Ausgangssituation
Vor einiger Zeit kündigte Bitnami die Umstellung der öffentlichen Container Repositories an.
Bitnami ist dafür bekannt sowohl Helm Charts als auch Container-Images für eine Vielzahl von Applikationen bereitzustellen. Dazu gehören z.b. Helm Charts und Container Images für Keycloak, den RabbitMQ Cluster Operator und viele weitere. Viele dieser Charts und Images werden von Unternehmen, Privatpersonen aber auch von OpenSource Projekten verwendet.
Aktuell basieren die von Bitnami bereitgestellten Images auf Debian. Zukünftig sollen die Images auf speziell gehärteten Distroless Images basieren.
Eine Timeline der Anpassungen inklusive FAQ findet sich auf GitHub
Was ändert sich konkret?
Am 28.08.2025 wird, laut Bitnamis Aussage, das aktuelle Dockerhub Repo Bitnami umgestellt. Alle bis dahin verfügbaren Images werden ab diesem Zeitpunkt nur noch innerhalb des Bitnami Legacy Repositories verfügbar sein.
Die neuen Secure Images sind zum Teil bereits jetzt unter bitnamisecure verfügbar. Allerdings wird ohne Subscription nur ein sehr kleines Subset an Images bereitgestellt. Derzeit finden sich unter bitnami 343 verschiedene Repositories – unter bitnamisecure hingegen nur noch 44 (Stand 2025-08-19). Hinzu kommt, dass die neuen Secure Images in der freien Variante nur noch unter ihren Digests bereitgestellt werden. Das einzig vorhandene Tag „latest“ zeigt immer auf das zuletzt bereitgestellte Image. Welche Version dahinter steht, ist auf den ersten Blick nicht ersichtlich.
Action Required?
Sofern Sie Helm Charts von Bitnami mit Container Images aus dem aktuellen Repository verwenden, besteht Handlungsbedarf. Aktuell verwendete Bitnami Helm Charts referenzieren meist die das (noch) aktuelle Repository.
Je nach Umgebung kann es sein, dass die Auswirkungen der Umstellung erst zu einem späteren Zeitpunkt spürbar werden. Zum Beispiel bei einem Container- oder Pod-Restart, sofern die gecachte Version des Images bereinigt wurde oder der Pod auf einer Node gestartet wurde, die das Image nicht im direkten Zugriff (Cache) hat. Sofern ein Container Proxy zum Bezug der Images verwendet wird, ggf. noch später.
Benötigte Anpassungen
Wer sicherstellen will, dass die aktuell verwendeten Images weiter bezogen werden können, sollte auf das Bitnami Legacy Repository umstellen. Dies ist bereits jetzt möglich.
Betroffene Helm Charts können z.B. mit angepassten Values Dateien gepatcht werden.
Leider handelt es sich bei den genannten Anpassungen nur um einen Quickfix. Wer langfristig sichere und aktualisierte Images verwenden möchte, muss sich umstellen.
Dies kann bedeuten auf ein alternatives Helm-Chart oder Container Image zu wechseln, sich mit den neuen Gegebenheiten des bitnamisecure Repositories abzufinden oder aber für den bisherigen Komfort zu bezahlen.
Welche Alternativen gibt es?
Für Unternehmen, die nicht bereit sind, die neuen Lizenzgebühren zu zahlen, gibt es verschiedene Alternativen:
- Eigene Container Images bauen: Unternehmen können ihre eigenen Container Images auf Basis von Dockerfiles und offiziellen Basis-Images erstellen.
- Open-Source-Alternativen: Es gibt zahlreiche Open-Source-Projekte, die vergleichbare Funktionalitäten wie Bitnami bieten. Beispiele sind „Helm Hub“ oder „Artifact Hub“.
- Community-Charts: Viele Projekte bieten eigene Helm Charts an, die von der Community gepflegt werden.
Referenzen

Wieder einmal ist eine KubeCon zu Ende gegangen
Dieses Jahr veranstaltete die CNCF das Treffen in der französischen Hauptstadt. Im Süden von Paris, an der PARIS EXPO PORTE DE VERSAILLES, kamen dieses Jahr erneut über 12.000 Teilnehmer zusammen.
Neben verschiedenen Vorträgen und Unkonferenzen gab es auch eine große Auswahl an Contribfests-Slots, die es Interessierten erleichterten, sich an verschiedenen Projekten zu beteiligen. Der thematische Schwerpunkt lag dieses Jahr eindeutig auf Künstlicher Intelligenz und Maschinellem Lernen.
Der Mittwochmorgen begann um 9 Uhr. Alle Keynotes hatten eines gemeinsam: das Thema KI/ML! Hier sind einige Titel: „Accelerating AI Workloads with GPUs in Kubernetes“, „Build an open source Platform for AI/ML“ oder „Optimizing Performance and Sustainability for AI“. Zusätzlich zu den Keynotes wurden den Teilnehmern auch zahlreiche Vorträge zum Thema KI und ML angeboten. Wer sich für dieses Thema interessierte, konnte während der drei Tage jederzeit im Raum „Paris“ fündig werden. Das neue Whitepaper zu „Cloud Native AI“ wurde ebenfalls während der Keynotes angekündigt.
Ort



Wer die Konferenz betreten wollte, musste zuerst eine Sicherheitskontrolle passieren, bestehend aus Metalldetektoren und möglichen Taschenkontrollen.
Leider gab es dieses Jahr wieder das Problem überfüllter Räume. Mehrmals am Tag war es notwendig, spontan umzuplanen, da der ausgewählte Vortrag leider bereits überfüllt war und kein Einlass mehr möglich war. Dies galt leider auch für einige Keynotes am Morgen.
Einige Impressionen

Der CNCF Storage TAG und die Storage SIG berichteten über aktuelle Entwicklungen im Speicherbereich und erwähnten verschiedene Whitepaper („CNCF Storage Whitepaper, Performance and Benchmarking Whitepaper, Cloud Native Disaster Recovery Whitepaper und das Data on Kubernetes Whitepaper.“). Unter anderem wurde gezeigt, wie „PersistentVolumeAttributes“ verwendet werden können, um PersistentVolume-Attribute anzupassen, beispielsweise um die Anzahl der IOPS für ein Volume während des Betriebs anzupassen.
Im Contribfest-Slot zu Metal3 (Metal Kubed) gaben die Maintainer des Projekts einen ersten Einblick und zeigten, wie eine Entwicklungsumgebung eingerichtet werden kann. Unter anderem bietet Metal3 eine ClusterAPI (CAPI)-Implementierung, die zur Verwaltung von Bare-Metal-Systemen verwendet werden kann. Ironic, das aus dem OpenStack-Projekt stammt, wird im Hintergrund verwendet.
Beim Vortrag „From UI to Storage“ gaben Thanos-Maintainer einen Einblick in die aktuelle Implementierung und potenzielle zukünftige Verbesserungen.
In der „CRI-O Odyssey“ sprachen die CRI-O-Maintainer über Innovationen innerhalb der Container Runtime. Dazu gehörten die Themen „Confidential Containers“ und „Podman-in-Kubernetes“. Auch das Thema WASM-Integration stand auf der Agenda.
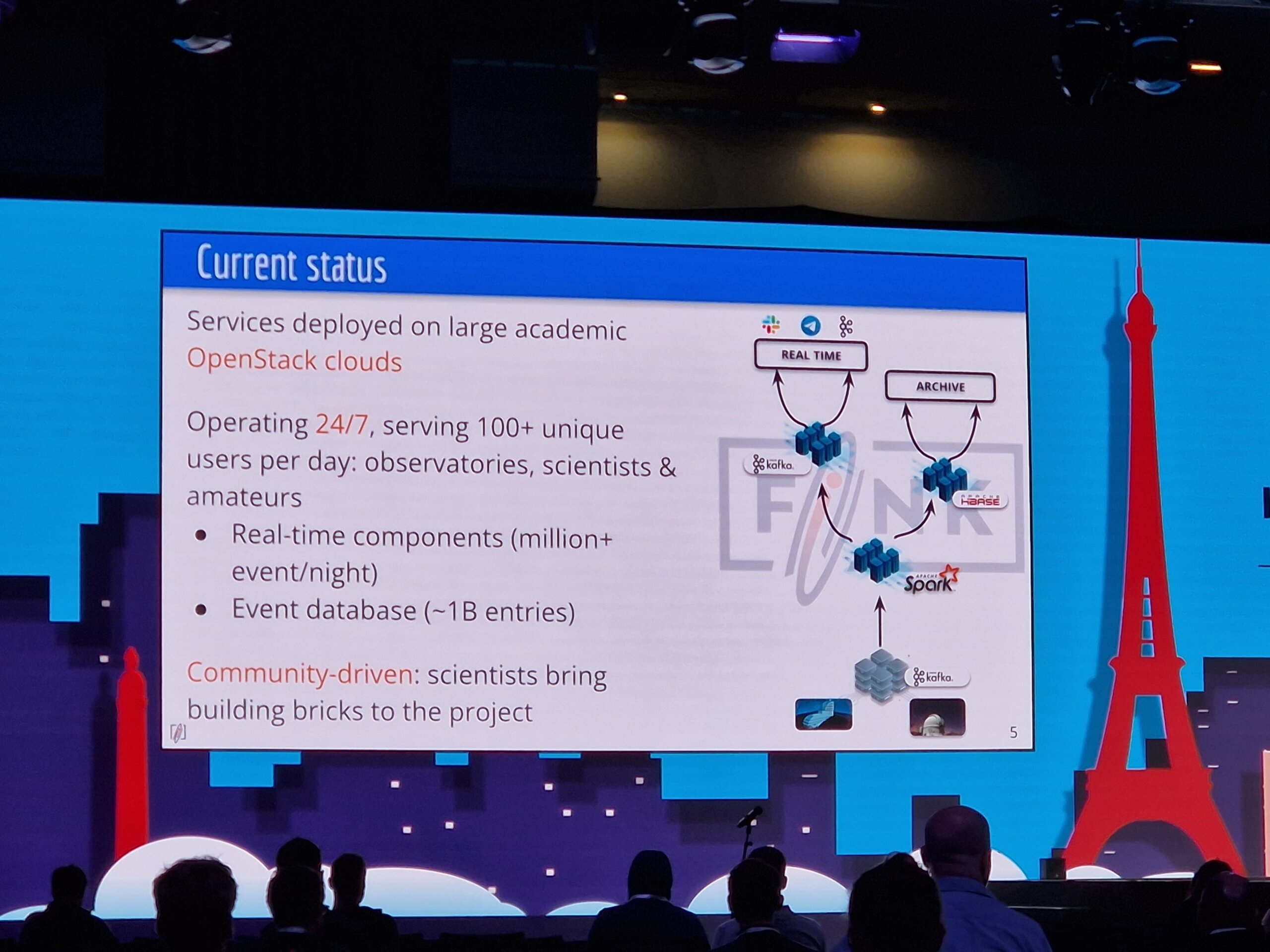
Die Maintainer von Fink berichteten über „Fink on Kubernetes“ und wie das System zur Klassifizierung von Objekten wie Asteroiden oder Supernovae im Bereich der Astronomie eingesetzt wird.
Im Vortrag „eBPF: Abilities and Limitations“ wurden nicht nur allgemeine Missverständnisse geklärt, sondern auch Wege aufgezeigt, bestehende Einschränkungen zu umgehen. Zudem wurde die Frage aufgeworfen, ob eBPF Turing-vollständig ist und eine Version von Conways „Game of Life“ in eBPF vorgestellt.
Wer schon immer wissen wollte, wie Istio mTLS in Multi-Cluster-Umgebungen mithilfe von SPIRE implementiert werden kann, wurde in Raum D fündig. Nach einer kurzen Einführung in SPIFFE und SPIRE wurde gezeigt, wie Istio-Komponenten mit dem SPIRE-Agenten verbunden werden können.
Die Maintainer von operator-sdk sprachen über aktuelle Innovationen im operator-SDK und OLM V1. Besonders interessant waren die Änderungen im Operator Lifecycle Manager, die in Version 1 (zuvor Version 0) eingeführt wurden. Unter anderem ist OLM v1 nun in der Lage, verpackte Operatoren über Helm zu verwalten, auch ohne vorherige Vorbereitung durch die Operator-Maintainer.
Fazit
Neben vielen interessanten Vorträgen gab es zahlreiche Gelegenheiten für angeregte Diskussionen mit anderen Konferenzteilnehmern und zum Austausch mit Ausstellern oder Projekt-Maintainern.
Wir freuen uns schon auf die KubeCon 2025 in London!



















Nach unseren Beiträgen zu Podman und Buildah widmen wir uns heute dem dritten Tool aus der Sammlung von RedHat-Container Tools: Skopeo.
Bei Skopeo handelt es sich um ein vergleichsweise kleines Tool, das hauptsächlich Anwendung in der Container-Erstellung und -Nutzung findet und damit prädestiniert für folgende Aufgaben und Bereiche ist:
- Kopieren von Images zwischen verschiedenen Registries
- Synchronisieren von Images zwischen verschiedenen Stellen
- Inspizieren von Images in einer Registry ohne vorherigen Download
- Löschen von Images
Hierbei ist noch zu erwähnen, dass Skopeo auch einen lokalen Docker-Daemon wie eine Registry behandelt und dies als Quelle genutzt werden kann. Auch wird, wenn nicht anders angegeben, immer auch für die Images von der aktuell für Skopeo genutzten Architektur ausgegangen. Dies lässt sich jedoch durch Parameter ändern bzw. erweitern.
