Die Linux®-Installation für Anfänger mag auf den ersten Blick komplex erscheinen, doch mit der richtigen Anleitung ist der Umstieg auf das Open-Source-Betriebssystem durchaus machbar. Linux® bietet Sicherheit und Stabilität sowie vollständige Kostentransparenz ohne Lizenzgebühren. Dieser Leitfaden führt Sie durch die wichtigsten Schritte einer erfolgreichen Linux®-Installation: von der Auswahl der passenden Distribution über die Partitionierung bis zur ersten Konfiguration nach dem Start. (mehr …)
Der Linux®-Marktanteil wird bis 2026 voraussichtlich weiter wachsen, besonders in den Bereichen Server, Cloud-Computing und Enterprise-Lösungen. Während Linux® auf Desktop-Systemen noch eine Nische besetzt, ist es bereits bei Servern und Cloud-Infrastrukturen weit verbreitet. Diese Entwicklung beeinflusst Unternehmensentscheidungen erheblich, da Linux & Open Source-Lösungen sowohl Kosteneinsparungen als auch technische Flexibilität bieten.
Was bedeutet der aktuelle Linux-Marktanteil für Unternehmen?
Linux® hält derzeit etwa 3 % des Desktop-Marktes, ist jedoch mit über 70 % im Server-Bereich und nahezu 100 % der Top-500-Supercomputer weltweit vertreten. Diese Verteilung zeigt deutlich, in welchen Bereichen Linux & Open Source eingesetzt wird und welche strategischen Möglichkeiten Unternehmen daraus ableiten können.
Im Server-Segment nutzen Unternehmen Linux® aufgrund seiner Stabilität, Sicherheit und Kosteneffizienz. Cloud-Anbieter wie Amazon Web Services®, Google Cloud® und Microsoft® Azure® basieren ihre Infrastrukturen größtenteils auf Linux-Systemen. Diese Verbreitung macht Linux-Kenntnisse für IT-Teams relevant.
Für Geschäftsentscheidungen bedeutet dies konkret:
- Reduzierte Lizenzkosten durch den Wegfall proprietärer Betriebssystemlizenzen
- Flexibilität bei der Anpassung von Systemen an spezifische Anforderungen
- Sicherheit durch transparenten Quellcode und schnelle Patch-Zyklen
- Unabhängigkeit von einzelnen Herstellern und deren Lizenzpolitik
Mobile Geräte verstärken diesen Trend zusätzlich, da Android® auf dem Linux-Kernel basiert und damit einen großen Anteil mobiler Betriebssysteme ausmacht. Diese Verbreitung schafft ein Ökosystem, in dem Linux-Kompetenzen zunehmend relevant werden.
Wie entwickelt sich Linux im Vergleich zu anderen Betriebssystemen?
Linux® zeigt im Vergleich zu Windows® und macOS® unterschiedliche Entwicklungsmuster je nach Einsatzbereich. Während Windows den Desktop-Markt weiterhin führt, gewinnt Linux kontinuierlich Marktanteile im Server-Bereich mit Distributionen wie Ubuntu®, Red Hat® Enterprise Linux und SUSE®.
Im Enterprise-Umfeld wird Linux durch seine Anpassbarkeit und die Möglichkeit geschätzt, Systeme exakt auf Unternehmensanforderungen zuzuschneiden. Windows bleibt etabliert in Office-Umgebungen, bringt jedoch Lizenzkosten mit sich.
Die Eigenschaften von Linux zeigen sich besonders in:
- Container-Technologien und Mikroservice-Architekturen
- Cloud-nativen Anwendungen und DevOps-Umgebungen
- IoT-Geräten und eingebetteten Systemen
- Hochleistungsrechnen und wissenschaftlichen Anwendungen
macOS® behält seine Position in kreativen Branchen, während Linux in technischen und entwicklungsorientierten Umgebungen wächst. Diese Spezialisierung führt dazu, dass viele Unternehmen hybride Ansätze verfolgen, bei denen verschiedene Betriebssysteme je nach Anwendungsfall eingesetzt werden.
Der Trend zeigt: Linux gewinnt überall dort Marktanteile, wo technische Flexibilität, Kosteneffizienz und Anpassbarkeit relevant sind. Linux & Open Source-Technologien werden damit zu einer strategischen Option für zukunftsorientierte Unternehmen.
Welche Faktoren beeinflussen das Linux-Wachstum bis 2026?
Das Linux-Wachstum bis 2026 wird hauptsächlich durch Cloud-Computing, Containerisierung und die digitale Transformation vorangetrieben. Diese Technologietrends verstärken die Nachfrage nach flexiblen, kostengünstigen und sicheren Betriebssystemen, wodurch Linux & Open Source-Lösungen zunehmend relevant werden.
Cloud-Computing bleibt ein wichtiger Wachstumstreiber. Da die meisten Cloud-Infrastrukturen auf Linux basieren, steigt mit der Cloud-Adoption automatisch die Linux-Nutzung. Unternehmen, die ihre Workloads in die Cloud verlagern, kommen unweigerlich mit Linux-Systemen in Kontakt.
Container-Technologien wie Docker® und Kubernetes® oder Virtualisierung mit beispielsweise Proxmox®, die primär auf Linux laufen, verändern die Art, wie Anwendungen entwickelt und bereitgestellt werden. Diese Technologien ermöglichen es Unternehmen, Anwendungen effizienter zu skalieren und zu verwalten.
Weitere entscheidende Faktoren sind:
- Internet of Things (IoT) – Linux läuft auf vielen IoT-Geräten aufgrund seiner Anpassbarkeit
- Kosteneinsparungen – keine Lizenzgebühren und reduzierte Hardware-Anforderungen
- Sicherheitsaspekte – transparenter Code und schnelle Sicherheitsupdates
- Edge Computing – Linux eignet sich für dezentrale Rechenarchitekturen
- Künstliche Intelligenz – die meisten KI-Frameworks laufen auf Linux
Die wachsende Bedeutung von Open Source in der digitalen Transformation verstärkt diese Entwicklung zusätzlich. Unternehmen erkennen zunehmend den Wert offener Standards und herstellerunabhängiger Lösungen für ihre langfristige IT-Strategie.
Warum setzen immer mehr deutsche Unternehmen auf Linux?
Deutsche Unternehmen wenden sich verstärkt Linux zu, da es den strengen Datenschutzanforderungen der DSGVO entspricht und vollständige Kontrolle über Datenverarbeitung und -speicherung ermöglicht. Die Transparenz von Linux & Open Source-Systemen erleichtert die Erfüllung von Compliance-Anforderungen erheblich.
Regulatorische Aspekte spielen eine entscheidende Rolle. Deutsche Behörden und Unternehmen schätzen die Möglichkeit, den Quellcode zu prüfen und sicherzustellen, dass keine versteckten Funktionen oder Backdoors existieren. Diese Transparenz ist besonders wichtig für kritische Infrastrukturen und sensible Datenverarbeitung.
Kostenfaktoren verstärken die Linux-Adoption in Deutschland zusätzlich. Mittelständische Unternehmen können durch den Wegfall von Lizenzkosten erhebliche Einsparungen erzielen, die in andere Bereiche der Digitalisierung investiert werden können.
Spezifische Aspekte für deutsche Unternehmen:
- Datensouveränität durch vollständige Kontrolle über IT-Systeme
- Unabhängigkeit von einzelnen Technologieanbietern
- Unterstützung der europäischen Digitalstrategie
- Förderung lokaler IT-Kompetenz und Innovation
- Langfristige Planungssicherheit ohne Lizenzüberraschungen
Die deutsche Präferenz für Engineering-Exzellenz und technische Perfektion harmoniert mit der Linux-Philosophie. Open Source ermöglicht es deutschen Unternehmen, Systeme nach ihren exakten Anforderungen zu optimieren und dabei hohe Qualitätsstandards zu erfüllen.
Wie credativ® bei der Linux-Migration und -Betreuung hilft
credativ® unterstützt Unternehmen seit 1999 bei der erfolgreichen Einführung und dem Betrieb von Linux-Systemen durch umfassende Beratung, professionelle Migration und kontinuierlichen 24/7-Support. Als herstellerunabhängiges Unternehmen bieten wir maßgeschneiderte Linux & Open Source-Lösungen für jede Unternehmensgröße.
Unsere Linux-Services umfassen:
- Strategische Beratung für Linux-Migrationen und Systemarchitekturen
- Professionelle Migration von bestehenden Systemen auf Linux-Plattformen
- 24/7-Support für Debian Linux, PostgreSQL® und weitere Open-Source-Projekte
- Schulungen und Wissenstransfer für interne IT-Teams
- Langfristige Wartung und Optimierung von Linux-Infrastrukturen
Als deutsches Unternehmen verstehen wir die spezifischen Anforderungen des deutschen Marktes, einschließlich Datenschutzbestimmungen und Compliance-Vorgaben. Unser Support-Team besteht ausschließlich aus festangestellten Spezialisten ohne zwischengeschaltetes Callcenter.
Sie möchten die Möglichkeiten von Linux für Ihr Unternehmen nutzen? Kontaktieren Sie uns für eine unverbindliche Beratung und erfahren Sie, wie wir Ihre Linux-Migration erfolgreich gestalten können. Vereinbaren Sie noch heute einen Termin mit unseren Linux-Experten.
Transparenzhinweis
credativ® ist autorisierter Reseller für Red Hat® (Red Hat Inc.) und PostgreSQL® Competence Center (PostgreSQL Community). Linux® ist eine eingetragene Marke von Linus Torvalds. Windows®, Microsoft® und Azure® sind eingetragene Marken der Microsoft Corporation. Amazon Web Services® ist eine eingetragene Marke von Amazon.com Inc. Google Cloud® ist eine eingetragene Marke von Google LLC. Android® ist eine eingetragene Marke von Google LLC. Ubuntu® ist eine eingetragene Marke von Canonical Ltd. SUSE® ist eine eingetragene Marke der SUSE LLC. Docker® ist eine eingetragene Marke von Docker Inc. Kubernetes® ist eine eingetragene Marke der Cloud Native Computing Foundation. macOS® ist eine eingetragene Marke der Apple Inc.
Die Nennung der Marken dient ausschließlich der sachlichen Beschreibung von Migrationsszenarien und Dienstleistungen der credativ GmbH. Es besteht keine geschäftliche Verbindung zu den genannten Markeninhabern.
Foreman ist eindeutig in einer IPv4-Welt verwurzelt. Das sieht man überall. Es scheint, als ob es Ihnen keinen Host ohne IPv4 geben möchte, aber ohne IPv6 ist es in Ordnung. Aber das muss nicht so sein, also begeben wir uns gemeinsam auf eine Reise, um Foreman und die Dinge um ihn herum in die Gegenwart zu bringen.
(mehr …)
Vom 14. bis 19 Juli 2025 findet diese Woche im westfranzösischen Brest die diesjährige Debian Conference (DebConf25) mit über 450 Teilnehmern statt – das zentrale Treffen der weltweiten Debian-Community. Die DebConf bringt jährlich Entwickler:innen, Maintainer, Contributor und Interessierte zusammen, um gemeinsam an der freien Linux-Distribution Debian zu arbeiten und sich zu aktuellen Entwicklungen auszutauschen.
credativ ist dieses Jahr wieder als Sponsor dabei – aber auch mit einigen Mitarbeiter vor Ort vertreten.
Eine Woche im Zeichen freier Software
Die DebConf25 bietet ein breit gefächertes Programm mit über 130 Sessions: technische Vorträge, Diskussionsrunden, Workshops und BoF-Sessions („Birds of a Feather“) zu ganz unterschiedlichen Themen aus dem Debian-Kosmos. Einige Schwerpunkte dieses Jahres:
- Fortschritte rund um Debian 13 „Trixie“, an dessen Veröffentlichung aktuell stark gearbeitet wird
- Reproducible Builds, Systemintegration und Security-Themen
- Debian in Cloud-Umgebungen und im Container-Kontext
- Verbesserte CI/CD-Infrastruktur und neue Tools für Maintainer:innen
Viele der Vorträge werden, wie immer, aufgezeichnet und sind auf video.debian.net öffentlich verfügbar, oder aber sind live über https://debconf25.debconf.org/ anschaubar.
credativ engagiert sich – nicht nur vor Ort
Als langjähriger Teil der Debian-Community ist es für credativ selbstverständlich auch 2025 wieder als Sponsor zur DebConf beizutragen. Darüber hinaus sind unsere Kollegen Bastian, Martin und Noël vor Ort, um sich mit anderen Entwickler:innen auszutauschen, Vorträge oder BoFs zu besuchen und aktuelle Trends in der Community mitzuerleben.
Gerade für Unternehmen mit Fokus auf professionelle Open-Source-Dienstleistungen ist Debian nach wie vor eine tragende Säule – ob im Rechenzentrum, im Embedded-Bereich oder in komplexen Infrastrukturprojekten.
Debian bleibt relevant – technisch wie kulturell
Debian ist nicht nur eine der stabilsten und zuverlässigsten Linux-Distributionen, sondern steht auch für eine besondere Form von Community und Zusammenarbeit. Die offene, transparente und dezentrale Organisation des Projekts ist bis heute beispielhaft.
Für uns bei credativ ist das Debian-Projekt seit jeher ein zentrales Element unserer Arbeit – und gleichzeitig eine Gemeinschaft, zu der wir durch technische Beiträge, Paketpflege und langfristiges Engagement aktiv beitragen.
Danke, DebConf-Team!
Ein herzlicher Dank geht an das Organisationsteam der DebConf25 sowie an alle Helfer:innen, die diese großartige Konferenz möglich gemacht haben. Brest ist ein wunderschöner und passender Veranstaltungsort mit frischer Atlantikluft, einer entspannten Atmosphäre und viel Raum für Austausch und Zusammenarbeit.
Ausblick auf 2026
Die Planungen für die DebConf26 laufen bereits. Wir freuen uns auf die nächste Ausgabe der DebConf, welche in Santa Fe, Argentinien stattfinden wird – und darauf, auch in Zukunft Teil dieser lebendigen und wichtigen Community zu sein.
Debian Bug Squashing Party 2025 in Wien
Es war wieder soweit, wir waren mit auf der Debian Bug Squashing Party 2025!
 Auch dieses Jahr hatten wir wieder die Gelegenheit an der Debian Bug Squashing Party (BSP) 2025 teilzunehmen. Alexander (formorer) und Florian (gyptazy) vertraten dabei uns als credativ GmbH und wirkten aktiv am Geschehen mit. Auch diesmal war es ein spannendes und produktives Event, bei dem Entwickler und Debian-Enthusiasten zusammenkamen, um gemeinsam an der Verbesserung des Debian-Projekts zu arbeiten.
Auch dieses Jahr hatten wir wieder die Gelegenheit an der Debian Bug Squashing Party (BSP) 2025 teilzunehmen. Alexander (formorer) und Florian (gyptazy) vertraten dabei uns als credativ GmbH und wirkten aktiv am Geschehen mit. Auch diesmal war es ein spannendes und produktives Event, bei dem Entwickler und Debian-Enthusiasten zusammenkamen, um gemeinsam an der Verbesserung des Debian-Projekts zu arbeiten.
Einführung
Wenn es um die Bereitstellung von erweitertem Support für End-of-Life (EOL) Linux-Distributionen geht, kann die traditionelle Methode, Pakete aus Quellen zu erstellen, bestimmte Herausforderungen mit sich bringen. Eine der größten Herausforderungen ist die Notwendigkeit für einzelne Entwickler, Build-Abhängigkeiten in ihren eigenen Build-Umgebungen zu installieren. Dies führt oft zur Installation unterschiedlicher Build-Abhängigkeiten, was zu Problemen bei der Binärkompatibilität führt. Zusätzlich sind weitere Herausforderungen zu berücksichtigen, wie die Einrichtung einer isolierten und sauberen Build-Umgebung für verschiedene parallele Paket-Builds, die Implementierung einer effektiven Strategie zur Paketvalidierung und die Verwaltung der Repository-Veröffentlichung usw.
Um diese Herausforderungen zu meistern, wird dringend empfohlen, eine dedizierte Build-Infrastruktur zu haben, die das Erstellen von Paketen auf konsistente und reproduzierbare Weise ermöglicht. Mit einer solchen Infrastruktur können Teams diese Probleme effektiv angehen und sicherstellen, dass die notwendigen Pakete und Abhängigkeiten verfügbar sind, wodurch die Notwendigkeit für einzelne Entwickler entfällt, ihre eigenen Build-Umgebungen zu verwalten.
