heap-Tabellen verwenden ihn nicht
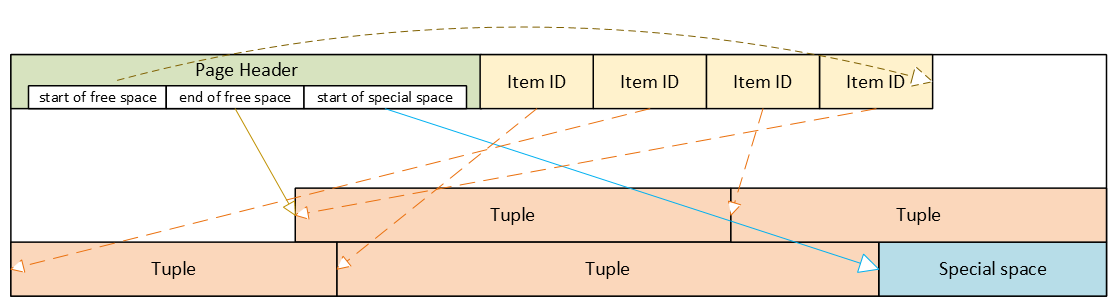
Beschädigter Seitenheader: der gesamte Block wird unzugänglich
Der Seitenheader enthält die Layout-Pointer für die Seite. Die wichtigsten Felder, die wir auch über pageinspect sehen können, sind:
- pd_flags: header flag bits
- pd_lower: offset to the start of free space
- pd_upper: offset to the end of free space
- pd_special: offset to the start of special space
- plus lsn, checksum, pagesize, version, prune_xid
ERROR: invalid page in block 285 of relation base/16384/29724
Dies ist die einzige Klasse von Beschädigungsfehlern, die durch Aktivieren von zero_damaged_pages = on übersprungen werden kann, wenn der Cluster keine Datenblock-Prüfsummen verwendet. Mit zero_damaged_pages = on werden Blöcke mit beschädigten Headern im Speicher „genullt“ und übersprungen, was buchstäblich bedeutet, dass der gesamte Inhalt des Blocks durch Nullen ersetzt wird. AUTOVACUUM entfernt genullte Seiten, kann aber nicht ungescannte Seiten nullen.
Woher der Fehler im PostgreSQL-Quellcode kommt
/* * Die folgenden Überprüfungen beweisen nicht, dass der Header korrekt ist, sondern nur, dass * es vernünftig genug aussieht, um in den Pufferpool aufgenommen zu werden. Spätere Verwendung von * der Block kann immer noch Probleme aufdecken, weshalb wir die * Checksummenoption anbieten. */ if ((p->pd_flags & ~PD_VALID_FLAG_BITS) == 0 && p->pd_lower <= p->pd_upper && p->pd_upper <= p->pd_special && p->pd_special <= BLCKSZ && p->pd_special == MAXALIGN(p->pd_special)) header_sane = true; if (header_sane && !checksum_failure) return true;
SELECT * FROM page_header(get_raw_page('pg_toast.pg_toast_32840', 100));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
------------+----------+-------+-------+-------+---------+----------+---------+-----------
0/2B2FCD68 | 0 | 4 | 40 | 64 | 8192 | 8192 | 4 | 0
Wenn der Header als beschädigt getestet wird, können wir mit SQL nichts diagnostizieren. Mit zero_damaged_pages = off endet jeder Versuch, diese Seite zu lesen, mit einem ähnlichen Fehler wie im obigen Beispiel. Wenn wir zero_damaged_pages = on setzen, wird beim ersten Versuch, diese Seite zu lesen, alles durch Nullen ersetzt, einschließlich des Headers:
SELECT * from page_header(get_raw_page('pg_toast.pg_toast_28740', 578)); WARNING: invalid page in block 578 of relation base/16384/28751; zeroing out page lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid -----+----------+-------+-------+-------+---------+----------+---------+----------- 0/0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
Beschädigtes Item-IDs-Array: Offsets und Längen werden unsinnig
- ERROR: invalid memory alloc request size 18446744073709551594
- DEBUG: server process (PID 76) was terminated by signal 11: Segmentation fault
SELECT lp, lp_off, lp_flags, lp_len, t_xmin, t_xmax, t_field3, t_ctid, t_infomask2, t_infomask, t_hoff, t_bits, t_oid, substr(t_data::text,1,50) as t_data
FROM heap_page_items(get_raw_page('public.test_table', 7));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+----------------------------------------------------
1 | 7936 | 1 | 252 | 29475 | 0 | 0 | (7,1) | 5 | 2310 | 24 | | | \x01010000010100000101000018030000486f742073656520
2 | 7696 | 1 | 236 | 29476 | 0 | 0 | (7,2) | 5 | 2310 | 24 | | | \x020100000201000002010000d802000043756c747572616c