Entwicklung
Die Skopeo Version 1.0 wurde am 18.05.2020 veröffentlicht und wird aktuell, wie auch die anderen RHEL-Container-Tools, unter der Apache 2.0 Lizenz angeboten. Es wird ebenfalls in Golang entwickelt, hat keinen festen Release-Zyklus und wird von der containers-group betreut. Der Code kann auf Github eingesehen werden.
Installation
Die Installation von Skopeo ist mittlerweile auf fast allen Linux-Distributionen recht trivial über eine einfache Paketinstallation erledigt, da alle gängigen Distributionen das Paket mittlerweile in den Repositories hinterlegt haben. Sollte eine bestimmte Version benötigt werden, oder es nicht möglich sein Pakete zu installieren, so wird Skopeo auch als dedizierter Container zur Verfügung gestellt.
Auch ist hier wie üblich zu beachten, dass nicht jede Distribution auch die aktuellste Version bereit stellt und damit ggf. Dritt-Repositories hinzugefügt werden müssen.
Eine detaillierte Dokumentation dazu findet sich auf Github.
Konfiguration
Skopeo nutzt hier, ebenso wie podman und buildah, folgende Dateien als Standard:
- /etc/containers/policy.json – Für, falls benötigt, Image-Policies. Kann auch per Parameter
--policyübergeben werden. - /etc/containers/registries.d – Standardverzeichnis für die eventuell spezielle Konfiguration von Image-Registries. Als prominentes Beispiel wäre hier z.B. das SSL-Verifiy für eigene Entwicklungsregistries. Kann auch per Parameter
--registries.düberschrieben werden.
Arbeiten mit Skopeo
In den hier verwendeten Beispielen nutzen wir die aktuell unter CentOS 8 Streams verfügbare Version 1.5.0.
Inspizieren eines Images
Mittels skopeo inspect können die Details zu einem Image bzw. dem Repository eingesehen werden ohne sich die Daten vorher herunterladen zu müssen. Es werden unter anderem alle verfügbaren Tags des Repositorys sowie verschiedene Details zum angefragten Image beziehungsweise Image-Tag.
Es werden hierbei noch verschiedene Parameter angeboten um bestimmte Details anzufragen oder die Ausgabe anzupassen.
Folgend ein paar Beispiele:
--config– Liefert mehr Details zum eigentlichen Image das angefragt wird. So werden zum Beispiel angelegte Volumes, Ports usw. direkt ersichtlich.--creds– Übergabe von Logindaten (username:password) der Zielregistry--tls-verify– Gibt an ob das SSL Zertifikat der Registry validiert werden soll oder nicht (Boolean)--no-tags– Unterbindet die Ausgabe aller Tags des angefragten Images
Alle Optionen für inspect sowie diverse Beispiele finden sich in der Dokumentation.
Hierzu ein Beispiel für ein generisches skopeo inspect:
$ skopeo inspect docker://docker.io/library/postgres:latest
{
"Name": "docker.io/library/postgres",
"Digest": "sha256:f91f537eb66b6f80217bb6921cd3dd4035b81a5bd1291e02cfa17ed55b7b9d28",
"RepoTags": [
"10",
...
"bullseye",
"buster",
"latest"
],
"Created": "2022-01-04T01:19:59.244463885Z",
"DockerVersion": "20.10.7",
"Labels": null,
"Architecture": "amd64",
"Os": "linux",
"Layers": [
"sha256:a2abf6c4d29d43a4bf9fbb769f524d0fb36a2edab49819c1bf3e76f409f953ea",
...
],
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/lib/postgresql/14/bin",
"GOSU_VERSION=1.14",
"LANG=en_US.utf8",
"PG_MAJOR=14",
"PG_VERSION=14.1-1.pgdg110+1",
"PGDATA=/var/lib/postgresql/data"
]
}
Und ein Bespiel für ein skopeo inspect --config:
$ skopeo inspect --config docker://docker.io/library/postgres:latest
{
"created": "2022-01-04T01:19:59.244463885Z",
"architecture": "amd64",
"os": "linux",
"config": {
"ExposedPorts": {
"5432/tcp": {}
},
"Env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/lib/postgresql/14/bin",
"GOSU_VERSION=1.14",
"LANG=en_US.utf8",
"PG_MAJOR=14",
"PG_VERSION=14.1-1.pgdg110+1",
"PGDATA=/var/lib/postgresql/data"
],
"Entrypoint": [
"docker-entrypoint.sh"
],
"Cmd": [
"postgres"
],
"Volumes": {
"/var/lib/postgresql/data": {}
},
"StopSignal": "SIGINT"
},
"rootfs": {
"type": "layers",
"diff_ids": [
"sha256:2edcec3590a4ec7f40cf0743c15d78fb39d8326bc029073b41ef9727da6c851f",
...
]
},
"history": [
{
"created": "2021-12-21T01:22:43.418913408Z",
"created_by": "/bin/sh -c #(nop) ADD file:09675d11695f65c55efdc393ff0cd32f30194cd7d0fbef4631eebfed4414ac97 in / "
},
...
{
"created": "2022-01-04T01:19:59.244463885Z",
"created_by": "/bin/sh -c #(nop) CMD [\"postgres\"]",
"empty_layer": true
}
]
}
Um eine dedizierte Liste aller im Repository verfügbaren Image-Tags zu bekommen eignet sich der Befehl skopeo list-tags. Skopeo braucht nur die URL zum Repository, zum Beispiel docker://docker.io/library/postgres, und kann so die ganze Liste aller Image-Tags auslesen und verfügbar machen.
Die Dokumentation ist selbst-erklärend und fällt entsprechend kompakt aus.
Kopieren von Images
Mittels skopeo copy können Images entweder zwischen verschiedenen Registries kopiert werden, oder auch zum Beispiel von einer Registry in ein lokales Verzeichnis.
Hierbei stehen vielfältige Parameter zur Verfügung, wobei hier wieder nur ein paar Beispiele genannt werden sollen:
--additional-tag– Versieht das Image in der Ziel-Registry mit zusätzlichen Tags--all– Kopiert alle Architektur-Versionen des Images. Nicht nur das zur aktuellen Architektur passende.--sign-by– Signiert das Image in der Ziel-Registry mit einem angegebenen Schlüssel--dest-compress-format– Bestimmt die Kompressionsmethode für das Zielimage. Auch das Level ist als Parameter verfügbar--encryption-key– Gibt Protokoll und Key für eine Verschlüsselung der Layer in der Ziel-Registry an
Hierbei kann es natürlich nötig sein Login-Informationen anzugeben. Details dazu werden weiter unten beschrieben.
Generelle Dokumentation zu den Copy-Möglichkeiten findet sich in der Dokumentation.
Löschen von Images
Mit Skopeo ist es ebenfalls möglich Images einer Registry remote als “gelöscht” zu markieren. Hierbei ist zu beachten, dass das Image erst dann tatsächlich im Dateisystem entfernt wird, wenn die Löschroutine / Garbage-Collection des Registry ihren Lauf hatte. Neben der Authentifizierung sind hier keine weiteren Optionen möglich.
Alle Informationen finden sich inkl. Beispielen in der offiziellen Dokumentation.
Synchronisieren von Images
Skopeo bietet die Möglichkeit alle Images eines Repositories entweder mit einem anderen Repository oder einem lokalen Ordner zu synchronisieren. Hierbei werden alle Images des Quellpfades in den Zielpfad übernommen.
Anwendung findet diese Synchronisierungsmöglichkeit zum Beispiel bei lokalen Entwicklungsumgebung deren Images in einem Repository liegen und dort automatisch synchronisiert werden können. Auch der umgekehrte Weg, die Synchronisierung aller Images aus einem internen Repository auf eine lokale Umgebung ist hiermit einfach umzusetzen.
Es ist sogar möglich als Quelle eine yaml-Datei anzugeben in welcher als Liste verschiedene Images aus verschiedenen Repositories hinterlegt sind und diese dann einmal auf einen bestimmten Host oder eine andere Registry zu kopieren. Hierbei ist zu beachten, dass in der YAML-Version keine lokalen Pfade als Quelle erlaubt sind. Natürlich können in der yaml-Datei auch verschiedene zusätzliche Parameter wie zum Beispiel Logindaten hinterlegt werden.
Eine volle Übersicht der Parameter und verschiedene Beispiele finden sich wie gewohnt in der Dokumentation.
Authentifizierung
In fast allen Fällen ist es möglich die Parameter für die Authentifizierung direkt im skopeo-Aufruf mit anzugeben.
Bei Befehlen welche Quelle und Ziel beinhalten gibt es die Möglichkeit für --src-creds sowie --dest-creds. Beim Arbeiten an einer einzelnen Registry wird meist nur --creds genutzt. Gleichermaßen gibt es auch diverse Einzelparameter für username und password.
Alternativ kann ein Login auch mittels skopeo login manuell gestartet werden. Dieser Aufruf erfragt die Logindaten interaktiv und erstellt ein Auth-file (Im Standard ${XDG_RUNTIME_DIR}/containers/auth.json), welches dann ebenfalls als Parameter an die einzelnen Skopeo-Aufrufe weitergereicht werden kann. So müssen Authentifizierungsdaten nicht zwangsläufig im Code selbst hinterlegt werden sondern können, angepasst an die Vorliebe des Nutzers, interaktiv erfragt werden. Diese Auth-Datei teilt sich Skopeo auch mit Podman und Buildah und reiht sich damit nahtlos in die Sammlung von RedHat-Container Tools ein.
Um Datensätze wieder zu entfernen kann skopeo logout genutzt werden.
Fazit
Skopeo ist eine sinnvolle Ergänzung zu den beiden anderen Container-Tools und bietet einige Features bei denen sich der Autor schon länger fragt warum diese nicht auch an andere Stelle zur Verfügung stehen.
Besonders die inspect und copy Funktionen von Skopeo können viele verschiedene andere Schritte und auch eine Menge Zeit einsparen wenn man viel mit verschiedenen Repositories arbeitet. Allein sich die verschiedenen Tags eines Images und deren Details anzuschauen ist durchaus eine große Hilfe in der alltäglichen Arbeit und erspart diverse Suchanfragen und Recherchen über UIs.
Auch das einfache Kopieren eines Images von einer Registry (z.B. Docker-Hub) in eine interne Registry ist gerade nach den Limitierung von Dockerhub eine willkommene Funktion, auch wenn die nach und nach Einzug haltende Funktion des Cache-Proxies bei einigen Registries wie zum Beispiel Harbor dies auch ablösen kann.
Wir unterstützen Sie gerne
Mit über 22+ Jahren an Entwicklungs- und Dienstleistungserfahrung im Open Source Bereich, kann die credativ GmbH Sie mit einem beispiellosen und individuell konfigurierbaren Support professionell Begleiten und Sie in allen Fragen bei Ihrer Open Source Infrastruktur voll und ganz unterstützen.
Die credativ GmbH ist ein herstellerunabhängiges Beratungs- und Dienstleistungs- unternehmen mit Standort in Mönchengladbach.
Wer sich mit Containern und deren Orchestrierung für verteilte, skalierbare und hochverfügbare Anwendungen beschäftigt, wird wohl unweigerlich früher oder später auf Kubernetes stoßen. Es gibt genug Gründe, Container und Kubernetes dem traditionelleren Deployment auf virtuellen Maschinen vorzuziehen. Beispielsweise lassen sich verfügbare Hardware-Ressourcen flexibler an die laufenden Anwendungen verteilen.
Doch durch diese Flexibilität ergeben sich leider auch einige Fallstricke, die man beachten sollte. Aus diesem Grund möchte ich mit diesem Artikel einen Überblick bieten, welche Mittel Kubernetes für die Verwaltung von Hardware-Ressourcen bietet und wie Ihr sie einsetzen könnt.
Test-Setup
Für Demonstrationen werde ich einen Kubernetes-Cluster mit einer Control-Plane-Node und zwei Workern auf Basis von Kubernetes 1.18.6. verwenden Wenn Ihr beim Lesen die Beispiele mit nachvollziehen möchtet, solltet Ihr ebenfalls einen Cluster mit mindestens zwei Worker-Nodes zum Testen verwenden. Ein Cluster mit nur einer Node (wie z.B. mit Minikube) reicht nicht aus, weil damit das verschieben von Pods zwischen Nodes nicht nachvollzogen werden kann.
Solltet ihr gerade keinen Kubernetes-Cluster zum Testen zur Hand haben, empfehle ich kubeadm zu verwenden, um einen Cluster mit mehreren Nodes zu installieren. Die in diesem Artikel verwendeten Beispielwerte gehen dabei von Nodes mit jeweils 4GiB Arbeitsspeicher aus.