Der Open Build Service (OBS) von OpenSUSE bietet eine weithin anerkannte öffentliche Build-Infrastruktur, die RPM-basierte, Debian-basierte und Arch-basierte Paket-Builds unterstützt. Diese Infrastruktur ist bei Anwendern, die angepasste Paket-Builds auf wichtigen Linux-Distributionen benötigen, hoch angesehen. Zusätzlich kann OBS als private Instanz bereitgestellt werden, was eine robuste Lösung für Organisationen bietet, die private Softwarepaket-Builds durchführen. Mit seinem umfangreichen Funktionsumfang dient OBS als umfassende Build-Infrastruktur, die die Anforderungen von Teams erfüllt, um sicherheitsgepatchte Pakete auf Basis bereits vorhandener Pakete zu erstellen, um beispielsweise den Support von End-of-Life (EOL) Linux-Distributionen zu verlängern.
Fakten
Am 30. Juni 2024 haben zwei wichtige Linux-Distributionen, Debian 10 „Buster“ und CentOS 7, ihren End-of-Life (EOL)-Status erreicht. Diese Distributionen fanden in zahlreichen großen Unternehmensumgebungen weite Verbreitung. Aufgrund verschiedener Faktoren können Organisationen jedoch Schwierigkeiten haben, Migrationsprozesse rechtzeitig abzuschließen, was eine vorübergehende erweiterte Unterstützung für diese Distributionen erforderlich macht.
Wenn eine Distribution ihren End-of-Life (EOL)-Support vom Upstream erreicht, werden Spiegelserver und die entsprechende Infrastruktur typischerweise entfernt. Dies stellt eine erhebliche Herausforderung für Organisationen dar, die diese Distributionen noch verwenden und erweiterten Support suchen, da sie nicht nur Zugang zu einem lokalen Offline-Spiegel benötigen, sondern auch die Infrastruktur, um Pakete so neu zu erstellen, dass dies mit ihren früheren originalen Upstream-Builds konsistent ist, wann immer Pakete aus Sicherheitsgründen neu erstellt werden müssen.
Ziel
Um Dienstprogramme bereitzustellen, die Teams beim Erstellen von Paketen unterstützen, kann OBS ihnen helfen. Dabei hilft es ihnen auch, eine Build-Infrastruktur zu haben, die alle vorhandenen Quell- und Binärpakete zusammen mit ihren Sicherheitspatches in einer semi-originalen Build-Umgebung erstellt und so den Support für EOL Linux-Distributionen weiter verlängert. Dies wird erreicht, indem Paket-Builds auf einem ähnlichen Qualitäts- und Kompatibilitätsniveau wie ihre früheren originalen Upstream-Builds gehalten werden.
Anforderungen
Um das oben genannte Ziel zu erreichen, sind zwei wesentliche Komponenten erforderlich:
- Lokaler Spiegel der EOL Linux-Distribution
- Private OBS-Instanz.
Um eine private OBS-Instanz einzurichten, können Sie OBS aus dem Upstream-GitHub-Repository beziehen und auf Ihrem lokalen Rechner installieren sowie bauen, oder alternativ können Sie einfach den OBS Appliance Installer herunterladen, um eine private OBS-Instanz als neue Build-Infrastruktur zu integrieren.
Beachten Sie, dass der lokale Spiegel typischerweise nicht die Sicherheitspatches enthält, um den Support der EOL-Distribution ordnungsgemäß zu erweitern. Das bloße Neuerstellen der vorhandenen Pakete verlängert den Support solcher Distributionen nicht automatisch. Entweder müssen diese Sicherheitspatches von den Teams selbst gepflegt und manuell zum Paket-Update hinzugefügt werden, oder sie werden von einem Upstream-Projekt bezogen, das diese Patches bereits bereitstellt.
Nichtsdestotrotz kann die private OBS-Instanz, sobald sie erfolgreich installiert ist, mit dem lokalen Offline-Spiegel verknüpft werden, für den das Team den Support erweitern möchte, und als semi-originale Build-Umgebung konfiguriert werden. Dadurch kann die Build-Umgebung so nah wie möglich an die ursprüngliche Upstream-Build-Umgebung konfiguriert werden, um ein ähnliches Qualitäts- und Kompatibilitätsniveau zu gewährleisten, auch wenn Pakete für Sicherheitsupdates mit neuen Patches erstellt werden.
Auf diese Weise kann der bereits beendete Support einer Linux-Distribution verlängert werden, da ein dafür vorgesehenes Team nicht nur Pakete selbst erstellen, sondern auch Patches für Pakete bereitstellen kann, die von Fehlern oder Sicherheitslücken betroffen sind.
Ergebnis
Die OBS-Build-Infrastruktur bietet eine semi-originale Build-Umgebung, um den Paket-Build-Prozess zu vereinfachen, Inkonsistenzen zu reduzieren und Reproduzierbarkeit zu erreichen. Durch diesen Ansatz können Teams ihre Entwicklungs- und Test-Workflows vereinfachen und die Gesamtqualität und Zuverlässigkeit der generierten Pakete verbessern.
Demonstration
Wir möchten Ihnen demonstrieren, wie OBS als Build-Infrastruktur für Teams genutzt werden kann, um die benötigte Build- und Veröffentlichungs-Infrastruktur zur Verlängerung des Supports von End-of-Life (EOL) Linux-Distributionen bereitzustellen. Bitte beachten Sie jedoch, dass die folgenden Beispiele ausschließlich Demonstrationszwecken dienen und den spezifischen Ansatz möglicherweise nicht exakt widerspiegeln.
OBS konfigurieren
Sobald Ihre private OBS-Instanz eingerichtet ist, können Sie sich über die WebUI bei OBS anmelden. Sie müssen das Konto „Admin“ mit dem Standardpasswort „opensuse“ verwenden. Danach können Sie ein neues Projekt für die EOL Linux-Distribution erstellen sowie Benutzer und Gruppen für Teams hinzufügen, die an diesem Projekt arbeiten werden. Zusätzlich müssen Sie Ihr Projekt mit einem lokalen Spiegel der EOL Linux-Distribution verknüpfen und Ihr OBS-Projekt anpassen, um die frühere Upstream-Build-Umgebung zu replizieren.
OBS unterstützt die Funktion Download on Demand (DoD), die eine Verbindung zu einem lokalen Spiegel auf der OBS-Instanz mit dem dafür vorgesehenen Projekt innerhalb von OBS herstellen kann, um Build-Abhängigkeiten während des Build-Prozesses bei Bedarf abzurufen. Dies vereinfacht den Build-Workflow und reduziert den Bedarf an manuellen Eingriffen.
Hinweis: Einige Konfigurationen sind nur mit dem Admin-Konto verfügbar, darunter Benutzer verwalten, Gruppen und Download on Demand (DoD)-Repository hinzufügen.
Tauchen wir nun in die OBS-Konfiguration eines solchen Projekts ein.
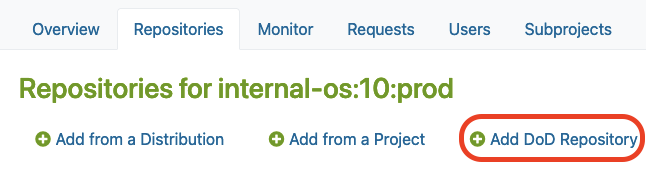
DoD-Repository hinzufügen
Nachdem Sie ein neues Projekt in OBS erstellt haben, finden Sie die Option „DoD-Repository hinzufügen“ im Reiter „Repositories“ unter dem Admin-Konto.
Dort müssen Sie auf die Schaltfläche „DoD-Repository hinzufügen“ klicken, wie unten gezeigt:
Lokalen Spiegel über DoD verknüpfen
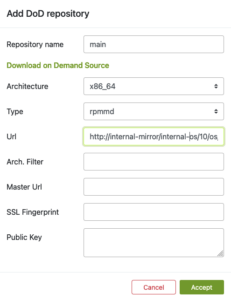
Als Nächstes können Sie eine URL angeben, um Ihren lokalen Spiegel über „DoD-Repository hinzufügen“ zu verknüpfen.
Dadurch konfigurieren Sie das DoD-Repository. Dafür müssen Sie:
- DoD-Repository benennen
- Geben Sie eine URL an, die auf den lokalen Spiegel verweist, der als Basis für das Erstellen von Paketen in unserem Projekt verwendet wird
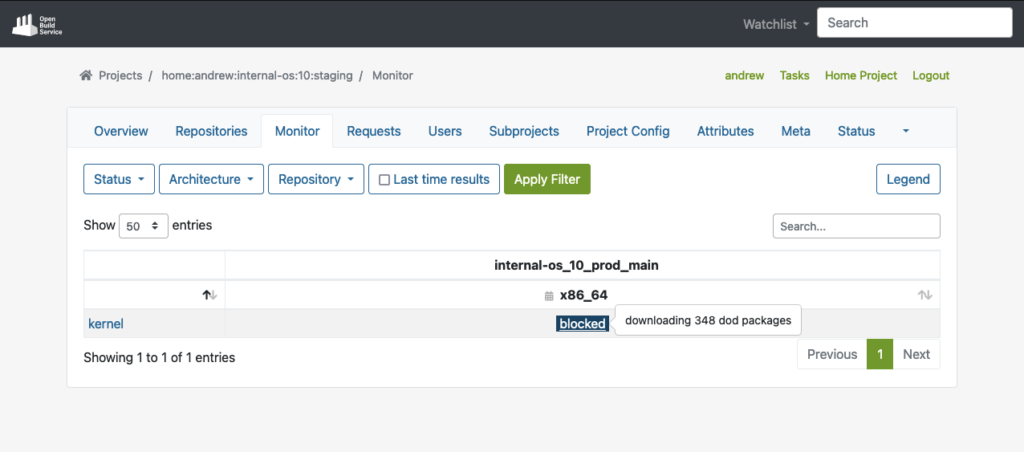
Die Build-Abhängigkeiten sollten nun für OBS automatisch über die DoD-Funktion zum Download verfügbar sein.
Wie Sie im folgenden Beispiel sehen können, konnte OBS alle Build-Abhängigkeiten für das gezeigte Paket „kernel“ über DoD abrufen, bevor es tatsächlich mit dem Erstellen des Pakets begann:
Nachdem Sie den lokalen Spiegel mit der EOL Linux-Distribution verbunden haben, sollten wir auch die Projektkonfiguration anpassen, um die semi-originale Build-Umgebung des früheren Upstream-Projekts in unserem OBS-Projekt neu zu erstellen.
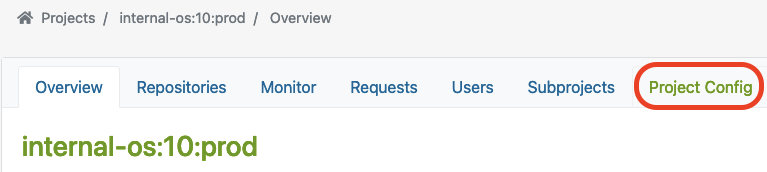
Projektkonfiguration
OBS bietet eine anpassbare Build-Umgebung über die Projektkonfiguration, die es Teams ermöglicht, spezifische Projektanforderungen zu erfüllen.
Es ermöglicht Teams, die Build-Umgebung über die Projektkonfiguration anzupassen, wodurch sie Makros, Pakete, Flags und andere Build-bezogene Einstellungen definieren können. Dies hilft, ihr Projekt an alle Anforderungen anzupassen, die zur Aufrechterhaltung der Kompatibilität mit den Originalpaketen erforderlich sind.
Die Projektkonfiguration finden Sie hier:
Werfen wir einen genaueren Blick auf einige Beispiele, die zeigen, wie die Projektkonfiguration für das Erstellen von RPM-basierten oder Debian-basierten Paketen aussehen könnte.
Je nach dem tatsächlichen Pakettyp, der von der EOL Linux-Distribution verwendet wurde, muss die Projektkonfiguration entsprechend angepasst werden.
RPM-basierte Konfiguration
Hier ist ein Beispiel für eine RPM-basierte Distribution, wo Sie Makros, Pakete, Flags und andere Build-bezogene Einstellungen definieren können.
Bitte beachten Sie, dass dieses Beispiel nur zu Demonstrationszwecken dient:
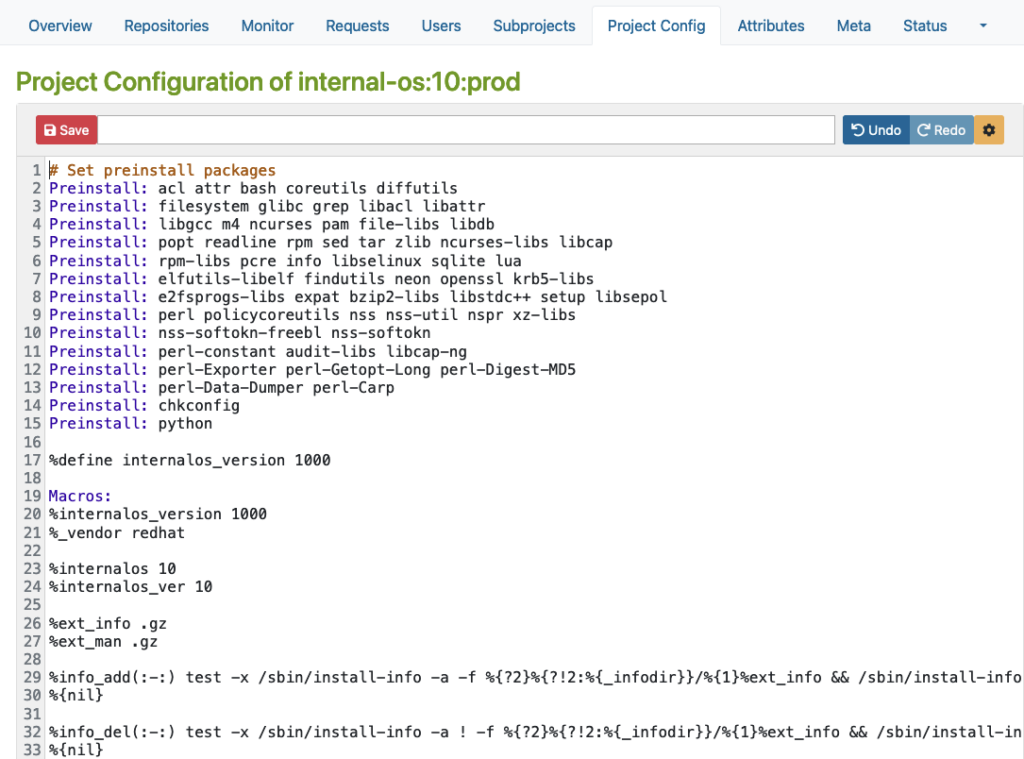
Debian-basierte Konfiguration
Dann gibt es ein weiteres Beispiel für eine Debian-basierte Distribution, wo Sie Repotype: debian angeben, vorinstallierte Pakete definieren und Build-bezogene Einstellungen in der Build-Umgebung festlegen können.
Auch hier gilt: Bitte beachten Sie, dass dieses Beispiel nur zu Demonstrationszwecken dient:
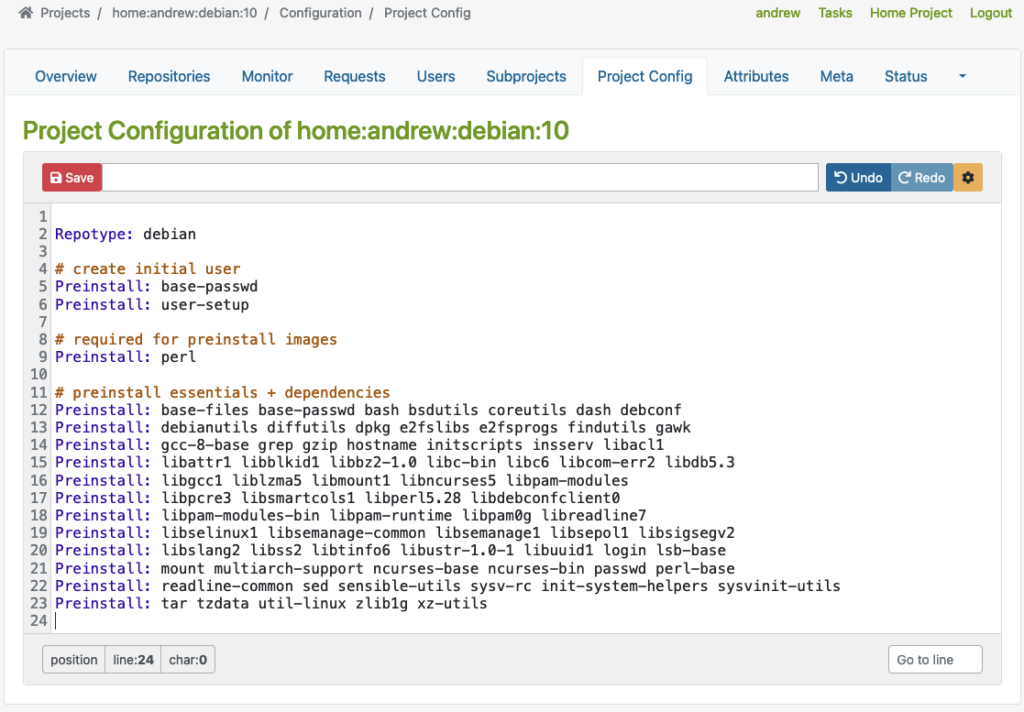
Wie Sie in den obigen Beispielen sehen können, definiert die Repotype das Repository-Format für die veröffentlichten Repositories. Preinstall definiert Pakete, die in der Build-Umgebung verfügbar sein sollten, während andere Pakete erstellt werden. Weitere Details zur Syntax finden Sie im Kapitel Build-Konfiguration im von OpenSuSE bereitgestellten Handbuch.