3 | 7504 | 1 | 189 | 29477 | 0 | 0 | (7,3) | 5 | 2310 | 24 | | | \x0301000003010000030100001c020000446f6f7220726563
4 | 7368 | 1 | 132 | 29478 | 0 | 0 | (7,4) | 5 | 2310 | 24 | | | \x0401000004010000040100009d4d6f76656d656e74207374
Hier können wir das Item-IDs-Array gut sehen – Offsets und Längen. Das erste Tupel wird ganz am Ende des Datenblocks gespeichert, daher hat es den größten Offset. Jedes nachfolgende Tupel wird näher und näher am Anfang der Seite gespeichert, sodass die Offsets kleiner werden. Wir können auch die Längen der Tupel sehen, sie sind alle unterschiedlich, da sie einen Textwert variabler Länge enthalten. Wir können auch Tupel und ihre Systemspalten sehen, aber wir werden sie uns später ansehen.
Wenn wir nun das Item-IDs-Array beschädigen und diagnostizieren, wie es aussieht, wird die Ausgabe verkürzt, da auch alle anderen Spalten leer sind. Aufgrund des beschädigten Item-IDs-Arrays können wir Tupel nicht richtig lesen. Hier können wir das Problem sofort erkennen: Offsets und Längen enthalten Zufallswerte, von denen die meisten 8192 überschreiten, d. h. weit über die Grenzen der Datenseite hinausgehen:
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax ----+--------+----------+--------+--------+-------- 1 | 19543 | 1 | 16226 | | 2 | 5585 | 2 | 3798 | | 3 | 25664 | 3 | 15332 | | 4 | 10285 | 2 | 17420 | |
SELECT * FROM verify_heapam('test_table', FALSE, FALSE, 'none', 7, 7); blkno | offnum | attnum | msg -------+--------+--------+--------------------------------------------------------------------------- 7 | 1 | | line pointer to page offset 19543 is not maximally aligned 7 | 2 | | line pointer redirection to item at offset 5585 exceeds maximum offset 4 7 | 4 | | line pointer redirection to item at offset 10285 exceeds maximum offset 4
Beschädigte Tupel: Systemspalten können Scans unterbrechen
- 58P01 – could not access status of transaction 3047172894
- XX000 – MultiXactId 1074710815 has not been created yet — apparent wraparound
- WARNING: Concurrent insert in progress within table „test_table“
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid ----+--------+----------+--------+------------+------------+------------+--------------------+-------------+------------+--------+--------+------- 1 | 6160 | 1 | 2032 | 1491852297 | 287039843 | 491133876 | (3637106980,61186) | 50867 | 46441 | 124 | | 2 | 4128 | 1 | 2032 | 3846288155 | 3344221045 | 2002219688 | (2496224126,65391) | 34913 | 32266 | 82 | | 3 | 2096 | 1 | 2032 | 1209990178 | 1861759146 | 2010821376 | (426538995,32644) | 23049 | 2764 | 215 | |
- XX000 – unexpected chunk number -556107646 (expected 20) for toast value 29611 in pg_toast_29580
- XX000 – found toasted toast chunk for toast value 29707 in pg_toast_29580
Umgang mit beschädigten Tupeln mit pg_surgery
Selbst ein einzelnes beschädigtes Tupel kann Selects aus der gesamten Tabelle verhindern. Beschädigung in xmin, xmax und hint bits führt dazu, dass eine Abfrage fehlschlägt, da der MVCC-Mechanismus die Sichtbarkeit dieser beschädigten Tupel nicht bestimmen kann. Ohne Datenblock-Prüfsummen können wir solche beschädigten Seiten nicht einfach nullen, da ihr Header bereits den „Sinnhaftigkeits“-Test bestanden hat. Wir müssten die Zeilen einzeln mit einem PL/pgSQL-Skript retten. Aber wenn eine Tabelle riesig ist und die Anzahl der beschädigten Tupel gering ist, ist dies höchst unpraktisch.