Kubernetes‘ Standard-Ressourcenverwaltung
Im späteren Verlauf möchte ich darauf eingehen, welche Stellschrauben Kubernetes im Bezug auf Ressourcenmanagement bietet. Zunächst möchte ich jedoch zeigen, wie Kubernetes die Ressourcen ohne weitere Einstellungen verwaltet und welche Probleme dabei auftreten können. Dazu erzeugen wir zunächst einen Prozess, der eine bestimmtem Menge Speicherplatz benötigt, die von einer Node bereitgestellt werden kann.:
$ kubectl label node knode1 load-target=
$ kubectl apply -f - << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress
spec:
replicas: 1
selector:
matchLabels:
app: stress
template:
metadata:
labels:
app: stress
spec:
containers:
- name: stress
image: alexeiled/stress-ng
args:
- --vm=1
- --vm-bytes=2g
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: load-target
operator: Exists
EOF
deployment.apps/stress createdDer gestartete Container, führt das Tool stress-ng aus. Mit den gegebenen Argumenten startet es einen Prozess, der daraufhin 2GiB Arbeitsspeicher alloziert und darauf schreibt. Mithilfe von Node-Affinities sorgen wir dafür, dass der Pod auf knode1 gestartet wird. Dort können wir die verursachte Last auch mit htop beobachten:
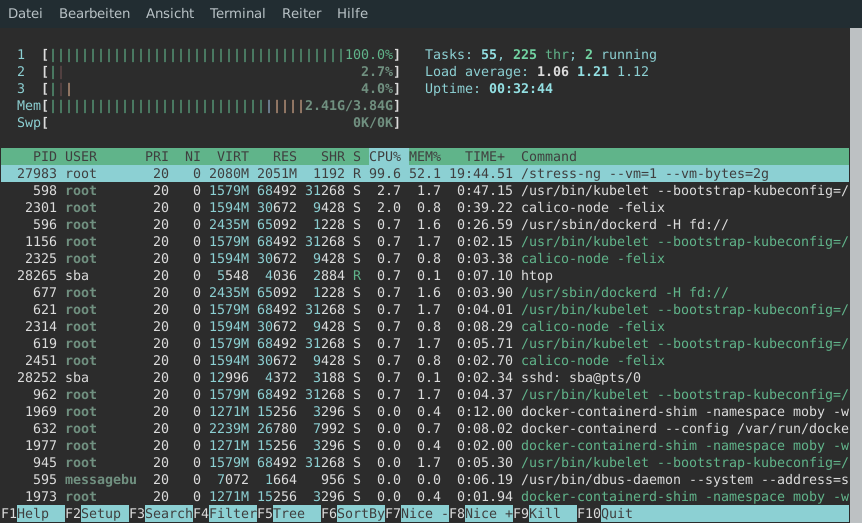
Die Node kann mit der verursachten Last derzeit noch ohne Probleme mithalten. Um zu sehen, was passiert wenn eine Node überlastet wird, müssen wir einen zweiten Pod erzeugen. Dazu erhöhen wir die Anzahl der Replicas des eben erstellten Deployments. Die Platzierung des zweiten Replicas ist dabei hauptsächlich dem Zufall überlassen. Wir wollen allerdings den Worst-Case betrachten, in dem beide Replicas auf der gleichen Node gestartet werden. Das erzwingen wir mithilfe der vorher schon erstellten Node-Affinities:
$ kubectl patch deployment stress -p '{"spec": {"replicas": 2}}'
deployment.apps/stress patchedWenn wir uns nun die Lastsituation auf knode1 erneut anschauen, hat sich die Situation im Gegensatz zu vorher geändert. Der Speicherverbrauch schwankt drastisch und wenn wir mit dmesg | tail in das Kernel-Log schauen, sehen wir wiederholt Nachrichten der folgenden Art:
[ 3248.919030] Out of memory: Killed process 105727 (stress-ng-vm) total-vm:3179200kB, anon-rss:2312000kB, file-rss:0kB, shmem-rss:44kB, UID:0 pgtables:4592kB oom_score_adj:1000 [ 3248.951392] oom_reaper: reaped process 105727 (stress-ng-vm), now anon-rss:0kB, file-rss:0kB, shmem-rss:44kB
Das liegt daran, dass die beiden Pods zusammen mehr Speicher belegen wollen, als auf der Node zur Verfügung steht. Der Kernel versucht Speicher freizugeben, indem er Prozesse tötet (SIGKILL). Für eine laufende Applikation wäre dieser Zustand nicht akzeptabel, weil Prozesse der Applikation im laufenden Betrieb getötet werden, was die Verfügbarkeit und Stabilität der Applikation beeinflusst. Bisher können wir allerdings auch kein anderes Ergebnis erwarten, weil wir per Node-Affinity explizit angegeben haben, dass beide Replicas auf knode1 ausgeführt werden sollen. Wenn wir knode2 ebenfalls für die Ausführung der Replicas freigeben, wäre zu erwarten, dass einer der Pods evicted wird. Damit ist gemeint, dass der Pod von seiner derzeitigen Node entfernt wird um Ressourcen zu sparen. Das erstellte Deployment wäre dann dafür verantwortlich, den Pod auf einer anderen Node neu zu erstellen. Probieren wir das also aus:
$ kubectl label node knode2 load-target= node/knode2 labeled
Überprüfen wir nun, wo die beiden Pods ausgeführt werden:
$ kubectl describe pod -l app=stress | grep '^Node:' Node: knode1/192.168.122.228 Node: knode1/192.168.122.228
Wie wir sehen, werden beide Pods weiterhin auf knode1 ausgeführt. Auch wenn wir die Situation länger beobachten, werden wir feststellen, dass Kubernetes keinen der Pods evicten wird. Stattdessen wird es die darin laufenden Prozesse weiterhin auf der überlasteten Node laufen lassen wird. Warum Kubernetes hier nicht einschreitet und was wir dagegen tun können, behandle ich im nächsten Abschnitt. Doch zunächst entfernen wir noch das erstellte Deployment und das Label von knode2 um den Basisstand für die nächsten Test wiederherzustellen:
$ kubectl label node knode2 load-target- node/knode2 labeled $ kubectl delete deployment stress deployment.apps "stress" deleted
Ressourcenverwaltung im Kubelet
Grundsätzlich sollte Kubernetes in einer solchen Situation reagieren. Wenn ein Kubelet (die Software die für die Ausführung von Pods auf den Nodes zuständig ist) meldet, dass die Ressourcen auf der Node knapp werden, sollte Kubernetes einen oder mehrere Pods von dieser Node „evicten“ und auf einer anderen Node neu starten. Das ist in unserem Test allerdings nicht passiert. Um herauszufinden wieso, schauen wir uns zunächst mit kubectl describe node knode1 die Informationen zu der Node an. Dabei erhalten wir unter Anderem eine Menge Informationen, die für die Ressourcenverwaltung relevant sind:
Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 250m (8%) 0 (0%) memory 0 (0%) 0 (0%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%)
Diese Tabelle sieht erst mal so aus, als ob sie den Ressourcenverbrauch auf der Node anzeigt. Sie zeigt allerdings nur Ressourcen auf der Node, die für bestimmtem Pods reserviert wurden und gibt uns deshalb keinen Aufschluss darüber, wie viele Ressourcen tatsächlich gerade verbraucht werden.
Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- MemoryPressure False Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Fri, 24 Jul 2020 13:57:18 +0000 Fri, 24 Jul 2020 13:57:18 +0000 KubeletReady kubelet is posting ready status. AppArmor enabled
Hier sehen wir, dass das kubelet der Meinung ist, es hätte genug Speicherplatz zur Verfügung. Das ist zwar unerwartet, erklärt aber warum Kubernetes nichts gegen die zu hohe Last unternommen hat. Solange das Kubelet nicht meldet, dass die Ressourcen knapp werden, sieht Kubernetes keinen Grund etwas an der Ressourcenverteilung zu ändern.
Warum das Kubelet keine Speicherknappheit meldet hängt mit dem folgenden Block zusammen:
Capacity: cpu: 3 ephemeral-storage: 20480580Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 4030888Ki pods: 110 Allocatable: cpu: 3 ephemeral-storage: 18874902497 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 3928488Ki pods: 110
Die Capacity zeigt uns an, wie viele Ressourcen eine Node insgesamt zur Verfügung hat. Der angezeigt Wert von memory: 4030888Ki entspricht dabei genau dem auf der Hardware verfügbaren Arbeitsspeicher. In Allocatable steht hingegen der Speicher, den die Node auch gestarteten Pods zur Verfügung stellt. Solange alle gestarteten Pods weniger als diese Menge an Speicher verbrauchen, ist für das Kubelet alles im grünen Bereich.
Dass das Kubelet in unserem Fall keinen Alarm wegen fehlendem Speicher schlägt, liegt daran, dass das Betriebssystem und das Kubelet selbst Speicherplatz verbrauchen, der dann für die Pods nicht zur Verfügung steht. Dadurch ist es für die gestarteten Pods praktisch gar nicht möglich die gesetzte Grenze zu überschreiten. Als Beispiel: Wenn unser Betriebssystem und das Kubelet zusammen ca. 300MiB belegen, bleiben vom verfügbaren Speicher noch ca. 3600MiB übrig. Wenn nun Pods gestartet werden und diese übrigen 3600MiB belegen, ist der physische Speicher voll. Unsere Pods bleiben aber unter dem gesetzen Limit von 3928488KiB (ca. 3836MiB) und unser Kubelet ist der Meinung es wäre genug Speicher vorhanden.
Die in Allocatable gesetzte Grenze ist also zu hoch gesetzt. Um das zu beheben, bietet das Kubelet die Möglichkeit, Speicher für das Betriebssystem und das Kubelet selbst zu reservieren und dadurch die Allocatable-Grenze für Pods zu verringern. Die entsprechenden Optionen dafür müssen in der Konfigurationsdatei des Kubelet gesetzt werden. Wenn ihr euren Cluster mit kubeadm installiert habt, befindet sich die Konfigurationsdatei auf der Node unter /var/lib/kubelet/config.yaml. Auf beiden Nodes müssen dort die folgenden Optionen eingefügt werden:
systemReserved: memory: 256Mi kubeReserved: memory: 256Mi evictionHard: memory.available: 128Mi evictionSoft: memory.available: 256Mi evictionSoftGracePeriod: memory.available: 5m
Damit Teilen wir dem Kubelet mehrere Dinge mit:
systemReservedsagt, dass für das System 256MiB Arbeitsspeicher reserviert werden sollen.kubeReservedsagt, dass für das Kubelet 256MiB Arbeitsspeicher reserviert werden sollen.evictionHardsagt, dass sobald für Pods weniger als 128MiB verbleiben, sofort Pods evicted werden sollen.evictionSoftundevictionSoftGracePeriodsagen, dass wenn länger als 5 Minuten für Pods weniger als 256MiB verfügbar sind Pods evicted werden sollen.
Mit diesen Werten sollte das Kubelet früh genug Alarm schlagen, wenn der Speicher knapp wird, um zu verhindern, dass unsere Node vollständig überlastet wird. Um die Optionen zu übernehmen, muss die entsprechende Node komplett rebootet werden. Normalerweise reicht ein Neustart des Kubelets aus, um Änderungen in der Konfiguration zu übernehmen. Bei Änderungen an Ressourcen-Limits muss das Kubelet allerdings Änderungen an bestehenden CGroups vornehmen, was nicht immer möglich ist. Ein Neustart garantiert deswegen schneller, dass die gesetzten Limits tatsächlich effektiv sind. Den Effekt können wir in den Node-Informationen bobachten:
$ kubectl describe node knode1 Capacity: [...] memory: 4030896Ki [...] Allocatable: [...] memory: 3375536Ki [...]
Hier sehen wir nun, dass der für Pods verfügbare Arbeitsspeicher weiter verringert wurde. Er ist nun exakt 768MiB geringer, als der Verfügbare Speicherplatz. Diese Zahl ergibt sich aus der Summe des für das System und Kubelet reservierten Speicherplatzes und der Soft-Eviction-Threshold.
Nun können wir nochmal testen, ob unsere Pods bei Ressourcenknappheit korrekt evicted werden. Dazu erstellen wir erneut ein Deployment um Last zu erzeugen:
$ kubectl apply -f - << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress
spec:
replicas: 2
selector:
matchLabels:
app: stress
template:
metadata:
labels:
app: stress
spec:
containers:
- name: stress
image: alexeiled/stress-ng
args:
- --vm=1
- --vm-bytes=2g
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: load-target
operator: Exists
EOF
deployment.apps/stress createdWenn wir nun die gestarteten Pods betrachten, werden wir nach einer Weile sehen, dass einer der Pods evicted wurde:
$ kubectl get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES stress-7c4bb6fdbd-nrm5d 1/1 Running 0 9s fd49:7f8a:1714:14fc:6f39:9d7d:8f25:721a knode2 <none> <none> stress-7c4bb6fdbd-nw6lk 1/1 Running 0 119s fd49:7f8a:1714:14fc:7dc6:67af:9a64:c3ac knode1 <none> <none> stress-7c4bb6fdbd-z8p6c 0/1 Evicted 0 119s <none> knode1 <none> <none>
Als Ersatz für den Pod, der evicted wurde, wurde ein neuer erstellt, der nach einer Weile auf einer Node neu gestartet werden soll. Dabei kann es vorkommen, dass der Pod auf der Node neu gestartet wird, von der er gerade evicted worden ist. Das führt dann dazu, dass der Pod direkt im Anschluss wieder evicted wird. Das liegt daran, dass Kubernetes bei der Zuordnung der Pods zu den Nodes weiterhin zufällig vorgeht, weil es vor der Ausführung eines Pods nicht abschätzen kann, wieviele Ressourcen der Pod zur Laufzeit benötigen werden. Solange insgesamt genug Ressourcen vorhanden sind, sollte jedoch jeder Pod früher oder später eine Node finden, auf der er genug Ressourcen bekommt.