Mit dieser anpassbaren Build-Umgebungsfunktion beginnt jeder Build in einer sauberen Chroot- oder KVM-Umgebung, was Konsistenz und Reproduzierbarkeit im Build-Prozess gewährleistet. Teams können unterschiedliche Build-Umgebungen in verschiedenen Projekten haben, die isoliert sind und parallel erstellt werden können. Die getrennten Projekte, zusammen mit dedizierten Chroot- oder KVM-Umgebungen für das Erstellen von Paketen, verhindern Interferenzen oder Konflikte zwischen Builds.
Benutzerverwaltung
Zusätzlich zu Projekten bietet OBS eine flexible Zugriffssteuerung, die es Teammitgliedern ermöglicht, unterschiedliche Rollen und Berechtigungen für verschiedene Projekte oder Distributionen zu haben. Dies gewährleistet eine effiziente Zusammenarbeit und ein optimiertes Workflow-Management.
Um diese Funktion ordnungsgemäß zu nutzen, müssen wir Benutzer und Gruppen über das Admin-Konto in OBS erstellen. Den Reiter „Benutzer“ finden Sie innerhalb des Projekts, wo Sie Benutzer und Gruppen mit unterschiedlichen Rollen hinzufügen können.
Das folgende Beispiel zeigt, wie Benutzer und Gruppen in einem bestimmten Projekt hinzugefügt werden:
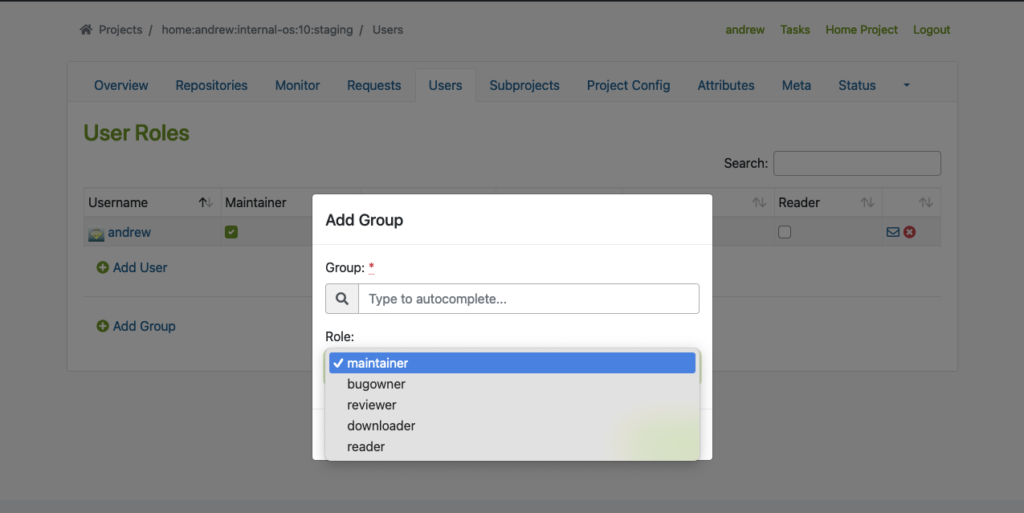
Flexible Projekteinrichtung
OBS ermöglicht Teams, separate Projekte für Entwicklungs-, Staging- und Veröffentlichungszwecke zu erstellen. Dieser kontrollierte Workflow gewährleistet eine gründliche Prüfung und Validierung von Paketen, bevor sie zur Veröffentlichung an das Produktionsprojekt übermittelt werden.
Teststrategie mit Projekten
Bevor Pakete freigegeben und veröffentlicht werden, ist eine ordnungsgemäße Prüfung dieser Pakete entscheidend. Um dies zu erreichen, bietet OBS eine Repository-Veröffentlichungs-Integration, die bei der Implementierung einer Teststrategie hilft. Entwickler können ihre Pakete zuerst in einem entsprechenden Staging-Repository veröffentlichen lassen, bevor der Validierungsprozess der Pakete beginnt, damit sie an das Produktionsprojekt übermittelt werden können. Von dort aus werden sie dann veröffentlicht und anderen Systemen zur Verfügung gestellt.
Es integriert sich nahtlos in die lokale Repository-Veröffentlichung, wodurch sichergestellt wird, dass alle Pakete im Build-Prozess sofort verfügbar sind. Dies eliminiert die Notwendigkeit zusätzlicher Konfigurationen auf internen oder externen Repositories.
Das nächste Beispiel zeigt ein Projekt ‚home:andrew:internal-os:10:staging‘, das als Staging-Repository verwendet wird. Dort importieren wir das Nginx-Quellpaket, um es anschließend zu erstellen und zu validieren.
Build-Prozess starten
Sobald die Build-Abhängigkeiten über DoD heruntergeladen wurden, startet der Build-Prozess automatisch.

Sobald der Build-Prozess für ein Paket wie „nginx“ erfolgreich ist, werden wir es auch in der Oberfläche sehen:
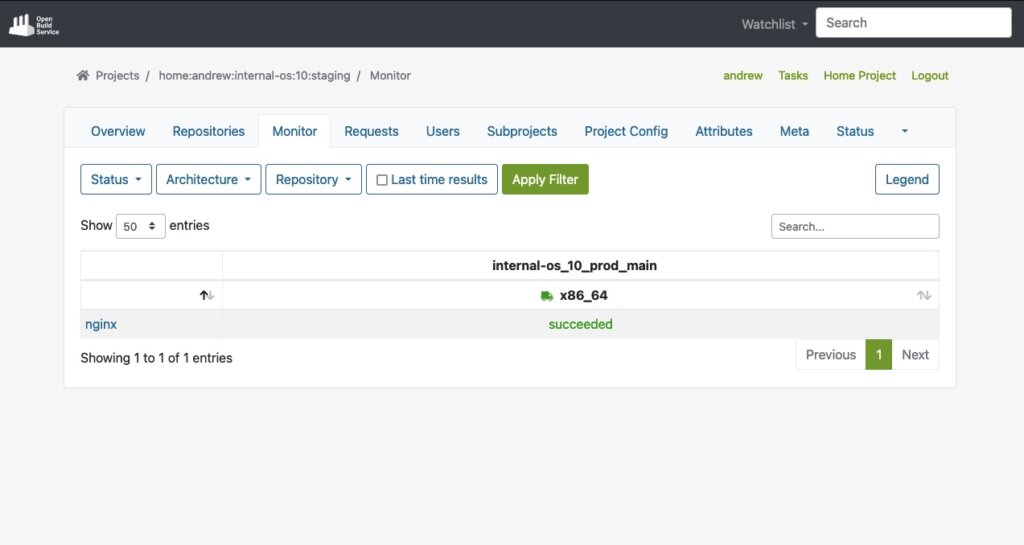
Zu guter Letzt wird das Paket automatisch in einem Repository veröffentlicht, das bereit ist, mit Paketmanagern wie YUM verwendet zu werden. In unserem Testfall hilft uns das YUM-bereite Repository, die Validierung einfach durchzuführen, indem wir Tests auf VMs oder tatsächlicher Hardware durchführen.
Unten sehen Sie ein Beispiel dieses Staging-Repositorys (Index des YUM-bereiten Staging-Repositorys):
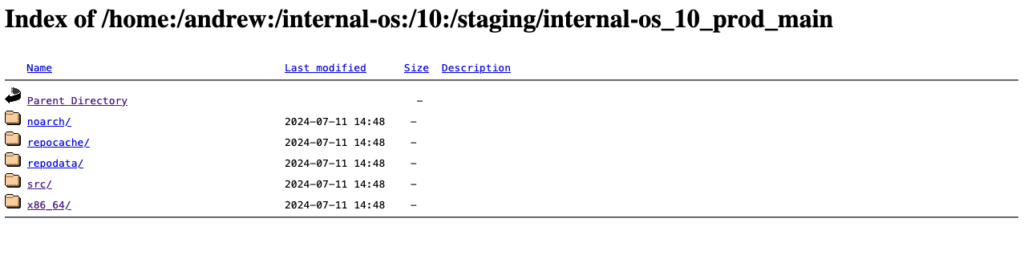
Bitte beachten Sie: Um die Teststrategie in unserem Beispiel zu erfüllen, sollten Pakete nur an das Produktionsprojekt übermittelt werden, sobald sie den Validierungsprozess im Staging-Repository erfolgreich durchlaufen haben.
Nach Validierung an Produktion übermitteln
Sobald wir die Funktionalität eines Pakets im Staging-Projekt und -Repository validiert haben, können wir fortfahren, indem wir das Paket an das Produktionsprojekt übermitteln. Unterhalb der Paketübersichtsseite (z. B. in unserem Fall das Paket „nginx“) finden Sie die Schaltfläche „Paket übermitteln“, um diesen Prozess zu starten:
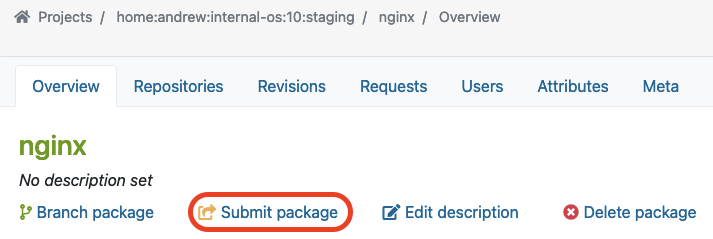
In unserem Beispiel verwenden wir das Projekt ‚internal-os:10:prod‘ für das Produktions-Repository. Zuvor haben wir das Paket „nginx“ im Staging-Repository erstellt und validiert. Nun möchten wir dieses Paket in das Produktionsprojekt übermitteln, das wir ‚internal-os:10:prod‘ nennen.
Sobald Sie auf „Paket übermitteln“ klicken, sollte das folgende Dialogfeld erscheinen. Hier können Sie das Formular ausfüllen, um das neu erstellte Paket an die Produktion zu übermitteln:
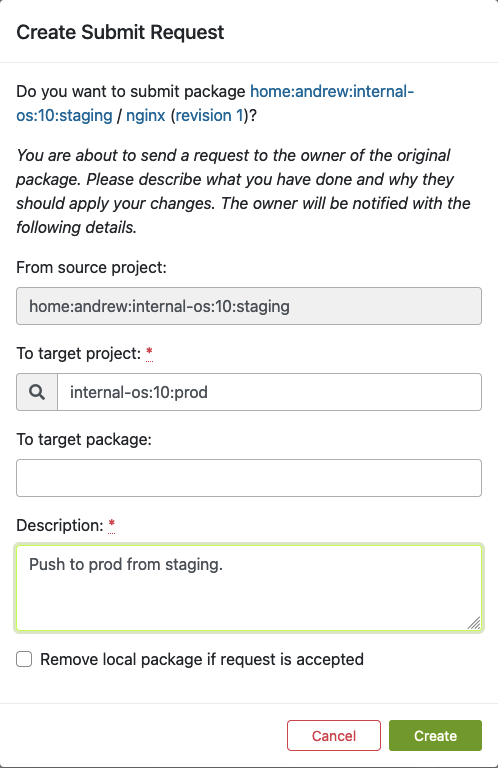
Füllen Sie dieses Formular aus und klicken Sie auf „Erstellen“, sobald Sie bereit sind, das neue Paket an das Produktionsprojekt zu übermitteln.
Anfragen finden
Neben der Übermittlung eines Pakets muss ein sogenannter Repository-Master die neu erstellten Anfragen für das vorgesehene Projekt genehmigen. Dieser Master findet eine Liste aller Anfragen im Reiter Anfragen, wo er/sie die Anfragen-Überprüfung durchführen kann.
Der Master findet „Anfragen“ auf der Projektübersichtsseite wie folgt:
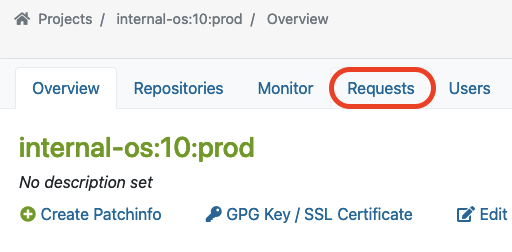
Hier sehen Sie ein Beispiel eines Pakets, das vom Staging an das Produktionsprojekt übermittelt wurde.
Der Master muss auf den mit einem roten Kreis markierten Link klicken, um die Anfragen-Überprüfung durchzuführen:
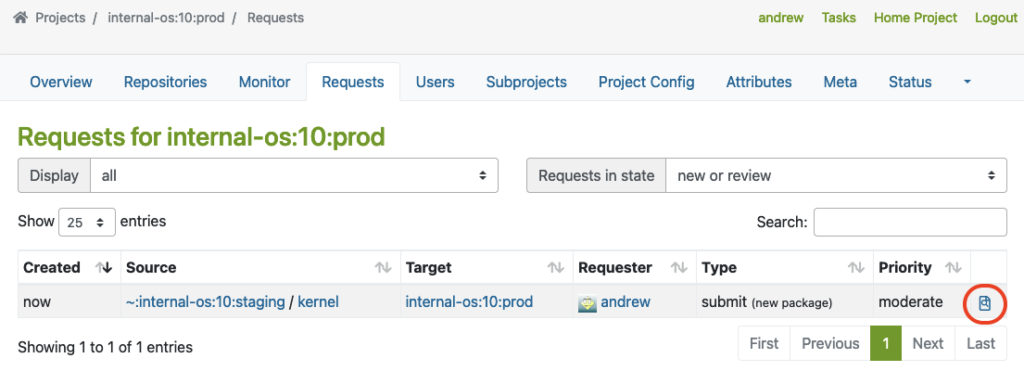
Dies öffnet die Oberfläche für die Anfragen-Überprüfung, in der der Repository-Master des Produktionsprojekts die Paketanfrage ablehnen oder annehmen kann:
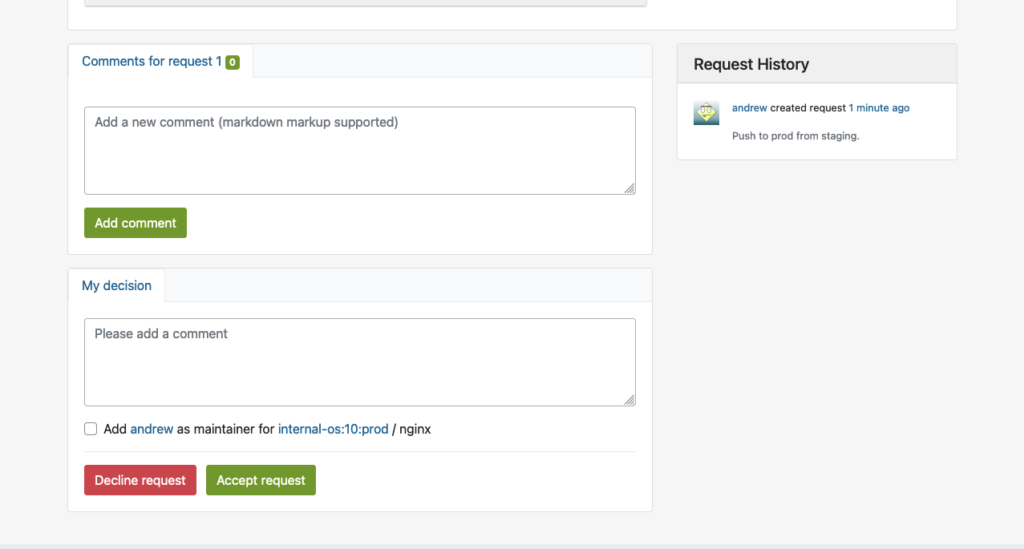
Im Produktionsprojekt reproduzieren
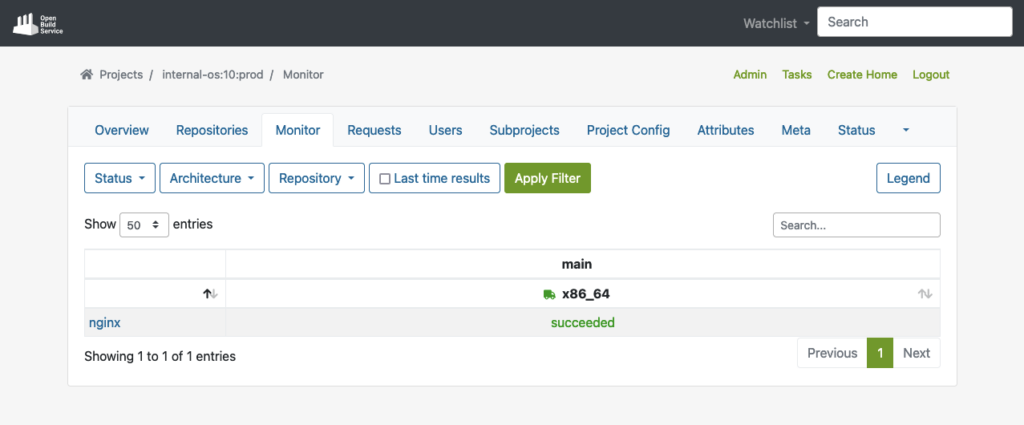
Sobald das Paket in das Produktionsprojekt aufgenommen wurde, wird es automatisch alle erforderlichen Abhängigkeiten von DoD herunterladen und den Build-Prozess reproduzieren.