In einem solchen Fall sollten wir über die Verwendung der pg_surgery-Erweiterung nachdenken, um beschädigte Tupel einzufrieren oder zu entfernen. Aber erstens ist die korrekte Identifizierung beschädigter Tupel entscheidend, und zweitens existiert die Erweiterung seit PostgreSQL 14, sie ist in älteren Versionen nicht verfügbar. Ihre Funktionen erfordern ctid, aber wir müssen einen geeigneten Wert basierend auf der Seitennummer und der Ordnungszahl des Tupels auf der Seite erstellen, wir können kein beschädigtes ctid aus dem Tupel-Header verwenden, wie oben gezeigt.
Einfrieren vs. Löschen
Eingefrorene Tupel sind für alle Transaktionen sichtbar und verhindern das Blockieren von Lesevorgängen. Sie enthalten aber immer noch beschädigte Daten: Abfragen geben Müll zurück. Daher wird uns das bloße Einfrieren beschädigter Tupel höchstwahrscheinlich nicht helfen, und wir müssen beschädigte Tupel löschen. Das vorherige Einfrieren kann jedoch hilfreich sein, um sicherzustellen, dass wir die richtigen Tupel anvisieren. Einfrieren bedeutet einfach, dass die Funktion heap_force_freeze (mit dem richtigen ctid) t_xmin durch den Wert 2 (eingefrorenes Tupel) ersetzt, t_xmax durch 0 und t_ctid repariert.
Aber alle anderen Werte bleiben so, wie sie sind, d. h. immer noch beschädigt. Die Verwendung der pageinspect-Erweiterung, wie oben gezeigt, bestätigt, dass wir mit einem richtigen Tupel arbeiten. Nach dieser Überprüfung können wir beschädigte Tupel mit der Funktion heap_force_kill mit den gleichen Parametern löschen. Diese Funktion überschreibt den Pointer im Item-ID-Array für dieses spezifische Tupel und markiert es als tot.
Warnung: Funktionen in pg_surgery gelten per Definition als unsicher, verwenden Sie sie daher mit Vorsicht. Sie können sie wie jede andere Funktion aus SQL aufrufen, aber es handelt sich nicht um MVCC-transaktionale Operationen. Ihre Aktionen sind irreversibel: ROLLBACK kann ein Einfrieren oder Löschen nicht „rückgängig machen“, da diese Funktionen eine Heap-Seite in gemeinsam genutzten Puffern direkt modifizieren und die Änderung im WAL-Protokoll protokollieren. Daher sollten wir sie zuerst auf einer Kopie dieser spezifischen Tabelle (wenn möglich) oder auf einer Testtabelle testen. Das Löschen des Tupels kann auch zu Inkonsistenzen in Indizes führen, da das Tupel nicht mehr existiert, aber in einem Index referenziert werden könnte. Sie schreiben Änderungen in das WAL-Protokoll; daher wird die Änderung an Standbys repliziert.
Zusammenfassung
 PostgreSQL 17 führte Streaming-E/A ein – das Gruppieren mehrerer Seitenlesevorgänge in einen einzigen Systemaufruf und die Verwendung intelligenterer posix_fadvise()-Hinweise. Allein das führte in einigen Workloads zu bis zu ~30 % schnelleren sequenziellen Scans, aber es war immer noch strikt synchron: Jeder Backend-Prozess führte einen Lesevorgang aus und wartete dann darauf, dass der Kernel Daten zurückgab, bevor er fortfuhr. Vor PG17 las PostgreSQL typischerweise eine 8-kB-Seite gleichzeitig.
PostgreSQL 17 führte Streaming-E/A ein – das Gruppieren mehrerer Seitenlesevorgänge in einen einzigen Systemaufruf und die Verwendung intelligenterer posix_fadvise()-Hinweise. Allein das führte in einigen Workloads zu bis zu ~30 % schnelleren sequenziellen Scans, aber es war immer noch strikt synchron: Jeder Backend-Prozess führte einen Lesevorgang aus und wartete dann darauf, dass der Kernel Daten zurückgab, bevor er fortfuhr. Vor PG17 las PostgreSQL typischerweise eine 8-kB-Seite gleichzeitig.