Ressourcen für Pods und Container verwalten
Nun wissen wir, wie wir unsere Pods vor der vollkommenen Überladung schützen. Wie wir gesehen haben, werden Pods von Nodes, die zu wenige Ressourcen haben, auch einfach wieder evicted. Dadurch wird der Pod beendet und womöglich erst zeitverzögert wieder gestartet. Wenn der Pod dabei eigentlich einen kritischen Service ausführen sollte, wäre dieser Ausfall sehr unerwünscht. Für diesen Fall bietet Kubernetes allerdings auch an, Ressourcen für Pods fest zu reservieren. Analog dazu kann man den Ressourcenverbrauch bestimmter Pods auch auf eine Maximum begrenzen. Um das zu demonstrieren, legen wir das folgende Deployment an:
apiVersion: apps/v1
kind: Deployment
metadata:
name: stress
spec:
replicas: 3
selector:
matchLabels:
app: stress
template:
metadata:
labels:
app: stress
spec:
containers:
- name: stress
image: alexeiled/stress-ng
args:
- --vm=1
- --vm-bytes=2g
resources:
requests:
memory: 3G
limits:
memory: 3.5G
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: load-target
operator: ExistsDie in resources festgelegten Ressourcen werden fest für den Container reserviert. Wir können uns also sicher sein, dass sie immer zur Verfügung stehen. Die in limit definierten Ressourcen sind eine harte Grenze für den Container, die nicht überschritten werden darf. Durch die Angabe dieser Werte stellen wir einerseits sicher, dass unser Pod die in requests angegeben Ressourcen immer zur Verfügung hat. Andererseits helfen wir auch Kubernetes, eine Node auszuwählen, die die benötigten Ressourcen auch bereitstellen kann. Nachdem wir das Deployment angelegt haben erscheinen die folgenden Pods:
$ kubectl get pod NAME READY STATUS RESTARTS AGE stress-8485c6dd5d-58m4s 1/1 Running 0 3m56s stress-8485c6dd5d-bznmn 0/1 Pending 0 3m56s stress-8485c6dd5d-jddd7 1/1 Running 0 3m56s
Wie wir sehen, sind zwei der Pods Running, während einer immer noch Pending ist. Wenn wir uns den Pod genau ansehen, sehen wir auch warum:
$ kubectl describe pod stress-8485c6dd5d-bznmn
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 Insufficient memory.Wie wir sehen, wird der Pod nicht scheduled, weil es keine Node gibt, die den nötigen Speicherplatz zur Verfügung stellen könnte.
Ressourcen die per request zugesichert wurden, stehen dem Container, der sie angefragt hat immer zur Verfügung. Während wir die angefragten Ressourcen verwenden, kann ein anderer Container sie zwar „borgen“. Wenn der Container, der die Ressourcen reserviert hat, die Ressourcen aber selber braucht, werden sie ihm immer zur Verfügung gestellt. Notfalls werden die Pods, die die Ressourcen geborgt haben, dafür auch evicted.
Was passiert, wenn ein Container versucht, das Limit einer Ressource zu überschreiten, hängt von der Ressource ab. Für Speicher-Limits werden ggf. Prozesse im Container getötet, bis das Limit wieder eingehalten wird. CPU-Limits werden durchgesetzt, indem Prozesse die am Limit sind, gedrosselt werden und entsprechend weniger Zeit auf der CPU erhalten.
Das setzen von Memory-Limits und -Requests beeinflusst ebenfalls die Priorität mit der Pods von Nodes evicted werden, wenn die Ressourcen knapp werden. Pods werden dabei in drei unterschiedliche Klassen unterteilt. Diese Klasse kann mit kubectl describe pod <pod> im Feld „QoS Class“ eingesehen werden. Die jeweilige Klasse leitet sich aus der Kombination an Ressourcen-Requests und -Limits nach den folgenden Regeln ab:
- Best Effort: Gilt für Pods deren Container keine Ressourcen-Anfragen haben. Sie werden als erstes evicted.
- Burstable: Gilt für Pods deren Container mindestens eine Ressourcen-Anfrage haben. Sie werden evicted, sobald es keine Pods mit der Klasse Best Effort mehr gibt. Dabei werden zuerst die Pods evicted, die ihre Resource-Requests am weitesten überschreiten
- Guaranteed: Gilt für Pods in denen alle Container Limits für sowohl CPU als auch Memory gesetzt haben. Die Requests und Limits müssen dabei jeweils genau gleich sein. Diese Pods werden nur evicted, wenn es keine andere Wahl gibt.
Fazit
Auch wenn die Standard-Einstellungen zunächst zu nicht ganz so dynamischen Ergebnissen führen, bietet Kubernetes doch eine Reihe von Möglichkeiten mit denen sich sehr flexible Ressourcenzuteilungen realisieren lassen. Von Pods, die vollständig flexibel Ressourcen zugeteilt bekommen, bis zu Pods, die ein strikt definiertes Kontingent an Ressourcen zur Verfügung haben, ist vieles möglich.
In diesem Artikel habe ich für Beispiele nur die Verwaltung von Arbeitsspeicher beachtet. Natürlich lassen sich analog dazu noch weitere Hardware-Ressourcen verwalten. Welche Ressourcen das sind und wie sie gemessen werden, kann man in der Kubernetes-Dokumentation nachlesen.
Bei Fragen rund um den Einsatz von Kubernetes stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an!
Seit einiger Zeit spricht ein Großteil der IT-Landschaft nur noch nur von „Containern“, „Microservices“ und „Kubernetes“.
Doch was sind Container eigentlich und auf welcher technischen Grundlage bauen sie auf?
Allgemeines
Ein Container ist, einfach erklärt, eine abgekapselte Laufzeitumgebung für Prozesse. Es gibt verschiedene Bereiche, die getrennt werden können – die wichtigsten dabei sind Prozesse (pid), Netzwerk (net), Volumes / Festplatten (mnt) und User / Gruppen-IDs (user).
Die Technologie dahinter nennt sich „Namespaces“ und ist im Linux Kernel seit Version 2.4.19 (2002) erstmals implementiert und später erweitert, jedoch erst seit der Version 3.8 (2013) im Userspace, also für die Nutzer sinnvoll nutzbar. Zusätzlich spielt hier die cgroups-Technologie eine große Rolle. Diese ermöglicht es den getrennten Bereichen Ressourcen wie CPU und RAM zur Verfügung zu stellen, bzw. diese zu definieren.
Eine bekannte und frühe Implementierung dieser Features ist lxc (linux containers) welche auch heute noch weiterentwickelt wird und diese Features systemnah umsetzt.
Linux Namespaces
Ein Namespace ist eine Möglichkeit, Ressourcen und Objekte in logische Gruppen zu unterteilen. Man könnte es auch als System-Kontext beschreiben in dem ein Prozess gestartet wird. Dabei ist es kein Problem innerhalb eines Namespaces eigene Namespaces für neu gestartete Prozesse zu erstellen.
Ein Beispiel aus der täglichen Praxis:
Wenn ein Linux Host startet, dann wird je Namespace-Typ eine Instanz erstellt. Der Init-Prozess mit der PID 1 (heute meist systemd) wird dann entsprechend den Instanzen zugeteilt. Dies ist soweit transparent und für die meisten Nutzer auch nur begrenzt relevant. Denn diesen Namespaces stehen alle Ressourcen des Systems zur Verfügung und auch neue Ressourcen werden diesem initial zugeordnet.
Um sich eine Liste der aktuell auf dem System laufenden Namespaces anzusehen gibt es das Tool lsns.
Im folgenden Beispiel sehen wir die initial erstellen Namespaces und die Zuweisung des init-Prozesses.
[root@buildah ~]# lsns -p1
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531836 pid 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531837 user 95 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531838 uts 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531839 ipc 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531840 mnt 90 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
4026531992 net 96 1 root /usr/lib/systemd/systemd --switched-root --system --deserialize 18
Ein Prozess kann immer nur einem Namespace pro Typ zugewiesen sein. So kann dem Prozess mit der PID 1 aus dem obigen Beispiel kein zusätzlicher pid-Namespace zugewiesen werden.
Die verschiedenen Typen haben untereinander keine Wechselwirkungen oder Abhängigkeiten. So kann man einem neuen Prozess (z.B. einer Shell) auch nur einen eigenen net-namespace zuordnen.
Um als Nutzer einen neuen Namespace zu erstellen, gibt es das Tool unshare. Mittels Parameter ist es hier möglich festzulegen, welche Namespacetypen für den Prozess erstellt werden sollen.
Folgend ein Beispiel wie eine Container-ähnliche Umgebung (in der alle möglichen Bereiche vom Hostsystem separiert werden) manuell erstellt werden kann.
Dazu starten wir mit einem normalen Nutzer ohne root-Berechtigungen eine Bash-Shell mit den gezeigten Parametern.
[podmanager@buildah ~]$ unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
[root@buildah ~]# id
uid=0(root) gid=0(root) Gruppen=0(root) Kontext=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
[root@buildah ~]# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
[root@buildah ~]# lsns
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026531836 pid 1 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532192 user 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532193 mnt 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532194 uts 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532196 ipc 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
4026532198 pid 2 953 root /bin/bash
4026532200 net 3 952 root unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
Wie zu sehen ist, befindet sich der Prozess nun in einem gekapselten Bereich mit eigenen IDs und Netzwerkbereich. Es wurde jedoch die gesamte Festplattenkonfiguration mit in den neuen Bereich übernommen, und somit auch der Ordner /proc, in dem die Prozesse des Hostsystems aufgelistet sind.
[root@buildah ~]# ps -ef f | head
UID PID PPID C STIME TTY STAT TIME CMD
nobody 2 0 0 14:22 ? S 0:00 [kthreadd]
nobody 3 2 0 14:22 ? I< 0:00 \_ [rcu_gp]
nobody 4 2 0 14:22 ? I< 0:00 \_ [rcu_par_gp]
nobody 6 2 0 14:22 ? I< 0:00 \_ [kworker/0:0H-kblockd]
nobody 8 2 0 14:22 ? I< 0:00 \_ [mm_percpu_wq]
nobody 9 2 0 14:22 ? S 0:00 \_ [ksoftirqd/0]
nobody 10 2 0 14:22 ? I 0:00 \_ [rcu_sched]
nobody 11 2 0 14:22 ? S 0:00 \_ [migration/0]
nobody 12 2 0 14:22 ? S 0:00 \_ [watchdog/0]
Um dies noch zu berichtigen ist ein mount -t proc proc /proc nötig. Dieses überlagert das /proc des Host-Systems wodurch nun ausschließlich die Prozesse der neuen Umgebung sichtbar sind.
[root@buildah ~]# mount -t proc proc /proc
[root@buildah ~]# ps -ef f
UID PID PPID C STIME TTY STAT TIME CMD
root 1 0 0 15:05 pts/1 S 0:00 /bin/bash
root 27 1 0 15:11 pts/1 R+ 0:00 ps -ef f
Um die Umgebung zu verlassen genügt ein exit, oder die Tastenkombination STRG+D.
[root@buildah ~]# exit
exit
[podmanager@buildah ~]$
cgroups
Control Groups (kurz cgroups) sind kein direkter Namespace, sondern ermöglichen es Prozesse in einer Art Namespace zu gruppieren und die zur Verfügung stehenden Ressourcen wie CPU und / oder RAM zu begrenzen bzw. zu priorisieren.
Es gibt mittlerweile eine aktualisierte Version der cgroups (cgroupsV2) im Kernel. Jedoch wird diese produktiv wohl nur von Fedora >= 31 genutzt, da es hier einige Inkompatibilitäten mit Docker, jedoch nicht mit Podman gibt.
Die Einrichtung ist jedoch etwas komplexer und soll daher hier nicht erläutert werden, sondern wird Gegenstand eines eigenen Artikels.
Weiterführende Information dazu finden sich jedoch für Interessierte hier (cgroupsv1) und hier (cgroupsv2)
Das Dateisystem eines Containers
Jeder Container beinhaltet alle für den Betrieb der Binaries notwendigen Komponenten, wie Bibliotheken und Binaries.
Die einzige Abhängigkeit zum Hostsystem besteht im Allgemeinen darin, dass die Applikationen auf dem Kernel des Hostsystems lauffähig sein müssen.
Das Dateisystem ist dabei jedoch keine separate Festplatte oder ähnliches, sondern lediglich ein Archiv, das einen Verzeichnisbaum enthält.
Dieses Archiv wird dann spätestens beim Start eines Containers in einen Ordner entpackt und mittels eines mnt-Namespaces und chroot auf diesen Ordner als neues Dateisystem genutzt. Das chroot ändert dabei den Einstiegspunkt für das Dateisystem auf das der Nutzer Zugriff hat. So wird z.B. /var/lib/docker/container1/dateisystem auf dem Host zum neuen / innerhalb des Containers.
Auch dazu ein Beispiel mit der separierten Umgebung aus dem vorherigen Abschnitt.
Zuerst exportieren wir das Dateisystem des Postgres-Containers als tar-Archiv und entpacken es anschließend in einen Unterordner.
[podmanager@buildah ~]$ podman export 3b62694339c6 -o postgres_container.tar
[podmanager@buildah ~]$ ls -l postgres_container.tar
-rw-r--r--. 1 podmanager podmanager 313597440 31. Mär 15:31 postgres_container.tar
[podmanager@buildah ~]$ mkdir postgres_root
[podmanager@buildah ~]$ tar -xf postgres_container.tar -C postgres_root/
[podmanager@buildah ~]$ ls -l postgres_root/
insgesamt 12
drwxr-xr-x. 2 podmanager podmanager 4096 3. Mär 01:27 bin
drwxr-xr-x. 2 podmanager podmanager 6 1. Feb 18:09 boot
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 dev
drwxr-xr-x. 2 podmanager podmanager 6 3. Mär 01:27 docker-entrypoint-initdb.d
lrwxrwxrwx. 1 podmanager podmanager 34 4. Mär 18:35 docker-entrypoint.sh -> usr/local/bin/docker-entrypoint.sh
drwxr-xr-x. 37 podmanager podmanager 4096 31. Mär 14:24 etc
drwxr-xr-x. 2 podmanager podmanager 6 1. Feb 18:09 home
drwxr-xr-x. 8 podmanager podmanager 96 26. Feb 01:54 lib
drwxr-xr-x. 2 podmanager podmanager 34 24. Feb 01:00 lib64
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 media
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 mnt
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 opt
drwxr-xr-x. 2 podmanager podmanager 6 1. Feb 18:09 proc
drwx------. 2 podmanager podmanager 76 31. Mär 14:44 root
drwxr-xr-x. 5 podmanager podmanager 84 31. Mär 14:24 run
drwxr-xr-x. 2 podmanager podmanager 4096 3. Mär 01:27 sbin
drwxr-xr-x. 2 podmanager podmanager 6 24. Feb 01:00 srv
drwxr-xr-x. 2 podmanager podmanager 6 1. Feb 18:09 sys
drwxrwxr-x. 2 podmanager podmanager 6 3. Mär 01:27 tmp
drwxr-xr-x. 10 podmanager podmanager 105 24. Feb 01:00 usr
drwxr-xr-x. 11 podmanager podmanager 139 24. Feb 01:00 var
Nun erstellen wir wieder eine Shell mit eigenen Namespaces und führen das chroot aus.