Das folgende Beispiel zeigt das erfolgreich erstellte Paket im Produktions-Repository, nachdem der Build-Prozess abgeschlossen wurde:
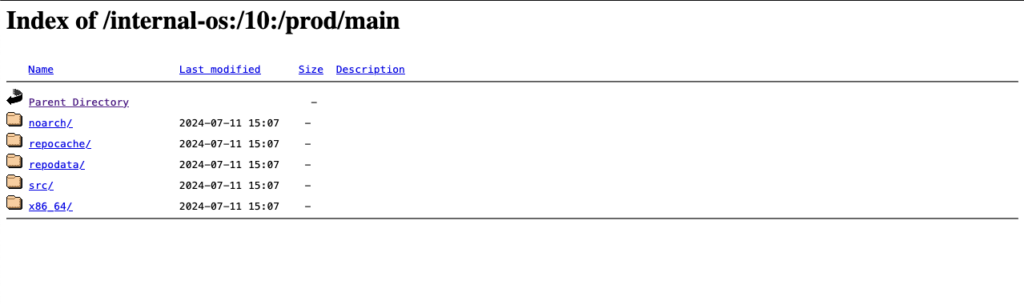
In YUM-bereitem Repository für Produktion veröffentlichen
Schließlich wird das Paket auch im YUM-fähigen Prod-Repository veröffentlicht, sobald das Paket erfolgreich erstellt wurde. Hier sehen Sie ein Beispiel für das YUM-fähige Prod-Repository, das OBS verwaltet.
(Hinweis: Sie können den Projekt- und Repository-Namen in Ihren Einstellungen festlegen):
Extras
In diesem Kapitel möchten wir uns einige mögliche zusätzliche Anpassungen für OBS in Ihren Build-Infrastrukturen ansehen.
Automatisierte Build-Pipelines
OBS unterstützt automatisierte Builds, die sich nahtlos in Delivery-Pipelines integrieren lassen. Teams können CI-Trigger einrichten, um neue Pakete in OBS zu übertragen und automatisch Builds basierend auf vordefinierten Kriterien zu initiieren. Dies reduziert den manuellen Aufwand und gewährleistet die zeitnahe Bereitstellung aktualisierter Pakete.
Pakete erhalten automatisierte Builds, wenn sie in ein OBS-Projekt übertragen werden, wodurch Administratoren automatisierte Builds einfach über Pipelines integrieren können:

OBS-Worker
Darüber hinaus ist der Open Build Service in der Lage, mehrere Worker (Builder) in verschiedenen Architekturen zu konfigurieren. Wenn Sie mit anderen Architekturen bauen möchten, installieren Sie einfach das Paket ‚obs-worker‘ auf einer anderen Hardware mit einer anderen Architektur und bearbeiten Sie dann einfach die Datei /etc/sysconfig/obs-server.
In dieser Datei müssen Sie mindestens die folgenden Parameter auf dem Worker-Knoten festlegen:
- OBS_SRC_SERVER
- OBS_REPO_SERVERS
- OBS_WORKER_INSTANCES
Diese Methode kann auch nützlich sein, wenn Sie mehr Worker in derselben Architektur in OBS verfügbar haben möchten. Die öffentliche OBS-Instanz von OpenSUSE verfügt über ein groß angelegtes Setup, das ein gutes Beispiel dafür ist.
Emulierter Build
Im Open Build Service ist es auch möglich, emulierte Builds für Cross-Architektur-Build-Funktionen über QEMU zu konfigurieren. Durch die Verwendung dieser Funktion sind fast keine Änderungen in den Paketquellen erforderlich. Entwickler können auf Zielarchitekturen bauen, ohne dass andere Hardwarearchitekturen verfügbar sein müssen. Sie können jedoch auf Probleme mit Fehlern oder fehlender Unterstützung in QEMU stoßen, und die Emulation kann den Build-Prozess erheblich verlangsamen. Sehen Sie sich beispielsweise an, wie OpenSuSE dies auf RISC-V verwaltet hat, als sie in der anfänglichen Portierungsphase nicht über die echte Hardware verfügten.
Fazit
Die Integration einer privaten OBS-Instanz als Build-Infrastruktur bietet Teams eine robuste und umfassende Lösung, um sicherheitsgepatchte Pakete für die erweiterte Unterstützung von End-of-Life (EOL) Linux-Distributionen zu erstellen. Auf diese Weise können Teams den Paket-Build-Prozess vereinheitlichen, Inkonsistenzen reduzieren und Reproduzierbarkeit erreichen. Dieser Ansatz vereinfacht den Entwicklungs- und Test-Workflow und verbessert gleichzeitig die Gesamtqualität und Zuverlässigkeit der generierten Pakete. Durch die Replikation der semi-originalen Build-Umgebung werden die resultierenden Pakete in ähnlicher Qualität und Kompatibilität wie Upstream-Builds erstellt.
Wenn Sie an der Integration einer privaten Build-Infrastruktur interessiert sind oder erweiterte Unterstützung für eine EOL-Linux-Distribution benötigen, kontaktieren Sie uns bitte. Unser Team verfügt über das Fachwissen, um Sie bei der Integration einer privaten OBS-Instanz in Ihre bestehende Infrastruktur zu unterstützen.
Dieser Artikel wurde ursprünglich von Andrew Lee verfasst.
DebConf 2024 vom 28. Juli bis 4. August 2024 https://debconf24.debconf.org/
Letzte Woche fand die jährliche Debian Community Conference DebConf in Busan, Südkorea, statt. Vier NetApp-Mitarbeiter (Michael, Andrew, Christop und Noël) nahmen die ganze Woche an der Pukyong National University teil. Das Camp findet vor der Konferenz statt, wo die Infrastruktur aufgebaut wird und die ersten Kooperationen stattfinden. Das Camp wird in einem separaten Artikel beschrieben: https://www.credativ.de/en/blog/credativ-inside/debcamp-bootstrap-for-debconf24/
Zu dieser Zeit herrschte in Korea eine Hitzewelle mit hoher Luftfeuchtigkeit, aber der Veranstaltungsort und die Unterkünfte an der Universität sind klimatisiert, so dass die Zusammenarbeit, Vorträge und BoF unter den gegebenen Umständen möglich waren.
Rund 400 Debian-Enthusiasten aus aller Welt waren vor Ort, und weitere Personen nahmen per Video-Streaming und dem Matrix-Online-Chat #debconf:matrix.debian.social aus der Ferne teil.
Das Content-Team erstellte einen Zeitplan mit verschiedenen Aspekten von Debian: technisch, sozial, politisch, ….
https://debconf24.debconf.org/schedule/
Während der DebConf24 gab es zwei größere Ankündigungen:
- die neue Distribution eLxr https://elxr.org/ basierend auf Debian, initiiert von Windriver
https://debconf24.debconf.org/talks/138-a-unified-approach-for-intelligent-deployments-at-the-edge/
Zwei wichtige Punkte, die ich aus diesem Vortrag mitgenommen habe, sind, dass Windriver CentOS austauschen möchte und eine binäre Distribution bevorzugt. - Das Debian-Paketverwaltungssystem erhält einen neuen Solver https://debconf24.debconf.org/talks/8-the-new-apt-solver/
Die Liste der interessanten Vorträge aus einer ganzen Konferenzwoche ist noch viel länger. Die meisten Vorträge und BoF wurden live gestreamt und die Aufzeichnungen sind im Videoarchiv zu finden:
https://meetings-archive.debian.net/pub/debian-meetings/2024/DebConf24/
Es ist Tradition, einen Tagesausflug zur Kontaktpflege zu machen und einen interessanteren Blick auf die Stadt und das Land zu bekommen. https://wiki.debian.org/DebConf/24/DayTrip/ (Entschuldigung, die Details der drei Tagesausflüge sind auf der Website für Teilnehmer).
Für das jährliche Gruppenfoto müssen wir ins Freie in die Hitze mit hoher Luftfeuchtigkeit gehen, aber ich hoffe, Sie werden uns nicht schwitzen sehen.
{kind=link}
Die Debian Konferenz 2025 findet im Juli in Brest, Frankreich, statt: https://wiki.debian.org/DebConf/25/ und wir werden dabei sein. 🙂 Vielleicht ist es eine Chance für Sie, sich uns anzuschließen.
Siehe auch Debian News: DebConf24 schließt in Busan und DebConf25-Termine angekündigt
Mit Version 256 hat systemd run0 eingeführt. Lennart Poettering beschreibt run0 als Alternative zu sudo und erklärt auf Mastodon zugleich, was in seinen Augen das Problem mit sudo ist.
In diesem Blogeintrag wollen wir aber nicht auf die Stärken oder Schwächen von sudo eingehen, sondern uns run0 einmal etwas genauer anschauen und es als sudo-Alternative verwenden.
Anders als sudo verwendet run0 weder die Konfigurationsdatei /etc/sudoers, noch ein SUID-Bit zur Erweiterung der User-Berechtigungen. Im Hintergrund nutzt es systemd-run zum Start neuer Prozesse, welches bereits seit einigen Jahren in systemd zu finden ist.
PolKit kommt zum Einsatz, wenn es darum geht zu prüfen, ob ein User auch entsprechende Berechtigungen besitzt, run0 zu verwenden. Hierbei können alle Regeln verwendet werden, die die Konfiguration von PolKit hergeben. In unserem Beispiel werden wir uns auf eine einfache Variante konzentrieren.
Versuchsaufbau
Für unser Beispiel verwenden wir eine t2.micro EC2-Instanz mit Debian Bookworm. Da run0 erst in systemd Version 256 Einzug gehalten hat und Debian Bookworm zum aktuellen Zeitpunkt noch mit Version 252 ausgeliefert wird, müssen wir zunächst das Debian Testing Repository hinzufügen.
❯ ssh admin@2a05:d014:ac8:7e00:c4f4:af36:3938:206e … admin@ip-172-31-15-135:~$ sudo su - root@ip-172-31-15-135:~# cat < /etc/apt/sources.list.d/testing.list > deb https://deb.debian.org/debian testing main > EOF root@ip-172-31-15-135:~# apt update Get:1 file:/etc/apt/mirrors/debian.list Mirrorlist [38 B] Get:5 file:/etc/apt/mirrors/debian-security.list Mirrorlist [47 B] Get:7 https://deb.debian.org/debian testing InRelease [169 kB] Get:2 https://cdn-aws.deb.debian.org/debian bookworm InRelease [151 kB] … Fetched 41.3 MB in 6s (6791 kB/s) Reading package lists... Done Building dependency tree... Done Reading state information... Done 299 packages can be upgraded. Run 'apt list --upgradable' to see them. root@ip-172-31-15-135:~# apt-cache policy systemd systemd: Installed: 252.17-1~deb12u1 Candidate: 256.1-2 Version table: 256.1-2 500 500 https://deb.debian.org/debian testing/main amd64 Packages 254.5-1~bpo12+3 100 100 mirror+file:/etc/apt/mirrors/debian.list bookworm-backports/main amd64 Packages 252.22-1~deb12u1 500 500 mirror+file:/etc/apt/mirrors/debian.list bookworm/main amd64 Packages *** 252.17-1~deb12u1 100 100 /var/lib/dpkg/status root@ip-172-31-15-135:~# apt-get install systemd … root@ip-172-31-15-135:~# dpkg -l | grep systemd ii libnss-resolve:amd64 256.1-2 amd64 nss module to resolve names via systemd-resolved ii libpam-systemd:amd64 256.1-2 amd64 system and service manager - PAM module ii libsystemd-shared:amd64 256.1-2 amd64 systemd shared private library ii libsystemd0:amd64 256.1-2 amd64 systemd utility library ii systemd 256.1-2 amd64 system and service manager ii systemd-cryptsetup 256.1-2 amd64 Provides cryptsetup, integritysetup and veritysetup utilities ii systemd-resolved 256.1-2 amd64 systemd DNS resolver ii systemd-sysv 256.1-2 amd64 system and service manager - SysV compatibility symlinks ii systemd-timesyncd 256.1-2 amd64 minimalistic service to synchronize local time with NTP servers root@ip-172-31-15-135:~# reboot …
Zum initialen Login wird der User admin verwendet. Dieser User wurde durch cloud-init bereits in der Datei /etc/sudoers.d/90-cloud-init-users hinterlegt und darf demnach ohne Passwortabfrage beliebige sudo-Kommandos ausführen.
sudo cat /etc/sudoers.d/90-cloud-init-users # Created by cloud-init v. 22.4.2 on Thu, 27 Jun 2024 09:22:48 +0000 # User rules for admin admin ALL=(ALL) NOPASSWD:ALL
Analog zu sudo wollen wir nun run0 für den User admin freischalten.
Ohne weitere Konfiguration erhält der User admin einen Login-Prompt, bei dem er nach dem root-Passwort gefragt wird. Dabei handelt es sich um das Standardverhalten von PolKit.
admin@ip-172-31-15-135:~$ run0 ==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ==== Authentication is required to manage system services or other units. Authenticating as: Debian (admin) Password:Da dies nicht dem von uns gewünschten Verhalten entspricht, müssen wir in Form einer PolKit-Regel ein wenig nachhelfen. Zusätzliche PolKit Regeln werden unter /etc/polkit-1/rules.d/ abgelegt.
root@ip-172-31-15-135:~# cat < /etc/polkit-1/rules.d/99-run0.rules
polkit.addRule(function(action, subject) {
if (action.id = "org.freedesktop.systemd1.manage-units") {
if (subject.user === "admin") {
return polkit.Result.YES;
}
}
});
> EOF
Die verwendete Regel ist dabei wie folgt aufgebaut: Zunächst wird überprüft, ob es sich bei der aufgeführten action um org.freedesktop.systemd1.manage-units handelt. Ist das der Fall, wird geprüft, ob es sich bei dem ausführenden User um den User admin handelt. Sind beide Voraussetzungen erfüllt, gibt unsere Regel „YES“ zurück, was bedeutet, dass keine weitere Prüfung (z.B. Passwortabfrage) nötig ist.
Alternativ hierzu könnte auch geprüft werden, ob der ausführende User einer bestimmten Gruppe angehört, wie z.B. admin oder sudo (if (subject.isInGroup("admin")). Auch wäre es denkbar, den Benutzer nach seinem eigenen Passwort zu fragen anstelle des root-Passworts.
Die neue Regel wird von PolKit automatisch eingelesen und kann sofort verwendet werden. Via journalctl -u polkit kann geprüft werden, ob es etwaige Fehler beim Einlesen der neuen Regeln gab. Nach der Konfiguration von PolKit darf der User admin nun analog zu unserer initialen sudo-Konfiguration run0 ausführen.
Prozessaufbau
Im nachfolgenden Listing wird ersichtlich, worin der Unterschied des Call-Stacks zwischen sudo und run0 liegt. Während im Falle von sudo jeweils eigene Child-Prozesse gestartet werden, startet run0 einen neuen Prozess via systemd-run.
root@ip-172-31-15-135:~# sudo su - root@ip-172-31-15-135:~# ps fo tty,ruser,ppid,pid,sess,cmd TT RUSER PPID PID SESS CMD pts/2 admin 1484 1514 1484 sudo su - pts/0 admin 1514 1515 1515 \_ sudo su - pts/0 root 1515 1516 1515 \_ su - pts/0 root 1516 1517 1515 \_ -bash pts/0 root 1517 1522 1515 \_ ps fo tty,ruser,ppid,pid,sess,cmd
admin@ip-172-31-15-135:~$ run0 root@ip-172-31-15-135:/home/admin# ps fo tty,ruser,ppid,pid,sess,cmd TT RUSER PPID PID SESS CMD pts/0 root 1 1562 1562 -/bin/bash pts/0 root 1562 1567 1562 \_ ps fo tty,ruser,ppid,pid,sess,cmd
Fazit und Anmerkung
Wie das oben stehende Beispiel gezeigt hat, kann run0 generell als einfache sudo-Alternative verwendet werden und bietet dabei einige sicherheitsrelevante Vorteile. Falls run0 sich gegenüber sudo durchsetzt, wird dies allerdings nicht innerhalb des nächsten Jahres geschehen. Einigen Distributionen fehlt stand jetzt schlicht eine ausreichend aktuelle systemd-Version. Hinzukommt, dass die Konfiguration von PolKit für einige Admins nicht zu den täglichen Aufgaben gehört und hier erst Know-How aufgebaut werden muss, um etwaige vorhandene sudo-„Konstrukte“ zu überführen.