- Sequenzielle Heap-Scans, wie einfache SELECT- und COPY-Operationen, die viele Daten streamen
- VACUUM auf großen Tabellen und Indizes
- ANALYZE-Stichproben
- Bitmap-Heap-Scans
Autovacuum profitiert ebenfalls von dieser Änderung, da seine Worker dieselben VACUUM/ANALYZE-Codepfade verwenden. Andere Operationen bleiben vorerst synchron:
- B‑Baum-Indexscans / Index‑Only-Scans
- Wiederherstellung & Replikation
- Alle Schreiboperationen INSERT, UPDATE, DELETE, WAL-Schreibvorgänge
- Kleine OLTP-Lookups, die eine einzelne Heap-Seite berühren
Es wird erwartet, dass zukünftige Arbeiten die Abdeckung erweitern, insbesondere Index‑Only-Scans und einige Optimierungen des Schreibpfads.
Signifikante Verbesserungen für Cloud-Volumes
Community-Benchmarks zeigen, dass PostgreSQL 18 AIO die Kaltcache-Datenlesevorgänge in Cloud-Setups mit netzwerkgebundenem Speicher, bei denen die Latenz hoch ist, deutlich verbessert. Die AWS-Dokumentation besagt, dass die durchschnittliche Latenz von Block Express-Volumes „unter 500 Mikrosekunden für 16 KiB E/A-Größe“ liegt, während die Latenz von General Purpose-Volumes 800 Mikrosekunden überschreiten kann. Einige Artikel legen nahe, dass unter hoher Last jeder physische Block, der von der Festplatte gelesen wird, etwa 1 ms kosten kann, während die Seitenverarbeitung in PostgreSQL viel günstiger ist. Indem wir viele Seiten in einem Lesevorgang kombinieren, kosten alle diese Seiten zusammen jetzt etwa 1 ms. Und indem wir mehrere Leseanforderungen gleichzeitig parallel ausführen, zahlen wir diese 1 ms Latenz effektiv nur einmal pro Batch.
Asynchrone E/A-Methoden
Das neue Subsystem kann in einem von drei Modi ausgeführt werden, die über den Parameter io_method mit den möglichen Werten „worker“ (Standard), „io_uring“ und „sync“ konfiguriert werden. Wir werden erläutern, wie die einzelnen Modi funktionieren, und dann zeigen, wie die asynchrone E/A in unserer Umgebung überwacht werden kann.
io_method = sync
Dieser Modus schaltet AIO effektiv aus. Lesevorgänge werden über dieselbe AIO-API, aber synchron ausgeführt, wobei reguläre preadv- oder pwritev-Methoden auf dem Backend-Prozess verwendet werden, der die E/A ausgegeben hat. Diese Methode verwendet keinen zusätzlichen gemeinsam genutzten Speicher und ist hauptsächlich für Regressionstests gedacht oder wenn wir vermuten, dass sich AIO falsch verhält. Sie wird auch intern als Fallback auf die synchrone E/A für Operationen verwendet, die keine asynchrone E/A verwenden können. PostgreSQL-Kernfunktionen geben einen Fehler aus, wenn eine Erweiterung versuchen würde, die asynchrone E/A über die AIO-API zu erzwingen, wenn die globale io_method auf „sync“ gesetzt ist. Verfügbare Benchmarks zeigen, dass dieser PostgreSQL 18-Modus ähnlich wie die Streaming-E/A von PostgreSQL 17 funktioniert.
io_method = io_uring (Linux only)
SELECT pg_config FROM pg_config() where pg_config::text ilike ’%liburing%’;
- Backends schreiben Anforderungen über die API in einen Submission-Ring im gemeinsam genutzten Speicher
- Der Kernel führt E/A asynchron aus und schreibt Ergebnisse in einen Completion-Ring
- Der Inhalt des Completion-Rings wird vom Backend mit weniger Kontextwechseln verarbeitet
Die Ausführung erfolgt weiterhin im selben Prozess wie bei der Methode „sync„, aber es werden Kernel-Worker-Threads für die parallele Verarbeitung verwendet. Dies ist typischerweise bei sehr schnellen NVMe-SSDs von Vorteil.