[podmanager@buildah ~]$ unshare --mount --uts --ipc --net --pid --fork --user --map-root-user /bin/bash
[root@buildah ~]# cat /etc/redhat-release
CentOS Linux release 8.1.1911 (Core)
[root@buildah ~]# chroot postgres_root
root@buildah:/var/lib/postgresql/data# /bin/cat /etc/issue
Debian GNU/Linux 10 \n \l
Zum Abschluss muss noch das /proc-Dateisystem, wie erwähnt, berichtigt werden.
Ist dies erledigt, haben wir die gleiche Arbeitsumgebung die wir auch in einem Container hätten.
root@buildah:/var/lib/postgresql/data# /bin/mount -t proc proc /proc
root@buildah:/var/lib/postgresql/data# /bin/ps -ef f
UID PID PPID C STIME TTY STAT TIME CMD
root 1 0 0 13:34 ? S 0:00 /bin/bash
root 27 1 0 13:35 ? S 0:00 /bin/bash -i
root 54 27 0 13:43 ? R+ 0:00 \_ /bin/ps -ef f
Fazit
Dies ist natürlich nur ein schneller Überblick über das technische Gerüst der Containertechnologie, das auf bekannten Features des Linux-Kernels baut.
Docker und auch Podman nutzen diese Features, bieten jedoch sehr viel mehr Funktionen und vor allem Komfort-Funktionen im Handling dazu.
Spätestens bei der Nutzung von Containerorchestrierungswerkzeugen wie Kubernetes oder okd kommen ebenfalls einige Schichten an Komplexität hinzu.
Bei Fragen rund um den Einsatz von Containern stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an!
Was ist „GitOps“?
Der Begriff „GitOps“ wird verwendet, wenn zur Einrichtung und Wartung von Infrastruktur und Applikationen eines oder mehrere Code-Repositories (meist Git) als Grundlage dienen. In diesen werden z.B. die Kubernetes-Yamls verwaltet die auf dem einen oder anderen Weg in Kubernetes deployed werden sollen.
Ein anderes Beispiel wären Ansible-Playbooks (kubespray, ansible-ceph), die ebenfalls über ein Git-Repository versioniert werden können. So ist jederzeit ersichtlich, wer welche Änderung zu welchem Zeitpunkt durchgeführt hat. Alte Stände können somit ohne Aufwand wiederhergestellt werden.
Gerade im Kubernetes-Umfeld gibt es zu den Repositories häufig noch eine Pipeline, die die hinterlegten Daten verarbeitet und deployed.
Als Alternative bieten sich hier natürlich Operatoren direkt in Kubernetes an, die die Aufgaben einer separaten Pipeline übernehmen und speziell für die Wartung von Kubernetes-Deployments konzipiert sind. Hierzu zählen Lösungen wie z.B. Flux oder auch Argo CD.
Das Projekt
Flux (oder auch FluxCD) wird primär von Weaveworks (für das CNI-Plugin bekannt) entwickelt. Ursprünglich sollte Flux als Service-Routing-Tool für Container entwickelt werden, was jedoch recht schnell verworfen wurde.
Am 22.08.2017 wurde Flux in der Version 1.0 veröffentlicht. Seitdem werden im Abstand von 1-2 Monaten neue Versionen released. Der Quellcode ist wie üblich auf Github hinterlegt, die Website des Projekts findet sich unter https://fluxcd.io/.
Das Projekt besteht aus zwei Hauptkomponenten, dem fluxd-Daemon, der im Kubernetes-Cluster deployed wird, und dem fluxctl-CLI, die z.B. lokal verwendet werden kann, um den fluxd zu steuern bzw. Flux im Cluster zu installieren. Beide Komponenten sind in golang implementiert.
Funktionsweise
Dankenswerterweise stellt Flux ein übersichtliches Schaubild zur Verfügung, das die Abläufe illustriert:
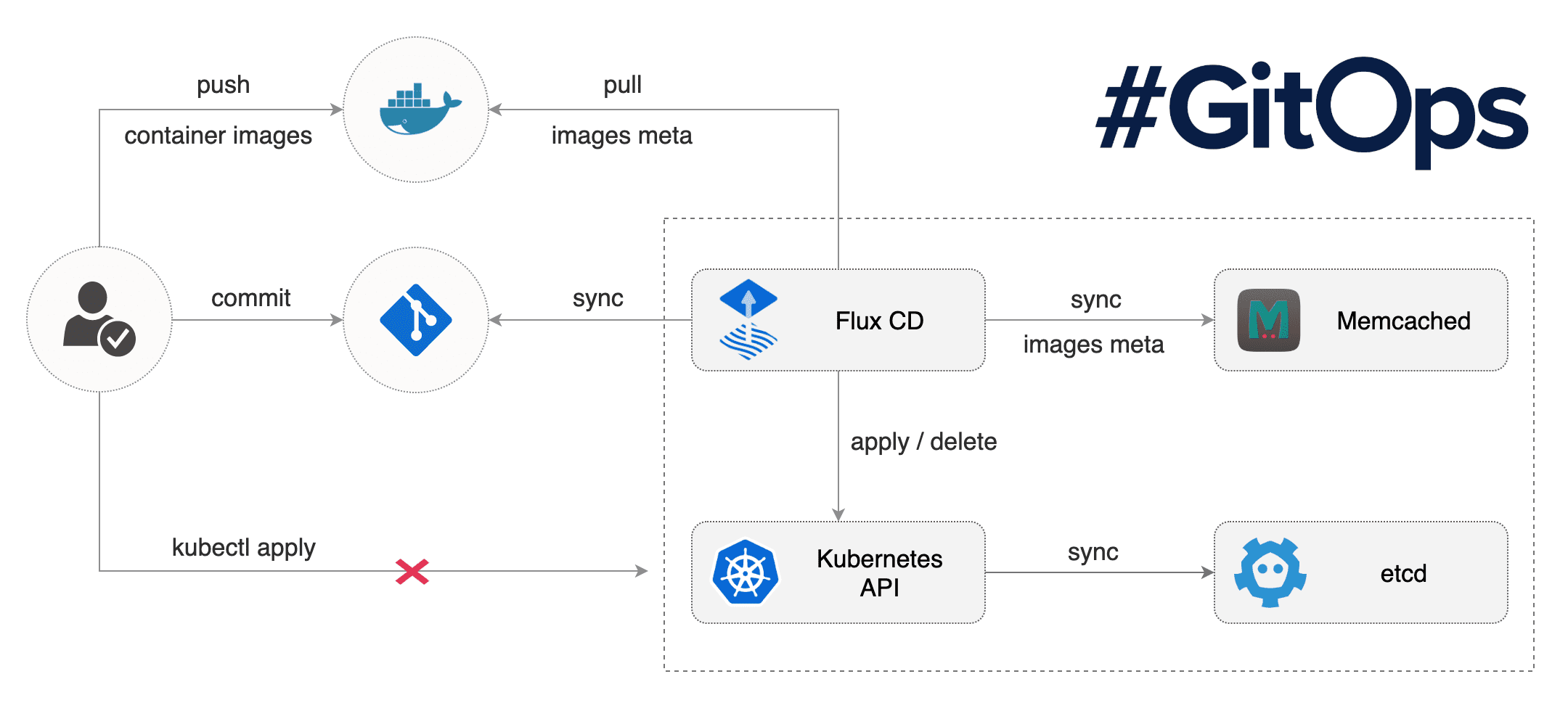
Via fluxctl wird der fluxd+memcache in einem Namespace im Cluster deployed und für ein Git-Repository konfiguriert. Dieses wird dann in regelmäßigen Abständen gepulled und die im Repository enthaltenen Yaml-Files im Cluster deployed.
Zusätzlich bietet Flux die Möglichkeit, automatisiert Images, die in Containern benutzt werden, zu aktualisieren sobald eine neue Version bereitsteht.
Die Details zu den einzelnen Funktionen folgen in einem späteren Abschnitt.
Installation
Die Installation von Flux ist in der Dokumentation entsprechend beschrieben. Vor der Installation sollte man sich jedoch die Einschränkungen genauer anschauen.
So kann Flux z.B. aktuell pro Instanz nur ein einzelnes Git-Repository nutzen. Ausserdem kann es im Vergleich zu den Hosts oder Kubernetes selbst, Unterschiede in der Möglichkeit der Namensauflösung geben, da Flux selbst in einem Container läuft. So können z.B. keine Image-Metadaten ausgelesen werden wenn eine private Registry genutzt wird die auf localhost lauscht.
Die genauen, einzelnen Schritte sollen hier nicht weiter ausgeführt werden, da diese bereits sehr ausführlich dokumentiert sind.
Wichtig: fluxctl benötigt für die Ausführung zwingend ein konfiguriertes kubectl auf dem Host, auf dem es ausgeführt wird. Da während der Installation neue RBACs für den Serviceaccount von fluxd angelegt werden, was entsprechend weitreichende Berechtigungen benötigt, empfiehlt es sich, diese mit cluster-admin Berechtigungen auszuführen. Es ist auch möglich fluxctl beim Aufruf den kubectl-Context mitzuteilen, welchen er nutzen soll, sollte dieser vom Standardcontext abweichen.
Folgend der Ablauf der Installation auf der Kommandozeile. Der Aufruf zur Installation von Flux wurde dabei der Einfachheit halber in ein kurzes Shellskript eingebettet:
#!/bin/bash
GITUSER=""
GITMAIL=""
GITURL=""
GITPATHS="namespaces,workloads"
FLUXNS="flux"
fluxctl install \
--git-user=${GITUSER} \
--git-email=${GITMAIL} \
--git-url=${GITURL} \
--git-path=${GITPATHS} \
--namespace=${FLUXNS} | kubectl apply -f -
$ kubectl create ns flux
namespace/flux created
$ ./install_flux.sh
deployment.apps/flux created
secret/flux-git-deploy created
deployment.apps/memcached created
service/memcached created
serviceaccount/flux created
clusterrole.rbac.authorization.k8s.io/flux created
clusterrolebinding.rbac.authorization.k8s.io/flux created
$ kubectl get all -n flux
NAME READY STATUS RESTARTS AGE
pod/flux-676dcdd787-tbqcw 1/1 Running 0 119s
pod/memcached-86bdf9f56b-8kj46 1/1 Running 0 119s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/memcached ClusterIP 10.106.85.32 <none> 11211/TCP 119s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/flux 1/1 1 1 119s
deployment.apps/memcached 1/1 1 1 119s
NAME DESIRED CURRENT READY AGE
replicaset.apps/flux-676dcdd787 1 1 1 119s
replicaset.apps/memcached-86bdf9f56b 1 1 1 119s
Da Flux sich im Standard mittels SSH am Git-Repository authentifiziert, muss der Public-Key von Flux noch hinterlegt werden.
Diesen kann man sich via fluxctl mit folgendem Befehl ausgeben lassen:
$ fluxctl identity --k8s-fwd-ns flux
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABgQDP3mVuuDYto+lhuxRbZFrAV0jurOgNwxzFnWxHVKP9EZpnUOK0FUPiiTnMvCQK1PrGSHmXoXEgQvx9UU+XgEStOvr3xlU2AjkvFwaH+2MbSrT0HEV/2Nib2YVyeM+4T65BY7E+pkqrSQg86Q3WN7x3d1peMJQI4BeMmsaddPI7dpvy+unxTe0cdS/D6IjH6em9pTKwaWx+h9kp8BpQBI+OTFoL6dEp+ITZi+bCkk43R9zVhw21SroutTvPuIgdDCIn178JgfsJanA9jAn7woGY8D1+cc6R9jlkcnOR5IVQdOl9CC2EQUgvdZu3cyeW5xZvUwxY+10apZrV9tzHyRA9vqyobHn3sixJc8g3fD8ppVe2xBz9aFFUTEKJJbpNnVyhDXx4Q+nUEUVa17sGjUj05Q3UFTS/YW/YVUJYG4+SYIqxX0PZnvZ6gk94EFa37lWsE0Sud4Z6qnn6yMJD0yP0dAJDd6xLG7/sJGJCalvnhsDP1gVwWLJHtYjEjZXkSHk= root@flux-676dcdd787-tbqcw
Es gibt aber auch die Möglichkeit, einen eigenen, spezifischen Key zu hinterlegen. Dies ist hier genauer erläutert.
Ohne zusätzliche Konfiguration wir das Git-Repository aller 5 Minuten gesynced. Allerdings kann man einen Sync auch manuell auslösen:
$ fluxctl sync --k8s-fwd-ns flux
Synchronizing with ssh://git@gitlab.com/XXX
Revision of master to apply is f27a086
Waiting for f27a086 to be applied ...