Zudem sollte ein entscheidender Vorteil von run0 nicht außen vor bleiben: Standardmäßig färbt es den Hintergrund rot! 😉

Wenn Sie die Wahl hätten, würden Sie eher Salsa oder Guacamole nehmen? Lassen Sie mich erklären, warum Sie Guacamole Salsa vorziehen sollten.
In diesem Blog-Artikel möchten wir uns eines der kleineren Apache-Projekte namens Apache Guacamole. Apache Guacamole ermöglicht Administratoren die Ausführung eines webbasierten Client-Tools für den Zugriff auf Remote-Anwendungen und -Server. Dies kann Remote-Desktop-Systeme, Anwendungen oder Terminalsitzungen umfassen. Benutzer können einfach über ihren Webbrowser darauf zugreifen. Es werden kein spezieller Client oder andere Tools benötigt. Von dort aus können sie sich anmelden und auf alle vorkonfigurierten Remote-Verbindungen zugreifen, die von einem Administrator festgelegt wurden.
Dabei unterstützt Guacamole eine Vielzahl von Protokollen wie VNC, RDP und SSH. Auf diese Weise können Benutzer im Grunde auf alles zugreifen, von Remote-Terminal-Sitzungen bis hin zu vollwertigen grafischen Benutzeroberflächen, die von Betriebssystemen wie Debian, Ubuntu, Windows und vielen mehr bereitgestellt werden.
Konvertieren Sie jede Windows-Anwendung in eine Webanwendung
Wenn wir diese Idee weiter spinnen, kann technisch gesehen jede Windows-Anwendung, die nicht für die Ausführung als Webanwendung konzipiert ist, mithilfe von Apache Guacamole in eine Webanwendung umgewandelt werden. Wir haben einem Kunden geholfen, seine Legacy-Anwendung zu Kubernetes zu bringen, sodass andere Benutzer ihre Webbrowser verwenden konnten, um sie auszuführen. Sicher, die Implementierung der Anwendung von Grund auf, sodass sie den Cloud-Native-Prinzipien folgt, ist die bevorzugte Lösung. Wie immer können jedoch Aufwand, Erfahrung und Kosten die verfügbare Zeit und das Budget übersteigen, und in diesen Fällen kann Apache Guacamole eine relativ einfache Möglichkeit zur Realisierung solcher Projekte bieten.
In diesem Blog-Artikel möchte ich Ihnen zeigen, wie einfach es ist, eine Legacy-Windows-Anwendung als Web-App auf Kubernetes auszuführen. Dazu verwenden wir einen Kubernetes-Cluster, der von kind erstellt wurde, und erstellen ein Kubernetes-Deployment, um kate – einen KDE-basierten Texteditor – zu unserer eigenen Webanwendung zu machen. Es ist nur ein Beispiel, daher gibt es möglicherweise bessere Anwendungen zum Transformieren, aber diese sollte ausreichen, um Ihnen die Konzepte hinter Apache Guacamole zu zeigen.
Also, ohne weiteres, erstellen wir unsere kate Webanwendung.
Vorbereitung von Kubernetes
Bevor wir beginnen können, müssen wir sicherstellen, dass wir einen Kubernetes-Cluster haben, auf dem wir testen können. Wenn Sie bereits einen Cluster haben, überspringen Sie diesen Abschnitt einfach. Wenn nicht, starten wir einen mit kind.
kind ist eine schlanke Implementierung von Kubernetes, die auf jeder Maschine ausgeführt werden kann. Es ist in Go geschrieben und kann wie folgt installiert werden:
# For AMD64 / x86_64
[ $(uname -m) = x86_64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.22.0/kind-linux-amd64
# For ARM64
[ $(uname -m) = aarch64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.22.0/kind-linux-arm64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind
Als Nächstes müssen wir einige Abhängigkeiten für unseren Cluster installieren. Dazu gehören beispielsweise docker und kubectl.
$ sudo apt install docker.io kubernetes-client
Durch die Erstellung unseres Kubernetes-Clusters mit kind benötigen wir docker, da der Kubernetes-Cluster innerhalb von Docker-Containern auf Ihrem Host-Rechner läuft. Die Installation von kubectl ermöglicht uns den Zugriff auf Kubernetes nach der Erstellung.
Sobald wir diese Pakete installiert haben, können wir mit der Erstellung unseres Clusters beginnen. Zuerst müssen wir eine Clusterkonfiguration definieren. Sie definiert, welche Ports von unserem Host-Rechner aus zugänglich sind, sodass wir auf unsere Guacamole-Anwendung zugreifen können. Denken Sie daran, dass der Cluster selbst innerhalb von Docker-Containern betrieben wird, daher müssen wir sicherstellen, dass wir von unserem Rechner aus darauf zugreifen können. Dazu definieren wir die folgende Konfiguration, die wir in einer Datei namens cluster.yaml speichern:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
listenAddress: "127.0.0.1"
protocol: TCP
Hierbei ordnen wir im Grunde den Port 30000 des Containers dem Port 30000 unseres lokalen Rechners zu, sodass wir später problemlos darauf zugreifen können. Behalten Sie dies im Hinterkopf, da dies der Port sein wird, den wir mit unserem Webbrowser verwenden werden, um auf unsere kate Instanz zuzugreifen.
Letztendlich wird diese Konfiguration von kind verwendet. Damit können Sie auch mehrere andere Parameter Ihres Clusters anpassen, abgesehen von der reinen Änderung der Portkonfiguration, die hier nicht erwähnt werden. Es lohnt sich, einen Blick in die Dokumentation von Kate zu werfen.
Sobald Sie die Konfiguration in cluster.yaml gespeichert haben, können wir nun mit der Erstellung unseres Clusters beginnen:
$ sudo kind create cluster --name guacamole --config cluster.yaml
Creating cluster "guacamole" ...
✓ Ensuring node image (kindest/node:v1.29.2) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-guacamole"
You can now use your cluster with:
kubectl cluster-info --context kind-guacamole
Have a question, bug, or feature request? Let us know! https://kind.sigs.k8s.io/#community 🙂
Da wir nicht alles im Root-Kontext ausführen möchten, exportieren wir die kubeconfig, sodass wir sie mit kubectl mit unserem nicht privilegierten Benutzer verwenden können:
$ sudo kind export kubeconfig \
--name guacamole \
--kubeconfig $PWD/config
$ export KUBECONFIG=$PWD/config
$ sudo chown $(logname): $KUBECONFIG
Dadurch sind wir bereit und können jetzt mit kubectl auf unseren Kubernetes-Cluster zugreifen. Dies ist unsere Grundlage, um mit der Migration unserer Anwendung zu beginnen.
Erstellung des Guacamole-Deployments
Um unsere Anwendung auf Kubernetes auszuführen, benötigen wir eine Art Workload-Ressource. Typischerweise könnten Sie einen Pod, ein Deployment, ein Statefulset oder ein Daemonset erstellen, um Workloads auf einem Cluster auszuführen.
Erstellen wir das Kubernetes-Deployment für unsere eigene Anwendung. Das unten gezeigte Beispiel zeigt die allgemeine Struktur des Deployments. Jede Containerdefinition wird anschließend ihre eigenen Beispiele haben, um sie detaillierter zu erklären.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web-based-kate
name: web-based-kate
spec:
replicas: 1
selector:
matchLabels:
app: web-based-kate
template:
metadata:
labels:
app: web-based-kate
spec:
containers:
# The guacamole server component that each
# user will connect to via their browser
- name: guacamole-server
image: docker.io/guacamole/guacamole:1.5.4
...
# The daemon that opens the connection to the
# remote entity
- name: guacamole-guacd
image: docker.io/guacamole/guacd:1.5.4
...
# Our own self written application that we
# want to make accessible via the web.
- name: web-based-kate
image: registry.example.com/own-app/web-based-kate:0.0.1
...
volumes:
- name: guacamole-config
secret:
secretName: guacamole-config
- name: guacamole-server
emptyDir: {}
- name: web-based-kate-home
emptyDir: {}
- name: web-based-kate-tmp
emptyDir: {}
Wie Sie sehen können, benötigen wir drei Container und einige Volumes für unsere Anwendung. Die ersten beiden Container sind Apache Guacamole selbst gewidmet. Erstens ist es die Serverkomponente, die der externe Endpunkt für Clients ist, um auf unsere Webanwendung zuzugreifen. Sie dient dem Webserver sowie der Benutzerverwaltung und -konfiguration, um Apache Guacamole auszuführen.
Daneben gibt es den guacd Daemon. Dies ist die Kernkomponente von Guacamole, die die Remote-Verbindungen zur Anwendung basierend auf der Konfiguration des Servers erstellt. Dieser Daemon leitet die Remote-Verbindung an die Clients weiter, indem er sie für den Guacamole-Server zugänglich macht, der die Verbindung dann an den Endbenutzer weiterleitet.
Schließlich haben wir unsere eigene Anwendung. Sie bietet einen Verbindungsendpunkt zum guacd Daemon unter Verwendung eines der von Guacamole unterstützten Protokolle und stellt die grafische Benutzeroberfläche (GUI) bereit.
Guacamole-Server
Lassen Sie uns nun tief in jede Containerspezifikation eintauchen. Wir beginnen mit der Guacamole-Serverinstanz. Diese verwaltet die Sitzungs- und Benutzerverwaltung und enthält die Konfiguration, die definiert, welche Remote-Verbindungen verfügbar sind und welche nicht.
- name: guacamole-server
image: docker.io/guacamole/guacamole:1.5.4
env:
- name: GUACD_HOSTNAME
value: "localhost"
- name: GUACD_PORT
value: "4822"
- name: GUACAMOLE_HOME
value: "/data/guacamole/settings"
- name: HOME
value: "/data/guacamole"
- name: WEBAPP_CONTEXT
value: ROOT
volumeMounts:
- name: guacamole-config
mountPath: /data/guacamole/settings
- name: guacamole-server
mountPath: /data/guacamole
ports:
- name: http
containerPort: 8080
securityContext:
allowPrivilegeEscalation: false
privileged: false
readOnlyRootFilesystem: true
capabilities:
drop: ["all"]
resources:
limits:
cpu: "250m"
memory: "256Mi"
requests:
cpu: "250m"
memory: "256Mi"
Da sie sich mit dem guacd Daemon verbinden muss, müssen wir die Verbindungsinformationen für guacd bereitstellen, indem wir sie über Umgebungsvariablen wie GUACD_HOSTNAME oder GUACD_PORT an den Container übergeben. Darüber hinaus wäre Guacamole normalerweise über http://<your domain>/guacamole zugänglich.
Dieses Verhalten kann jedoch durch Ändern der Umgebungsvariable WEBAPP_CONTEXT angepasst werden. In unserem Fall möchten wir beispielsweise nicht, dass ein Benutzer /guacamole eingibt, um darauf zuzugreifen, sondern es einfach so verwendet: http://<your domain>/
Guacamole guacd
Dann gibt es den guacd Daemon.
- name: guacamole-guacd
image: docker.io/guacamole/guacd:1.5.4
args:
- /bin/sh
- -c
- /opt/guacamole/sbin/guacd -b 127.0.0.1 -L $GUACD_LOG_LEVEL -f
securityContext:
allowPrivilegeEscalation: true
privileged: false
readOnlyRootFileSystem: true
capabilities:
drop: ["all"]
resources:
limits:
cpu: "250m"
memory: "512Mi"
requests:
cpu: "250m"
memory: "512Mi"
Es ist erwähnenswert, dass Sie die Argumente ändern sollten, die zum Starten des guacd Containers verwendet werden. In dem obigen Beispiel möchten wir, dass guacd aus Sicherheitsgründen nur auf localhost hört. Alle Container innerhalb desselben Pods teilen sich denselben Netzwerk-Namespace. Infolgedessen können sie über localhost aufeinander zugreifen. Dies gesagt, es besteht keine Notwendigkeit, diesen Dienst für andere Dienste zugänglich zu machen, die außerhalb dieses Pods laufen, sodass wir ihn auf localhost beschränken können. Um dies zu erreichen, müssen Sie den Parameter -b 127.0.0.1 setzen, der die entsprechende Listener-Adresse festlegt. Da Sie den gesamten Befehl überschreiben müssen, vergessen Sie nicht, auch die Parameter
Webbasiertes Kate
Um alles abzuschließen, haben wir die kate Anwendung, die wir in eine Webanwendung umwandeln möchten.
- name: web-based-kate
image: registry.example.com/own-app/web-based-kate:0.0.1
env:
- name: VNC_SERVER_PORT
value: "5900"
- name: VNC_RESOLUTION_WIDTH
value: "1280"
- name: VNC_RESOLUTION_HEIGHT
value: "720"
securityContext:
allowPrivilegeEscalation: true
privileged: false
readOnlyRootFileSystem: true
capabilities:
drop: ["all"]
volumeMounts:
- name: web-based-kate-home
mountPath: /home/kate
- name: web-based-kate-tmp
mountPath: /tmp
Konfiguration unseres Guacamole-Setups
Nachdem das Deployment eingerichtet ist, müssen wir die Konfiguration für unser Guacamole-Setup vorbereiten. Um zu wissen, welche Benutzer existieren und welche Verbindungen angeboten werden sollen, müssen wir Guacamole eine Mapping-Konfiguration bereitstellen.
In diesem Beispiel wird eine einfache Benutzerzuordnung zu Demonstrationszwecken gezeigt. Es verwendet eine statische Zuordnung, die in einer XML-Datei definiert ist, die an den Guacamole-Server übergeben wird. Typischerweise würden Sie stattdessen andere Authentifizierungsmethoden wie eine Datenbank oder LDAP verwenden.
Dies gesagt, fahren wir jedoch mit unserer statischen fort. Dazu definieren wir einfach ein Kubernetes Secret, das in den Guacamole-Server gemountet wird. Hierbei werden zwei Konfigurationsdateien definiert. Eine ist die sogenannte guacamole.properties. Dies ist die Hauptkonfigurationsdatei von Guacamole. Daneben definieren wir auch die user-mapping.xml, die alle verfügbaren Benutzer und ihre Verbindungen enthält.
apiVersion: v1
kind: Secret
metadata:
name: guacamole-config
stringData:
guacamole.properties: |
enable-environment-properties: true
user-mapping.xml: |
<user-mapping>
<authorize username="admin" password="PASSWORD" encoding="sha256">
<connection name="web-based-kate">
<protocol>vnc</protocol>
<param name="hostname">localhost</param>
<param name="port">5900</param>
</connection>
</authorize>
</user-mapping>
Wie Sie sehen können, haben wir nur einen bestimmten Benutzer namens admin definiert, der eine Verbindung namens web-based-kate verwenden kann. Um auf die kate Instanz zuzugreifen, würde Guacamole VNC als konfiguriertes Protokoll verwenden. Damit dies geschieht, muss unsere Webanwendung auf der anderen Seite einen VNC-Server-Port anbieten, sodass der
$ echo -n "test" | sha256sum
9f86d081884c7d659a2feaa0c55ad015a3bf4f1b2b0b822cd15d6c15b0f00a08 -
Als Nächstes referenziert der Hostname-Parameter den entsprechenden VNC-Server unseres kate Containers. Da wir unseren Container zusammen mit unseren Guacamole-Containern innerhalb desselben Pods starten, können der Guacamole-Server sowie der guacd auf den VNC-Server zugreift und die Remote-Sitzung über HTTP an Clients weiterleitet, die über ihre Webbrowser auf Guacamole zugreifen. Schließlich müssen wir auch den VNC-Server-Port angeben, der typischerweise 5900 ist, aber dies könnte bei Bedarf angepasst werden.
Die entsprechende guacamole.properties ist recht kurz. Durch Aktivieren des Konfigurationsparameters enabling-environment-properties stellen wir sicher, dass jeder Guacamole-Konfigurationsparameter auch über Umgebungsvariablen festgelegt werden kann. Auf diese Weise müssen wir diese Konfigurationsdatei nicht jedes Mal ändern, wenn wir die Konfiguration anpassen möchten, sondern wir müssen dem Guacamole-Server-Container nur aktualisierte Umgebungsvariablen bereitstellen.