Die io_uring-Linux-Funktion hatte jedoch auch eine schwierige Sicherheitshistorie. Sie umgeht traditionelle Syscall-Audit-Pfade und war daher an einem großen Teil der Linux-Kernel-Exploits beteiligt. Google berichtete, dass 60 % der Linux-Kernel-Schwachstellen im Jahr 2022 io_uring betrafen und einige Sicherheitstools diese Art von Angriffen nicht aufdecken konnten. Daher deaktivieren einige Containerumgebungen io_uring vollständig.
io_method = worker
Dies ist die plattformübergreifende, „sichere“ Implementierung und der Standard in PostgreSQL 18. Der Mechanismus ist dem bestehenden parallelen Abfrageverarbeitung sehr ähnlich. Der Hauptunterschied besteht darin, dass Hintergrund-E/A-Worker langlebige, unabhängige Prozesse sind, die beim Serverstart erstellt werden, nicht kurzlebige Prozesse, die pro Abfrage erzeugt werden.
- Beim Serverstart erstellt der Postmaster einen Pool von E/A-Worker-Prozessen. Die Anzahl wird durch den Parameter io_workers mit einem Standardwert von 3 gesteuert. Benchmarks legen jedoch nahe, dass diese Zahl auf vielen Kernmaschinen höher sein sollte, typischerweise zwischen ¼ und ½ der verfügbaren CPU-Threads. Der beste Wert hängt von der Workload und der Speicherlatenz ab.
- Backends übermitteln Leseanforderungen in eine gemeinsam genutzte Speicher-Submission-Queue. Diese Submission-Queue ist im Allgemeinen ein Ringpuffer, in den mehrere Backends gleichzeitig schreiben können. Sie enthält nur Metadaten über die Anforderung – Handle-Indizes, nicht den vollständigen Anforderungsdatensatz. Es gibt nur eine Submission-Queue für den gesamten Cluster, nicht pro Datenbank oder pro Backend. Die tatsächlichen Details der Anforderung werden in einer separaten Speicherstruktur gespeichert.
- Es wird geprüft, ob die Anforderung synchron ausgeführt werden muss oder asynchron verarbeitet werden kann. Die synchrone Ausführung kann auch gewählt werden, wenn die Submission-Queue voll ist. Dies vermeidet Probleme mit der gemeinsam genutzten Speichernutzung unter extremer Last. Im Falle einer synchronen Ausführung verwendet der Code den Pfad für die oben beschriebene „sync“-Methode.
- Die Anforderungsübermittlung im gemeinsam genutzten Speicher weckt einen E/A-Worker auf, der die Anforderung abruft und traditionelle blockierende read() / pread()-Aufrufe ausführt. Wenn die Queue noch nicht leer ist, kann der aufgeweckte Worker 2 zusätzliche Worker aufwecken, um sie parallel zu verarbeiten. Im Code wird erwähnt, dass dies in Zukunft auf konfigurierbare N Worker erweitert werden kann. Dieses Limit hilft, das sogenannte „Thundering Herd Problem“ zu vermeiden, bei dem ein einzelner Submitter zu viele Worker aufwecken würde, was zu Chaos und Sperren für andere Backends führen würde.
- Eine Einschränkung für die asynchrone E/A ist die Tatsache, dass Worker nicht einfach von Backends geöffnete Dateideskriptoren wiederverwenden können, sondern Dateien in ihrem eigenen Kontext neu öffnen müssen. Wenn dies für einige Arten von Operationen nicht möglich ist, wird für diese spezifische Anforderung der synchrone E/A-Pfad verwendet.
- Wenn Worker eine Anforderung ohne Fehler abschließen, schreiben sie Datenblöcke in gemeinsam genutzte Puffer, legen das Ergebnis in eine Completion-Queue und signalisieren das Backend.
- Aus der Perspektive des Backends wird die E/A „asynchron“, da das „Warten“ in Worker-Prozessen stattfindet, nicht im Abfrageprozess selbst.