Done.
Damit ist Flux erfolgreich installiert und zumindest grundlegend konfiguriert. Ein Beispieldeployment um die Funktionalität initial zu testen findet sich auch auf Github.
Nutzung/Konfiguration
Die Konfiguration des fluxd läuft weniger über den Daemon selbst, als mehr über z.B. Annotations an den Deployments.
Bevor damit begonnen werden kann, sollte noch der Begriff des Workloads erklärt werden. Dieser steht im Kontext von Flux für jede Clusterresource, die in irgendeiner Form Container mittels versionierten Images erstellt. Das wäre in Kubernetes neben Deployments z.B. auch Daemonsets, Statefulsets oder (Cron-)Jobs.
Diese können via dem CLI-Tool fluxctl gesteuert bzw. konfiguriert werden.
Generell werden die Workloads über Annotations gesteuert bzw. geben diese fluxd Anweisungen wie mit ihnen zu verfahren ist.
Ein Beispiel aus dem aktuellen Testcluster (Erläuterungen dazu folgen später):
$ kubectl get replicaset.apps/podinfo-7599d75df -n testspace -o yaml | head -12
apiVersion: apps/v1
kind: ReplicaSet
metadata:
annotations:
deployment.kubernetes.io/desired-replicas: "2"
deployment.kubernetes.io/max-replicas: "3"
deployment.kubernetes.io/revision: "1"
fluxcd.io/automated: "true"
fluxcd.io/sync-checksum: 1845334e4ef3156c6a84a2866206bebb626fac6c
fluxcd.io/tag.init: regex:^3.10.*
fluxcd.io/tag.podinfod: semver:~3.1
creationTimestamp: "2020-03-27T09:05:32Z"
Auflisten der Workloads
Eine Liste der Workloads kann man sich mittels fluxctl list-workloads ausgeben lassen. Dabei werden jedoch nur die Workloads im Namespace des fluxd-Container angezeigt. Um sich die Workloads in allen Namespaces anzeigen zu lassen kann hier -a angehangen werden. Für einen bestimmten Namespace steht -n $NS zu Verfügung wobei $NS der Name des Namespaces ist.
Folgend ein Beispiel aus dem Testsetup:
$ fluxctl list-workloads --k8s-fwd-ns flux -a
WORKLOAD CONTAINER IMAGE RELEASE POLICY
testspace:deployment/podinfo podinfod stefanprodan/podinfo:3.1.5 ready automated
init alpine:3.10
flux:deployment/flux flux docker.io/fluxcd/flux:1.18.0 ready
flux:deployment/memcached memcached memcached:1.5.20 ready
kube-system:daemonset/kube-proxy kube-proxy k8s.gcr.io/kube-proxy:v1.17.3 ready
kube-system:deployment/coredns coredns k8s.gcr.io/coredns:1.6.5 ready
$ fluxctl list-workloads --k8s-fwd-ns flux -n testspace
WORKLOAD CONTAINER IMAGE RELEASE POLICY
testspace:deployment/podinfo podinfod stefanprodan/podinfo:3.1.5 ready automated
init alpine:3.10
Um sich alle Instanzen des Containers podinfod anzeigen zu lassen kann folgendes verwendet werden:
$ fluxctl list-workloads --k8s-fwd-ns flux -a -c podinfod
WORKLOAD CONTAINER IMAGE RELEASE POLICY
testspace:deployment/podinfo podinfod stefanprodan/podinfo:3.1.5 ready automated
init alpine:3.10
Da flux nicht im default-Namespace deployed wurde muss entsprechend immer mit --k8s-fwd-ns flux der Namespace mit angegeben werden, in dem die entsprechende fluxd-Instanz zu finden ist.
Details zu den Workload-Images
Flux scannt neben dem Git-Repository auch die Container-Registry aus dem die Images deployed werden nach allen verfügbaren Versionen. Damit kann man sich auch alle Versionen der Images anzeigen lassen.
Hierfür muss man fluxctl nur zu list-images mitteilen welchen Workload in welchem Namespace man genauer untersuchen möchte.
$ fluxctl list-images --k8s-fwd-ns flux -n testspace --workload deployment/podinfo
WORKLOAD CONTAINER IMAGE CREATED
testspace:deployment/podinfo podinfod stefanprodan/podinfo
| 9715769 27 Oct 18 08:52 UTC
| 7181351 25 Mar 19 10:13 UTC
| 2192219 18 Aug 18 11:24 UTC
| 3.2.1 24 Mar 20 12:05 UTC
| 3.2.0 24 Mar 20 10:19 UTC
'-> 3.1.5 21 Jan 20 11:40 UTC
3.1.4 06 Nov 19 22:21 UTC
3.1.3 06 Nov 19 22:16 UTC
3.1.2 06 Nov 19 22:02 UTC
3.1.1 06 Nov 19 22:00 UTC
init alpine
| 3 23 Mar 20 21:19 UTC
| 3.11 23 Mar 20 21:19 UTC
| 3.11.5 23 Mar 20 21:19 UTC
| latest 23 Mar 20 21:19 UTC
| 20200319 20 Mar 20 03:25 UTC
| edge 20 Mar 20 03:25 UTC
| 3.8 23 Jan 20 16:53 UTC
| 3.8.5 23 Jan 20 16:53 UTC
| 3.9 23 Jan 20 16:53 UTC
| 3.9.5 23 Jan 20 16:53 UTC
'-> 3.10 23 Jan 20 16:53 UTC
Dies zeigt alle verfügbaren Versionen für alle Container im Workload. Hier werden standardmäßig die aktuellsten 10 Versionen + die aktuell Laufende angezeigt. Dies kann man mittels dem Parameter -l anpassen (0 bedeutet dabei alle).
Releasen eines Workloads
Um manuell eine Version eines Images zu deployen gibt es die release Funktion von fluxctl, die automatisch das neueste Image für den Container deployed (sofern nicht durch Konfiguration eingeschränkt).
Da im Deployment unseres Demosystems das automatische Update aktiviert ist, hier ein Beispiel aus der Dokumentation:
$ fluxctl release --workload=default:deployment/helloworld --user=phil --message="New version" --update-all-images
Submitting release ...
Commit pushed: 7dc025c
Applied 7dc025c61fdbbfc2c32f792ad61e6ff52cf0590a
WORKLOAD STATUS UPDATES
default:deployment/helloworld success helloworld: quay.io/weaveworks/helloworld:master-a000001 -> master-9a16ff945b9e
Automatische Releases
Um automatisch immer die neueste Version im Workload deployen zu lassen kann das Automation-Feature aktiviert werden.
Dies kann entweder in den Workload-Yamls im Git-Repository mittels der Annotation fluxcd.io/automated: "true" geschehen oder im Nachgang durch das fluxctl-Kommando
fluxctl automate --workload=$Workload.
Die Automatisierung kann entweder via der Annotation fluxcd.io/automated: "false" oder der CLI mit fluxctl deautomate --workload=$workload deaktiviert werden.
Wird eine neue Version eines Container in der Registry released welcher auch Teil eines Workloads ist, so wird bei aktivierter Automatisierung automatisch auch das Deployment des Workloads angepasst und die neue Version deployed.
Diese Änderung wird dann (in der Standardkonfiguration) auch in das Git-Repository gepushed. In der History äußert sich dies durch Einträge wie:
$ git log workloads/podinfo-dep.yaml
commit f27a08637d69d391bc639b62dfc5353b70a9e2e6 (HEAD -> master, origin/master)
Author: Author
Date: Mon Mar 23 11:39:14 2020 +0000
Auto-release stefanprodan/podinfo:3.1.5
commit 9db210a8066141bd5600f399078a79c2ab462b0b
Author: Author
Date: Mon Mar 23 11:39:01 2020 +0000
Auto-release alpine:3.10
Welche Versionen automatisch deployed werden kann natürlich ebenso konfiguriert werden, um z.B.: sicher zu stellen dass man innerhalb einer Major-Version verbleibt.
Dafür muss am Workload entsprechend die Version gepinned werden. In diesen ist beschrieben welche Tags die Images haben müssen, um deployed zu werden.
Das Schema dabei ist fluxcd.io/tag.<container-name>: <filter-type>:<filter-value> oder filter.fluxcd.io/<container-name>: <filter-type>:<filter-value>.
Als Filtertypen können folgende Optionen gesetzt werden:
- glob
- Einfache Wildcards mit
* - z.B.
fluxcd.io/tag.podinfod: glob:master-v1.*.*
- Einfache Wildcards mit
- semver
- „Semantic Versioning“. Die Tags müssen also in das Schema X.Y.Z. passen, und es kann ein Filter darauf angegeben werden.
- z.B:
fluxcd.io/tag.podinfod: semver:~3.1um alle Images der Version 3.1.X für das automatische Deployment freizugeben
- regexp / regex
- Reguläre Ausrdrücke, z.B.
fluxcd.io/tag.init: regex:^3.10.* - Wie üblich ist zu beachten, dass um den gesamten Tag abzudecken der regex auch mit
^$eingefasst werden muss.
- Reguläre Ausrdrücke, z.B.
Diese Annotations können entweder auch in den yamls der Workloads hinterlegt werden oder nachträglich via z.B. fluxctl policy --workload=default:deployment/helloworld --tag-all='glob:master-v1.*.*' gesetzt werden.
Eine umfassende Dokumentation dazu findet sich hier.
Rollback
Es ist auch soweit problemlos möglich auf ein älteres Release zurück zu wechseln, insofern dieses in die ggf. gesetzten Filter-Tags passt.
Hierzu muss zuerst die Automation abgeschaltet werden. Anschließend kann mit z.B. folgendem fluxctl release ein bestimmtes Release deployed werden:
$ fluxctl release --workload=default:deployment/helloworld --update-image=quay.io/weaveworks/helloworld:master-a000001
Hier ist natürlich bei Stateful-Applications darauf zu achten, das keine Inkompatibilitäten mit Drittkomponenten auftreten.
Locking/Unlocking
Der Vollständigkeit halber sei noch erwähnt, dass man Workloads auch generell via fluxctl lock --workload=deployment/helloworld für automatische Deployments jeder Art sperren kann. Ein entsperren erfolgt dann entsprechend mit fluxctl unlock --workload=deployment/helloworld.
Generierung/Anpassung von Workloads
Flux hat eine Unterstützung für Kustomize bereits von Haus aus eingebaut, womit es möglich ist in begrenztem Maße Workloads mittels Yaml-Overlays dynamisch anzupassen.
Da die Behandlung dieses Themas jedoch den Rahmen des Artikels sprengen würde sei hier nur die Dokumentation verlinkt.
Bei Interesse können wird dies jedoch gern in einem separaten Artikel genauer ausführen.
Bei Fragen zum Einsatz von Flux stehen wir Ihnen natürlich gerne zur Verfügung. Sprechen Sie uns an!
In unserem vorhergehenden Artikel über Buildah haben wir erläutert wie man Container auch ohne Docker und root-Berechtigungen erstellt.
In diesem Artikel soll es darum gehen wie man eben jene Container auch ohne erweiterte Rechte nutzen kann.
Podman gehört neben dem bereits erwähnten Buildah und Skopeo zu den RedHat Container Tools und ist, kurz Zusammengefasst, eine daemonlose Laufzeitumgebung für Container. Es ist dabei, wie der Docker-Daemon, für den Betrieb eines einzelnen Hosts ausgelegt und bietet auch keine Clusterfunktionalität.
Entwicklung
Podman wurde in der Version 1.0 am 11.01.2019 released und steht ebenfalls unter der Apache 2.0 Lizenz.
Die Implementierung erfolgt in Golang und wird von der „containers organisation“ in erster Instanz vorangetrieben. Diese beinhaltet sowohl RedHat-Mitarbeiter als auch externe Entwickler.
Der Code kann auf Github eingesehen werden. Die Entwicklung erfolgt dabei in keinem festen Releasezyklus. So können sowohl Monate wie auch Wochen zwischen den Versionen liegen, je nachdem wenn Entschieden wird, dass genügend neue Features für einen Release implementiert wurden.
Podman selbst baut komplett auf die libpod auf, bzw. könnte man auch sagen, dass es das Tool zur libpod ist. Daher ist der Name des Repositorys auch libpod und nicht podman.
Container ohne root-Berechtigungen
Eine zentrale Komponente von Buildah und auch Podman ist hier die libpod welche es ermöglicht Container nur mit Nutzerberechtigungen zu starten und Images zu erstellen.
Diese setzt auf slirp4netns, fuse-overlayfs und die /etc/sub(u|g)id.
Dieser Bereich wurde bereits ausführlich im Artikel zu Buildah behandelt, weswegen hier nur auf diesen verwiesen wird, um Wiederholungen zu vermeiden.
Installation
Podman ist bei den gängigen RedHat-Distributionen direkt in den Repositories verfügbar.
Diese können dort je nach Version via dnf install podman oder yum install podman installiert werden.
Zu beachten ist, dass die Pakete in den CentOS-Distributionen nicht unbedingt aktuell sind. Daher bietet es sich hier an ebenfalls auf Kubic auszuweichen.
Für Debian und Derivate sowie Suse stehen analog zu Buildah Pakete in Kubic bereit.
Weitere Informationen dazu finden sich in der Dokumentation
[podmanager@buildah ~]$ podman -v podman version 1.8.2
Konfiguration
Die Konfigurationsdatei für Podman ist analog zu Builder unter /etc/containers/libpod.conf für die globale und unter ~/.config/containers/libpod.conf für die benutzerspezifische Konfiguration zu finden.