Guacamole zugänglich machen
Zu guter Letzt müssen wir den Guacamole-Server für Clients zugänglich machen. Obwohl jeder bereitgestellte Dienst über localhost aufeinander zugreifen kann, gilt dies nicht für Clients, die versuchen, auf Guacamole zuzugreifen. Daher müssen wir den Server-Port 8080 von Guacamole für die Außenwelt verfügbar machen. Dies kann durch Erstellen eines Kubernetes-Dienstes vom Typ NodePort erreicht werden. Dieser Dienst leitet jede Anfrage von einem lokalen Node-Port an den entsprechenden Container weiter, der den konfigurierten Zielport anbietet. In unserem Fall wäre dies der Guacamole-Server-Container, der Port 8080 anbietet.
apiVersion: v1
kind: Service
metadata:
name: web-based-kate
spec:
type: NodePort
selector:
app: web-based-kate
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
nodePort: 30000
Dieser spezifische Port wird dann dem Port 30000 des Knotens zugeordnet, für den wir auch den kind Cluster so konfiguriert haben, dass er seinen Node-Port 30000 an den Port 30000 des Host-Systems weiterleitet. Dieser Port ist derjenige, den wir verwenden müssten, um mit unseren Webbrowsern auf Guacamole zuzugreifen.
Vorbereitung des Anwendungscontainers
Bevor wir mit der Bereitstellung unserer Anwendung beginnen können, müssen wir unseren kate Container vorbereiten. Dazu erstellen wir einfach einen Debian-Container, der kate ausführt. Beachten Sie, dass Sie typischerweise schlanke Basis-Images wie alpine verwenden würden, um solche Anwendungen auszuführen. Für diese Demonstration verwenden wir jedoch die Debian-Images, da es einfacher ist, sie zu starten, aber im Allgemeinen benötigen Sie nur einen kleinen Bruchteil der Funktionalität, die von diesem Basis-Image bereitgestellt wird. Darüber hinaus möchten Sie – aus Sicherheitsgründen – Ihre Images klein halten, um die Angriffsfläche zu minimieren und sicherzustellen, dass sie einfacher zu warten sind. Für den Moment werden wir jedoch mit dem Debian-Image fortfahren.
In dem Beispiel unten sehen Sie eine Dockerfile für den kate Container.
FROM debian:12
# Install all required packages
RUN apt update && \
apt install -y x11vnc xvfb kate
# Add user for kate
RUN adduser kate --system --home /home/kate -uid 999
# Copy our entrypoint in the container
COPY entrypoint.sh /opt
USER 999
ENTRYPOINT [ "/opt/entrypoint.sh" ]
Hier sehen Sie, dass wir einen dedizierten Benutzer namens kate (Benutzer-ID 999) erstellen, für den wir auch ein Home-Verzeichnis erstellen. Dieses Home-Verzeichnis wird für alle Dateien verwendet, die kate während der Laufzeit erstellt. Da wir readOnlyRootFilesystem auf true gesetzt haben, müssen wir sicherstellen, dass wir eine Art beschreibbares Volume (z. B. EmptyDir) in das Home-Verzeichnis von Kate mounten. Andernfalls könnte Kate dann keine Laufzeitdaten schreiben.
Darüber hinaus müssen wir die folgenden drei Pakete installieren:
- x11vnc
- xvfb
- kate
Dies sind die einzigen Pakete, die wir für unseren Container benötigen. Darüber hinaus müssen wir auch ein Entrypoint-Skript erstellen, um die Anwendung zu starten und den Container entsprechend vorzubereiten. Dieses Entrypoint-Skript erstellt die Konfiguration für kate, startet es in einer virtuellen Anzeige mit xvfb-run und stellt diese virtuelle Anzeige Endbenutzern mit dem VNC-Server über x11vnc bereit. In der Zwischenzeit wird xdrrinfo verwendet, um zu überprüfen, ob die virtuelle Anzeige nach dem Start von kate erfolgreich hochgefahren wurde. Wenn es zu lange dauert, schlägt das Entrypoint-Skript fehl, indem es den Exit-Code 1 zurückgibt.
Dadurch stellen wir sicher, dass der Container bei einem Fehler nicht in einer Endlosschleife hängen bleibt und Kubernetes den Container neu startet, wenn er die Anwendung nicht erfolgreich starten konnte. Darüber hinaus ist es wichtig zu überprüfen, ob die virtuelle Anzeige vor der Übergabe an den VNC-Server hochgefahren wurde, da der VNC-Server abstürzen würde, wenn die virtuelle Anzeige nicht betriebsbereit ist, da er etwas zum Teilen benötigt. Andererseits wird unser Container beendet, wenn
#!/bin/bash
set -e
# If no resolution is provided
if [ -z $VNC_RESOLUTION_WIDTH ]; then
VNC_RESOLUTION_WIDTH=1920
fi
if [ -z $VNC_RESOLUTION_HEIGHT ]; then
VNC_RESOLUTION_HEIGHT=1080
fi
# If no server port is provided
if [ -z $VNC_SERVER_PORT ]; then
VNC_SERVER_PORT=5900
fi
# Prepare configuration for kate
mkdir -p $HOME/.local/share/kate
echo "[MainWindow0]
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: Height=$VNC_RESOLUTION_HEIGHT
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: Width=$VNC_RESOLUTION_WIDTH
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: XPosition=0
"$VNC_RESOLUTION_WIDTH"x"$VNC_RESOLUTION_HEIGHT" screen: YPosition=0
Active ViewSpace=0
Kate-MDI-Sidebar-Visible=false" > $HOME/.local/share/kate/anonymous.katesession
# We need to define an XAuthority file
export XAUTHORITY=$HOME/.Xauthority
# Define execution command
APPLICATION_CMD="kate"
# Let's start our application in a virtual display
xvfb-run \
-n 99 \
-s ':99 -screen 0 '$VNC_RESOLUTION_WIDTH'x'$VNC_RESOLUTION_HEIGHT'x16' \
-f $XAUTHORITY \
$APPLICATION_CMD &
# Let's wait until the virtual display is initalize before
# we proceed. But don't wait infinitely.
TIMEOUT=10
while ! (xdriinfo -display :99 nscreens); do
sleep 1
let TIMEOUT-=1
done
# Now, let's make the virtual display accessible by
# exposing it via the VNC Server that is listening on
# localhost and the specified port (e.g. 5900)
x11vnc \
-display :99 \
-nopw \
-localhost \
-rfbport $VNC_SERVER_PORT \
-forever
Nachdem wir diese Dateien vorbereitet haben, können wir nun unser Image erstellen und es mit den folgenden Befehlen in unseren Kubernetes-Cluster importieren:
# Do not forget to give your entrypoint script
# the proper permissions do be executed
$ chmod +x entrypoint.sh
# Next, build the image and import it into kind,
# so that it can be used from within the clusters.
$ sudo docker build -t registry.example.com/own-app/web-based-kate:0.0.1 .
$ sudo kind load -n guacamole docker-image registry.example.com/own-app/web-based-kate:0.0.1
Das Image wird in kind importiert, sodass jede Workload-Ressource, die in unserem kind Cluster betrieben wird, darauf zugreifen kann. Wenn Sie einen anderen Kubernetes-Cluster verwenden, müssen Sie diesen in eine Registry hochladen, von der Ihr Cluster Images abrufen kann.
Schließlich können wir auch unsere zuvor erstellten Kubernetes-Manifeste auf den Cluster anwenden. Nehmen wir an, wir haben alles in einer Datei namens
$ kubectl apply -f kubernetes.yaml
deployment.apps/web-based-kate configured
secret/guacamole-config configured
service/web-based-kate unchanged
Auf diese Weise werden ein Kubernetes-Deployment, ein Secret und ein Service erstellt, die letztendlich einen Kubernetes-Pod erstellen, auf den wir anschließend zugreifen können.
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
web-based-kate-7894778fb6-qwp4z 3/3 Running 0 10m
Überprüfung unseres Deployments
Jetzt ist es Showtime! Nach der Vorbereitung von allem sollten wir in der Lage sein, mit unserem Webbrowser auf unsere webbasierte kate Anwendung zuzugreifen. Wie bereits erwähnt, haben wir NodePort aufgenommen wird. Dieser leitet dann alle Anfragen an unseren dafür vorgesehenen Guacamole-Server-Container weiter, der den Webserver für den Zugriff auf Remote-Anwendungen über Guacamole anbietet.
Wenn alles klappt, sollten Sie den folgenden Anmeldebildschirm sehen:
Nach erfolgreicher Anmeldung wird die Remote-Verbindung hergestellt und Sie sollten den Willkommensbildschirm von kate sehen:
Wenn Sie auf New klicken, können Sie eine neue Textdatei erstellen:
Diese Textdateien können sogar gespeichert werden, aber denken Sie daran, dass sie nur so lange existieren, wie unser Kubernetes-Pod existiert. Sobald er gelöscht wird, wird auch das entsprechende EmptyDir, das wir in unseren kate Container gemountet haben, gelöscht und alle Dateien darin gehen verloren. Darüber hinaus ist der Container auf schreibgeschützt gesetzt, was bedeutet, dass ein Benutzer nur Dateien in die Volumes (z. B. EmptyDir) schreiben kann, die wir in unseren Container gemountet haben.
Fazit
Nachdem wir gesehen haben, dass es relativ einfach ist, jede Anwendung mithilfe von Apache Guacamole in eine webbasierte Anwendung umzuwandeln, bleibt nur noch eine wichtige Frage offen…
Was bevorzugen Sie am meisten? Salsa oder Guacamole?
Nachdem die vorausgegangenen Artikel eine Einführung in AppArmor gegeben sowie das Vorgehen zum Erstellen eines AppArmor-Profils für nginx beschrieben haben, geht dieser Artikel noch einen Schritt weiter: neben statischen Inhalten soll der nginx-Webserver auch klassische CGI-Scripte ausführen und deren Ausgabe zurückliefern können.
Obwohl das Common Gateway Interface, kurz CGI, seine Hochzeit in den 1990er Jahren erlebte und vielerorts durch modernere Alternativen verdrängt wurde, finden sich auch heute noch Systeme und Prozesse bei denen jahrzehntelang gepflegte CGI-Scripte zum Einsatz kommen.
Unabhängig davon eignet sich die Thematik für diesen Artikel deshalb besonders, weil der Aufbau und die Einrichtung eines Szenarios einfach genug zu beschreiben ist, sodass das eigentliche Thema für diesen Artikel, nämlich AppArmor-Kindprofile, problemlos auf andere Konstrukte übertragen werden kann.
nginx und fcgiwrap
Eine weit verbreitete Methode, um den nginx-Webserver um die Fähigkeit CGI-Scripte ausführen zu können zu erweitern, ist die Verwendung von fcgiwrap.
Die Projektbeschreibung nennt fcgiwrap einen “einfachen FastCGI-Wrapper für CGI-Scripte”, also ein Programm, das herkömmliche CGI-Scripte ausführt und für diese die FastCGI-Kommunikation mit dem Webserver übernimmt, ohne dass die eigentlichen Scripte angepasst werden müssen.
Um den Rahmen dieses Artikels nicht zu sprengen sei auf die Anleitung aus dem nginx-Wiki zur Installation und Konfiguration von fcgiwrap verwiesen.
Beispielkonfiguration
Das folgende Listing zeigt die für unser Szenario verwendete Konfigurationsdatei /etc/nginx/conf.d/cgi-bin.conf, welche auf der von fcgiwrap mitgelieferten Beispielkonfiguration, zu finden unter /usr/share/doc/fcgiwrap/examples/nginx.conf, basiert.
location /cgi-bin/ {
gzip off;
root /var/www;
fastcgi_pass unix:/var/run/fcgiwrap.socket;
include /etc/nginx/fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
}Aus dem Listing ist leicht zu entnehmen, dass sich im Ordner /cgi-bin/ unterhalb des root-Verzeichnisses /var/www Scripte befinden, die ausgeführt werden sollen – in diesem Szenario handelt es sich dabei um einfache Python-Scripte.
Das Programm fcgiwrap läuft als eigenständiger Prozess auf dem System und öffnet ein Unix-Socket, über das der nginx-Webserver gemäß dem FastCGI-Protokoll mit fcgiwrap kommunizieren kann, um die Ausführung der Scripte zu veranlassen und die dabei erzeugte Ausgabe zurück zu erhalten.
Für die Überwachung und Absicherung des nginx-Webservers mittels AppArmor wird das im vorherigen Artikel erstellte Profil benutzt. Obwohl bislang ungenutzte Funktionen des nginx zum Einsatz kommen muss dieses nicht angepasst werden: auf den Ordner cgi-bin/ greift der Webserver selbst überhaupt nicht zu; stattdessen veranlasst er fcgiwrap über das Socket das angeforderte Script auszuführen.
Auch der Zugriff auf das Socket /var/run/fcgiwrap.socket muss nicht explizit erlaubt werden: hierfür existieren bereits Regeln in abstractions/base.
Kindprozesse
Spätestens hier wird klar: wenn nicht nginx, sondern fcgiwrap die Scripte ausführt, greift das verwendete AppArmor-Profil nicht, da dieses nur die nginx-Prozesse überwacht. Es muss also ein weiteres Profil angelegt werden!
Mit einem einzigen Profil für fcgiwrap ist es dabei jedoch nicht getan, denn ein Script, das von fcgiwrap ausgeführt wird, läuft als eigenständiger Kindprozess: für ein Python-Script startet fcgiwrap also beispielsweise den Python-Interpreter – und der sollte dann auch von AppArmor überwacht werden!
Anders gesagt: da ein Profil für fcgiwrap wiederum nur Prozesse der Programmdatei /usr/sbin/fcgiwrap berücksichtigt, liefe der Python-Interpreter ohne AppArmor-Kontrolle. Durch spezielle Execute-Permissions und Kindprofile lässt sich jedoch genau bestimmen ob und in welchem Rahmen Kindprozesse eines von AppArmor überwachten Prozesses ausgeführt werden dürfen.
Kindprofile
Das folgende Listing zeigt den Inhalt des AppArmor-Profils /etc/apparmor.d/usr.sbin.fcgiwrap. Anhand dieses Listings soll die Definition von Kindprofilen erläutert werden:
include <tunables/global>
@{CGIBIN}=/var/www/cgi-bin
profile fcgiwrap /usr/sbin/fcgiwrap {
include <abstractions/base>
/usr/sbin/fcgiwrap mr,
@{CGIBIN}/* rcix,
profile @{CGIBIN}/* {
include <abstractions/base>
include <abstractions/nameservice>
include <abstractions/python>
/usr/bin/python3.9 mr,
@{CGIBIN}/* r,
}
}Auf den ersten Blick gleicht das gezeigte Profil den Profilen aus den vergangenen Artikeln. Es fällt jedoch auf, dass innerhalb des Profilteils ein weiteres, namenloses Profil definiert wird, dessen Pfadangabe auf alle Dateien in /var/www/cgi-bin/ passt.
Dieses sogenannte Kindprofil wird durch die Regel @{CGIBIN}/* rcix im äußeren Profil auf alle durch fcgiwrap ausgeführten Scripte im Ordner CGIBIN angewendet. Die Permission r steht dabei wie gehabt für Lesezugriff; interessanter ist die Permission cix: x erlaubt wie gehabt die Ausführung der Datei (execute), c gibt jedoch an, dass dabei ein entsprechendes Kindprofil angewendet werden soll. Wird das Kindprofil nicht gefunden sorgt i dafür, dass das aktuelle Profil vererbt (inherited) wird.
Würde die Permission c als Großbuchstabe, also C, angegeben, würden vor der Ausführung die Umgebungsvariablen gelöscht. Da CGI zur einwandfreien Funktion jedoch auf deren Erhalt angewiesen ist, kam diese Option hier nicht in Frage. Als Alternative zu i gibt es die Permission u, die dafür sorgt, dass der Kindprozess unconfined, also uneingeschränkt, läuft, falls das Kindprofil nicht gefunden wird. Auch dies wäre in diesem Falle nicht wünschenswert.
Im Quick guide to AppArmor profile Language findet sich im Abschnitt File permissions eine Übersicht an Möglichkeiten die Execute-Permission genauer zu spezifizieren. In der AppArmor Core Policy Reference werden sie im Abschnitt Execute rules noch einmal genauer gruppiert erläutert.
Da es sich bei Python um eine interpretierte Sprache handelt, werden die Scripte, wie oben erwähnt, nicht selbst ausgeführt, sondern (vereinfacht gesagt) von einem Interpreter geladen und von diesem ausgeführt. Der Aufbau des eigentlichen Kindprofils sollte daher leicht verständlich sein: der Python-Interpreter /usr/bin/python3.9 darf in den Speicher geladen und ausgeführt werden (mr) und alle Dateien im Ordner @{CGIBIN} lesen, eine Berechtigung zur Ausführung ist nicht nötig.