- Funktioniert auf allen unterstützten Betriebssystemen
- Einfache Fehlerbehandlung: Wenn ein Worker abstürzt, werden Anforderungen als fehlgeschlagen markiert, der Worker beendet und ein neuer Worker vom Postmaster erzeugt
- Vermeidet die Sicherheitsbedenken bezüglich der Linux io_uring-Schnittstelle
- Der Nachteil sind zusätzliche Kontextwechsel und mögliche Konflikte in der gemeinsam genutzten Speicher-Queue, aber für viele Workloads macht die Möglichkeit, Lesevorgänge einfach zu überlappen, das leicht wett.
- Diese Methode verbessert die Leistung auch dann, wenn alle Blöcke nur aus dem lokalen Linux-Speichercache kopiert werden, da dies jetzt parallel erfolgt
Tuning der neuen E/A-Parameter
PostgreSQL 18 fügt mehrere Parameter im Zusammenhang mit Festplatten-E/A hinzu oder aktualisiert sie. Wir haben bereits io_method und io_workers behandelt; sehen wir uns die anderen an. Weitere neue Parameter sind io_combine_limit und io_max_combine_limit. Sie steuern, wie viele Datenseiten PostgreSQL in einer einzigen AIO-Anforderung gruppiert. Größere Anforderungen führen typischerweise zu einem besseren Durchsatz, können aber auch die Latenz und die Speichernutzung erhöhen. Werte ohne Einheiten werden in 8-kB-Datenblöcken interpretiert. Mit Einheiten (kB, MB) stellen sie direkt die Größe dar – sollten jedoch Vielfache von 8 kB sein.
Der Parameter io_max_combine_limit ist eine feste Obergrenze beim Serverstart, io_combine_limit ist der vom Benutzer einstellbare Wert, der zur Laufzeit geändert werden kann, aber das Maximum nicht überschreiten darf. Die Standardwerte für beide sind 128 kB (16 Datenseiten). Die Dokumentation empfiehlt jedoch, unter Unix bis zu 1 MB (128 Datenseiten) und unter Windows 128 kB (16 Datenseiten – aufgrund von Einschränkungen in internen Windows-Puffern) einzustellen. Wir können mit höheren Werten experimentieren, aber basierend auf HW- und OS-Limits erreichen die AIO-Vorteile nach einer bestimmten Chunk-Größe ein Plateau; ein zu hohes Einstellen hilft nicht und kann sogar die Latenz erhöhen.
PostgreSQL 18 führt auch die Einstellung io_max_concurrency ein, die die maximale Anzahl von E/As steuert, die ein Prozess gleichzeitig ausführen kann. Die Standardeinstellung -1 bedeutet, dass der Wert automatisch basierend auf anderen Einstellungen ausgewählt wird, aber er darf 64 nicht überschreiten.
Ein weiterer verwandter Parameter ist effective_io_concurrency – die Anzahl der gleichzeitigen E/A-Operationen, die gleichzeitig auf dem Speicher ausgeführt werden können. Der Wertebereich liegt zwischen 1 und 1000, der Wert 0 deaktiviert asynchrone E/A-Anforderungen. Der Standardwert ist jetzt 16, einige Community-Artikel empfehlen, auf modernen SSDs bis zu 200 zu gehen. Die beste Einstellung hängt von der spezifischen Hardware und dem Betriebssystem ab, einige Artikel warnen jedoch auch davor, dass ein zu hoher Wert die E/A-Latenz für alle Abfragen erheblich erhöhen kann.