Die Vorlage mit den Default-Werten findet sich unter /usr/share/containers/libpod.conf. Diese sollte jedoch nicht direkt, sondern durch die beiden Alternativen angepasst werden.
In der Datei lassen sich verschiedene Parameter für Podman konfigurieren; welches CNI-Plugin genutzt werden soll, welche Container-Runtime oder auch wo die Volumes der Container zu finden sind.
Ein Online-Beispiel findet sich auf Github
Für einen ersten Testbetrieb sind hier jedoch keine Änderungen erforderlich, es dient lediglich dazu ggf. podman an die eigenen Wünsche anzupassen.
Arbeiten mit Podman
Podman wurde als Drop-In-Replacement für Docker entworfen und daher funktionieren die meisten Befehle wie ps, rm, inspect, logs oder exec analog zu docker und sollen hier wenn dann nur kurz erwähnt werden. Die Funktionalität ist dabei nicht nur auf den Betrieb von Container beschränkt, es ist im begrenzten Maße auch möglich Container zu erstellen. Im Hintergrund setzt Podman auf die Funktionalität von Buildah, kann jedoch Container nur aus einem Containerfile heraus erstellen.
Details dazu finden sich in der Dokumentation
Auch ein podman top $ContainerID funktioniert ebenso wie das Erstellen, Migrieren und Restore eines Checkpoints.
[user@system1 ~]$ podman container checkpoint <container_id> -e /tmp/checkpoint.tar.gz [user@system1 ~]$ scp /tmp/checkpoint.tar.gz <destination_system>:/tmp [user@system2 ~]$ podman container restore -i /tmp/checkpoint.tar.gz
In den folgenden Bereichen soll daher in erster Linie auf die Unterschiede in der Containerhandhabe zwischen Docker und Podman eingegangen werden.
Einen Container starten
Um einen Container der Wahl (hier postgres) zu starten, pullen wir das Image und starten dies anschließend.
[podmanager@buildah ~]$ podman pull postgres
...
Copying config 73119b8892 done
Writing manifest to image destination
Storing signatures
73119b8892f9cda38bb0f125b1638c7c0e71f4abe9a5cded9129c3f28a6d35c3
[podmanager@buildah ~]$ podman inspect postgres | grep "PG_VERSION="
"PG_VERSION=12.2-2.pgdg100+1",
"created_by": "/bin/sh -c #(nop) ENV PG_VERSION=12.2-2.pgdg100+1",
[podmanager@buildah ~]$ podman run -d -e POSTGRES_PASSWORD=SuperDB --name=postgres_dev postgres
c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7
[podmanager@buildah ~]$ podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c8b9732b6ad2 docker.io/library/postgres:latest postgres 5 seconds ago Up 4 seconds ago postgres_dev
Es läuft nun ein PostgreSQL®-Container mit dem Namen „postgres_dev“. Dies unterscheidet sich soweit nicht von Docker.
Die Besonderheit von podman ist erst in der Prozessliste ersichtlich:
podmana+ 2209 1 0 13:11 ? Ssl 0:00 /usr/bin/conmon --api-version 1 -c c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -u c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -r /usr/bin/runc -b 232070 2219 2209 0 13:11 ? Ss 0:00 \_ postgres
Der PostgreSQL®-Prozess läuft nicht als Kind eines Daemon-Prozesses, sondern der Komponente „conmon“.
Diese überwacht den Zustand des Containers nach dem Start. Außerdem stellt es den Socket für die Kommunikation bereit und den Stream für den Output, welche
in das von podman konfigurierte Log geschrieben werden.
Weiterführende Informationen zu conmon finden sich auf Github
Starten wir jetzt einen zweiten Container (postgres_prod) via podman wird ein weiterer conmon-Prozess gestartet:
[podmanager@buildah ~]$ podman run -d -e POSTGRES_PASSWORD=SuperDB --name=postgres_prod postgres 6581a25c82620c725fe1cfb6546479edac856228ecb3c11ad63ab95a453c1b64 [podmanager@buildah ~]$ podman ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 6581a25c8262 docker.io/library/postgres:latest postgres 15 seconds ago Up 15 seconds ago postgres_prod c8b9732b6ad2 docker.io/library/postgres:latest postgres 7 minutes ago Up 7 minutes ago postgres_dev
podmana+ 2209 1 0 13:11 ? Ssl 0:00 /usr/bin/conmon --api-version 1 -c c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -u c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -r /usr/bin/runc -b 232070 2219 2209 0 13:11 ? Ss 0:00 \_ postgres ... podmana+ 2337 1 0 13:19 ? Ssl 0:00 /usr/bin/conmon --api-version 1 -c 6581a25c82620c725fe1cfb6546479edac856228ecb3c11ad63ab95a453c1b64 -u 6581a25c82620c725fe1cfb6546479edac856228ecb3c11ad63ab95a453c1b64 -r /usr/bin/runc -b 232070 2348 2337 0 13:19 ? Ss 0:00 \_ postgres ...
Hier finden sich im Prozess jeweils die UUIDs der Container wieder.
Der cmdline des Prozesses ist natürlich sehr viel länger als hier dargestellt. Folgend noch ein komplettes Beispiel manuell formatiert:
[podmanager@buildah ~]$ ps -ef f | grep conmon ... podmana+ 2209 1 0 13:11 ? Ssl 0:00 /usr/bin/conmon --api-version 1 -c c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -u c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -r /usr/bin/runc -b /home/podmanager/.local/share/containers/storage/overlay-containers/c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7/userdata -p /var/tmp/run-1002/containers/overlay-containers/c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7/userdata/pidfile -l k8s-file:/home/podmanager/.local/share/containers/storage/overlay-containers/c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7/userdata/ctr.log --exit-dir /var/tmp/run-1002/libpod/tmp/exits --socket-dir-path /var/tmp/run-1002/libpod/tmp/socket --log-level error --runtime-arg --log-format=json --runtime-arg --log --runtime-arg=/var/tmp/run-1002/containers/overlay-containers/c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7/userdata/oci-log --conmon-pidfile /var/tmp/run-1002/containers/overlay-containers/c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7/userdata/conmon.pid --exit-command /usr/bin/podman --exit-command-arg --root --exit-command-arg /home/podmanager/.local/share/containers/storage --exit-command-arg --runroot --exit-command-arg /var/tmp/run-1002/containers --exit-command-arg --log-level --exit-command-arg error --exit-command-arg --cgroup-manager --exit-command-arg cgroupfs --exit-command-arg --tmpdir --exit-command-arg /var/tmp/run-1002/libpod/tmp --exit-command-arg --runtime --exit-command-arg runc --exit-command-arg --storage-driver --exit-command-arg overlay --exit-command-arg --storage-opt --exit-command-arg overlay.mount_program=/usr/bin/fuse-overlayfs --exit-command-arg --storage-opt --exit-command-arg overlay.mount_program=/usr/bin/fuse-overlayfs --exit-command-arg --events-backend --exit-command-arg file --exit-command-arg container --exit-command-arg cleanup --exit-command-arg c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 ...
Durch die Formatierung ist sehr schön zu sehen, wie die Übergabe von Parametern zwischen podman und conmon über die *args funktioniert.
Zusätzlich zu conmon wird natürlich auch jeweils eine Instanz von slirp4netns und fuse-overlayfs pro container gestartet um Netzwerk und Storage ohne root-Berechtigungen bereitzustellen.
podmana+ 2201 1 0 13:11 ? Ss 0:00 /usr/bin/fuse-overlayfs -o lowerdir=/home/podmanager/.local/share/containers/storage/overlay/l/FX4RZGGJ5HSNVMGVFG6K3I7PIL:/home/podmanager/.local/share/containers/storage/overlay/l/AIHUOS podmana+ 2206 1 0 13:11 pts/0 S 0:00 /usr/bin/slirp4netns --disable-host-loopback --mtu 65520 --enable-sandbox -c -e 3 -r 4 --netns-type=path /tmp/run-1002/netns/cni-18902a12-5b1b-15d3-0c31-138efe1d66ba tap0 podmana+ 2209 1 0 13:11 ? Ssl 0:00 /usr/bin/conmon --api-version 1 -c c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -u c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -r /usr/bin/runc -b 232070 2219 2209 0 13:11 ? Ss 0:00 \_ postgres
Erstellen eines Systemd-service-files
Da die Container ohne Daemon laufen und einzeln angestartet werden können, bietet es sich natürlich auch an diese nicht via Docker, sondern via Systemd zu steuern.
Das Schreiben von Service-files ist jedoch im allgemeinen mühsam, weswegen podman dafür direkt eine Funktion eingebaut hat.
Folgend ein Beispiel für unsere postgres_dev
[podmanager@buildah ~]$ podman generate systemd postgres_dev # container-c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7.service # autogenerated by Podman 1.8.2 # Tue Mar 24 13:47:11 CET 2020 [Unit] Description=Podman container-c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7.service Documentation=man:podman-generate-systemd(1) Wants=network.target After=network-online.target [Service] Environment=PODMAN_SYSTEMD_UNIT=%n Restart=on-failure ExecStart=/usr/bin/podman start c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 ExecStop=/usr/bin/podman stop -t 10 c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 PIDFile=/var/tmp/run-1002/containers/overlay-containers/c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7/userdata/conmon.pid KillMode=none Type=forking [Install] WantedBy=multi-user.target default.target
Einen Fehler gibt es hier jedoch noch. Es muss im Servicefile der User ergänzt werden unter dem der Container gestartet werden soll, insofern dies nicht als root passieren soll. Dazu muss in der Sektion [Service] nur User=podmanager ergänzt werden (bzw. der Username auf ihrem System).
Um den Container als Service zu hinterlegen wären unter CentOS 8 folgende Schritte durchzuführen:
[podmanager@buildah ~]$ podman generate systemd --files --name postgres_dev
/home/podmanager/container-postgres_dev.service
# User= im servicefile ergänzen
[podmanager@buildah ~]$ sudo cp /home/podmanager/container-postgres_dev.service /etc/systemd/system/
[podmanager@buildah ~]$ sudo systemctl daemon-reload
[podmanager@buildah ~]$ sudo systemctl start container-postgres_dev.service
[podmanager@buildah ~]$ systemctl status container-postgres_dev.service
● container-postgres_dev.service - Podman container-postgres_dev.service
Loaded: loaded (/etc/systemd/system/container-postgres_dev.service; disabled; vendor preset: disabled)
Active: active (running) since Tue 2020-03-24 14:04:14 CET; 1s ago
Docs: man:podman-generate-systemd(1)
Process: 7691 ExecStart=/usr/bin/podman start postgres_dev (code=exited, status=0/SUCCESS)
Main PID: 7717 (conmon)
Tasks: 11 (limit: 25028)
Memory: 46.7M
CGroup: /system.slice/container-postgres_dev.service
├─7710 /usr/bin/fuse-overlayfs -o lowerdir=/home/podmanager/.local/share/containers/storage/overlay/l/FX4RZGGJ5HSNVMGVFG6K3I7PIL:/home/podmanager/.local/share/containers/storage/overlay/l/AIHUOSIVGT5DN5GCUR7PRELVKK:/home/podma>
├─7714 /usr/bin/slirp4netns --disable-host-loopback --mtu 65520 --enable-sandbox -c -e 3 -r 4 --netns-type=path /tmp/run-1002/netns/cni-a0ee9d78-2f8c-a563-1947-92d0766a43b7 tap0
├─7717 /usr/bin/conmon --api-version 1 -c c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -u c8b9732b6ad253710ae6e75f934a74e8469e61bc5b5d88c2fa92c7257d00d2e7 -r /usr/bin/runc -b /home/podmanager/.local/share/c>
├─7727 postgres
├─7758 postgres: checkpointer
├─7759 postgres: background writer
├─7760 postgres: walwriter
├─7761 postgres: autovacuum launcher
├─7762 postgres: stats collector
└─7763 postgres: logical replication launcher
Mär 24 14:04:13 buildah.localdomain systemd[1]: Starting Podman container-postgres_dev.service...
Mär 24 14:04:14 buildah.localdomain podman[7691]: postgres_dev
Mär 24 14:04:14 buildah.localdomain systemd[1]: Started Podman container-postgres_dev.service.
Wichtig zu erwähnen ist noch, dass man den über Systemd gestarteten Container natürlich auch via podman administrieren / erreichen kann, zumindest das Starten und Stoppen aber dem Service überlassen sollte.
Erstellen eines Pods
Wie der Name vermuten lässt ist es mit Podman nicht nur möglich Container zu erstellen, sondern diese auch in Pods zu organisieren.
Ein Pod stellt dabei analog zu Kubernetes einen organisatorischen Verbund von Containern dar die sich auch bestimmte Namespaces wie pids, network o.ä. teilen können.
Diese werden dann via podman pod $cmd administriert.
Im Folgenden laden wir das Image des postgres-exporters für prometheus und erstellen daraus einen Pod mit der Bezeichnung postgres-prod-pod.