Zur Ausführung eines Python-Scripts werden in der Regel noch verschiedene Bibliotheken und Module benötigt. Diese, beziehungsweise ihre Pfade, wurden bereits in <abstractions/python> zusammengefasst, sodass AppArmor-Profile für Python-Scripte diese Regeln lediglich mittels include einbinden müssen.
Das obige Kindprofil enthält sonst keinerlei Regeln. Daher beschränken sich die erlaubten Zugriffe auf solche, die von den in den Abstractions enthaltenen Regeln definiert werden. Durch die Erfahrungen aus den letzten beiden Artikeln ist das Kindprofil jedoch schnell um entsprechende Regeln erweitert. Auch aa-logprof kann hierbei wieder zu Rate gezogen werden.
Sollen die Scripte beispielsweise Dateien im Verzeichnis /data lesend und schreibend verarbeiten dürfen, geht es von Hand immer noch am schnellsten: es muss lediglich die Zeile /data/* rw, in das Kindprofil eingetragen werden.
Der Anfang ist gemacht
Der Einsatz von Kindprofilen beschränkt sich nicht nur auf Webserver: jegliche Software, die andere Programme als Kindprozess startet lässt sich nach diesem Prinzip genauso gut mit AppArmor überwachen und absichern. Gleiches gilt für Scripte und Interpreter anderer Programmiersprachen.
Wir unterstützen Sie gerne
Ob AppArmor, Debian oder PostgreSQL: mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich kann die credativ GmbH Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Sie haben Fragen zu unserem Artikel oder würden sich wünschen, dass die Spezialisten von credativ sich eine andere Software ihrer Wahl angucken? Dann schauen Sie doch vorbei und melden sich über unser Kontaktformular oder schreiben uns eine E-Mail an info@credativ.de.
Über credativ
Die credativ GmbH ist ein herstellerunabhängiges Beratungs- und Dienstleistungsunternehmen mit Standort in Mönchengladbach. Seit dem erfolgreichen Merger mit Instaclustr 2021 ist die credativ GmbH das europäische Hauptquartier der Instaclustr Gruppe.
Die Instaclustr Gruppe hilft Unternehmen bei der Realisierung eigener Applikationen im großen Umfang dank Managed-Plattform-Solutions für Open Source Technologien wie zum Beispiel Apache Cassandra®, Apache Kafka®, Apache Spark™, Redis™, OpenSearch™, Apache ZooKeeper™, PostgreSQL® und Cadence. Instaclustr kombiniert eine komplette Dateninfrastruktur-Umgebung mit praktischer Expertise, Support und Consulting um eine kontinuierliche Leistung und Optimierung zu gewährleisten. Durch Beseitigung der Komplexität der Infrastruktur wird es Unternehmen ermöglicht, ihre internen Entwicklungs- und Betriebsressourcen auf die Entwicklung innovativer kundenorientierter Anwendungen zu geringeren Kosten zu konzentrieren. Zu den Kunden von Instaclustr gehören einige der größten und innovativsten Fortune-500-Unternehmen.
Wie im vorausgegangenen Beitrag beschrieben erfolgt unter unixoiden Systemen die Rechtekontrolle traditionell nach dem Prinzip der Discretionary Access Control (DAC). Anwendungen und Dienste laufen unter einer bestimmten User- und Group-ID und erhalten die entsprechenden Zugriffsrechte auf Dateien und Ordner.
AppArmor implementiert für Linux, aufbauend auf den Linux Security Modules, eine sogenannte Mandatory Access Control: eine Zugriffskontrollstrategie mit der einzelnen Programmen bestimmte Rechte gewährt oder verweigert werden können. Diese Sicherheitsschicht existiert zusätzlich zur traditionellen DAC.
Seit Debian 10 buster ist AppArmor standardmäßig im Kernel enthalten und aktiviert. Die Pakete apparmor und apparmor-utils bringen Tools zur Erstellung und Pflege von AppArmor-Profilen mit.
Mitgelieferte Profile
Die beiden erwähnten Pakete bringen keine fertigen Profile, sondern lediglich die im vorigen Artikel erwähnten Abstractions mit: Sammlungen von Regeln, die in mehreren Profilen eingebunden werden können.
Manche Programme bringen ihre Profile in ihren Paketen selbst mit, andere enthalten Profile, wenn entsprechende Module nachinstalliert werden – zum Beispiel mod_apparmor beim Apache Webserver.
Die Pakete apparmor-profiles und apparmor-profiles-extra enthalten AppArmor-Profile, die nach der Installation in den Verzeichnissen /etc/apparmor.d (für erprobte Profile) beziehungsweise /usr/share/apparmor/extra-profiles (für experimentelle Profile) zu finden sind. Diese Profile können als Grundlage für eigene Profile herangezogen werden.
Profile selbst erstellen
Während für die meisten gängigen Serverdienste wie beispielsweise den Apache Webserver zumindest experimentelle Profile zur Verfügung stehen, ist für den nginx Webserver nichts zu finden. Dies ist jedoch nicht weiter tragisch, denn ein neues AppArmor-Profil ist mit Hilfe der apparmor-utils schnell erstellt.
Beispiel nginx
Im Folgenden wird eine einfache Basisinstallation des nginx, die lediglich HTML-Dateien unter /var/www/html über HTTP ausliefert, angenommen. Dabei liegt der Fokus vor allem auf der allgemeinen Herangehensweise, sich wiederholende Schritte werden also übersprungen.
Die geschilderte Herangehensweise lässt sich auf beliebige andere Programme übertragen. Um sich über die verwendeten Pfade und Dateien eines Programms zu informieren, kann dpkg mit der Option -L herangezogen werden, welche alle Pfade eines Pakets auflistet. Dabei ist zu beachten, dass hierfür möglicherweise mehrere Pakete befragt werden müssen, für nginx liefert das gleichnamige Paket kaum brauchbare Informationen; diese erhält man erst mit dem Paket nginx-common:
# dpkg -L nginx-common
Für die folgenden Schritte empfiehlt es sich zwei Terminals mit root-Rechten geöffnet zu haben.
Bevor der Webserver-Prozess zur Erstellung eines Profils beobachtet werden kann, müssen all seine laufenden Prozesse beendet werden:
# systemctl stop nginx
Sind alle Prozesse gestoppt, wird im zweiten Terminal aa-genprof mit dem Pfad der Programmdatei des Webservers aufgerufen:
# aa-genprof /usr/sbin/nginx
Es erscheinen einige Informationen zum aktuellen Aufruf von aa-genprof, darunter der Hinweis Profiling: /usr/sbin/nginx, gefolgt von Please start the application to be profiled in another window and exercise its functionality now.
Um dem Folge zu leisten wird im ersten Terminalfenster der Webserver-Prozess wieder gestartet:
# systemctl start nginx
Bevor im zweiten Fenster die Option S zum durchsuchen der Logdateien nach AppArmor-Events aufgerufen wird, sollte der Webserver einige Momente laufen, auch sollte er von einem Browser aus aufgerufen werden, damit möglichst alle üblichen Aktivitäten des Prozesses aufgezeichnet werden.
Ist dies geschehen, können mit einem Druck auf die Taste S die Logdateien nach Events durchsucht werden:
[(S)can system log for AppArmor events] / (F)inish Reading log entries from /var/log/syslog. Updating AppArmor profiles in /etc/apparmor.d. Complain-mode changes:
Wurde ein Event gefunden, wird das betroffene Profil sowie die Aktion angezeigt, die von AppArmor aufgezeichnet wurde:
Profile: /usr/sbin/nginx Capability: dac_override Severity: 9 [1 - capability dac_override,] (A)llow / [(D)eny] / (I)gnore / Audi(t) / Abo(r)t / (F)inish
Hier fordert das Programm /usr/sbin/nginx die Capability dac_override an, die bereits im letzten Artikel beschrieben wurde. Sie ist für den Betrieb des Webservers unabdingbar und wird mittels Druck auf A erlaubt. Alternativ kann die Anforderung mit D verweigert oder mit I ignoriert werden. Mit der Option Audit würde diese Anforderung auch weiterhin im laufenden Betrieb in der Logdatei aufgezeichnet.
Profile: /usr/sbin/nginx Capability: net_bind_service Severity: 8 [1 - #include <abstractions/nis>] 2 - capability net_bind_service,
Das nächste Event zeigt, dass der Prozess die Capability net_bind_service anfordert, der benötigt wird, um einen Port mit einer Portnummer kleiner als 1024 zu öffnen.
Anders als bei der ersten Nachfrage gibt es hier zwei Möglichkeiten den Zugriff zukünftig zu erlauben: in der ersten Option werden Abstractions für NIS, den Network Information Service eingebunden. In dieser Abstraction, welche unter /etc/apparmor.d/abstractions/nis zu finden ist, ist neben einer Regel, die den Zugriff auf Regelwerke für NIS erlaubt auch die Capability net_bind_service aufgeführt.
Da der HTTP-Server jedoch keine NIS-Funktionalität mitbringt, reicht es lediglich die Capability zu erlauben. Mit einem Druck auf 2 und A wird diese in das Profil übernommen.
Gleiches gilt für die in den folgenden Schritten vorgeschlagenen Abstractions für dovecot und postfix: hier genügt es lediglich die Capabilities setgid und setuid zu erlauben.
Manchmal kann die Bezeichnung der Abstractions etwas irreführend sein: so enthält die Abstraction nameservice neben Regeln, welche neben dem lesenden Zugriff auf die üblichen Nameservice-Dateien wie passwd oder hosts erlauben auch solche Regeln, die den Netzwerkzugriff gestatten. Es lohnt also immer ein Blick in die jeweilige Datei unter /etc/apparmor.d/abstractions/, ob sich das Einbinden der Abstraction lohnt.
Nachdem der Webserver-Prozess alle nötigen Capabilities erhalten hat, versucht er offenbar seine Fehler-Logdatei /var/log/nginx/log mit Schreibrechten zu öffnen. Hier fällt auf, dass neben dem üblichen Allow, Deny und Ignore noch die Optionen Glob und Glob with Extension hinzugekommen sind.
Profile: /usr/sbin/nginx Path: /var/log/nginx/error.log New Mode: w Severity: 8 [1 - /var/log/nginx/error.log w,] (A)llow / [(D)eny] / (I)gnore / (G)lob / Glob with (E)xtension / (N)ew / Audi(t) / Abo(r)t / (F)inish
Bei Eingabe von E wird der Liste ein weiterer Vorschlag hinzugefügt:
1 - /var/log/nginx/error.log w, [2 - /var/log/nginx/*.log w,]
Der Dateiname error.log wurde durch einen Wildcard und die Endung .log ersetzt. Diese Regel würde neben den Schreibrechten auf die Datei /var/log/nginx/error.log beispielsweise auch solche auf die Datei /var/log/nginx/access.log gewähren – das sind (mindestens) zwei Regeln zusammengefasst zu einer einzigen.
Diese Regeln würde für dieses Beispiel bereits ausreichen, möglicherweise sollen aber auch Dateien, welche nicht die Dateiendung .log besitzen, im Verzeichnis /var/log geschrieben werden dürfen. Durch Eingabe von G wird der Liste noch ein weiterer Vorschlag hinzugefügt:
1 - /var/log/nginx/error.log w, 2 - /var/log/nginx/*.log w, [3 - /var/log/nginx/* w,]
Der Dateiname wurde nun durch einen einzelnen Wildcard ersetzt, der Prozess dürfte also beliebige Dateien in /var/log/nginx mit Schreibrechten öffnen.
Wie bereits erwähnt werden durch die vorgeschlagenen Regeln ausschließlich Schreib-, jedoch keine Leserechte eingeräumt, selbst wenn die Zugriffsrechte der Datei mehr erlauben würden. Für Logdatei eines Webservers reichen die Schreibrechte jedoch völlig aus.
Im Folgenden verlangt nginx lesenden Zugriff auf verschiedene Konfigurationsdateien, zum Beispiel /etc/nginx/nginx.conf. Diese befindet sich im Konfigurationsverzeichnis des nginx Webservers, in dem noch weitere Dateien liegen, die ebenfalls gelesen werden können sollen.
Profile: /usr/sbin/nginx Path: /etc/nginx/nginx.conf New Mode: owner r Severity: unknown [1 - owner /etc/nginx/nginx.conf r,]
Auch hier kann mit G die Regel auf alle Dateien des Verzeichnisses /etc/nginx erweitert werden.
1 - owner /etc/nginx/nginx.conf r, [2 - owner /etc/nginx/* r,]
Gleiches gilt für die Unterverzeichnisse des Konfigurationsverzeichnisses, diese können durch Globbing als /etc/nginx/*/ abgedeckt werden.
Einen Spezialfall für das Globbing stellen die in jenen Unterverzeichnissen enthaltenen Dateien dar:
Profile: /usr/sbin/nginx Path: /etc/nginx/sites-available/default New Mode: owner r Severity: unknown [1 - owner /etc/nginx/sites-available/default r,]
Nach zweifacher Eingabe von G wird nach dem von oben bekannten Wildcard * das Wildcard ** vorgeschlagen, welches, wie im vorherigen Artikel beschrieben, alle in Unterverzeichnissen (und deren Unterverzeichnissen) befindlichen Dateien abdeckt.
1 - owner /etc/nginx/sites-available/default r, 2 - owner /etc/nginx/sites-available/* r, [3 - owner /etc/nginx/** r,]
Die letzten Schritte enthielten außerdem alle das Attribut owner: dieses bewirkt, dass eine Regel ausschließlich dann Anwendung findet, wenn der zugreifende Prozess auch Besitzer der Datei ist. Ist die Datei vorhanden, gehört jedoch jemand anderem, wird der Zugriff verweigert.
Es folgen noch einige weitere Pfade und Dateien wie /usr/share/nginx/modules-available/, /run/nginx.pid und /proc/sys/kernel/random/boot_id, welche der nginx ebenfalls zum ordnungsgemäßen Betrieb benötigt. Die Vorgehensweise bleibt jedoch unverändert.
Sind alle Events durchlaufen schließt das Programm mit der Meldung:
= Changed Local Profiles = The following local profiles were changed. Would you like to save them? [1 - /usr/sbin/nginx] (S)ave Changes / Save Selec(t)ed Profile / [(V)iew Changes] / View Changes b/w (C)lean profiles / Abo(r)t
Die Optionen sind klar: mit S werden Änderungen gespeichert, mit V können diese vorher als Diff angeschaut werden. Das folgende Listing zeigt das im obigen Durchlauf erzeugte Profil.
include <tunables/global>
profile nginx /usr/sbin/nginx {
include <abstractions/base>
include <abstractions/nameservice>
capability dac_override,
capability dac_read_search,
capability setgid,
capability setuid,
/usr/sbin/nginx mr,
/var/log/nginx/*.log w,
/var/www/html/** r,
owner /etc/nginx/* r,
owner /etc/nginx/** r,
owner /run/nginx.pid rw,
owner /usr/share/GeoIP/*.mmdb r,
owner /usr/share/nginx/modules-available/*.conf r,
owner /var/cache/nginx/** rw,
owner /var/lib/nginx/** rw,
}Nach dem Speichern der Änderungen kehrt aa-genprof zu seinem Startbildschirm zurück. Hier könnte nun erneut in Logdateien nach Events gesucht oder aber das Programm mit F beendet werden.
Das Programm endet mit der Meldung:
Setting /usr/sbin/nginx to enforce mode. Reloaded AppArmor profiles in enforce mode.
Das soeben erstellte Profil wurde also geladen und in den enforce-Modus versetzt. Das bedeutet, dass dem Programm nur noch im Profil erlaubte Zugriffe möglich sind, alle anderen Zugriffsversuche werden von AppArmor blockiert und im Syslog festgehalten.
Für simple Programme ist die Erstellung eines Profils damit beendet und AppArmor kann seine Arbeit verrichten; komplexere Programme hingegen werden im weiteren Verlauf bislang unbekanntes Verhalten zeigen, das vom bislang erstellten Profil unterbunden würde. Hier hilft es, das Profil mittels aa-complain in den sogenannten complain-Modus zu schalten.
# aa-complain nginx
Zugriffe, welche über das bekannte Profil hinausgehen werden im complain-Modus grundsätzlich erlaubt, aber im Syslog festgehalten.
Feb 18 15:25:50 web01 kernel: [ 9908.611408] audit: type=1400 audit(1645197950.338:100): apparmor="ALLOWED" operation="open" profile="nginx" name="/srv/www/index.html" pid=4490 comm="nginx" requested_mask="r" denied_mask="r" fsuid=33 ouid=0
Im obigen Auszug aus dem Syslog wurde das Webroot-Verzeichnis auf dem Host web01 zu /srv/www geändert, das vormals erstellte AppArmor-Profil jedoch nicht angepasst. Da sich das Profil nun im complain-Modus befindet wurde der Zugriff dennoch erlaubt: apparmor="ALLOWED"; im enforce-Mode stünde dort ein DENIED und der Zugriff würde verweigert.