So überwachen Sie asynchrone E/A
pg_stat_activity
SELECT pid, backend_start, wait_event_type, wait_event, backend_type FROM pg_stat_activity WHERE backend_type = 'io worker'; pid | backend_start. | wait_event_type | wait_event | backend_type ------+-------------------------------+-----------------+--------------+-------------- 34 | 2025-12-09 11:44:23.852461+00 | Activity | IoWorkerMain | io worker 35 | 2025-12-09 11:44:23.852832+00 | Activity | IoWorkerMain | io worker 36 | 2025-12-09 11:44:23.853119+00 | IO | DataFileRead | io worker 37 | 2025-12-09 11:44:23.8534+00 | IO | DataFileRead | io worker
SELECT a.pid, a.usename, a.application_name, a.backend_type, a.state, a.query, ai.operation, ai.state AS aio_state, ai.length AS aio_bytes, ai.target_desc FROM pg_aios ai JOIN pg_stat_activity a ON a.pid = ai.pid ORDER BY a.backend_type, a.pid, ai.io_id; -[ RECORD 1 ]----+------------------------------------------------------------------------ pid | 58 usename | postgres application_name | psql backend_type | client backend state | active query. | explain analyze SELECT ........ operation | readv aio_state | SUBMITTED aio_bytes | 704512 target_desc | blocks 539820..539905 in file "pg_tblspc/16647/PG_18_202506291/5/16716" -[ RECORD 2 ]----+------------------------------------------------------------------------ pid | 159 usename | postgres application_name | psql backend_type | parallel worker state | active query | explain analyze SELECT ........ operation | readv aio_state | SUBMITTED aio_bytes | 704512 target_desc | blocks 536326..536411 in file "pg_tblspc/16647/PG_18_202506291/5/16716"
pg_aios: Current AIO handles
- pid: Backend, das die E/A ausgibt
- io_id, io_generation: identifizieren ein Handle über die Wiederverwendung hinweg
- state: HANDED_OUT, DEFINED, STAGED, SUBMITTED, COMPLETED_IO, COMPLETED_SHARED, COMPLETED_LOCAL
- operation: invalid, readv (vektorisierter Lesevorgang) oder writev (vektorisierter Schreibvorgang)
- off, length: Offset und Größe der E/A-Operation
- target, target_desc: was wir lesen/schreiben (typischerweise Relationen)
- result: UNKNOWN, OK, PARTIAL, WARNING, ERROR
-- Zusammenfassung der aktuellen AIO-Handles nach Status und Ergebnis SELECT state, result, count(*) AS cnt, pg_size_pretty(sum(length)) AS total_size FROM pg_aios GROUP BY state, result ORDER BY state, result; state | result | cnt | total_size ------------------+---------+-----+------------ COMPLETED_SHARED | OK | 1 | 688 kB SUBMITTED | UNKNOWN | 6 | 728 kB -- In-flight async I/O handles SELECT COUNT(*) AS aio_handles, SUM(length) AS aio_bytes FROM pg_aios; aio_handles | aio_bytes -------------+----------- 7 | 57344 -- Sessions currently waiting on I/O SELECT COUNT(*) AS sessions_waiting_on_io FROM pg_stat_activity WHERE wait_event_type = 'IO'; sessions_waiting_on_io ------------------------ 9
SELECT pid, state, operation, pg_size_pretty(length) AS io_size, target_desc, result FROM pg_aios ORDER BY pid, io_id; pid | state | operation | io_size | target_desc | result -----+-----------+-----------+------------+-------------------------------------------------------------------------+--------- 51 | SUBMITTED | readv | 688 kB | blocks 670470..670555 in file "pg_tblspc/16647/PG_18_202506291/5/16716" | UNKNOWN 63 | SUBMITTED | readv | 8192 bytes | block 1347556 in file "pg_tblspc/16647/PG_18_202506291/5/16719" | UNKNOWN 65 | SUBMITTED | readv | 688 kB | blocks 671236..671321 in file "pg_tblspc/16647/PG_18_202506291/5/16716" | UNKNOWN 66 | SUBMITTED | readv | 8192 bytes | block 1344674 in file "pg_tblspc/16647/PG_18_202506291/5/16719" | UNKNOWN 67 | SUBMITTED | readv | 8192 bytes | block 1337819 in file "pg_tblspc/16647/PG_18_202506291/5/16719" | UNKNOWN 68 | SUBMITTED | readv | 688 kB | blocks 672002..672087 in file "pg_tblspc/16647/PG_18_202506291/5/16716" | UNKNOWN 69 | SUBMITTED | readv | 688 kB | blocks 673964..674049 in file "pg_tblspc/16647/PG_18_202506291/5/16716" | UNKNOWN