[podmanager@buildah ~]$ podman pull docker.io/wrouesnel/postgres_exporter
[podmanager@buildah ~]$ podman pod create --name postgres-prod-pod
727e7544515e0e683525e555934e02a341a42009a9c49fb2fd53094187a1e97c
[podmanager@buildah ~]$ podman run -d --pod postgres-prod-pod -e POSTGRES_PASSWORD=SuperDB postgres:latest
8f313260973ef6eb6fa84d2893875213cee89b48c93d08de7642b0a8b03c4a88
[podmanager@buildah ~]$ podman run -d --pod postgres-prod-pod -e DATA_SOURCE_NAME="postgresql://postgres:password@localhost:5432/postgres?sslmode=disable" postgres_exporter
fee22f24ff9b2ace599831fa022fb1261ef836846e0ba938c7b469d8dfb8a48a
[podmanager@buildah ~]$ podman pod ps
POD ID NAME STATUS CREATED # OF CONTAINERS INFRA ID
727e7544515e postgres-prod-pod Running 48 seconds ago 3 6edc862441f1
[podmanager@buildah ~]$ podman pod inspect postgres-prod-pod
{
"Config": {
"id": "727e7544515e0e683525e555934e02a341a42009a9c49fb2fd53094187a1e97c",
"name": "postgres-prod-pod",
"hostname": "postgres-prod-pod",
"labels": {
},
"cgroupParent": "/libpod_parent",
"sharesCgroup": true,
"sharesIpc": true,
"sharesNet": true,
"sharesUts": true,
"infraConfig": {
"makeInfraContainer": true,
"infraPortBindings": null
},
"created": "2020-03-24T14:44:27.01249721+01:00",
"lockID": 0
},
"State": {
"cgroupPath": "/libpod_parent/727e7544515e0e683525e555934e02a341a42009a9c49fb2fd53094187a1e97c",
"infraContainerID": "6edc862441f18234f0c61693f11d946f601973a71b85fa9d777273feed68ed3c",
"status": "Running"
},
"Containers": [
{
"id": "6edc862441f18234f0c61693f11d946f601973a71b85fa9d777273feed68ed3c",
"state": "running"
},
{
"id": "8f313260973ef6eb6fa84d2893875213cee89b48c93d08de7642b0a8b03c4a88",
"state": "running"
},
{
"id": "fee22f24ff9b2ace599831fa022fb1261ef836846e0ba938c7b469d8dfb8a48a",
"state": "running"
}
]
}
Hier ist nun zu sehen, dass der Pod die beiden Container postgres und postgres-exporter beinhaltet (Vergleich UUIDs).
Der dritte Container ist der Infra-Container für das Bootstrapping und soll hier nicht weiter Thema sein.
In der Prozessliste zeigt sich das Ganze dann wie folgt:
podmana+ 6279 1 0 14:44 ? Ss 0:00 /usr/bin/fuse-overlayfs -o lowerdir=/home/podmanager/.local/share/containers/storage/overlay/l/ podmana+ 6281 1 0 14:44 pts/2 S 0:00 /usr/bin/slirp4netns --disable-host-loopback --mtu 65520 --enable-sandbox -c -e 3 -r 4 --netns-type=path /tmp/run-1002/netns/cni-5fe4356e-77c0-8127-f72b-7335c2ed05c4 tap0 podmana+ 6284 1 0 14:44 ? Ssl 0:00 /usr/bin/conmon --api-version 1 -c 6edc862441f18234f0c61693f11d946f601973a71b85fa9d777273feed68ed3c -u 6edc862441f18234f0c61693f11d946f601973a71b85fa9d777273feed68ed3c -r /usr/bin/runc -b podmana+ 6296 6284 0 14:44 ? Ss 0:00 \_ /pause podmana+ 6308 1 0 14:44 ? Ss 0:00 /usr/bin/fuse-overlayfs -o lowerdir=/home/podmanager/.local/share/containers/storage/overlay/l/FX4RZGGJ5HSNVMGVFG6K3I7PIL:/home/podmanager/.local/share/containers/storage/overlay/l/AIHUOS podmana+ 6312 1 0 14:44 ? Ssl 0:00 /usr/bin/conmon --api-version 1 -c 8f313260973ef6eb6fa84d2893875213cee89b48c93d08de7642b0a8b03c4a88 -u 8f313260973ef6eb6fa84d2893875213cee89b48c93d08de7642b0a8b03c4a88 -r /usr/bin/runc -b 232070 6322 6312 0 14:44 ? Ss 0:00 \_ postgres ... 232070 6549 6322 0 14:44 ? Ss 0:00 \_ postgres: postgres postgres ::1(51290) idle podmana+ 6520 1 0 14:44 ? Ss 0:00 /usr/bin/fuse-overlayfs -o lowerdir=/home/podmanager/.local/share/containers/storage/overlay/l/P5NJW4TB6JUFOBBIN2MOHW7272:/home/podmanager/.local/share/containers/storage/overlay/l/KVC54Z podmana+ 6523 1 0 14:44 ? Ssl 0:00 /usr/bin/conmon --api-version 1 -c fee22f24ff9b2ace599831fa022fb1261ef836846e0ba938c7b469d8dfb8a48a -u fee22f24ff9b2ace599831fa022fb1261ef836846e0ba938c7b469d8dfb8a48a -r /usr/bin/runc -b 251072 6534 6523 0 14:44 ? Ssl 0:00 \_ /postgres_exporter
Hier ist zu sehen, dass es zwar mehrere conmon und overlayfs-Prozesse für die Container gibt, jedoch nur einen slirp4netns, da die Container sich diesen teilen und darüber auch via localhost kommunizieren können.
Auch ist zu sehen dass die PostgreSQL®-Datenbank eine Verbindung von localhost hat (PID 6549) wobei es sich um den Exporter handelt.
Im Normalfall werden bei der Erstellung eines Pods via podman pod create folgende Namespaces für die Container zusammengefasst: net,ipc,uts und user.
Somit hat auch jeder Container trotz der Zusammenfassung im Pod noch seinen eigenen PID-namespace.
Sollte dies jedoch gewünscht sein, so kann mittels dem Parameter --share bei der Erstellung angegeben werden was alles geteilt werden soll.
So sieht z.B. die Prozessliste des Pods ohne gemeinsamen pid-namespace aus. Jeder Container hat seine eigene Prozesstruktur.
[podmanager@buildah ~]$ podman pod top postgres-prod-pod USER PID PPID %CPU ELAPSED TTY TIME COMMAND 0 1 0 0.000 11m45.845291911s ? 0s /pause postgres 1 0 0.000 11m45.854330176s ? 0s postgres postgres 25 1 0.000 11m45.854387876s ? 0s postgres: checkpointer postgres 26 1 0.000 11m45.854441615s ? 0s postgres: background writer postgres 27 1 0.000 11m45.854483844s ? 0s postgres: walwriter postgres 28 1 0.000 11m45.854525645s ? 0s postgres: autovacuum launcher postgres 29 1 0.000 11m45.854567082s ? 0s postgres: stats collector postgres 30 1 0.000 11m45.854613262s ? 0s postgres: logical replication launcher postgres 31 1 0.000 11m45.854653703s ? 0s postgres: postgres postgres ::1(51292) idle postgres_exporter 1 0 0.000 11m45.859505449s ? 0s /postgres_exporter
Als Alternative die Ausgabe bei der Erstellung des Pods mittels podman pod create --name postgres-prod-pod --share=pid,net,ipc,uts,user
[podmanager@buildah ~]$ podman pod top postgres-prod-pod USER PID PPID %CPU ELAPSED TTY TIME COMMAND root 1 0 0.000 20.396867487s ? 0s /pause postgres 6 0 0.000 20.396936905s pts/0 0s postgres postgres 60 6 0.000 18.396997034s ? 0s postgres: checkpointer postgres 61 6 0.000 18.397086198s ? 0s postgres: background writer postgres 62 6 0.000 18.39713465s ? 0s postgres: walwriter postgres 63 6 0.000 18.39718056s ? 0s postgres: autovacuum launcher postgres 64 6 0.000 18.397229737s ? 0s postgres: stats collector postgres 65 6 0.000 18.397279102s ? 0s postgres: logical replication launcher 20001 66 0 0.000 16.397325377s pts/0 0s /postgres_exporter
Zur Auswahl stehen bei --share ipc, net, pid, user und uts.
Der gesamte pod kann nun auch via podman pod stop/start gestartet und gestoppt werden.
Ebenso können für Pods wie Container systemd-service-files generiert werden.
Podman und Kubernetes
Podman bietet einige Unterstützung im Bereich Kubernetes-YAML.
So ist es z.B. möglich aus den Pods, welche man mit podman erstellt hat, kubernes-Pod YAML zu generieren.
[podmanager@buildah ~]$ podman generate kube postgres-prod-pod -f postgres-prod-pod.yaml
[podmanager@buildah ~]$ cat postgres-prod-pod.yaml
# Generation of Kubernetes YAML is still under development!
#
# Save the output of this file and use kubectl create -f to import
# it into Kubernetes.
#
# Created with podman-1.8.2
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2020-03-24T14:08:14Z"
labels:
app: postgres-prod-pod
name: postgres-prod-pod
spec:
containers:
- command:
- postgres
env:
...
image: docker.io/library/postgres:latest
name: reverentptolemy
resources: {}
securityContext:
allowPrivilegeEscalation: true
capabilities: {}
privileged: false
readOnlyRootFilesystem: false
seLinuxOptions: {}
workingDir: /
- env:
...
image: docker.io/wrouesnel/postgres_exporter:latest
name: friendlyshirley
resources: {}
securityContext:
allowPrivilegeEscalation: true
capabilities: {}
privileged: false
readOnlyRootFilesystem: false
runAsGroup: 20001
runAsUser: 20001
seLinuxOptions: {}
workingDir: /
status: {}
Mit der Option -s wird sogar noch ein Service mit ggf. published-Ports generiert:
---
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2020-03-24T14:10:42Z"
labels:
app: postgres-prod-pod
name: postgres-prod-pod
spec:
selector:
app: postgres-prod-pod
type: NodePort
status:
loadBalancer: {}
Die generate-yaml Funktionalität greift dabei für Pods wie auch für Services und auch in beide Richtungen.
Mit podman play ist es möglich Pod und Container-Definitionen in podman zu testen.
Fazit
Dies war ein grober Einblick in die Möglichkeiten Container ohne Daemon und root-Berechtigungen auf einem Host zu betreiben.
Natürlich ist mit podman noch viel mehr möglich, jedoch würde die Erläuterung jeder Option hier den Rahmen sprengen.
Zu erwähnen ist vielleicht noch, dass Podman mit aktiviertem cgroupsV2 auch z.B. Resourcennutzung in Pods auswerten kann.
Dies ist jedoch aktuell nur unter Fedora31 standardmäßig aktiviert.
Vom 14.11.2017 bis 17.11.2017 fand die ContainerConf 2017 im Rosengarten Mannheim statt. Es handelt sich hierbei um die zweite jährliche Veranstaltung die parallel zur fünften „Continous Lifecycle“ stattfand.
Beide Konferenzen drehen sich um alle erdenklichen Themen des Spektrums CI/CD, DevOps, Container und deren Tools, Methoden und das soziale System darum. Da beide Konferenzen parallel angeboten wurden, war nur die Anmeldung an einer der beiden Veranstaltungen nötig, um das volle Programm nutzen zu können. Als Veranstalter treten der dpunkt Verlag, Heise Developer und die IX auf.
Ingesamt fanden sich in diesem Jahr 640 Gäste ein. Die Konferenzen wurden in jeweils vier Tracks organisiert, die am 15.11. und 16.11. besucht werden konnten. In den Tagen vor und nach der Konferenz wurden verschieden Workshops u.A. zu den Themen Kubernetes, Monitoring mit Prometheus oder dem Erstellen von CD-Pipelines angeboten. Diese fanden entweder im Rosengarten oder dem angeschlossenen Dorint-Hotel statt.

Die Räumlichkeiten der Veranstaltung waren hochwertig ausgestattet und auch die gastronomische Versorgung der Teilnehmer war zu jedem Zeitpunkt mit kleinen Snacks, einem reichhaltigen Mittagsbuffet, sowie der ganztägigen Versorgung mit verschiedenen Getränken, sichergestellt. Am Abend des ersten eigentlichen Konferenztages wurde ein Social-Event mit verschiedenen Thementischen angeboten, an welcher man zu den angebotenen Themen diskutieren und verschiedene Menschen und Firmen kennenlernen konnte. Natürlich wurde auch hier die Verköstigung und Unterhaltung der Gäste mittels Livemusik sichergestellt.
Durch die vier parallelen Tracks hatte man häufig die Qual der Wahl, wie z.B. zwischen „Die Grenzen von Continuous Delivery“ (Eberhard Wolff, innoQ) und „DockAir – ein Rundflug durch das Kubernetes-Ökosystem“ (Nicolas Byl, codecentric).
Einige Vorträge werden nachträglich noch als Videoaufzeichnung veröffentlicht. Aktuell sind jedoch nur die Keynotes von 2017 verfügbar.
Gerade die Keynotes waren wie gewohnt mehr sozialer und organisatorischer als technischer Natur. So berichtete Jennifer Davis (Chef) von ihren ersten Erfahrungen in der Welt der Container, oder Patrick Kua (N26) vom Umdenken in den Bereichen Architektur und Umgang mit den Systemen. Brandon Philips (CoreOS) erläuterte in der letzten Keynote die Abstufungen verschiedener „Lock-ins“ und wie man diese (teilweise) umgehen kann.

Zwischen dem gebotenen Programm hatte man die Möglichkeit die zahlreichen Stände der Sponsoren zu besuchen und sich die Anbieter verschiedener Dienstleistungen genauer anzuschauen bzw. kennenzulernen. So waren hier z.B. Giant Swarm, CoreOS, Chef, Puppet und die Denic, sowie auch 1&1 vertreten. An vielen Stellen gab es Gewinnspiele, Merchandise oder einfach nur Informationen und Kontakte. Unser persönliches Highlight war eine „Trivial-Pursuit DevOps-Edition“ von automic.
Die ContainerConf 2017 war eine sowohl für Laien wie auch Experten lohnende Veranstaltung. Wir freuen uns schon auf nächstes Jahr!