An den übrigen Informationen ist gut zu erkennen, was passiert ist: der Prozess mit der Prozess-ID (pid) 4190 hat versucht die Datei /srv/www/index.html (name) lesend (requested_mask) zu öffnen, was aufgrund des Profils (profile) nginx jedoch untersagt wäre (denied_mask).
Sollte eine mit AppArmor abgesicherte Software also einmal nicht so funktionieren wie erwartet, lohnt zu allererst ein Blick ins Syslog!
Nach einiger Zeit werden sich dort einige Einträge befinden, die dann in das AppArmor-Profil übernommen werden sollen. Dafür wird das Programm aa-logprof verwendet: es durchsucht das Syslog nach Einträgen und fragt in der Manier von aa-genprof nach, ob und wie darauf Einträge im Profil erstellt werden sollen. Dieser Vorgang kann beliebig oft wiederholt werden.
Finden sich im Syslog keine weiteren Einträge mehr, Wurde das Profil genügend angepasst und kann mit aa-enforce wieder in den enforce-Modus versetzt werden:
# aa-enforce nginx
Damit ist die grundlegende Erstellung eines einfachen AppArmor-Profils abgeschlossen und die Prozesse des nginx werden entsprechend der darin definierten Regeln kontrolliert und überwacht.
Wir unterstützen Sie gerne
Ob AppArmor, Debian oder PostgreSQL: mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich, kann die credativ GmbH Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Sie haben Fragen zu unserem Artikel oder würden sich wünschen, dass die Spezialisten von credativ sich eine andere Software ihrer Wahl angucken?
Dann schauen Sie doch vorbei und melden sich über unser Kontaktformular oder schreiben uns eine E-mail an info@credativ.de.
Über credativ
Die credativ GmbH ist ein herstellerunabhängiges Beratungs- und Dienstleistungsunternehmen mit Standort in Mönchengladbach.
Eigentlich ist Zugriffskontrolle unter Linux eine einfache Sache:
Dateien geben ihre Zugriffsrechte (Ausführen, Schreiben, Lesen) getrennt für ihren Besitzer, ihre Gruppe und zu guter Letzt sonstige Benutzer an. Jeder Prozess (egal ob die Shell eines Benutzers oder ein Systemdienst) auf dem System läuft unter einer Benutzer-ID sowie Gruppen-ID, welche für die Zugriffskontrolle herangezogen werden.
Einem Webserver, der mit den Rechten des Users www-data und der Gruppe www-data ausgeführt wird, kann so der Zugriff auf seine Konfigurationsdatei im Verzeichnis /etc, seine Logdatei unter /log und die auszuliefernden Dateien unter /var/www gestattet werden. Mehr Zugriffsrechte sollte der Webserver für seine Arbeit nicht brauchen.
Dennoch könnte er, sei es durch Fehlkonfiguration oder eine Sicherheitslücke, auch auf Dateien anderer Benutzer und Gruppen zugreifen und diese ausliefern, solange diese für jedermann lesbar sind, wie es zum Beispiel technisch bedingt bei /etc/passwd der Fall ist. Mit der traditionellen Discretionary Access Control (DAC), wie sie unter Linux und anderen unixoiden Systemen eingesetzt wird, ist dies leider nicht zu verhindern.
Schon seit Dezember 2003 bietet der Linux-Kernel jedoch mit den Linux Security Modules (LSM) ein Framework an, mit der sich eine Mandatory Access Control (MAC) implementieren lässt, bei der in Regelwerken genau spezifiziert werden kann, auf welche Ressourcen ein Prozess zugreifen darf. AppArmor implementiert eine solche MAC und ist bereits seit 2010 im Linux-Kernel enthalten. Während es ursprünglich nur bei SuSE und später Ubuntu Verwendung fand, ist es seit Buster (2019) auch in Debian standardmäßig aktiviert.
AppArmor
AppArmor überprüft und überwacht auf Basis eines Profils, welche Berechtigungen ein Programm oder Script auf einem System hat. Ein Profil enthält dabei im Normalfall das Regelwerk für ein einzelnes Programm. Darin ist zum Beispiel definiert wie (lesend, schreibend) auf welche Dateien und Verzeichnisse zugegriffen werden darf, ob ein Netzwerksocket erzeugt werden darf oder ob und in welchem Rahmen andere Anwendungen ausgeführt werden dürfen. Alle anderen, nicht im Profil definierten Aktionen, werden verweigert.
Aufbau eines Profils
Das folgende Listing (die Zeilennummern sind nicht Bestandteil der Datei und dienen lediglich der Orientierung) zeigt das Profil für einen einfachen Webserver, dessen Programmdatei unter /usr/sbin/httpd zu finden ist.
Standardmäßig liegen AppArmor-Profile im Verzeichnis /etc/apparmor.d und sind per Konvention nach dem Pfad der Programmdatei benannt. Der erste Schrägstrich wird dabei ausgelassen, alle folgenden Schrägstriche werden durch Punkte ersetzt. Das Profil des Webservers befindet sich demnach in der Datei /etc/apparmor.d/usr.sbin.httpd.
1 include <tunables/global>
2
3 @{WEBROOT}=/var/www/html
4
5 profile httpd /usr/sbin/httpd {
6 include <abstractions/base>
7 include <abstractions/nameservice>
8
9 capability dac_override,
10 capability dac_read_search,
11 capability setgid,
12 capability setuid,
13
14 /usr/sbin/httpd mr,
15
16 /etc/httpd/httpd.conf r,
17 /run/httpd.pid rw,
18
19 @{WEBROOT}/** r,
20
21 /var/log/httpd/*.log w,
22 }Präambel
Die Anweisung include in Zeile 1 fügt, wie die gleichnamige C-Präprozessordirektive, den Inhalt anderer Dateien an Ort und Stelle ein. Ist der Dateiname wie hier von spitzen Klammern umgeben, so bezieht sich der angegebene Pfad auf den Ordner /etc/apparmor.d, bei Anführungszeichen ist der Pfad relativ zur Profildatei.
Vereinzelt, wenn auch mittlerweile veraltet, findet sich noch die Schreibweise #include. Da Kommentare in AppArmor-Profilen jedoch mit einem # beginnen und der Rest der Zeile ignoriert wird, führt die alte Schreibweise zu einem Widerspruch: eine vermeintlich auskommentierte #include-Anweisung würde nämlich sehr wohl ausgeführt! Um eine include-Anweisung auszukommentieren empfiehlt sich also ein Leerzeichen nach dem #.
Die Dateien im Unterordner tunables enthalten in der Regel Variablen- und Alias-Definitionen, die von mehreren Profilen benutzt und gemäß dem don’t repeat yourself-Prinzip (DRY) nur an einer Stelle definiert werden.
In Zeile 2 wird mit @{WEBROOT} die Variable WEBROOT angelegt und ihr den Wert /var/www/html zugewiesen. Würden neben dem aktuellen Profil auch noch andere Profile Regeln für das Webroot-Verzeichnis definieren, könnte sie stattdessen auch in einer eigenen Datei tunables definiert und in den entsprechenden Profilen per include eingebunden werden.
Profilteil
Der Profilteil beginnt in Zeile 5 mit dem Schlüsselwort profile. Ihm folgt der Name des Profils, hier httpd, der Pfad der ausführbaren Datei, /usr/sbin/httpd, sowie gegebenenfalls Flags, welche das Verhalten des Profils beeinflussen. Von geschweiften Klammern eingeschlossen folgen dann die einzelnen Regeln des Profils.
Wie bereits zuvor fügt auch in den Zeilen 6 und 7 include den Inhalt der angeführten Datei an Ort und Stelle ein. Im Unterordner abstractions befinden sich gemäß dem DRY-Prinzip Dateien mit Regelsätzen, die in der gleichen Form immer wieder auftreten, da sie grundlegende aber auch spezifische Funktionalitäten behandeln.
So wird in der Datei base beispielsweise neben dem Zugriff auf verschiedene Dateisysteme wie /dev, /proc und /sys auch der auf Laufzeitbibliotheken oder einige systemweite Konfigurationsdateien geregelt. Die Datei nameservice enthält, entgegen ihrer Benennung, nicht nur Regeln, welche die Namensauflösung betreffen, sondern auch solche, die überhaupt erst einen Zugriff auf das Netzwerk erlauben. Diese beiden abstractions finden sich also in den meisten Profilen, vor allem von Netzwerkdiensten.
Beginnend mit Zeile 9 räumen Regeln mit dem Schlüsselwort capability einem Programm besondere Privilegien, sogenannte capabilities ein. Dabei gehören setuid und setgid sicherlich zu den bekannteren: sie erlauben dem Programm, seine eigene uid und gid zu ändern; beispielsweise kann ein Webserver so als root starten, den privilegierten Port 80 öffnen und dann seine root-Rechte ablegen. dac_override und dac_read_search erlauben es, die Überprüfung von Lese-, Schreib- und Ausführungsrechten zu umgehen. Ohne diese capability dürfte selbst ein Programm, welches unter der uid root läuft, anders als man es von der Shell gewöhnt ist, nicht ungeachtet der Dateiattribute die Dateien zugreifen.
Ab Zeile 14 befinden sich Regeln, welche über Zugriffsberechtigungen auf Pfade (also Ordner und Dateien) entscheiden. Der Aufbau ist denkbar einfach: zu Beginn wird der Pfad angegeben, gefolgt von einem Leerzeichen und den Kürzeln für die erteilten Berechtigungen.
Exkurs: Berechtigungen
Folgende Tabelle liefert einen kurzen Überblick über die gängigsten Berechtigungen:
| Kürzel | Bedeutung | Beschreibung |
|---|---|---|
r | read | lesender Zugriff |
w | write | schreibender Zugriff |
a | append | Anhängen von Daten |
x | execute | Ausführen |
m | memory map executable | Mappen und Ausführen des Inhalts der Datei im Speicher |
k | lock | Setzen einer Sperre |
l | link | Erstellen eines Links |
Exkurs: Globbing
Pfade können sowohl einzeln voll ausgeschrieben oder mehrere Pfade durch Wildcards zu einem Pfad zusammengefasst werden. Dieses Globbing genannte Verfahren findet heutzutage auch bei den meisten Shells Anwendung, sodass diese Schreibweise keine Schwierigkeiten mit sich bringen sollte.
| Ausdruck | Beschreibung |
|---|---|
/dir/file | bezeichnet genau eine Datei |
/dir/* | umfasst alle Dateien innerhalb von /dir/ |
/dir/** | umfasst alle Dateien innerhalb von /dir/ samt Unterverzeichnisse |
? | steht für genau ein Zeichen |
{} | Geschweifte Klammern ermöglichen Alternationen |
[] | Eckige Klammern können für Zeichenklassen verwendet Werden |
Beispiele:
| Ausdruck | Beschreibung |
|---|---|
/dir/??? | bezeichnet also alle Dateien in /dir, deren Dateiname genau 3 Zeichen lang ist |
/dir/*.{png,jpg} | bezeichnet alle Bilddateien in /dir, deren Dateiendung png oder jpg lautet |
/dir/[abc]* | bezeichnet alle Dateien in /dir, deren Name mit den Buchstaben a, b oder c beginnt |
Für Zugriffe auf die Programmdatei /usr/sbin/httpd erhält der Webserver in Zeile 14 die Berechtigungen mr. Das Kürzel r steht für read und bedeutet, dass der Inhalt der Datei gelesen werden darf, m steht für memory map executable und erlaubt es, den Inhalt der Datei in den Arbeitsspeicher zu laden und auszuführen.
Wer einen Blick in die Datei
/etc/apparmor.d/abstractions/basewagt, wird sehen, dass die Berechtigungmunter anderem auch für das Laden von Bibliotheken nötig ist.
Während des Startvorgangs wird der Webserver versuchen seine Konfiguration aus der Datei /etc/httpd.conf auszulesen. Da der Pfad die Berechtigung r zum lesen besitzt, wird AppArmor dies erlauben. Anschließend schreibt httpd seine PID in die Datei /run/httpd.pid. Das Kürzel w steht natürlich für write und erlaubt Schreiboperationen auf dem Pfad. (Zeilen 16, 17)
Der Webserver soll Dateien unterhalb des WEBROOT-Verzeichnisses ausliefern. Um nicht alle Dateien und Unterverzeichnisse nicht einzeln aufführen zu müssen kann der Wildcard ** benutzt werden. Der Ausdruck @{WEBROOT}/** in Zeile 19 steht also für alle Dateien innerhalb und unterhalb des Ordners /var/www/html – inklusive Unterordnern und versteckten Dateien. Da es sich um eine statische Webseite handelt und der Webserver die Dateien nicht zu verändern braucht, wird mit r nur eine Leseberechtigung erteilt.
Wie üblich werden alle Zugriffe auf den Webserver in den Logdateien access.log und error.log im Verzeichnis /var/log/httpd/ protokolliert. Diese werden vom Webserver nur geschrieben, es reicht also in Zeile 21 mit w lediglich eine Schreibberechtigung auf den Pfad /var/log/httpd/* zu setzen.
Damit ist das Profil auch schon komplett und bereit für den Einsatz. Neben den hier gezeigten gibt es noch eine ganze Reihe weiterer Regeltypen, mit denen das erlaubte Verhalten eines Prozesses genau definiert werden kann.
Weitere Informationen zum Aufbau von Profilen finden sich in der Manpage zu apparmor.d sowie im Wiki-Artikel zur AppArmor Quick Profile Language, eine ausführliche Beschreibung aller Regeln findet sich in der AppArmor Core Policy Reference.
Erstellung eines Profils
Einige Anwendungen und Pakete bringen bereits fertige AppArmor-Profile mit, andere müssen noch an die Gegebenheiten angepasst werden. Wiederum andere Pakete bringen überhaupt keine Profile mit – diese müssen vom Admin selbst erstellt werden.
Um ein neues AppArmor-Profil für eine Anwendung zu erstellen wird üblicherweise zuerst ein nur sehr grundlegendes Profil angelegt und AppArmor angewiesen dieses im sogenannten complain mode zu behandeln. Hier werden Zugriffe, welche noch nicht im Profil definiert sind, in den Logdateien des Systems festzuhalten.
Anhand dieser Log-Einträge kann das Profil dann nach einiger Zeit nachgebessert und, wenn keine Einträge mehr in den Logs auftauchen, AppArmor angewiesen werden die in dem Profil in den enforce mode zu übernehmen und die darin aufgeführten Regeln durchzusetzen sowie nicht definierte Zugriffe zu sperren.
Auch wenn es problemlos möglich ist ein AppArmor-Profil von Hand in einem Texteditor zu erstellen und anzupassen, finden sich im Paket apparmor-utils verschiedene Hilfsprogramme, die einem die Arbeit erleichtern können: so hilft aa-genprof beim Anlegen eines neuen Profils, aa-complain schaltet dieses in den complain mode, aa-logprof hilft dabei Logdateien zu durchsuchen und dem Profil entsprechende neue Regeln hinzuzufügen, aa-enforce schaltet das Profil letztendlich in den enforce mode.
Im nächsten Artikel dieser Serie werden wir auf den hier geschaffenen Grundlagen ein eigenes Profil für den Webserver nginx erstellen.
Wir unterstützen Sie gerne
Ob AppArmor, Debian oder PostgreSQL: mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich kann die credativ GmbH Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Sie haben Fragen zu unserem Artikel oder würden sich wünschen, dass die Spezialisten von credativ sich eine andere Software ihrer Wahl angucken? Dann schauen Sie doch vorbei und melden sich über unser Kontaktformular oder schreiben uns eine E-Mail an info@credativ.de.
Über credativ
Die credativ GmbH ist ein herstellerunabhängiges Beratungs- und Dienstleistungsunternehmen mit Standort in Mönchengladbach. Seit dem erfolgreichen Merger mit Instaclustr 2021 ist die credativ GmbH das europäische Hauptquartier der Instaclustr Gruppe.
Die Instaclustr Gruppe hilft Unternehmen bei der Realisierung eigener Applikationen im großen Umfang dank Managed-Plattform-Solutions für Open Source Technologien wie zum Beispiel Apache Cassandra®, Apache Kafka®, Apache Spark™, Redis™, OpenSearch™, Apache ZooKeeper™, PostgreSQL® und Cadence. Instaclustr kombiniert eine komplette Dateninfrastruktur-Umgebung mit praktischer Expertise, Support und Consulting um eine kontinuierliche Leistung und Optimierung zu gewährleisten. Durch Beseitigung der Komplexität der Infrastruktur wird es Unternehmen ermöglicht, ihre internen Entwicklungs- und Betriebsressourcen auf die Entwicklung innovativer kundenorientierter Anwendungen zu geringeren Kosten zu konzentrieren. Zu den Kunden von Instaclustr gehören einige der größten und innovativsten Fortune-500-Unternehmen.