pg_stat_io: Cumulative I/O stats
SELECT backend_type, context, sum(reads) AS reads,
pg_size_pretty(sum(read_bytes)) AS read_bytes,
round(sum(read_time)::numeric, 2) AS read_ms, sum(writes) AS writes,
pg_size_pretty(sum(write_bytes)) AS write_bytes,
round(sum(write_time)::numeric, 2) AS write_ms, sum(extends) AS extends,
pg_size_pretty(sum(extend_bytes)) AS extend_bytes
FROM pg_stat_io
WHERE object = 'relation' AND backend_type IN ('client backend')
GROUP BY backend_type, context
ORDER BY backend_type, context;
backend_type | context | reads | read_bytes | read_ms | writes | write_bytes | write_ms | extends | extend_bytes
----------------+-----------+---------+------------+-----------+--------+-------------+----------+---------+--------------
client backend | bulkread | 13833 | 9062 MB | 124773.28 | 0 | 0 bytes | 0.00 | |
client backend | bulkwrite | 0 | 0 bytes | 0.00 | 0 | 0 bytes | 0.00 | 0 | 0 bytes
client backend | init | 0 | 0 bytes | 0.00 | 0 | 0 bytes | 0.00 | 0 | 0 bytes
client backend | normal | 2265214 | 17 GB | 553940.57 | 0 | 0 bytes | 0.00 | 0 | 0 bytes
client backend | vacuum | 0 | 0 bytes | 0.00 | 0 | 0 bytes | 0.00 | 0 | 0 bytes
-- Top-Tabellen nach gelesenen Heap-Blöcken und Cache-Trefferrate
SELECT relid::regclass AS table_name, heap_blks_read, heap_blks_hit,
ROUND( CASE WHEN heap_blks_read + heap_blks_hit = 0 THEN 0
ELSE heap_blks_hit::numeric / (heap_blks_read + heap_blks_hit) * 100 END, 2) AS cache_hit_pct
FROM pg_statio_user_tables
ORDER BY heap_blks_read DESC LIMIT 20;
table_name | heap_blks_read | heap_blks_hit | cache_hit_pct
----------------------+----------------+---------------+---------------
table1 | 18551282 | 3676632 | 16.54
table2 | 1513673 | 102222970 | 98.54
table3 | 19713 | 1034435 | 98.13
...
-- Top-Indizes nach gelesenen Indexblöcken und Cache-Trefferrate
SELECT relid::regclass AS table_name, indexrelid::regclass AS index_name,
idx_blks_read, idx_blks_hit
FROM pg_statio_user_indexes
ORDER BY idx_blks_read DESC LIMIT 20;
table_name | index_name | idx_blks_read | idx_blks_hit
------------+-----------------+---------------+--------------
table1 | idx_table1_date | 209289 | 141
table2 | table2_pkey | 37221 | 1223747
table3 | table3_pkey | 9825 | 3143947
...
SELECT pg_stat_reset_shared(‚io‘);
Führen Sie dann unsere Arbeitslast aus und fragen Sie
pg_stat_io
erneut ab, um zu sehen, wie viele Bytes gelesen/geschrieben wurden und wie viel Zeit für das Warten auf E/A aufgewendet wurde.
Fazit
PostgreSQL ist ein eingetragenes Warenzeichen der PostgreSQL Community Association of Canada.
Wie ich in meinem Vortrag auf der PostgreSQL Conference Europe 2025 erläutert habe, kann Datenbeschädigung unbemerkt in jeder PostgreSQL-Datenbank vorhanden sein und bleibt unentdeckt, bis wir beschädigte Daten physisch lesen. Es kann viele Gründe geben, warum einige Datenblöcke in Tabellen oder anderen Objekten beschädigt werden können. Selbst moderne Speicherhardware ist alles andere als unfehlbar. Binäre Backups, die mit dem pg_basebackup-Tool erstellt wurden – einer sehr gängigen Backup-Strategie in der PostgreSQL-Umgebung – lassen diese Probleme verborgen. Denn sie prüfen keine Daten, sondern kopieren ganze Datendateien so, wie sie sind. Mit der Veröffentlichung von PostgreSQL 18 hat die Community beschlossen, Daten-Checksummen standardmäßig zu aktivieren – ein wichtiger Schritt zur frühzeitigen Erkennung dieser Fehler. Dieser Beitrag untersucht, wie PostgreSQL Checksummen implementiert, wie es Checksummenfehler behandelt und wie wir sie auf bestehenden Clustern aktivieren können.